Versión imprimible multipagina. Haga click aquí para imprimir.
Arquitectura de Kubernetes
- 1: Nodos
- 2: Comunicación Nodo-Maestro
- 3: Conceptos subyacentes del Cloud Controller Manager
- 4: Container Runtime Interface (CRI)
1 - Nodos
Un nodo es una máquina de trabajo en Kubernetes, previamente conocida como minion. Un nodo puede ser una máquina virtual o física, dependiendo del tipo de clúster. Cada nodo está gestionado por el componente máster y contiene los servicios necesarios para ejecutar pods. Los servicios en un nodo incluyen el container runtime, kubelet y el kube-proxy. Accede a la sección The Kubernetes Node en el documento de diseño de arquitectura para más detalle.
Estado del Nodo
El estado de un nodo comprende la siguiente información:
Direcciones
El uso de estos campos varía dependiendo del proveedor de servicios en la nube y/o de la configuración en máquinas locales.
HostName: El nombre de la máquina huésped como aparece en el kernel del nodo. Puede ser reconfigurado a través del kubelet usando el parámetro--hostname-override.ExternalIP: La dirección IP del nodo que es accesible externamente (que está disponible desde fuera del clúster).InternalIP: La dirección IP del nodo que es accesible únicamente desde dentro del clúster.
Estados
El campo conditions describe el estado de todos los nodos en modo Running.
| Estado | Descripción |
|---|---|
OutOfDisk |
True si no hay espacio suficiente en el nodo para añadir nuevos pods; sino False |
Ready |
True si el nodo está en buen estado y preparado para aceptar nuevos pods, Falso si no puede aceptar nuevos pods, y Unknown si el controlador aún no tiene constancia del nodo después del último node-monitor-grace-period (por defecto cada 40 segundos) |
MemoryPressure |
True si hay presión en la memoria del nodo -- es decir, si el consumo de memoria en el nodo es elevado; sino False |
PIDPressure |
True si el número de PIDs consumidos en el nodo es alto -- es decir, si hay demasiados procesos en el nodo; sino False |
DiskPressure |
True si hay presión en el tamaño del disco -- esto es, si la capacidad del disco es baja; sino False |
NetworkUnavailable |
True si la configuración de red del nodo no es correcta; sino False |
El estado del nodo se representa como un objeto JSON. Por ejemplo, la siguiente respuesta describe un nodo en buen estado:
"conditions": [
{
"type": "Ready",
"status": "True"
}
]
Si el status de la condición Ready se mantiene como Unknown o False por más tiempo de lo que dura un pod-eviction-timeout, se pasa un argumento al kube-controller-manager y todos los pods en el nodo se marcan para borrado por el controlador de nodos. El tiempo de desalojo por defecto es de cinco minutos. En algunos casos, cuando el nodo se encuentra inaccesible, el API Server no puede comunicar con el kubelet del nodo. La decisión de borrar pods no se le puede hacer llegar al kubelet hasta que la comunicación con el API Server se ha restablecido. Mientras tanto, los pods marcados para borrado pueden continuar ejecutándose en el nodo aislado.
En versiones de Kubernetes anteriores a 1.5, el controlador de nodos forzaba el borrado de dichos pods inaccesibles desde el API Server. Sin embargo, desde la versión 1.5, el nodo controlador no fuerza el borrado de pods hasta que se confirma que dichos pods han dejado de ejecutarse en el clúster. Pods que podrían estar ejecutándose en un nodo inalcanzable se muestran como Terminating o Unknown. En aquellos casos en los que Kubernetes no puede deducir si un nodo ha abandonado el clúster de forma permanente, puede que sea el administrador el que tenga que borrar el nodo de forma manual. Borrar un objeto Node en un clúster de Kubernetes provoca que los objetos Pod que se ejecutaban en el nodo sean eliminados en el API Server y libera sus nombres.
En la versión 1.12, la funcionalidad TaintNodesByCondition se eleva a beta, de forma que el controlador del ciclo de vida de nodos crea taints de forma automática, que representan estados de nodos.
