概念部分帮助你了解 Kubernetes 系统的各个部分以及 Kubernetes 用来表示集群的抽象概念, 并帮助你更深入地理解 Kubernetes 是如何工作的。
概念
- 1: 概述
- 1.1: Kubernetes 对象
- 1.1.1: Kubernetes 对象管理
- 1.1.2: 对象名称和 ID
- 1.1.3: 标签和选择算符
- 1.1.4: 名字空间
- 1.1.5: 注解
- 1.1.6: 字段选择器
- 1.1.7: Finalizers
- 1.1.8: 属主与附属
- 1.1.9: 推荐使用的标签
- 1.2: Kubernetes 组件
- 1.3: Kubernetes API
- 2: Kubernetes 架构
- 2.1: 节点
- 2.2: 节点与控制面之间的通信
- 2.3: 控制器
- 2.4: 租约(Lease)
- 2.5: 云控制器管理器
- 2.6: 关于 cgroup v2
- 2.7: 容器运行时接口(CRI)
- 2.8: 垃圾收集
- 2.9: 混合版本代理
- 3: 容器
- 3.1: 镜像
- 3.2: 容器环境
- 3.3: 容器运行时类(Runtime Class)
- 3.4: 容器生命周期回调
- 4: 工作负载
- 4.1: Pod
- 4.1.1: Pod 的生命周期
- 4.1.2: Init 容器
- 4.1.3: 边车容器
- 4.1.4: 干扰(Disruptions)
- 4.1.5: 临时容器
- 4.1.6: Pod QoS 类
- 4.1.7: 用户命名空间
- 4.1.8: Downward API
- 4.2: 工作负载管理
- 4.2.1: Deployments
- 4.2.2: ReplicaSet
- 4.2.3: StatefulSet
- 4.2.4: DaemonSet
- 4.2.5: Job
- 4.2.6: 已完成 Job 的自动清理
- 4.2.7: CronJob
- 4.2.8: ReplicationController
- 4.3: 自动扩缩工作负载
- 5: 服务、负载均衡和联网
- 5.1: 服务(Service)
- 5.2: Ingress
- 5.3: Ingress 控制器
- 5.4: Gateway API
- 5.5: EndpointSlice
- 5.6: 网络策略
- 5.7: Service 与 Pod 的 DNS
- 5.8: IPv4/IPv6 双协议栈
- 5.9: 拓扑感知路由
- 5.10: Windows 网络
- 5.11: Service ClusterIP 分配
- 5.12: 服务内部流量策略
- 6: 存储
- 6.1: 卷
- 6.2: 持久卷
- 6.3: 投射卷
- 6.4: 临时卷
- 6.5: 存储类
- 6.6: 动态卷制备
- 6.7: 卷快照
- 6.8: 卷快照类
- 6.9: CSI 卷克隆
- 6.10: 存储容量
- 6.11: 特定于节点的卷数限制
- 6.12: 卷健康监测
- 6.13: Windows 存储
- 7: 配置
- 7.1: 配置最佳实践
- 7.2: ConfigMap
- 7.3: Secret
- 7.4: 为 Pod 和容器管理资源
- 7.5: 使用 kubeconfig 文件组织集群访问
- 7.6: Windows 节点的资源管理
- 8: 安全
- 8.1: Pod 安全性标准
- 8.2: 服务账号
- 8.3: Pod 安全性准入
- 8.4: Pod 安全策略
- 8.5: Windows 节点的安全性
- 8.6: Kubernetes API 访问控制
- 8.7: 基于角色的访问控制良好实践
- 8.8: Kubernetes Secret 良好实践
- 8.9: 多租户
- 8.10: Kubernetes API 服务器旁路风险
- 8.11: 安全检查清单
- 9: 策略
- 9.1: 限制范围
- 9.2: 资源配额
- 9.3: 进程 ID 约束与预留
- 9.4: 节点资源管理器
- 10: 调度、抢占和驱逐
- 10.1: Kubernetes 调度器
- 10.2: 将 Pod 指派给节点
- 10.3: Pod 开销
- 10.4: Pod 调度就绪态
- 10.5: Pod 拓扑分布约束
- 10.6: 污点和容忍度
- 10.7: 调度框架
- 10.8: 动态资源分配
- 10.9: 调度器性能调优
- 10.10: 资源装箱
- 10.11: Pod 优先级和抢占
- 10.12: 节点压力驱逐
- 10.13: API 发起的驱逐
- 11: 集群管理
- 11.1: 证书
- 11.2: 管理资源
- 11.3: 集群网络系统
- 11.4: 日志架构
- 11.5: Kubernetes 系统组件指标
- 11.6: 系统日志
- 11.7: 追踪 Kubernetes 系统组件
- 11.8: Kubernetes 中的代理
- 11.9: API 优先级和公平性
- 11.10: 安装扩展(Addon)
- 12: Kubernetes 中的 Windows
- 12.1: Kubernetes 中的 Windows 容器
- 12.2: Kubernetes 中的 Windows 容器调度指南
- 13: 扩展 Kubernetes
- 13.1: Operator 模式
- 13.2: 计算、存储和网络扩展
- 13.3: 扩展 Kubernetes API
- 13.3.1: 定制资源
- 13.3.2: Kubernetes API 聚合层
1 - 概述
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,方便进行声明式配置和自动化。Kubernetes 拥有一个庞大且快速增长的生态系统,其服务、支持和工具的使用范围广泛。
此页面是 Kubernetes 的概述。
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态,其服务、支持和工具的使用范围相当广泛。
Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”。k8s 这个缩写是因为 k 和 s 之间有八个字符的关系。 Google 在 2014 年开源了 Kubernetes 项目。 Kubernetes 建立在 Google 大规模运行生产工作负载十几年经验的基础上, 结合了社区中最优秀的想法和实践。
时光回溯
让我们回顾一下为何 Kubernetes 能够裨益四方。

传统部署时代:
早期,各个组织是在物理服务器上运行应用程序。 由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。 例如,如果在同一台物理服务器上运行多个应用程序, 则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。 一种解决方案是将每个应用程序都运行在不同的物理服务器上, 但是当某个应用程序资源利用率不高时,剩余资源无法被分配给其他应用程序, 而且维护许多物理服务器的成本很高。
虚拟化部署时代:
因此,虚拟化技术被引入了。虚拟化技术允许你在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序, 而因此可以具有更高的可扩缩性,以及降低硬件成本等等的好处。 通过虚拟化,你可以将一组物理资源呈现为可丢弃的虚拟机集群。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:
容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。 因此,容器比起 VM 被认为是更轻量级的。且与 VM 类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来,例如:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性), 提供可靠且频繁的容器镜像构建和部署。
- 关注开发与运维的分离:在构建、发布时创建应用程序容器镜像,而不是在部署时, 从而将应用程序与基础架构分离。
- 可观察性:不仅可以显示 OS 级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在笔记本计算机上也可以和在云中运行一样的应用程序。
- 跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
为什么需要 Kubernetes,它能做什么?
容器是打包和运行应用程序的好方式。在生产环境中, 你需要管理运行着应用程序的容器,并确保服务不会下线。 例如,如果一个容器发生故障,则你需要启动另一个容器。 如果此行为交由给系统处理,是不是会更容易一些?
这就是 Kubernetes 要来做的事情! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移你的应用、提供部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary (金丝雀) 部署。
Kubernetes 为你提供:
-
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来暴露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
-
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
-
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
-
自动完成装箱计算
你为 Kubernetes 提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。 Kubernetes 可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。
-
自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。
-
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
- 批处理执行 除了服务外,Kubernetes 还可以管理你的批处理和 CI(持续集成)工作负载,如有需要,可以替换失败的容器。
- 水平扩缩 使用简单的命令、用户界面或根据 CPU 使用率自动对你的应用进行扩缩。
- IPv4/IPv6 双栈 为 Pod(容器组)和 Service(服务)分配 IPv4 和 IPv6 地址。
- 为可扩展性设计 在不改变上游源代码的情况下为你的 Kubernetes 集群添加功能。
Kubernetes 不是什么
Kubernetes 不是传统的、包罗万象的 PaaS(平台即服务)系统。 由于 Kubernetes 是在容器级别运行,而非在硬件级别,它提供了 PaaS 产品共有的一些普遍适用的功能, 例如部署、扩展、负载均衡,允许用户集成他们的日志记录、监控和警报方案。 但是,Kubernetes 不是单体式(monolithic)系统,那些默认解决方案都是可选、可插拔的。 Kubernetes 为构建开发人员平台提供了基础,但是在重要的地方保留了用户选择权,能有更高的灵活性。
Kubernetes:
- 不限制支持的应用程序类型。 Kubernetes 旨在支持极其多种多样的工作负载,包括无状态、有状态和数据处理工作负载。 如果应用程序可以在容器中运行,那么它应该可以在 Kubernetes 上很好地运行。
- 不部署源代码,也不构建你的应用程序。 持续集成(CI)、交付和部署(CI/CD)工作流取决于组织的文化和偏好以及技术要求。
- 不提供应用程序级别的服务作为内置服务,例如中间件(例如消息中间件)、 数据处理框架(例如 Spark)、数据库(例如 MySQL)、缓存、集群存储系统 (例如 Ceph)。这样的组件可以在 Kubernetes 上运行,并且/或者可以由运行在 Kubernetes 上的应用程序通过可移植机制(例如开放服务代理)来访问。
- 不是日志记录、监视或警报的解决方案。 它集成了一些功能作为概念证明,并提供了收集和导出指标的机制。
- 不提供也不要求配置用的语言、系统(例如 jsonnet),它提供了声明性 API, 该声明性 API 可以由任意形式的声明性规范所构成。
- 不提供也不采用任何全面的机器配置、维护、管理或自我修复系统。
- 此外,Kubernetes 不仅仅是一个编排系统,实际上它消除了编排的需要。 编排的技术定义是执行已定义的工作流程:首先执行 A,然后执行 B,再执行 C。 而 Kubernetes 包含了一组独立可组合的控制过程,可以持续地将当前状态驱动到所提供的预期状态。 你不需要在乎如何从 A 移动到 C,也不需要集中控制,这使得系统更易于使用且功能更强大、 系统更健壮,更为弹性和可扩展。
接下来
- 查阅 Kubernetes 组件
- 查阅 Kubernetes API
- 查阅 Cluster 架构
- 开始 Kubernetes 的建置吧!
1.1 - Kubernetes 对象
Kubernetes 对象是 Kubernetes 系统中的持久性实体。 Kubernetes 使用这些实体表示你的集群状态。 了解 Kubernetes 对象模型以及如何使用这些对象。
本页说明了在 Kubernetes API 中是如何表示 Kubernetes 对象的,
以及如何使用 .yaml 格式的文件表示 Kubernetes 对象。
理解 Kubernetes 对象
在 Kubernetes 系统中,Kubernetes 对象是持久化的实体。 Kubernetes 使用这些实体去表示整个集群的状态。 具体而言,它们描述了如下信息:
- 哪些容器化应用正在运行(以及在哪些节点上运行)
- 可以被应用使用的资源
- 关于应用运行时行为的策略,比如重启策略、升级策略以及容错策略
Kubernetes 对象是一种“意向表达(Record of Intent)”。一旦创建该对象, Kubernetes 系统将不断工作以确保该对象存在。通过创建对象,你本质上是在告知 Kubernetes 系统,你想要的集群工作负载状态看起来应是什么样子的, 这就是 Kubernetes 集群所谓的期望状态(Desired State)。
操作 Kubernetes 对象 —— 无论是创建、修改或者删除 —— 需要使用
Kubernetes API。
比如,当使用 kubectl 命令行接口(CLI)时,CLI 会调用必要的 Kubernetes API;
也可以在程序中使用客户端库,
来直接调用 Kubernetes API。
对象规约(Spec)与状态(Status)
几乎每个 Kubernetes 对象包含两个嵌套的对象字段,它们负责管理对象的配置:
对象 spec(规约) 和对象 status(状态)。
对于具有 spec 的对象,你必须在创建对象时设置其内容,描述你希望对象所具有的特征:
期望状态(Desired State)。
status 描述了对象的当前状态(Current State),它是由 Kubernetes
系统和组件设置并更新的。在任何时刻,Kubernetes
控制平面
都一直在积极地管理着对象的实际状态,以使之达成期望状态。
例如,Kubernetes 中的 Deployment 对象能够表示运行在集群中的应用。
当创建 Deployment 时,你可能会设置 Deployment 的 spec,指定该应用要有 3 个副本运行。
Kubernetes 系统读取 Deployment 的 spec,
并启动我们所期望的应用的 3 个实例 —— 更新状态以与规约相匹配。
如果这些实例中有的失败了(一种状态变更),Kubernetes 系统会通过执行修正操作来响应
spec 和 status 间的不一致 —— 意味着它会启动一个新的实例来替换。
关于对象 spec、status 和 metadata 的更多信息,可参阅 Kubernetes API 约定。
描述 Kubernetes 对象
创建 Kubernetes 对象时,必须提供对象的 spec,用来描述该对象的期望状态,
以及关于对象的一些基本信息(例如名称)。
当使用 Kubernetes API 创建对象时(直接创建或经由 kubectl 创建),
API 请求必须在请求主体中包含 JSON 格式的信息。
大多数情况下,你会通过 清单(Manifest) 文件为 kubectl 提供这些信息。
按照惯例,清单是 YAML 格式的(你也可以使用 JSON 格式)。
像 kubectl 这样的工具在通过 HTTP 进行 API 请求时,
会将清单中的信息转换为 JSON 或其他受支持的序列化格式。
这里有一个清单示例文件,展示了 Kubernetes Deployment 的必需字段和对象 spec:

apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # 告知 Deployment 运行 2 个与该模板匹配的 Pod
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
与上面使用清单文件来创建 Deployment 类似,另一种方式是使用 kubectl 命令行接口(CLI)的
kubectl apply 命令,
将 .yaml 文件作为参数。下面是一个示例:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
输出类似下面这样:
deployment.apps/nginx-deployment created
必需字段
在想要创建的 Kubernetes 对象所对应的清单(YAML 或 JSON 文件)中,需要配置的字段如下:
apiVersion- 创建该对象所使用的 Kubernetes API 的版本kind- 想要创建的对象的类别metadata- 帮助唯一标识对象的一些数据,包括一个name字符串、UID和可选的namespacespec- 你所期望的该对象的状态
对每个 Kubernetes 对象而言,其 spec 之精确格式都是不同的,包含了特定于该对象的嵌套字段。
Kubernetes API 参考可以帮助你找到想要使用
Kubernetes 创建的所有对象的规约格式。
例如,参阅 Pod API 参考文档中
spec 字段。
对于每个 Pod,其 .spec 字段设置了 Pod 及其期望状态(例如 Pod 中每个容器的容器镜像名称)。
另一个对象规约的例子是 StatefulSet API 中的
spec 字段。
对于 StatefulSet 而言,其 .spec 字段设置了 StatefulSet 及其期望状态。
在 StatefulSet 的 .spec 内,有一个为 Pod 对象提供的模板。
该模板描述了 StatefulSet 控制器为了满足 StatefulSet 规约而要创建的 Pod。
不同类型的对象可以有不同的 .status 信息。API 参考页面给出了 .status 字段的详细结构,
以及针对不同类型 API 对象的具体内容。
说明:
请查看配置最佳实践来获取有关编写 YAML 配置文件的更多信息。
服务器端字段验证
从 Kubernetes v1.25 开始,API
服务器提供了服务器端字段验证,
可以检测对象中未被识别或重复的字段。它在服务器端提供了 kubectl --validate 的所有功能。
kubectl 工具使用 --validate 标志来设置字段验证级别。它接受值
ignore、warn 和 strict,同时还接受值 true(等同于 strict)和
false(等同于 ignore)。kubectl 的默认验证设置为 --validate=true。
Strict- 严格的字段验证,验证失败时会报错
Warn- 执行字段验证,但错误会以警告形式提供而不是拒绝请求
Ignore- 不执行服务器端字段验证
当 kubectl 无法连接到支持字段验证的 API 服务器时,它将回退为使用客户端验证。
Kubernetes 1.27 及更高版本始终提供字段验证;较早的 Kubernetes 版本可能没有此功能。
如果你的集群版本低于 v1.27,可以查阅适用于你的 Kubernetes 版本的文档。
接下来
如果你刚开始学习 Kubernetes,可以进一步阅读以下信息:
- 最重要的 Kubernetes 基本对象 Pod。
- Deployment 对象。
- Kubernetes 中的控制器。
- kubectl 和 kubectl 命令。
Kubernetes 对象管理
介绍了如何使用 kubectl 来管理对象。
如果你还没有安装 kubectl,你可能需要安装 kubectl。
从总体上了解 Kubernetes API,可以查阅:
若要更深入地了解 Kubernetes 对象,可以阅读本节的其他页面:
1.1.1 - Kubernetes 对象管理
kubectl 命令行工具支持多种不同的方式来创建和管理 Kubernetes
对象。
本文档概述了不同的方法。
阅读 Kubectl book 来了解 kubectl
管理对象的详细信息。
管理技巧
警告:
应该只使用一种技术来管理 Kubernetes 对象。混合和匹配技术作用在同一对象上将导致未定义行为。
| 管理技术 | 作用于 | 建议的环境 | 支持的写者 | 学习难度 |
|---|---|---|---|---|
| 指令式命令 | 活跃对象 | 开发项目 | 1+ | 最低 |
| 指令式对象配置 | 单个文件 | 生产项目 | 1 | 中等 |
| 声明式对象配置 | 文件目录 | 生产项目 | 1+ | 最高 |
指令式命令
使用指令式命令时,用户可以在集群中的活动对象上进行操作。用户将操作传给
kubectl 命令作为参数或标志。
这是开始或者在集群中运行一次性任务的推荐方法。因为这个技术直接在活跃对象 上操作,所以它不提供以前配置的历史记录。
例子
通过创建 Deployment 对象来运行 nginx 容器的实例:
kubectl create deployment nginx --image nginx
权衡
与对象配置相比的优点:
- 命令用单个动词表示。
- 命令仅需一步即可对集群进行更改。
与对象配置相比的缺点:
- 命令不与变更审查流程集成。
- 命令不提供与更改关联的审核跟踪。
- 除了实时内容外,命令不提供记录源。
- 命令不提供用于创建新对象的模板。
指令式对象配置
在指令式对象配置中,kubectl 命令指定操作(创建,替换等),可选标志和 至少一个文件名。指定的文件必须包含 YAML 或 JSON 格式的对象的完整定义。
有关对象定义的详细信息,请查看 API 参考。
警告:
replace 指令式命令将现有规范替换为新提供的规范,并放弃对配置文件中
缺少的对象的所有更改。此方法不应与对象规约被独立于配置文件进行更新的
资源类型一起使用。比如类型为 LoadBalancer 的服务,它的 externalIPs
字段就是独立于集群配置进行更新。
例子
创建配置文件中定义的对象:
kubectl create -f nginx.yaml
删除两个配置文件中定义的对象:
kubectl delete -f nginx.yaml -f redis.yaml
通过覆盖活动配置来更新配置文件中定义的对象:
kubectl replace -f nginx.yaml
权衡
与指令式命令相比的优点:
- 对象配置可以存储在源控制系统中,比如 Git。
- 对象配置可以与流程集成,例如在推送和审计之前检查更新。
- 对象配置提供了用于创建新对象的模板。
与指令式命令相比的缺点:
- 对象配置需要对对象架构有基本的了解。
- 对象配置需要额外的步骤来编写 YAML 文件。
与声明式对象配置相比的优点:
- 指令式对象配置行为更加简单易懂。
- 从 Kubernetes 1.5 版本开始,指令对象配置更加成熟。
与声明式对象配置相比的缺点:
- 指令式对象配置更适合文件,而非目录。
- 对活动对象的更新必须反映在配置文件中,否则会在下一次替换时丢失。
声明式对象配置
使用声明式对象配置时,用户对本地存储的对象配置文件进行操作,但是用户
未定义要对该文件执行的操作。
kubectl 会自动检测每个文件的创建、更新和删除操作。
这使得配置可以在目录上工作,根据目录中配置文件对不同的对象执行不同的操作。
说明:
声明式对象配置保留其他编写者所做的修改,即使这些更改并未合并到对象配置文件中。
可以通过使用 patch API 操作仅写入观察到的差异,而不是使用 replace API
操作来替换整个对象配置来实现。
例子
处理 configs 目录中的所有对象配置文件,创建并更新活跃对象。
可以首先使用 diff 子命令查看将要进行的更改,然后在进行应用:
kubectl diff -f configs/
kubectl apply -f configs/
递归处理目录:
kubectl diff -R -f configs/
kubectl apply -R -f configs/
权衡
与指令式对象配置相比的优点:
- 对活动对象所做的更改即使未合并到配置文件中,也会被保留下来。
- 声明性对象配置更好地支持对目录进行操作并自动检测每个文件的操作类型(创建,修补,删除)。
与指令式对象配置相比的缺点:
- 声明式对象配置难于调试并且出现异常时结果难以理解。
- 使用 diff 产生的部分更新会创建复杂的合并和补丁操作。
接下来
1.1.2 - 对象名称和 ID
每个 Kubernetes 对象也有一个 UID 来标识在整个集群中的唯一性。
比如,在同一个名字空间
中只能有一个名为 myapp-1234 的 Pod,但是可以命名一个 Pod 和一个 Deployment 同为 myapp-1234。
对于用户提供的非唯一性的属性,Kubernetes 提供了标签(Label)和 注解(Annotation)机制。
名称
客户端提供的字符串,引用资源 URL 中的对象,如/api/v1/pods/some name。
某一时刻,只能有一个给定类型的对象具有给定的名称。但是,如果删除该对象,则可以创建同名的新对象。
名称在同一资源的所有 API 版本中必须是唯一的。 这些 API 资源通过各自的 API 组、资源类型、名字空间(对于划分名字空间的资源)和名称来区分。 换言之,API 版本在此上下文中是不相关的。
说明:
当对象所代表的是一个物理实体(例如代表一台物理主机的 Node)时, 如果在 Node 对象未被删除并重建的条件下,重新创建了同名的物理主机, 则 Kubernetes 会将新的主机看作是老的主机,这可能会带来某种不一致性。
以下是比较常见的四种资源命名约束。
DNS 子域名
很多资源类型需要可以用作 DNS 子域名的名称。 DNS 子域名的定义可参见 RFC 1123。 这一要求意味着名称必须满足如下规则:
- 不能超过 253 个字符
- 只能包含小写字母、数字,以及 '-' 和 '.'
- 必须以字母数字开头
- 必须以字母数字结尾
RFC 1123 标签名
某些资源类型需要其名称遵循 RFC 1123 所定义的 DNS 标签标准。也就是命名必须满足如下规则:
- 最多 63 个字符
- 只能包含小写字母、数字,以及 '-'
- 必须以字母数字开头
- 必须以字母数字结尾
RFC 1035 标签名
某些资源类型需要其名称遵循 RFC 1035 所定义的 DNS 标签标准。也就是命名必须满足如下规则:
- 最多 63 个字符
- 只能包含小写字母、数字,以及 '-'
- 必须以字母开头
- 必须以字母数字结尾
说明:
RFC 1035 和 RFC 1123 标签标准之间的唯一区别是 RFC 1123 标签允许以数字开头,而 RFC 1035 标签只能以小写字母字符开头。
路径分段名称
某些资源类型要求名称能被安全地用作路径中的片段。
换句话说,其名称不能是 .、..,也不可以包含 / 或 % 这些字符。
下面是一个名为 nginx-demo 的 Pod 的配置清单:
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
说明:
某些资源类型可能具有额外的命名约束。
UID
Kubernetes 系统生成的字符串,唯一标识对象。
在 Kubernetes 集群的整个生命周期中创建的每个对象都有一个不同的 UID,它旨在区分类似实体的历史事件。
Kubernetes UID 是全局唯一标识符(也叫 UUID)。 UUID 是标准化的,见 ISO/IEC 9834-8 和 ITU-T X.667。
接下来
- 进一步了解 Kubernetes 标签和注解。
- 参阅 Kubernetes 标识符和名称的设计文档。
1.1.3 - 标签和选择算符
标签(Labels) 是附加到 Kubernetes 对象(比如 Pod)上的键值对。 标签旨在用于指定对用户有意义且相关的对象的标识属性,但不直接对核心系统有语义含义。 标签可以用于组织和选择对象的子集。标签可以在创建时附加到对象,随后可以随时添加和修改。 每个对象都可以定义一组键/值标签。每个键对于给定对象必须是唯一的。
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
标签能够支持高效的查询和监听操作,对于用户界面和命令行是很理想的。 应使用注解记录非识别信息。
动机
标签使用户能够以松散耦合的方式将他们自己的组织结构映射到系统对象,而无需客户端存储这些映射。
服务部署和批处理流水线通常是多维实体(例如,多个分区或部署、多个发行序列、多个层,每层多个微服务)。 管理通常需要交叉操作,这打破了严格的层次表示的封装,特别是由基础设施而不是用户确定的严格的层次结构。
示例标签:
"release" : "stable","release" : "canary""environment" : "dev","environment" : "qa","environment" : "production""tier" : "frontend","tier" : "backend","tier" : "cache""partition" : "customerA","partition" : "customerB""track" : "daily","track" : "weekly"
有一些常用标签的例子;你可以任意制定自己的约定。 请记住,标签的 Key 对于给定对象必须是唯一的。
语法和字符集
标签是键值对。有效的标签键有两个段:可选的前缀和名称,用斜杠(/)分隔。
名称段是必需的,必须小于等于 63 个字符,以字母数字字符([a-z0-9A-Z])开头和结尾,
带有破折号(-),下划线(_),点( .)和之间的字母数字。
前缀是可选的。如果指定,前缀必须是 DNS 子域:由点(.)分隔的一系列 DNS 标签,总共不超过 253 个字符,
后跟斜杠(/)。
如果省略前缀,则假定标签键对用户是私有的。
向最终用户对象添加标签的自动系统组件(例如 kube-scheduler、kube-controller-manager、
kube-apiserver、kubectl 或其他第三方自动化工具)必须指定前缀。
kubernetes.io/ 和 k8s.io/ 前缀是为 Kubernetes 核心组件保留的。
有效标签值:
- 必须为 63 个字符或更少(可以为空)
- 除非标签值为空,必须以字母数字字符(
[a-z0-9A-Z])开头和结尾 - 包含破折号(
-)、下划线(_)、点(.)和字母或数字
例如,以下是一个清单 (manifest),适用于具有 environment: production 和 app: nginx 这两个标签的 Pod:
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
标签选择算符
与名称和 UID 不同, 标签不支持唯一性。通常,我们希望许多对象携带相同的标签。
通过标签选择算符,客户端/用户可以识别一组对象。标签选择算符是 Kubernetes 中的核心分组原语。
API 目前支持两种类型的选择算符:基于等值的和基于集合的。
标签选择算符可以由逗号分隔的多个需求组成。
在多个需求的情况下,必须满足所有要求,因此逗号分隔符充当逻辑与(&&)运算符。
空标签选择算符或者未指定的选择算符的语义取决于上下文, 支持使用选择算符的 API 类别应该将算符的合法性和含义用文档记录下来。
说明:
对于某些 API 类别(例如 ReplicaSet)而言,两个实例的标签选择算符不得在命名空间内重叠, 否则它们的控制器将互相冲突,无法确定应该存在的副本个数。
注意:
对于基于等值的和基于集合的条件而言,不存在逻辑或(||)操作符。
你要确保你的过滤语句按合适的方式组织。
基于等值的需求
基于等值或基于不等值的需求允许按标签键和值进行过滤。
匹配对象必须满足所有指定的标签约束,尽管它们也可能具有其他标签。
可接受的运算符有 =、== 和 != 三种。
前两个表示相等(并且是同义词),而后者表示不相等。例如:
environment = production
tier != frontend
前者选择所有资源,其键名等于 environment,值等于 production。
后者选择所有资源,其键名等于 tier,值不同于 frontend,所有资源都没有带有 tier 键的标签。
可以使用逗号运算符来过滤 production 环境中的非 frontend 层资源:environment=production,tier!=frontend。
基于等值的标签要求的一种使用场景是 Pod 要指定节点选择标准。
例如,下面的示例 Pod 选择带有标签 "accelerator=nvidia-tesla-p100"。
apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "registry.k8s.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
基于集合的需求
基于集合的标签需求允许你通过一组值来过滤键。
支持三种操作符:in、notin 和 exists(只可以用在键标识符上)。例如:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
- 第一个示例选择了所有键等于
environment并且值等于production或者qa的资源。 - 第二个示例选择了所有键等于
tier并且值不等于frontend或者backend的资源,以及所有没有tier键标签的资源。 - 第三个示例选择了所有包含了有
partition标签的资源;没有校验它的值。 - 第四个示例选择了所有没有
partition标签的资源;没有校验它的值。
类似地,逗号分隔符充当与运算符。因此,使用 partition 键(无论为何值)和
environment 不同于 qa 来过滤资源可以使用 partition, environment notin (qa) 来实现。
基于集合的标签选择算符是相等标签选择算符的一般形式,因为 environment=production
等同于 environment in (production);!= 和 notin 也是类似的。
基于集合的要求可以与基于相等的要求混合使用。例如:partition in (customerA, customerB),environment!=qa。
API
LIST 和 WATCH 过滤
LIST 和 WATCH 操作可以使用查询参数指定标签选择算符过滤一组对象。 两种需求都是允许的。(这里显示的是它们出现在 URL 查询字符串中)
- 基于等值的需求:
?labelSelector=environment%3Dproduction,tier%3Dfrontend - 基于集合的需求:
?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
两种标签选择算符都可以通过 REST 客户端用于 list 或者 watch 资源。
例如,使用 kubectl 定位 apiserver,可以使用基于等值的标签选择算符可以这么写:
kubectl get pods -l environment=production,tier=frontend
或者使用基于集合的需求:
kubectl get pods -l 'environment in (production),tier in (frontend)'
正如刚才提到的,基于集合的需求更具有表达力。例如,它们可以实现值的或操作:
kubectl get pods -l 'environment in (production, qa)'
或者通过notin运算符限制不匹配:
kubectl get pods -l 'environment,environment notin (frontend)'
在 API 对象中设置引用
一些 Kubernetes 对象,例如 services
和 replicationcontrollers,
也使用了标签选择算符去指定了其他资源的集合,例如
pods。
Service 和 ReplicationController
一个 Service 指向的一组 Pod 是由标签选择算符定义的。同样,一个 ReplicationController
应该管理的 Pod 的数量也是由标签选择算符定义的。
两个对象的标签选择算符都是在 json 或者 yaml 文件中使用映射定义的,并且只支持
基于等值需求的选择算符:
"selector": {
"component" : "redis",
}
或者
selector:
component: redis
这个选择算符(分别在 json 或者 yaml 格式中)等价于 component=redis 或 component in (redis)。
支持基于集合需求的资源
比较新的资源,例如 Job、
Deployment、
ReplicaSet 和
DaemonSet,
也支持基于集合的需求。
selector:
matchLabels:
component: redis
matchExpressions:
- { key: tier, operator: In, values: [cache] }
- { key: environment, operator: NotIn, values: [dev] }
matchLabels 是由 {key,value} 对组成的映射。
matchLabels 映射中的单个 {key,value} 等同于 matchExpressions 的元素,
其 key 字段为 "key",operator 为 "In",而 values 数组仅包含 "value"。
matchExpressions 是 Pod 选择算符需求的列表。
有效的运算符包括 In、NotIn、Exists 和 DoesNotExist。
在 In 和 NotIn 的情况下,设置的值必须是非空的。
来自 matchLabels 和 matchExpressions 的所有要求都按逻辑与的关系组合到一起
-- 它们必须都满足才能匹配。
选择节点集
通过标签进行选择的一个用例是确定节点集,方便 Pod 调度。 有关更多信息,请参阅选择节点文档。
有效地使用标签
到目前为止我们使用的示例中的资源最多使用了一个标签。 在许多情况下,应使用多个标签来区分不同集合。
例如,不同的应用可能会为 app 标签设置不同的值。
但是,类似 guestbook 示例
这样的多层应用,还需要区分每一层。前端可能会带有以下标签:
labels:
app: guestbook
tier: frontend
Redis 的主从节点会有不同的 tier 标签,甚至还有一个额外的 role 标签:
labels:
app: guestbook
tier: backend
role: master
以及
labels:
app: guestbook
tier: backend
role: replica
标签使得我们能够按照所指定的任何维度对我们的资源进行切片和切块:
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-replica-2q2yf 1/1 Running 0 1m guestbook backend replica
guestbook-redis-replica-qgazl 1/1 Running 0 1m guestbook backend replica
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=replica
NAME READY STATUS RESTARTS AGE
guestbook-redis-replica-2q2yf 1/1 Running 0 3m
guestbook-redis-replica-qgazl 1/1 Running 0 3m
更新标签
有时需要要在创建新资源之前对现有的 Pod 和其它资源重新打标签。
这可以用 kubectl label 完成。
例如,如果想要将所有 NGINX Pod 标记为前端层,运行:
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
首先用标签 "app=nginx" 过滤所有的 Pod,然后用 "tier=fe" 标记它们。 想要查看你刚设置了标签的 Pod,请运行:
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
此命令将输出所有 "app=nginx" 的 Pod,并有一个额外的描述 Pod 所在分层的标签列
(用参数 -L 或者 --label-columns 标明)。
想要了解更多信息,请参考标签和
kubectl label
命令文档。
接下来
- 学习如何给节点添加标签
- 查阅众所周知的标签、注解和污点
- 参见推荐使用的标签
- 使用名字空间标签来实施 Pod 安全性标准
- 阅读为 Pod 标签编写控制器的博文
1.1.4 - 名字空间
在 Kubernetes 中,名字空间(Namespace) 提供一种机制,将同一集群中的资源划分为相互隔离的组。 同一名字空间内的资源名称要唯一,但跨名字空间时没有这个要求。 名字空间作用域仅针对带有名字空间的对象, (例如 Deployment、Service 等),这种作用域对集群范围的对象 (例如 StorageClass、Node、PersistentVolume 等)不适用。
何时使用多个名字空间
名字空间适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本不需要创建或考虑名字空间。当需要名字空间提供的功能时,请开始使用它们。
名字空间为名称提供了一个范围。资源的名称需要在名字空间内是唯一的,但不能跨名字空间。 名字空间不能相互嵌套,每个 Kubernetes 资源只能在一个名字空间中。
名字空间是在多个用户之间划分集群资源的一种方法(通过资源配额)。
不必使用多个名字空间来分隔仅仅轻微不同的资源,例如同一软件的不同版本: 应该使用标签来区分同一名字空间中的不同资源。
说明:
对于生产集群,请考虑不要使用 default 名字空间,而是创建其他名字空间来使用。
初始名字空间
Kubernetes 启动时会创建四个初始名字空间:
default- Kubernetes 包含这个名字空间,以便于你无需创建新的名字空间即可开始使用新集群。
kube-node-lease- 该名字空间包含用于与各个节点关联的 Lease(租约)对象。 节点租约允许 kubelet 发送心跳, 由此控制面能够检测到节点故障。
kube-public- 所有的客户端(包括未经身份验证的客户端)都可以读取该名字空间。 该名字空间主要预留为集群使用,以便某些资源需要在整个集群中可见可读。 该名字空间的公共属性只是一种约定而非要求。
kube-system- 该名字空间用于 Kubernetes 系统创建的对象。
使用名字空间
名字空间的创建和删除在名字空间的管理指南文档描述。
说明:
避免使用前缀 kube- 创建名字空间,因为它是为 Kubernetes 系统名字空间保留的。
查看名字空间
你可以使用以下命令列出集群中现存的名字空间:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1d
为请求设置名字空间
要为当前请求设置名字空间,请使用 --namespace 参数。
例如:
kubectl run nginx --image=nginx --namespace=<名字空间名称>
kubectl get pods --namespace=<名字空间名称>
设置名字空间偏好
你可以永久保存名字空间,以用于对应上下文中所有后续 kubectl 命令。
kubectl config set-context --current --namespace=<名字空间名称>
# 验证
kubectl config view --minify | grep namespace:
名字空间和 DNS
当你创建一个服务时, Kubernetes 会创建一个相应的 DNS 条目。
该条目的形式是 <服务名称>.<名字空间名称>.svc.cluster.local,这意味着如果容器只使用
<服务名称>,它将被解析到本地名字空间的服务。这对于跨多个名字空间(如开发、测试和生产)
使用相同的配置非常有用。如果你希望跨名字空间访问,则需要使用完全限定域名(FQDN)。
因此,所有的名字空间名称都必须是合法的 RFC 1123 DNS 标签。
警告:
通过创建与公共顶级域名同名的名字空间, 这些名字空间中的服务可以拥有与公共 DNS 记录重叠的、较短的 DNS 名称。 所有名字空间中的负载在执行 DNS 查找时, 如果查找的名称没有尾部句点, 就会被重定向到这些服务上,因此呈现出比公共 DNS 更高的优先序。
为了缓解这类问题,需要将创建名字空间的权限授予可信的用户。 如果需要,你可以额外部署第三方的安全控制机制, 例如以准入 Webhook 的形式,阻止用户创建与公共 TLD 同名的名字空间。
并非所有对象都在名字空间中
大多数 kubernetes 资源(例如 Pod、Service、副本控制器等)都位于某些名字空间中。 但是名字空间资源本身并不在名字空间中。而且底层资源, 例如节点和持久化卷不属于任何名字空间。
查看哪些 Kubernetes 资源在名字空间中,哪些不在名字空间中:
# 位于名字空间中的资源
kubectl api-resources --namespaced=true
# 不在名字空间中的资源
kubectl api-resources --namespaced=false
自动打标签
特性状态:
Kubernetes 1.22 [stable]
Kubernetes 控制面会为所有名字空间设置一个不可变更的标签
kubernetes.io/metadata.name。
标签的值是名字空间的名称。
接下来
1.1.5 - 注解
你可以使用 Kubernetes 注解为对象附加任意的非标识的元数据。 客户端程序(例如工具和库)能够获取这些元数据信息。
为对象附加元数据
你可以使用标签或注解将元数据附加到 Kubernetes 对象。 标签可以用来选择对象和查找满足某些条件的对象集合。 相反,注解不用于标识和选择对象。 注解中的元数据,可以很小,也可以很大,可以是结构化的,也可以是非结构化的,能够包含标签不允许的字符。 可以在同一对象的元数据中同时使用标签和注解。
注解和标签一样,是键/值对:
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
说明:
Map 中的键和值必须是字符串。 换句话说,你不能使用数字、布尔值、列表或其他类型的键或值。
以下是一些例子,用来说明哪些信息可以使用注解来记录:
- 由声明性配置所管理的字段。 将这些字段附加为注解,能够将它们与客户端或服务端设置的默认值、 自动生成的字段以及通过自动调整大小或自动伸缩系统设置的字段区分开来。
- 构建、发布或镜像信息(如时间戳、发布 ID、Git 分支、PR 数量、镜像哈希、仓库地址)。
- 指向日志记录、监控、分析或审计仓库的指针。
-
可用于调试目的的客户端库或工具信息:例如,名称、版本和构建信息。
-
用户或者工具/系统的来源信息,例如来自其他生态系统组件的相关对象的 URL。
-
轻量级上线工具的元数据信息:例如,配置或检查点。
-
负责人员的电话或呼机号码,或指定在何处可以找到该信息的目录条目,如团队网站。
-
从用户到最终运行的指令,以修改行为或使用非标准功能。
你可以将这类信息存储在外部数据库或目录中而不使用注解, 但这样做就使得开发人员很难生成用于部署、管理、自检的客户端共享库和工具。
语法和字符集
注解(Annotations) 存储的形式是键/值对。有效的注解键分为两部分:
可选的前缀和名称,以斜杠(/)分隔。
名称段是必需项,并且必须在 63 个字符以内,以字母数字字符([a-z0-9A-Z])开头和结尾,
并允许使用破折号(-),下划线(_),点(.)和字母数字。
前缀是可选的。如果指定,则前缀必须是 DNS 子域:一系列由点(.)分隔的 DNS 标签,
总计不超过 253 个字符,后跟斜杠(/)。
如果省略前缀,则假定注解键对用户是私有的。 由系统组件添加的注解
(例如,kube-scheduler,kube-controller-manager,kube-apiserver,kubectl
或其他第三方组件),必须为终端用户添加注解前缀。
kubernetes.io/ 和 k8s.io/ 前缀是为 Kubernetes 核心组件保留的。
例如,下面是一个 Pod 的清单,其注解中包含 imageregistry: https://hub.docker.com/:
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations:
imageregistry: "https://hub.docker.com/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
接下来
- 进一步了解标签和选择算符。
- 查找众所周知的标签、注解和污点。
1.1.6 - 字段选择器
“字段选择器(Field selectors)”允许你根据一个或多个资源字段的值筛选 Kubernetes 对象。 下面是一些使用字段选择器查询的例子:
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
下面这个 kubectl 命令将筛选出
status.phase
字段值为 Running 的所有 Pod:
kubectl get pods --field-selector status.phase=Running
说明:
字段选择器本质上是资源“过滤器(Filters)”。默认情况下,字段选择器/过滤器是未被应用的,
这意味着指定类型的所有资源都会被筛选出来。
这使得 kubectl get pods 和 kubectl get pods --field-selector ""
这两个 kubectl 查询是等价的。
支持的字段
不同的 Kubernetes 资源类型支持不同的字段选择器。
所有资源类型都支持 metadata.name 和 metadata.namespace 字段。
使用不被支持的字段选择器会产生错误。例如:
kubectl get ingress --field-selector foo.bar=baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
支持的操作符
你可在字段选择器中使用 =、== 和 != (= 和 == 的意义是相同的)操作符。
例如,下面这个 kubectl 命令将筛选所有不属于 default 命名空间的 Kubernetes 服务:
kubectl get services --all-namespaces --field-selector metadata.namespace!=default
说明:
基于集合的操作符
(in、notin、exists)不支持字段选择算符。
链式选择器
同标签和其他选择器一样,
字段选择器可以通过使用逗号分隔的列表组成一个选择链。
下面这个 kubectl 命令将筛选 status.phase 字段不等于 Running 同时
spec.restartPolicy 字段等于 Always 的所有 Pod:
kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
多种资源类型
你能够跨多种资源类型来使用字段选择器。
下面这个 kubectl 命令将筛选出所有不在 default 命名空间中的 StatefulSet 和 Service:
kubectl get statefulsets,services --all-namespaces --field-selector metadata.namespace!=default
1.1.7 - Finalizers
Finalizer 是带有命名空间的键,告诉 Kubernetes 等到特定的条件被满足后, 再完全删除被标记为删除的资源。 Finalizer 提醒控制器清理被删除的对象拥有的资源。
当你告诉 Kubernetes 删除一个指定了 Finalizer 的对象时,
Kubernetes API 通过填充 .metadata.deletionTimestamp 来标记要删除的对象,
并返回 202 状态码(HTTP "已接受") 使其进入只读状态。
此时控制平面或其他组件会采取 Finalizer 所定义的行动,
而目标对象仍然处于终止中(Terminating)的状态。
这些行动完成后,控制器会删除目标对象相关的 Finalizer。
当 metadata.finalizers 字段为空时,Kubernetes 认为删除已完成并删除对象。
你可以使用 Finalizer 控制资源的垃圾收集。 例如,你可以定义一个 Finalizer,在删除目标资源前清理相关资源或基础设施。
你可以使用 Finalizers 来控制对象的垃圾回收, 方法是在删除目标资源之前提醒控制器执行特定的清理任务。
Finalizers 通常不指定要执行的代码。 相反,它们通常是特定资源上的键的列表,类似于注解。 Kubernetes 自动指定了一些 Finalizers,但你也可以指定你自己的。
Finalizers 如何工作
当你使用清单文件创建资源时,你可以在 metadata.finalizers 字段指定 Finalizers。
当你试图删除该资源时,处理删除请求的 API 服务器会注意到 finalizers 字段中的值,
并进行以下操作:
- 修改对象,将你开始执行删除的时间添加到
metadata.deletionTimestamp字段。 - 禁止对象被删除,直到其
metadata.finalizers字段内的所有项被删除。 - 返回
202状态码(HTTP "Accepted")。
管理 finalizer 的控制器注意到对象上发生的更新操作,对象的 metadata.deletionTimestamp
被设置,意味着已经请求删除该对象。然后,控制器会试图满足资源的 Finalizers 的条件。
每当一个 Finalizer 的条件被满足时,控制器就会从资源的 finalizers 字段中删除该键。
当 finalizers 字段为空时,deletionTimestamp 字段被设置的对象会被自动删除。
你也可以使用 Finalizers 来阻止删除未被管理的资源。
一个常见的 Finalizer 的例子是 kubernetes.io/pv-protection,
它用来防止意外删除 PersistentVolume 对象。
当一个 PersistentVolume 对象被 Pod 使用时,
Kubernetes 会添加 pv-protection Finalizer。
如果你试图删除 PersistentVolume,它将进入 Terminating 状态,
但是控制器因为该 Finalizer 存在而无法删除该资源。
当 Pod 停止使用 PersistentVolume 时,
Kubernetes 清除 pv-protection Finalizer,控制器就会删除该卷。
说明:
- 当你
DELETE一个对象时,Kubernetes 为该对象增加删除时间戳,然后立即开始限制 对这个正处于待删除状态的对象的.metadata.finalizers字段进行修改。 你可以删除现有的 finalizers (从finalizers列表删除条目),但你不能添加新的 finalizer。 对象的deletionTimestamp被设置后也不能修改。 - 删除请求已被发出之后,你无法复活该对象。唯一的方法是删除它并创建一个新的相似对象。
属主引用、标签和 Finalizers
与标签类似, 属主引用 描述了 Kubernetes 中对象之间的关系,但它们作用不同。 当一个控制器 管理类似于 Pod 的对象时,它使用标签来跟踪相关对象组的变化。 例如,当 Job 创建一个或多个 Pod 时, Job 控制器会给这些 Pod 应用上标签,并跟踪集群中的具有相同标签的 Pod 的变化。
Job 控制器还为这些 Pod 添加了“属主引用”,指向创建 Pod 的 Job。 如果你在这些 Pod 运行的时候删除了 Job, Kubernetes 会使用属主引用(而不是标签)来确定集群中哪些 Pod 需要清理。
当 Kubernetes 识别到要删除的资源上的属主引用时,它也会处理 Finalizers。
在某些情况下,Finalizers 会阻止依赖对象的删除, 这可能导致目标属主对象被保留的时间比预期的长,而没有被完全删除。 在这些情况下,你应该检查目标属主和附属对象上的 Finalizers 和属主引用,来排查原因。
说明:
在对象卡在删除状态的情况下,要避免手动移除 Finalizers,以允许继续删除操作。 Finalizers 通常因为特殊原因被添加到资源上,所以强行删除它们会导致集群出现问题。 只有了解 finalizer 的用途时才能这样做,并且应该通过一些其他方式来完成 (例如,手动清除其余的依赖对象)。
接下来
- 在 Kubernetes 博客上阅读使用 Finalizers 控制删除。
1.1.8 - 属主与附属
在 Kubernetes 中,一些对象是其他对象的“属主(Owner)”。 例如,ReplicaSet 是一组 Pod 的属主。 具有属主的对象是属主的“附属(Dependent)”。
属主关系不同于一些资源使用的标签和选择算符机制。
例如,有一个创建 EndpointSlice 对象的 Service,
该 Service 使用标签来让控制平面确定哪些
EndpointSlice 对象属于该 Service。除开标签,每个代表 Service 所管理的
EndpointSlice 都有一个属主引用。属主引用避免 Kubernetes
的不同部分干扰到不受它们控制的对象。
对象规约中的属主引用
附属对象有一个 metadata.ownerReferences 字段,用于引用其属主对象。一个有效的属主引用,
包含与附属对象同在一个命名空间下的对象名称和一个
UID。
Kubernetes 自动为一些对象的附属资源设置属主引用的值,
这些对象包含 ReplicaSet、DaemonSet、Deployment、Job、CronJob、ReplicationController 等。
你也可以通过改变这个字段的值,来手动配置这些关系。
然而,通常不需要这么做,你可以让 Kubernetes 自动管理附属关系。
附属对象还有一个 ownerReferences.blockOwnerDeletion 字段,该字段使用布尔值,
用于控制特定的附属对象是否可以阻止垃圾收集删除其属主对象。
如果控制器(例如 Deployment 控制器)
设置了 metadata.ownerReferences 字段的值,Kubernetes 会自动设置
blockOwnerDeletion 的值为 true。
你也可以手动设置 blockOwnerDeletion 字段的值,以控制哪些附属对象会阻止垃圾收集。
Kubernetes 准入控制器根据属主的删除权限控制用户访问,以便为附属资源更改此字段。 这种控制机制可防止未经授权的用户延迟属主对象的删除。
说明:
根据设计,kubernetes 不允许跨名字空间指定属主。 名字空间范围的附属可以指定集群范围的或者名字空间范围的属主。 名字空间范围的属主必须和该附属处于相同的名字空间。 如果名字空间范围的属主和附属不在相同的名字空间,那么该属主引用就会被认为是缺失的, 并且当附属的所有属主引用都被确认不再存在之后,该附属就会被删除。
集群范围的附属只能指定集群范围的属主。 在 v1.20+ 版本,如果一个集群范围的附属指定了一个名字空间范围类型的属主, 那么该附属就会被认为是拥有一个不可解析的属主引用,并且它不能够被垃圾回收。
在 v1.20+ 版本,如果垃圾收集器检测到无效的跨名字空间的属主引用,
或者一个集群范围的附属指定了一个名字空间范围类型的属主,
那么它就会报告一个警告事件。该事件的原因是 OwnerRefInvalidNamespace,
involvedObject 属性中包含无效的附属。
你可以运行 kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace
来获取该类型的事件。
属主关系与 Finalizer
当你告诉 Kubernetes 删除一个资源,API 服务器允许管理控制器处理该资源的任何
Finalizer 规则。
Finalizer
防止意外删除你的集群所依赖的、用于正常运作的资源。
例如,如果你试图删除一个仍被 Pod 使用的 PersistentVolume,该资源不会被立即删除,
因为 PersistentVolume 有
kubernetes.io/pv-protection Finalizer。
相反,数据卷将进入 Terminating 状态,
直到 Kubernetes 清除这个 Finalizer,而这种情况只会发生在 PersistentVolume
不再被挂载到 Pod 上时。
当你使用前台或孤立级联删除时,
Kubernetes 也会向属主资源添加 Finalizer。
在前台删除中,会添加 foreground Finalizer,这样控制器必须在删除了拥有
ownerReferences.blockOwnerDeletion=true 的附属资源后,才能删除属主对象。
如果你指定了孤立删除策略,Kubernetes 会添加 orphan Finalizer,
这样控制器在删除属主对象后,会忽略附属资源。
接下来
- 了解更多关于 Kubernetes Finalizer。
- 了解关于垃圾收集。
- 阅读对象元数据的 API 参考文档。
1.1.9 - 推荐使用的标签
除了 kubectl 和 dashboard 之外,你还可以使用其他工具来可视化和管理 Kubernetes 对象。 一组通用的标签可以让多个工具之间相互操作,用所有工具都能理解的通用方式描述对象。
除了支持工具外,推荐的标签还以一种可以查询的方式描述了应用程序。
元数据围绕 应用(application) 的概念进行组织。Kubernetes 不是平台即服务(PaaS),没有或强制执行正式的应用程序概念。 相反,应用程序是非正式的,并使用元数据进行描述。应用程序包含的定义是松散的。
说明:
这些是推荐的标签。它们使管理应用程序变得更容易但不是任何核心工具所必需的。
共享标签和注解都使用同一个前缀:app.kubernetes.io。没有前缀的标签是用户私有的。
共享前缀可以确保共享标签不会干扰用户自定义的标签。
标签
为了充分利用这些标签,应该在每个资源对象上都使用它们。
| 键 | 描述 | 示例 | 类型 |
|---|---|---|---|
app.kubernetes.io/name |
应用程序的名称 | mysql |
字符串 |
app.kubernetes.io/instance |
用于唯一确定应用实例的名称 | mysql-abcxzy |
字符串 |
app.kubernetes.io/version |
应用程序的当前版本(例如语义版本 1.0、修订版哈希等) | 5.7.21 |
字符串 |
app.kubernetes.io/component |
架构中的组件 | database |
字符串 |
app.kubernetes.io/part-of |
此级别的更高级别应用程序的名称 | wordpress |
字符串 |
app.kubernetes.io/managed-by |
用于管理应用程序的工具 | helm |
字符串 |
为说明这些标签的实际使用情况,请看下面的 StatefulSet 对象:
# 这是一段节选
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: helm
应用和应用实例
应用可以在 Kubernetes 集群中安装一次或多次。在某些情况下,可以安装在同一命名空间中。 例如,可以不止一次地为不同的站点安装不同的 WordPress。
应用的名称和实例的名称是分别记录的。例如,WordPress 应用的
app.kubernetes.io/name 为 wordpress,而其实例名称
app.kubernetes.io/instance 为 wordpress-abcxzy。
这使得应用和应用的实例均可被识别,应用的每个实例都必须具有唯一的名称。
示例
为了说明使用这些标签的不同方式,以下示例具有不同的复杂性。
一个简单的无状态服务
考虑使用 Deployment 和 Service 对象部署的简单无状态服务的情况。
以下两个代码段表示如何以最简单的形式使用标签。
下面的 Deployment 用于监督运行应用本身的那些 Pod。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
下面的 Service 用于暴露应用。
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
带有一个数据库的 Web 应用程序
考虑一个稍微复杂的应用:一个使用 Helm 安装的 Web 应用(WordPress), 其中使用了数据库(MySQL)。以下代码片段说明用于部署此应用程序的对象的开始。
以下 Deployment 的开头用于 WordPress:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
这个 Service 用于暴露 WordPress:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
MySQL 作为一个 StatefulSet 暴露,包含它和它所属的较大应用程序的元数据:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
Service 用于将 MySQL 作为 WordPress 的一部分暴露:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
使用 MySQL StatefulSet 和 Service,你会注意到有关 MySQL 和 WordPress 的信息,包括更广泛的应用程序。
1.2 - Kubernetes 组件
Kubernetes 集群由控制平面的组件和一组称为节点的机器组成。
当你部署完 Kubernetes,便拥有了一个完整的集群。
一组工作机器,称为节点, 会运行容器化应用程序。每个集群至少有一个工作节点。
工作节点会托管 Pod,而 Pod 就是作为应用负载的组件。 控制平面管理集群中的工作节点和 Pod。 在生产环境中,控制平面通常跨多台计算机运行, 一个集群通常运行多个节点,提供容错性和高可用性。
本文档概述了一个正常运行的 Kubernetes 集群所需的各种组件。

Kubernetes 集群的组件
控制平面组件(Control Plane Components)
控制平面组件会为集群做出全局决策,比如资源的调度。
以及检测和响应集群事件,例如当不满足部署的 replicas
字段时,要启动新的 Pod)。
控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。 请参阅使用 kubeadm 构建高可用性集群 中关于跨多机器控制平面设置的示例。
kube-apiserver
API 服务器是 Kubernetes 控制平面的组件, 该组件负责公开了 Kubernetes API,负责处理接受请求的工作。 API 服务器是 Kubernetes 控制平面的前端。
Kubernetes API 服务器的主要实现是 kube-apiserver。
kube-apiserver 设计上考虑了水平扩缩,也就是说,它可通过部署多个实例来进行扩缩。
你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
etcd
一致且高可用的键值存储,用作 Kubernetes 所有集群数据的后台数据库。
如果你的 Kubernetes 集群使用 etcd 作为其后台数据库, 请确保你针对这些数据有一份 备份计划。
你可以在官方文档中找到有关 etcd 的深入知识。
kube-scheduler
kube-scheduler 是控制平面的组件,
负责监视新创建的、未指定运行节点(node)的 Pods,
并选择节点来让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 及 Pods 集合的资源需求、软硬件及策略约束、 亲和性及反亲和性规范、数据位置、工作负载间的干扰及最后时限。
kube-controller-manager
kube-controller-manager 是控制平面的组件, 负责运行控制器进程。
从逻辑上讲, 每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在同一个进程中运行。
有许多不同类型的控制器。以下是一些例子:
- 节点控制器(Node Controller):负责在节点出现故障时进行通知和响应
- 任务控制器(Job Controller):监测代表一次性任务的 Job 对象,然后创建 Pod 来运行这些任务直至完成
- 端点分片控制器(EndpointSlice controller):填充端点分片(EndpointSlice)对象(以提供 Service 和 Pod 之间的链接)。
- 服务账号控制器(ServiceAccount controller):为新的命名空间创建默认的服务账号(ServiceAccount)。
以上并不是一个详尽的列表。
cloud-controller-manager
一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager) 允许将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。cloud-controller-manager 仅运行特定于云平台的控制器。
因此如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境,
所部署的集群不需要有云控制器管理器。
与 kube-controller-manager 类似,cloud-controller-manager
将若干逻辑上独立的控制回路组合到同一个可执行文件中,
供你以同一进程的方式运行。
你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。
下面的控制器都包含对云平台驱动的依赖:
- 节点控制器(Node Controller):用于在节点终止响应后检查云提供商以确定节点是否已被删除
- 路由控制器(Route Controller):用于在底层云基础架构中设置路由
- 服务控制器(Service Controller):用于创建、更新和删除云提供商负载均衡器
Node 组件
节点组件会在每个节点上运行,负责维护运行的 Pod 并提供 Kubernetes 运行环境。
kubelet
kubelet 会在集群中每个节点(node)上运行。
它保证容器(containers)都运行在
Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpec,确保这些 PodSpec 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
kube-proxy
kube-proxy 是集群中每个节点(node)上所运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点上的一些网络规则, 这些网络规则会允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了可用的数据包过滤层,则 kube-proxy 会通过它来实现网络规则。 否则,kube-proxy 仅做流量转发。
容器运行时(Container Runtime)
这个基础组件使 Kubernetes 能够有效运行容器。 它负责管理 Kubernetes 环境中容器的执行和生命周期。
Kubernetes 支持许多容器运行环境,例如 containerd、 CRI-O 以及 Kubernetes CRI (容器运行环境接口) 的其他任何实现。
插件(Addons)
插件使用 Kubernetes 资源(DaemonSet、
Deployment 等)实现集群功能。
因为这些插件提供集群级别的功能,插件中命名空间域的资源属于 kube-system 命名空间。
下面描述众多插件中的几种。有关可用插件的完整列表,请参见 插件(Addons)。
DNS
尽管其他插件都并非严格意义上的必需组件,但几乎所有 Kubernetes 集群都应该有集群 DNS, 因为很多示例都需要 DNS 服务。
集群 DNS 是一个 DNS 服务器,和环境中的其他 DNS 服务器一起工作,它为 Kubernetes 服务提供 DNS 记录。
Kubernetes 启动的容器自动将此 DNS 服务器包含在其 DNS 搜索列表中。
Web 界面(仪表盘)
Dashboard 是 Kubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身, 并进行故障排除。
容器资源监控
容器资源监控 将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中, 并提供浏览这些数据的界面。
集群层面日志
集群层面日志机制负责将容器的日志数据保存到一个集中的日志存储中, 这种集中日志存储提供搜索和浏览接口。
网络插件
网络插件 是实现容器网络接口(CNI)规范的软件组件。它们负责为 Pod 分配 IP 地址,并使这些 Pod 能在集群内部相互通信。
接下来
进一步了解以下内容:
- 节点及其与控制平面的通信。
- Kubernetes 中的控制器。
- Kubernetes 的默认调度程序 kube-scheduler。
- etcd 的官方文档。
- Kubernetes 中的几个容器运行时。
- 使用 cloud-controller-manager 与云提供商进行集成。
- kubectl 命令。
1.3 - Kubernetes API
Kubernetes API 使你可以查询和操纵 Kubernetes 中对象的状态。 Kubernetes 控制平面的核心是 API 服务器和它暴露的 HTTP API。 用户、集群的不同部分以及外部组件都通过 API 服务器相互通信。
Kubernetes 控制面的核心是 API 服务器。 API 服务器负责提供 HTTP API,以供用户、集群中的不同部分和集群外部组件相互通信。
Kubernetes API 使你可以在 Kubernetes 中查询和操纵 API 对象 (例如 Pod、Namespace、ConfigMap 和 Event)的状态。
大部分操作都可以通过 kubectl 命令行接口或类似 kubeadm 这类命令行工具来执行, 这些工具在背后也是调用 API。不过,你也可以使用 REST 调用来访问这些 API。 Kubernetes 为那些希望使用 Kubernetes API 编写应用的开发者提供一组客户端库。
每个 Kubernetes 集群都会发布集群所使用的 API 规范。
Kubernetes 使用两种机制来发布这些 API 规范;这两种机制都有助于实现自动互操作。
例如,kubectl 工具获取并缓存 API 规范,以实现命令行补全和其他特性。所支持的两种机制如下:
- 发现 API 提供有关 Kubernetes API 的信息:API 名称、资源、版本和支持的操作。 此 API 是特定于 Kubernetes 的一个术语,因为它是一个独立于 Kubernetes OpenAPI 的 API。 其目的是为可用的资源提供简要总结,不详细说明资源的具体模式。有关资源模式的参考,请参阅 OpenAPI 文档。
- Kubernetes OpenAPI 文档为所有 Kubernetes API 端点提供(完整的) OpenAPI v2.0 和 v3.0 模式。OpenAPI v3 是访问 OpenAPI 的首选方法, 因为它提供了更全面和准确的 API 视图。其中包括所有可用的 API 路径,以及每个端点上每个操作所接收和生成的所有资源。 它还包括集群支持的所有可扩展组件。这些数据是完整的规范,比 Discovery API 提供的规范要大得多。
Discovery API
Kubernetes 通过 Discovery API 发布集群所支持的所有组版本和资源列表。对于每个资源,包括以下内容:
- 名称
- 集群作用域还是名字空间作用域
- 端点 URL 和所支持的动词
- 别名
- 组、版本、类别
API 以聚合和非聚合形式提供。聚合的发现提供两个端点,而非聚合的发现为每个组版本提供单独的端点。
聚合的发现
特性状态:
Kubernetes v1.27 [beta]
Kubernetes 为聚合的发现提供了 Beta 支持,通过两个端点(/api 和 /apis)发布集群所支持的所有资源。
请求这个端点会大大减少从集群获取发现数据时发送的请求数量。你可以通过带有
Accept 头(Accept: application/json;v=v2beta1;g=apidiscovery.k8s.io;as=APIGroupDiscoveryList)
的请求发送到不同端点,来指明聚合发现的资源。
如果没有使用 Accept 头指示资源类型,对于 /api 和 /apis 端点的默认响应将是一个非聚合的发现文档。
内置资源的发现文档可以在 Kubernetes GitHub 代码仓库中找到。如果手头没有 Kubernetes 集群可供查询, 此 Github 文档可用作可用资源的基础集合的参考。端点还支持 ETag 和 protobuf 编码。
非聚合的发现
在不使用聚合发现的情况下,发现 API 以不同级别发布,同时根端点为下游文档发布发现信息。
集群支持的所有组版本列表发布在 /api 和 /apis 端点。例如:
{
"kind": "APIGroupList",
"apiVersion": "v1",
"groups": [
{
"name": "apiregistration.k8s.io",
"versions": [
{
"groupVersion": "apiregistration.k8s.io/v1",
"version": "v1"
}
],
"preferredVersion": {
"groupVersion": "apiregistration.k8s.io/v1",
"version": "v1"
}
},
{
"name": "apps",
"versions": [
{
"groupVersion": "apps/v1",
"version": "v1"
}
],
"preferredVersion": {
"groupVersion": "apps/v1",
"version": "v1"
}
},
...