De forma similar, el planificador de tareas ignora estados cuando evalúa un nodo; en su lugar mira los taints del nodo y las tolerancias de los pods.
En la actualidad, los usuarios pueden elegir entre la versión de planificación antigua y el nuevo, más flexible, modelo de planificación. Un pod que no tiene definida ninguna tolerancia es planificado utilizando el modelo antiguo, pero si un nodo tiene definidas ciertas tolerancias, sólo puede ser asignado a un nodo que lo permita.
Capacidad
Describe los recursos disponibles en el nodo: CPU, memoria, y el número máximo de pods que pueden ser planificados dentro del nodo.
Información
Información general sobre el nodo: versión del kernel, versión de Kubernetes (versiones del kubelet y del kube-proxy), versión de Docker (si se utiliza), nombre del sistema operativo. Toda esta información es recogida por el kubelet en el nodo.
Gestión
A diferencia de pods y services, los nodos no son creados por Kubernetes de forma inherente; o son creados de manera externa por los proveedores de servicios en la nube como Google Compute Engine, o existen en la colección de máquinas virtuales o físicas. De manera que cuando Kubernetes crea un nodo, crea un objeto que representa el nodo. Después de ser creado, Kubernetes comprueba si el nodo es válido o no. Por ejemplo, si intentas crear un nodo con el siguiente detalle:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes crea un objeto Node internamente (la representación), y valida el nodo comprobando su salud en el campo metadata.name. Si el nodo es válido -- es decir, si todos los servicios necesarios están ejecutándose -- el nodo es elegible para correr un pod. Sino, es ignorado para cualquier actividad del clúster hasta que se convierte en un nodo válido.
Node explícitamente.
Actualmente, hay tres componentes que interactúan con la interfaz de nodos de Kubernetes: controlador de nodos, kubelet y kubectl.
Controlador de Nodos
El controlador de nodos es un componente maestro en Kubernetes que gestiona diferentes aspectos de los nodos.
El controlador juega múltiples papeles en la vida de un nodo. El primero es asignar un bloque CIDR (Class Inter-Domain Routing) al nodo cuando este se registra (si la asignación CIDR está activada) que contendrá las IPs disponibles para asignar a los objetos que se ejecutarán en ese nodo.
El segundo es mantener actualizada la lista interna del controlador con la lista de máquinas disponibles a través del proveedor de servicios en la nube. Cuando Kubernetes se ejecuta en la nube, si un nodo deja de responder, el controlador del nodo preguntará al proveedor si la máquina virtual de dicho nodo continúa estando disponible. Si no lo está, el controlador borrará dicho nodo de su lista interna.
El tercero es el de monitorizar la salud de los nodos. El controlador de nodos es el responsable de actualizar la condición NodeReady del campo NodeStatus a ConditionUnknown cuando un nodo deja de estar accesible (por ejemplo, si deja de recibir señales de vida del nodo indicando que está disponible, conocidas como latidos o hearbeats en inglés) y, también es responsable de posteriormente desalojar todos los pods del nodo si este continúa estando inalcanzable. Por defecto, cuando un nodo deja de responder, el controlador sigue reintentando contactar con el nodo durante 40 segundos antes de marcar el nodo con ConditionUnknown y, si el nodo no se recupera de ese estado pasados 5 minutos, empezará a drenar los pods del nodo para desplegarlos en otro nodo que esté disponible. El controlador comprueba el estado de cada nodo cada --node-monitor-period segundos.
En versiones de Kubernetes previas a 1.13, NodeStatus es el heartbeat del nodo. Empezando con 1.13 la funcionalidad de node lease se introduce como alfa (NodeLease,
KEP-0009). Cuando la funcionalidad está habilitada, cada nodo tiene un objeto Lease asociado en el namespace kube-node-lease que se renueva periódicamente y ambos, el NodeStatus y el Lease son considerados como hearbeats del nodo. Node leases se renuevan con frecuencia, mientras que NodeStatus se transmite desde el nodo al máster únicamente si hay cambios o si ha pasado cierto tiempo (por defecto, 1 minuto, que es más que la cuenta atrás por defecto de 40 segundos que marca un nodo como inalcanzable). Al ser los node lease más ligeros que NodeStatus, los hearbeats resultan más económicos desde las perspectivas de escalabilidad y de rendimiento.
En Kubernetes 1.4, se actualizó la lógica del controlador de nodos para gestionar mejor los casos en los que un gran número de nodos tiene problemas alcanzando el nodo máster (Por ejemplo, cuando el nodo máster es el que tiene un problema de red). Desde 1.4, el controlador de nodos observa el estado de todos los nodos en el clúster cuando toma decisiones sobre desalojo de pods.
En la mayoría de los casos, el controlador de nodos limita el ritmo de desalojo --node-eviction-rate (0.1 por defecto) por segundo, lo que significa que no desalojará pods de más de un nodo cada diez segundos.
El comportamiento de desalojo de nodos cambia cuando un nodo en una zona de disponibilidad tiene problemas. El controlador de nodos comprobará qué porcentaje de nodos en la zona no se encuentran en buen estado (es decir, que su condición NodeReady tiene un valor ConditionUnknown o ConditionFalse) al mismo tiempo. Si la fracción de nodos con problemas es de al menos --unhealthy-zone-threshold (0.55 por defecto) entonces se reduce el ratio de desalojos: si el clúster es pequeño (por ejemplo, tiene menos o los mismos nodos que --large-cluster-size-threshold - 50 por defecto) entonces los desalojos se paran. Sino, el ratio se reduce a --secondary-node-eviction-rate (0.01 por defecto) por segundo. La razón por la que estas políticas se implementan por zonas de disponibilidad es debido a que una zona puede quedarse aislada del nodo máster mientras que las demás continúan conectadas. Si un clúster no comprende más de una zona, todo el clúster se considera una única zona.
La razón principal por la que se distribuyen nodos entre varias zonas de disponibilidad es para que el volumen de trabajo se transfiera a aquellas zonas que se encuentren en buen estado cuando una de las zonas se caiga.
Por consiguiente, si todos los nodos de una zona se encuentran en mal estado, el nodo controlador desaloja al ritmo normal --node-eviction-rate. En el caso extremo de que todas las zonas se encuentran en mal estado (es decir, no responda ningún nodo del clúster), el controlador de nodos asume que hay algún tipo de problema con la conectividad del nodo máster y paraliza todos los desalojos hasta que se restablezca la conectividad.
Desde la versión 1.6 de Kubernetes el controlador de nodos también es el responsable de desalojar pods que están ejecutándose en nodos con NoExecute taints, cuando los pods no permiten dichos taints. De forma adicional, como una funcionalidad alfa que permanece deshabilitada por defecto, el NodeController es responsable de añadir taints que se corresponden con problemas en los nodos del tipo nodo inalcanzable o nodo no preparado. En esta sección de la documentación hay más detalles acerca de los taints NoExecute y de la funcionalidad alfa.
Desde la versión 1.8, el controlador de nodos puede ser responsable de la creación de taints que representan condiciones de nodos. Esta es una funcionalidad alfa en 1.8.
Auto-Registro de Nodos
Cuando el atributo del kubelet --register-node está habilitado (el valor por defecto), el kubelet intentará auto-registrarse con el API Server. Este es el patrón de diseño preferido, y utilizado por la mayoría de distribuciones.
Para auto-registro, el kubelet se inicia con las siguientes opciones:
--kubeconfig- La ruta a las credenciales para autentificarse con el API Server.--cloud-provider- Cómo comunicarse con un proveedor de servicios para leer meta-datos sobre si mismo.--register-node- Registro automático con el API Server.--register-with-taints- Registro del nodo con la lista de taints proporcionada (separada por comas<key>=<value>:<effect>). Esta opción se ignora si el atributo--register-nodeno está habilitado.--node-ip- La dirección IP del nodo.--node-labels- Etiquetas para añadir al nodo durante el registro en el clúster (ver las restricciones que impone el NodeRestriction admission plugin en 1.13+).--node-status-update-frequency- Especifica la frecuencia con la que el nodo envía información de estado al máster.