}
用户需要发出额外的请求才能在 /apis/<group>/<version>(例如 /apis/rbac.authorization.k8s.io/v1alpha1)
获取每个组版本的发现文档。这些发现文档会公布在特定组版本下所提供的资源列表。
kubectl 使用这些端点来获取某集群所支持的资源列表。
OpenAPI 接口定义
有关 OpenAPI 规范的细节,参阅 OpenAPI 文档。
Kubernetes 同时提供 OpenAPI v2.0 和 OpenAPI v3.0。OpenAPI v3 是访问 OpenAPI 的首选方法,
因为它提供了对 Kubernetes 资源更全面(无损)的表示。由于 OpenAPI v2 的限制,
所公布的 OpenAPI 中会丢弃掉一些字段,包括但不限于 default、nullable、oneOf。
OpenAPI v2
Kubernetes API 服务器通过 /openapi/v2 端点提供聚合的 OpenAPI v2 规范。
你可以按照下表所给的请求头部,指定响应的格式:
| 头部 | 可选值 | 说明 |
|---|---|---|
Accept-Encoding |
gzip |
不指定此头部也是可以的 |
Accept |
application/com.github.proto-openapi.spec.v2@v1.0+protobuf |
主要用于集群内部 |
application/json |
默认值 | |
* |
提供application/json |
OpenAPI v3
特性状态:
Kubernetes v1.27 [stable]
Kubernetes 支持将其 API 的描述以 OpenAPI v3 形式发布。
发现端点 /openapi/v3 被提供用来查看可用的所有组、版本列表。
此列表仅返回 JSON。这些组、版本以下面的格式提供:
{
"paths": {
...,
"api/v1": {
"serverRelativeURL": "/openapi/v3/api/v1?hash=CC0E9BFD992D8C59AEC98A1E2336F899E8318D3CF4C68944C3DEC640AF5AB52D864AC50DAA8D145B3494F75FA3CFF939FCBDDA431DAD3CA79738B297795818CF"
},
"apis/admissionregistration.k8s.io/v1": {
"serverRelativeURL": "/openapi/v3/apis/admissionregistration.k8s.io/v1?hash=E19CC93A116982CE5422FC42B590A8AFAD92CDE9AE4D59B5CAAD568F083AD07946E6CB5817531680BCE6E215C16973CD39003B0425F3477CFD854E89A9DB6597"
},
....
}
}
为了改进客户端缓存,相对的 URL 会指向不可变的 OpenAPI 描述。
为了此目的,API 服务器也会设置正确的 HTTP 缓存标头
(Expires 为未来 1 年,和 Cache-Control 为 immutable)。
当一个过时的 URL 被使用时,API 服务器会返回一个指向最新 URL 的重定向。
Kubernetes API 服务器会在端点 /openapi/v3/apis/<group>/<version>?hash=<hash>
发布一个 Kubernetes 组版本的 OpenAPI v3 规范。
请参阅下表了解可接受的请求头部。
| 头部 | 可选值 | 说明 |
|---|---|---|
Accept-Encoding |
gzip |
不提供此头部也是可接受的 |
Accept |
application/com.github.proto-openapi.spec.v3@v1.0+protobuf |
主要用于集群内部使用 |
application/json |
默认 | |
* |
以 application/json 形式返回 |
k8s.io/client-go/openapi3
包中提供了获取 OpenAPI v3 的 Golang 实现。
Kubernetes 1.29 发布了 OpenAPI v2.0 和 v3.0; 近期没有支持 v3.1 的计划。
Protobuf 序列化
Kubernetes 为 API 实现了一种基于 Protobuf 的序列化格式,主要用于集群内部通信。 关于此格式的详细信息,可参考 Kubernetes Protobuf 序列化设计提案。 每种模式对应的接口描述语言(IDL)位于定义 API 对象的 Go 包中。
持久化
Kubernetes 通过将序列化状态的对象写入到 etcd 中完成存储操作。
API 发现
集群支持的所有组版本列表被发布在 /api 和 /apis 端点。
每个组版本还会通过 /apis/<group>/<version>
(例如 /apis/rbac.authorization.k8s.io/v1alpha1)广播支持的资源列表。
这些端点由 kubectl 用于获取集群支持的资源列表。
聚合发现
特性状态:
Kubernetes v1.27 [beta]
Kubernetes 对聚合发现提供 Beta 支持,通过两个端点(/api 和 /apis)
发布集群支持的所有资源,而不是每个组版本都需要一个端点。
请求此端点显著减少了获取平均 Kubernetes 集群发现而发送的请求数量。
通过请求各自的端点并附带表明聚合发现资源
Accept: application/json;v=v2beta1;g=apidiscovery.k8s.io;as=APIGroupDiscoveryList
的 Accept 头部来进行访问。
该端点还支持 ETag 和 protobuf 编码。
API 组和版本控制
为了更容易消除字段或重组资源的呈现方式,Kubernetes 支持多个 API 版本,每个版本位于不同的 API 路径,
例如 /api/v1 或 /apis/rbac.authorization.k8s.io/v1alpha1。
版本控制是在 API 级别而不是在资源或字段级别完成的,以确保 API 呈现出清晰、一致的系统资源和行为视图, 并能够控制对生命结束和/或实验性 API 的访问。
为了更容易演进和扩展其 API,Kubernetes 实现了 API 组, 这些 API 组可以被启用或禁用。
API 资源通过其 API 组、资源类型、名字空间(用于名字空间作用域的资源)和名称来区分。 API 服务器透明地处理 API 版本之间的转换:所有不同的版本实际上都是相同持久化数据的呈现。 API 服务器可以通过多个 API 版本提供相同的底层数据。
例如,假设针对相同的资源有两个 API 版本:v1 和 v1beta1。
如果你最初使用其 API 的 v1beta1 版本创建了一个对象,
你稍后可以使用 v1beta1 或 v1 API 版本来读取、更新或删除该对象,
直到 v1beta1 版本被废弃和移除为止。此后,你可以使用 v1 API 继续访问和修改该对象。
API 变更
任何成功的系统都要随着新的使用案例的出现和现有案例的变化来成长和变化。 为此,Kubernetes 已设计了 Kubernetes API 来持续变更和成长。 Kubernetes 项目的目标是 不要 给现有客户端带来兼容性问题,并在一定的时期内维持这种兼容性, 以便其他项目有机会作出适应性变更。
一般而言,新的 API 资源和新的资源字段可以被频繁地添加进来。 删除资源或者字段则要遵从 API 废弃策略。
Kubernetes 对维护达到正式发布(GA)阶段的官方 API 的兼容性有着很强的承诺,通常这一 API 版本为 v1。
此外,Kubernetes 保持与 Kubernetes 官方 API 的 Beta API 版本持久化数据的兼容性,
并确保在该功能特性已进入稳定期时数据可以通过 GA API 版本进行转换和访问。
如果你采用一个 Beta API 版本,一旦该 API 进阶,你将需要转换到后续的 Beta 或稳定的 API 版本。 执行此操作的最佳时间是 Beta API 处于弃用期,因为此时可以通过两个 API 版本同时访问那些对象。 一旦 Beta API 结束其弃用期并且不再提供服务,则必须使用替换的 API 版本。
说明:
尽管 Kubernetes 也努力为 Alpha API 版本维护兼容性,在有些场合兼容性是无法做到的。 如果你使用了任何 Alpha API 版本,需要在升级集群时查看 Kubernetes 发布说明, 如果 API 确实以不兼容的方式发生变更,则需要在升级之前删除所有现有的 Alpha 对象。
关于 API 版本分级的定义细节,请参阅 API 版本参考页面。
API 扩展
有两种途径来扩展 Kubernetes API:
接下来
- 了解如何通过添加你自己的 CustomResourceDefinition 来扩展 Kubernetes API。
- 控制 Kubernetes API 访问页面描述了集群如何针对 API 访问管理身份认证和鉴权。
- 通过阅读 API 参考了解 API 端点、资源类型以及示例。
- 阅读 API 变更(英文) 以了解什么是兼容性的变更以及如何变更 API。
2 - Kubernetes 架构
Kubernetes 背后的架构概念。

Kubernetes 集群架构
2.1 - 节点
Kubernetes 通过将容器放入在节点(Node)上运行的 Pod 中来执行你的工作负载。 节点可以是一个虚拟机或者物理机器,取决于所在的集群配置。 每个节点包含运行 Pod 所需的服务; 这些节点由控制面负责管理。
通常集群中会有若干个节点;而在一个学习所用或者资源受限的环境中,你的集群中也可能只有一个节点。
节点上的组件包括 kubelet、 容器运行时以及 kube-proxy。
管理
向 API 服务器添加节点的方式主要有两种:
- 节点上的
kubelet向控制面执行自注册; - 你(或者别的什么人)手动添加一个 Node 对象。
在你创建了 Node 对象或者节点上的
kubelet 执行了自注册操作之后,控制面会检查新的 Node 对象是否合法。
例如,如果你尝试使用下面的 JSON 对象来创建 Node 对象:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes 会在内部创建一个 Node 对象作为节点的表示。Kubernetes 检查 kubelet
向 API 服务器注册节点时使用的 metadata.name 字段是否匹配。
如果节点是健康的(即所有必要的服务都在运行中),则该节点可以用来运行 Pod。
否则,直到该节点变为健康之前,所有的集群活动都会忽略该节点。
说明:
Kubernetes 会一直保存着非法节点对应的对象,并持续检查该节点是否已经变得健康。
你,或者某个控制器必须显式地删除该 Node 对象以停止健康检查操作。
Node 对象的名称必须是合法的 DNS 子域名。
节点名称唯一性
节点的名称用来标识 Node 对象。 没有两个 Node 可以同时使用相同的名称。 Kubernetes 还假定名字相同的资源是同一个对象。 就 Node 而言,隐式假定使用相同名称的实例会具有相同的状态(例如网络配置、根磁盘内容) 和类似节点标签这类属性。这可能在节点被更改但其名称未变时导致系统状态不一致。 如果某个 Node 需要被替换或者大量变更,需要从 API 服务器移除现有的 Node 对象, 之后再在更新之后重新将其加入。
节点自注册
当 kubelet 标志 --register-node 为 true(默认)时,它会尝试向 API 服务注册自己。
这是首选模式,被绝大多数发行版选用。
对于自注册模式,kubelet 使用下列参数启动:
--kubeconfig- 用于向 API 服务器执行身份认证所用的凭据的路径。--cloud-provider- 与某云驱动 进行通信以读取与自身相关的元数据的方式。--register-node- 自动向 API 服务器注册。--register-with-taints- 使用所给的污点列表 (逗号分隔的<key>=<value>:<effect>)注册节点。当register-node为 false 时无效。
-
--node-ip- 可选的以英文逗号隔开的节点 IP 地址列表。你只能为每个地址簇指定一个地址。 例如在单协议栈 IPv4 集群中,需要将此值设置为 kubelet 应使用的节点 IPv4 地址。 参阅配置 IPv4/IPv6 双协议栈了解运行双协议栈集群的详情。如果你未提供这个参数,kubelet 将使用节点默认的 IPv4 地址(如果有); 如果节点没有 IPv4 地址,则 kubelet 使用节点的默认 IPv6 地址。
--node-labels- 在集群中注册节点时要添加的标签。 (参见 NodeRestriction 准入控制插件所实施的标签限制)。--node-status-update-frequency- 指定 kubelet 向 API 服务器发送其节点状态的频率。
当 Node 鉴权模式和 NodeRestriction 准入插件被启用后, 仅授权 kubelet 创建/修改自己的 Node 资源。
说明:
正如节点名称唯一性一节所述,当 Node 的配置需要被更新时,
一种好的做法是重新向 API 服务器注册该节点。例如,如果 kubelet 重启时其 --node-labels
是新的值集,但同一个 Node 名称已经被使用,则所作变更不会起作用,
因为节点标签是在 Node 注册时完成的。
如果在 kubelet 重启期间 Node 配置发生了变化,已经被调度到某 Node 上的 Pod 可能会出现行为不正常或者出现其他问题,例如,已经运行的 Pod 可能通过污点机制设置了与 Node 上新设置的标签相排斥的规则,也有一些其他 Pod, 本来与此 Pod 之间存在不兼容的问题,也会因为新的标签设置而被调到同一节点。 节点重新注册操作可以确保节点上所有 Pod 都被排空并被正确地重新调度。
手动节点管理
你可以使用 kubectl 来创建和修改 Node 对象。
如果你希望手动创建节点对象时,请设置 kubelet 标志 --register-node=false。
你可以修改 Node 对象(忽略 --register-node 设置)。
例如,你可以修改节点上的标签或并标记其为不可调度。
你可以结合使用 Node 上的标签和 Pod 上的选择算符来控制调度。 例如,你可以限制某 Pod 只能在符合要求的节点子集上运行。
如果标记节点为不可调度(unschedulable),将阻止新 Pod 调度到该 Node 之上, 但不会影响任何已经在其上的 Pod。 这是重启节点或者执行其他维护操作之前的一个有用的准备步骤。
要标记一个 Node 为不可调度,执行以下命令:
kubectl cordon $NODENAME
更多细节参考安全地腾空节点。
说明:
被 DaemonSet 控制器创建的 Pod 能够容忍节点的不可调度属性。 DaemonSet 通常提供节点本地的服务,即使节点上的负载应用已经被腾空, 这些服务也仍需运行在节点之上。
节点状态
一个节点的状态包含以下信息:
你可以使用 kubectl 来查看节点状态和其他细节信息:
kubectl describe node <节点名称>
更多细节参见 Node Status。
节点心跳
Kubernetes 节点发送的心跳帮助你的集群确定每个节点的可用性,并在检测到故障时采取行动。
对于节点,有两种形式的心跳:
节点控制器
节点控制器是 Kubernetes 控制面组件, 管理节点的方方面面。
节点控制器在节点的生命周期中扮演多个角色。 第一个是当节点注册时为它分配一个 CIDR 区段(如果启用了 CIDR 分配)。
第二个是保持节点控制器内的节点列表与云服务商所提供的可用机器列表同步。 如果在云环境下运行,只要某节点不健康,节点控制器就会询问云服务是否节点的虚拟机仍可用。 如果不可用,节点控制器会将该节点从它的节点列表删除。
第三个是监控节点的健康状况。节点控制器负责:
- 在节点不可达的情况下,在 Node 的
.status中更新Ready状况。 在这种情况下,节点控制器将 NodeReady 状况更新为Unknown。 - 如果节点仍然无法访问:对于不可达节点上的所有 Pod 触发
API 发起的逐出操作。
默认情况下,节点控制器在将节点标记为
Unknown后等待 5 分钟提交第一个驱逐请求。
默认情况下,节点控制器每 5 秒检查一次节点状态,可以使用 kube-controller-manager
组件上的 --node-monitor-period 参数来配置周期。
逐出速率限制
大部分情况下,节点控制器把逐出速率限制在每秒 --node-eviction-rate 个(默认为 0.1)。
这表示它每 10 秒钟内至多从一个节点驱逐 Pod。
当一个可用区域(Availability Zone)中的节点变为不健康时,节点的驱逐行为将发生改变。
节点控制器会同时检查可用区域中不健康(Ready 状况为 Unknown 或 False)
的节点的百分比:
- 如果不健康节点的比例超过
--unhealthy-zone-threshold(默认为 0.55), 驱逐速率将会降低。 - 如果集群较小(意即小于等于
--large-cluster-size-threshold个节点 - 默认为 50), 驱逐操作将会停止。 - 否则驱逐速率将降为每秒
--secondary-node-eviction-rate个(默认为 0.01)。
在逐个可用区域中实施这些策略的原因是, 当一个可用区域可能从控制面脱离时其它可用区域可能仍然保持连接。 如果你的集群没有跨越云服务商的多个可用区域,那(整个集群)就只有一个可用区域。
跨多个可用区域部署你的节点的一个关键原因是当某个可用区域整体出现故障时,
工作负载可以转移到健康的可用区域。
因此,如果一个可用区域中的所有节点都不健康时,节点控制器会以正常的速率
--node-eviction-rate 进行驱逐操作。
在所有的可用区域都不健康(也即集群中没有健康节点)的极端情况下,
节点控制器将假设控制面与节点间的连接出了某些问题,它将停止所有驱逐动作
(如果故障后部分节点重新连接,节点控制器会从剩下不健康或者不可达节点中驱逐 Pod)。
节点控制器还负责驱逐运行在拥有 NoExecute 污点的节点上的 Pod,
除非这些 Pod 能够容忍此污点。
节点控制器还负责根据节点故障(例如节点不可访问或没有就绪)
为其添加污点。
这意味着调度器不会将 Pod 调度到不健康的节点上。
资源容量跟踪
Node 对象会跟踪节点上资源的容量(例如可用内存和 CPU 数量)。 通过自注册机制生成的 Node 对象会在注册期间报告自身容量。 如果你手动添加了 Node, 你就需要在添加节点时手动设置节点容量。
Kubernetes 调度器
保证节点上有足够的资源供其上的所有 Pod 使用。
它会检查节点上所有容器的请求的总和不会超过节点的容量。
总的请求包括由 kubelet 启动的所有容器,但不包括由容器运行时直接启动的容器,
也不包括不受 kubelet 控制的其他进程。
说明:
如果要为非 Pod 进程显式保留资源。 请参考为系统守护进程预留资源。
节点拓扑
特性状态:
Kubernetes v1.27 [stable]
如果启用了 TopologyManager 特性门控,
kubelet 可以在作出资源分配决策时使用拓扑提示。
参考控制节点上拓扑管理策略了解详细信息。
节点体面关闭
特性状态:
Kubernetes v1.21 [beta]
kubelet 会尝试检测节点系统关闭事件并终止在节点上运行的所有 Pod。
在节点终止期间,kubelet 保证 Pod 遵从常规的 Pod 终止流程, 且不接受新的 Pod(即使这些 Pod 已经绑定到该节点)。
节点体面关闭特性依赖于 systemd,因为它要利用 systemd 抑制器锁机制, 在给定的期限内延迟节点关闭。
节点体面关闭特性受 GracefulNodeShutdown
特性门控控制,
在 1.21 版本中是默认启用的。
注意,默认情况下,下面描述的两个配置选项,shutdownGracePeriod 和
shutdownGracePeriodCriticalPods 都是被设置为 0 的,因此不会激活节点体面关闭功能。
要激活此功能特性,这两个 kubelet 配置选项要适当配置,并设置为非零值。
一旦 systemd 检测到或通知节点关闭,kubelet 就会在节点上设置一个
NotReady 状况,并将 reason 设置为 "node is shutting down"。
kube-scheduler 会重视此状况,不将 Pod 调度到受影响的节点上;
其他第三方调度程序也应当遵循相同的逻辑。这意味着新的 Pod 不会被调度到该节点上,
因此不会有新 Pod 启动。
如果检测到节点关闭过程正在进行中,kubelet 也会在 PodAdmission
阶段拒绝 Pod,即使是该 Pod 带有 node.kubernetes.io/not-ready:NoSchedule
的容忍度。
同时,当 kubelet 通过 API 在其 Node 上设置该状况时,kubelet 也开始终止在本地运行的所有 Pod。
在体面关闭节点过程中,kubelet 分两个阶段来终止 Pod:
- 终止在节点上运行的常规 Pod。
- 终止在节点上运行的关键 Pod。
节点体面关闭的特性对应两个
KubeletConfiguration 选项:
shutdownGracePeriod:- 指定节点应延迟关闭的总持续时间。此时间是 Pod 体面终止的时间总和,不区分常规 Pod 还是关键 Pod。
shutdownGracePeriodCriticalPods:- 在节点关闭期间指定用于终止关键 Pod
的持续时间。该值应小于
shutdownGracePeriod。
- 在节点关闭期间指定用于终止关键 Pod
的持续时间。该值应小于
说明:
在某些情况下,节点终止过程会被系统取消(或者可能由管理员手动取消)。
无论哪种情况下,节点都将返回到 Ready 状态。然而,已经开始终止进程的
Pod 将不会被 kubelet 恢复,需要被重新调度。
例如,如果设置了 shutdownGracePeriod=30s 和 shutdownGracePeriodCriticalPods=10s,
则 kubelet 将延迟 30 秒关闭节点。
在关闭期间,将保留前 20(30 - 10)秒用于体面终止常规 Pod,
而保留最后 10 秒用于终止关键 Pod。
说明:
当 Pod 在正常节点关闭期间被驱逐时,它们会被标记为关闭。
运行 kubectl get pods 时,被驱逐的 Pod 的状态显示为 Terminated。
并且 kubectl describe pod 表示 Pod 因节点关闭而被驱逐:
Reason: Terminated
Message: Pod was terminated in response to imminent node shutdown.
基于 Pod 优先级的节点体面关闭
特性状态:
Kubernetes v1.24 [beta]
为了在节点体面关闭期间提供更多的灵活性,尤其是处理关闭期间的 Pod 排序问题, 节点体面关闭机制能够关注 Pod 的 PriorityClass 设置,前提是你已经在集群中启用了此功能特性。 此功能特性允许集群管理员基于 Pod 的优先级类(Priority Class) 显式地定义节点体面关闭期间 Pod 的处理顺序。
前文所述的节点体面关闭特性能够分两个阶段关闭 Pod, 首先关闭的是非关键的 Pod,之后再处理关键 Pod。 如果需要显式地以更细粒度定义关闭期间 Pod 的处理顺序,需要一定的灵活度, 这时可以使用基于 Pod 优先级的体面关闭机制。
当节点体面关闭能够处理 Pod 优先级时,节点体面关闭的处理可以分为多个阶段, 每个阶段关闭特定优先级类的 Pod。kubelet 可以被配置为按确切的阶段处理 Pod, 且每个阶段可以独立设置关闭时间。
假设集群中存在以下自定义的 Pod 优先级类。
| Pod 优先级类名称 | Pod 优先级类数值 |
|---|---|
custom-class-a |
100000 |
custom-class-b |
10000 |
custom-class-c |
1000 |
regular/unset |
0 |
在 kubelet 配置中,
shutdownGracePeriodByPodPriority 可能看起来是这样:
| Pod 优先级类数值 | 关闭期限 |
|---|---|
| 100000 | 10 秒 |
| 10000 | 180 秒 |
| 1000 | 120 秒 |
| 0 | 60 秒 |
对应的 kubelet 配置 YAML 将会是:
shutdownGracePeriodByPodPriority:
- priority: 100000
shutdownGracePeriodSeconds: 10
- priority: 10000
shutdownGracePeriodSeconds: 180
- priority: 1000
shutdownGracePeriodSeconds: 120
- priority: 0
shutdownGracePeriodSeconds: 60
上面的表格表明,所有 priority 值大于等于 100000 的 Pod 会得到 10 秒钟期限停止,
所有 priority 值介于 10000 和 100000 之间的 Pod 会得到 180 秒钟期限停止,
所有 priority 值介于 1000 和 10000 之间的 Pod 会得到 120 秒钟期限停止,
所有其他 Pod 将获得 60 秒的时间停止。
用户不需要为所有的优先级类都设置数值。例如,你也可以使用下面这种配置:
| Pod 优先级类数值 | 关闭期限 |
|---|---|
| 100000 | 300 秒 |
| 1000 | 120 秒 |
| 0 | 60 秒 |
在上面这个场景中,优先级类为 custom-class-b 的 Pod 会与优先级类为 custom-class-c
的 Pod 在关闭时按相同期限处理。
如果在特定的范围内不存在 Pod,则 kubelet 不会等待对应优先级范围的 Pod。 kubelet 会直接跳到下一个优先级数值范围进行处理。
如果此功能特性被启用,但没有提供配置数据,则不会出现排序操作。
使用此功能特性需要启用 GracefulNodeShutdownBasedOnPodPriority
特性门控,
并将 kubelet 配置
中的 shutdownGracePeriodByPodPriority 设置为期望的配置,
其中包含 Pod 的优先级类数值以及对应的关闭期限。
说明:
在节点体面关闭期间考虑 Pod 优先级的能力是作为 Kubernetes v1.23 中的 Alpha 功能引入的。 在 Kubernetes 1.29 中该功能是 Beta 版,默认启用。
kubelet 子系统中会生成 graceful_shutdown_start_time_seconds 和
graceful_shutdown_end_time_seconds 度量指标以便监视节点关闭行为。
处理节点非体面关闭
特性状态:
Kubernetes v1.28 [stable]
节点关闭的操作可能无法被 kubelet 的节点关闭管理器检测到, 是因为该命令不会触发 kubelet 所使用的抑制锁定机制,或者是因为用户错误的原因, 即 ShutdownGracePeriod 和 ShutdownGracePeriodCriticalPod 配置不正确。 请参考以上节点体面关闭部分了解更多详细信息。
当某节点关闭但 kubelet 的节点关闭管理器未检测到这一事件时, 在那个已关闭节点上、属于 StatefulSet 的 Pod 将停滞于终止状态,并且不能移动到新的运行节点上。 这是因为已关闭节点上的 kubelet 已不存在,亦无法删除 Pod, 因此 StatefulSet 无法创建同名的新 Pod。 如果 Pod 使用了卷,则 VolumeAttachments 不会从原来的已关闭节点上删除, 因此这些 Pod 所使用的卷也无法挂接到新的运行节点上。 所以,那些以 StatefulSet 形式运行的应用无法正常工作。 如果原来的已关闭节点被恢复,kubelet 将删除 Pod,新的 Pod 将被在不同的运行节点上创建。 如果原来的已关闭节点没有被恢复,那些在已关闭节点上的 Pod 将永远滞留在终止状态。
为了缓解上述情况,用户可以手动将具有 NoExecute 或 NoSchedule 效果的
node.kubernetes.io/out-of-service 污点添加到节点上,标记其无法提供服务。
如果在 kube-controller-manager
上启用了 NodeOutOfServiceVolumeDetach
特性门控,
并且节点被通过污点标记为无法提供服务,如果节点 Pod 上没有设置对应的容忍度,
那么这样的 Pod 将被强制删除,并且该在节点上被终止的 Pod 将立即进行卷分离操作。
这样就允许那些在无法提供服务节点上的 Pod 能在其他节点上快速恢复。
在非体面关闭期间,Pod 分两个阶段终止:
- 强制删除没有匹配的
out-of-service容忍度的 Pod。 - 立即对此类 Pod 执行分离卷操作。
说明:
- 在添加
node.kubernetes.io/out-of-service污点之前, 应该验证节点已经处于关闭或断电状态(而不是在重新启动中)。 - 将 Pod 移动到新节点后,用户需要手动移除停止服务的污点, 并且用户要检查关闭节点是否已恢复,因为该用户是最初添加污点的用户。
交换内存管理
特性状态:
Kubernetes v1.28 [beta]
要在节点上启用交换内存,必须启用 kubelet 的 NodeSwap 特性门控,
同时使用 --fail-swap-on 命令行参数或者将 failSwapOn
配置设置为 false。
警告:
当内存交换功能被启用后,Kubernetes 数据(如写入 tmpfs 的 Secret 对象的内容)可以被交换到磁盘。
用户还可以选择配置 memorySwap.swapBehavior 以指定节点使用交换内存的方式。例如:
memorySwap:
swapBehavior: UnlimitedSwap
UnlimitedSwap(默认):Kubernetes 工作负载可以根据请求使用尽可能多的交换内存, 一直到达到系统限制为止。LimitedSwap:Kubernetes 工作负载对交换内存的使用受到限制。 只有具有 Burstable QoS 的 Pod 可以使用交换空间。
如果启用了特性门控但是未指定 memorySwap 的配置,默认情况下 kubelet 将使用与
UnlimitedSwap 设置相同的行为。
采用 LimitedSwap 时,不属于 Burstable QoS 分类的 Pod
(即 BestEffort/Guaranteed QoS Pod)
被禁止使用交换内存。为了保持上述的安全性和节点健康性保证,
在 LimitedSwap 生效时,不允许这些 Pod 使用交换内存。
在详细介绍交换限制的计算之前,有必要定义以下术语:
nodeTotalMemory:节点上可用的物理内存总量。totalPodsSwapAvailable:节点上可供 Pod 使用的交换内存总量 (一些交换内存可能被保留由系统使用)。containerMemoryRequest:容器的内存请求。
交换限制被配置为 (containerMemoryRequest / nodeTotalMemory) * totalPodsSwapAvailable 的值。
需要注意的是,位于 Burstable QoS Pod 中的容器可以通过将内存请求设置为与内存限制相同来选择不使用交换空间。 以这种方式配置的容器将无法访问交换内存。
只有 Cgroup v2 支持交换空间,Cgroup v1 不支持。
如需了解更多信息、协助测试和提交反馈,请参阅关于 Kubernetes 1.28:NodeSwap 进阶至 Beta1 的博客文章、 KEP-2400 及其设计提案。
接下来
进一步了解以下资料:
- 构成节点的组件。
- Node 的 API 定义。
- 架构设计文档中有关 Node 的章节。
- 污点和容忍度。
- 节点资源管理器。
- Windows 节点的资源管理。
2.2 - 节点与控制面之间的通信
本文列举控制面节点(确切地说是 API 服务器)和 Kubernetes 集群之间的通信路径。 目的是为了让用户能够自定义他们的安装,以实现对网络配置的加固, 使得集群能够在不可信的网络上(或者在一个云服务商完全公开的 IP 上)运行。
节点到控制面
Kubernetes 采用的是中心辐射型(Hub-and-Spoke)API 模式。 所有从节点(或运行于其上的 Pod)发出的 API 调用都终止于 API 服务器。 其它控制面组件都没有被设计为可暴露远程服务。 API 服务器被配置为在一个安全的 HTTPS 端口(通常为 443)上监听远程连接请求, 并启用一种或多种形式的客户端身份认证机制。 一种或多种客户端鉴权机制应该被启用, 特别是在允许使用匿名请求 或服务账户令牌的时候。
应该使用集群的公共根证书开通节点, 这样它们就能够基于有效的客户端凭据安全地连接 API 服务器。 一种好的方法是以客户端证书的形式将客户端凭据提供给 kubelet。 请查看 kubelet TLS 启动引导 以了解如何自动提供 kubelet 客户端证书。
想要连接到 API 服务器的 Pod
可以使用服务账号安全地进行连接。
当 Pod 被实例化时,Kubernetes 自动把公共根证书和一个有效的持有者令牌注入到 Pod 里。
kubernetes 服务(位于 default 名字空间中)配置了一个虚拟 IP 地址,
用于(通过 kube-proxy)转发请求到
API 服务器的 HTTPS 末端。
控制面组件也通过安全端口与集群的 API 服务器通信。
这样,从集群节点和节点上运行的 Pod 到控制面的连接的缺省操作模式即是安全的, 能够在不可信的网络或公网上运行。
控制面到节点
从控制面(API 服务器)到节点有两种主要的通信路径。 第一种是从 API 服务器到集群中每个节点上运行的 kubelet 进程。 第二种是从 API 服务器通过它的代理功能连接到任何节点、Pod 或者服务。
API 服务器到 kubelet
从 API 服务器到 kubelet 的连接用于:
- 获取 Pod 日志。
- 挂接(通过 kubectl)到运行中的 Pod。
- 提供 kubelet 的端口转发功能。
这些连接终止于 kubelet 的 HTTPS 末端。 默认情况下,API 服务器不检查 kubelet 的服务证书。这使得此类连接容易受到中间人攻击, 在非受信网络或公开网络上运行也是 不安全的。
为了对这个连接进行认证,使用 --kubelet-certificate-authority 标志给
API 服务器提供一个根证书包,用于 kubelet 的服务证书。
如果无法实现这点,又要求避免在非受信网络或公共网络上进行连接,可在 API 服务器和 kubelet 之间使用 SSH 隧道。
最后,应该启用 Kubelet 认证/鉴权 来保护 kubelet API。
API 服务器到节点、Pod 和服务
从 API 服务器到节点、Pod 或服务的连接默认为纯 HTTP 方式,因此既没有认证,也没有加密。
这些连接可通过给 API URL 中的节点、Pod 或服务名称添加前缀 https: 来运行在安全的 HTTPS 连接上。
不过这些连接既不会验证 HTTPS 末端提供的证书,也不会提供客户端证书。
因此,虽然连接是加密的,仍无法提供任何完整性保证。
这些连接 目前还不能安全地 在非受信网络或公共网络上运行。
SSH 隧道
Kubernetes 支持使用 SSH 隧道来保护从控制面到节点的通信路径。 在这种配置下,API 服务器建立一个到集群中各节点的 SSH 隧道(连接到在 22 端口监听的 SSH 服务器) 并通过这个隧道传输所有到 kubelet、节点、Pod 或服务的请求。 这一隧道保证通信不会被暴露到集群节点所运行的网络之外。
说明:
SSH 隧道目前已被废弃。除非你了解个中细节,否则不应使用。 Konnectivity 服务是 SSH 隧道的替代方案。
Konnectivity 服务
特性状态:
Kubernetes v1.18 [beta]
作为 SSH 隧道的替代方案,Konnectivity 服务提供 TCP 层的代理,以便支持从控制面到集群的通信。 Konnectivity 服务包含两个部分:Konnectivity 服务器和 Konnectivity 代理, 分别运行在控制面网络和节点网络中。 Konnectivity 代理建立并维持到 Konnectivity 服务器的网络连接。 启用 Konnectivity 服务之后,所有控制面到节点的通信都通过这些连接传输。
请浏览 Konnectivity 服务任务 在你的集群中配置 Konnectivity 服务。
接下来
- 阅读 Kubernetes 控制面组件
- 进一步了解 Hubs and Spoke model
- 进一步了解如何保护集群
- 进一步了解 Kubernetes API
- 设置 Konnectivity 服务
- 使用端口转发来访问集群中的应用
- 学习如何检查 Pod 的日志 以及如何使用 kubectl 端口转发
2.3 - 控制器
在机器人技术和自动化领域,控制回路(Control Loop)是一个非终止回路,用于调节系统状态。
这是一个控制环的例子:房间里的温度自动调节器。
当你设置了温度,告诉了温度自动调节器你的期望状态(Desired State)。 房间的实际温度是当前状态(Current State)。 通过对设备的开关控制,温度自动调节器让其当前状态接近期望状态。
在 Kubernetes 中,控制器通过监控集群 的公共状态,并致力于将当前状态转变为期望的状态。控制器模式
一个控制器至少追踪一种类型的 Kubernetes 资源。这些
对象
有一个代表期望状态的 spec 字段。
该资源的控制器负责确保其当前状态接近期望状态。
控制器可能会自行执行操作;在 Kubernetes 中更常见的是一个控制器会发送信息给 API 服务器,这会有副作用。 具体可参看后文的例子。
通过 API 服务器来控制
Job 控制器是一个 Kubernetes 内置控制器的例子。 内置控制器通过和集群 API 服务器交互来管理状态。
Job 是一种 Kubernetes 资源,它运行一个或者多个 Pod,
来执行一个任务然后停止。
(一旦被调度了,对 kubelet 来说 Pod
对象就会变成期望状态的一部分)。
在集群中,当 Job 控制器拿到新任务时,它会保证一组 Node 节点上的 kubelet
可以运行正确数量的 Pod 来完成工作。
Job 控制器不会自己运行任何的 Pod 或者容器。Job 控制器是通知 API 服务器来创建或者移除 Pod。
控制面中的其它组件
根据新的消息作出反应(调度并运行新 Pod)并且最终完成工作。
创建新 Job 后,所期望的状态就是完成这个 Job。Job 控制器会让 Job 的当前状态不断接近期望状态:创建为 Job 要完成工作所需要的 Pod,使 Job 的状态接近完成。
控制器也会更新配置对象。例如:一旦 Job 的工作完成了,Job 控制器会更新 Job 对象的状态为 Finished。
(这有点像温度自动调节器关闭了一个灯,以此来告诉你房间的温度现在到你设定的值了)。
直接控制
相比 Job 控制器,有些控制器需要对集群外的一些东西进行修改。
例如,如果你使用一个控制回路来保证集群中有足够的 节点,那么控制器就需要当前集群外的 一些服务在需要时创建新节点。
和外部状态交互的控制器从 API 服务器获取到它想要的状态,然后直接和外部系统进行通信 并使当前状态更接近期望状态。
(实际上有一个控制器 可以水平地扩展集群中的节点。)
这里的重点是,控制器做出了一些变更以使得事物更接近你的期望状态, 之后将当前状态报告给集群的 API 服务器。 其他控制回路可以观测到所汇报的数据的这种变化并采取其各自的行动。
在温度计的例子中,如果房间很冷,那么某个控制器可能还会启动一个防冻加热器。 就 Kubernetes 集群而言,控制面间接地与 IP 地址管理工具、存储服务、云驱动 APIs 以及其他服务协作,通过扩展 Kubernetes 来实现这点。
期望状态与当前状态
Kubernetes 采用了系统的云原生视图,并且可以处理持续的变化。
在任务执行时,集群随时都可能被修改,并且控制回路会自动修复故障。 这意味着很可能集群永远不会达到稳定状态。
只要集群中的控制器在运行并且进行有效的修改,整体状态的稳定与否是无关紧要的。
设计
作为设计原则之一,Kubernetes 使用了很多控制器,每个控制器管理集群状态的一个特定方面。 最常见的一个特定的控制器使用一种类型的资源作为它的期望状态, 控制器管理控制另外一种类型的资源向它的期望状态演化。 例如,Job 的控制器跟踪 Job 对象(以发现新的任务)和 Pod 对象(以运行 Job,然后查看任务何时完成)。 在这种情况下,新任务会创建 Job,而 Job 控制器会创建 Pod。
使用简单的控制器而不是一组相互连接的单体控制回路是很有用的。 控制器会失败,所以 Kubernetes 的设计正是考虑到了这一点。
说明:
可以有多个控制器来创建或者更新相同类型的对象。 在后台,Kubernetes 控制器确保它们只关心与其控制资源相关联的资源。
例如,你可以创建 Deployment 和 Job;它们都可以创建 Pod。 Job 控制器不会删除 Deployment 所创建的 Pod,因为有信息 (标签)让控制器可以区分这些 Pod。
运行控制器的方式
Kubernetes 内置一组控制器,运行在 kube-controller-manager 内。 这些内置的控制器提供了重要的核心功能。
Deployment 控制器和 Job 控制器是 Kubernetes 内置控制器的典型例子。 Kubernetes 允许你运行一个稳定的控制平面,这样即使某些内置控制器失败了, 控制平面的其他部分会接替它们的工作。
你会遇到某些控制器运行在控制面之外,用以扩展 Kubernetes。 或者,如果你愿意,你也可以自己编写新控制器。 你可以以一组 Pod 来运行你的控制器,或者运行在 Kubernetes 之外。 最合适的方案取决于控制器所要执行的功能是什么。
接下来
- 阅读 Kubernetes 控制平面组件
- 了解 Kubernetes 对象 的一些基本知识
- 进一步学习 Kubernetes API
- 如果你想编写自己的控制器,请查看 Kubernetes 扩展模式 以及控制器样例。
2.4 - 租约(Lease)
分布式系统通常需要租约(Lease);租约提供了一种机制来锁定共享资源并协调集合成员之间的活动。
在 Kubernetes 中,租约概念表示为 coordination.k8s.io
API 组中的
Lease 对象,
常用于类似节点心跳和组件级领导者选举等系统核心能力。
节点心跳
Kubernetes 使用 Lease API 将 kubelet 节点心跳传递到 Kubernetes API 服务器。
对于每个 Node,在 kube-node-lease 名字空间中都有一个具有匹配名称的 Lease 对象。
在此基础上,每个 kubelet 心跳都是对该 Lease 对象的 update 请求,更新该 Lease 的 spec.renewTime 字段。
Kubernetes 控制平面使用此字段的时间戳来确定此 Node 的可用性。
更多细节请参阅 Node Lease 对象。
领导者选举
Kubernetes 也使用 Lease 确保在任何给定时间某个组件只有一个实例在运行。
这在高可用配置中由 kube-controller-manager 和 kube-scheduler 等控制平面组件进行使用,
这些组件只应有一个实例激活运行,而其他实例待机。
API 服务器身份
特性状态:
Kubernetes v1.26 [beta]
从 Kubernetes v1.26 开始,每个 kube-apiserver 都使用 Lease API 将其身份发布到系统中的其他位置。
虽然它本身并不是特别有用,但为客户端提供了一种机制来发现有多少个 kube-apiserver 实例正在操作
Kubernetes 控制平面。kube-apiserver 租约的存在使得未来可以在各个 kube-apiserver 之间协调新的能力。
你可以检查 kube-system 名字空间中名为 kube-apiserver-<sha256-hash> 的 Lease 对象来查看每个
kube-apiserver 拥有的租约。你还可以使用标签选择算符 apiserver.kubernetes.io/identity=kube-apiserver:
kubectl -n kube-system get lease -l apiserver.kubernetes.io/identity=kube-apiserver
NAME HOLDER AGE
apiserver-07a5ea9b9b072c4a5f3d1c3702 apiserver-07a5ea9b9b072c4a5f3d1c3702_0c8914f7-0f35-440e-8676-7844977d3a05 5m33s
apiserver-7be9e061c59d368b3ddaf1376e apiserver-7be9e061c59d368b3ddaf1376e_84f2a85d-37c1-4b14-b6b9-603e62e4896f 4m23s
apiserver-1dfef752bcb36637d2763d1868 apiserver-1dfef752bcb36637d2763d1868_c5ffa286-8a9a-45d4-91e7-61118ed58d2e 4m43s
租约名称中使用的 SHA256 哈希基于 API 服务器所看到的操作系统主机名生成。
每个 kube-apiserver 都应该被配置为使用集群中唯一的主机名。
使用相同主机名的 kube-apiserver 新实例将使用新的持有者身份接管现有 Lease,而不是实例化新的 Lease 对象。
你可以通过检查 kubernetes.io/hostname 标签的值来查看 kube-apisever 所使用的主机名:
kubectl -n kube-system get lease apiserver-07a5ea9b9b072c4a5f3d1c3702 -o yaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: "2023-07-02T13:16:48Z"
labels:
apiserver.kubernetes.io/identity: kube-apiserver
kubernetes.io/hostname: master-1
name: apiserver-07a5ea9b9b072c4a5f3d1c3702
namespace: kube-system
resourceVersion: "334899"
uid: 90870ab5-1ba9-4523-b215-e4d4e662acb1
spec:
holderIdentity: apiserver-07a5ea9b9b072c4a5f3d1c3702_0c8914f7-0f35-440e-8676-7844977d3a05
leaseDurationSeconds: 3600
renewTime: "2023-07-04T21:58:48.065888Z"
kube-apiserver 中不再存续的已到期租约将在到期 1 小时后被新的 kube-apiserver 作为垃圾收集。
你可以通过禁用 APIServerIdentity
特性门控来禁用 API 服务器身份租约。
工作负载
你自己的工作负载可以定义自己使用的 Lease。例如,
你可以运行自定义的控制器,
让主要成员或领导者成员在其中执行其对等方未执行的操作。
你定义一个 Lease,以便控制器副本可以使用 Kubernetes API 进行协调以选择或选举一个领导者。
如果你使用 Lease,良好的做法是为明显关联到产品或组件的 Lease 定义一个名称。
例如,如果你有一个名为 Example Foo 的组件,可以使用名为 example-foo 的 Lease。
如果集群操作员或其他终端用户可以部署一个组件的多个实例, 则选择名称前缀并挑选一种机制(例如 Deployment 名称的哈希)以避免 Lease 的名称冲突。
你可以使用另一种方式来达到相同的效果:不同的软件产品不相互冲突。
2.5 - 云控制器管理器
特性状态:
Kubernetes v1.11 [beta]
使用云基础设施技术,你可以在公有云、私有云或者混合云环境中运行 Kubernetes。 Kubernetes 的信条是基于自动化的、API 驱动的基础设施,同时避免组件间紧密耦合。
组件 cloud-controller-manager 是指云控制器管理器, 一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager) 允许将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
通过分离 Kubernetes 和底层云基础设置之间的互操作性逻辑,
cloud-controller-manager 组件使云提供商能够以不同于 Kubernetes 主项目的步调发布新特征。
cloud-controller-manager 组件是基于一种插件机制来构造的,
这种机制使得不同的云厂商都能将其平台与 Kubernetes 集成。
设计

云控制器管理器以一组多副本的进程集合的形式运行在控制面中,通常表现为 Pod
中的容器。每个 cloud-controller-manager
在同一进程中实现多个控制器。
说明:
你也可以用 Kubernetes 插件 的形式而不是控制面中的一部分来运行云控制器管理器。
云控制器管理器的功能
云控制器管理器中的控制器包括:
节点控制器
节点控制器负责在云基础设施中创建了新服务器时为之更新节点(Node)对象。 节点控制器从云提供商获取当前租户中主机的信息。节点控制器执行以下功能:
- 使用从云平台 API 获取的对应服务器的唯一标识符更新 Node 对象;
- 利用特定云平台的信息为 Node 对象添加注解和标签,例如节点所在的区域 (Region)和所具有的资源(CPU、内存等等);
- 获取节点的网络地址和主机名;
- 检查节点的健康状况。如果节点无响应,控制器通过云平台 API 查看该节点是否已从云中禁用、删除或终止。如果节点已从云中删除, 则控制器从 Kubernetes 集群中删除 Node 对象。
某些云驱动实现中,这些任务被划分到一个节点控制器和一个节点生命周期控制器中。
路由控制器
Route 控制器负责适当地配置云平台中的路由,以便 Kubernetes 集群中不同节点上的容器之间可以相互通信。
取决于云驱动本身,路由控制器可能也会为 Pod 网络分配 IP 地址块。
服务控制器
服务(Service)与受控的负载均衡器、 IP 地址、网络包过滤、目标健康检查等云基础设施组件集成。 服务控制器与云驱动的 API 交互,以配置负载均衡器和其他基础设施组件。 你所创建的 Service 资源会需要这些组件服务。
鉴权
本节分别讲述云控制器管理器为了完成自身工作而产生的对各类 API 对象的访问需求。
节点控制器
节点控制器只操作 Node 对象。它需要读取和修改 Node 对象的完全访问权限。
v1/Node:
- get
- list
- create
- update
- patch
- watch
- delete
路由控制器
路由控制器会监听 Node 对象的创建事件,并据此配置路由设施。 它需要读取 Node 对象的 Get 权限。
v1/Node:
- get
服务控制器
服务控制器监测 Service 对象的 create、update 和 delete 事件, 并配置对应服务的 Endpoints 对象 (对于 EndpointSlices,kube-controller-manager 按需对其进行管理)。
为了访问 Service 对象,它需要 list 和 watch 访问权限。 为了更新 Service 对象,它需要 patch 和 update 访问权限。
为了能够配置 Service 对应的 Endpoints 资源, 它需要 create、list、get、watch 和 update 等访问权限。
v1/Service:
- list
- get
- watch
- patch
- update
其他
在云控制器管理器的实现中,其核心部分需要创建 Event 对象的访问权限, 并创建 ServiceAccount 资源以保证操作安全性的权限。
v1/Event:
- create
- patch
- update
v1/ServiceAccount:
- create
用于云控制器管理器 RBAC 的 ClusterRole 如下例所示:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
接下来
-
云控制器管理器的管理 给出了运行和管理云控制器管理器的指南。
-
要升级 HA 控制平面以使用云控制器管理器, 请参见将复制的控制平面迁移以使用云控制器管理器。
-
想要了解如何实现自己的云控制器管理器,或者对现有项目进行扩展么?