Cuando el Node authorization mode y el NodeRestriction admission plugin están habilitados, los kubelets sólo tienen permisos para crear/modificar su propio objeto Node.
Administración Manual de Nodos
Los administradores del clúster pueden crear y modificar objetos Node.
Si un administrador desea crear objetos Node de forma manual, debe levantar kubelet con el atributo --register-node=false.
Los administradores del clúster pueden modificar recursos Node (independientemente del valor de --register-node). Dichas modificaciones incluyen crear etiquetas en el nodo y/o marcarlo como no-planificable (de forma que pods no pueden ser planificados para instalación en el nodo).
Etiquetas y selectores de nodos pueden utilizarse de forma conjunta para controlar las tareas de planificación, por ejemplo, para determinar un subconjunto de nodos elegibles para ejecutar un pod.
Marcar un nodo como no-planificable impide que nuevos pods sean planificados en dicho nodo, pero no afecta a ninguno de los pods que existían previamente en el nodo. Esto resulta de utilidad como paso preparatorio antes de reiniciar un nodo, etc. Por ejemplo, para marcar un nodo como no-planificable, se ejecuta el siguiente comando:
kubectl cordon $NODENAME
Capacidad del Nodo
La capacidad del nodo (número de CPUs y cantidad de memoria) es parte del objeto Node.
Normalmente, nodos se registran a sí mismos y declaran sus capacidades cuando el objeto Node es creado. Si se está haciendo administración manual, las capacidades deben configurarse en el momento de añadir el nodo.
El planificador de Kubernetes asegura la existencia de recursos suficientes para todos los pods que se ejecutan en un nodo. Comprueba que la suma recursos solicitados por los pods no exceda la capacidad del nodo. Incluye todos los pods iniciados por el kubelet, pero no tiene control sobre contenedores iniciados directamente por el runtime de contenedores ni sobre otros procesos que corren fuera de contenedores.
Para reservar explícitamente recursos en la máquina huésped para procesos no relacionados con pods, sigue este tutorial reserva de recursos para daemons de sistema.
Objeto API
Un nodo es un recurso principal dentro de la REST API de Kubernetes. Más detalles sobre el objeto en la API se puede encontrar en: Object Node API.
2 - Comunicación Nodo-Maestro
Este documento cataloga las diferentes vías de comunicación entre el nodo máster (en realidad el apiserver) y el clúster de Kubernetes. La intención es permitir a los usuarios personalizar sus instalaciones para proteger sus configuraciones de red de forma que el clúster pueda ejecutarse en una red insegura. (o en un proveedor de servicios en la nube con direcciones IP públicas)
Clúster a Máster
Todos los canales de comunicación desde el clúster hacia el máster terminan en el apiserver (ningún otro componente del máster está diseñado para exponer servicios remotos). En un despliegue típico, el apiserver está configurado para escuchar conexiones remotas en un canal seguro cómo HTTPS en el puerto (443) con una o más formas de autenticación de clientes habilitada. Una o más formas de autorización deberían ser habilitadas, especialmente si se permiten peticiones anónimas o tokens de cuenta de servicio.
Los nodos deben ser aprovisionados con el certificado raíz público del clúster de forma que puedan conectar de forma segura con el apiserver en conjunción con credenciales de cliente válidas. Por ejemplo, en un despliegue por defecto en GKE, las credenciales de cliente proporcionadas al kubelet están en la forma de certificados de cliente. Accede kubelet TLS bootstrapping para ver cómo aprovisionar certificados de cliente de forma automática.
Aquellos Pods que deseen conectar con el apiserver pueden hacerlo de forma segura a través de una cuenta de servicio, de esta forma Kubernetes inserta de forma automática el certificado raíz público y un bearer token válido en el pod cuando este es instanciado. El servicio kubernetes (en todos los namespaces) se configura con una dirección IP virtual que es redireccionada (via kube-proxy) al punto de acceso HTTPS en el apiserver.
Los componentes máster también se comunican con el apiserver del clúster a través de un puerto seguro.
Como resultado, el modo de operación por defecto para conexiones desde el clúster (nodos y pods ejecutándose en nodos) al máster es seguro por defecto y puede correr en redes públicas y/o inseguras.
Máster a Clúster
Hay dos vías de comunicación primaria desde el máster (apiserver) al clúster. La primera es desde el apiserver al proceso kubelet que se ejecuta en cada nodo del clúster. La segunda es desde el apiserver a cualquier nodo, pod, o servicio a través de la funcionalidad proxy del apiserver.
apiserver al kubelet
Las conexiones del apiserver al kubelet se utilizan para:
- Recoger entradas de registro de pods.
- Conectar (a través de
kubectl) con pods en ejecución. - Facilitar la funcionalidad
port-forwardingdel kubelet.
Estas conexiones terminan en el endpoint HTTPS del kubelet. Por defecto, el apiserver no verifica el certificado del kubelet, por lo que la conexión es vulnerable a ataques del tipo man-in-the-middle, e insegura para conectar a través de redes públicas o de no confianza.
Para verificar esta conexión, se utiliza el atributo --kubeket-certificate-authority que provee el apiserver con un certificado raíz con el que verificar el certificado del kubelet.
Si esto no es posible, se utiliza un túnel SSH entre el apiserver y el kubelet para conectar a través de redes públicas o de no confianza.
Finalmente, autenticación y/o autorización al kubelet debe ser habilitada para proteger su API.
apiserver a nodos, pods y servicios
Las conexiones desde el apiserver a un nodo, pod o servicio se realizan por defecto con HTTP y, por consiguiente, no son autentificadas o encriptadas. Pueden ser ejecutadas en una conexión HTTPS segura añadiendo el prefijo https: al nodo, pod o nombre de servicio en la API URL, pero los receptores no validan el certificado provisto por el endpoint HTTPS ni facilitan credenciales de cliente asi que, aunque la conexión esté encriptada, esta no ofrece garantía de integridad. Estas conexiones no son seguras para conectar a través de redes públicas o inseguras.
Túneles SSH
Kubernetes ofrece soporte para túneles SSH que protegen la comunicación Máster -> Clúster. En este modo de configuración, el apiserver inicia un túnel SSH a cada nodo en el clúster (conectando al servidor SSH en el puerto 22) y transfiere todo el tráfico destinado a un kubelet, nodo, pod o servicio a través del túnel. El túnel garantiza que dicho tráfico no es expuesto fuera de la red en la que se ejecutan los nodos.
Los túneles SSH se consideran obsoletos, y no deberían utilizarse a menos que se sepa lo que se está haciendo. Se está diseñando un reemplazo para este canal de comunicación.
3 - Conceptos subyacentes del Cloud Controller Manager
El concepto del Cloud Controller Manager (CCM) (no confundir con el ejecutable) fue creado originalmente para permitir que Kubernetes y el código específico de proveedores de servicios en la nube evolucionen de forma independiente. El Cloud Controller Manager se ejecuta a la par con otros componentes maestros como el Kubernetes Controller Manager, el API Server y el planificador. También puede ejecutarse como un extra, en cuyo caso se ejecuta por encima de Kubernetes.
El diseño del Cloud Controller Manager está basado en un sistema de plugins, lo que permite a nuevos proveedores de servicios integrarse de forma fácil con Kubernetes. Se está trabajando en implementar nuevos proveedores de servicios y para migrar los existentes del antiguo modelo al nuevo CCM.
Este documento describe los conceptos tras el Cloud Controller Manager y detalla sus funciones asociadas.