- 云控制器管理器使用 Go 语言的接口(具体指在
kubernetes/cloud-provider
项目中
cloud.go文件中所定义的CloudProvider接口),从而使得针对各种云平台的具体实现都可以接入。
- 本文中列举的共享控制器(节点控制器、路由控制器和服务控制器等)的实现以及其他一些生成具有
CloudProvider 接口的框架的代码,都是 Kubernetes 的核心代码。
特定于云驱动的实现虽不是 Kubernetes 核心成分,仍要实现
CloudProvider接口。
- 关于如何开发插件的详细信息, 可参考开发云控制器管理器文档。
- 云控制器管理器使用 Go 语言的接口(具体指在
kubernetes/cloud-provider
项目中
2.6 - 关于 cgroup v2
在 Linux 上,控制组约束分配给进程的资源。
kubelet 和底层容器运行时都需要对接 cgroup 来强制执行为 Pod 和容器管理资源, 这包括为容器化工作负载配置 CPU/内存请求和限制。
Linux 中有两个 cgroup 版本:cgroup v1 和 cgroup v2。cgroup v2 是新一代的 cgroup API。
什么是 cgroup v2?
特性状态:
Kubernetes v1.25 [stable]
cgroup v2 是 Linux cgroup API 的下一个版本。cgroup v2 提供了一个具有增强资源管理能力的统一控制系统。
cgroup v2 对 cgroup v1 进行了多项改进,例如:
- API 中单个统一的层次结构设计
- 更安全的子树委派给容器
- 更新的功能特性, 例如压力阻塞信息(Pressure Stall Information,PSI)
- 跨多个资源的增强资源分配管理和隔离
- 统一核算不同类型的内存分配(网络内存、内核内存等)
- 考虑非即时资源变化,例如页面缓存回写
一些 Kubernetes 特性专门使用 cgroup v2 来增强资源管理和隔离。 例如,MemoryQoS 特性改进了内存 QoS 并依赖于 cgroup v2 原语。
使用 cgroup v2
使用 cgroup v2 的推荐方法是使用一个默认启用 cgroup v2 的 Linux 发行版。
要检查你的发行版是否使用 cgroup v2,请参阅识别 Linux 节点上的 cgroup 版本。
要求
cgroup v2 具有以下要求:
- 操作系统发行版启用 cgroup v2
- Linux 内核为 5.8 或更高版本
- 容器运行时支持 cgroup v2。例如:
- containerd v1.4 和更高版本
- cri-o v1.20 和更高版本
- kubelet 和容器运行时被配置为使用 systemd cgroup 驱动
Linux 发行版 cgroup v2 支持
有关使用 cgroup v2 的 Linux 发行版的列表, 请参阅 cgroup v2 文档。
- Container-Optimized OS(从 M97 开始)
- Ubuntu(从 21.10 开始,推荐 22.04+)
- Debian GNU/Linux(从 Debian 11 Bullseye 开始)
- Fedora(从 31 开始)
- Arch Linux(从 2021 年 4 月开始)
- RHEL 和类似 RHEL 的发行版(从 9 开始)
要检查你的发行版是否使用 cgroup v2, 请参阅你的发行版文档或遵循识别 Linux 节点上的 cgroup 版本中的指示说明。
你还可以通过修改内核 cmdline 引导参数在你的 Linux 发行版上手动启用 cgroup v2。
如果你的发行版使用 GRUB,则应在 /etc/default/grub 下的 GRUB_CMDLINE_LINUX
中添加 systemd.unified_cgroup_hierarchy=1,
然后执行 sudo update-grub。不过,推荐的方法仍是使用一个默认已启用 cgroup v2 的发行版。
迁移到 cgroup v2
要迁移到 cgroup v2,需确保满足要求,然后升级到一个默认启用 cgroup v2 的内核版本。
kubelet 能够自动检测操作系统是否运行在 cgroup v2 上并相应调整其操作,无需额外配置。
切换到 cgroup v2 时,用户体验应没有任何明显差异,除非用户直接在节点上或从容器内访问 cgroup 文件系统。
cgroup v2 使用一个与 cgroup v1 不同的 API,因此如果有任何应用直接访问 cgroup 文件系统, 则需要将这些应用更新为支持 cgroup v2 的版本。例如:
- 一些第三方监控和安全代理可能依赖于 cgroup 文件系统。你要将这些代理更新到支持 cgroup v2 的版本。
- 如果以独立的 DaemonSet 的形式运行 cAdvisor 以监控 Pod 和容器, 需将其更新到 v0.43.0 或更高版本。
- 如果你部署 Java 应用程序,最好使用完全支持 cgroup v2 的版本:
- OpenJDK / HotSpot: jdk8u372、11.0.16、15 及更高的版本
- IBM Semeru Runtimes: 8.0.382.0、11.0.20.0、17.0.8.0 及更高的版本
- IBM Java: 8.0.8.6 及更高的版本
- 如果你正在使用 uber-go/automaxprocs 包, 确保你使用的版本是 v1.5.1 或者更高。
识别 Linux 节点上的 cgroup 版本
cgroup 版本取决于正在使用的 Linux 发行版和操作系统上配置的默认 cgroup 版本。
要检查你的发行版使用的是哪个 cgroup 版本,请在该节点上运行 stat -fc %T /sys/fs/cgroup/ 命令:
stat -fc %T /sys/fs/cgroup/
对于 cgroup v2,输出为 cgroup2fs。
对于 cgroup v1,输出为 tmpfs。
接下来
2.7 - 容器运行时接口(CRI)
CRI 是一个插件接口,它使 kubelet 能够使用各种容器运行时,无需重新编译集群组件。
你需要在集群中的每个节点上都有一个可以正常工作的容器运行时, 这样 kubelet 能启动 Pod 及其容器。
容器运行时接口(CRI)是 kubelet 和容器运行时之间通信的主要协议。
Kubernetes 容器运行时接口(Container Runtime Interface;CRI)定义了主要 gRPC 协议, 用于节点组件 kubelet 和容器运行时之间的通信。
API
特性状态:
Kubernetes v1.23 [stable]
当通过 gRPC 连接到容器运行时,kubelet 将充当客户端。运行时和镜像服务端点必须在容器运行时中可用,
可以使用 --image-service-endpoint
命令行标志在 kubelet 中单独配置。
对 Kubernetes v1.29,kubelet 偏向于使用 CRI v1 版本。
如果容器运行时不支持 CRI 的 v1 版本,那么 kubelet 会尝试协商较老的、仍被支持的所有版本。
v1.29 版本的 kubelet 也可协商 CRI v1alpha2 版本,但该版本被视为已弃用。
如果 kubelet 无法协商出可支持的 CRI 版本,则 kubelet 放弃并且不会注册为节点。
升级
升级 Kubernetes 时,kubelet 会尝试在组件重启时自动选择最新的 CRI 版本。 如果失败,则将如上所述进行回退。如果由于容器运行时已升级而需要 gRPC 重拨, 则容器运行时还必须支持最初选择的版本,否则重拨预计会失败。 这需要重新启动 kubelet。
接下来
- 了解更多有关 CRI 协议定义
2.8 - 垃圾收集
垃圾收集(Garbage Collection)是 Kubernetes 用于清理集群资源的各种机制的统称。 垃圾收集允许系统清理如下资源:
- 终止的 Pod
- 已完成的 Job
- 不再存在属主引用的对象
- 未使用的容器和容器镜像
- 动态制备的、StorageClass 回收策略为 Delete 的 PV 卷
- 阻滞或者过期的 CertificateSigningRequest (CSR)
- 在以下情形中删除了的节点对象:
- 当集群使用云控制器管理器运行于云端时;
- 当集群使用类似于云控制器管理器的插件运行在本地环境中时。
- 节点租约对象
属主与依赖
Kubernetes 中很多对象通过属主引用 链接到彼此。属主引用(Owner Reference)可以告诉控制面哪些对象依赖于其他对象。 Kubernetes 使用属主引用来为控制面以及其他 API 客户端在删除某对象时提供一个清理关联资源的机会。 在大多数场合,Kubernetes 都是自动管理属主引用的。
属主关系与某些资源所使用的标签和选择算符不同。
例如,考虑一个创建 EndpointSlice 对象的 Service。
Service 使用标签来允许控制面确定哪些 EndpointSlice 对象被该 Service 使用。
除了标签,每个被 Service 托管的 EndpointSlice 对象还有一个属主引用属性。
属主引用可以帮助 Kubernetes 中的不同组件避免干预并非由它们控制的对象。
说明:
根据设计,系统不允许出现跨名字空间的属主引用。名字空间作用域的依赖对象可以指定集群作用域或者名字空间作用域的属主。 名字空间作用域的属主必须存在于依赖对象所在的同一名字空间。 如果属主位于不同名字空间,则属主引用被视为不存在,而当检查发现所有属主都已不存在时,依赖对象会被删除。
集群作用域的依赖对象只能指定集群作用域的属主。 在 1.20 及更高版本中,如果一个集群作用域的依赖对象指定了某个名字空间作用域的类别作为其属主, 则该对象被视为拥有一个无法解析的属主引用,因而无法被垃圾收集处理。
在 1.20 及更高版本中,如果垃圾收集器检测到非法的跨名字空间 ownerReference,
或者某集群作用域的依赖对象的 ownerReference 引用某名字空间作用域的类别,
系统会生成一个警告事件,其原因为 OwnerRefInvalidNamespace,involvedObject
设置为非法的依赖对象。你可以通过运行
kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace
来检查是否存在这类事件。
级联删除
Kubernetes 会检查并删除那些不再拥有属主引用的对象,例如在你删除了 ReplicaSet 之后留下来的 Pod。当你删除某个对象时,你可以控制 Kubernetes 是否去自动删除该对象的依赖对象, 这个过程称为级联删除(Cascading Deletion)。 级联删除有两种类型,分别如下:
- 前台级联删除
- 后台级联删除
你也可以使用 Kubernetes Finalizers 来控制垃圾收集机制如何以及何时删除包含属主引用的资源。
前台级联删除
在前台级联删除中,正在被你删除的属主对象首先进入 deletion in progress 状态。 在这种状态下,针对属主对象会发生以下事情:
- Kubernetes API 服务器将某对象的
metadata.deletionTimestamp字段设置为该对象被标记为要删除的时间点。 - Kubernetes API 服务器也会将
metadata.finalizers字段设置为foregroundDeletion。 - 在删除过程完成之前,通过 Kubernetes API 仍然可以看到该对象。
当属主对象进入删除过程中状态后,控制器删除其依赖对象。控制器在删除完所有依赖对象之后, 删除属主对象。这时,通过 Kubernetes API 就无法再看到该对象。
在前台级联删除过程中,唯一可能阻止属主对象被删除的是那些带有
ownerReference.blockOwnerDeletion=true 字段的依赖对象。
参阅使用前台级联删除
以了解进一步的细节。
后台级联删除
在后台级联删除过程中,Kubernetes 服务器立即删除属主对象,控制器在后台清理所有依赖对象。 默认情况下,Kubernetes 使用后台级联删除方案,除非你手动设置了要使用前台删除, 或者选择遗弃依赖对象。
参阅使用后台级联删除 以了解进一步的细节。
被遗弃的依赖对象
当 Kubernetes 删除某个属主对象时,被留下来的依赖对象被称作被遗弃的(Orphaned)对象。 默认情况下,Kubernetes 会删除依赖对象。要了解如何重载这种默认行为,可参阅 删除属主对象和遗弃依赖对象。
未使用容器和镜像的垃圾收集
kubelet 会每两分钟对未使用的镜像执行一次垃圾收集, 每分钟对未使用的容器执行一次垃圾收集。 你应该避免使用外部的垃圾收集工具,因为外部工具可能会破坏 kubelet 的行为,移除应该保留的容器。
要配置对未使用容器和镜像的垃圾收集选项,可以使用一个
配置文件,基于
KubeletConfiguration
资源类型来调整与垃圾收集相关的 kubelet 行为。
容器镜像生命周期
Kubernetes 通过其镜像管理器(Image Manager) 来管理所有镜像的生命周期, 该管理器是 kubelet 的一部分,工作时与 cadvisor 协同。 kubelet 在作出垃圾收集决定时会考虑如下磁盘用量约束:
HighThresholdPercentLowThresholdPercent
磁盘用量超出所配置的 HighThresholdPercent 值时会触发垃圾收集,
垃圾收集器会基于镜像上次被使用的时间来按顺序删除它们,首先删除的是最近未使用的镜像。
kubelet 会持续删除镜像,直到磁盘用量到达 LowThresholdPercent 值为止。
未使用容器镜像的垃圾收集
特性状态:
Kubernetes v1.29 [alpha]
这是一个 Alpha 特性,不论磁盘使用情况如何,你都可以指定本地镜像未被使用的最长时间。 这是一个可以为每个节点配置的 kubelet 设置。
请为 kubelet 启用 ImageMaximumGCAge
特性门控,
并在 kubelet 配置文件中为 ImageMaximumGCAge 字段赋值来配置该设置。
该值应遵循 Kubernetes 持续时间(Duration) 格式;例如,你可以将配置字段设置为 3d12h,
代表 3 天 12 小时。
容器垃圾收集
kubelet 会基于如下变量对所有未使用的容器执行垃圾收集操作,这些变量都是你可以定义的:
MinAge:kubelet 可以垃圾回收某个容器时该容器的最小年龄。设置为0表示禁止使用此规则。MaxPerPodContainer:每个 Pod 可以包含的已死亡的容器个数上限。设置为小于0的值表示禁止使用此规则。MaxContainers:集群中可以存在的已死亡的容器个数上限。设置为小于0的值意味着禁止应用此规则。
除以上变量之外,kubelet 还会垃圾收集除无标识的以及已删除的容器,通常从最近未使用的容器开始。
当保持每个 Pod 的最大数量的容器(MaxPerPodContainer)会使得全局的已死亡容器个数超出上限
(MaxContainers)时,MaxPerPodContainer 和 MaxContainers 之间可能会出现冲突。
在这种情况下,kubelet 会调整 MaxPerPodContainer 来解决这一冲突。
最坏的情形是将 MaxPerPodContainer 降格为 1,并驱逐最近未使用的容器。
此外,当隶属于某已被删除的 Pod 的容器的年龄超过 MinAge 时,它们也会被删除。
说明:
kubelet 仅会回收由它所管理的容器。
配置垃圾收集
你可以通过配置特定于管理资源的控制器来调整资源的垃圾收集行为。 下面的页面为你展示如何配置垃圾收集:
接下来
- 进一步了解 Kubernetes 对象的属主关系。
- 进一步了解 Kubernetes finalizers。
- 进一步了解 TTL 控制器, 该控制器负责清理已完成的 Job。
2.9 - 混合版本代理
特性状态:
Kubernetes v1.28 [alpha]
Kubernetes 1.29 包含了一个 Alpha 特性,可以让 API 服务器代理指向其他对等 API 服务器的资源请求。当一个集群中运行着多个 API 服务器,且各服务器的 Kubernetes 版本不同时 (例如在上线 Kubernetes 新版本的时间跨度较长时),这一特性非常有用。
此特性通过将(升级过程中所发起的)资源请求引导到正确的 kube-apiserver 使得集群管理员能够配置高可用的、升级动作更安全的集群。 该代理机制可以防止用户在升级过程中看到意外的 404 Not Found 错误。
这个机制称为 Mixed Version Proxy(混合版本代理)。
启用混合版本代理
当你启动 API 服务器时,
确保启用了 UnknownVersionInteroperabilityProxy
特性门控:
kube-apiserver \
--feature-gates=UnknownVersionInteroperabilityProxy=true \
# 需要为此特性添加的命令行参数
--peer-ca-file=<指向 kube-apiserver CA 证书的路径>
--proxy-client-cert-file=<指向聚合器代理证书的路径>,
--proxy-client-key-file=<指向聚合器代理密钥的路径>,
--requestheader-client-ca-file=<指向聚合器 CA 证书的路径>,
# requestheader-allowed-names 可设置为空以允许所有 Common Name
--requestheader-allowed-names=<验证代理客户端证书的合法 Common Name>,
# 此特性的可选标志
--peer-advertise-ip=`应由对等方用于代理请求的 kube-apiserver IP`
--peer-advertise-port=`应由对等方用于代理请求的 kube-apiserver 端口`
# ... 和其他常规标志
API 服务器之间的代理传输和身份验证
-
源 kube-apiserver 重用现有的 API 服务器客户端身份验证标志
--proxy-client-cert-file和--proxy-client-key-file来表明其身份,供对等(目标 kube-apiserver)验证。 目标 API 服务器根据你使用--requestheader-client-ca-file命令行参数指定的配置来验证对等连接。 -
要对目标服务器所用的证书进行身份验证,必须通过指定
--peer-ca-file命令行参数来为源 API 服务器配置一个证书机构包。
对等 API 服务器连接的配置
要设置 kube-apiserver 的网络位置以供对等方来代理请求,
使用为 kube-apiserver 设置的 --peer-advertise-ip 和 --peer-advertise-port 命令行参数,
或在 API 服务器配置文件中指定这些字段。如果未指定这些参数,对等方将使用 --advertise-address
或 --bind-address 命令行参数的值。如果这些也未设置,则使用主机的默认接口。
混合版本代理
启用混合版本代理时, 聚合层会加载一个特殊的过滤器, 完成以下操作:
- 当资源请求到达无法提供该 API 的 API 服务器时 (可能的原因是服务器早于该 API 的正式引入日期或该 API 在 API 服务器上被关闭), API 服务器会尝试将请求发送到能够提供所请求 API 的对等 API 服务器。 API 服务器通过发现本地服务器无法识别的 API 组/版本/资源来实现这一点, 并尝试将这些请求代理到能够处理这些请求的对等 API 服务器。
- 如果对等 API 服务器无法响应,则源 API 服务器将以 503("Service Unavailable")错误进行响应。
内部工作原理
当 API 服务器收到一个资源请求时,它首先检查哪些 API 服务器可以提供所请求的资源。
这个检查是使用内部的
StorageVersion API
进行的。
- 如果资源被收到请求(例如
GET /api/v1/pods/some-pod)的 API 服务器所了解,则请求会在本地处理。
- 如果没有找到适合所请求资源(例如
GET /my-api/v1/my-resource)的内部StorageVersion对象, 并且所配置的 APIService 设置了指向扩展 API 服务器的代理,那么代理操作将按照扩展 API 的常规流程进行。
-
如果找到了对应所请求资源(例如
GET /batch/v1/jobs)的合法的内部StorageVersion对象, 并且正在处理请求的 API 服务器(处理中的 API 服务器)禁用了batchAPI, 则正处理的 API 服务器使用已获取的StorageVersion对象中的信息, 获取提供相关 API 组/版本/资源(在此情况下为api/v1/batch)的对等 API 服务器。 处理中的 API 服务器随后将请求代理到能够理解所请求资源且匹配的对等 kube-apiserver 之一。-
如果没有对等方了解所给的 API 组/版本/资源,则处理请求的 API 服务器将请求传递给自己的处理程序链, 最终应返回 404("Not Found")响应。
-
如果处理请求的 API 服务器已经识别并选择了一个对等 API 服务器,但该对等方无法响应 (原因可能是网络连接问题或正接收的请求与向控制平面注册对等信息的控制器之间存在数据竞争等), 则处理请求的 API 服务器会以 503("Service Unavailable")错误进行响应。
-
3 - 容器
打包应用及其运行依赖环境的技术。
每个运行的容器都是可重复的; 包含依赖环境在内的标准,意味着无论你在哪里运行它都会得到相同的行为。
容器将应用程序从底层的主机设施中解耦。 这使得在不同的云或 OS 环境中部署更加容易。
Kubernetes 集群中的每个节点都会运行容器, 这些容器构成分配给该节点的 Pod。 单个 Pod 中的容器会在共同调度下,于同一位置运行在相同的节点上。
容器镜像
容器镜像是一个随时可以运行的软件包, 包含运行应用程序所需的一切:代码和它需要的所有运行时、应用程序和系统库,以及一些基本设置的默认值。
容器旨在设计成无状态且不可变的: 你不应更改已经运行的容器的代码。如果有一个容器化的应用程序需要修改, 正确的流程是:先构建包含更改的新镜像,再基于新构建的镜像重新运行容器。
容器运行时
这个基础组件使 Kubernetes 能够有效运行容器。 它负责管理 Kubernetes 环境中容器的执行和生命周期。
Kubernetes 支持许多容器运行环境,例如 containerd、 CRI-O 以及 Kubernetes CRI (容器运行环境接口) 的其他任何实现。
通常,你可以允许集群为一个 Pod 选择其默认的容器运行时。如果你需要在集群中使用多个容器运行时, 你可以为一个 Pod 指定 RuntimeClass, 以确保 Kubernetes 会使用特定的容器运行时来运行这些容器。
你还可以通过 RuntimeClass,使用相同的容器运行时,但使用不同设定的配置来运行不同的 Pod。
3.1 - 镜像
容器镜像(Image)所承载的是封装了应用程序及其所有软件依赖的二进制数据。 容器镜像是可执行的软件包,可以单独运行;该软件包对所处的运行时环境具有良定(Well Defined)的假定。
你通常会创建应用的容器镜像并将其推送到某仓库(Registry),然后在 Pod 中引用它。
本页概要介绍容器镜像的概念。
说明:
如果你正在寻找 Kubernetes 某个发行版本(如最新次要版本 v1.29) 的容器镜像,请访问下载 Kubernetes。
镜像名称
容器镜像通常会被赋予 pause、example/mycontainer 或者 kube-apiserver 这类的名称。
镜像名称也可以包含所在仓库的主机名。例如:fictional.registry.example/imagename。
还可以包含仓库的端口号,例如:fictional.registry.example:10443/imagename。
如果你不指定仓库的主机名,Kubernetes 认为你在使用 Docker 公共仓库。
在镜像名称之后,你可以添加一个标签(Tag)(与使用 docker 或 podman 等命令时的方式相同)。
使用标签能让你辨识同一镜像序列中的不同版本。
镜像标签可以包含小写字母、大写字母、数字、下划线(_)、句点(.)和连字符(-)。
关于在镜像标签中何处可以使用分隔字符(_、- 和 .)还有一些额外的规则。
如果你不指定标签,Kubernetes 认为你想使用标签 latest。
更新镜像
当你最初创建一个 Deployment、
StatefulSet、Pod
或者其他包含 Pod 模板的对象时,如果没有显式设定的话,
Pod 中所有容器的默认镜像拉取策略是 IfNotPresent。这一策略会使得
kubelet
在镜像已经存在的情况下直接略过拉取镜像的操作。
镜像拉取策略
容器的 imagePullPolicy 和镜像的标签会影响
kubelet 尝试拉取(下载)指定的镜像。
以下列表包含了 imagePullPolicy 可以设置的值,以及这些值的效果:
IfNotPresent- 只有当镜像在本地不存在时才会拉取。
Always- 每当 kubelet 启动一个容器时,kubelet 会查询容器的镜像仓库, 将名称解析为一个镜像摘要。 如果 kubelet 有一个容器镜像,并且对应的摘要已在本地缓存,kubelet 就会使用其缓存的镜像; 否则,kubelet 就会使用解析后的摘要拉取镜像,并使用该镜像来启动容器。
Never- Kubelet 不会尝试获取镜像。如果镜像已经以某种方式存在本地, kubelet 会尝试启动容器;否则,会启动失败。 更多细节见提前拉取镜像。
只要能够可靠地访问镜像仓库,底层镜像提供者的缓存语义甚至可以使 imagePullPolicy: Always 高效。
你的容器运行时可以注意到节点上已经存在的镜像层,这样就不需要再次下载。
说明:
在生产环境中部署容器时,你应该避免使用 :latest 标签,因为这使得正在运行的镜像的版本难以追踪,并且难以正确地回滚。
相反,应指定一个有意义的标签,如 v1.42.0,和/或者一个摘要。
为了确保 Pod 总是使用相同版本的容器镜像,你可以指定镜像的摘要;
将 <image-name>:<tag> 替换为 <image-name>@<digest>,例如 image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2。
当使用镜像标签时,如果镜像仓库修改了代码所对应的镜像标签,可能会出现新旧代码混杂在 Pod 中运行的情况。 镜像摘要唯一标识了镜像的特定版本,因此 Kubernetes 每次启动具有指定镜像名称和摘要的容器时,都会运行相同的代码。 通过摘要指定镜像可固定你运行的代码,这样镜像仓库的变化就不会导致版本的混杂。
有一些第三方的准入控制器 在创建 Pod(和 Pod 模板)时产生变更,这样运行的工作负载就是根据镜像摘要,而不是标签来定义的。 无论镜像仓库上的标签发生什么变化,你都想确保你所有的工作负载都运行相同的代码,那么指定镜像摘要会很有用。
默认镜像拉取策略
当你(或控制器)向 API 服务器提交一个新的 Pod 时,你的集群会在满足特定条件时设置 imagePullPolicy 字段:
- 如果你省略了
imagePullPolicy字段,并且你为容器镜像指定了摘要, 那么imagePullPolicy会自动设置为IfNotPresent。
- 如果你省略了
imagePullPolicy字段,并且容器镜像的标签是:latest,imagePullPolicy会自动设置为Always。 - 如果你省略了
imagePullPolicy字段,并且没有指定容器镜像的标签,imagePullPolicy会自动设置为Always。 - 如果你省略了
imagePullPolicy字段,并且为容器镜像指定了非:latest的标签,imagePullPolicy就会自动设置为IfNotPresent。
说明:
容器的 imagePullPolicy 的值总是在对象初次 创建 时设置的,
如果后来镜像的标签或摘要发生变化,则不会更新。
例如,如果你用一个 非 :latest 的镜像标签创建一个 Deployment,
并在随后更新该 Deployment 的镜像标签为 :latest,则 imagePullPolicy 字段 不会 变成 Always。
你必须手动更改已经创建的资源的拉取策略。
必要的镜像拉取
如果你想总是强制执行拉取,你可以使用下述的一中方式:
- 设置容器的
imagePullPolicy为Always。 - 省略
imagePullPolicy,并使用:latest作为镜像标签; 当你提交 Pod 时,Kubernetes 会将策略设置为Always。 - 省略
imagePullPolicy和镜像的标签; 当你提交 Pod 时,Kubernetes 会将策略设置为Always。 - 启用准入控制器 AlwaysPullImages。
ImagePullBackOff
当 kubelet 使用容器运行时创建 Pod 时,容器可能因为 ImagePullBackOff 导致状态为
Waiting。
ImagePullBackOff 状态意味着容器无法启动,
因为 Kubernetes 无法拉取容器镜像(原因包括无效的镜像名称,或从私有仓库拉取而没有 imagePullSecret)。
BackOff 部分表示 Kubernetes 将继续尝试拉取镜像,并增加回退延迟。
Kubernetes 会增加每次尝试之间的延迟,直到达到编译限制,即 300 秒(5 分钟)。
基于运行时类的镜像拉取
特性状态:
Kubernetes v1.29 [alpha]
Kubernetes 包含了根据 Pod 的 RuntimeClass 来执行镜像拉取的 Alpha 支持。
如果你启用了 RuntimeClassInImageCriApi 特性门控,
kubelet 会通过一个元组(镜像名称,运行时处理程序)而不仅仅是镜像名称或镜像摘要来引用容器镜像。
你的容器运行时
可能会根据选定的运行时处理程序调整其行为。
基于运行时类来拉取镜像对于基于 VM 的容器(如 Windows Hyper-V 容器)会有帮助。
串行和并行镜像拉取
默认情况下,kubelet 以串行方式拉取镜像。 也就是说,kubelet 一次只向镜像服务发送一个镜像拉取请求。 其他镜像拉取请求必须等待,直到正在处理的那个请求完成。
节点独立地做出镜像拉取的决策。即使你使用串行的镜像拉取,两个不同的节点也可以并行拉取相同的镜像。
如果你想启用并行镜像拉取,可以在 kubelet 配置
中将字段 serializeImagePulls 设置为 false。
当serializeImagePulls 设置为 false 时,kubelet 会立即向镜像服务发送镜像拉取请求,多个镜像将同时被拉动。
启用并行镜像拉取时,请确保你的容器运行时的镜像服务可以处理并行镜像拉取。
kubelet 从不代表一个 Pod 并行地拉取多个镜像。
例如,如果你有一个 Pod,它有一个初始容器和一个应用容器,那么这两个容器的镜像拉取将不会并行。 但是,如果你有两个使用不同镜像的 Pod,当启用并行镜像拉取时,kubelet 会代表两个不同的 Pod 并行拉取镜像。
最大并行镜像拉取数量
特性状态:
Kubernetes v1.27 [alpha]
当 serializeImagePulls 被设置为 false 时,kubelet 默认对同时拉取的最大镜像数量没有限制。
如果你想限制并行镜像拉取的数量,可以在 kubelet 配置中设置字段 maxParallelImagePulls。
当 maxParallelImagePulls 设置为 n 时,只能同时拉取 n 个镜像,
超过 n 的任何镜像都必须等到至少一个正在进行拉取的镜像拉取完成后,才能拉取。
当启用并行镜像拉取时,限制并行镜像拉取的数量可以防止镜像拉取消耗过多的网络带宽或磁盘 I/O。
你可以将 maxParallelImagePulls 设置为大于或等于 1 的正数。
如果将 maxParallelImagePulls 设置为大于等于 2,则必须将 serializeImagePulls 设置为 false。
kubelet 在无效的 maxParallelImagePulls 设置下会启动失败。
带镜像索引的多架构镜像
除了提供二进制的镜像之外,
容器仓库也可以提供容器镜像索引。
镜像索引可以指向镜像的多个镜像清单,
提供特定于体系结构版本的容器。
这背后的理念是让你可以为镜像命名(例如:pause、example/mycontainer、kube-apiserver)
的同时,允许不同的系统基于它们所使用的机器体系结构取回正确的二进制镜像。
Kubernetes 自身通常在命名容器镜像时添加后缀 -$(ARCH)。
为了向前兼容,请在生成较老的镜像时也提供后缀。
这里的理念是为某镜像(如 pause)生成针对所有平台都适用的清单时,
生成 pause-amd64 这类镜像,以便较老的配置文件或者将镜像后缀硬编码到其中的
YAML 文件也能兼容。
使用私有仓库
从私有仓库读取镜像时可能需要密钥。 凭据可以用以下方式提供:
- 配置节点向私有仓库进行身份验证
- 所有 Pod 均可读取任何已配置的私有仓库
- 需要集群管理员配置节点
- kubelet 凭据提供程序,动态获取私有仓库的凭据
- kubelet 可以被配置为使用凭据提供程序 exec 插件来访问对应的私有镜像库
- 预拉镜像
- 所有 Pod 都可以使用节点上缓存的所有镜像
- 需要所有节点的 root 访问权限才能进行设置
- 在 Pod 中设置 ImagePullSecrets
- 只有提供自己密钥的 Pod 才能访问私有仓库
- 特定于厂商的扩展或者本地扩展
- 如果你在使用定制的节点配置,你(或者云平台提供商)可以实现让节点向容器仓库认证的机制
下面将详细描述每一项。
配置 Node 对私有仓库认证
设置凭据的具体说明取决于你选择使用的容器运行时和仓库。 你应该参考解决方案的文档来获取最准确的信息。
有关配置私有容器镜像仓库的示例, 请参阅任务从私有镜像库中拉取镜像。 该示例使用 Docker Hub 中的私有镜像仓库。
用于认证镜像拉取的 kubelet 凭据提供程序
说明:
此方法尤其适合 kubelet 需要动态获取仓库凭据时。 最常用于由云提供商提供的仓库,其中身份认证令牌的生命期是短暂的。
你可以配置 kubelet,以调用插件可执行文件的方式来动态获取容器镜像的仓库凭据。 这是为私有仓库获取凭据最稳健和最通用的方法,但也需要 kubelet 级别的配置才能启用。
有关更多细节请参见配置 kubelet 镜像凭据提供程序。
config.json 说明
对于 config.json 的解释在原始 Docker 实现和 Kubernetes 的解释之间有所不同。
在 Docker 中,auths 键只能指定根 URL,而 Kubernetes 允许 glob URL 以及前缀匹配的路径。
唯一的限制是 glob 模式(*)必须为每个子域名包括点(.)。
匹配的子域名数量必须等于 glob 模式(*.)的数量,例如:
*.kubernetes.io不会匹配kubernetes.io,但会匹配abc.kubernetes.io*.*.kubernetes.io不会匹配abc.kubernetes.io,但会匹配abc.def.kubernetes.ioprefix.*.io将匹配prefix.kubernetes.io*-good.kubernetes.io将匹配prefix-good.kubernetes.io
这意味着,像这样的 config.json 是有效的:
{
"auths": {
"my-registry.io/images": { "auth": "…" },
"*.my-registry.io/images": { "auth": "…" }
}
}
现在镜像拉取操作会将每种有效模式的凭据都传递给 CRI 容器运行时。例如下面的容器镜像名称会匹配成功:
my-registry.io/imagesmy-registry.io/images/my-imagemy-registry.io/images/another-imagesub.my-registry.io/images/my-image
但这些不会匹配成功:
a.sub.my-registry.io/images/my-imagea.b.sub.my-registry.io/images/my-image
kubelet 为每个找到的凭据的镜像按顺序拉取。这意味着对于不同的路径在 config.json 中也可能有多项:
{
"auths": {
"my-registry.io/images": {
"auth": "…"
},
"my-registry.io/images/subpath": {
"auth": "…"
}
}
}
如果一个容器指定了要拉取的镜像 my-registry.io/images/subpath/my-image,
并且其中一个失败,kubelet 将尝试从另一个身份验证源下载镜像。
提前拉取镜像
说明:
该方法适用于你能够控制节点配置的场合。 如果你的云供应商负责管理节点并自动置换节点,这一方案无法可靠地工作。
默认情况下,kubelet 会尝试从指定的仓库拉取每个镜像。
但是,如果容器属性 imagePullPolicy 设置为 IfNotPresent 或者 Never,
则会优先使用(对应 IfNotPresent)或者一定使用(对应 Never)本地镜像。
如果你希望使用提前拉取镜像的方法代替仓库认证,就必须保证集群中所有节点提前拉取的镜像是相同的。
这一方案可以用来提前载入指定的镜像以提高速度,或者作为向私有仓库执行身份认证的一种替代方案。
所有的 Pod 都可以使用节点上提前拉取的镜像。
在 Pod 上指定 ImagePullSecrets
说明:
运行使用私有仓库中镜像的容器时,建议使用这种方法。
Kubernetes 支持在 Pod 中设置容器镜像仓库的密钥。
imagePullSecrets 必须全部与 Pod 位于同一个名字空间中。
引用的 Secret 必须是 kubernetes.io/dockercfg 或 kubernetes.io/dockerconfigjson 类型。
使用 Docker Config 创建 Secret
你需要知道用于向仓库进行身份验证的用户名、密码和客户端电子邮件地址,以及它的主机名。 运行以下命令,注意替换适当的大写值:
kubectl create secret docker-registry <name> \
--docker-server=DOCKER_REGISTRY_SERVER \
--docker-username=DOCKER_USER \
--docker-password=DOCKER_PASSWORD \
--docker-email=DOCKER_EMAIL
如果你已经有 Docker 凭据文件,则可以将凭据文件导入为 Kubernetes Secret, 而不是执行上面的命令。 基于已有的 Docker 凭据创建 Secret 解释了如何完成这一操作。
如果你在使用多个私有容器仓库,这种技术将特别有用。
原因是 kubectl create secret docker-registry 创建的是仅适用于某个私有仓库的 Secret。
说明:
Pod 只能引用位于自身所在名字空间中的 Secret,因此需要针对每个名字空间重复执行上述过程。
在 Pod 中引用 ImagePullSecrets
现在,在创建 Pod 时,可以在 Pod 定义中增加 imagePullSecrets 部分来引用该 Secret。
imagePullSecrets 数组中的每一项只能引用同一名字空间中的 Secret。
例如:
cat <<EOF > pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
EOF
cat <<EOF >> ./kustomization.yaml
resources:
- pod.yaml
EOF
你需要对使用私有仓库的每个 Pod 执行以上操作。不过,
设置该字段的过程也可以通过为服务账号资源设置
imagePullSecrets 来自动完成。有关详细指令,
可参见将 ImagePullSecrets 添加到服务账号。
你也可以将此方法与节点级别的 .docker/config.json 配置结合使用。
来自不同来源的凭据会被合并。
使用案例
配置私有仓库有多种方案,以下是一些常用场景和建议的解决方案。
- 集群运行非专有镜像(例如,开源镜像)。镜像不需要隐藏。
- 使用来自公共仓库的公共镜像
- 无需配置
- 某些云厂商会自动为公开镜像提供高速缓存,以便提升可用性并缩短拉取镜像所需时间
- 使用来自公共仓库的公共镜像
- 集群运行一些专有镜像,这些镜像需要对公司外部隐藏,对所有集群用户可见
- 使用托管的私有仓库
- 在需要访问私有仓库的节点上可能需要手动配置
- 或者,在防火墙内运行一个组织内部的私有仓库,并开放读取权限
- 不需要配置 Kubernetes
- 使用控制镜像访问的托管容器镜像仓库服务
- 与手动配置节点相比,这种方案能更好地处理集群自动扩缩容
- 或者,在不方便更改节点配置的集群中,使用
imagePullSecrets
- 使用托管的私有仓库
- 集群使用专有镜像,且有些镜像需要更严格的访问控制
- 确保 AlwaysPullImages 准入控制器被启用。 否则,所有 Pod 都可以使用所有镜像。
- 确保将敏感数据存储在 Secret 资源中,而不是将其打包在镜像里。
- 集群是多租户的并且每个租户需要自己的私有仓库
- 确保 AlwaysPullImages 准入控制器。 否则,所有租户的所有的 Pod 都可以使用所有镜像。
- 为私有仓库启用鉴权。
- 为每个租户生成访问仓库的凭据,放置在 Secret 中,并将 Secret 发布到各租户的名字空间下。
- 租户将 Secret 添加到每个名字空间中的 imagePullSecrets。
如果你需要访问多个仓库,可以为每个仓库创建一个 Secret。
旧版的内置 kubelet 凭据提供程序
在旧版本的 Kubernetes 中,kubelet 与云提供商凭据直接集成。 这使它能够动态获取镜像仓库的凭据。
kubelet 凭据提供程序集成存在三个内置实现: ACR(Azure 容器仓库)、ECR(Elastic 容器仓库)和 GCR(Google 容器仓库)。
有关该旧版机制的更多信息,请阅读你正在使用的 Kubernetes 版本的文档。 从 Kubernetes v1.26 到 v1.29 不再包含该旧版机制,因此你需要:
- 在每个节点上配置一个 kubelet 镜像凭据提供程序
- 使用
imagePullSecrets和至少一个 Secret 指定镜像拉取凭据
接下来
- 阅读 OCI Image Manifest 规范。
- 了解容器镜像垃圾收集。
- 了解从私有仓库拉取镜像。
3.2 - 容器环境
本页描述了在容器环境里容器可用的资源。
容器环境
Kubernetes 的容器环境给容器提供了几个重要的资源:
容器信息
一个容器的 hostname 是该容器运行所在的 Pod 的名称。通过 hostname 命令或者调用 libc 中的
gethostname 函数可以获取该名称。
Pod 名称和命名空间可以通过 下行 API 转换为环境变量。
Pod 定义中的用户所定义的环境变量也可在容器中使用,就像在 container 镜像中静态指定的任何环境变量一样。
集群信息
创建容器时正在运行的所有服务都可用作该容器的环境变量。 这里的服务仅限于新容器的 Pod 所在的名字空间中的服务,以及 Kubernetes 控制面的服务。
对于名为 foo 的服务,当映射到名为 bar 的容器时,定义了以下变量:
FOO_SERVICE_HOST=<其上服务正运行的主机>
FOO_SERVICE_PORT=<其上服务正运行的端口>
服务具有专用的 IP 地址。如果启用了 DNS 插件, 可以在容器中通过 DNS 来访问服务。
接下来
- 学习更多有关容器生命周期回调的知识。
- 动手为容器的生命周期事件设置处理函数。
3.3 - 容器运行时类(Runtime Class)
特性状态:
Kubernetes v1.20 [stable]
本页面描述了 RuntimeClass 资源和运行时的选择机制。
RuntimeClass 是一个用于选择容器运行时配置的特性,容器运行时配置用于运行 Pod 中的容器。
动机
你可以在不同的 Pod 设置不同的 RuntimeClass,以提供性能与安全性之间的平衡。 例如,如果你的部分工作负载需要高级别的信息安全保证,你可以决定在调度这些 Pod 时尽量使它们在使用硬件虚拟化的容器运行时中运行。 这样,你将从这些不同运行时所提供的额外隔离中获益,代价是一些额外的开销。
你还可以使用 RuntimeClass 运行具有相同容器运行时但具有不同设置的 Pod。
设置
- 在节点上配置 CRI 的实现(取决于所选用的运行时)
- 创建相应的 RuntimeClass 资源
1. 在节点上配置 CRI 实现
RuntimeClass 的配置依赖于运行时接口(CRI)的实现。 根据你使用的 CRI 实现,查阅相关的文档(下方)来了解如何配置。
说明:
RuntimeClass 假设集群中的节点配置是同构的(换言之,所有的节点在容器运行时方面的配置是相同的)。 如果需要支持异构节点,配置方法请参阅下面的调度。
所有这些配置都具有相应的 handler 名,并被 RuntimeClass 引用。
handler 必须是有效的 DNS 标签名。
2. 创建相应的 RuntimeClass 资源
在上面步骤 1 中,每个配置都需要有一个用于标识配置的 handler。
针对每个 handler 需要创建一个 RuntimeClass 对象。
RuntimeClass 资源当前只有两个重要的字段:RuntimeClass 名 (metadata.name) 和 handler (handler)。
对象定义如下所示:
# RuntimeClass 定义于 node.k8s.io API 组
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
# 用来引用 RuntimeClass 的名字
# RuntimeClass 是一个集群层面的资源
name: myclass
# 对应的 CRI 配置的名称
handler: myconfiguration
RuntimeClass 对象的名称必须是有效的 DNS 子域名。
说明:
建议将 RuntimeClass 写操作(create、update、patch 和 delete)限定于集群管理员使用。 通常这是默认配置。参阅授权概述了解更多信息。
使用说明
一旦完成集群中 RuntimeClasses 的配置,
你可以在 Pod spec 中指定 runtimeClassName 来使用它。例如:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