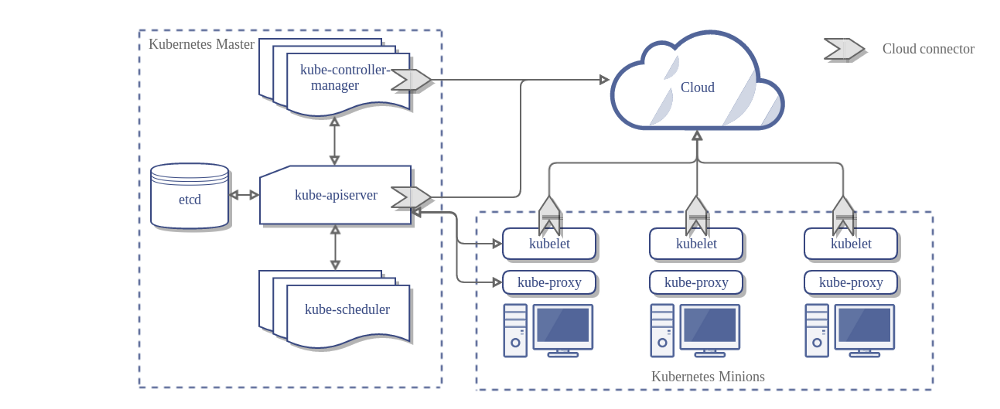
En la siguiente imagen, se puede visualizar la arquitectura de un cluster de Kubernetes que no utiliza el Cloud Controller Manager:
Diseño
En el diagrama anterior, Kubernetes y el proveedor de servicios en la nube están integrados a través de diferentes componentes:
- Kubelet
- Kubernetes controller manager
- Kubernetes API server
El CCM consolida toda la lógica dependiente de la nube de estos tres componentes para crear un punto de integración único. La nueva arquitectura con CCM se muestra a continuación:
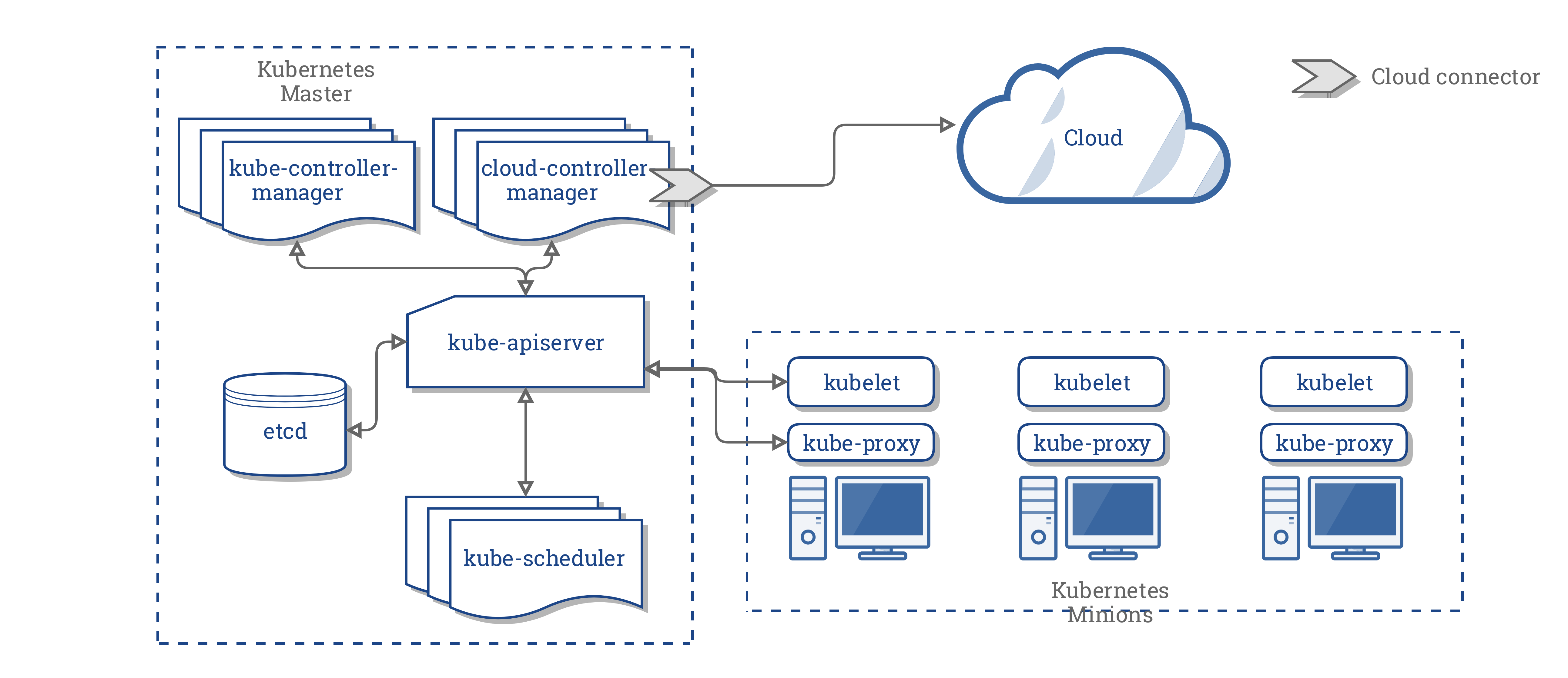
Componentes del CCM
El CCM secciona parte de la funcionalidad del Kubernetes Controller Manager (KCM) y la ejecuta como procesos independientes. Específicamente, aquellos controladores en el KCM que son dependientes de la nube:
- Controlador de Nodos
- Controlador de Volúmenes
- Controlador de Rutas
- Controlador de Servicios
En la versión 1.9, el CCM se encarga de la ejecución de los siguientes controladores:
- Controlador de Nodos
- Controlador de Rutas
- Controlador de Servicios
El plan original para habilitar volúmenes en CCM era utilizar volúmenes Flex con soporte para volúmenes intercambiables. Sin embargo, otro programa conocido como CSI (Container Storage Interface) se está planeando para reemplazar Flex.
Considerando todo lo anterior, se ha decidido esperar hasta que CSI esté listo.
Funciones del CCM
El CCM hereda sus funciones de componentes que son dependientes de un proveedor de servicios en la nube. Esta sección se ha estructurado basado en dichos componentes:
1. Kubernetes Controller Manager
La mayoría de las funciones del CCM derivan del KCM. Como se ha mencionado en la sección anterior, el CCM es responsable de los siguientes circuitos de control:
- Controlador de Nodos