runtimeClassName: myclass
# ...
这一设置会告诉 kubelet 使用所指的 RuntimeClass 来运行该 Pod。
如果所指的 RuntimeClass 不存在或者 CRI 无法运行相应的 handler,
那么 Pod 将会进入 Failed 终止阶段。
你可以查看相应的事件,
获取执行过程中的错误信息。
如果未指定 runtimeClassName,则将使用默认的 RuntimeHandler,相当于禁用 RuntimeClass 功能特性。
CRI 配置
关于如何安装 CRI 运行时,请查阅 CRI 安装。
containerd
通过 containerd 的 /etc/containerd/config.toml 配置文件来配置运行时 handler。
handler 需要配置在 runtimes 块中:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.${HANDLER_NAME}]
更详细信息,请查阅 containerd 的配置指南
CRI-O
通过 CRI-O 的 /etc/crio/crio.conf 配置文件来配置运行时 handler。
handler 需要配置在
crio.runtime 表之下:
[crio.runtime.runtimes.${HANDLER_NAME}]
runtime_path = "${PATH_TO_BINARY}"
更详细信息,请查阅 CRI-O 配置文档。
调度
特性状态:
Kubernetes v1.16 [beta]
通过为 RuntimeClass 指定 scheduling 字段,
你可以通过设置约束,确保运行该 RuntimeClass 的 Pod 被调度到支持该 RuntimeClass 的节点上。
如果未设置 scheduling,则假定所有节点均支持此 RuntimeClass。
为了确保 pod 会被调度到支持指定运行时的 node 上,每个 node 需要设置一个通用的 label 用于被
runtimeclass.scheduling.nodeSelector 挑选。在 admission 阶段,RuntimeClass 的 nodeSelector 将会与
Pod 的 nodeSelector 合并,取二者的交集。如果有冲突,Pod 将会被拒绝。
如果 node 需要阻止某些需要特定 RuntimeClass 的 Pod,可以在 tolerations 中指定。
与 nodeSelector 一样,tolerations 也在 admission 阶段与 Pod 的 tolerations 合并,取二者的并集。
更多有关 node selector 和 tolerations 的配置信息,请查阅 将 Pod 分派到节点。
Pod 开销
特性状态:
Kubernetes v1.24 [stable]
你可以指定与运行 Pod 相关的开销资源。声明开销即允许集群(包括调度器)在决策 Pod 和资源时将其考虑在内。
Pod 开销通过 RuntimeClass 的 overhead 字段定义。
通过使用这个字段,你可以指定使用该 RuntimeClass 运行 Pod 时的开销并确保 Kubernetes 将这些开销计算在内。
接下来
3.4 - 容器生命周期回调
这个页面描述了 kubelet 管理的容器如何使用容器生命周期回调框架, 藉由其管理生命周期中的事件触发,运行指定代码。
概述
类似于许多具有生命周期回调组件的编程语言框架,例如 Angular、Kubernetes 为容器提供了生命周期回调。 回调使容器能够了解其管理生命周期中的事件,并在执行相应的生命周期回调时运行在处理程序中实现的代码。
容器回调
有两个回调暴露给容器:
PostStart
这个回调在容器被创建之后立即被执行。 但是,不能保证回调会在容器入口点(ENTRYPOINT)之前执行。 没有参数传递给处理程序。
PreStop
在容器因 API 请求或者管理事件(诸如存活态探针、启动探针失败、资源抢占、资源竞争等)
而被终止之前,此回调会被调用。
如果容器已经处于已终止或者已完成状态,则对 preStop 回调的调用将失败。
在用来停止容器的 TERM 信号被发出之前,回调必须执行结束。
Pod 的终止宽限周期在 PreStop 回调被执行之前即开始计数,
所以无论回调函数的执行结果如何,容器最终都会在 Pod 的终止宽限期内被终止。
没有参数会被传递给处理程序。
有关终止行为的更详细描述,请参见 终止 Pod。
回调处理程序的实现
容器可以通过实现和注册该回调的处理程序来访问该回调。 针对容器,有三种类型的回调处理程序可供实现:
- Exec - 在容器的 cgroups 和名字空间中执行特定的命令(例如
pre-stop.sh)。 命令所消耗的资源计入容器的资源消耗。 - HTTP - 对容器上的特定端点执行 HTTP 请求。
- Sleep - 将容器暂停一段指定的时间。
当特性门控
PodLifecycleSleepAction被启用时, “Sleep” 操作才可用。
回调处理程序执行
当调用容器生命周期管理回调时,Kubernetes 管理系统根据回调动作执行其处理程序,
httpGet、tcpSocket 和 sleep 由 kubelet 进程执行,而 exec 在容器中执行。
回调处理程序调用在包含容器的 Pod 上下文中是同步的。
这意味着对于 PostStart 回调,容器入口点和回调异步触发。
但是,如果回调运行或挂起的时间太长,则容器无法达到 running 状态。
PreStop 回调并不会与停止容器的信号处理程序异步执行;回调必须在可以发送信号之前完成执行。
如果 PreStop 回调在执行期间停滞不前,Pod 的阶段会变成 Terminating并且一直处于该状态,
直到其 terminationGracePeriodSeconds 耗尽为止,这时 Pod 会被杀死。
这一宽限期是针对 PreStop 回调的执行时间及容器正常停止时间的总和而言的。
例如,如果 terminationGracePeriodSeconds 是 60,回调函数花了 55 秒钟完成执行,
而容器在收到信号之后花了 10 秒钟来正常结束,那么容器会在其能够正常结束之前即被杀死,
因为 terminationGracePeriodSeconds 的值小于后面两件事情所花费的总时间(55+10)。
如果 PostStart 或 PreStop 回调失败,它会杀死容器。
用户应该使他们的回调处理程序尽可能的轻量级。 但也需要考虑长时间运行的命令也很有用的情况,比如在停止容器之前保存状态。
回调递送保证
回调的递送应该是至少一次,这意味着对于任何给定的事件,
例如 PostStart 或 PreStop,回调可以被调用多次。
如何正确处理被多次调用的情况,是回调实现所要考虑的问题。
通常情况下,只会进行单次递送。 例如,如果 HTTP 回调接收器宕机,无法接收流量,则不会尝试重新发送。 然而,偶尔也会发生重复递送的可能。 例如,如果 kubelet 在发送回调的过程中重新启动,回调可能会在 kubelet 恢复后重新发送。
调试回调处理程序
回调处理程序的日志不会在 Pod 事件中公开。
如果处理程序由于某种原因失败,它将播放一个事件。
对于 PostStart,这是 FailedPostStartHook 事件,对于 PreStop,这是 FailedPreStopHook 事件。
要自己生成失败的 FailedPostStartHook 事件,请修改
lifecycle-events.yaml
文件将 postStart 命令更改为 “badcommand” 并应用它。
以下是通过运行 kubectl describe pod lifecycle-demo 后你看到的一些结果事件的示例输出:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/lifecycle-demo to ip-XXX-XXX-XX-XX.us-east-2...
Normal Pulled 6s kubelet Successfully pulled image "nginx" in 229.604315ms
Normal Pulling 4s (x2 over 6s) kubelet Pulling image "nginx"
Normal Created 4s (x2 over 5s) kubelet Created container lifecycle-demo-container
Normal Started 4s (x2 over 5s) kubelet Started container lifecycle-demo-container
Warning FailedPostStartHook 4s (x2 over 5s) kubelet Exec lifecycle hook ([badcommand]) for Container "lifecycle-demo-container" in Pod "lifecycle-demo_default(30229739-9651-4e5a-9a32-a8f1688862db)" failed - error: command 'badcommand' exited with 126: , message: "OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"badcommand\": executable file not found in $PATH: unknown\r\n"
Normal Killing 4s (x2 over 5s) kubelet FailedPostStartHook
Normal Pulled 4s kubelet Successfully pulled image "nginx" in 215.66395ms
Warning BackOff 2s (x2 over 3s) kubelet Back-off restarting failed container
接下来
- 进一步了解容器环境。
- 动手为容器的生命周期事件设置处理函数。
4 - 工作负载
理解 Kubernetes 中可部署的最小计算对象 Pod 以及辅助 Pod 运行的上层抽象。
工作负载是在 Kubernetes 上运行的应用程序。
在 Kubernetes 中,无论你的负载是由单个组件还是由多个一同工作的组件构成, 你都可以在一组 Pod 中运行它。 在 Kubernetes 中,Pod 代表的是集群上处于运行状态的一组 容器的集合。
Kubernetes Pod 遵循预定义的生命周期。 例如,当在你的集群中运行了某个 Pod,但是 Pod 所在的 节点 出现致命错误时, 所有该节点上的 Pod 的状态都会变成失败。Kubernetes 将这类失败视为最终状态: 即使该节点后来恢复正常运行,你也需要创建新的 Pod 以恢复应用。
不过,为了减轻用户的使用负担,通常不需要用户直接管理每个 Pod。
而是使用负载资源来替用户管理一组 Pod。
这些负载资源通过配置 控制器
来确保正确类型的、处于运行状态的 Pod 个数是正确的,与用户所指定的状态相一致。
Kubernetes 提供若干种内置的工作负载资源:
- Deployment 和 ReplicaSet (替换原来的资源 ReplicationController)。 Deployment 很适合用来管理你的集群上的无状态应用,Deployment 中的所有 Pod 都是相互等价的,并且在需要的时候被替换。
- StatefulSet 让你能够运行一个或者多个以某种方式跟踪应用状态的 Pod。 例如,如果你的负载会将数据作持久存储,你可以运行一个 StatefulSet,将每个 Pod 与某个 PersistentVolume 对应起来。你在 StatefulSet 中各个 Pod 内运行的代码可以将数据复制到同一 StatefulSet 中的其它 Pod 中以提高整体的服务可靠性。
- DaemonSet
定义提供节点本地支撑设施的 Pod。这些 Pod 可能对于你的集群的运维是
非常重要的,例如作为网络链接的辅助工具或者作为网络
插件
的一部分等等。每次你向集群中添加一个新节点时,如果该节点与某
DaemonSet的规约匹配,则控制平面会为该 DaemonSet 调度一个 Pod 到该新节点上运行。 - Job 和 CronJob。 定义一些一直运行到结束并停止的任务。 你可以使用 Job 来定义只需要执行一次并且执行后即视为完成的任务。你可以使用 CronJob 来根据某个排期表来多次运行同一个 Job。
在庞大的 Kubernetes 生态系统中,你还可以找到一些提供额外操作的第三方工作负载相关的资源。 通过使用定制资源定义(CRD), 你可以添加第三方工作负载资源,以完成原本不是 Kubernetes 核心功能的工作。 例如,如果你希望运行一组 Pod,但要求所有 Pod 都可用时才执行操作 (比如针对某种高吞吐量的分布式任务),你可以基于定制资源实现一个能够满足这一需求的扩展, 并将其安装到集群中运行。
接下来
除了阅读了解每类资源外,你还可以了解与这些资源相关的任务:
- 使用 Deployment 运行一个无状态的应用
- 以单实例或者多副本集合 的形式运行有状态的应用;
- 使用 CronJob 运行自动化的任务
要了解 Kubernetes 将代码与配置分离的实现机制,可参阅配置节。
关于 Kubernetes 如何为应用管理 Pod,还有两个支撑概念能够提供相关背景信息:
- 垃圾收集机制负责在 对象的属主资源被删除时在集群中清理这些对象。
- Time-to-Live 控制器会在 Job 结束之后的指定时间间隔之后删除它们。
一旦你的应用处于运行状态,你就可能想要以 Service 的形式使之可在互联网上访问;或者对于 Web 应用而言,使用 Ingress 资源将其暴露到互联网上。
4.1 - Pod
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
Pod(就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个) 容器; 这些容器共享存储、网络、以及怎样运行这些容器的声明。 Pod 中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行。 Pod 所建模的是特定于应用的 “逻辑主机”,其中包含一个或多个应用容器, 这些容器相对紧密地耦合在一起。 在非云环境中,在相同的物理机或虚拟机上运行的应用类似于在同一逻辑主机上运行的云应用。
除了应用容器,Pod 还可以包含在 Pod 启动期间运行的 Init 容器。 你也可以注入临时性容器来调试正在运行的 Pod。
什么是 Pod?
说明:
为了运行 Pod,你需要提前在每个节点安装好容器运行时。
Pod 的共享上下文包括一组 Linux 名字空间、控制组(cgroup)和可能一些其他的隔离方面, 即用来隔离容器的技术。 在 Pod 的上下文中,每个独立的应用可能会进一步实施隔离。
Pod 类似于共享名字空间并共享文件系统卷的一组容器。
Kubernetes 集群中的 Pod 主要有两种用法:
-
运行单个容器的 Pod。"每个 Pod 一个容器"模型是最常见的 Kubernetes 用例; 在这种情况下,可以将 Pod 看作单个容器的包装器,并且 Kubernetes 直接管理 Pod,而不是容器。
-
运行多个协同工作的容器的 Pod。 Pod 可以封装由紧密耦合且需要共享资源的多个并置容器组成的应用。 这些位于同一位置的容器构成一个内聚单元。
将多个并置、同管的容器组织到一个 Pod 中是一种相对高级的使用场景。 只有在一些场景中,容器之间紧密关联时你才应该使用这种模式。
你不需要运行多个容器来扩展副本(为了弹性或容量); 如果你需要多个副本,请参阅工作负载管理。
使用 Pod
下面是一个 Pod 示例,它由一个运行镜像 nginx:1.14.2 的容器组成。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
要创建上面显示的 Pod,请运行以下命令:
kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
Pod 通常不是直接创建的,而是使用工作负载资源创建的。 有关如何将 Pod 用于工作负载资源的更多信息,请参阅使用 Pod。
用于管理 Pod 的工作负载资源
通常你不需要直接创建 Pod,甚至单实例 Pod。相反,你会使用诸如 Deployment 或 Job 这类工作负载资源来创建 Pod。 如果 Pod 需要跟踪状态,可以考虑 StatefulSet 资源。
每个 Pod 都旨在运行给定应用程序的单个实例。如果希望横向扩展应用程序 (例如,运行多个实例以提供更多的资源),则应该使用多个 Pod,每个实例使用一个 Pod。 在 Kubernetes 中,这通常被称为副本(Replication)。 通常使用一种工作负载资源及其控制器来创建和管理一组 Pod 副本。
参见 Pod 和控制器以了解 Kubernetes 如何使用工作负载资源及其控制器以实现应用的扩缩和自动修复。
使用 Pod
你很少在 Kubernetes 中直接创建一个个的 Pod,甚至是单实例(Singleton)的 Pod。 这是因为 Pod 被设计成了相对临时性的、用后即抛的一次性实体。 当 Pod 由你或者间接地由控制器 创建时,它被调度在集群中的节点上运行。 Pod 会保持在该节点上运行,直到 Pod 结束执行、Pod 对象被删除、Pod 因资源不足而被驱逐或者节点失效为止。
说明:
重启 Pod 中的容器不应与重启 Pod 混淆。 Pod 不是进程,而是容器运行的环境。 在被删除之前,Pod 会一直存在。
Pod 的名称必须是一个合法的 DNS 子域值, 但这可能对 Pod 的主机名产生意外的结果。为获得最佳兼容性,名称应遵循更严格的 DNS 标签规则。
Pod 操作系统
特性状态:
Kubernetes v1.25 [stable]
你应该将 .spec.os.name 字段设置为 windows 或 linux 以表示你希望 Pod 运行在哪个操作系统之上。
这两个是 Kubernetes 目前支持的操作系统。将来,这个列表可能会被扩充。
在 Kubernetes v1.29 中,为此字段设置的值对 Pod
的调度没有影响。
设置 .spec.os.name 有助于确定性地标识 Pod 的操作系统并用于验证。
如果你指定的 Pod 操作系统与运行 kubelet 所在节点的操作系统不同,
那么 kubelet 将会拒绝运行该 Pod。
Pod 安全标准也使用这个字段来避免强制执行与该操作系统无关的策略。
Pod 和控制器
你可以使用工作负载资源来创建和管理多个 Pod。 资源的控制器能够处理副本的管理、上线,并在 Pod 失效时提供自愈能力。 例如,如果一个节点失败,控制器注意到该节点上的 Pod 已经停止工作, 就可以创建替换性的 Pod。调度器会将替身 Pod 调度到一个健康的节点执行。
下面是一些管理一个或者多个 Pod 的工作负载资源的示例:
Pod 模板
工作负载资源的控制器通常使用 **Pod 模板(Pod Template)**来替你创建 Pod 并管理它们。
Pod 模板是包含在工作负载对象中的规范,用来创建 Pod。这类负载资源包括 Deployment、 Job 和 DaemonSet 等。
工作负载的控制器会使用负载对象中的 PodTemplate 来生成实际的 Pod。
PodTemplate 是你用来运行应用时指定的负载资源的目标状态的一部分。
下面的示例是一个简单的 Job 的清单,其中的 template 指示启动一个容器。
该 Pod 中的容器会打印一条消息之后暂停。
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# 这里是 Pod 模板
spec:
containers:
- name: hello
image: busybox:1.28
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# 以上为 Pod 模板
修改 Pod 模板或者切换到新的 Pod 模板都不会对已经存在的 Pod 直接起作用。 如果改变工作负载资源的 Pod 模板,工作负载资源需要使用更新后的模板来创建 Pod, 并使用新创建的 Pod 替换旧的 Pod。
例如,StatefulSet 控制器针对每个 StatefulSet 对象确保运行中的 Pod 与当前的 Pod 模板匹配。如果编辑 StatefulSet 以更改其 Pod 模板, StatefulSet 将开始基于更新后的模板创建新的 Pod。
每个工作负载资源都实现了自己的规则,用来处理对 Pod 模板的更新。 如果你想了解更多关于 StatefulSet 的具体信息, 请阅读 StatefulSet 基础教程中的更新策略。
在节点上,kubelet 并不直接监测或管理与 Pod 模板相关的细节或模板的更新,这些细节都被抽象出来。 这种抽象和关注点分离简化了整个系统的语义, 并且使得用户可以在不改变现有代码的前提下就能扩展集群的行为。
Pod 更新与替换
正如前面章节所述,当某工作负载的 Pod 模板被改变时, 控制器会基于更新的模板创建新的 Pod 对象而不是对现有 Pod 执行更新或者修补操作。
Kubernetes 并不禁止你直接管理 Pod。对运行中的 Pod 的某些字段执行就地更新操作还是可能的。不过,类似
patch 和
replace
这类更新操作有一些限制:
-
Pod 的绝大多数元数据都是不可变的。例如,你不可以改变其
namespace、name、uid或者creationTimestamp字段;generation字段是比较特别的, 如果更新该字段,只能增加字段取值而不能减少。 -
如果
metadata.deletionTimestamp已经被设置,则不可以向metadata.finalizers列表中添加新的条目。 -
Pod 更新不可以改变除
spec.containers[*].image、spec.initContainers[*].image、spec.activeDeadlineSeconds或spec.tolerations之外的字段。 对于spec.tolerations,你只被允许添加新的条目到其中。 -
在更新
spec.activeDeadlineSeconds字段时,以下两种更新操作是被允许的:- 如果该字段尚未设置,可以将其设置为一个正数;
- 如果该字段已经设置为一个正数,可以将其设置为一个更小的、非负的整数。
资源共享和通信
Pod 使它的成员容器间能够进行数据共享和通信。
Pod 中的存储
一个 Pod 可以设置一组共享的存储卷。 Pod 中的所有容器都可以访问该共享卷,从而允许这些容器共享数据。 卷还允许 Pod 中的持久数据保留下来,即使其中的容器需要重新启动。 有关 Kubernetes 如何在 Pod 中实现共享存储并将其提供给 Pod 的更多信息, 请参考存储。
Pod 联网
每个 Pod 都在每个地址族中获得一个唯一的 IP 地址。
Pod 中的每个容器共享网络名字空间,包括 IP 地址和网络端口。
Pod 内的容器可以使用 localhost 互相通信。
当 Pod 中的容器与 Pod 之外的实体通信时,它们必须协调如何使用共享的网络资源(例如端口)。
在同一个 Pod 内,所有容器共享一个 IP 地址和端口空间,并且可以通过 localhost 发现对方。
他们也能通过如 SystemV 信号量或 POSIX 共享内存这类标准的进程间通信方式互相通信。
不同 Pod 中的容器的 IP 地址互不相同,如果没有特殊配置,就无法通过 OS 级 IPC 进行通信。
如果某容器希望与运行于其他 Pod 中的容器通信,可以通过 IP 联网的方式实现。
Pod 中的容器所看到的系统主机名与为 Pod 配置的 name 属性值相同。
网络部分提供了更多有关此内容的信息。
容器的特权模式
说明:
你的容器运行时必须支持特权容器的概念才能使用这一配置。
Pod 中的所有容器都可以在特权模式下运行,以使用原本无法访问的操作系统管理权能。 此模式同时适用于 Windows 和 Linux。
Linux 特权容器
在 Linux 中,Pod 中的所有容器都可以使用容器规约中的
安全性上下文中的
privileged(Linux)参数启用特权模式。
这对于想要使用操作系统管理权能(Capabilities,如操纵网络堆栈和访问硬件设备)的容器很有用。
Windows 特权容器
特性状态:
Kubernetes v1.26 [stable]
在 Windows 中,你可以使用 Pod 规约中安全上下文的 windowsOptions.hostProcess 参数来创建
Windows HostProcess Pod。
这些 Pod 中的所有容器都必须以 Windows HostProcess 容器方式运行。
HostProcess Pod 可以直接运行在主机上,它也能像 Linux 特权容器一样,用于执行管理任务。
静态 Pod
**静态 Pod(Static Pod)**直接由特定节点上的 kubelet 守护进程管理,
不需要 API 服务器看到它们。
尽管大多数 Pod 都是通过控制面(例如,Deployment)
来管理的,对于静态 Pod 而言,kubelet 直接监控每个 Pod,并在其失效时重启之。
静态 Pod 通常绑定到某个节点上的 kubelet。
其主要用途是运行自托管的控制面。
在自托管场景中,使用 kubelet
来管理各个独立的控制面组件。
kubelet 自动尝试为每个静态 Pod 在 Kubernetes API
服务器上创建一个镜像 Pod。
这意味着在节点上运行的 Pod 在 API 服务器上是可见的,但不可以通过 API 服务器来控制。
有关更多信息,请参阅创建静态 Pod 的指南。
说明:
静态 Pod 的 spec 不能引用其他的 API 对象(例如:
ServiceAccount、
ConfigMap、
Secret 等)。
Pod 管理多个容器
Pod 被设计成支持构造内聚的服务单元的多个协作进程(形式为容器)。 Pod 中的容器被自动并置到集群中的同一物理机或虚拟机上,并可以一起进行调度。 容器之间可以共享资源和依赖、彼此通信、协调何时以及何种方式终止自身。
Kubernetes 集群中的 Pod 主要有两种用法:
- 运行单个容器的 Pod。"每个 Pod 一个容器" 模型是最常见的 Kubernetes 用例; 在这种情况下,可以将 Pod 看作单个容器的包装器。Kubernetes 直接管理 Pod,而不是容器。
- 运行多个需要协同工作的容器的 Pod。 Pod 可以封装由多个紧密耦合且需要共享资源的并置容器组成的应用。 这些位于同一位置的容器可能形成单个内聚的服务单元 —— 一个容器将文件从共享卷提供给公众, 而另一个单独的边车容器则刷新或更新这些文件。 Pod 将这些容器和存储资源打包为一个可管理的实体。
例如,你可能有一个容器,为共享卷中的文件提供 Web 服务器支持,以及一个单独的 边车(Sidercar) 容器负责从远端更新这些文件,如下图所示:

有些 Pod 具有 Init 容器和 应用容器。 Init 容器默认会在启动应用容器之前运行并完成。
你还可以拥有为主应用 Pod 提供辅助服务的 边车容器(例如:服务网格)。
特性状态:
Kubernetes v1.29 [beta]
启用 SidecarContainers 特性门控(默认启用)允许你为
Init 容器指定 restartPolicy: Always。设置重启策略为 Always 会确保设置的 Init 容器被视为边车,
并在 Pod 的整个生命周期内保持运行。
更多细节参阅边车容器和重启策略
容器探针
Probe 是由 kubelet 对容器执行的定期诊断。要执行诊断,kubelet 可以执行三种动作:
ExecAction(借助容器运行时执行)TCPSocketAction(由 kubelet 直接检测)HTTPGetAction(由 kubelet 直接检测)
你可以参阅 Pod 的生命周期文档中的探针部分。
接下来
- 了解 Pod 生命周期。
- 了解 RuntimeClass, 以及如何使用它来配置不同的 Pod 使用不同的容器运行时配置。
- 了解 PodDisruptionBudget, 以及你可以如何利用它在出现干扰因素时管理应用的可用性。
- Pod 在 Kubernetes REST API 中是一个顶层资源。 Pod 对象的定义中包含了更多的细节信息。
- 博客分布式系统工具箱:复合容器模式中解释了在同一 Pod 中包含多个容器时的几种常见布局。
- 了解 Pod 拓扑分布约束。
要了解为什么 Kubernetes 会在其他资源 (如 StatefulSet 或 Deployment) 封装通用的 Pod API,相关的背景信息可以在前人的研究中找到。具体包括:
4.1.1 - Pod 的生命周期
本页面讲述 Pod 的生命周期。
Pod 遵循预定义的生命周期,起始于 Pending 阶段,
如果至少其中有一个主要容器正常启动,则进入 Running,之后取决于 Pod
中是否有容器以失败状态结束而进入 Succeeded 或者 Failed 阶段。
在 Pod 运行期间,kubelet 能够重启容器以处理一些失效场景。
在 Pod 内部,Kubernetes 跟踪不同容器的状态并确定使
Pod 重新变得健康所需要采取的动作。
在 Kubernetes API 中,Pod 包含规约部分和实际状态部分。 Pod 对象的状态包含了一组 Pod 状况(Conditions)。 如果应用需要的话,你也可以向其中注入自定义的就绪态信息。
Pod 在其生命周期中只会被调度一次。 一旦 Pod 被调度(分派)到某个节点,Pod 会一直在该节点运行,直到 Pod 停止或者被终止。
Pod 生命期
和一个个独立的应用容器一样,Pod 也被认为是相对临时性(而不是长期存在)的实体。 Pod 会被创建、赋予一个唯一的 ID(UID), 并被调度到节点,并在终止(根据重启策略)或删除之前一直运行在该节点。
如果一个节点死掉了,调度到该节点的 Pod 也被计划在给定超时期限结束后删除。
Pod 自身不具有自愈能力。如果 Pod 被调度到某节点而该节点之后失效, Pod 会被删除;类似地,Pod 无法在因节点资源耗尽或者节点维护而被驱逐期间继续存活。 Kubernetes 使用一种高级抽象来管理这些相对而言可随时丢弃的 Pod 实例, 称作控制器。
任何给定的 Pod (由 UID 定义)从不会被“重新调度(rescheduled)”到不同的节点; 相反,这一 Pod 可以被一个新的、几乎完全相同的 Pod 替换掉。 如果需要,新 Pod 的名字可以不变,但是其 UID 会不同。
如果某物声称其生命期与某 Pod 相同,例如存储卷, 这就意味着该对象在此 Pod (UID 亦相同)存在期间也一直存在。 如果 Pod 因为任何原因被删除,甚至某完全相同的替代 Pod 被创建时, 这个相关的对象(例如这里的卷)也会被删除并重建。

Pod 结构图例
一个包含多个容器的 Pod 中包含一个用来拉取文件的程序和一个 Web 服务器, 均使用持久卷作为容器间共享的存储。
Pod 阶段
Pod 的 status 字段是一个
PodStatus
对象,其中包含一个 phase 字段。
Pod 的阶段(Phase)是 Pod 在其生命周期中所处位置的简单宏观概述。 该阶段并不是对容器或 Pod 状态的综合汇总,也不是为了成为完整的状态机。
Pod 阶段的数量和含义是严格定义的。
除了本文档中列举的内容外,不应该再假定 Pod 有其他的 phase 值。
下面是 phase 可能的值:
| 取值 | 描述 |
|---|---|
Pending(悬决) |
Pod 已被 Kubernetes 系统接受,但有一个或者多个容器尚未创建亦未运行。此阶段包括等待 Pod 被调度的时间和通过网络下载镜像的时间。 |
Running(运行中) |
Pod 已经绑定到了某个节点,Pod 中所有的容器都已被创建。至少有一个容器仍在运行,或者正处于启动或重启状态。 |
Succeeded(成功) |
Pod 中的所有容器都已成功终止,并且不会再重启。 |
Failed(失败) |
Pod 中的所有容器都已终止,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止。 |
Unknown(未知) |
因为某些原因无法取得 Pod 的状态。这种情况通常是因为与 Pod 所在主机通信失败。 |
说明:
当一个 Pod 被删除时,执行一些 kubectl 命令会展示这个 Pod 的状态为 Terminating(终止)。
这个 Terminating 状态并不是 Pod 阶段之一。
Pod 被赋予一个可以体面终止的期限,默认为 30 秒。
你可以使用 --force 参数来强制终止 Pod。
从 Kubernetes 1.27 开始,除了静态 Pod
和没有 Finalizer 的强制终止 Pod
之外,kubelet 会将已删除的 Pod 转换到终止阶段
(Failed 或 Succeeded 具体取决于 Pod 容器的退出状态),然后再从 API 服务器中删除。
如果某节点死掉或者与集群中其他节点失联,Kubernetes
会实施一种策略,将失去的节点上运行的所有 Pod 的 phase 设置为 Failed。
容器状态
Kubernetes 会跟踪 Pod 中每个容器的状态,就像它跟踪 Pod 总体上的阶段一样。 你可以使用容器生命周期回调 来在容器生命周期中的特定时间点触发事件。
一旦调度器将 Pod
分派给某个节点,kubelet
就通过容器运行时开始为
Pod 创建容器。容器的状态有三种:Waiting(等待)、Running(运行中)和
Terminated(已终止)。
要检查 Pod 中容器的状态,你可以使用 kubectl describe pod <pod 名称>。
其输出中包含 Pod 中每个容器的状态。
每种状态都有特定的含义:
Waiting (等待)
如果容器并不处在 Running 或 Terminated 状态之一,它就处在 Waiting 状态。
处于 Waiting 状态的容器仍在运行它完成启动所需要的操作:例如,
从某个容器镜像仓库拉取容器镜像,或者向容器应用 Secret
数据等等。
当你使用 kubectl 来查询包含 Waiting 状态的容器的 Pod 时,你也会看到一个
Reason 字段,其中给出了容器处于等待状态的原因。
Running(运行中)
Running 状态表明容器正在执行状态并且没有问题发生。
如果配置了 postStart 回调,那么该回调已经执行且已完成。
如果你使用 kubectl 来查询包含 Running 状态的容器的 Pod 时,
你也会看到关于容器进入 Running 状态的信息。
Terminated(已终止)
处于 Terminated 状态的容器已经开始执行并且或者正常结束或者因为某些原因失败。
如果你使用 kubectl 来查询包含 Terminated 状态的容器的 Pod 时,
你会看到容器进入此状态的原因、退出代码以及容器执行期间的起止时间。
如果容器配置了 preStop 回调,则该回调会在容器进入 Terminated
状态之前执行。
容器重启策略
Pod 的 spec 中包含一个 restartPolicy 字段,其可能取值包括
Always、OnFailure 和 Never。默认值是 Always。
restartPolicy 应用于 Pod
中的应用容器和常规的
Init 容器。
Sidecar 容器忽略
Pod 级别的 restartPolicy 字段:在 Kubernetes 中,Sidecar 被定义为
initContainers 内的一个条目,其容器级别的 restartPolicy 被设置为 Always。
对于因错误而退出的 Init 容器,如果 Pod 级别 restartPolicy 为 OnFailure 或 Always,
则 kubelet 会重新启动 Init 容器。
当 kubelet 根据配置的重启策略处理容器重启时,仅适用于同一 Pod
内替换容器并在同一节点上运行的重启。当 Pod 中的容器退出时,kubelet
会按指数回退方式计算重启的延迟(10s、20s、40s、...),其最长延迟为 5 分钟。
一旦某容器执行了 10 分钟并且没有出现问题,kubelet 对该容器的重启回退计时器执行重置操作。
Sidecar 容器和 Pod 生命周期中解释了
init containers 在指定 restartpolicy 字段时的行为。
Pod 状况
Pod 有一个 PodStatus 对象,其中包含一个 PodConditions 数组。Pod 可能通过也可能未通过其中的一些状况测试。 Kubelet 管理以下 PodCondition:
PodScheduled:Pod 已经被调度到某节点;PodReadyToStartContainers:Pod 沙箱被成功创建并且配置了网络(Beta 特性,默认启用);ContainersReady:Pod 中所有容器都已就绪;Initialized:所有的 Init 容器都已成功完成;Ready:Pod 可以为请求提供服务,并且应该被添加到对应服务的负载均衡池中。
| 字段名称 | 描述 |
|---|---|
type |
Pod 状况的名称 |
status |
表明该状况是否适用,可能的取值有 "True"、"False" 或 "Unknown" |
lastProbeTime |
上次探测 Pod 状况时的时间戳 |
lastTransitionTime |
Pod 上次从一种状态转换到另一种状态时的时间戳 |
reason |
机器可读的、驼峰编码(UpperCamelCase)的文字,表述上次状况变化的原因 |
message |
人类可读的消息,给出上次状态转换的详细信息 |
Pod 就绪态
特性状态:
Kubernetes v1.29 [beta]
你的应用可以向 PodStatus 中注入额外的反馈或者信号:Pod Readiness(Pod 就绪态)。
要使用这一特性,可以设置 Pod 规约中的 readinessGates 列表,为 kubelet
提供一组额外的状况供其评估 Pod 就绪态时使用。
就绪态门控基于 Pod 的 status.conditions 字段的当前值来做决定。
如果 Kubernetes 无法在 status.conditions 字段中找到某状况,
则该状况的状态值默认为 "False"。
这里是一个例子:
kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # 内置的 Pod 状况
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # 额外的 Pod 状况
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: true
...
你所添加的 Pod 状况名称必须满足 Kubernetes 标签键名格式。
Pod 就绪态的状态
命令 kubectl patch 不支持修改对象的状态。
如果需要设置 Pod 的 status.conditions,应用或者
Operators
需要使用 PATCH 操作。你可以使用
Kubernetes 客户端库之一来编写代码,
针对 Pod 就绪态设置定制的 Pod 状况。
对于使用定制状况的 Pod 而言,只有当下面的陈述都适用时,该 Pod 才会被评估为就绪:
- Pod 中所有容器都已就绪;
readinessGates中的所有状况都为True值。
当 Pod 的容器都已就绪,但至少一个定制状况没有取值或者取值为 False,
kubelet 将 Pod 的状况设置为 ContainersReady。
Pod 网络就绪
特性状态:
Kubernetes v1.25 [alpha]
说明:
在其早期开发过程中,这种状况被命名为 PodHasNetwork。
在 Pod 被调度到某节点后,它需要被 kubelet 接受并且挂载所需的存储卷。
一旦这些阶段完成,Kubelet 将与容器运行时(使用容器运行时接口(Container Runtime Interface;CRI))
一起为 Pod 生成运行时沙箱并配置网络。如果启用了 PodReadyToStartContainersCondition
特性门控
(Kubernetes 1.29 版本中默认启用),
PodReadyToStartContainers 状况会被添加到 Pod 的 status.conditions 字段中。
当 kubelet 检测到 Pod 不具备配置了网络的运行时沙箱时,PodReadyToStartContainers
状况将被设置为 False。以下场景中将会发生这种状况:
- 在 Pod 生命周期的早期阶段,kubelet 还没有开始使用容器运行时为 Pod 设置沙箱时。
- 在 Pod 生命周期的末期阶段,Pod 的沙箱由于以下原因被销毁时:
- 节点重启时 Pod 没有被驱逐
- 对于使用虚拟机进行隔离的容器运行时,Pod 沙箱虚拟机重启时,需要创建一个新的沙箱和全新的容器网络配置。
在运行时插件成功完成 Pod 的沙箱创建和网络配置后,
kubelet 会将 PodReadyToStartContainers 状况设置为 True。
当 PodReadyToStartContainers 状况设置为 True 后,
Kubelet 可以开始拉取容器镜像和创建容器。
对于带有 Init 容器的 Pod,kubelet 会在 Init 容器成功完成后将 Initialized 状况设置为 True
(这发生在运行时成功创建沙箱和配置网络之后),
对于没有 Init 容器的 Pod,kubelet 会在创建沙箱和网络配置开始之前将
Initialized 状况设置为 True。
Pod 调度就绪态
特性状态:
Kubernetes v1.26 [alpha]
有关详细信息,请参阅 Pod 调度就绪态。
容器探针
probe 是由 kubelet 对容器执行的定期诊断。 要执行诊断,kubelet 既可以在容器内执行代码,也可以发出一个网络请求。
检查机制
使用探针来检查容器有四种不同的方法。 每个探针都必须准确定义为这四种机制中的一种:
exec- 在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
grpc- 使用 gRPC 执行一个远程过程调用。 目标应该实现 gRPC 健康检查。 如果响应的状态是 "SERVING",则认为诊断成功。
httpGet- 对容器的 IP 地址上指定端口和路径执行 HTTP
GET请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。 tcpSocket- 对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。 如果远程系统(容器)在打开连接后立即将其关闭,这算作是健康的。
注意: 和其他机制不同,
exec 探针的实现涉及每次执行时创建/复制多个进程。
因此,在集群中具有较高 pod 密度、较低的 initialDelaySeconds 和 periodSeconds 时长的时候,
配置任何使用 exec 机制的探针可能会增加节点的 CPU 负载。
这种场景下,请考虑使用其他探针机制以避免额外的开销。
探测结果
每次探测都将获得以下三种结果之一:
Success(成功)- 容器通过了诊断。
Failure(失败)- 容器未通过诊断。
Unknown(未知)- 诊断失败,因此不会采取任何行动。
探测类型
针对运行中的容器,kubelet 可以选择是否执行以下三种探针,以及如何针对探测结果作出反应:
livenessProbe- 指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器,
并且容器将根据其重启策略决定未来。如果容器不提供存活探针,
则默认状态为
Success。 readinessProbe- 指示容器是否准备好为请求提供服务。如果就绪态探测失败,
端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。
初始延迟之前的就绪态的状态值默认为
Failure。 如果容器不提供就绪态探针,则默认状态为Success。 startupProbe- 指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被
禁用,直到此探针成功为止。如果启动探测失败,
kubelet将杀死容器, 而容器依其重启策略进行重启。 如果容器没有提供启动探测,则默认状态为Success。
如欲了解如何设置存活态、就绪态和启动探针的进一步细节, 可以参阅配置存活态、就绪态和启动探针。
何时该使用存活态探针?
如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活态探针;
kubelet 将根据 Pod 的 restartPolicy 自动执行修复操作。
如果你希望容器在探测失败时被杀死并重新启动,那么请指定一个存活态探针,
并指定 restartPolicy 为 "Always" 或 "OnFailure"。
何时该使用就绪态探针?
如果要仅在探测成功时才开始向 Pod 发送请求流量,请指定就绪态探针。 在这种情况下,就绪态探针可能与存活态探针相同,但是规约中的就绪态探针的存在意味着 Pod 将在启动阶段不接收任何数据,并且只有在探针探测成功后才开始接收数据。
如果你希望容器能够自行进入维护状态,也可以指定一个就绪态探针, 检查某个特定于就绪态的因此不同于存活态探测的端点。
如果你的应用程序对后端服务有严格的依赖性,你可以同时实现存活态和就绪态探针。 当应用程序本身是健康的,存活态探针检测通过后,就绪态探针会额外检查每个所需的后端服务是否可用。 这可以帮助你避免将流量导向只能返回错误信息的 Pod。
如果你的容器需要在启动期间加载大型数据、配置文件或执行迁移, 你可以使用启动探针。 然而,如果你想区分已经失败的应用和仍在处理其启动数据的应用,你可能更倾向于使用就绪探针。
说明:
请注意,如果你只是想在 Pod 被删除时能够排空请求,则不一定需要使用就绪态探针; 在删除 Pod 时,Pod 会自动将自身置于未就绪状态,无论就绪态探针是否存在。 等待 Pod 中的容器停止期间,Pod 会一直处于未就绪状态。
何时该使用启动探针?
对于所包含的容器需要较长时间才能启动就绪的 Pod 而言,启动探针是有用的。 你不再需要配置一个较长的存活态探测时间间隔,只需要设置另一个独立的配置选定, 对启动期间的容器执行探测,从而允许使用远远超出存活态时间间隔所允许的时长。
如果你的容器启动时间通常超出 initialDelaySeconds + failureThreshold × periodSeconds
总值,你应该设置一个启动探测,对存活态探针所使用的同一端点执行检查。
periodSeconds 的默认值是 10 秒。你应该将其 failureThreshold 设置得足够高,
以便容器有充足的时间完成启动,并且避免更改存活态探针所使用的默认值。
这一设置有助于减少死锁状况的发生。
Pod 的终止
由于 Pod 所代表的是在集群中节点上运行的进程,当不再需要这些进程时允许其体面地终止是很重要的。
一般不应武断地使用 KILL 信号终止它们,导致这些进程没有机会完成清理操作。
设计的目标是令你能够请求删除进程,并且知道进程何时被终止,同时也能够确保删除操作终将完成。 当你请求删除某个 Pod 时,集群会记录并跟踪 Pod 的体面终止周期, 而不是直接强制地杀死 Pod。在存在强制关闭设施的前提下, kubelet 会尝试体面地终止 Pod。
通常 Pod 体面终止的过程为:kubelet 先发送一个带有体面超时限期的 TERM(又名 SIGTERM)
信号到每个容器中的主进程,将请求发送到容器运行时来尝试停止 Pod 中的容器。
停止容器的这些请求由容器运行时以异步方式处理。
这些请求的处理顺序无法被保证。许多容器运行时遵循容器镜像内定义的 STOPSIGNAL 值,
如果不同,则发送容器镜像中配置的 STOPSIGNAL,而不是 TERM 信号。
一旦超出了体面终止限期,容器运行时会向所有剩余进程发送 KILL 信号,之后
Pod 就会被从 API 服务器上移除。
如果 kubelet 或者容器运行时的管理服务在等待进程终止期间被重启,
集群会从头开始重试,赋予 Pod 完整的体面终止限期。
下面是一个例子:
-
你使用
kubectl工具手动删除某个特定的 Pod,而该 Pod 的体面终止限期是默认值(30 秒)。 -
API 服务器中的 Pod 对象被更新,记录涵盖体面终止限期在内 Pod 的最终死期,超出所计算时间点则认为 Pod 已死(dead)。 如果你使用
kubectl describe来查验你正在删除的 Pod,该 Pod 会显示为 "Terminating" (正在终止)。 在 Pod 运行所在的节点上:kubelet一旦看到 Pod 被标记为正在终止(已经设置了体面终止限期),kubelet即开始本地的 Pod 关闭过程。-
如果 Pod 中的容器之一定义了
preStop回调,kubelet开始在容器内运行该回调逻辑。如果超出体面终止限期时,preStop回调逻辑仍在运行,kubelet会请求给予该 Pod 的宽限期一次性增加 2 秒钟。如果
preStop回调在体面期结束后仍在运行,kubelet 将请求短暂的、一次性的体面期延长 2 秒。说明:如果 `preStop` 回调所需要的时间长于默认的体面终止限期,你必须修改 `terminationGracePeriodSeconds` 属性值来使其正常工作。
-
kubelet接下来触发容器运行时发送 TERM 信号给每个容器中的进程 1。说明:Pod 中的容器会在不同时刻收到 TERM 信号,接收顺序也是不确定的。 如果关闭的顺序很重要,可以考虑使用 `preStop` 回调逻辑来协调。
-
-
在
kubelet启动 Pod 的体面关闭逻辑的同时,控制平面会评估是否将关闭的 Pod 从对应的 EndpointSlice(和端点)对象中移除,过滤条件是 Pod 被对应的服务以某 选择算符选定。 ReplicaSet 和其他工作负载资源不再将关闭进程中的 Pod 视为合法的、能够提供服务的副本。关闭动作很慢的 Pod 不应继续处理常规服务请求,而应开始终止并完成对打开的连接的处理。 一些应用程序不仅需要完成对打开的连接的处理,还需要更进一步的体面终止逻辑 - 比如:排空和完成会话。
任何正在终止的 Pod 所对应的端点都不会立即从 EndpointSlice 中被删除,EndpointSlice API(以及传统的 Endpoints API)会公开一个状态来指示其处于 终止状态。 正在终止的端点始终将其
ready状态设置为false(为了向后兼容 1.26 之前的版本), 因此负载均衡器不会将其用于常规流量。如果需要排空正被终止的 Pod 上的流量,可以将
serving状况作为实际的就绪状态。你可以在教程 探索 Pod 及其端点的终止行为 中找到有关如何实现连接排空的更多详细信息。
说明:
如果你的集群中没有启用 EndpointSliceTerminatingCondition 特性门控 (该门控从 Kubernetes 1.22 开始默认开启,在 1.26 中锁定为默认), 那么一旦 Pod 的终止宽限期开始,Kubernetes 控制平面就会从所有的相关 EndpointSlices 中移除 Pod。 上述行为是在 EndpointSliceTerminatingCondition 特性门控被启用时描述的。
说明:
从 Kubernetes 1.29 开始,如果你的 Pod 包含一个或多个 Sidecar
容器(重启策略为 Always 的 Init 容器),kubelet 将延迟向这些
Sidecar 容器发送 TERM 信号,直到最后一个主容器完全终止。
Sidecar 容器将以 Pod 规约中定义的相反顺序终止。
这可确保 Sidecar 容器继续为 Pod 中的其他容器提供服务,直到不再需要它们为止。
请注意,主容器的缓慢终止也会延迟边车容器的终止。 如果宽限期在终止过程完成之前到期,Pod 可能会进入紧急终止状态。 在这种情况下,Pod 中的所有剩余容器将在短暂的宽限期内同时终止。
同样,如果 Pod 的 preStop 回调超过了终止宽限期,则可能会发生紧急终止。 一般来说,如果你在没有 Sidecar 容器的情况下使用 preStop 回调来控制终止顺序, 那么现在可以删除它们从而允许 kubelet 自动管理 Sidecar 终止。
-
超出终止宽限期限时,
kubelet会触发强制关闭过程。容器运行时会向 Pod 中所有容器内仍在运行的进程发送SIGKILL信号。kubelet也会清理隐藏的pause容器,如果容器运行时使用了这种容器的话。 -
kubelet将 Pod 转换到终止阶段(Failed或Succeeded具体取决于其容器的结束状态)。 这一步从 1.27 版本开始得到保证。 -
kubelet触发强制从 API 服务器上删除 Pod 对象的逻辑,并将体面终止限期设置为 0 (这意味着马上删除)。 -
API 服务器删除 Pod 的 API 对象,从任何客户端都无法再看到该对象。
强制终止 Pod
注意:
对于某些工作负载及其 Pod 而言,强制删除很可能会带来某种破坏。
默认情况下,所有的删除操作都会附有 30 秒钟的宽限期限。
kubectl delete 命令支持 --grace-period=<seconds> 选项,允许你重载默认值,
设定自己希望的期限值。
将宽限期限强制设置为 0 意味着立即从 API 服务器删除 Pod。
如果 Pod 仍然运行于某节点上,强制删除操作会触发 kubelet 立即执行清理操作。
说明:
你必须在设置 --grace-period=0 的同时额外设置 --force 参数才能发起强制删除请求。
执行强制删除操作时,API 服务器不再等待来自 kubelet 的、关于 Pod
已经在原来运行的节点上终止执行的确认消息。
API 服务器直接删除 Pod 对象,这样新的与之同名的 Pod 即可以被创建。
在节点侧,被设置为立即终止的 Pod 仍然会在被强行杀死之前获得一点点的宽限时间。
注意:
马上删除时不等待确认正在运行的资源已被终止。这些资源可能会无限期地继续在集群上运行。
如果你需要强制删除 StatefulSet 的 Pod, 请参阅从 StatefulSet 中删除 Pod 的任务文档。
Pod 的垃圾收集
对于已失败的 Pod 而言,对应的 API 对象仍然会保留在集群的 API 服务器上, 直到用户或者控制器进程显式地将其删除。
Pod 的垃圾收集器(PodGC)是控制平面的控制器,它会在 Pod 个数超出所配置的阈值
(根据 kube-controller-manager 的 terminated-pod-gc-threshold 设置)时删除已终止的
Pod(阶段值为 Succeeded 或 Failed)。
这一行为会避免随着时间演进不断创建和终止 Pod 而引起的资源泄露问题。
此外,PodGC 会清理满足以下任一条件的所有 Pod:
- 孤儿 Pod - 绑定到不再存在的节点,
- 计划外终止的 Pod
- 终止过程中的 Pod,当启用
NodeOutOfServiceVolumeDetach特性门控时, 绑定到有node.kubernetes.io/out-of-service污点的未就绪节点。
若启用 PodDisruptionConditions 特性门控,在清理 Pod 的同时,
如果它们处于非终止状态阶段,PodGC 也会将它们标记为失败。
此外,PodGC 在清理孤儿 Pod 时会添加 Pod 干扰状况。参阅
Pod 干扰状况 了解更多详情。
接下来
- 动手实践为容器生命周期时间关联处理程序。
- 动手实践配置存活态、就绪态和启动探针。
- 进一步了解容器生命周期回调。
- 进一步了解 Sidecar 容器。
- 关于 API 中定义的有关 Pod 和容器状态的详细规范信息,
可参阅 API 参考文档中 Pod 的
status字段。
4.1.2 - Init 容器
本页提供了 Init 容器的概览。Init 容器是一种特殊容器,在 Pod 内的应用容器启动之前运行。Init 容器可以包括一些应用镜像中不存在的实用工具和安装脚本。
你可以在 Pod 的规约中与用来描述应用容器的 containers 数组平行的位置指定
Init 容器。
在 Kubernetes 中,边车容器 是在主应用容器之前启动并持续运行的容器。本文介绍 Init 容器:在 Pod 初始化期间完成运行的容器。
理解 Init 容器
每个 Pod 中可以包含多个容器, 应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
Init 容器与普通的容器非常像,除了如下两点:
- 它们总是运行到完成。
- 每个都必须在下一个启动之前成功完成。
如果 Pod 的 Init 容器失败,kubelet 会不断地重启该 Init 容器直到该容器成功为止。
然而,如果 Pod 对应的 restartPolicy 值为 "Never",并且 Pod 的 Init 容器失败,
则 Kubernetes 会将整个 Pod 状态设置为失败。
为 Pod 设置 Init 容器需要在
Pod 规约中添加 initContainers 字段,
该字段以 Container
类型对象数组的形式组织,和应用的 containers 数组同级相邻。
参阅 API 参考的容器章节了解详情。
Init 容器的状态在 status.initContainerStatuses 字段中以容器状态数组的格式返回
(类似 status.containerStatuses 字段)。
与普通容器的不同之处
Init 容器支持应用容器的全部字段和特性,包括资源限制、 数据卷和安全设置。 然而,Init 容器对资源请求和限制的处理稍有不同, 在下面容器内的资源共享节有说明。
常规的 Init 容器(即不包括边车容器)不支持 lifecycle、livenessProbe、readinessProbe 或
startupProbe 字段。Init 容器必须在 Pod 准备就绪之前完成运行;而边车容器在 Pod 的生命周期内继续运行,
它支持一些探针。有关边车容器的细节请参阅边车容器。
如果为一个 Pod 指定了多个 Init 容器,这些容器会按顺序逐个运行。 每个 Init 容器必须运行成功,下一个才能够运行。当所有的 Init 容器运行完成时, Kubernetes 才会为 Pod 初始化应用容器并像平常一样运行。
与边车容器的不同之处
Init 容器在主应用容器启动之前运行并完成其任务。 与边车容器不同, Init 容器不会持续与主容器一起运行。
Init 容器按顺序完成运行,等到所有 Init 容器成功完成之后,主容器才会启动。
Init 容器不支持 lifecycle、livenessProbe、readinessProbe 或 startupProbe,
而边车容器支持所有这些探针以控制其生命周期。
Init 容器与主应用容器共享资源(CPU、内存、网络),但不直接与主应用容器进行交互。 不过这些容器可以使用共享卷进行数据交换。
使用 Init 容器
因为 Init 容器具有与应用容器分离的单独镜像,其启动相关代码具有如下优势:
-
Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。 例如,没有必要仅为了在安装过程中使用类似
sed、awk、python或dig这样的工具而去FROM一个镜像来生成一个新的镜像。 -
应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
-
与同一 Pod 中的多个应用容器相比,Init 容器能以不同的文件系统视图运行。因此,Init 容器可以被赋予访问应用容器不能访问的 Secret 的权限。
-
由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。 一旦前置条件满足,Pod 内的所有的应用容器会并行启动。
-
Init 容器可以安全地运行实用程序或自定义代码,而在其他方式下运行这些实用程序或自定义代码可能会降低应用容器镜像的安全性。 通过将不必要的工具分开,你可以限制应用容器镜像的被攻击范围。
示例
下面是一些如何使用 Init 容器的想法:
-
等待一个 Service 完成创建,通过类似如下 Shell 命令:
for i in {1..100}; do sleep 1; if nslookup myservice; then exit 0; fi; done; exit 1
-
注册这个 Pod 到远程服务器,通过在命令中调用 API,类似如下:
curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)'
-
在启动应用容器之前等一段时间,使用类似命令:
sleep 60
-
克隆 Git 仓库到卷中。
-
将配置值放到配置文件中,运行模板工具为主应用容器动态地生成配置文件。 例如,在配置文件中存放
POD_IP值,并使用 Jinja 生成主应用配置文件。
使用 Init 容器的情况
下面的例子定义了一个具有 2 个 Init 容器的简单 Pod。 第一个等待 myservice 启动,
第二个等待 mydb 启动。 一旦这两个 Init 容器都启动完成,Pod 将启动 spec 节中的应用容器。
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app.kubernetes.io/name: MyApp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
你通过运行下面的命令启动 Pod:
kubectl apply -f myapp.yaml
输出类似于:
pod/myapp-pod created
使用下面的命令检查其状态:
kubectl get -f myapp.yaml
输出类似于:
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 6m
或者查看更多详细信息:
kubectl describe -f myapp.yaml
输出类似于:
Name: myapp-pod
Namespace: default
[...]