- Controlador de Rutas
- Controlador de Servicios
Controlador de Nodos
El controlador de nodos es responsable de inicializar un nodo obteniendo información del proveedor de servicios sobre los nodos ejecutándose en el clúster. El controlador de nodos lleva a cabo las siguientes funciones:
- Inicializa un nodo con etiquetas de región y zona específicas del proveedor.
- Inicializa un nodo con detalles de la instancia específicos del proveedor, como por ejemplo, el tipo o el tamaño.
- Obtiene las direcciones de red del nodo y su hostname.
- En caso de que el nodo deje de responder, comprueba la nube para ver si el nodo ha sido borrado. Si lo ha sido, borra el objeto nodo en Kubernetes.
Controlador de Rutas
El controlador de Rutas es responsable de configurar rutas en la nube para que contenedores en diferentes nodos dentro de un clúster kubernetes se puedan comunicar entre sí.
Controlador de Servicios
El controlador de servicios es responsable de monitorizar eventos de creación, actualización y borrado de servicios. Basándose en el estado actual de los servicios en el clúster Kubernetes, configura balanceadores de carga del proveedor (como Amazon ELB, Google LB, or Oracle Cloud Infrastructure Lb) de forma que estos reflejen los servicios definidos en Kubernetes. Adicionalmente, se asegura de que los sistemas de apoyo de servicios para balanceadores de carga en la nube se encuentren actualizados.
2. Kubelet
El controlador de nodos incluye la funcionalidad del kubelet que es dependiente de la nube. Previa a la introducción de CCM, el kubelet era responsable de inicializar un nodo con detalles específicos al proveedor como direcciones IP, etiquetas de región/zona y tipo de instancia. La introduccion de CCM transfiere esta inicialización del kubelet al CCM.