Labels: app.kubernetes.io/name=MyApp
Status: Pending
[...]
Init Containers:
init-myservice:
[...]
State: Running
[...]
init-mydb:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Containers:
myapp-container:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
16s 16s 1 {default-scheduler } Normal Scheduled Successfully assigned myapp-pod to 172.17.4.201
16s 16s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulling pulling image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulled Successfully pulled image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Created Created container init-myservice
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Started Started container init-myservice
如需查看 Pod 内 Init 容器的日志,请执行:
kubectl logs myapp-pod -c init-myservice # 查看第一个 Init 容器
kubectl logs myapp-pod -c init-mydb # 查看第二个 Init 容器
在这一刻,Init 容器将会等待至发现名称为 mydb 和 myservice
的服务。
如下为创建这些 Service 的配置文件:
---
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
apiVersion: v1
kind: Service
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
创建 mydb 和 myservice 服务的命令:
kubectl apply -f services.yaml
输出类似于:
service/myservice created
service/mydb created
这样你将能看到这些 Init 容器执行完毕,随后 my-app 的 Pod 进入 Running 状态:
kubectl get -f myapp.yaml
输出类似于:
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 9m
这个简单例子应该能为你创建自己的 Init 容器提供一些启发。 接下来节提供了更详细例子的链接。
具体行为
在 Pod 启动过程中,每个 Init 容器会在网络和数据卷初始化之后按顺序启动。 kubelet 运行依据 Init 容器在 Pod 规约中的出现顺序依次运行之。
每个 Init 容器成功退出后才会启动下一个 Init 容器。
如果某容器因为容器运行时的原因无法启动,或以错误状态退出,kubelet 会根据
Pod 的 restartPolicy 策略进行重试。
然而,如果 Pod 的 restartPolicy 设置为 "Always",Init 容器失败时会使用
restartPolicy 的 "OnFailure" 策略。
在所有的 Init 容器没有成功之前,Pod 将不会变成 Ready 状态。
Init 容器的端口将不会在 Service 中进行聚集。正在初始化中的 Pod 处于 Pending 状态,
但会将状况 Initializing 设置为 false。
如果 Pod 重启,所有 Init 容器必须重新执行。
对 Init 容器规约的修改仅限于容器的 image 字段。
更改 Init 容器的 image 字段,等同于重启该 Pod。
因为 Init 容器可能会被重启、重试或者重新执行,所以 Init 容器的代码应该是幂等的。
特别地,基于 emptyDirs 写文件的代码,应该对输出文件可能已经存在做好准备。
Init 容器具有应用容器的所有字段。然而 Kubernetes 禁止使用 readinessProbe,
因为 Init 容器不能定义不同于完成态(Completion)的就绪态(Readiness)。
Kubernetes 会在校验时强制执行此检查。
在 Pod 上使用 activeDeadlineSeconds 和在容器上使用 livenessProbe 可以避免
Init 容器一直重复失败。
activeDeadlineSeconds 时间包含了 Init 容器启动的时间。
但建议仅在团队将其应用程序部署为 Job 时才使用 activeDeadlineSeconds,
因为 activeDeadlineSeconds 在 Init 容器结束后仍有效果。
如果你设置了 activeDeadlineSeconds,已经在正常运行的 Pod 会被杀死。
在 Pod 中的每个应用容器和 Init 容器的名称必须唯一; 与任何其它容器共享同一个名称,会在校验时抛出错误。
容器内的资源共享
在给定的 Init、边车和应用容器执行顺序下,资源使用适用于如下规则:
- 所有 Init 容器上定义的任何特定资源的 limit 或 request 的最大值,作为 Pod 有效初始 request/limit。 如果任何资源没有指定资源限制,这被视为最高限制。
- Pod 对资源的 有效 limit/request 是如下两者中的较大者:
- 所有应用容器对某个资源的 limit/request 之和
- 对某个资源的有效初始 limit/request
- 基于有效 limit/request 完成调度,这意味着 Init 容器能够为初始化过程预留资源, 这些资源在 Pod 生命周期过程中并没有被使用。
- Pod 的 有效 QoS 层,与 Init 容器和应用容器的一样。
配额和限制适用于有效 Pod 的请求和限制值。
Pod 级别的控制组(Cgroup)是基于 Pod 的有效 request 和 limit,与调度器相同。
Pod 重启的原因
Pod 重启会导致 Init 容器重新执行,主要有如下几个原因:
-
Pod 的基础设施容器 (译者注:如
pause容器) 被重启。这种情况不多见, 必须由具备 root 权限访问节点的人员来完成。 -
当
restartPolicy设置为Always,Pod 中所有容器会终止而强制重启。 由于垃圾回收机制的原因, Init 容器的完成记录将会丢失。
当 Init 容器的镜像发生改变或者 Init 容器的完成记录因为垃圾收集等原因被丢失时, Pod 不会被重启。这一行为适用于 Kubernetes v1.20 及更新版本。 如果你在使用较早版本的 Kubernetes,可查阅你所使用的版本对应的文档。
接下来
进一步了解以下内容:
- 创建包含 Init 容器的 Pod
- 调试 Init 容器
- kubelet 和 kubectl 的概述。
- 探针类型: 存活态探针、就绪态探针、启动探针。
- 边车容器。
4.1.3 - 边车容器
特性状态:
Kubernetes v1.29 [beta]
边车容器是与主应用容器在同一个 Pod 中运行的辅助容器。 这些容器通过提供额外的服务或功能(如日志记录、监控、安全性或数据同步)来增强或扩展主应用容器的功能, 而无需直接修改主应用代码。
启用边车容器
Kubernetes 1.29 默认启用,一个名为 SidecarContainers
的特性门控允许你为
Pod 的 initContainers 字段中列出的容器指定 restartPolicy。这些可重启的边车容器与同一
Pod 内的其他 Init 容器及主应用容器相互独立。
边车容器可以在不影响主应用容器和其他 Init 容器的情况下启动、停止或重启。
边车容器和 Pod 生命周期
如果创建 Init 容器时将 restartPolicy 设置为 Always,
则它将在整个 Pod 的生命周期内启动并持续运行。这对于运行与主应用容器分离的支持服务非常有帮助。
如果为此 Init 容器指定了 readinessProbe,其结果将用于确定 Pod 的 ready 状态。
由于这些容器被定义为 Init 容器,所以它们享有与其他 Init 容器相同的顺序和按序执行保证, 可以将它们与其他 Init 容器混合在一起,形成复杂的 Pod 初始化流程。
与常规 Init 容器相比,在 initContainers 中定义的边车容器在启动后继续运行。
当 Pod 的 .spec.initContainers 中有多个条目时,这一点非常重要。
在边车风格的 Init 容器运行后(kubelet 将该 Init 容器的 started 状态设置为 true),
kubelet 启动 .spec.initContainers 这一有序列表中的下一个 Init 容器。
该状态要么因为容器中有一个正在运行的进程且没有定义启动探针而变为 true,
要么是其 startupProbe 成功而返回的结果。
以下是一个具有两个容器的 Deployment 示例,其中一个是边车:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: alpine:latest
command: ['sh', '-c', 'echo "logging" > /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
initContainers:
- name: logshipper
image: alpine:latest
restartPolicy: Always
command: ['sh', '-c', 'tail /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
volumes:
- name: data
emptyDir: {}此特性也适用于带有边车的 Job,因为边车容器在主容器完成后不会阻止 Job 的完成。
以下是一个具有两个容器的 Job 示例,其中一个是边车:
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
template:
spec:
containers:
- name: myjob
image: alpine:latest
command: ['sh', '-c', 'echo "logging" > /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
initContainers:
- name: logshipper
image: alpine:latest
restartPolicy: Always
command: ['sh', '-c', 'tail /opt/logs.txt']
volumeMounts:
- name: data
mountPath: /opt
restartPolicy: Never
volumes:
- name: data
emptyDir: {}与常规容器的区别
边车容器与同一 Pod 中的常规容器并行运行。不过边车容器不执行主应用逻辑,而是为主应用提供支持功能。
边车容器具有独立的生命周期。它们可以独立于常规容器启动、停止和重启。 这意味着你可以更新、扩展或维护边车容器,而不影响主应用。
边车容器与主容器共享相同的网络和存储命名空间。这种共存使它们能够紧密交互并共享资源。
与 Init 容器的区别
边车容器与主容器并行工作,扩展其功能并提供附加服务。
边车容器与主应用容器同时运行。它们在整个 Pod 的生命周期中都处于活动状态,并且可以独立于主容器启动和停止。 与 Init 容器不同, 边车容器支持探针来控制其生命周期。
这些边车容器可以直接与主应用容器进行交互,共享相同的网络命名空间、文件系统和环境变量。 所有这些容器紧密合作,提供额外的功能。
容器内的资源共享
假如执行顺序为 Init 容器、边车容器和应用容器,则关于资源用量适用以下规则:
- 所有 Init 容器上定义的任何特定资源的 limit 或 request 的最大值,作为 Pod 有效初始 request/limit。 如果任何资源没有指定资源限制,则被视为最高限制。
- Pod 对资源的 有效 limit/request 是如下两者中的较大者:
- 所有应用容器对某个资源的 limit/request 之和
- Init 容器中对某个资源的有效 limit/request
- 系统基于有效的 limit/request 完成调度,这意味着 Init 容器能够为初始化过程预留资源, 而这些资源在 Pod 的生命周期中不再被使用。
- Pod 的 有效 QoS 级别,对于 Init 容器和应用容器而言是相同的。
配额和限制适用于 Pod 的有效请求和限制值。
Pod 级别的 cgroup 是基于 Pod 的有效请求和限制值,与调度器相同。
接下来
- 阅读关于原生边车容器的博文。
- 阅读如何创建具有 Init 容器的 Pod。
- 了解探针类型: 存活态探针、就绪态探针、启动探针。
- 了解 Pod 开销。
4.1.4 - 干扰(Disruptions)
本指南针对的是希望构建高可用性应用的应用所有者,他们有必要了解可能发生在 Pod 上的干扰类型。
文档同样适用于想要执行自动化集群操作(例如升级和自动扩展集群)的集群管理员。
自愿干扰和非自愿干扰
Pod 不会消失,除非有人(用户或控制器)将其销毁,或者出现了不可避免的硬件或软件系统错误。
我们把这些不可避免的情况称为应用的非自愿干扰(Involuntary Disruptions)。例如:
- 节点下层物理机的硬件故障
- 集群管理员错误地删除虚拟机(实例)
- 云提供商或虚拟机管理程序中的故障导致的虚拟机消失
- 内核错误
- 节点由于集群网络隔离从集群中消失
- 由于节点资源不足导致 pod 被驱逐。
除了资源不足的情况,大多数用户应该都熟悉这些情况;它们不是特定于 Kubernetes 的。
我们称其他情况为自愿干扰(Voluntary Disruptions)。 包括由应用所有者发起的操作和由集群管理员发起的操作。 典型的应用所有者的操作包括:
- 删除 Deployment 或其他管理 Pod 的控制器
- 更新了 Deployment 的 Pod 模板导致 Pod 重启
- 直接删除 Pod(例如,因为误操作)
集群管理员操作包括:
- 排空(drain)节点进行修复或升级。
- 从集群中排空节点以缩小集群(了解集群自动扩缩)。
- 从节点中移除一个 Pod,以允许其他 Pod 使用该节点。
这些操作可能由集群管理员直接执行,也可能由集群管理员所使用的自动化工具执行,或者由集群托管提供商自动执行。
咨询集群管理员或联系云提供商,或者查询发布文档,以确定是否为集群启用了任何资源干扰源。 如果没有启用,可以不用创建 Pod Disruption Budgets(Pod 干扰预算)
注意:
并非所有的自愿干扰都会受到 Pod 干扰预算的限制。 例如,删除 Deployment 或 Pod 的删除操作就会跳过 Pod 干扰预算检查。
处理干扰
以下是减轻非自愿干扰的一些方法:
- 确保 Pod 在请求中给出所需资源。
- 如果需要更高的可用性,请复制应用。 (了解有关运行多副本的无状态 和有状态应用的信息。)
- 为了在运行复制应用时获得更高的可用性,请跨机架(使用 反亲和性) 或跨区域(如果使用多区域集群)扩展应用。
自愿干扰的频率各不相同。在一个基本的 Kubernetes 集群中,没有自愿干扰(只有用户触发的干扰)。 然而,集群管理员或托管提供商可能运行一些可能导致自愿干扰的额外服务。例如,节点软 更新可能导致自愿干扰。另外,集群(节点)自动缩放的某些 实现可能导致碎片整理和紧缩节点的自愿干扰。集群 管理员或托管提供商应该已经记录了各级别的自愿干扰(如果有的话)。 有些配置选项,例如在 pod spec 中 使用 PriorityClasses 也会产生自愿(和非自愿)的干扰。
干扰预算
特性状态:
Kubernetes v1.21 [stable]
即使你会经常引入自愿性干扰,Kubernetes 提供的功能也能够支持你运行高度可用的应用。
作为一个应用的所有者,你可以为每个应用创建一个 PodDisruptionBudget(PDB)。
PDB 将限制在同一时间因自愿干扰导致的多副本应用中发生宕机的 Pod 数量。
例如,基于票选机制的应用希望确保运行中的副本数永远不会低于票选所需的数量。
Web 前端可能希望确保提供负载的副本数量永远不会低于总数的某个百分比。
集群管理员和托管提供商应该使用遵循 PodDisruptionBudgets 的接口 (通过调用Eviction API), 而不是直接删除 Pod 或 Deployment。
例如,kubectl drain 命令可以用来标记某个节点即将停止服务。
运行 kubectl drain 命令时,工具会尝试驱逐你所停服的节点上的所有 Pod。
kubectl 代表你所提交的驱逐请求可能会暂时被拒绝,
所以该工具会周期性地重试所有失败的请求,
直到目标节点上的所有的 Pod 都被终止,或者达到配置的超时时间。
PDB 指定应用可以容忍的副本数量(相当于应该有多少副本)。
例如,具有 .spec.replicas: 5 的 Deployment 在任何时间都应该有 5 个 Pod。
如果 PDB 允许其在某一时刻有 4 个副本,那么驱逐 API 将允许同一时刻仅有一个(而不是两个)Pod 自愿干扰。
使用标签选择器来指定构成应用的一组 Pod,这与应用的控制器(Deployment、StatefulSet 等) 选择 Pod 的逻辑一样。
Pod 的“预期”数量由管理这些 Pod 的工作负载资源的 .spec.replicas 参数计算出来的。
控制平面通过检查 Pod 的
.metadata.ownerReferences 来发现关联的工作负载资源。
PDB 无法防止非自愿干扰; 但它们确实计入预算。
由于应用的滚动升级而被删除或不可用的 Pod 确实会计入干扰预算,
但是工作负载资源(如 Deployment 和 StatefulSet)
在进行滚动升级时不受 PDB 的限制。
应用更新期间的故障处理方式是在对应的工作负载资源的 spec 中配置的。
建议在你的 PodDisruptionBudget 中将
不健康 Pod 驱逐策略
设置为 AlwaysAllow 以支持在节点腾空期间驱逐行为不当的应用程序。
默认行为是等待应用程序 Pod 变得
健康,然后才能继续执行腾空。
当使用驱逐 API 驱逐 Pod 时,Pod 会被体面地
终止,期间会
参考 PodSpec
中的 terminationGracePeriodSeconds 配置值。
PodDisruptionBudget 例子
假设集群有 3 个节点,node-1 到 node-3。集群上运行了一些应用。
其中一个应用有 3 个副本,分别是 pod-a,pod-b 和 pod-c。
另外,还有一个不带 PDB 的无关 pod pod-x 也同样显示出来。
最初,所有的 Pod 分布如下:
| node-1 | node-2 | node-3 |
|---|---|---|
| pod-a available | pod-b available | pod-c available |
| pod-x available |
3 个 Pod 都是 deployment 的一部分,并且共同拥有同一个 PDB,要求 3 个 Pod 中至少有 2 个 Pod 始终处于可用状态。
例如,假设集群管理员想要重启系统,升级内核版本来修复内核中的缺陷。
集群管理员首先使用 kubectl drain 命令尝试腾空 node-1 节点。
命令尝试驱逐 pod-a 和 pod-x。操作立即就成功了。
两个 Pod 同时进入 terminating 状态。这时的集群处于下面的状态:
| node-1 draining | node-2 | node-3 |
|---|---|---|
| pod-a terminating | pod-b available | pod-c available |
| pod-x terminating |
Deployment 控制器观察到其中一个 Pod 正在终止,因此它创建了一个替代 Pod pod-d。
由于 node-1 被封锁(cordon),pod-d 落在另一个节点上。
同样其他控制器也创建了 pod-y 作为 pod-x 的替代品。
(注意:对于 StatefulSet 来说,pod-a(也称为 pod-0)需要在替换 Pod 创建之前完全终止,
替代它的也称为 pod-0,但是具有不同的 UID。除此之外,此示例也适用于 StatefulSet。)
当前集群的状态如下:
| node-1 draining | node-2 | node-3 |
|---|---|---|
| pod-a terminating | pod-b available | pod-c available |
| pod-x terminating | pod-d starting | pod-y |
在某一时刻,Pod 被终止,集群如下所示:
| node-1 drained | node-2 | node-3 |
|---|---|---|
| pod-b available | pod-c available | |
| pod-d starting | pod-y |
此时,如果一个急躁的集群管理员试图排空(drain)node-2 或 node-3,drain 命令将被阻塞,
因为对于 Deployment 来说只有 2 个可用的 Pod,并且它的 PDB 至少需要 2 个。
经过一段时间,pod-d 变得可用。
集群状态如下所示:
| node-1 drained | node-2 | node-3 |
|---|---|---|
| pod-b available | pod-c available | |
| pod-d available | pod-y |
现在,集群管理员试图排空(drain)node-2。
drain 命令将尝试按照某种顺序驱逐两个 Pod,假设先是 pod-b,然后是 pod-d。
命令成功驱逐 pod-b,但是当它尝试驱逐 pod-d时将被拒绝,因为对于
Deployment 来说只剩一个可用的 Pod 了。
Deployment 创建 pod-b 的替代 Pod pod-e。
因为集群中没有足够的资源来调度 pod-e,drain 命令再次阻塞。集群最终将是下面这种状态:
| node-1 drained | node-2 | node-3 | no node |
|---|---|---|---|
| pod-b terminating | pod-c available | pod-e pending | |
| pod-d available | pod-y |
此时,集群管理员需要增加一个节点到集群中以继续升级操作。
可以看到 Kubernetes 如何改变干扰发生的速率,根据:
- 应用需要多少个副本
- 优雅关闭应用实例需要多长时间
- 启动应用新实例需要多长时间
- 控制器的类型
- 集群的资源能力
Pod 干扰状况
特性状态:
Kubernetes v1.26 [beta]
说明:
要使用此行为,你必须在集群中启用 PodDisruptionConditions
特性门控。
启用后,会给 Pod 添加一个 DisruptionTarget
状况,
用来表明该 Pod 因为发生干扰而被删除。
状况中的 reason 字段进一步给出 Pod 终止的原因,如下:
PreemptionByScheduler- Pod 将被调度器抢占, 目的是接受优先级更高的新 Pod。 要了解更多的相关信息,请参阅 Pod 优先级和抢占。
DeletionByTaintManager- 由于 Pod 不能容忍
NoExecute污点,Pod 将被 Taint Manager(kube-controller-manager中节点生命周期控制器的一部分)删除; 请参阅基于污点的驱逐。
EvictionByEvictionAPI- Pod 已被标记为通过 Kubernetes API 驱逐。
DeletionByPodGC- 绑定到一个不再存在的 Node 上的 Pod 将被 Pod 垃圾收集删除。
说明:
Pod 的干扰可能会被中断。控制平面可能会重新尝试继续干扰同一个 Pod,但这没办法保证。
因此,DisruptionTarget 状况可能会被添加到 Pod 上,
但该 Pod 实际上可能不会被删除。
在这种情况下,一段时间后,Pod 干扰状况将被清除。
当 PodDisruptionConditions 特性门控被启用时,在清理 Pod 的同时,如果这些 Pod 处于非终止阶段,
则 Pod 垃圾回收器 (PodGC) 也会将这些 Pod 标记为失效
(另见 Pod 垃圾回收)。
使用 Job(或 CronJob)时,你可能希望将这些 Pod 干扰状况作为 Job Pod 失效策略的一部分。
分离集群所有者和应用所有者角色
通常,将集群管理者和应用所有者视为彼此了解有限的独立角色是很有用的。这种责任分离在下面这些场景下是有意义的:
- 当有许多应用团队共用一个 Kubernetes 集群,并且有自然的专业角色
- 当第三方工具或服务用于集群自动化管理
Pod 干扰预算通过在角色之间提供接口来支持这种分离。
如果你的组织中没有这样的责任分离,则可能不需要使用 Pod 干扰预算。
如何在集群上执行干扰性操作
如果你是集群管理员,并且需要对集群中的所有节点执行干扰操作,例如节点或系统软件升级,则可以使用以下选项
- 接受升级期间的停机时间。
- 故障转移到另一个完整的副本集群。
- 没有停机时间,但是对于重复的节点和人工协调成本可能是昂贵的。
- 编写可容忍干扰的应用和使用 PDB。
- 不停机。
- 最小的资源重复。
- 允许更多的集群管理自动化。
- 编写可容忍干扰的应用是棘手的,但对于支持容忍自愿干扰所做的工作,和支持自动扩缩和容忍非 自愿干扰所做工作相比,有大量的重叠
接下来
-
参考配置 Pod 干扰预算中的方法来保护你的应用。
-
进一步了解排空节点的信息。
-
了解更新 Deployment 的过程,包括如何在其进程中维持应用的可用性
4.1.5 - 临时容器
特性状态:
Kubernetes v1.25 [stable]
本页面概述了临时容器:一种特殊的容器,该容器在现有 Pod 中临时运行,以便完成用户发起的操作,例如故障排查。 你会使用临时容器来检查服务,而不是用它来构建应用程序。
了解临时容器
Pod 是 Kubernetes 应用程序的基本构建块。 由于 Pod 是一次性且可替换的,因此一旦 Pod 创建,就无法将容器加入到 Pod 中。 取而代之的是,通常使用 Deployment 以受控的方式来删除并替换 Pod。
有时有必要检查现有 Pod 的状态。例如,对于难以复现的故障进行排查。 在这些场景中,可以在现有 Pod 中运行临时容器来检查其状态并运行任意命令。
什么是临时容器?
临时容器与其他容器的不同之处在于,它们缺少对资源或执行的保证,并且永远不会自动重启,
因此不适用于构建应用程序。
临时容器使用与常规容器相同的 ContainerSpec 节来描述,但许多字段是不兼容和不允许的。
- 临时容器没有端口配置,因此像
ports、livenessProbe、readinessProbe这样的字段是不允许的。 - Pod 资源分配是不可变的,因此
resources配置是不允许的。 - 有关允许字段的完整列表,请参见 EphemeralContainer 参考文档。
临时容器是使用 API 中的一种特殊的 ephemeralcontainers 处理器进行创建的,
而不是直接添加到 pod.spec 段,因此无法使用 kubectl edit 来添加一个临时容器。
与常规容器一样,将临时容器添加到 Pod 后,将不能更改或删除临时容器。
说明:
临时容器不被静态 Pod 支持。
临时容器的用途
当由于容器崩溃或容器镜像不包含调试工具而导致 kubectl exec 无用时,
临时容器对于交互式故障排查很有用。
尤其是,Distroless 镜像
允许用户部署最小的容器镜像,从而减少攻击面并减少故障和漏洞的暴露。
由于 distroless 镜像不包含 Shell 或任何的调试工具,因此很难单独使用
kubectl exec 命令进行故障排查。
使用临时容器时, 启用进程名字空间共享很有帮助, 可以查看其他容器中的进程。
接下来
- 了解如何使用临时调试容器来进行调试
4.1.6 - Pod QoS 类
本页介绍 Kubernetes 中的 服务质量(Quality of Service,QoS) 类, 阐述 Kubernetes 如何根据为 Pod 中的容器指定的资源约束为每个 Pod 设置 QoS 类。 Kubernetes 依赖这种分类来决定当 Node 上没有足够可用资源时要驱逐哪些 Pod。
QoS 类
Kubernetes 对你运行的 Pod 进行分类,并将每个 Pod 分配到特定的 QoS 类中。
Kubernetes 使用这种分类来影响不同 Pod 被处理的方式。Kubernetes 基于 Pod
中容器的资源请求进行分类,
同时确定这些请求如何与资源限制相关。
这称为服务质量 (QoS) 类。
Kubernetes 基于每个 Pod 中容器的资源请求和限制为 Pod 设置 QoS 类。Kubernetes 使用 QoS
类来决定从遇到节点压力的
Node 中驱逐哪些 Pod。可选的 QoS 类有 Guaranteed、Burstable 和 BestEffort。
当一个 Node 耗尽资源时,Kubernetes 将首先驱逐在该 Node 上运行的 BestEffort Pod,
然后是 Burstable Pod,最后是 Guaranteed Pod。当这种驱逐是由于资源压力时,
只有超出资源请求的 Pod 才是被驱逐的候选对象。
Guaranteed
Guaranteed Pod 具有最严格的资源限制,并且最不可能面临驱逐。
在这些 Pod 超过其自身的限制或者没有可以从 Node 抢占的低优先级 Pod 之前,
这些 Pod 保证不会被杀死。这些 Pod 不可以获得超出其指定 limit 的资源。这些 Pod 也可以使用
static
CPU 管理策略来使用独占的 CPU。
判据
Pod 被赋予 Guaranteed QoS 类的几个判据:
- Pod 中的每个容器必须有内存 limit 和内存 request。
- 对于 Pod 中的每个容器,内存 limit 必须等于内存 request。
- Pod 中的每个容器必须有 CPU limit 和 CPU request。
- 对于 Pod 中的每个容器,CPU limit 必须等于 CPU request。
Burstable
Burstable Pod 有一些基于 request 的资源下限保证,但不需要特定的 limit。
如果未指定 limit,则默认为其 limit 等于 Node 容量,这允许 Pod 在资源可用时灵活地增加其资源。
在由于 Node 资源压力导致 Pod 被驱逐的情况下,只有在所有 BestEffort Pod 被驱逐后
这些 Pod 才会被驱逐。因为 Burstable Pod 可以包括没有资源 limit 或资源 request 的容器,
所以 Burstable Pod 可以尝试使用任意数量的节点资源。
判据
Pod 被赋予 Burstable QoS 类的几个判据:
- Pod 不满足针对 QoS 类
Guaranteed的判据。 - Pod 中至少一个容器有内存或 CPU 的 request 或 limit。
BestEffort
BestEffort QoS 类中的 Pod 可以使用未专门分配给其他 QoS 类中的 Pod 的节点资源。
例如若你有一个节点有 16 核 CPU 可供 kubelet 使用,并且你将 4 核 CPU 分配给一个 Guaranteed Pod,
那么 BestEffort QoS 类中的 Pod 可以尝试任意使用剩余的 12 核 CPU。
如果节点遇到资源压力,kubelet 将优先驱逐 BestEffort Pod。
判据
如果 Pod 不满足 Guaranteed 或 Burstable 的判据,则它的 QoS 类为 BestEffort。
换言之,只有当 Pod 中的所有容器没有内存 limit 或内存 request,也没有 CPU limit 或
CPU request 时,Pod 才是 BestEffort。Pod 中的容器可以请求(除 CPU 或内存之外的)
其他资源并且仍然被归类为 BestEffort。
使用 cgroup v2 的内存 QoS
特性状态:
Kubernetes v1.29 []
内存 QoS 使用 cgroup v2 的内存控制器来保证 Kubernetes 中的内存资源。
Pod 中容器的内存请求和限制用于设置由内存控制器所提供的特定接口 memory.min 和 memory.high。
当 memory.min 被设置为内存请求时,内存资源被保留并且永远不会被内核回收;
这就是内存 QoS 确保 Kubernetes Pod 的内存可用性的方式。而如果容器中设置了内存限制,
这意味着系统需要限制容器内存的使用;内存 QoS 使用 memory.high 来限制接近其内存限制的工作负载,
确保系统不会因瞬时内存分配而不堪重负。
内存 QoS 依赖于 QoS 类来确定应用哪些设置;它们的机制不同,但都提供对服务质量的控制。
某些行为独立于 QoS 类
某些行为独立于 Kubernetes 分配的 QoS 类。例如:
- 所有超过资源 limit 的容器都将被 kubelet 杀死并重启,而不会影响该 Pod 中的其他容器。
- 如果一个容器超出了自身的资源 request,且该容器运行的节点面临资源压力,则该容器所在的 Pod 就会成为被驱逐的候选对象。 如果出现这种情况,Pod 中的所有容器都将被终止。Kubernetes 通常会在不同的节点上创建一个替代的 Pod。
- Pod 的资源 request 等于其成员容器的资源 request 之和,Pod 的资源 limit 等于其成员容器的资源 limit 之和。
- kube-scheduler 在选择要抢占的 Pod 时不考虑 QoS 类。当集群没有足够的资源来运行你所定义的所有 Pod 时,就会发生抢占。
接下来
- 进一步了解为 Pod 和容器管理资源。
- 进一步了解节点压力驱逐。
- 进一步了解 Pod 优先级和抢占。
- 进一步了解 Pod 干扰。
- 进一步了解如何为容器和 Pod 分配内存资源。
- 进一步了解如何为容器和 Pod 分配 CPU 资源。
- 进一步了解如何配置 Pod 的服务质量。
4.1.7 - 用户命名空间
特性状态:
Kubernetes v1.25 [alpha]
本页解释了在 Kubernetes Pod 中如何使用用户命名空间。 用户命名空间将容器内运行的用户与主机中的用户隔离开来。
在容器中以 root 身份运行的进程可以在主机中以不同的(非 root)用户身份运行; 换句话说,该进程在用户命名空间内的操作具有完全的权限, 但在命名空间外的操作是无特权的。
你可以使用这个功能来减少被破坏的容器对主机或同一节点中的其他 Pod 的破坏。 有几个安全漏洞被评为 高 或 重要, 当用户命名空间处于激活状态时,这些漏洞是无法被利用的。 预计用户命名空间也会减轻一些未来的漏洞。
准备开始
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
这是一个只对 Linux 有效的功能特性,且需要 Linux 支持在所用文件系统上挂载 idmap。 这意味着:
- 在节点上,你用于
/var/lib/kubelet/pods/的文件系统,或你为此配置的自定义目录, 需要支持 idmap 挂载。 - Pod 卷中使用的所有文件系统都必须支持 idmap 挂载。
在实践中,这意味着你最低需要 Linux 6.3,因为 tmpfs 在该版本中开始支持 idmap 挂载。 这通常是需要的,因为有几个 Kubernetes 功能特性使用 tmpfs (默认情况下挂载的服务账号令牌使用 tmpfs、Secret 使用 tmpfs 等等)。
Linux 6.3 中支持 idmap 挂载的一些比较流行的文件系统是:btrfs、ext4、xfs、fat、 tmpfs、overlayfs。
此外,需要在容器运行时提供支持, 才能在 Kubernetes Pod 中使用这一功能:
- CRI-O:1.25(及更高)版本支持配置容器的用户命名空间。
containerd v1.7 与 Kubernetes v1.27 至 v1.29 版本中的用户命名空间不兼容。 Kubernetes v1.25 和 v1.26 使用了早期的实现,在用户命名空间方面与 containerd v1.7 兼容。 如果你使用的 Kubernetes 版本不是 1.29,请查看该版本 Kubernetes 的文档以获取更准确的信息。 如果有比 v1.7 更新的 containerd 版本可供使用,请检查 containerd 文档以获取兼容性信息。
你可以在 GitHub 上的 [issue][CRI-dockerd-issue] 中查看 cri-dockerd 中用户命名空间支持的状态。
介绍
用户命名空间是一个 Linux 功能,允许将容器中的用户映射到主机中的不同用户。 此外,在某用户命名空间中授予 Pod 的权能只在该命名空间中有效,在该命名空间之外无效。
一个 Pod 可以通过将 pod.spec.hostUsers 字段设置为 false 来选择使用用户命名空间。
kubelet 将挑选 Pod 所映射的主机 UID/GID, 并以此保证同一节点上没有两个 Pod 使用相同的方式进行映射。
pod.spec 中的 runAsUser、runAsGroup、fsGroup 等字段总是指的是容器内的用户。
启用该功能时,有效的 UID/GID 在 0-65535 范围内。这以限制适用于文件和进程(runAsUser、runAsGroup 等)。
使用这个范围之外的 UID/GID 的文件将被视为属于溢出 ID,
通常是 65534(配置在 /proc/sys/kernel/overflowuid和/proc/sys/kernel/overflowgid)。
然而,即使以 65534 用户/组的身份运行,也不可能修改这些文件。
大多数需要以 root 身份运行但不访问其他主机命名空间或资源的应用程序, 在用户命名空间被启用时,应该可以继续正常运行,不需要做任何改变。
了解 Pod 的用户命名空间
一些容器运行时的默认配置(如 Docker Engine、containerd、CRI-O)使用 Linux 命名空间进行隔离。 其他技术也存在,也可以与这些运行时(例如,Kata Containers 使用虚拟机而不是 Linux 命名空间)结合使用。 本页适用于使用 Linux 命名空间进行隔离的容器运行时。
在创建 Pod 时,默认情况下会使用几个新的命名空间进行隔离: 一个网络命名空间来隔离容器网络,一个 PID 命名空间来隔离进程视图等等。 如果使用了一个用户命名空间,这将把容器中的用户与节点中的用户隔离开来。
这意味着容器可以以 root 身份运行,并将该身份映射到主机上的一个非 root 用户。
在容器内,进程会认为它是以 root 身份运行的(因此像 apt、yum 等工具可以正常工作),
而实际上该进程在主机上没有权限。
你可以验证这一点,例如,如果你从主机上执行 ps aux 来检查容器进程是以哪个用户运行的。
ps 显示的用户与你在容器内执行 id 命令时看到的用户是不一样的。
这种抽象限制了可能发生的情况,例如,容器设法逃逸到主机上时的后果。 鉴于容器是作为主机上的一个非特权用户运行的,它能对主机做的事情是有限的。
此外,由于每个 Pod 上的用户将被映射到主机中不同的非重叠用户, 他们对其他 Pod 可以执行的操作也是有限的。
授予一个 Pod 的权能也被限制在 Pod 的用户命名空间内, 并且在这一命名空间之外大多无效,有些甚至完全无效。这里有两个例子:
CAP_SYS_MODULE若被授予一个使用用户命名空间的 Pod 则没有任何效果,这个 Pod 不能加载内核模块。CAP_SYS_ADMIN只限于 Pod 所在的用户命名空间,在该命名空间之外无效。
在不使用用户命名空间的情况下,以 root 账号运行的容器,在容器逃逸时,在节点上有 root 权限。 而且如果某些权能被授予了某容器,这些权能在宿主机上也是有效的。 当我们使用用户命名空间时,这些都不再成立。
如果你想知道关于使用用户命名空间时的更多变化细节,请参见 man 7 user_namespaces。
设置一个节点以支持用户命名空间
建议主机的文件和主机的进程使用 0-65535 范围内的 UID/GID。
kubelet 会把高于这个范围的 UID/GID 分配给 Pod。 因此,为了保证尽可能多的隔离,主机的文件和主机的进程所使用的 UID/GID 应该在 0-65535 范围内。
请注意,这个建议对减轻 CVE-2021-25741 等 CVE 的影响很重要; 在这些 CVE 中,Pod 有可能读取主机中的任意文件。 如果 Pod 和主机的 UID/GID 不重叠,Pod 能够做的事情就会受到限制: Pod 的 UID/GID 不会与主机的文件所有者/组相匹配。
与 Pod 安全准入检查的集成
特性状态:
Kubernetes v1.29 [alpha]
对于启用了用户命名空间的 Linux Pod,Kubernetes 会以受控方式放宽
Pod 安全性标准的应用。
这种行为可以通过特性门控
UserNamespacesPodSecurityStandards 进行控制,可以让最终用户提前尝试此特性。
如果管理员启用此特性门控,必须确保群集中的所有节点都启用了用户命名空间。
如果你启用相关特性门控并创建了使用用户命名空间的 Pod,以下的字段不会被限制,
即使在执行了 Baseline 或 Restricted Pod 安全性标准的上下文中。这种行为不会带来安全问题,
因为带有用户命名空间的 Pod 内的 root 实际上指的是容器内的用户,绝不会映射到主机上的特权用户。
以下是在这种情况下不进行检查的 Pod 字段列表:
spec.securityContext.runAsNonRootspec.containers[*].securityContext.runAsNonRootspec.initContainers[*].securityContext.runAsNonRootspec.ephemeralContainers[*].securityContext.runAsNonRootspec.securityContext.runAsUserspec.containers[*].securityContext.runAsUserspec.initContainers[*].securityContext.runAsUser
限制
当 Pod 使用用户命名空间时,不允许 Pod 使用其他主机命名空间。
特别是,如果你设置了 hostUsers: false,那么你就不可以设置如下属性:
hostNetwork: truehostIPC: truehostPID: true
接下来
4.1.8 - Downward API
有两种方法可以将 Pod 和容器字段暴露给运行中的容器:环境变量和由特殊卷类型承载的文件。 这两种暴露 Pod 和容器字段的方法统称为 Downward API。
对于容器来说,在不与 Kubernetes 过度耦合的情况下,拥有关于自身的信息有时是很有用的。 Downward API 允许容器在不使用 Kubernetes 客户端或 API 服务器的情况下获得自己或集群的信息。
例如,现有应用程序假设某特定的周知的环境变量是存在的,其中包含唯一标识符。 一种方法是对应用程序进行封装,但这很繁琐且容易出错,并且违背了低耦合的目标。 更好的选择是使用 Pod 名称作为标识符,并将 Pod 名称注入到周知的环境变量中。
在 Kubernetes 中,有两种方法可以将 Pod 和容器字段暴露给运行中的容器:
- 作为环境变量
- 作为
downwardAPI卷中的文件
这两种暴露 Pod 和容器字段的方式统称为 Downward API。
可用字段
只有部分 Kubernetes API 字段可以通过 Downward API 使用。本节列出了你可以使用的字段。
你可以使用 fieldRef 传递来自可用的 Pod 级字段的信息。在 API 层面,一个 Pod 的
spec 总是定义了至少一个 Container。
你可以使用 resourceFieldRef 传递来自可用的 Container 级字段的信息。
可通过 fieldRef 获得的信息
对于某些 Pod 级别的字段,你可以将它们作为环境变量或使用 downwardAPI 卷提供给容器。
通过这两种机制可用的字段有:
metadata.name- Pod 的名称
metadata.namespace- Pod 的命名空间
metadata.uid- Pod 的唯一 ID
metadata.annotations['<KEY>']- Pod 的注解
<KEY>的值(例如:metadata.annotations['myannotation'])
metadata.labels['<KEY>']- Pod 的标签
<KEY>的值(例如:metadata.labels['mylabel'])
以下信息可以通过环境变量获得,但不能作为 downwardAPI 卷 fieldRef 获得:
spec.serviceAccountName- Pod 的服务账号名称
spec.nodeName- Pod 运行时所处的节点名称
status.hostIP- Pod 所在节点的主 IP 地址
status.hostIPs- 这组 IP 地址是
status.hostIP的双协议栈版本,第一个 IP 始终与status.hostIP相同。 该字段在启用了PodHostIPs特性门控后可用。
status.podIP- Pod 的主 IP 地址(通常是其 IPv4 地址)
status.podIPs- 这组 IP 地址是
status.podIP的双协议栈版本, 第一个 IP 始终与status.podIP相同。
以下信息可以通过 downwardAPI 卷 fieldRef 获得,但不能作为环境变量获得:
metadata.labels- Pod 的所有标签,格式为
标签键名="转义后的标签值",每行一个标签
metadata.annotations- Pod 的全部注解,格式为
注解键名="转义后的注解值",每行一个注解
可通过 resourceFieldRef 获得的信息
resource: limits.cpu- 容器的 CPU 限制值
resource: requests.cpu- 容器的 CPU 请求值
resource: limits.memory- 容器的内存限制值
resource: requests.memory- 容器的内存请求值
resource: limits.hugepages-*- 容器的巨页限制值
resource: requests.hugepages-*- 容器的巨页请求值
resource: limits.ephemeral-storage- 容器的临时存储的限制值
resource: requests.ephemeral-storage- 容器的临时存储的请求值
资源限制的后备信息
如果没有为容器指定 CPU 和内存限制时尝试使用 Downward API 暴露该信息,那么 kubelet 默认会根据 节点可分配资源 计算并暴露 CPU 和内存的最大可分配值。
接下来
你可以阅读有关 downwardAPI 卷的内容。
你可以尝试使用 Downward API 暴露容器或 Pod 级别的信息:
- 作为环境变量
- 作为
downwardAPI卷中的文件
4.2 - 工作负载管理
Kubernetes 提供了几个内置的 API 来声明式管理工作负载及其组件。
最终,你的应用以容器的形式在 Pods 中运行; 但是,直接管理单个 Pod 的工作量将会非常繁琐。例如,如果一个 Pod 失败了,你可能希望运行一个新的 Pod 来替换它。Kubernetes 可以为你完成这些操作。
你可以使用 Kubernetes API 创建工作负载对象, 这些对象所表达的是比 Pod 更高级别的抽象概念,Kubernetes 控制平面根据你定义的工作负载对象规约自动管理 Pod 对象。
用于管理工作负载的内置 API 包括:
Deployment (也间接包括 ReplicaSet) 是在集群上运行应用的最常见方式。Deployment 适合在集群上管理无状态应用工作负载, 其中 Deployment 中的任何 Pod 都是可互换的,可以在需要时进行替换。 (Deployment 替代原来的 ReplicationController API)。
StatefulSet 允许你管理一个或多个运行相同应用代码、但具有不同身份标识的 Pod。 StatefulSet 与 Deployment 不同。Deployment 中的 Pod 预期是可互换的。 StatefulSet 最常见的用途是能够建立其 Pod 与其持久化存储之间的关联。 例如,你可以运行一个将每个 Pod 关联到 PersistentVolume 的 StatefulSet。如果该 StatefulSet 中的一个 Pod 失败了,Kubernetes 将创建一个新的 Pod, 并连接到相同的 PersistentVolume。
DaemonSet 定义了在特定节点上提供本地设施的 Pod, 例如允许该节点上的容器访问存储系统的驱动。当必须在合适的节点上运行某种驱动或其他节点级别的服务时, 你可以使用 DaemonSet。DaemonSet 中的每个 Pod 执行类似于经典 Unix / POSIX 服务器上的系统守护进程的角色。DaemonSet 可能对集群的操作至关重要, 例如作为插件让该节点访问集群网络, 也可能帮助你管理节点,或者提供增强正在运行的容器平台所需的、不太重要的设施。 你可以在集群的每个节点上运行 DaemonSets(及其 Pod),或者仅在某个子集上运行 (例如,只在安装了 GPU 的节点上安装 GPU 加速驱动)。
你可以使用 Job 和/或 CronJob 定义一次性任务和定时任务。 Job 表示一次性任务,而每个 CronJob 可以根据排期表重复执行。
本节中的其他主题:
4.2.1 - Deployments
Deployment 用于管理运行一个应用负载的一组 Pod,通常适用于不保持状态的负载。
一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力。
你负责描述 Deployment 中的目标状态,而 Deployment 控制器(Controller) 以受控速率更改实际状态, 使其变为期望状态。你可以定义 Deployment 以创建新的 ReplicaSet,或删除现有 Deployment, 并通过新的 Deployment 收养其资源。
说明:
不要管理 Deployment 所拥有的 ReplicaSet。 如果存在下面未覆盖的使用场景,请考虑在 Kubernetes 仓库中提出 Issue。
用例
以下是 Deployments 的典型用例:
- 创建 Deployment 以将 ReplicaSet 上线。ReplicaSet 在后台创建 Pod。 检查 ReplicaSet 的上线状态,查看其是否成功。
- 通过更新 Deployment 的 PodTemplateSpec,声明 Pod 的新状态 。 新的 ReplicaSet 会被创建,Deployment 以受控速率将 Pod 从旧 ReplicaSet 迁移到新 ReplicaSet。 每个新的 ReplicaSet 都会更新 Deployment 的修订版本。
- 如果 Deployment 的当前状态不稳定,回滚到较早的 Deployment 版本。 每次回滚都会更新 Deployment 的修订版本。
- 扩大 Deployment 规模以承担更多负载。
- 暂停 Deployment 的上线 以应用对 PodTemplateSpec 所作的多项修改, 然后恢复其执行以启动新的上线版本。
- 使用 Deployment 状态来判定上线过程是否出现停滞。
- 清理较旧的不再需要的 ReplicaSet 。
下面是一个 Deployment 示例。其中创建了一个 ReplicaSet,负责启动三个 nginx Pod:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
在该例中:
-
创建名为
nginx-deployment(由.metadata.name字段标明)的 Deployment。 该名称将成为后续创建 ReplicaSet 和 Pod 的命名基础。 参阅编写 Deployment 规约获取更多详细信息。 -
该 Deployment 创建一个 ReplicaSet,它创建三个(由
.spec.replicas字段标明)Pod 副本。 -
.spec.selector字段定义所创建的 ReplicaSet 如何查找要管理的 Pod。 在这里,你选择在 Pod 模板中定义的标签(app: nginx)。 不过,更复杂的选择规则是也可能的,只要 Pod 模板本身满足所给规则即可。说明:.spec.selector.matchLabels字段是{key,value}键值对映射。 在matchLabels映射中的每个{key,value}映射等效于matchExpressions中的一个元素, 即其key字段是 “key”,operator为 “In”,values数组仅包含 “value”。 在matchLabels和matchExpressions中给出的所有条件都必须满足才能匹配。
template字段包含以下子字段:- Pod 被使用
.metadata.labels字段打上app: nginx标签。 - Pod 模板规约(即
.template.spec字段)指示 Pod 运行一个nginx容器, 该容器运行版本为 1.14.2 的nginxDocker Hub 镜像。 - 创建一个容器并使用
.spec.template.spec.containers[0].name字段将其命名为nginx。
- Pod 被使用
开始之前,请确保的 Kubernetes 集群已启动并运行。 按照以下步骤创建上述 Deployment :
-
通过运行以下命令创建 Deployment :
kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yaml
-
运行
kubectl get deployments检查 Deployment 是否已创建。 如果仍在创建 Deployment,则输出类似于:NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 0/3 0 0 1s在检查集群中的 Deployment 时,所显示的字段有:
NAME列出了名字空间中 Deployment 的名称。READY显示应用程序的可用的“副本”数。显示的模式是“就绪个数/期望个数”。UP-TO-DATE显示为了达到期望状态已经更新的副本数。AVAILABLE显示应用可供用户使用的副本数。AGE显示应用程序运行的时间。
请注意期望副本数是根据
.spec.replicas字段设置 3。
-
要查看 Deployment 上线状态,运行
kubectl rollout status deployment/nginx-deployment。输出类似于:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated... deployment "nginx-deployment" successfully rolled out
-
几秒钟后再次运行
kubectl get deployments。输出类似于:NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 18s注意 Deployment 已创建全部三个副本,并且所有副本都是最新的(它们包含最新的 Pod 模板) 并且可用。
-
要查看 Deployment 创建的 ReplicaSet(
rs),运行kubectl get rs。 输出类似于:NAME DESIRED CURRENT READY AGE nginx-deployment-75675f5897 3 3 3 18sReplicaSet 输出中包含以下字段:
NAME列出名字空间中 ReplicaSet 的名称;DESIRED显示应用的期望副本个数,即在创建 Deployment 时所定义的值。 此为期望状态;CURRENT显示当前运行状态中的副本个数;READY显示应用中有多少副本可以为用户提供服务;AGE显示应用已经运行的时间长度。
注意 ReplicaSet 的名称格式始终为
[Deployment 名称]-[哈希]。 该名称将成为所创建的 Pod 的命名基础。 其中的哈希字符串与 ReplicaSet 上的pod-template-hash标签一致。
-
要查看每个 Pod 自动生成的标签,运行
kubectl get pods --show-labels。 输出类似于:NAME READY STATUS RESTARTS AGE LABELS nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897 nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897 nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897所创建的 ReplicaSet 确保总是存在三个
nginxPod。
说明:
你必须在 Deployment 中指定适当的选择算符和 Pod 模板标签(在本例中为 app: nginx)。
标签或者选择算符不要与其他控制器(包括其他 Deployment 和 StatefulSet)重叠。
Kubernetes 不会阻止你这样做,但是如果多个控制器具有重叠的选择算符,
它们可能会发生冲突执行难以预料的操作。
Pod-template-hash 标签
注意:
不要更改此标签。
Deployment 控制器将 pod-template-hash 标签添加到 Deployment
所创建或收留的每个 ReplicaSet 。
此标签可确保 Deployment 的子 ReplicaSet 不重叠。
标签是通过对 ReplicaSet 的 PodTemplate 进行哈希处理。
所生成的哈希值被添加到 ReplicaSet 选择算符、Pod 模板标签,并存在于在 ReplicaSet
可能拥有的任何现有 Pod 中。
更新 Deployment
说明:
仅当 Deployment Pod 模板(即 .spec.template)发生改变时,例如模板的标签或容器镜像被更新,
才会触发 Deployment 上线。其他更新(如对 Deployment 执行扩缩容的操作)不会触发上线动作。
按照以下步骤更新 Deployment:
-
先来更新 nginx Pod 以使用
nginx:1.16.1镜像,而不是nginx:1.14.2镜像。kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1或者使用下面的命令:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1在这里,
deployment/nginx-deployment表明 Deployment 的名称,nginx表明需要进行更新的容器, 而nginx:1.16.1则表示镜像的新版本以及它的标签。输出类似于:
deployment.apps/nginx-deployment image updated或者,可以对 Deployment 执行
edit操作并将.spec.template.spec.containers[0].image从nginx:1.14.2更改至nginx:1.16.1。kubectl edit deployment/nginx-deployment输出类似于:
deployment.apps/nginx-deployment edited
-
要查看上线状态,运行:
kubectl rollout status deployment/nginx-deployment输出类似于:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...或者
deployment "nginx-deployment" successfully rolled out
获取关于已更新的 Deployment 的更多信息:
-
在上线成功后,可以通过运行
kubectl get deployments来查看 Deployment: 输出类似于:NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 36s
-
运行
kubectl get rs以查看 Deployment 通过创建新的 ReplicaSet 并将其扩容到 3 个副本并将旧 ReplicaSet 缩容到 0 个副本完成了 Pod 的更新操作:kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-deployment-1564180365 3 3 3 6s nginx-deployment-2035384211 0 0 0 36s
-
现在运行
get pods应仅显示新的 Pod:kubectl get pods输出类似于:
NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-khku8 1/1 Running 0 14s nginx-deployment-1564180365-nacti 1/1 Running 0 14s nginx-deployment-1564180365-z9gth 1/1 Running 0 14s下次要更新这些 Pod 时,只需再次更新 Deployment Pod 模板即可。
Deployment 可确保在更新时仅关闭一定数量的 Pod。默认情况下,它确保至少所需 Pod 的 75% 处于运行状态(最大不可用比例为 25%)。
Deployment 还确保仅所创建 Pod 数量只可能比期望 Pod 数高一点点。 默认情况下,它可确保启动的 Pod 个数比期望个数最多多出 125%(最大峰值 25%)。
例如,如果仔细查看上述 Deployment ,将看到它首先创建了一个新的 Pod,然后删除旧的 Pod, 并创建了新的 Pod。它不会杀死旧 Pod,直到有足够数量的新 Pod 已经出现。 在足够数量的旧 Pod 被杀死前并没有创建新 Pod。它确保至少 3 个 Pod 可用, 同时最多总共 4 个 Pod 可用。 当 Deployment 设置为 4 个副本时,Pod 的个数会介于 3 和 5 之间。
-
获取 Deployment 的更多信息
kubectl describe deployments输出类似于:
Name: nginx-deployment Namespace: default CreationTimestamp: Thu, 30 Nov 2017 10:56:25 +0000 Labels: app=nginx Annotations: deployment.kubernetes.io/revision=2 Selector: app=nginx Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True NewReplicaSetAvailable OldReplicaSets: <none> NewReplicaSet: nginx-deployment-1564180365 (3/3 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 2m deployment-controller Scaled up replica set nginx-deployment-2035384211 to 3 Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 1 Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 2 Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 2 Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 1 Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 3 Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 0可以看到,当第一次创建 Deployment 时,它创建了一个 ReplicaSet(
nginx-deployment-2035384211) 并将其直接扩容至 3 个副本。更新 Deployment 时,它创建了一个新的 ReplicaSet (nginx-deployment-1564180365),并将其扩容为 1,等待其就绪;然后将旧 ReplicaSet 缩容到 2, 将新的 ReplicaSet 扩容到 2 以便至少有 3 个 Pod 可用且最多创建 4 个 Pod。 然后,它使用相同的滚动更新策略继续对新的 ReplicaSet 扩容并对旧的 ReplicaSet 缩容。 最后,你将有 3 个可用的副本在新的 ReplicaSet 中,旧 ReplicaSet 将缩容到 0。
说明:
Kubernetes 在计算 availableReplicas 数值时不考虑终止过程中的 Pod,
availableReplicas 的值一定介于 replicas - maxUnavailable 和 replicas + maxSurge 之间。
因此,你可能在上线期间看到 Pod 个数比预期的多,Deployment 所消耗的总的资源也大于
replicas + maxSurge 个 Pod 所用的资源,直到被终止的 Pod 所设置的
terminationGracePeriodSeconds 到期为止。
翻转(多 Deployment 动态更新)
Deployment 控制器每次注意到新的 Deployment 时,都会创建一个 ReplicaSet 以启动所需的 Pod。
如果更新了 Deployment,则控制标签匹配 .spec.selector 但模板不匹配 .spec.template 的 Pod 的现有 ReplicaSet 被缩容。
最终,新的 ReplicaSet 缩放为 .spec.replicas 个副本,
所有旧 ReplicaSet 缩放为 0 个副本。
当 Deployment 正在上线时被更新,Deployment 会针对更新创建一个新的 ReplicaSet 并开始对其扩容,之前正在被扩容的 ReplicaSet 会被翻转,添加到旧 ReplicaSet 列表 并开始缩容。
例如,假定你在创建一个 Deployment 以生成 nginx:1.14.2 的 5 个副本,但接下来
更新 Deployment 以创建 5 个 nginx:1.16.1 的副本,而此时只有 3 个 nginx:1.14.2
副本已创建。在这种情况下,Deployment 会立即开始杀死 3 个 nginx:1.14.2 Pod,
并开始创建 nginx:1.16.1 Pod。它不会等待 nginx:1.14.2 的 5
个副本都创建完成后才开始执行变更动作。
更改标签选择算符
通常不鼓励更新标签选择算符。建议你提前规划选择算符。 在任何情况下,如果需要更新标签选择算符,请格外小心, 并确保自己了解这背后可能发生的所有事情。
说明:
在 API 版本 apps/v1 中,Deployment 标签选择算符在创建后是不可变的。
- 添加选择算符时要求使用新标签更新 Deployment 规约中的 Pod 模板标签,否则将返回验证错误。 此更改是非重叠的,也就是说新的选择算符不会选择使用旧选择算符所创建的 ReplicaSet 和 Pod, 这会导致创建新的 ReplicaSet 时所有旧 ReplicaSet 都会被孤立。
- 选择算符的更新如果更改了某个算符的键名,这会导致与添加算符时相同的行为。
- 删除选择算符的操作会删除从 Deployment 选择算符中删除现有算符。 此操作不需要更改 Pod 模板标签。现有 ReplicaSet 不会被孤立,也不会因此创建新的 ReplicaSet, 但请注意已删除的标签仍然存在于现有的 Pod 和 ReplicaSet 中。
回滚 Deployment
有时,你可能想要回滚 Deployment;例如,当 Deployment 不稳定时(例如进入反复崩溃状态)。 默认情况下,Deployment 的所有上线记录都保留在系统中,以便可以随时回滚 (你可以通过修改修订历史记录限制来更改这一约束)。
说明:
Deployment 被触发上线时,系统就会创建 Deployment 的新的修订版本。
这意味着仅当 Deployment 的 Pod 模板(.spec.template)发生更改时,才会创建新修订版本
-- 例如,模板的标签或容器镜像发生变化。
其他更新,如 Deployment 的扩缩容操作不会创建 Deployment 修订版本。
这是为了方便同时执行手动缩放或自动缩放。
换言之,当你回滚到较早的修订版本时,只有 Deployment 的 Pod 模板部分会被回滚。
-
假设你在更新 Deployment 时犯了一个拼写错误,将镜像名称命名设置为
nginx:1.161而不是nginx:1.16.1:kubectl set image deployment/nginx-deployment nginx=nginx:1.161输出类似于:
deployment.apps/nginx-deployment image updated
-
此上线进程会出现停滞。你可以通过检查上线状态来验证:
kubectl rollout status deployment/nginx-deployment输出类似于:
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...
- 按 Ctrl-C 停止上述上线状态观测。有关上线停滞的详细信息,参考这里。
-
你可以看到旧的副本(算上来自
nginx-deployment-1564180365和nginx-deployment-2035384211的副本)有 3 个, 新的副本(来自nginx-deployment-3066724191)有 1 个:kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-deployment-1564180365 3 3 3 25s nginx-deployment-2035384211 0 0 0 36s nginx-deployment-3066724191 1 1 0 6s
-
查看所创建的 Pod,你会注意到新 ReplicaSet 所创建的 1 个 Pod 卡顿在镜像拉取循环中。
kubectl get pods输出类似于:
NAME READY STATUS RESTARTS AGE nginx-deployment-1564180365-70iae 1/1 Running 0 25s nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s nginx-deployment-1564180365-hysrc 1/1 Running 0 25s nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6s说明:Deployment 控制器自动停止有问题的上线过程,并停止对新的 ReplicaSet 扩容。 这行为取决于所指定的 rollingUpdate 参数(具体为
maxUnavailable)。 默认情况下,Kubernetes 将此值设置为 25%。
-
获取 Deployment 描述信息:
kubectl describe deployment输出类似于:
Name: nginx-deployment Namespace: default CreationTimestamp: Tue, 15 Mar 2016 14:48:04 -0700 Labels: app=nginx Selector: app=nginx Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.161 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True ReplicaSetUpdated OldReplicaSets: nginx-deployment-1564180365 (3/3 replicas created) NewReplicaSet: nginx-deployment-3066724191 (1/1 replicas created) Events: FirstSeen LastSeen Count From SubObjectPath Type Reason Message --------- -------- ----- ---- ------------- -------- ------ ------- 1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-2035384211 to 3 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 1 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 2 22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 2 21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 1 21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 3 13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 0 13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-3066724191 to 1要解决此问题,需要回滚到以前稳定的 Deployment 版本。
检查 Deployment 上线历史
按照如下步骤检查回滚历史:
-
首先,检查 Deployment 修订历史:
kubectl rollout history deployment/nginx-deployment输出类似于:
deployments "nginx-deployment" REVISION CHANGE-CAUSE 1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml 2 kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 3 kubectl set image deployment/nginx-deployment nginx=nginx:1.161CHANGE-CAUSE的内容是从 Deployment 的kubernetes.io/change-cause注解复制过来的。 复制动作发生在修订版本创建时。你可以通过以下方式设置CHANGE-CAUSE消息:- 使用
kubectl annotate deployment/nginx-deployment kubernetes.io/change-cause="image updated to 1.16.1"为 Deployment 添加注解。 - 手动编辑资源的清单。
- 使用
-
要查看修订历史的详细信息,运行:
kubectl rollout history deployment/nginx-deployment --revision=2输出类似于:
deployments "nginx-deployment" revision 2 Labels: app=nginx pod-template-hash=1159050644 Annotations: kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP QoS Tier: cpu: BestEffort memory: BestEffort Environment Variables: <none> No volumes.
回滚到之前的修订版本
按照下面给出的步骤将 Deployment 从当前版本回滚到以前的版本(即版本 2)。
-
假定现在你已决定撤消当前上线并回滚到以前的修订版本:
kubectl rollout undo deployment/nginx-deployment输出类似于:
deployment.apps/nginx-deployment rolled back或者,你也可以通过使用
--to-revision来回滚到特定修订版本:kubectl rollout undo deployment/nginx-deployment --to-revision=2输出类似于:
deployment.apps/nginx-deployment rolled back与回滚相关的指令的更详细信息,请参考
kubectl rollout。现在,Deployment 正在回滚到以前的稳定版本。正如你所看到的,Deployment 控制器生成了回滚到修订版本 2 的
DeploymentRollback事件。
-
检查回滚是否成功以及 Deployment 是否正在运行,运行:
kubectl get deployment nginx-deployment输出类似于:
NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 30m
-
获取 Deployment 描述信息:
kubectl describe deployment nginx-deployment输出类似于:
Name: nginx-deployment Namespace: default CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500 Labels: app=nginx Annotations: deployment.kubernetes.io/revision=4 kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 Selector: app=nginx Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.16.1 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available True MinimumReplicasAvailable Progressing True NewReplicaSetAvailable OldReplicaSets: <none> NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3 Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0 Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1 Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2 Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0
缩放 Deployment
你可以使用如下指令缩放 Deployment:
kubectl scale deployment/nginx-deployment --replicas=10
输出类似于:
deployment.apps/nginx-deployment scaled
假设集群启用了Pod 的水平自动缩放, 你可以为 Deployment 设置自动缩放器,并基于现有 Pod 的 CPU 利用率选择要运行的 Pod 个数下限和上限。
kubectl autoscale deployment/nginx-deployment --min=10 --max=15 --cpu-percent=80
输出类似于:
deployment.apps/nginx-deployment scaled
比例缩放
RollingUpdate 的 Deployment 支持同时运行应用程序的多个版本。 当自动缩放器缩放处于上线进程(仍在进行中或暂停)中的 RollingUpdate Deployment 时, Deployment 控制器会平衡现有的活跃状态的 ReplicaSet(含 Pod 的 ReplicaSet)中的额外副本, 以降低风险。这称为 比例缩放(Proportional Scaling)。
例如,你正在运行一个 10 个副本的 Deployment,其 maxSurge=3,maxUnavailable=2。
-
确保 Deployment 的这 10 个副本都在运行。
kubectl get deploy输出类似于:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 10 10 10 10 50s
-
更新 Deployment 使用新镜像,碰巧该镜像无法从集群内部解析。
kubectl set image deployment/nginx-deployment nginx=nginx:sometag输出类似于:
deployment.apps/nginx-deployment image updated
-
镜像更新使用 ReplicaSet
nginx-deployment-1989198191启动新的上线过程, 但由于上面提到的maxUnavailable要求,该进程被阻塞了。检查上线状态:kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-deployment-1989198191 5 5 0 9s nginx-deployment-618515232 8 8 8 1m
- 然后,出现了新的 Deployment 扩缩请求。自动缩放器将 Deployment 副本增加到 15。 Deployment 控制器需要决定在何处添加 5 个新副本。如果未使用比例缩放,所有 5 个副本 都将添加到新的 ReplicaSet 中。使用比例缩放时,可以将额外的副本分布到所有 ReplicaSet。 较大比例的副本会被添加到拥有最多副本的 ReplicaSet,而较低比例的副本会进入到 副本较少的 ReplicaSet。所有剩下的副本都会添加到副本最多的 ReplicaSet。 具有零副本的 ReplicaSet 不会被扩容。
在上面的示例中,3 个副本被添加到旧 ReplicaSet 中,2 个副本被添加到新 ReplicaSet。 假定新的副本都很健康,上线过程最终应将所有副本迁移到新的 ReplicaSet 中。 要确认这一点,请运行:
kubectl get deploy
输出类似于:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7m
上线状态确认了副本是如何被添加到每个 ReplicaSet 的。
kubectl get rs
输出类似于:
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7m
暂停、恢复 Deployment 的上线过程
在你更新一个 Deployment 的时候,或者计划更新它的时候, 你可以在触发一个或多个更新之前暂停 Deployment 的上线过程。 当你准备应用这些变更时,你可以重新恢复 Deployment 上线过程。 这样做使得你能够在暂停和恢复执行之间应用多个修补程序,而不会触发不必要的上线操作。
-
例如,对于一个刚刚创建的 Deployment:
获取该 Deployment 信息:
kubectl get deploy输出类似于:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx 3 3 3 3 1m获取上线状态:
kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-2142116321 3 3 3 1m
-
使用如下指令暂停上线:
kubectl rollout pause deployment/nginx-deployment输出类似于:
deployment.apps/nginx-deployment paused
-
接下来更新 Deployment 镜像:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1输出类似于:
deployment.apps/nginx-deployment image updated
-
注意没有新的上线被触发:
kubectl rollout history deployment/nginx-deployment输出类似于:
deployments "nginx" REVISION CHANGE-CAUSE 1 <none>
-
获取上线状态验证现有的 ReplicaSet 没有被更改:
kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-2142116321 3 3 3 2m
-
你可以根据需要执行很多更新操作,例如,可以要使用的资源:
kubectl set resources deployment/nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi输出类似于:
deployment.apps/nginx-deployment resource requirements updated暂停 Deployment 上线之前的初始状态将继续发挥作用,但新的更新在 Deployment 上线被暂停期间不会产生任何效果。
-
最终,恢复 Deployment 上线并观察新的 ReplicaSet 的创建过程,其中包含了所应用的所有更新:
kubectl rollout resume deployment/nginx-deployment输出类似于这样:
deployment.apps/nginx-deployment resumed
-
观察上线的状态,直到完成。
kubectl get rs -w输出类似于:
NAME DESIRED CURRENT READY AGE nginx-2142116321 2 2 2 2m nginx-3926361531 2 2 0 6s nginx-3926361531 2 2 1 18s nginx-2142116321 1 2 2 2m nginx-2142116321 1 2 2 2m nginx-3926361531 3 2 1 18s nginx-3926361531 3 2 1 18s nginx-2142116321 1 1 1 2m nginx-3926361531 3 3 1 18s nginx-3926361531 3 3 2 19s nginx-2142116321 0 1 1 2m nginx-2142116321 0 1 1 2m nginx-2142116321 0 0 0 2m nginx-3926361531 3 3 3 20s
-
获取最近上线的状态:
kubectl get rs输出类似于:
NAME DESIRED CURRENT READY AGE nginx-2142116321 0 0 0 2m nginx-3926361531 3 3 3 28s
说明:
你不可以回滚处于暂停状态的 Deployment,除非先恢复其执行状态。
Deployment 状态
Deployment 的生命周期中会有许多状态。上线新的 ReplicaSet 期间可能处于 Progressing(进行中),可能是 Complete(已完成),也可能是 Failed(失败)以至于无法继续进行。
进行中的 Deployment
执行下面的任务期间,Kubernetes 标记 Deployment 为进行中(Progressing)_:
- Deployment 创建新的 ReplicaSet
- Deployment 正在为其最新的 ReplicaSet 扩容
- Deployment 正在为其旧有的 ReplicaSet(s) 缩容
- 新的 Pod 已经就绪或者可用(就绪至少持续了 MinReadySeconds 秒)。
当上线过程进入“Progressing”状态时,Deployment 控制器会向 Deployment 的
.status.conditions 中添加包含下面属性的状况条目:
type: Progressingstatus: "True"reason: NewReplicaSetCreated|reason: FoundNewReplicaSet|reason: ReplicaSetUpdated
你可以使用 kubectl rollout status 监视 Deployment 的进度。
完成的 Deployment
当 Deployment 具有以下特征时,Kubernetes 将其标记为完成(Complete);
- 与 Deployment 关联的所有副本都已更新到指定的最新版本,这意味着之前请求的所有更新都已完成。
- 与 Deployment 关联的所有副本都可用。
- 未运行 Deployment 的旧副本。
当上线过程进入“Complete”状态时,Deployment 控制器会向 Deployment 的
.status.conditions 中添加包含下面属性的状况条目:
type: Progressingstatus: "True"reason: NewReplicaSetAvailable
这一 Progressing 状况的状态值会持续为 "True",直至新的上线动作被触发。
即使副本的可用状态发生变化(进而影响 Available 状况),Progressing 状况的值也不会变化。
你可以使用 kubectl rollout status 检查 Deployment 是否已完成。
如果上线成功完成,kubectl rollout status 返回退出代码 0。
kubectl rollout status deployment/nginx-deployment
输出类似于:
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deployment" successfully rolled out
从 kubectl rollout 命令获得的返回状态为 0(成功):
echo $?
0
失败的 Deployment
你的 Deployment 可能会在尝试部署其最新的 ReplicaSet 受挫,一直处于未完成状态。 造成此情况一些可能因素如下:
- 配额(Quota)不足
- 就绪探测(Readiness Probe)失败
- 镜像拉取错误
- 权限不足
- 限制范围(Limit Ranges)问题
- 应用程序运行时的配置错误
检测此状况的一种方法是在 Deployment 规约中指定截止时间参数:
(.spec.progressDeadlineSeconds)。
.spec.progressDeadlineSeconds 给出的是一个秒数值,Deployment 控制器在(通过 Deployment 状态)
标示 Deployment 进展停滞之前,需要等待所给的时长。
以下 kubectl 命令设置规约中的 progressDeadlineSeconds,从而告知控制器
在 10 分钟后报告 Deployment 的上线没有进展:
kubectl patch deployment/nginx-deployment -p '{"spec":{"progressDeadlineSeconds":600}}'
输出类似于:
deployment.apps/nginx-deployment patched
超过截止时间后,Deployment 控制器将添加具有以下属性的 Deployment 状况到
Deployment 的 .status.conditions 中:
type: Progressingstatus: "False"reason: ProgressDeadlineExceeded
这一状况也可能会比较早地失败,因而其状态值被设置为 "False",
其原因为 ReplicaSetCreateError。
一旦 Deployment 上线完成,就不再考虑其期限。
参考 Kubernetes API Conventions 获取更多状态状况相关的信息。
说明:
除了报告 Reason=ProgressDeadlineExceeded 状态之外,Kubernetes 对已停止的
Deployment 不执行任何操作。更高级别的编排器可以利用这一设计并相应地采取行动。
例如,将 Deployment 回滚到其以前的版本。
说明:
如果你暂停了某个 Deployment 上线,Kubernetes 不再根据指定的截止时间检查 Deployment 上线的进展。 你可以在上线过程中间安全地暂停 Deployment 再恢复其执行,这样做不会导致超出最后时限的问题。
Deployment 可能会出现瞬时性的错误,可能因为设置的超时时间过短, 也可能因为其他可认为是临时性的问题。例如,假定所遇到的问题是配额不足。 如果描述 Deployment,你将会注意到以下部分:
kubectl describe deployment nginx-deployment
输出类似于:
<...>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
ReplicaFailure True FailedCreate
<...>
如果运行 kubectl get deployment nginx-deployment -o yaml,Deployment 状态输出
将类似于这样:
status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: Replica set "nginx-deployment-4262182780" is progressing.
reason: ReplicaSetUpdated
status: "True"
type: Progressing
- lastTransitionTime: 2016-10-04T12:25:42Z
lastUpdateTime: 2016-10-04T12:25:42Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: 'Error creating: pods "nginx-deployment-4262182780-" is forbidden: exceeded quota:
object-counts, requested: pods=1, used: pods=3, limited: pods=2'
reason: FailedCreate
status: "True"
type: ReplicaFailure
observedGeneration: 3
replicas: 2
unavailableReplicas: 2
最终,一旦超过 Deployment 进度限期,Kubernetes 将更新状态和进度状况的原因:
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreate
可以通过缩容 Deployment 或者缩容其他运行状态的控制器,或者直接在命名空间中增加配额
来解决配额不足的问题。如果配额条件满足,Deployment 控制器完成了 Deployment 上线操作,
Deployment 状态会更新为成功状况(Status=True 和 Reason=NewReplicaSetAvailable)。
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
type: Available 加上 status: True 意味着 Deployment 具有最低可用性。
最低可用性由 Deployment 策略中的参数指定。
type: Progressing 加上 status: True 表示 Deployment 处于上线过程中,并且正在运行,
或者已成功完成进度,最小所需新副本处于可用。
请参阅对应状况的 Reason 了解相关细节。
在我们的案例中 reason: NewReplicaSetAvailable 表示 Deployment 已完成。
你可以使用 kubectl rollout status 检查 Deployment 是否未能取得进展。
如果 Deployment 已超过进度限期,kubectl rollout status 返回非零退出代码。
kubectl rollout status deployment/nginx-deployment
输出类似于:
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
error: deployment "nginx" exceeded its progress deadline
kubectl rollout 命令的退出状态为 1(表明发生了错误):
echo $?
1
对失败 Deployment 的操作
可应用于已完成的 Deployment 的所有操作也适用于失败的 Deployment。 你可以对其执行扩缩容、回滚到以前的修订版本等操作,或者在需要对 Deployment 的 Pod 模板应用多项调整时,将 Deployment 暂停。
清理策略
你可以在 Deployment 中设置 .spec.revisionHistoryLimit 字段以指定保留此
Deployment 的多少个旧有 ReplicaSet。其余的 ReplicaSet 将在后台被垃圾回收。
默认情况下,此值为 10。
说明:
显式将此字段设置为 0 将导致 Deployment 的所有历史记录被清空,因此 Deployment 将无法回滚。
金丝雀部署
如果要使用 Deployment 向用户子集或服务器子集上线版本, 则可以遵循资源管理所描述的金丝雀模式, 创建多个 Deployment,每个版本一个。
编写 Deployment 规约
同其他 Kubernetes 配置一样, Deployment 需要 .apiVersion,.kind 和 .metadata 字段。
有关配置文件的其他信息,请参考部署 Deployment、
配置容器和使用 kubectl 管理资源等相关文档。
当控制面为 Deployment 创建新的 Pod 时,Deployment 的 .metadata.name 是命名这些 Pod 的部分基础。
Deployment 的名称必须是一个合法的
DNS 子域值,
但这会对 Pod 的主机名产生意外的结果。为获得最佳兼容性,名称应遵循更严格的
DNS 标签规则。
Deployment 还需要
.spec 部分。
Pod 模板
.spec 中只有 .spec.template 和 .spec.selector 是必需的字段。
.spec.template 是一个 Pod 模板。
它和 Pod 的语法规则完全相同。
只是这里它是嵌套的,因此不需要 apiVersion 或 kind。
除了 Pod 的必填字段外,Deployment 中的 Pod 模板必须指定适当的标签和适当的重新启动策略。 对于标签,请确保不要与其他控制器重叠。请参考选择算符。
只有 .spec.template.spec.restartPolicy
等于 Always 才是被允许的,这也是在没有指定时的默认设置。
副本
.spec.replicas 是指定所需 Pod 的可选字段。它的默认值是1。
如果你对某个 Deployment 执行了手动扩缩操作(例如,通过
kubectl scale deployment deployment --replicas=X),
之后基于清单对 Deployment 执行了更新操作(例如通过运行
kubectl apply -f deployment.yaml),那么通过应用清单而完成的更新会覆盖之前手动扩缩所作的变更。
如果一个 HorizontalPodAutoscaler
(或者其他执行水平扩缩操作的类似 API)在管理 Deployment 的扩缩,
则不要设置 .spec.replicas。
恰恰相反,应该允许 Kubernetes
控制面来自动管理
.spec.replicas 字段。
选择算符
.spec.selector 是指定本 Deployment 的 Pod
标签选择算符的必需字段。
.spec.selector 必须匹配 .spec.template.metadata.labels,否则请求会被 API 拒绝。
在 API apps/v1版本中,.spec.selector 和 .metadata.labels 如果没有设置的话,
不会被默认设置为 .spec.template.metadata.labels,所以需要明确进行设置。
同时在 apps/v1版本中,Deployment 创建后 .spec.selector 是不可变的。
当 Pod 的标签和选择算符匹配,但其模板和 .spec.template 不同时,或者此类 Pod
的总数超过 .spec.replicas 的设置时,Deployment 会终结之。
如果 Pod 总数未达到期望值,Deployment 会基于 .spec.template 创建新的 Pod。
说明:
你不应直接创建与此选择算符匹配的 Pod,也不应通过创建另一个 Deployment 或者类似于 ReplicaSet 或 ReplicationController 这类控制器来创建标签与此选择算符匹配的 Pod。 如果这样做,第一个 Deployment 会认为它创建了这些 Pod。 Kubernetes 不会阻止你这么做。
如果有多个控制器的选择算符发生重叠,则控制器之间会因冲突而无法正常工作。
策略
.spec.strategy 策略指定用于用新 Pod 替换旧 Pod 的策略。
.spec.strategy.type 可以是 “Recreate” 或 “RollingUpdate”。“RollingUpdate” 是默认值。
重新创建 Deployment
如果 .spec.strategy.type==Recreate,在创建新 Pod 之前,所有现有的 Pod 会被杀死。
说明:
这只会确保为了升级而创建新 Pod 之前其他 Pod 都已终止。如果你升级一个 Deployment, 所有旧版本的 Pod 都会立即被终止。控制器等待这些 Pod 被成功移除之后, 才会创建新版本的 Pod。如果你手动删除一个 Pod,其生命周期是由 ReplicaSet 来控制的, 后者会立即创建一个替换 Pod(即使旧的 Pod 仍然处于 Terminating 状态)。 如果你需要一种“最多 n 个”的 Pod 个数保证,你需要考虑使用 StatefulSet。
滚动更新 Deployment
Deployment 会在 .spec.strategy.type==RollingUpdate时,采取
滚动更新的方式更新 Pod。你可以指定 maxUnavailable 和 maxSurge
来控制滚动更新过程。
最大不可用
.spec.strategy.rollingUpdate.maxUnavailable 是一个可选字段,
用来指定更新过程中不可用的 Pod 的个数上限。该值可以是绝对数字(例如,5),也可以是所需
Pod 的百分比(例如,10%)。百分比值会转换成绝对数并去除小数部分。
如果 .spec.strategy.rollingUpdate.maxSurge 为 0,则此值不能为 0。
默认值为 25%。
例如,当此值设置为 30% 时,滚动更新开始时会立即将旧 ReplicaSet 缩容到期望 Pod 个数的70%。 新 Pod 准备就绪后,可以继续缩容旧有的 ReplicaSet,然后对新的 ReplicaSet 扩容, 确保在更新期间可用的 Pod 总数在任何时候都至少为所需的 Pod 个数的 70%。
最大峰值
.spec.strategy.rollingUpdate.maxSurge 是一个可选字段,用来指定可以创建的超出期望
Pod 个数的 Pod 数量。此值可以是绝对数(例如,5)或所需 Pod 的百分比(例如,10%)。
如果 MaxUnavailable 为 0,则此值不能为 0。百分比值会通过向上取整转换为绝对数。
此字段的默认值为 25%。
例如,当此值为 30% 时,启动滚动更新后,会立即对新的 ReplicaSet 扩容,同时保证新旧 Pod 的总数不超过所需 Pod 总数的 130%。一旦旧 Pod 被杀死,新的 ReplicaSet 可以进一步扩容, 同时确保更新期间的任何时候运行中的 Pod 总数最多为所需 Pod 总数的 130%。
以下是一些使用 maxUnavailable 和 maxSurge 的滚动更新 Deployment 的示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
进度期限秒数
.spec.progressDeadlineSeconds 是一个可选字段,用于指定系统在报告 Deployment
进展失败之前等待 Deployment 取得进展的秒数。
这类报告会在资源状态中体现为 type: Progressing、status: False、
reason: ProgressDeadlineExceeded。Deployment 控制器将在默认 600 毫秒内持续重试 Deployment。
将来,一旦实现了自动回滚,Deployment 控制器将在探测到这样的条件时立即回滚 Deployment。
如果指定,则此字段值需要大于 .spec.minReadySeconds 取值。
最短就绪时间
.spec.minReadySeconds 是一个可选字段,用于指定新创建的 Pod
在没有任意容器崩溃情况下的最小就绪时间,
只有超出这个时间 Pod 才被视为可用。默认值为 0(Pod 在准备就绪后立即将被视为可用)。
要了解何时 Pod 被视为就绪,
可参考容器探针。
修订历史限制
Deployment 的修订历史记录存储在它所控制的 ReplicaSet 中。
.spec.revisionHistoryLimit 是一个可选字段,用来设定出于回滚目的所要保留的旧 ReplicaSet 数量。
这些旧 ReplicaSet 会消耗 etcd 中的资源,并占用 kubectl get rs 的输出。
每个 Deployment 修订版本的配置都存储在其 ReplicaSet 中;因此,一旦删除了旧的 ReplicaSet,
将失去回滚到 Deployment 的对应修订版本的能力。
默认情况下,系统保留 10 个旧 ReplicaSet,但其理想值取决于新 Deployment 的频率和稳定性。
更具体地说,将此字段设置为 0 意味着将清理所有具有 0 个副本的旧 ReplicaSet。 在这种情况下,无法撤消新的 Deployment 上线,因为它的修订历史被清除了。
paused(暂停的)
.spec.paused 是用于暂停和恢复 Deployment 的可选布尔字段。
暂停的 Deployment 和未暂停的 Deployment 的唯一区别是,Deployment 处于暂停状态时,
PodTemplateSpec 的任何修改都不会触发新的上线。
Deployment 在创建时是默认不会处于暂停状态。
接下来
- 进一步了解 Pod。
- 使用 Deployment 运行一个无状态应用。
- 阅读 Deployment, 以了解 Deployment API 的细节。
- 阅读 PodDisruptionBudget 了解如何使用它来在可能出现干扰的情况下管理应用的可用性。
- 使用 kubectl 来创建一个 Deployment。
4.2.2 - ReplicaSet
ReplicaSet 的作用是维持在任何给定时间运行的一组稳定的副本 Pod。 通常,你会定义一个 Deployment,并用这个 Deployment 自动管理 ReplicaSet。
ReplicaSet 的目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的 Pod 的可用性。
ReplicaSet 的工作原理
ReplicaSet 是通过一组字段来定义的,包括一个用来识别可获得的 Pod 的集合的选择算符、一个用来标明应该维护的副本个数的数值、一个用来指定应该创建新 Pod 以满足副本个数条件时要使用的 Pod 模板等等。 每个 ReplicaSet 都通过根据需要创建和删除 Pod 以使得副本个数达到期望值, 进而实现其存在价值。当 ReplicaSet 需要创建新的 Pod 时,会使用所提供的 Pod 模板。
ReplicaSet 通过 Pod 上的 metadata.ownerReferences 字段连接到附属 Pod,该字段给出当前对象的属主资源。 ReplicaSet 所获得的 Pod 都在其 ownerReferences 字段中包含了属主 ReplicaSet 的标识信息。正是通过这一连接,ReplicaSet 知道它所维护的 Pod 集合的状态, 并据此计划其操作行为。
ReplicaSet 使用其选择算符来辨识要获得的 Pod 集合。如果某个 Pod 没有 OwnerReference 或者其 OwnerReference 不是一个控制器, 且其匹配到某 ReplicaSet 的选择算符,则该 Pod 立即被此 ReplicaSet 获得。
何时使用 ReplicaSet
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行。 然而,Deployment 是一个更高级的概念,它管理 ReplicaSet,并向 Pod 提供声明式的更新以及许多其他有用的功能。 因此,我们建议使用 Deployment 而不是直接使用 ReplicaSet, 除非你需要自定义更新业务流程或根本不需要更新。
这实际上意味着,你可能永远不需要操作 ReplicaSet 对象:而是使用 Deployment,并在 spec 部分定义你的应用。
示例
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# 按你的实际情况修改副本数
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
将此清单保存到 frontend.yaml 中,并将其提交到 Kubernetes 集群,
就能创建 yaml 文件所定义的 ReplicaSet 及其管理的 Pod。
kubectl apply -f https://kubernetes.io/examples/controllers/frontend.yaml
你可以看到当前被部署的 ReplicaSet:
kubectl get rs
并看到你所创建的前端:
NAME DESIRED CURRENT READY AGE
frontend 3 3 3 6s
你也可以查看 ReplicaSet 的状态:
kubectl describe rs/frontend
你会看到类似如下的输出:
Name: frontend
Namespace: default
Selector: tier=frontend
Labels: app=guestbook
tier=frontend
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"ReplicaSet","metadata":{"annotations":{},"labels":{"app":"guestbook","tier":"frontend"},"name":"frontend",...
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: tier=frontend
Containers:
php-redis:
Image: gcr.io/google_samples/gb-frontend:v3
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 117s replicaset-controller Created pod: frontend-wtsmm
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-b2zdv
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-vcmts
最后可以查看启动了的 Pod 集合:
kubectl get pods
你会看到类似如下的 Pod 信息:
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 6m36s
frontend-vcmts 1/1 Running 0 6m36s
frontend-wtsmm 1/1 Running 0 6m36s
你也可以查看 Pod 的属主引用被设置为前端的 ReplicaSet。 要实现这点,可取回运行中的某个 Pod 的 YAML:
kubectl get pods frontend-b2zdv -o yaml
输出将类似这样,frontend ReplicaSet 的信息被设置在 metadata 的
ownerReferences 字段中:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-02-12T07:06:16Z"
generateName: frontend-
labels:
tier: frontend
name: frontend-b2zdv
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: frontend
uid: f391f6db-bb9b-4c09-ae74-6a1f77f3d5cf
...
非模板 Pod 的获得
尽管你完全可以直接创建裸的 Pod,强烈建议你确保这些裸的 Pod 并不包含可能与你的某个 ReplicaSet 的选择算符相匹配的标签。原因在于 ReplicaSet 并不仅限于拥有在其模板中设置的 Pod,它还可以像前面小节中所描述的那样获得其他 Pod。
以前面的 frontend ReplicaSet 为例,并在以下清单中指定这些 Pod:
apiVersion: v1
kind: Pod
metadata:
name: pod1
labels:
tier: frontend
spec:
containers:
- name: hello1
image: gcr.io/google-samples/hello-app:2.0
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
labels:
tier: frontend
spec:
containers:
- name: hello2
image: gcr.io/google-samples/hello-app:1.0
由于这些 Pod 没有控制器(Controller,或其他对象)作为其属主引用, 并且其标签与 frontend ReplicaSet 的选择算符匹配,它们会立即被该 ReplicaSet 获取。
假定你在 frontend ReplicaSet 已经被部署之后创建 Pod,并且你已经在 ReplicaSet 中设置了其初始的 Pod 副本数以满足其副本计数需要:
kubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yaml
新的 Pod 会被该 ReplicaSet 获取,并立即被 ReplicaSet 终止, 因为它们的存在会使得 ReplicaSet 中 Pod 个数超出其期望值。
取回 Pod:
kubectl get pods
输出显示新的 Pod 或者已经被终止,或者处于终止过程中:
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 10m
frontend-vcmts 1/1 Running 0 10m
frontend-wtsmm 1/1 Running 0 10m
pod1 0/1 Terminating 0 1s
pod2 0/1 Terminating 0 1s
如果你先行创建 Pod:
kubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yaml
之后再创建 ReplicaSet:
kubectl apply -f https://kubernetes.io/examples/controllers/frontend.yaml
你会看到 ReplicaSet 已经获得了该 Pod,并仅根据其规约创建新的 Pod, 直到新的 Pod 和原来的 Pod 的总数达到其预期个数。 这时取回 Pod 列表:
kubectl get pods
将会生成下面的输出:
NAME READY STATUS RESTARTS AGE
frontend-hmmj2 1/1 Running 0 9s
pod1 1/1 Running 0 36s
pod2 1/1 Running 0 36s
采用这种方式,一个 ReplicaSet 中可以包含异质的 Pod 集合。
编写 ReplicaSet 的清单
与所有其他 Kubernetes API 对象一样,ReplicaSet 也需要 apiVersion、kind、和 metadata 字段。
对于 ReplicaSet 而言,其 kind 始终是 ReplicaSet。
当控制平面为 ReplicaSet 创建新的 Pod 时,ReplicaSet
的 .metadata.name 是命名这些 Pod 的部分基础。ReplicaSet 的名称必须是一个合法的
DNS 子域值,
但这可能对 Pod 的主机名产生意外的结果。为获得最佳兼容性,名称应遵循更严格的
DNS 标签规则。
ReplicaSet 也需要
.spec
部分。
Pod 模板
.spec.template 是一个 Pod 模板,
要求设置标签。在 frontend.yaml 示例中,我们指定了标签 tier: frontend。
注意不要将标签与其他控制器的选择算符重叠,否则那些控制器会尝试收养此 Pod。
对于模板的重启策略
字段,.spec.template.spec.restartPolicy,唯一允许的取值是 Always,这也是默认值.
Pod 选择算符
.spec.selector 字段是一个标签选择算符。
如前文中所讨论的,这些是用来标识要被获取的 Pod
的标签。在签名的 frontend.yaml 示例中,选择算符为:
matchLabels:
tier: frontend
在 ReplicaSet 中,.spec.template.metadata.labels 的值必须与 spec.selector
值相匹配,否则该配置会被 API 拒绝。
说明:
对于设置了相同的 .spec.selector,但
.spec.template.metadata.labels 和 .spec.template.spec 字段不同的两个
ReplicaSet 而言,每个 ReplicaSet 都会忽略被另一个 ReplicaSet 所创建的 Pod。
Replicas
你可以通过设置 .spec.replicas 来指定要同时运行的 Pod 个数。
ReplicaSet 创建、删除 Pod 以与此值匹配。
如果你没有指定 .spec.replicas,那么默认值为 1。
使用 ReplicaSet
删除 ReplicaSet 和它的 Pod
要删除 ReplicaSet 和它的所有 Pod,使用
kubectl delete 命令。
默认情况下,垃圾收集器
自动删除所有依赖的 Pod。
当使用 REST API 或 client-go 库时,你必须在 -d 选项中将 propagationPolicy
设置为 Background 或 Foreground。例如:
kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
-H "Content-Type: application/json"
只删除 ReplicaSet
你可以只删除 ReplicaSet 而不影响它的各个 Pod,方法是使用
kubectl delete
命令并设置 --cascade=orphan 选项。
当使用 REST API 或 client-go 库时,你必须将 propagationPolicy 设置为 Orphan。
例如:
kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
-H "Content-Type: application/json"
一旦删除了原来的 ReplicaSet,就可以创建一个新的来替换它。
由于新旧 ReplicaSet 的 .spec.selector 是相同的,新的 ReplicaSet 将接管老的 Pod。
但是,它不会努力使现有的 Pod 与新的、不同的 Pod 模板匹配。
若想要以可控的方式更新 Pod 的规约,可以使用
Deployment
资源,因为 ReplicaSet 并不直接支持滚动更新。
将 Pod 从 ReplicaSet 中隔离
可以通过改变标签来从 ReplicaSet 中移除 Pod。 这种技术可以用来从服务中去除 Pod,以便进行排错、数据恢复等。 以这种方式移除的 Pod 将被自动替换(假设副本的数量没有改变)。
扩缩 ReplicaSet
通过更新 .spec.replicas 字段,ReplicaSet 可以被轻松地进行扩缩。ReplicaSet
控制器能确保匹配标签选择器的数量的 Pod 是可用的和可操作的。
在降低集合规模时,ReplicaSet 控制器通过对可用的所有 Pod 进行排序来优先选择要被删除的那些 Pod。 其一般性算法如下:
- 首先选择剔除悬决(Pending,且不可调度)的各个 Pod
- 如果设置了
controller.kubernetes.io/pod-deletion-cost注解,则注解值较小的优先被裁减掉 - 所处节点上副本个数较多的 Pod 优先于所处节点上副本较少者
- 如果 Pod 的创建时间不同,最近创建的 Pod 优先于早前创建的 Pod 被裁减。
(当
LogarithmicScaleDown这一特性门控 被启用时,创建时间是按整数幂级来分组的)。
如果以上比较结果都相同,则随机选择。
Pod 删除开销
特性状态:
Kubernetes v1.22 [beta]
通过使用 controller.kubernetes.io/pod-deletion-cost
注解,用户可以对 ReplicaSet 缩容时要先删除哪些 Pod 设置偏好。
此注解要设置到 Pod 上,取值范围为 [-2147483648, 2147483647]。 所代表的是删除同一 ReplicaSet 中其他 Pod 相比较而言的开销。 删除开销较小的 Pod 比删除开销较高的 Pod 更容易被删除。
Pod 如果未设置此注解,则隐含的设置值为 0。负值也是可接受的。 如果注解值非法,API 服务器会拒绝对应的 Pod。
此功能特性处于 Beta 阶段,默认被启用。你可以通过为 kube-apiserver 和
kube-controller-manager 设置特性门控
PodDeletionCost 来禁用此功能。
说明:
- 此机制实施时仅是尽力而为,并不能对 Pod 的删除顺序作出任何保证;
- 用户应避免频繁更新注解值,例如根据某观测度量值来更新此注解值是应该避免的。 这样做会在 API 服务器上产生大量的 Pod 更新操作。
使用场景示例
同一应用的不同 Pod 可能其利用率是不同的。在对应用执行缩容操作时,
可能希望移除利用率较低的 Pod。为了避免频繁更新 Pod,应用应该在执行缩容操作之前更新一次
controller.kubernetes.io/pod-deletion-cost 注解值
(将注解值设置为一个与其 Pod 利用率对应的值)。
如果应用自身控制器缩容操作时(例如 Spark 部署的驱动 Pod),这种机制是可以起作用的。
ReplicaSet 作为水平的 Pod 自动扩缩器目标
ReplicaSet 也可以作为水平的 Pod 扩缩器 (HPA) 的目标。也就是说,ReplicaSet 可以被 HPA 自动扩缩。 以下是 HPA 以我们在前一个示例中创建的副本集为目标的示例。
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: frontend-scaler
spec:
scaleTargetRef:
kind: ReplicaSet
name: frontend
minReplicas: 3
maxReplicas: 10
targetCPUUtilizationPercentage: 50
将这个列表保存到 hpa-rs.yaml 并提交到 Kubernetes 集群,就能创建它所定义的
HPA,进而就能根据复制的 Pod 的 CPU 利用率对目标 ReplicaSet 进行自动扩缩。
kubectl apply -f https://k8s.io/examples/controllers/hpa-rs.yaml
或者,可以使用 kubectl autoscale 命令完成相同的操作(而且它更简单!)