En este nuevo modelo, el kubelet inicializa un nodo sin información especifica del proveedor de servicios. Sin embargo, añade un taint al nodo recién creado de forma que este no esté disponible para el planificador hasta que el CCM completa el nodo con la información específica del proveedor. Sólo entonces elimina el taint y el nodo se vuelve accesible.
Mecanismo de Plugins (extensiones)
El Cloud Controller Manager utiliza interfaces Go(lang), lo que permite que implementaciones de cualquier proveedor de servicios sean conectadas. Específicamente, utiliza el CloudProvider Interface definido aquí.
La implementación de los cuatro controladores referenciados en este documento, algunas estructuras de inicialización junto con el interface CloudProvider, permanecerán como parte del núcleo de Kubernetes.
Para más información sobre el desarrollo de extensiones/plugins, consultar Desarrollo del CCM.
Autorización
Esta sección divide el nivel de acceso requerido por varios objetos API para que el CCM pueda llevar acabo sus operaciones.
Controlador de Nodos
El controlador de nodos sólo opera con objetos Nodo. Necesita de acceso total para obtener, listar, crear, actualizar, arreglar, monitorizar y borrar objetos Nodo.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Controlador de Rutas
El controlador de rutas permanece a la escucha de eventos de creación de nodos y configura sus rutas. Necesita acceso a los objetos Nodo.
v1/Node:
- Get
Controlador de Servicios
El controlador de servicios permanece a la escucha de eventos de creación, actualización y borrado de objetos Servicio, y se encarga de configurar los endpoints para dichos servicios.
Para acceder a los objetos Servicio, necesita permisos para listar y monitorizar. Para el mantenimiento de servicios necesita permisos para parchear y actualizar.
Para configurar endpoints para los servicios necesita permisos para crear, listar, obtener, monitorizar y actualizar.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Otros
La implementación del núcleo de CCM requiere acceso para crear eventos, y para asegurar la seguridad de operaciones; necesita acceso para crear ServiceAccounts.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
El RBAC ClusterRole para CCM se muestra a continuación:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Implementaciones de Proveedores
Los siguientes proveedores de servicios en la nube han implementado CCMs:
Administración del Clúster
Instrucciones para configurar y ejecutar el CCM pueden encontrarse aquí.
4 - Container Runtime Interface (CRI)
CRI es una interfaz de plugin que permite que kubelet use una amplia variedad de container runtimes, sin necesidad de volver a compilar los componentes del clúster.
Necesitas un container runtime ejecutándose en cada Nodo en tu clúster, de manera que kubelet pueda iniciar los Pods y sus contenedores.
Container Runtime Interface (CRI) es el protocolo principal para la comunicación entre el kubelet y el Container Runtime.
La Kubernetes Container Runtime Interface (CRI) define el principal protocolo de gRPC para la comunicación entre los componentes de clúster kubelet y container runtime.
API
Kubernetes v1.23 [stable]
Kubelet actúa como un cliente cuando se conecta al runtime del contenedor a través de gRPC.
El runtime y los endpoints del servicio de imágenes deben estar disponibles en el runtime del contenedor,
que se puede configurar por separado dentro de kubelet usando
--image-service-endpoint banderas de línea de comando.
Para Kubernetes v1.29, kubelet prefiere usar CRI v1.
Si el runtime del contenedor no es compatible con v1 del CRI, kubelet intenta
negociar cualquier versión compatible anterior.
Kubelet v1.29 también puede negociar CRI v1alpha2, pero
esta versión se considera obsoleta.
Si kubelet no puede negociar una versión CRI soportada, kubelet se da por vencido
y no se registra como nodo.
Actualizando
Al actualizar Kubernetes, kubelet intenta seleccionar automáticamente la última versión de CRI al reiniciar el componente. Si eso falla, entonces la alternativa se llevará a cabo como se mencionó anteriormente. Si se requirió una rellamada de gRPC porque el runtime del contenedor se ha actualizado, entonces el runtime del contenedor también debe soportar la versión seleccionada inicialmente o se espera que la rellamada falle. Esto requiere un reinicio de kubelet.
Siguientes pasos
- Más información sobre CRI definición de protocolo