kubectl autoscale rs frontend --max=10 --min=3 --cpu-percent=50
ReplicaSet 的替代方案
Deployment(推荐)
Deployment 是一个可以拥有
ReplicaSet 并使用声明式方式在服务器端完成对 Pod 滚动更新的对象。
尽管 ReplicaSet 可以独立使用,目前它们的主要用途是提供给 Deployment 作为编排
Pod 创建、删除和更新的一种机制。当使用 Deployment 时,你不必关心如何管理它所创建的
ReplicaSet,Deployment 拥有并管理其 ReplicaSet。
因此,建议你在需要 ReplicaSet 时使用 Deployment。
裸 Pod
与用户直接创建 Pod 的情况不同,ReplicaSet 会替换那些由于某些原因被删除或被终止的 Pod,例如在节点故障或破坏性的节点维护(如内核升级)的情况下。 因为这个原因,我们建议你使用 ReplicaSet,即使应用程序只需要一个 Pod。 想像一下,ReplicaSet 类似于进程监视器,只不过它在多个节点上监视多个 Pod, 而不是在单个节点上监视单个进程。 ReplicaSet 将本地容器重启的任务委托给了节点上的某个代理(例如,Kubelet)去完成。
Job
使用Job 代替 ReplicaSet,
可以用于那些期望自行终止的 Pod。
DaemonSet
对于管理那些提供主机级别功能(如主机监控和主机日志)的容器,
就要用 DaemonSet
而不用 ReplicaSet。
这些 Pod 的寿命与主机寿命有关:这些 Pod 需要先于主机上的其他 Pod 运行,
并且在机器准备重新启动/关闭时安全地终止。
ReplicationController
ReplicaSet 是 ReplicationController 的后继者。二者目的相同且行为类似,只是 ReplicationController 不支持 标签用户指南 中讨论的基于集合的选择算符需求。 因此,相比于 ReplicationController,应优先考虑 ReplicaSet。
接下来
- 了解 Pod。
- 了解 Deployment。
- 使用 Deployment 运行一个无状态应用, 它依赖于 ReplicaSet。
ReplicaSet是 Kubernetes REST API 中的顶级资源。阅读 ReplicaSet 对象定义理解关于该资源的 API。- 阅读 Pod 干扰预算(Disruption Budget), 了解如何在干扰下运行高度可用的应用。
4.2.3 - StatefulSet
StatefulSet 运行一组 Pod,并为每个 Pod 保留一个稳定的标识。 这可用于管理需要持久化存储或稳定、唯一网络标识的应用。
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。
和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
如果希望使用存储卷为工作负载提供持久存储,可以使用 StatefulSet 作为解决方案的一部分。 尽管 StatefulSet 中的单个 Pod 仍可能出现故障, 但持久的 Pod 标识符使得将现有卷与替换已失败 Pod 的新 Pod 相匹配变得更加容易。
使用 StatefulSet
StatefulSet 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和扩缩。
- 有序的、自动的滚动更新。
在上面描述中,“稳定的”意味着 Pod 调度或重调度的整个过程是有持久性的。 如果应用程序不需要任何稳定的标识符或有序的部署、删除或扩缩, 则应该使用由一组无状态的副本控制器提供的工作负载来部署应用程序,比如 Deployment 或者 ReplicaSet 可能更适用于你的无状态应用部署需要。
限制
- 给定 Pod 的存储必须由
PersistentVolume Provisioner
基于所请求的
storage class来制备,或者由管理员预先制备。 - 删除或者扩缩 StatefulSet 并不会删除它关联的存储卷。 这样做是为了保证数据安全,它通常比自动清除 StatefulSet 所有相关的资源更有价值。
- StatefulSet 当前需要无头服务来负责 Pod 的网络标识。你需要负责创建此服务。
- 当删除一个 StatefulSet 时,该 StatefulSet 不提供任何终止 Pod 的保证。 为了实现 StatefulSet 中的 Pod 可以有序且体面地终止,可以在删除之前将 StatefulSet 缩容到 0。
- 在默认 Pod 管理策略(
OrderedReady) 时使用滚动更新, 可能进入需要人工干预才能修复的损坏状态。
组件
下面的示例演示了 StatefulSet 的组件。
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # 必须匹配 .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # 默认值是 1
minReadySeconds: 10 # 默认值是 0
template:
metadata:
labels:
app: nginx # 必须匹配 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
说明:
这个示例出于简化考虑使用了 ReadWriteOnce 访问模式。但对于生产环境,
Kubernetes 项目建议使用 ReadWriteOncePod 访问模式。
上述例子中:
- 名为
nginx的 Headless Service 用来控制网络域名。 - 名为
web的 StatefulSet 有一个 Spec,它表明将在独立的 3 个 Pod 副本中启动 nginx 容器。 volumeClaimTemplates将通过 PersistentVolume 制备程序所准备的 PersistentVolumes 来提供稳定的存储。
StatefulSet 的命名需要遵循 DNS 标签规范。
Pod 选择算符
你必须设置 StatefulSet 的 .spec.selector 字段,使之匹配其在
.spec.template.metadata.labels 中设置的标签。
未指定匹配的 Pod 选择算符将在创建 StatefulSet 期间导致验证错误。
卷申领模板
你可以设置 .spec.volumeClaimTemplates,
它可以使用 PersistentVolume 制备程序所准备的
PersistentVolumes 来提供稳定的存储。
最短就绪秒数
特性状态:
Kubernetes v1.25 [stable]
.spec.minReadySeconds 是一个可选字段。
它指定新创建的 Pod 应该在没有任何容器崩溃的情况下运行并准备就绪,才能被认为是可用的。
这用于在使用滚动更新策略时检查滚动的进度。
该字段默认为 0(Pod 准备就绪后将被视为可用)。
要了解有关何时认为 Pod 准备就绪的更多信息,
请参阅容器探针。
Pod 标识
StatefulSet Pod 具有唯一的标识,该标识包括顺序标识、稳定的网络标识和稳定的存储。 该标识和 Pod 是绑定的,与该 Pod 调度到哪个节点上无关。
序号索引
对于具有 N 个副本的 StatefulSet,该 StatefulSet 中的每个 Pod 将被分配一个整数序号,
该序号在此 StatefulSet 中是唯一的。默认情况下,这些 Pod 将被赋予从 0 到 N-1 的序号。
StatefulSet 的控制器也会添加一个包含此索引的 Pod 标签:apps.kubernetes.io/pod-index。
起始序号
特性状态:
Kubernetes v1.27 [beta]
.spec.ordinals 是一个可选的字段,允许你配置分配给每个 Pod 的整数序号。
该字段默认为 nil 值。你必须启用 StatefulSetStartOrdinal
特性门控才能使用此字段。
一旦启用,你就可以配置以下选项:
.spec.ordinals.start:如果.spec.ordinals.start字段被设置,则 Pod 将被分配从.spec.ordinals.start到.spec.ordinals.start + .spec.replicas - 1的序号。
稳定的网络 ID
StatefulSet 中的每个 Pod 根据 StatefulSet 的名称和 Pod 的序号派生出它的主机名。
组合主机名的格式为$(StatefulSet 名称)-$(序号)。
上例将会创建三个名称分别为 web-0、web-1、web-2 的 Pod。
StatefulSet 可以使用无头服务控制它的
Pod 的网络域。管理域的这个服务的格式为:
$(服务名称).$(名字空间).svc.cluster.local,其中 cluster.local 是集群域。
一旦每个 Pod 创建成功,就会得到一个匹配的 DNS 子域,格式为:
$(pod 名称).$(所属服务的 DNS 域名),其中所属服务由 StatefulSet 的 serviceName 域来设定。
取决于集群域内部 DNS 的配置,有可能无法查询一个刚刚启动的 Pod 的 DNS 命名。 当集群内其他客户端在 Pod 创建完成前发出 Pod 主机名查询时,就会发生这种情况。 负缓存 (在 DNS 中较为常见) 意味着之前失败的查询结果会被记录和重用至少若干秒钟, 即使 Pod 已经正常运行了也是如此。
如果需要在 Pod 被创建之后及时发现它们,可使用以下选项:
- 直接查询 Kubernetes API(比如,利用 watch 机制)而不是依赖于 DNS 查询
- 缩短 Kubernetes DNS 驱动的缓存时长(通常这意味着修改 CoreDNS 的 ConfigMap,目前缓存时长为 30 秒)
正如限制中所述, 你需要负责创建无头服务以便为 Pod 提供网络标识。
下面给出一些选择集群域、服务名、StatefulSet 名、及其怎样影响 StatefulSet 的 Pod 上的 DNS 名称的示例:
| 集群域名 | 服务(名字空间/名字) | StatefulSet(名字空间/名字) | StatefulSet 域名 | Pod DNS | Pod 主机名 |
|---|---|---|---|---|---|
| cluster.local | default/nginx | default/web | nginx.default.svc.cluster.local | web-{0..N-1}.nginx.default.svc.cluster.local | web-{0..N-1} |
| cluster.local | foo/nginx | foo/web | nginx.foo.svc.cluster.local | web-{0..N-1}.nginx.foo.svc.cluster.local | web-{0..N-1} |
| kube.local | foo/nginx | foo/web | nginx.foo.svc.kube.local | web-{0..N-1}.nginx.foo.svc.kube.local | web-{0..N-1} |
说明:
集群域会被设置为 cluster.local,除非有其他配置。
稳定的存储
对于 StatefulSet 中定义的每个 VolumeClaimTemplate,每个 Pod 接收到一个 PersistentVolumeClaim。
在上面的 nginx 示例中,每个 Pod 将会得到基于 StorageClass my-storage-class 制备的
1 GiB 的 PersistentVolume。如果没有指定 StorageClass,就会使用默认的 StorageClass。
当一个 Pod 被调度(重新调度)到节点上时,它的 volumeMounts 会挂载与其
PersistentVolumeClaims 相关联的 PersistentVolume。
请注意,当 Pod 或者 StatefulSet 被删除时,与 PersistentVolumeClaims 相关联的
PersistentVolume 并不会被删除。要删除它必须通过手动方式来完成。
Pod 名称标签
当 StatefulSet 控制器创建 Pod 时,
它会添加一个标签 statefulset.kubernetes.io/pod-name,该标签值设置为 Pod 名称。
这个标签允许你给 StatefulSet 中的特定 Pod 绑定一个 Service。
Pod 索引标签
特性状态:
Kubernetes v1.28 [beta]
当 StatefulSet 控制器创建一个 Pod 时,
新的 Pod 会被打上 apps.kubernetes.io/pod-index 标签。标签的取值为 Pod 的序号索引。
此标签使你能够将流量路由到特定索引值的 Pod、使用 Pod 索引标签来过滤日志或度量值等等。
注意要使用这一特性需要启用特性门控 PodIndexLabel,而该门控默认是被启用的。
部署和扩缩保证
- 对于包含 N 个 副本的 StatefulSet,当部署 Pod 时,它们是依次创建的,顺序为
0..N-1。 - 当删除 Pod 时,它们是逆序终止的,顺序为
N-1..0。 - 在将扩缩操作应用到 Pod 之前,它前面的所有 Pod 必须是 Running 和 Ready 状态。
- 在一个 Pod 终止之前,所有的继任者必须完全关闭。
StatefulSet 不应将 pod.Spec.TerminationGracePeriodSeconds 设置为 0。
这种做法是不安全的,要强烈阻止。
更多的解释请参考强制删除 StatefulSet Pod。
在上面的 nginx 示例被创建后,会按照 web-0、web-1、web-2 的顺序部署三个 Pod。 在 web-0 进入 Running 和 Ready 状态前不会部署 web-1。在 web-1 进入 Running 和 Ready 状态前不会部署 web-2。 如果 web-1 已经处于 Running 和 Ready 状态,而 web-2 尚未部署,在此期间发生了 web-0 运行失败,那么 web-2 将不会被部署,要等到 web-0 部署完成并进入 Running 和 Ready 状态后,才会部署 web-2。
如果用户想将示例中的 StatefulSet 扩缩为 replicas=1,首先被终止的是 web-2。
在 web-2 没有被完全停止和删除前,web-1 不会被终止。
当 web-2 已被终止和删除、web-1 尚未被终止,如果在此期间发生 web-0 运行失败,
那么就不会终止 web-1,必须等到 web-0 进入 Running 和 Ready 状态后才会终止 web-1。
Pod 管理策略
StatefulSet 允许你放宽其排序保证,
同时通过它的 .spec.podManagementPolicy 域保持其唯一性和身份保证。
OrderedReady Pod 管理
OrderedReady Pod 管理是 StatefulSet 的默认设置。
它实现了上面描述的功能。
并行 Pod 管理
Parallel Pod 管理让 StatefulSet 控制器并行的启动或终止所有的 Pod,
启动或者终止其他 Pod 前,无需等待 Pod 进入 Running 和 Ready 或者完全停止状态。
这个选项只会影响扩缩操作的行为,更新则不会被影响。
更新策略
StatefulSet 的 .spec.updateStrategy 字段让你可以配置和禁用掉自动滚动更新 Pod
的容器、标签、资源请求或限制、以及注解。有两个允许的值:
OnDelete- 当 StatefulSet 的
.spec.updateStrategy.type设置为OnDelete时, 它的控制器将不会自动更新 StatefulSet 中的 Pod。 用户必须手动删除 Pod 以便让控制器创建新的 Pod,以此来对 StatefulSet 的.spec.template的变动作出反应。 RollingUpdateRollingUpdate更新策略对 StatefulSet 中的 Pod 执行自动的滚动更新。这是默认的更新策略。
滚动更新
当 StatefulSet 的 .spec.updateStrategy.type 被设置为 RollingUpdate 时,
StatefulSet 控制器会删除和重建 StatefulSet 中的每个 Pod。
它将按照与 Pod 终止相同的顺序(从最大序号到最小序号)进行,每次更新一个 Pod。
Kubernetes 控制平面会等到被更新的 Pod 进入 Running 和 Ready 状态,然后再更新其前身。
如果你设置了 .spec.minReadySeconds(查看最短就绪秒数),
控制平面在 Pod 就绪后会额外等待一定的时间再执行下一步。
分区滚动更新
通过声明 .spec.updateStrategy.rollingUpdate.partition 的方式,RollingUpdate
更新策略可以实现分区。
如果声明了一个分区,当 StatefulSet 的 .spec.template 被更新时,
所有序号大于等于该分区序号的 Pod 都会被更新。
所有序号小于该分区序号的 Pod 都不会被更新,并且,即使它们被删除也会依据之前的版本进行重建。
如果 StatefulSet 的 .spec.updateStrategy.rollingUpdate.partition 大于它的
.spec.replicas,则对它的 .spec.template 的更新将不会传递到它的 Pod。
在大多数情况下,你不需要使用分区,但如果你希望进行阶段更新、执行金丝雀或执行分阶段上线,则这些分区会非常有用。
最大不可用 Pod
特性状态:
Kubernetes v1.24 [alpha]
你可以通过指定 .spec.updateStrategy.rollingUpdate.maxUnavailable
字段来控制更新期间不可用的 Pod 的最大数量。
该值可以是绝对值(例如,“5”)或者是期望 Pod 个数的百分比(例如,10%)。
绝对值是根据百分比值四舍五入计算的。
该字段不能为 0。默认设置为 1。
该字段适用于 0 到 replicas - 1 范围内的所有 Pod。
如果在 0 到 replicas - 1 范围内存在不可用 Pod,这类 Pod 将被计入 maxUnavailable 值。
说明:
maxUnavailable 字段处于 Alpha 阶段,仅当 API 服务器启用了 MaxUnavailableStatefulSet
特性门控时才起作用。
强制回滚
在默认 Pod 管理策略(OrderedReady) 下使用滚动更新,
可能进入需要人工干预才能修复的损坏状态。
如果更新后 Pod 模板配置进入无法运行或就绪的状态(例如, 由于错误的二进制文件或应用程序级配置错误),StatefulSet 将停止回滚并等待。
在这种状态下,仅将 Pod 模板还原为正确的配置是不够的。 由于已知问题,StatefulSet 将继续等待损坏状态的 Pod 准备就绪(永远不会发生),然后再尝试将其恢复为正常工作配置。
恢复模板后,还必须删除 StatefulSet 尝试使用错误的配置来运行的 Pod。这样, StatefulSet 才会开始使用被还原的模板来重新创建 Pod。
PersistentVolumeClaim 保留
特性状态:
Kubernetes v1.27 [beta]
在 StatefulSet 的生命周期中,可选字段
.spec.persistentVolumeClaimRetentionPolicy 控制是否删除以及如何删除 PVC。
使用该字段,你必须在 API 服务器和控制器管理器启用 StatefulSetAutoDeletePVC
特性门控。
启用后,你可以为每个 StatefulSet 配置两个策略:
whenDeleted- 配置删除 StatefulSet 时应用的卷保留行为。
whenScaled- 配置当 StatefulSet 的副本数减少时应用的卷保留行为;例如,缩小集合时。
对于你可以配置的每个策略,你可以将值设置为 Delete 或 Retain。
Delete- 对于受策略影响的每个 Pod,基于 StatefulSet 的
volumeClaimTemplate字段创建的 PVC 都会被删除。 使用whenDeleted策略,所有来自volumeClaimTemplate的 PVC 在其 Pod 被删除后都会被删除。 使用whenScaled策略,只有与被缩减的 Pod 副本对应的 PVC 在其 Pod 被删除后才会被删除。
Retain(默认)- 来自
volumeClaimTemplate的 PVC 在 Pod 被删除时不受影响。这是此新功能之前的行为。
请记住,这些策略仅适用于由于 StatefulSet 被删除或被缩小而被删除的 Pod。 例如,如果与 StatefulSet 关联的 Pod 由于节点故障而失败, 并且控制平面创建了替换 Pod,则 StatefulSet 保留现有的 PVC。 现有卷不受影响,集群会将其附加到新 Pod 即将启动的节点上。
策略的默认值为 Retain,与此新功能之前的 StatefulSet 行为相匹配。
这是一个示例策略。
apiVersion: apps/v1
kind: StatefulSet
...
spec:
persistentVolumeClaimRetentionPolicy:
whenDeleted: Retain
whenScaled: Delete
...
StatefulSet 控制器为其 PVC
添加了属主引用,
这些 PVC 在 Pod 终止后被垃圾回收器删除。
这使 Pod 能够在删除 PVC 之前(以及在删除后备 PV 和卷之前,取决于保留策略)干净地卸载所有卷。
当你设置 whenDeleted 删除策略,对 StatefulSet 实例的属主引用放置在与该 StatefulSet 关联的所有 PVC 上。
whenScaled 策略必须仅在 Pod 缩减时删除 PVC,而不是在 Pod 因其他原因被删除时删除。
执行协调操作时,StatefulSet 控制器将其所需的副本数与集群上实际存在的 Pod 进行比较。
对于 StatefulSet 中的所有 Pod 而言,如果其 ID 大于副本数,则将被废弃并标记为需要删除。
如果 whenScaled 策略是 Delete,则在删除 Pod 之前,
首先将已销毁的 Pod 设置为与 StatefulSet 模板对应的 PVC 的属主。
这会导致 PVC 仅在已废弃的 Pod 终止后被垃圾收集。
这意味着如果控制器崩溃并重新启动,在其属主引用更新到适合策略的 Pod 之前,不会删除任何 Pod。 如果在控制器关闭时强制删除了已废弃的 Pod,则属主引用可能已被设置,也可能未被设置,具体取决于控制器何时崩溃。 更新属主引用可能需要几个协调循环,因此一些已废弃的 Pod 可能已经被设置了属主引用,而其他可能没有。 出于这个原因,我们建议等待控制器恢复,控制器将在终止 Pod 之前验证属主引用。 如果这不可行,则操作员应验证 PVC 上的属主引用,以确保在强制删除 Pod 时删除预期的对象。
副本数
.spec.replicas 是一个可选字段,用于指定所需 Pod 的数量。它的默认值为 1。
如果你手动扩缩已部署的负载,例如通过 kubectl scale statefulset statefulset --replicas=X,
然后根据清单更新 StatefulSet(例如:通过运行 kubectl apply -f statefulset.yaml),
那么应用该清单的操作会覆盖你之前所做的手动扩缩。
如果 HorizontalPodAutoscaler
(或任何类似的水平扩缩 API)正在管理 StatefulSet 的扩缩,
请不要设置 .spec.replicas。
相反,允许 Kubernetes 控制平面自动管理 .spec.replicas 字段。
接下来
- 了解 Pod。
- 了解如何使用 StatefulSet
- 跟随示例部署有状态应用。
- 跟随示例使用 StatefulSet 部署 Cassandra。
- 跟随示例运行多副本的有状态应用程序。
- 了解如何扩缩 StatefulSet。
- 了解删除 StatefulSet涉及到的操作。
- 了解如何配置 Pod 以使用卷进行存储。
- 了解如何配置 Pod 以使用 PersistentVolume 作为存储。
StatefulSet是 Kubernetes REST API 中的顶级资源。阅读 StatefulSet 对象定义理解关于该资源的 API。- 阅读 Pod 干扰预算(Disruption Budget),了解如何在干扰下运行高度可用的应用。
4.2.4 - DaemonSet
DaemonSet 定义了提供节点本地设施的 Pod。这些设施可能对于集群的运行至关重要,例如网络辅助工具,或者作为 add-on 的一部分。
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet 的一些典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
一种简单的用法是为每种类型的守护进程在所有的节点上都启动一个 DaemonSet。 一个稍微复杂的用法是为同一种守护进程部署多个 DaemonSet;每个具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求。
编写 DaemonSet Spec
创建 DaemonSet
你可以在 YAML 文件中描述 DaemonSet。 例如,下面的 daemonset.yaml 文件描述了一个运行 fluentd-elasticsearch Docker 镜像的 DaemonSet:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# 这些容忍度设置是为了让该守护进程集在控制平面节点上运行
# 如果你不希望自己的控制平面节点运行 Pod,可以删除它们
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
# 可能需要设置较高的优先级类以确保 DaemonSet Pod 可以抢占正在运行的 Pod
# priorityClassName: important
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
基于 YAML 文件创建 DaemonSet:
kubectl apply -f https://k8s.io/examples/controllers/daemonset.yaml
必需字段
与所有其他 Kubernetes 配置一样,DaemonSet 也需要 apiVersion、kind 和 metadata 字段。
有关使用这些配置文件的通用信息,
参见运行无状态应用和使用 kubectl 管理对象。
DaemonSet 对象的名称必须是一个合法的 DNS 子域名。
DaemonSet 也需要 .spec 节区。
Pod 模板
.spec 中唯一必需的字段是 .spec.template。
.spec.template 是一个 Pod 模板。
除了它是嵌套的,因而不具有 apiVersion 或 kind 字段之外,它与
Pod 具有相同的 schema。
除了 Pod 必需字段外,在 DaemonSet 中的 Pod 模板必须指定合理的标签(查看 Pod 选择算符)。
在 DaemonSet 中的 Pod 模板必须具有一个值为 Always 的
RestartPolicy。
当该值未指定时,默认是 Always。
Pod 选择算符
.spec.selector 字段表示 Pod 选择算符,它与
Job 的 .spec.selector 的作用是相同的。
你必须指定与 .spec.template 的标签匹配的 Pod 选择算符。
此外,一旦创建了 DaemonSet,它的 .spec.selector 就不能修改。
修改 Pod 选择算符可能导致 Pod 意外悬浮,并且这对用户来说是费解的。
spec.selector 是一个对象,如下两个字段组成:
matchLabels- 与 ReplicationController 的.spec.selector的作用相同。matchExpressions- 允许构建更加复杂的选择器,可以通过指定 key、value 列表以及将 key 和 value 列表关联起来的 Operator。
当上述两个字段都指定时,结果会按逻辑与(AND)操作处理。
.spec.selector 必须与 .spec.template.metadata.labels 相匹配。
如果配置中这两个字段不匹配,则会被 API 拒绝。
在选定的节点上运行 Pod
如果指定了 .spec.template.spec.nodeSelector,DaemonSet 控制器将在能够与
Node 选择算符匹配的节点上创建 Pod。
类似这种情况,可以指定 .spec.template.spec.affinity,之后 DaemonSet
控制器将在能够与节点亲和性匹配的节点上创建 Pod。
如果根本就没有指定,则 DaemonSet Controller 将在所有节点上创建 Pod。
Daemon Pods 是如何被调度的
DaemonSet 可用于确保所有符合条件的节点都运行该 Pod 的一个副本。
DaemonSet 控制器为每个符合条件的节点创建一个 Pod,并添加 Pod 的 spec.affinity.nodeAffinity
字段以匹配目标主机。Pod 被创建之后,默认的调度程序通常通过设置 .spec.nodeName 字段来接管 Pod 并将
Pod 绑定到目标主机。如果新的 Pod 无法放在节点上,则默认的调度程序可能会根据新 Pod
的优先级抢占
(驱逐)某些现存的 Pod。
说明:
当 DaemonSet 中的 Pod 必须运行在每个节点上时,通常需要将 DaemonSet
的 .spec.template.spec.priorityClassName 设置为具有更高优先级的
PriorityClass,
以确保可以完成驱逐。
用户通过设置 DaemonSet 的 .spec.template.spec.schedulerName 字段,可以为 DaemonSet
的 Pod 指定不同的调度程序。
当评估符合条件的节点时,原本在 .spec.template.spec.affinity.nodeAffinity 字段上指定的节点亲和性将由
DaemonSet 控制器进行考量,但在创建的 Pod 上会被替换为与符合条件的节点名称匹配的节点亲和性。
ScheduleDaemonSetPods 允许你使用默认调度器而不是 DaemonSet 控制器来调度这些 DaemonSet,
方法是将 NodeAffinity 条件而不是 .spec.nodeName 条件添加到这些 DaemonSet Pod。
默认调度器接下来将 Pod 绑定到目标主机。
如果 DaemonSet Pod 的节点亲和性配置已存在,则被替换
(原始的节点亲和性配置在选择目标主机之前被考虑)。
DaemonSet 控制器仅在创建或修改 DaemonSet Pod 时执行这些操作,
并且不会更改 DaemonSet 的 spec.template。
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- target-host-name
污点和容忍度
DaemonSet 控制器会自动将一组容忍度添加到 DaemonSet Pod:
| 容忍度键名 | 效果 | 描述 |
|---|---|---|
node.kubernetes.io/not-ready |
NoExecute |
DaemonSet Pod 可以被调度到不健康或还不准备接受 Pod 的节点上。在这些节点上运行的所有 DaemonSet Pod 将不会被驱逐。 |
node.kubernetes.io/unreachable |
NoExecute |
DaemonSet Pod 可以被调度到从节点控制器不可达的节点上。在这些节点上运行的所有 DaemonSet Pod 将不会被驱逐。 |
node.kubernetes.io/disk-pressure |
NoSchedule |
DaemonSet Pod 可以被调度到具有磁盘压力问题的节点上。 |
node.kubernetes.io/memory-pressure |
NoSchedule |
DaemonSet Pod 可以被调度到具有内存压力问题的节点上。 |
node.kubernetes.io/pid-pressure |
NoSchedule |
DaemonSet Pod 可以被调度到具有进程压力问题的节点上。 |
node.kubernetes.io/unschedulable |
NoSchedule |
DaemonSet Pod 可以被调度到不可调度的节点上。 |
node.kubernetes.io/network-unavailable |
NoSchedule |
仅针对请求主机联网的 DaemonSet Pod 添加此容忍度,即 Pod 具有 spec.hostNetwork: true。这些 DaemonSet Pod 可以被调度到网络不可用的节点上。 |
你也可以在 DaemonSet 的 Pod 模板中定义自己的容忍度并将其添加到 DaemonSet Pod。
因为 DaemonSet 控制器自动设置 node.kubernetes.io/unschedulable:NoSchedule 容忍度,
所以 Kubernetes 可以在标记为不可调度的节点上运行 DaemonSet Pod。
如果你使用 DaemonSet 提供重要的节点级别功能, 例如集群联网, Kubernetes 在节点就绪之前将 DaemonSet Pod 放到节点上会很有帮助。 例如,如果没有这种特殊的容忍度,因为网络插件未在节点上运行,所以你可能会在未标记为就绪的节点上陷入死锁状态, 同时因为该节点还未就绪,所以网络插件不会在该节点上运行。
与 Daemon Pod 通信
与 DaemonSet 中的 Pod 进行通信的几种可能模式如下:
-
推送(Push):配置 DaemonSet 中的 Pod,将更新发送到另一个服务,例如统计数据库。 这些服务没有客户端。
-
NodeIP 和已知端口:DaemonSet 中的 Pod 可以使用
hostPort,从而可以通过节点 IP 访问到 Pod。客户端能通过某种方法获取节点 IP 列表,并且基于此也可以获取到相应的端口。 -
DNS:创建具有相同 Pod 选择算符的无头服务, 通过使用
endpoints资源或从 DNS 中检索到多个 A 记录来发现 DaemonSet。 -
Service:创建具有相同 Pod 选择算符的服务,并使用该服务随机访问到某个节点上的守护进程(没有办法访问到特定节点)。
更新 DaemonSet
如果节点的标签被修改,DaemonSet 将立刻向新匹配上的节点添加 Pod, 同时删除不匹配的节点上的 Pod。
你可以修改 DaemonSet 创建的 Pod。不过并非 Pod 的所有字段都可更新。 下次当某节点(即使具有相同的名称)被创建时,DaemonSet 控制器还会使用最初的模板。
你可以删除一个 DaemonSet。如果使用 kubectl 并指定 --cascade=orphan 选项,
则 Pod 将被保留在节点上。接下来如果创建使用相同选择算符的新 DaemonSet,
新的 DaemonSet 会收养已有的 Pod。
如果有 Pod 需要被替换,DaemonSet 会根据其 updateStrategy 来替换。
你可以对 DaemonSet 执行滚动更新操作。
DaemonSet 的替代方案
init 脚本
直接在节点上启动守护进程(例如使用 init、upstartd 或 systemd)的做法当然是可行的。
不过,基于 DaemonSet 来运行这些进程有如下一些好处:
-
像所运行的其他应用一样,DaemonSet 具备为守护进程提供监控和日志管理的能力。
-
为守护进程和应用所使用的配置语言和工具(如 Pod 模板、
kubectl)是相同的。 -
在资源受限的容器中运行守护进程能够增加守护进程和应用容器的隔离性。 然而,这一点也可以通过在容器中运行守护进程但却不在 Pod 中运行之来实现。
裸 Pod
直接创建 Pod并指定其运行在特定的节点上也是可以的。 然而,DaemonSet 能够替换由于任何原因(例如节点失败、例行节点维护、内核升级) 而被删除或终止的 Pod。 由于这个原因,你应该使用 DaemonSet 而不是单独创建 Pod。
静态 Pod
通过在一个指定的、受 kubelet 监视的目录下编写文件来创建 Pod 也是可行的。
这类 Pod 被称为静态 Pod。
不像 DaemonSet,静态 Pod 不受 kubectl 和其它 Kubernetes API 客户端管理。
静态 Pod 不依赖于 API 服务器,这使得它们在启动引导新集群的情况下非常有用。
此外,静态 Pod 在将来可能会被废弃。
Deployment
DaemonSet 与 Deployment 非常类似, 它们都能创建 Pod,并且 Pod 中的进程都不希望被终止(例如,Web 服务器、存储服务器)。
建议为无状态的服务使用 Deployment,比如前端服务。 对这些服务而言,对副本的数量进行扩缩容、平滑升级,比精确控制 Pod 运行在某个主机上要重要得多。 当需要 Pod 副本总是运行在全部或特定主机上,并且当该 DaemonSet 提供了节点级别的功能(允许其他 Pod 在该特定节点上正确运行)时, 应该使用 DaemonSet。
例如,网络插件通常包含一个以 DaemonSet 运行的组件。 这个 DaemonSet 组件确保它所在的节点的集群网络正常工作。
接下来
- 了解 Pod。
- 了解如何使用 DaemonSet
- 对 DaemonSet 执行滚动更新
- 对 DaemonSet 执行回滚(例如:新的版本没有达到你的预期)
- 理解Kubernetes 如何将 Pod 分配给节点。
- 了解设备插件和 扩展(Addons),它们常以 DaemonSet 运行。
DaemonSet是 Kubernetes REST API 中的顶级资源。阅读 DaemonSet 对象定义理解关于该资源的 API。
4.2.5 - Job
Job 表示一次性任务,运行完成后就会停止。
Job 会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pod。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。
一种简单的使用场景下,你会创建一个 Job 对象以便以一种可靠的方式运行某 Pod 直到完成。 当第一个 Pod 失败或者被删除(比如因为节点硬件失效或者重启)时,Job 对象会启动一个新的 Pod。
你也可以使用 Job 以并行的方式运行多个 Pod。
如果你想按某种排期表(Schedule)运行 Job(单个任务或多个并行任务),请参阅 CronJob。
运行示例 Job
下面是一个 Job 配置示例。它负责计算 π 到小数点后 2000 位,并将结果打印出来。 此计算大约需要 10 秒钟完成。
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
你可以使用下面的命令来运行此示例:
kubectl apply -f https://kubernetes.io/examples/controllers/job.yaml
输出类似于:
job.batch/pi created
使用 kubectl 来检查 Job 的状态:
Name: pi
Namespace: default
Selector: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
Labels: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name=pi
...
Annotations: batch.kubernetes.io/job-tracking: ""
Parallelism: 1
Completions: 1
Start Time: Mon, 02 Dec 2019 15:20:11 +0200
Completed At: Mon, 02 Dec 2019 15:21:16 +0200
Duration: 65s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name=pi
Containers:
pi:
Image: perl:5.34.0
Port: <none>
Host Port: <none>
Command:
perl
-Mbignum=bpi
-wle
print bpi(2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 21s job-controller Created pod: pi-xf9p4
Normal Completed 18s job-controller Job completed
apiVersion: batch/v1
kind: Job
metadata:
annotations: batch.kubernetes.io/job-tracking: ""
...
creationTimestamp: "2022-11-10T17:53:53Z"
generation: 1
labels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
batch.kubernetes.io/job-name: pi
name: pi
namespace: default
resourceVersion: "4751"
uid: 204fb678-040b-497f-9266-35ffa8716d14
spec:
backoffLimit: 4
completionMode: NonIndexed
completions: 1
parallelism: 1
selector:
matchLabels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
suspend: false
template:
metadata:
creationTimestamp: null
labels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
batch.kubernetes.io/job-name: pi
spec:
containers:
- command:
- perl
- -Mbignum=bpi
- -wle
- print bpi(2000)
image: perl:5.34.0
imagePullPolicy: IfNotPresent
name: pi
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
active: 1
ready: 0
startTime: "2022-11-10T17:53:57Z"
uncountedTerminatedPods: {}
要查看 Job 对应的已完成的 Pod,可以执行 kubectl get pods。
要以机器可读的方式列举隶属于某 Job 的全部 Pod,你可以使用类似下面这条命令:
pods=$(kubectl get pods --selector=batch.kubernetes.io/job-name=pi --output=jsonpath='{.items[*].metadata.name}')
echo $pods
输出类似于:
pi-5rwd7
这里,选择算符与 Job 的选择算符相同。--output=jsonpath 选项给出了一个表达式,
用来从返回的列表中提取每个 Pod 的 name 字段。
查看其中一个 Pod 的标准输出:
kubectl logs $pods
另外一种查看 Job 日志的方法:
kubectl logs jobs/pi
输出类似于:
3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901
编写 Job 规约
与 Kubernetes 中其他资源的配置类似,Job 也需要 apiVersion、kind 和 metadata 字段。
当控制面为 Job 创建新的 Pod 时,Job 的 .metadata.name 是命名这些 Pod 的基础组成部分。
Job 的名字必须是合法的 DNS 子域名值,
但这可能对 Pod 主机名产生意料之外的结果。为了获得最佳兼容性,此名字应遵循更严格的
DNS 标签规则。
即使该名字被要求遵循 DNS 子域名规则,也不得超过 63 个字符。
Job 配置还需要一个 .spec 节。
Job 标签
Job 标签将为 job-name 和 controller-uid 加上 batch.kubernetes.io/ 前缀。
Pod 模板
Job 的 .spec 中只有 .spec.template 是必需的字段。
字段 .spec.template 的值是一个 Pod 模板。
其定义规范与 Pod
完全相同,只是其中不再需要 apiVersion 或 kind 字段。
除了作为 Pod 所必需的字段之外,Job 中的 Pod 模板必须设置合适的标签 (参见 Pod 选择算符)和合适的重启策略。
Job 中 Pod 的 RestartPolicy
只能设置为 Never 或 OnFailure 之一。
Pod 选择算符
字段 .spec.selector 是可选的。在绝大多数场合,你都不需要为其赋值。
参阅设置自己的 Pod 选择算符。
Job 的并行执行
适合以 Job 形式来运行的任务主要有三种:
- 非并行 Job:
- 通常只启动一个 Pod,除非该 Pod 失败。
- 当 Pod 成功终止时,立即视 Job 为完成状态。
- 具有确定完成计数的并行 Job:
.spec.completions字段设置为非 0 的正数值。- Job 用来代表整个任务,当成功的 Pod 个数达到
.spec.completions时,Job 被视为完成。 - 当使用
.spec.completionMode="Indexed"时,每个 Pod 都会获得一个不同的 索引值,介于 0 和.spec.completions-1之间。
- 带工作队列的并行 Job:
- 不设置
spec.completions,默认值为.spec.parallelism。 - 多个 Pod 之间必须相互协调,或者借助外部服务确定每个 Pod 要处理哪个工作条目。 例如,任一 Pod 都可以从工作队列中取走最多 N 个工作条目。
- 每个 Pod 都可以独立确定是否其它 Pod 都已完成,进而确定 Job 是否完成。
- 当 Job 中任何 Pod 成功终止,不再创建新 Pod。
- 一旦至少 1 个 Pod 成功完成,并且所有 Pod 都已终止,即可宣告 Job 成功完成。
- 一旦任何 Pod 成功退出,任何其它 Pod 都不应再对此任务执行任何操作或生成任何输出。 所有 Pod 都应启动退出过程。
- 不设置
对于非并行的 Job,你可以不设置 spec.completions 和 spec.parallelism。
这两个属性都不设置时,均取默认值 1。
对于确定完成计数类型的 Job,你应该设置 .spec.completions 为所需要的完成个数。
你可以设置 .spec.parallelism,也可以不设置。其默认值为 1。
对于一个工作队列 Job,你不可以设置 .spec.completions,但要将.spec.parallelism
设置为一个非负整数。
关于如何利用不同类型的 Job 的更多信息,请参见 Job 模式一节。
控制并行性
并行性请求(.spec.parallelism)可以设置为任何非负整数。
如果未设置,则默认为 1。
如果设置为 0,则 Job 相当于启动之后便被暂停,直到此值被增加。
实际并行性(在任意时刻运行状态的 Pod 个数)可能比并行性请求略大或略小, 原因如下:
- 对于确定完成计数 Job,实际上并行执行的 Pod 个数不会超出剩余的完成数。
如果
.spec.parallelism值较高,会被忽略。 - 对于工作队列 Job,有任何 Job 成功结束之后,不会有新的 Pod 启动。 不过,剩下的 Pod 允许执行完毕。
- 如果 Job 控制器 没有来得及作出响应,或者
- 如果 Job 控制器因为任何原因(例如,缺少
ResourceQuota或者没有权限)无法创建 Pod。 Pod 个数可能比请求的数目小。 - Job 控制器可能会因为之前同一 Job 中 Pod 失效次数过多而压制新 Pod 的创建。
- 当 Pod 处于体面终止进程中,需要一定时间才能停止。
完成模式
特性状态:
Kubernetes v1.24 [stable]
带有确定完成计数的 Job,即 .spec.completions 不为 null 的 Job,
都可以在其 .spec.completionMode 中设置完成模式:
-
NonIndexed(默认值):当成功完成的 Pod 个数达到.spec.completions所 设值时认为 Job 已经完成。换言之,每个 Job 完成事件都是独立无关且同质的。 要注意的是,当.spec.completions取值为 null 时,Job 被隐式处理为NonIndexed。 -
Indexed:Job 的 Pod 会获得对应的完成索引,取值为 0 到.spec.completions-1。 该索引可以通过四种方式获取:- Pod 注解
batch.kubernetes.io/job-completion-index。 - Pod 标签
batch.kubernetes.io/job-completion-index(适用于 v1.28 及更高版本)。 请注意,必须启用PodIndexLabel特性门控才能使用此标签,默认被启用。 - 作为 Pod 主机名的一部分,遵循模式
$(job-name)-$(index)。 当你同时使用带索引的 Job(Indexed Job)与 服务(Service), Job 中的 Pod 可以通过 DNS 使用确切的主机名互相寻址。 有关如何配置的更多信息,请参阅带 Pod 间通信的 Job。 - 对于容器化的任务,在环境变量
JOB_COMPLETION_INDEX中。
当每个索引都对应一个成功完成的 Pod 时,Job 被认为是已完成的。 关于如何使用这种模式的更多信息,可参阅 用带索引的 Job 执行基于静态任务分配的并行处理。
- Pod 注解
说明:
带同一索引值启动的 Pod 可能不止一个(由于节点故障、kubelet 重启或 Pod 驱逐等各种原因),尽管这种情况很少发生。 在这种情况下,只有第一个成功完成的 Pod 才会被记入完成计数中并更新作业的状态。 其他为同一索引值运行或完成的 Pod 一旦被检测到,将被 Job 控制器删除。
处理 Pod 和容器失效
Pod 中的容器可能因为多种不同原因失效,例如因为其中的进程退出时返回值非零,
或者容器因为超出内存约束而被杀死等等。
如果发生这类事件,并且 .spec.template.spec.restartPolicy = "OnFailure",
Pod 则继续留在当前节点,但容器会被重新运行。
因此,你的程序需要能够处理在本地被重启的情况,或者要设置
.spec.template.spec.restartPolicy = "Never"。
关于 restartPolicy 的更多信息,可参阅
Pod 生命周期。
整个 Pod 也可能会失败,且原因各不相同。
例如,当 Pod 启动时,节点失效(被升级、被重启、被删除等)或者其中的容器失败而
.spec.template.spec.restartPolicy = "Never"。
当 Pod 失败时,Job 控制器会启动一个新的 Pod。
这意味着,你的应用需要处理在一个新 Pod 中被重启的情况。
尤其是应用需要处理之前运行所产生的临时文件、锁、不完整的输出等问题。
默认情况下,每个 Pod 失效都被计入 .spec.backoffLimit 限制,
请参阅 Pod 回退失效策略。
但你可以通过设置 Job 的 Pod 失效策略自定义对 Pod 失效的处理方式。
此外,你可以通过设置 .spec.backoffLimitPerIndex 字段,
选择为 Indexed Job 的每个索引独立计算 Pod 失败次数
(细节参阅逐索引的回退限制)。
注意,即使你将 .spec.parallelism 设置为 1,且将 .spec.completions 设置为
1,并且 .spec.template.spec.restartPolicy 设置为 "Never",同一程序仍然有可能被启动两次。
如果你确实将 .spec.parallelism 和 .spec.completions 都设置为比 1 大的值,
那就有可能同时出现多个 Pod 运行的情况。
为此,你的 Pod 也必须能够处理并发性问题。
当特性门控
PodDisruptionConditions 和 JobPodFailurePolicy 都被启用且 .spec.podFailurePolicy 字段被设置时,
Job 控制器不会将终止过程中的 Pod(已设置 .metadata.deletionTimestamp 字段的 Pod)视为失效 Pod,
直到该 Pod 完全终止(其 .status.phase 为 Failed 或 Succeeded)。
但只要终止变得显而易见,Job 控制器就会创建一个替代的 Pod。一旦 Pod 终止,Job 控制器将把这个刚终止的
Pod 考虑在内,评估相关 Job 的 .backoffLimit 和 .podFailurePolicy。
如果不满足任一要求,即使 Pod 稍后以 phase: "Succeeded" 终止,Job 控制器也会将此即将终止的 Pod 计为立即失效。
Pod 回退失效策略
在有些情形下,你可能希望 Job 在经历若干次重试之后直接进入失败状态,
因为这很可能意味着遇到了配置错误。
为了实现这点,可以将 .spec.backoffLimit 设置为视 Job 为失败之前的重试次数。
失效回退的限制值默认为 6。
与 Job 相关的失效的 Pod 会被 Job 控制器重建,回退重试时间将会按指数增长
(从 10 秒、20 秒到 40 秒)最多至 6 分钟。
计算重试次数有以下两种方法:
- 计算
.status.phase = "Failed"的 Pod 数量。 - 当 Pod 的
restartPolicy = "OnFailure"时,针对.status.phase等于Pending或Running的 Pod,计算其中所有容器的重试次数。
如果两种方式其中一个的值达到 .spec.backoffLimit,则 Job 被判定为失败。
说明:
如果你的 Job 的 restartPolicy 被设置为 "OnFailure",就要注意运行该 Job 的 Pod
会在 Job 到达失效回退次数上限时自动被终止。
这会使得调试 Job 中可执行文件的工作变得非常棘手。
我们建议在调试 Job 时将 restartPolicy 设置为 "Never",
或者使用日志系统来确保失效 Job 的输出不会意外遗失。
逐索引的回退限制
特性状态:
Kubernetes v1.29 [beta]
运行 Indexed Job 时,你可以选择对每个索引独立处理 Pod 失败的重试。
为此,可以设置 .spec.backoffLimitPerIndex 来指定每个索引的最大 Pod 失败次数。
当某个索引超过逐索引的回退限制后,Kubernetes 将视该索引为已失败,并将其添加到 .status.failedIndexes 字段中。
无论你是否设置了 backoffLimitPerIndex 字段,已成功执行的索引(具有成功执行的 Pod)将被记录在
.status.completedIndexes 字段中。
请注意,失败的索引不会中断其他索引的执行。一旦在指定了逐索引回退限制的 Job 中的所有索引完成, 如果其中至少有一个索引失败,Job 控制器会通过在状态中设置 Failed 状况将整个 Job 标记为失败。 即使其中一些(可能几乎全部)索引已被成功处理,该 Job 也会被标记为失败。
你还可以通过设置 .spec.maxFailedIndexes 字段来限制标记为失败的最大索引数。
当失败的索引数量超过 maxFailedIndexes 字段时,Job 控制器会对该 Job
的运行中的所有余下 Pod 触发终止操作。一旦所有 Pod 被终止,Job 控制器将通过设置 Job
状态中的 Failed 状况将整个 Job 标记为失败。
以下是定义 backoffLimitPerIndex 的 Job 示例清单:
apiVersion: batch/v1
kind: Job
metadata:
name: job-backoff-limit-per-index-example
spec:
completions: 10
parallelism: 3
completionMode: Indexed # 此特性所必需的字段
backoffLimitPerIndex: 1 # 每个索引最大失败次数
maxFailedIndexes: 5 # 终止 Job 执行之前失败索引的最大个数
template:
spec:
restartPolicy: Never # 此特性所必需的字段
containers:
- name: example
image: python
command: # 作业失败,因为至少有一个索引失败(此处所有偶数索引均失败),
# 但由于未超过 maxFailedIndexes,所以所有索引都会被执行
- python3
- -c
- |
import os, sys
print("Hello world")
if int(os.environ.get("JOB_COMPLETION_INDEX")) % 2 == 0:
sys.exit(1)
在上面的示例中,Job 控制器允许每个索引重新启动一次。 当失败的索引总数超过 5 个时,整个 Job 将被终止。
Job 完成后,该 Job 的状态如下所示:
kubectl get -o yaml job job-backoff-limit-per-index-example
status:
completedIndexes: 1,3,5,7,9
failedIndexes: 0,2,4,6,8
succeeded: 5 # 每 5 个成功的索引有 1 个成功的 Pod
failed: 10 # 每 5 个失败的索引有 2 个失败的 Pod(1 次重试)
conditions:
- message: Job has failed indexes
reason: FailedIndexes
status: "True"
type: Failed
此外,你可能想要结合使用逐索引回退与 Pod 失败策略。
在使用逐索引回退时,有一个新的 FailIndex 操作可用,它让你避免就某个索引进行不必要的重试。
Pod 失效策略
特性状态:
Kubernetes v1.26 [beta]
说明:
只有你在集群中启用了
JobPodFailurePolicy 特性门控,
你才能为某个 Job 配置 Pod 失效策略。
此外,建议启用 PodDisruptionConditions 特性门控以便在 Pod 失效策略中检测和处理 Pod 干扰状况
(参考:Pod 干扰状况)。
这两个特性门控都是在 Kubernetes 1.29 中提供的。
Pod 失效策略使用 .spec.podFailurePolicy 字段来定义,
它能让你的集群根据容器的退出码和 Pod 状况来处理 Pod 失效事件。
在某些情况下,你可能希望更好地控制 Pod 失效的处理方式,
而不是仅限于 Pod 回退失效策略所提供的控制能力,
后者是基于 Job 的 .spec.backoffLimit 实现的。以下是一些使用场景:
- 通过避免不必要的 Pod 重启来优化工作负载的运行成本, 你可以在某 Job 中一个 Pod 失效且其退出码表明存在软件错误时立即终止该 Job。
- 为了保证即使有干扰也能完成 Job,你可以忽略由干扰导致的 Pod 失效
(例如抢占、
通过 API 发起的驱逐
或基于污点的驱逐),
这样这些失效就不会被计入
.spec.backoffLimit的重试限制中。
你可以在 .spec.podFailurePolicy 字段中配置 Pod 失效策略,以满足上述使用场景。
该策略可以根据容器退出码和 Pod 状况来处理 Pod 失效。
下面是一个定义了 podFailurePolicy 的 Job 的清单:
apiVersion: batch/v1
kind: Job
metadata:
name: job-pod-failure-policy-example
spec:
completions: 12
parallelism: 3
template:
spec:
restartPolicy: Never
containers:
- name: main
image: docker.io/library/bash:5
command: ["bash"] # 模拟一个触发 FailJob 动作的错误的示例命令
args:
- -c
- echo "Hello world!" && sleep 5 && exit 42
backoffLimit: 6
podFailurePolicy:
rules:
- action: FailJob
onExitCodes:
containerName: main # 可选
operator: In # In 和 NotIn 二选一
values: [42]
- action: Ignore # Ignore、FailJob、Count 其中之一
onPodConditions:
- type: DisruptionTarget # 表示 Pod 失效
在上面的示例中,Pod 失效策略的第一条规则规定如果 main 容器失败并且退出码为 42,
Job 将被标记为失败。以下是 main 容器的具体规则:
- 退出码 0 代表容器成功
- 退出码 42 代表整个 Job 失败
- 所有其他退出码都代表容器失败,同时也代表着整个 Pod 失效。
如果重启总次数低于
backoffLimit定义的次数,则会重新启动 Pod, 如果等于backoffLimit所设置的次数,则代表整个 Job 失效。
说明:
因为 Pod 模板中指定了 restartPolicy: Never,
所以 kubelet 将不会重启 Pod 中的 main 容器。
Pod 失效策略的第二条规则,
指定对于状况为 DisruptionTarget 的失效 Pod 采取 Ignore 操作,
统计 .spec.backoffLimit 重试次数限制时不考虑 Pod 因干扰而发生的异常。
说明:
如果根据 Pod 失效策略或 Pod 回退失效策略判定 Pod 已经失效, 并且 Job 正在运行多个 Pod,Kubernetes 将终止该 Job 中仍处于 Pending 或 Running 的所有 Pod。
下面是此 API 的一些要求和语义:
- 如果你想在 Job 中使用
.spec.podFailurePolicy字段, 你必须将 Job 的 Pod 模板中的.spec.restartPolicy设置为Never。 - 在
spec.podFailurePolicy.rules中设定的 Pod 失效策略规则将按序评估。 一旦某个规则与 Pod 失效策略匹配,其余规则将被忽略。 当没有规则匹配 Pod 失效策略时,将会采用默认的处理方式。 - 你可能希望在
spec.podFailurePolicy.rules[*].onExitCodes.containerName中通过指定的名称限制只能针对特定容器应用对应的规则。 如果不设置此属性,规则将适用于所有容器。 如果指定了容器名称,它应该匹配 Pod 模板中的一个普通容器或一个初始容器(Init Container)。 - 你可以在
spec.podFailurePolicy.rules[*].action指定当 Pod 失效策略发生匹配时要采取的操作。 可能的值为:FailJob:表示 Pod 的任务应标记为 Failed,并且所有正在运行的 Pod 应被终止。Ignore:表示.spec.backoffLimit的计数器不应该增加,应该创建一个替换的 Pod。Count:表示 Pod 应该以默认方式处理。.spec.backoffLimit的计数器应该增加。FailIndex:表示使用此操作以及逐索引回退限制来避免就失败的 Pod 的索引进行不必要的重试。
说明:
当你使用 podFailurePolicy 时,Job 控制器只匹配处于 Failed 阶段的 Pod。
具有删除时间戳但不处于终止阶段(Failed 或 Succeeded)的 Pod 被视为仍在终止中。
这意味着终止中的 Pod 会保留一个跟踪 Finalizer,
直到到达终止阶段。
从 Kubernetes 1.27 开始,kubelet 将删除的 Pod 转换到终止阶段
(参阅 Pod 阶段)。
这确保已删除的 Pod 的 Finalizer 被 Job 控制器移除。
说明:
自 Kubernetes v1.28 开始,当使用 Pod 失败策略时,Job 控制器仅在这些 Pod 达到终止的
Failed 阶段时才会重新创建终止中的 Pod。这种行为类似于 podReplacementPolicy: Failed。
细节参阅 Pod 替换策略。
Job 终止与清理
Job 完成时不会再创建新的 Pod,不过已有的 Pod 通常也不会被删除。
保留这些 Pod 使得你可以查看已完成的 Pod 的日志输出,以便检查错误、警告或者其它诊断性输出。
Job 完成时 Job 对象也一样被保留下来,这样你就可以查看它的状态。
在查看了 Job 状态之后删除老的 Job 的操作留给了用户自己。
你可以使用 kubectl 来删除 Job(例如,kubectl delete jobs/pi
或者 kubectl delete -f ./job.yaml)。
当使用 kubectl 来删除 Job 时,该 Job 所创建的 Pod 也会被删除。
默认情况下,Job 会持续运行,除非某个 Pod 失败(restartPolicy=Never)
或者某个容器出错退出(restartPolicy=OnFailure)。
这时,Job 基于前述的 spec.backoffLimit 来决定是否以及如何重试。
一旦重试次数到达 .spec.backoffLimit 所设的上限,Job 会被标记为失败,
其中运行的 Pod 都会被终止。
终止 Job 的另一种方式是设置一个活跃期限。
你可以为 Job 的 .spec.activeDeadlineSeconds 设置一个秒数值。
该值适用于 Job 的整个生命期,无论 Job 创建了多少个 Pod。
一旦 Job 运行时间达到 activeDeadlineSeconds 秒,其所有运行中的 Pod 都会被终止,
并且 Job 的状态更新为 type: Failed 及 reason: DeadlineExceeded。
注意 Job 的 .spec.activeDeadlineSeconds 优先级高于其 .spec.backoffLimit 设置。
因此,如果一个 Job 正在重试一个或多个失效的 Pod,该 Job 一旦到达
activeDeadlineSeconds 所设的时限即不再部署额外的 Pod,
即使其重试次数还未达到 backoffLimit 所设的限制。
例如:
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-timeout
spec:
backoffLimit: 5
activeDeadlineSeconds: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
注意 Job 规约和 Job 中的
Pod 模板规约
都有 activeDeadlineSeconds 字段。
请确保你在合适的层次设置正确的字段。
还要注意的是,restartPolicy 对应的是 Pod,而不是 Job 本身:
一旦 Job 状态变为 type: Failed,就不会再发生 Job 重启的动作。
换言之,由 .spec.activeDeadlineSeconds 和 .spec.backoffLimit 所触发的 Job
终结机制都会导致 Job 永久性的失败,而这类状态都需要手工干预才能解决。
自动清理完成的 Job
完成的 Job 通常不需要留存在系统中。在系统中一直保留它们会给 API 服务器带来额外的压力。 如果 Job 由某种更高级别的控制器来管理,例如 CronJob, 则 Job 可以被 CronJob 基于特定的根据容量裁定的清理策略清理掉。
已完成 Job 的 TTL 机制
特性状态:
Kubernetes v1.23 [stable]
自动清理已完成 Job (状态为 Complete 或 Failed)的另一种方式是使用由
TTL 控制器所提供的 TTL 机制。
通过设置 Job 的 .spec.ttlSecondsAfterFinished 字段,可以让该控制器清理掉已结束的资源。
TTL 控制器清理 Job 时,会级联式地删除 Job 对象。 换言之,它会删除所有依赖的对象,包括 Pod 及 Job 本身。 注意,当 Job 被删除时,系统会考虑其生命周期保障,例如其 Finalizers。
例如:
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
Job pi-with-ttl 在结束 100 秒之后,可以成为被自动删除的对象。
如果该字段设置为 0,Job 在结束之后立即成为可被自动删除的对象。
如果该字段没有设置,Job 不会在结束之后被 TTL 控制器自动清除。
说明:
建议设置 ttlSecondsAfterFinished 字段,因为非托管任务
(是你直接创建的 Job,而不是通过其他工作负载 API(如 CronJob)间接创建的 Job)
的默认删除策略是 orphanDependents,这会导致非托管 Job 创建的 Pod 在该 Job 被完全删除后被保留。
即使控制面最终在 Pod 失效或完成后
对已删除 Job 中的这些 Pod 执行垃圾收集操作,
这些残留的 Pod 有时可能会导致集群性能下降,或者在最坏的情况下会导致集群因这种性能下降而离线。
你可以使用 LimitRange 和 ResourceQuota, 设定一个特定名字空间可以消耗的资源上限。
Job 模式
Job 对象可以用来处理一组相互独立而又彼此关联的“工作条目”。 这类工作条目可能是要发送的电子邮件、要渲染的视频帧、要编解码的文件、NoSQL 数据库中要扫描的主键范围等等。
在一个复杂系统中,可能存在多个不同的工作条目集合。 这里我们仅考虑用户希望一起管理的工作条目集合之一:批处理作业。
并行计算的模式有好多种,每种都有自己的强项和弱点。这里要权衡的因素有:
- 每个工作条目对应一个 Job 或者所有工作条目对应同一 Job 对象。 为每个工作条目创建一个 Job 的做法会给用户带来一些额外的负担,系统需要管理大量的 Job 对象。 用一个 Job 对象来完成所有工作条目的做法更适合处理大量工作条目的场景。
- 创建数目与工作条目相等的 Pod 或者令每个 Pod 可以处理多个工作条目。 当 Pod 个数与工作条目数目相等时,通常不需要在 Pod 中对现有代码和容器做较大改动; 让每个 Pod 能够处理多个工作条目的做法更适合于工作条目数量较大的场合。
- 有几种技术都会用到工作队列。这意味着需要运行一个队列服务, 并修改现有程序或容器使之能够利用该工作队列。 与之比较,其他方案在修改现有容器化应用以适应需求方面可能更容易一些。
- 当 Job 与某个无头 Service 之间存在关联时,你可以让 Job 中的 Pod 之间能够相互通信,从而协作完成计算。
下面是对这些权衡的汇总,第 2 到 4 列对应上面的权衡比较。 模式的名称对应了相关示例和更详细描述的链接。
| 模式 | 单个 Job 对象 | Pod 数少于工作条目数? | 直接使用应用无需修改? |
|---|---|---|---|
| 每工作条目一 Pod 的队列 | ✓ | 有时 | |
| Pod 数量可变的队列 | ✓ | ✓ | |
| 静态任务分派的带索引的 Job | ✓ | ✓ | |
| 带 Pod 间通信的 Job | ✓ | 有时 | 有时 |
| Job 模板扩展 | ✓ |
当你使用 .spec.completions 来设置完成数时,Job 控制器所创建的每个 Pod
使用完全相同的 spec。
这意味着任务的所有 Pod 都有相同的命令行,都使用相同的镜像和数据卷,
甚至连环境变量都(几乎)相同。
这些模式是让每个 Pod 执行不同工作的几种不同形式。
下表显示的是每种模式下 .spec.parallelism 和 .spec.completions 所需要的设置。
其中,W 表示的是工作条目的个数。
| 模式 | .spec.completions |
.spec.parallelism |
|---|---|---|
| 每工作条目一 Pod 的队列 | W | 任意值 |
| Pod 数量可变的队列 | 1 | 任意值 |
| 静态任务分派的带索引的 Job | W | |
| 带 Pod 间通信的 Job | W | W |
| Job 模板扩展 | 1 | 应该为 1 |
高级用法
挂起 Job
特性状态:
Kubernetes v1.24 [stable]
Job 被创建时,Job 控制器会马上开始执行 Pod 创建操作以满足 Job 的需求, 并持续执行此操作直到 Job 完成为止。 不过你可能想要暂时挂起 Job 执行,或启动处于挂起状态的 Job, 并拥有一个自定义控制器以后再决定什么时候开始。
要挂起一个 Job,你可以更新 .spec.suspend 字段为 true,
之后,当你希望恢复其执行时,将其更新为 false。
创建一个 .spec.suspend 被设置为 true 的 Job 本质上会将其创建为被挂起状态。
当 Job 被从挂起状态恢复执行时,其 .status.startTime 字段会被重置为当前的时间。
这意味着 .spec.activeDeadlineSeconds 计时器会在 Job 挂起时被停止,
并在 Job 恢复执行时复位。
当你挂起一个 Job 时,所有正在运行且状态不是 Completed 的 Pod
将被终止。
Pod 的体面终止期限会被考虑,不过 Pod 自身也必须在此期限之内处理完信号。
处理逻辑可能包括保存进度以便将来恢复,或者取消已经做出的变更等等。
Pod 以这种形式终止时,不会被记入 Job 的 completions 计数。
处于被挂起状态的 Job 的定义示例可能是这样子:
kubectl get job myjob -o yaml
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
suspend: true
parallelism: 1
completions: 5
template:
spec:
...
你也可以使用命令行为 Job 打补丁来切换 Job 的挂起状态。
挂起一个活跃的 Job:
kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":true}}'
恢复一个挂起的 Job:
kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":false}}'
Job 的 status 可以用来确定 Job 是否被挂起,或者曾经被挂起。
kubectl get jobs/myjob -o yaml
apiVersion: batch/v1
kind: Job
# .metadata 和 .spec 已省略
status:
conditions:
- lastProbeTime: "2021-02-05T13:14:33Z"
lastTransitionTime: "2021-02-05T13:14:33Z"
status: "True"
type: Suspended
startTime: "2021-02-05T13:13:48Z"
Job 的 "Suspended" 类型的状况在状态值为 "True" 时意味着 Job 正被挂起;
lastTransitionTime 字段可被用来确定 Job 被挂起的时长。
如果此状况字段的取值为 "False",则 Job 之前被挂起且现在在运行。
如果 "Suspended" 状况在 status 字段中不存在,则意味着 Job 从未被停止执行。
当 Job 被挂起和恢复执行时,也会生成事件:
kubectl describe jobs/myjob
Name: myjob
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m job-controller Created pod: myjob-hlrpl
Normal SuccessfulDelete 11m job-controller Deleted pod: myjob-hlrpl
Normal Suspended 11m job-controller Job suspended
Normal SuccessfulCreate 3s job-controller Created pod: myjob-jvb44
Normal Resumed 3s job-controller Job resumed
最后四个事件,特别是 "Suspended" 和 "Resumed" 事件,都是因为 .spec.suspend
字段值被改来改去造成的。在这两个事件之间,我们看到没有 Pod 被创建,不过当
Job 被恢复执行时,Pod 创建操作立即被重启执行。
可变调度指令
特性状态:
Kubernetes v1.27 [stable]
在大多数情况下,并行作业会希望 Pod 在一定约束条件下运行, 比如所有的 Pod 都在同一个区域,或者所有的 Pod 都在 GPU 型号 x 或 y 上,而不是两者的混合。
suspend 字段是实现这些语义的第一步。 suspend 允许自定义队列控制器,以决定工作何时开始;然而,一旦工作被取消暂停, 自定义队列控制器对 Job 中 Pod 的实际放置位置没有影响。
此特性允许在 Job 开始之前更新调度指令,从而为定制队列提供影响 Pod 放置的能力,同时将 Pod 与节点间的分配关系留给 kube-scheduler 决定。 这一特性仅适用于之前从未被暂停过的、已暂停的 Job。 控制器能够影响 Pod 放置,同时参考实际 pod-to-node 分配给 kube-scheduler。 这仅适用于从未暂停的 Job。
Job 的 Pod 模板中可以更新的字段是节点亲和性、节点选择器、容忍、标签、注解和 调度门控。
指定你自己的 Pod 选择算符
通常,当你创建一个 Job 对象时,你不会设置 .spec.selector。
系统的默认值填充逻辑会在创建 Job 时添加此字段。
它会选择一个不会与任何其他 Job 重叠的选择算符设置。
不过,有些场合下,你可能需要重载这个自动设置的选择算符。
为了实现这点,你可以手动设置 Job 的 spec.selector 字段。
做这个操作时请务必小心。
如果你所设定的标签选择算符并不唯一针对 Job 对应的 Pod 集合,
甚或该算符还能匹配其他无关的 Pod,这些无关的 Job 的 Pod 可能会被删除。
或者当前 Job 会将另外一些 Pod 当作是完成自身工作的 Pod,
又或者两个 Job 之一或者二者同时都拒绝创建 Pod,无法运行至完成状态。
如果所设置的算符不具有唯一性,其他控制器(如 RC 副本控制器)及其所管理的 Pod
集合可能会变得行为不可预测。
Kubernetes 不会在你设置 .spec.selector 时尝试阻止你犯这类错误。
下面是一个示例场景,在这种场景下你可能会使用刚刚讲述的特性。
假定名为 old 的 Job 已经处于运行状态。
你希望已有的 Pod 继续运行,但你希望 Job 接下来要创建的其他 Pod
使用一个不同的 Pod 模板,甚至希望 Job 的名字也发生变化。
你无法更新现有的 Job,因为这些字段都是不可更新的。
因此,你会删除 old Job,但允许该 Job 的 Pod 集合继续运行。
这是通过 kubectl delete jobs/old --cascade=orphan 实现的。
在删除之前,我们先记下该 Job 所使用的选择算符。
kubectl get job old -o yaml
输出类似于:
kind: Job
metadata:
name: old
...
spec:
selector:
matchLabels:
batch.kubernetes.io/controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
...
接下来你会创建名为 new 的新 Job,并显式地为其设置相同的选择算符。
由于现有 Pod 都具有标签
batch.kubernetes.io/controller-uid=a8f3d00d-c6d2-11e5-9f87-42010af00002,
它们也会被名为 new 的 Job 所控制。
你需要在新 Job 中设置 manualSelector: true,
因为你并未使用系统通常自动为你生成的选择算符。
kind: Job
metadata:
name: new
...
spec:
manualSelector: true
selector:
matchLabels:
batch.kubernetes.io/controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
...
新的 Job 自身会有一个不同于 a8f3d00d-c6d2-11e5-9f87-42010af00002 的唯一 ID。
设置 manualSelector: true
是在告诉系统你知道自己在干什么并要求系统允许这种不匹配的存在。
使用 Finalizer 追踪 Job
特性状态:
Kubernetes v1.26 [stable]
控制面会跟踪属于任何 Job 的 Pod,并通知是否有任何这样的 Pod 被从 API 服务器中移除。
为了实现这一点,Job 控制器创建的 Pod 带有 Finalizer batch.kubernetes.io/job-tracking。
控制器只有在 Pod 被记入 Job 状态后才会移除 Finalizer,允许 Pod 可以被其他控制器或用户移除。
说明:
如果你发现来自 Job 的某些 Pod 因存在负责跟踪的 Finalizer 而无法正常终止, 请参阅我的 Pod 一直处于终止状态。
弹性索引 Job
特性状态:
Kubernetes v1.27 [beta]
你可以通过同时改变 .spec.parallelism 和 .spec.completions 来扩大或缩小带索引 Job,
从而满足 .spec.parallelism == .spec.completions。
当 API 服务器
上的 ElasticIndexedJob 特性门控被禁用时,.spec.completions 是不可变的。
弹性索引 Job 的使用场景包括需要扩展索引 Job 的批处理工作负载,例如 MPI、Horovord、Ray
和 PyTorch 训练作业。
延迟创建替换 Pod
特性状态:
Kubernetes v1.29 [beta]
说明:
你只有在启用了 JobPodReplacementPolicy
特性门控后(默认启用),
才能为 Job 设置 podReplacementPolicy。
默认情况下,当 Pod 失败或正在终止(具有删除时间戳)时,Job 控制器会立即重新创建 Pod。
这意味着,在某个时间点上,当一些 Pod 正在终止时,为 Job 正运行中的 Pod 数量可以大于 parallelism
或超出每个索引一个 Pod(如果使用 Indexed Job)。
你可以选择仅在终止过程中的 Pod 完全终止(具有 status.phase: Failed)时才创建替换 Pod。
为此,可以设置 .spec.podReplacementPolicy: Failed。
默认的替换策略取决于 Job 是否设置了 podFailurePolicy。对于没有定义 Pod 失败策略的 Job,
省略 podReplacementPolicy 字段相当于选择 TerminatingOrFailed 替换策略:
控制平面在 Pod 删除时立即创建替换 Pod(只要控制平面发现该 Job 的某个 Pod 被设置了 deletionTimestamp)。
对于设置了 Pod 失败策略的 Job,默认的 podReplacementPolicy 是 Failed,不允许其他值。
请参阅 Pod 失败策略以了解更多关于 Job 的 Pod 失败策略的信息。
kind: Job
metadata:
name: new
...
spec:
podReplacementPolicy: Failed
...
如果你的集群启用了此特性门控,你可以检查 Job 的 .status.terminating 字段。
该字段值是当前处于终止过程中的、由该 Job 拥有的 Pod 的数量。
kubectl get jobs/myjob -o yaml
apiVersion: batch/v1
kind: Job
# .metadata 和 .spec 被省略
status:
terminating: 3 # 三个 Pod 正在终止且还未达到 Failed 阶段
替代方案
裸 Pod
当 Pod 运行所在的节点重启或者失败,Pod 会被终止并且不会被重启。 Job 会重新创建新的 Pod 来替代已终止的 Pod。 因为这个原因,我们建议你使用 Job 而不是独立的裸 Pod, 即使你的应用仅需要一个 Pod。
副本控制器
Job 与副本控制器是彼此互补的。 副本控制器管理的是那些不希望被终止的 Pod (例如,Web 服务器), Job 管理的是那些希望被终止的 Pod(例如,批处理作业)。
正如在 Pod 生命期 中讨论的,
Job 仅适合于 restartPolicy 设置为 OnFailure 或 Never 的 Pod。
注意:如果 restartPolicy 未设置,其默认值是 Always。
单个 Job 启动控制器 Pod
另一种模式是用唯一的 Job 来创建 Pod,而该 Pod 负责启动其他 Pod, 因此扮演了一种后启动 Pod 的控制器的角色。 这种模式的灵活性更高,但是有时候可能会把事情搞得很复杂,很难入门, 并且与 Kubernetes 的集成度很低。
这种模式的实例之一是用 Job 来启动一个运行脚本的 Pod,脚本负责启动 Spark 主控制器(参见 Spark 示例), 运行 Spark 驱动,之后完成清理工作。
这种方法的优点之一是整个过程得到了 Job 对象的完成保障, 同时维持了对创建哪些 Pod、如何向其分派工作的完全控制能力,
接下来
- 了解 Pod。
- 了解运行 Job 的不同的方式:
- 使用工作队列进行粗粒度并行处理
- 使用工作队列进行精细的并行处理
- 使用索引作业完成静态工作分配下的并行处理
- 基于一个模板运行多个 Job:使用展开的方式进行并行处理
- 跟随自动清理完成的 Job 文中的链接,了解你的集群如何清理完成和失败的任务。
Job是 Kubernetes REST API 的一部分。阅读 Job 对象定义理解关于该资源的 API。- 阅读
CronJob, 它允许你定义一系列定期运行的 Job,类似于 UNIX 工具cron。 - 根据循序渐进的示例,
练习如何使用
podFailurePolicy配置处理可重试和不可重试的 Pod 失效。
4.2.6 - 已完成 Job 的自动清理
一种用于清理已完成执行的旧 Job 的 TTL 机制。
特性状态:
Kubernetes v1.23 [stable]
当你的 Job 已结束时,将 Job 保留在 API 中(而不是立即删除 Job)很有用, 这样你就可以判断 Job 是成功还是失败。
Kubernetes TTL-after-finished 控制器提供了一种 TTL 机制来限制已完成执行的 Job 对象的生命期。
清理已完成的 Job
TTL-after-finished 控制器只支持 Job。你可以通过指定 Job 的 .spec.ttlSecondsAfterFinished
字段来自动清理已结束的 Job(Complete 或 Failed),
如示例所示。
TTL-after-finished 控制器假设 Job 能在执行完成后的 TTL 秒内被清理。一旦 Job
的状态条件发生变化表明该 Job 是 Complete 或 Failed,计时器就会启动;一旦 TTL 已过期,该 Job
就能被级联删除。
当 TTL 控制器清理作业时,它将做级联删除操作,即删除 Job 的同时也删除其依赖对象。
Kubernetes 尊重 Job 对象的生命周期保证,例如等待 Finalizer。
你可以随时设置 TTL 秒。以下是设置 Job 的 .spec.ttlSecondsAfterFinished 字段的一些示例:
- 在 Job 清单(manifest)中指定此字段,以便 Job 在完成后的某个时间被自动清理。
- 手动设置现有的、已完成的 Job 的此字段,以便这些 Job 可被清理。
- 在创建 Job 时使用修改性质的准入 Webhook 动态设置该字段。集群管理员可以使用它对已完成的作业强制执行 TTL 策略。
- 使用修改性质的准入 Webhook
在 Job 完成后动态设置该字段,并根据 Job 状态、标签等选择不同的 TTL 值。
对于这种情况,Webhook 需要检测 Job 的
.status变化,并且仅在 Job 被标记为已完成时设置 TTL。 - 编写你自己的控制器来管理与特定选择算符匹配的 Job 的清理 TTL。
警告
更新已完成 Job 的 TTL
在创建 Job 或已经执行结束后,你仍可以修改其 TTL 周期,例如 Job 的
.spec.ttlSecondsAfterFinished 字段。
如果你在当前 ttlSecondsAfterFinished 时长已过期后延长 TTL 周期,
即使延长 TTL 的更新得到了成功的 API 响应,Kubernetes 也不保证保留此 Job,
时间偏差
由于 TTL-after-finished 控制器使用存储在 Kubernetes Job 中的时间戳来确定 TTL 是否已过期, 因此该功能对集群中的时间偏差很敏感,这可能导致控制平面在错误的时间清理 Job 对象。
时钟并不总是如此正确,但差异应该很小。 设置非零 TTL 时请注意避免这种风险。
接下来
-
阅读自动清理 Job
-
参阅 Kubernetes 增强提案 (KEP) 了解此机制的演进过程。
4.2.7 - CronJob
CronJob 通过重复调度启动一次性的 Job。
特性状态:
Kubernetes v1.21 [stable]
CronJob 创建基于时隔重复调度的 Job。
CronJob 用于执行排期操作,例如备份、生成报告等。 一个 CronJob 对象就像 Unix 系统上的 crontab(cron table)文件中的一行。 它用 Cron 格式进行编写, 并周期性地在给定的调度时间执行 Job。
CronJob 有所限制,也比较特殊。 例如在某些情况下,单个 CronJob 可以创建多个并发任务。 请参阅下面的限制。
当控制平面为 CronJob 创建新的 Job 和(间接)Pod 时,CronJob 的 .metadata.name 是命名这些 Pod 的部分基础。
CronJob 的名称必须是一个合法的
DNS 子域值,
但这会对 Pod 的主机名产生意外的结果。为获得最佳兼容性,名称应遵循更严格的
DNS 标签规则。
即使名称是一个 DNS 子域,它也不能超过 52 个字符。这是因为 CronJob 控制器将自动在你所提供的 Job 名称后附加
11 个字符,并且存在 Job 名称的最大长度不能超过 63 个字符的限制。
示例
下面的 CronJob 示例清单会在每分钟打印出当前时间和问候消息:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
使用 CronJob 运行自动化任务一文会为你详细讲解此例。
编写 CronJob 声明信息
Cron 时间表语法
.spec.schedule 字段是必需的。该字段的值遵循 Cron 语法:
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周六)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
例如 0 0 13 * 5 表示此任务必须在每个星期五的午夜以及每个月的 13 日的午夜开始。
该格式也包含了扩展的 “Vixie cron” 步长值。 FreeBSD 手册中解释如下:
步长可被用于范围组合。范围后面带有
/<数字>可以声明范围内的步幅数值。 例如,0-23/2可被用在小时字段来声明命令在其他数值的小时数执行 (V7 标准中对应的方法是0,2,4,6,8,10,12,14,16,18,20,22)。 步长也可以放在通配符后面,因此如果你想表达 “每两小时”,就用*/2。
说明:
时间表中的问号 (?) 和星号 * 含义相同,它们用来表示给定字段的任何可用值。
除了标准语法,还可以使用一些类似 @monthly 的宏:
| 输入 | 描述 | 相当于 |
|---|---|---|
| @yearly (或 @annually) | 每年 1 月 1 日的午夜运行一次 | 0 0 1 1 * |
| @monthly | 每月第一天的午夜运行一次 | 0 0 1 * * |
| @weekly | 每周的周日午夜运行一次 | 0 0 * * 0 |
| @daily (或 @midnight) | 每天午夜运行一次 | 0 0 * * * |
| @hourly | 每小时的开始一次 | 0 * * * * |
为了生成 CronJob 时间表的表达式,你还可以使用 crontab.guru 这类 Web 工具。
任务模板
.spec.jobTemplate为 CronJob 创建的 Job 定义模板,它是必需的。它和
Job 的语法完全一样,
只不过它是嵌套的,没有 apiVersion 和 kind。
你可以为模板化的 Job 指定通用的元数据,
例如标签或注解。
有关如何编写一个 Job 的 .spec,
请参考编写 Job 规约。
Job 延迟开始的最后期限
.spec.startingDeadlineSeconds 字段是可选的。
它表示 Job 如果由于某种原因错过了调度时间,开始该 Job 的截止时间的秒数。
过了截止时间,CronJob 就不会开始该 Job 的实例(未来的 Job 仍在调度之中)。 例如,如果你有一个每天运行两次的备份 Job,你可能会允许它最多延迟 8 小时开始,但不能更晚, 因为更晚进行的备份将变得没有意义:你宁愿等待下一次计划的运行。
对于错过已配置的最后期限的 Job,Kubernetes 将其视为失败的 Job。
如果你没有为 CronJob 指定 startingDeadlineSeconds,那 Job 就没有最后期限。
如果 .spec.startingDeadlineSeconds 字段被设置(非空),
CronJob 控制器将会计算从预期创建 Job 到当前时间的时间差。
如果时间差大于该限制,则跳过此次执行。
例如,如果将其设置为 200,则 Job 控制器允许在实际调度之后最多 200 秒内创建 Job。
并发性规则
.spec.concurrencyPolicy 字段也是可选的。它声明了 CronJob 创建的 Job 执行时发生重叠如何处理。
spec 仅能声明下列规则中的一种:
Allow(默认):CronJob 允许并发 Job 执行。Forbid:CronJob 不允许并发执行;如果新 Job 的执行时间到了而老 Job 没有执行完,CronJob 会忽略新 Job 的执行。 另请注意,当老 Job 执行完成时,仍然会考虑.spec.startingDeadlineSeconds,可能会导致新的 Job 执行。Replace:如果新 Job 的执行时间到了而老 Job 没有执行完,CronJob 会用新 Job 替换当前正在运行的 Job。
请注意,并发性规则仅适用于相同 CronJob 创建的 Job。如果有多个 CronJob,它们相应的 Job 总是允许并发执行的。
调度挂起
通过将可选的 .spec.suspend 字段设置为 true,可以挂起针对 CronJob 执行的任务。
这个设置不会影响 CronJob 已经开始的任务。
如果你将此字段设置为 true,后续发生的执行都会被挂起
(这些任务仍然在调度中,但 CronJob 控制器不会启动这些 Job 来运行任务),直到你取消挂起 CronJob 为止。
注意:
在调度时间内挂起的执行都会被统计为错过的 Job。当现有的 CronJob 将 .spec.suspend 从 true 改为 false 时,
且没有开始的最后期限,错过的 Job 会被立即调度。
任务历史限制
.spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit 字段是可选的。
这两个字段指定应保留多少已完成和失败的 Job。
默认设置分别为 3 和 1。将限制设置为 0 代表相应类型的 Job 完成后不会保留。
有关自动清理 Job 的其他方式, 请参见自动清理完成的 Job。
时区
特性状态:
Kubernetes v1.27 [stable]
对于没有指定时区的 CronJob, kube-controller-manager 基于本地时区解释排期表(Schedule)。
你可以通过将 .spec.timeZone
设置为一个有效时区的名称,
为 CronJob 指定一个时区。例如设置 .spec.timeZone: "Etc/UTC" 将告诉
Kubernetes 基于世界标准时间解读排期表。
Go 标准库中的时区数据库包含在二进制文件中,并用作备用数据库,以防系统上没有可用的外部数据库。
CronJob 的限制
不支持的时区规范
在 .spec.schedule 中通过 CRON_TZ 或 TZ 变量来指定时区并未得到官方支持(而且从未支持过)。
从 Kubernetes 1.29 版本开始,如果你尝试设定包含 TZ 或 CRON_TZ 时区规范的排期表,
Kubernetes 将无法创建该资源,并会报告验证错误。
对已经设置 TZ 或 CRON_TZ 的 CronJob 进行更新时,
系统会继续向客户端发送警告。
修改 CronJob
按照设计,CronJob 包含一个用于新 Job 的模板。 如果你修改现有的 CronJob,你所做的更改将应用于修改完成后开始运行的新任务。 已经开始的任务(及其 Pod)将继续运行而不会发生任何变化。 也就是说,CronJob 不 会更新现有任务,即使这些任务仍在运行。
Job 创建
CronJob 根据其计划编排,在每次该执行任务的时候大约会创建一个 Job。 我们之所以说 "大约",是因为在某些情况下,可能会创建两个 Job,或者不会创建任何 Job。 我们试图使这些情况尽量少发生,但不能完全杜绝。因此,Job 应该是 幂等的。
如果 startingDeadlineSeconds 设置为很大的数值或未设置(默认),并且
concurrencyPolicy 设置为 Allow,则 Job 将始终至少运行一次。
注意:
如果 startingDeadlineSeconds 的设置值低于 10 秒钟,CronJob 可能无法被调度。
这是因为 CronJob 控制器每 10 秒钟执行一次检查。
对于每个 CronJob,CronJob 控制器(Controller) 检查从上一次调度的时间点到现在所错过了调度次数。如果错过的调度次数超过 100 次, 那么它就不会启动这个 Job,并记录这个错误:
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.
需要注意的是,如果 startingDeadlineSeconds 字段非空,则控制器会统计从
startingDeadlineSeconds 设置的值到现在而不是从上一个计划时间到现在错过了多少次 Job。
例如,如果 startingDeadlineSeconds 是 200,则控制器会统计在过去 200 秒中错过了多少次 Job。
如果未能在调度时间内创建 CronJob,则计为错过。
例如,如果 concurrencyPolicy 被设置为 Forbid,并且当前有一个调度仍在运行的情况下,
试图调度的 CronJob 将被计算为错过。
例如,假设一个 CronJob 被设置为从 08:30:00 开始每隔一分钟创建一个新的 Job,
并且它的 startingDeadlineSeconds 字段未被设置。如果 CronJob 控制器从
08:29:00 到 10:21:00 终止运行,则该 Job 将不会启动,
因为其错过的调度次数超过了 100。
为了进一步阐述这个概念,假设将 CronJob 设置为从 08:30:00 开始每隔一分钟创建一个新的 Job,
并将其 startingDeadlineSeconds 字段设置为 200 秒。
如果 CronJob 控制器恰好在与上一个示例相同的时间段(08:29:00 到 10:21:00)终止运行,
则 Job 仍将从 10:22:00 开始。
造成这种情况的原因是控制器现在检查在最近 200 秒(即 3 个错过的调度)中发生了多少次错过的
Job 调度,而不是从现在为止的最后一个调度时间开始。
CronJob 仅负责创建与其调度时间相匹配的 Job,而 Job 又负责管理其代表的 Pod。
接下来
- 了解 CronJob 所依赖的 Pod 与 Job 的概念。
- 阅读 CronJob
.spec.schedule字段的详细格式。 - 有关创建和使用 CronJob 的说明及 CronJob 清单的示例, 请参见使用 CronJob 运行自动化任务。
CronJob是 Kubernetes REST API 的一部分, 阅读 CronJob API 参考了解更多细节。
4.2.8 - ReplicationController
用于管理可水平扩展的工作负载的旧版 API。 被 Deployment 和 ReplicaSet API 取代。
说明:
现在推荐使用配置 ReplicaSet 的
Deployment 来建立副本管理机制。
ReplicationController 确保在任何时候都有特定数量的 Pod 副本处于运行状态。 换句话说,ReplicationController 确保一个 Pod 或一组同类的 Pod 总是可用的。
ReplicationController 如何工作
当 Pod 数量过多时,ReplicationController 会终止多余的 Pod。当 Pod 数量太少时,ReplicationController 将会启动新的 Pod。 与手动创建的 Pod 不同,由 ReplicationController 创建的 Pod 在失败、被删除或被终止时会被自动替换。 例如,在中断性维护(如内核升级)之后,你的 Pod 会在节点上重新创建。 因此,即使你的应用程序只需要一个 Pod,你也应该使用 ReplicationController 创建 Pod。 ReplicationController 类似于进程管理器,但是 ReplicationController 不是监控单个节点上的单个进程,而是监控跨多个节点的多个 Pod。
在讨论中,ReplicationController 通常缩写为 "rc",并作为 kubectl 命令的快捷方式。
一个简单的示例是创建一个 ReplicationController 对象来可靠地无限期地运行 Pod 的一个实例。 更复杂的用例是运行一个多副本服务(如 web 服务器)的若干相同副本。
运行一个示例 ReplicationController
这个示例 ReplicationController 配置运行 nginx Web 服务器的三个副本。
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
通过下载示例文件并运行以下命令来运行示例任务:
kubectl apply -f https://k8s.io/examples/controllers/replication.yaml
输出类似于:
replicationcontroller/nginx created
使用以下命令检查 ReplicationController 的状态:
kubectl describe replicationcontrollers/nginx
输出类似于:
Name: nginx
Namespace: default
Selector: app=nginx
Labels: app=nginx
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 0 Running / 3 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- ---- ------ -------
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-qrm3m
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-3ntk0
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-4ok8v
在这里,创建了三个 Pod,但没有一个 Pod 正在运行,这可能是因为正在拉取镜像。 稍后,相同的命令可能会显示:
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
要以机器可读的形式列出属于 ReplicationController 的所有 Pod,可以使用如下命令:
pods=$(kubectl get pods --selector=app=nginx --output=jsonpath={.items..metadata.name})
echo $pods
输出类似于:
nginx-3ntk0 nginx-4ok8v nginx-qrm3m
这里,选择算符与 ReplicationController 的选择算符相同(参见 kubectl describe 输出),并以不同的形式出现在 replication.yaml 中。
--output=jsonpath 选项指定了一个表达式,仅从返回列表中的每个 Pod 中获取名称。
编写一个 ReplicationController 清单
与所有其它 Kubernetes 配置一样,ReplicationController 需要 apiVersion、kind 和 metadata 字段。
当控制平面为 ReplicationController 创建新的 Pod 时,ReplicationController
的 .metadata.name 是命名这些 Pod 的部分基础。ReplicationController 的名称必须是一个合法的
DNS 子域值,
但这可能对 Pod 的主机名产生意外的结果。为获得最佳兼容性,名称应遵循更严格的
DNS 标签规则。
有关使用配置文件的常规信息, 参考对象管理。
ReplicationController 也需要一个 .spec 部分。
Pod 模板
.spec.template 是 .spec 的唯一必需字段。
.spec.template 是一个 Pod 模板。
它的模式与 Pod 完全相同,只是它是嵌套的,没有 apiVersion 或 kind 属性。
除了 Pod 所需的字段外,ReplicationController 中的 Pod 模板必须指定适当的标签和适当的重新启动策略。 对于标签,请确保不与其他控制器重叠。参考 Pod 选择算符。
只允许 .spec.template.spec.restartPolicy
等于 Always,如果没有指定,这是默认值。
对于本地容器重启,ReplicationController 委托给节点上的代理, 例如 Kubelet。
ReplicationController 上的标签
ReplicationController 本身可以有标签 (.metadata.labels)。
通常,你可以将这些设置为 .spec.template.metadata.labels;
如果没有指定 .metadata.labels 那么它默认为 .spec.template.metadata.labels。
但是,Kubernetes 允许它们是不同的,.metadata.labels 不会影响 ReplicationController 的行为。
Pod 选择算符
.spec.selector 字段是一个标签选择算符。
ReplicationController 管理标签与选择算符匹配的所有 Pod。
它不区分它创建或删除的 Pod 和其他人或进程创建或删除的 Pod。
这允许在不影响正在运行的 Pod 的情况下替换 ReplicationController。
如果指定了 .spec.template.metadata.labels,它必须和 .spec.selector 相同,否则它将被 API 拒绝。
如果没有指定 .spec.selector,它将默认为 .spec.template.metadata.labels。
另外,通常不应直接使用另一个 ReplicationController 或另一个控制器(例如 Job) 来创建其标签与该选择算符匹配的任何 Pod。如果这样做,ReplicationController 会认为它创建了这些 Pod。 Kubernetes 并没有阻止你这样做。
如果你的确创建了多个控制器并且其选择算符之间存在重叠,那么你将不得不自己管理删除操作(参考后文)。
多个副本
你可以通过设置 .spec.replicas 来指定应该同时运行多少个 Pod。
在任何时候,处于运行状态的 Pod 个数都可能高于或者低于设定值。例如,副本个数刚刚被增加或减少时,
或者一个 Pod 处于优雅终止过程中而其替代副本已经提前开始创建时。
如果你没有指定 .spec.replicas,那么它默认是 1。
使用 ReplicationController
删除一个 ReplicationController 以及它的 Pod
要删除一个 ReplicationController 以及它的 Pod,使用
kubectl delete。
kubectl 将 ReplicationController 缩容为 0 并等待以便在删除 ReplicationController 本身之前删除每个 Pod。
如果这个 kubectl 命令被中断,可以重新启动它。
当使用 REST API 或客户端库时,你需要明确地执行这些步骤(缩容副本为 0、 等待 Pod 删除,之后删除 ReplicationController 资源)。
只删除 ReplicationController
你可以删除一个 ReplicationController 而不影响它的任何 Pod。
使用 kubectl,为 kubectl delete 指定 --cascade=orphan 选项。
当使用 REST API 或客户端库时,只需删除 ReplicationController 对象。
一旦原始对象被删除,你可以创建一个新的 ReplicationController 来替换它。
只要新的和旧的 .spec.selector 相同,那么新的控制器将领养旧的 Pod。
但是,它不会做出任何努力使现有的 Pod 匹配新的、不同的 Pod 模板。
如果希望以受控方式更新 Pod 以使用新的 spec,请执行滚动更新操作。
从 ReplicationController 中隔离 Pod
通过更改 Pod 的标签,可以从 ReplicationController 的目标中删除 Pod。 此技术可用于从服务中删除 Pod 以进行调试、数据恢复等。以这种方式删除的 Pod 将被自动替换(假设复制副本的数量也没有更改)。
常见的使用模式
重新调度
如上所述,无论你想要继续运行 1 个 Pod 还是 1000 个 Pod,一个 ReplicationController 都将确保存在指定数量的 Pod,即使在节点故障或 Pod 终止(例如,由于另一个控制代理的操作)的情况下也是如此。
扩缩容
通过设置 replicas 字段,ReplicationController 可以允许扩容或缩容副本的数量。
你可以手动或通过自动扩缩控制代理来控制 ReplicationController 执行此操作。
滚动更新
ReplicationController 的设计目的是通过逐个替换 Pod 以方便滚动更新服务。
如 #1353 PR 中所述,建议的方法是使用 1 个副本创建一个新的 ReplicationController, 逐个扩容新的(+1)和缩容旧的(-1)控制器,然后在旧的控制器达到 0 个副本后将其删除。 这一方法能够实现可控的 Pod 集合更新,即使存在意外失效的状况。
理想情况下,滚动更新控制器将考虑应用程序的就绪情况,并确保在任何给定时间都有足够数量的 Pod 有效地提供服务。
这两个 ReplicationController 将需要创建至少具有一个不同标签的 Pod, 比如 Pod 主要容器的镜像标签,因为通常是镜像更新触发滚动更新。
多个版本跟踪
除了在滚动更新过程中运行应用程序的多个版本之外,通常还会使用多个版本跟踪来长时间, 甚至持续运行多个版本。这些跟踪将根据标签加以区分。
例如,一个服务可能把具有 tier in (frontend), environment in (prod) 的所有 Pod 作为目标。
现在假设你有 10 个副本的 Pod 组成了这个层。但是你希望能够 canary (金丝雀)发布这个组件的新版本。
你可以为大部分副本设置一个 ReplicationController,其中 replicas 设置为 9,
标签为 tier=frontend, environment=prod, track=stable 而为 canary
设置另一个 ReplicationController,其中 replicas 设置为 1,
标签为 tier=frontend, environment=prod, track=canary。
现在这个服务覆盖了 canary 和非 canary Pod。但你可以单独处理
ReplicationController,以测试、监控结果等。
和服务一起使用 ReplicationController
多个 ReplicationController 可以位于一个服务的后面,例如,一部分流量流向旧版本, 一部分流量流向新版本。
一个 ReplicationController 永远不会自行终止,但它不会像服务那样长时间存活。 服务可以由多个 ReplicationController 控制的 Pod 组成,并且在服务的生命周期内 (例如,为了执行 Pod 更新而运行服务),可以创建和销毁许多 ReplicationController。 服务本身和它们的客户端都应该忽略负责维护服务 Pod 的 ReplicationController 的存在。
编写多副本的应用
由 ReplicationController 创建的 Pod 是可替换的,语义上是相同的, 尽管随着时间的推移,它们的配置可能会变得异构。 这显然适合于多副本的无状态服务器,但是 ReplicationController 也可以用于维护主选、 分片和工作池应用程序的可用性。 这样的应用程序应该使用动态的工作分配机制,例如 RabbitMQ 工作队列, 而不是静态的或者一次性定制每个 Pod 的配置,这被认为是一种反模式。 执行的任何 Pod 定制,例如资源的垂直自动调整大小(例如,CPU 或内存), 都应该由另一个在线控制器进程执行,这与 ReplicationController 本身没什么不同。
ReplicationController 的职责
ReplicationController 仅确保所需的 Pod 数量与其标签选择算符匹配,并且是可操作的。 目前,它的计数中只排除终止的 Pod。 未来,可能会考虑系统提供的就绪状态和其他信息, 我们可能会对替换策略添加更多控制, 我们计划发出事件,这些事件可以被外部客户端用来实现任意复杂的替换和/或缩减策略。
ReplicationController 永远被限制在这个狭隘的职责范围内。
它本身既不执行就绪态探测,也不执行活跃性探测。
它不负责执行自动扩缩,而是由外部自动扩缩器控制(如
#492 中所述),后者负责更改其 replicas 字段值。
我们不会向 ReplicationController 添加调度策略(例如,
spreading)。
它也不应该验证所控制的 Pod 是否与当前指定的模板匹配,因为这会阻碍自动调整大小和其他自动化过程。
类似地,完成期限、整理依赖关系、配置扩展和其他特性也属于其他地方。
我们甚至计划考虑批量创建 Pod 的机制(查阅 #170)。
ReplicationController 旨在成为可组合的构建基元。 我们希望在它和其他补充原语的基础上构建更高级别的 API 或者工具,以便于将来的用户使用。 kubectl 目前支持的 "macro" 操作(运行、扩缩、滚动更新)就是这方面的概念示例。 例如,我们可以想象类似于 Asgard 的东西管理 ReplicationController、自动定标器、服务、调度策略、金丝雀发布等。
API 对象
在 Kubernetes REST API 中 Replication controller 是顶级资源。 更多关于 API 对象的详细信息可以在 ReplicationController API 对象找到。
ReplicationController 的替代方案
ReplicaSet
ReplicaSet 是下一代 ReplicationController,
支持新的基于集合的标签选择算符。
它主要被 Deployment
用来作为一种编排 Pod 创建、删除及更新的机制。
请注意,我们推荐使用 Deployment 而不是直接使用 ReplicaSet,除非你需要自定义更新编排或根本不需要更新。
Deployment (推荐)
Deployment
是一种更高级别的 API 对象,用于更新其底层 ReplicaSet 及其 Pod。
如果你想要这种滚动更新功能,那么推荐使用 Deployment,因为它们是声明式的、服务端的,并且具有其它特性。
裸 Pod
与用户直接创建 Pod 的情况不同,ReplicationController 能够替换因某些原因被删除或被终止的 Pod, 例如在节点故障或中断节点维护的情况下,例如内核升级。 因此,我们建议你使用 ReplicationController,即使你的应用程序只需要一个 Pod。 可以将其看作类似于进程管理器,它只管理跨多个节点的多个 Pod,而不是单个节点上的单个进程。 ReplicationController 将本地容器重启委托给节点上的某个代理(例如 Kubelet)。
Job
对于预期会自行终止的 Pod (即批处理任务),使用
Job 而不是 ReplicationController。
DaemonSet
对于提供机器级功能(例如机器监控或机器日志记录)的 Pod,
使用 DaemonSet 而不是
ReplicationController。
这些 Pod 的生命期与机器的生命期绑定:它们需要在其他 Pod 启动之前在机器上运行,
并且在机器准备重新启动或者关闭时安全地终止。
接下来
- 了解 Pod。
- 了解 Depolyment,ReplicationController 的替代品。
ReplicationController是 Kubernetes REST API 的一部分,阅读 ReplicationController 对象定义以了解 replication controllers 的 API。
4.3 - 自动扩缩工作负载
通过自动扩缩,你可以用某种方式自动更新你的工作负载。在面对资源需求变化的时候可以使你的集群更灵活、更高效。
在 Kubernetes 中,你可以根据当前的资源需求扩缩工作负载。 这让你的集群可以更灵活、更高效地面对资源需求的变化。
当你扩缩工作负载时,你可以增加或减少工作负载所管理的副本数量,或者就地调整副本的可用资源。
第一种手段称为水平扩缩,第二种称为垂直扩缩。
扩缩工作负载有手动和自动两种方式,这取决于你的使用情况。
手动扩缩工作负载
Kubernetes 支持工作负载的手动扩缩。水平扩缩可以使用 kubectl 命令行工具完成。
对于垂直扩缩,你需要更新工作负载的资源定义。
这两种策略的示例见下文。
- 水平扩缩:运行应用程序的多个实例
- 垂直扩缩:调整分配给容器的 CPU 和内存资源
自动扩缩工作负载
Kubernetes 也支持工作负载的自动扩缩,这也是本页的重点。
在 Kubernetes 中自动扩缩的概念是指自动更新管理一组 Pod 的能力(例如 Deployment)。
水平扩缩工作负载
在 Kubernetes 中,你可以使用 HorizontalPodAutoscaler (HPA) 实现工作负载的自动水平扩缩。
它以 Kubernetes API 资源和控制器的方式实现, 并定期调整工作负载中副本的数量 以满足设置的资源利用率,如 CPU 或内存利用率。
这是一个为 Deployment 部署配置 HorizontalPodAutoscaler 的示例教程。
垂直扩缩工作负载
特性状态:
Kubernetes v1.25 [stable]
你可以使用 VerticalPodAutoscaler (VPA) 实现工作负载的垂直扩缩。 不同于 HPA,VPA 并非默认来源于 Kubernetes,而是一个独立的项目, 参见 on GitHub。
安装后,你可以为工作负载创建 CustomResourceDefinitions(CRDs), 定义如何以及何时扩缩被管理副本的资源。
说明:
你需要在集群中安装 Metrics Server,这样,你的 HPA 才能正常工作。
目前,VPA 可以有四种不同的运行模式:
| 模式 | 描述 |
|---|---|
Auto |
目前是 Recreate,将来可能改为就地更新 |
Recreate |
VPA 会在创建 Pod 时分配资源请求,并且当请求的资源与新的建议值区别很大时通过驱逐 Pod 的方式来更新现存的 Pod |
Initial |
VPA 只有在创建时分配资源请求,之后不做更改 |
Off |
VPA 不会自动更改 Pod 的资源需求,建议值仍会计算并可在 VPA 对象中查看 |
就地调整的要求
特性状态:
Kubernetes v1.27 [alpha]
在不重启 Pod 或其中容器就地调整工作负载的情况下要求 Kubernetes 版本大于 1.27。
此外,特性门控 InPlaceVerticalScaling 需要开启。
InPlacePodVerticalScaling:
启用就地 Pod 垂直扩缩。
根据集群规模自动扩缩
对于需要根据集群规模实现扩缩的工作负载(例如:cluster-dns 或者其他系统组件),
你可以使用 Cluster Proportional Autoscaler。
与 VPA 一样,这个项目不是 Kubernetes 核心项目的一部分,它在 GitHub 上有自己的项目。
集群弹性伸缩器 (Cluster Proportional Autoscaler) 会观测可调度 节点 和 内核数量, 并调整目标工作负载的副本数量。
如果副本的数量需要保持一致,你可以使用 Cluster Proportional Vertical Autoscaler 来根据集群规模进行垂直扩缩。 这个项目目前处于 beta 阶段,你可以在 GitHub 上找到它。
集群弹性伸缩器会扩缩工作负载的副本数量,垂直集群弹性伸缩器 (Cluster Proportional Vertical Autoscaler) 会根据节点和/或核心的数量 调整工作负载的资源请求(例如 Deployment 和 DaemonSet)。
事件驱动型自动扩缩
通过事件驱动实现工作负载的扩缩也是可行的, 例如使用 Kubernetes Event Driven Autoscaler (KEDA)。
KEDA 是 CNCF 的毕业项目,能让你根据要处理事件的数量对工作负载进行扩缩,例如队列中消息的数量。 有多种针对不同事件源的适配可供选择。
根据计划自动扩缩
扩缩工作负载的另一种策略是计划进行扩缩,例如在非高峰时段减少资源消耗。
与事件驱动型自动扩缩相似,这种行为可以使用 KEDA 和 Cron scaler 实现。
你可以在计划扩缩器 (Cron scaler) 中定义计划来实现工作负载的横向扩缩。
扩缩集群基础设施
如果扩缩工作负载无法满足你的需求,你也可以扩缩集群基础设施本身。
扩缩集群基础设施通常是指增加或移除节点。 这可以通过以下两种自动扩缩器中的任意一种实现:
这两种扩缩器的工作原理都是通过监测节点上被标记为 unschedulable 或 underutilized 的 Pod 数量, 然后根据需要增加或移除节点。
接下来
5 - 服务、负载均衡和联网
Kubernetes 网络背后的概念和资源。
Kubernetes 网络模型
集群中每一个 Pod 都会获得自己的、
独一无二的 IP 地址,
这就意味着你不需要显式地在 Pod 之间创建链接,你几乎不需要处理容器端口到主机端口之间的映射。
这将形成一个干净的、向后兼容的模型;在这个模型里,从端口分配、命名、服务发现、
负载均衡、
应用配置和迁移的角度来看,Pod 可以被视作虚拟机或者物理主机。
Kubernetes 强制要求所有网络设施都满足以下基本要求(从而排除了有意隔离网络的策略):
- Pod 能够与所有其他节点上的 Pod 通信, 且不需要网络地址转译(NAT)
- 节点上的代理(比如:系统守护进程、kubelet)可以和节点上的所有 Pod 通信
说明:对于支持在主机网络中运行 Pod 的平台(比如:Linux),
当 Pod 挂接到节点的宿主网络上时,它们仍可以不通过 NAT 和所有节点上的 Pod 通信。
这个模型不仅不复杂,而且还和 Kubernetes 的实现从虚拟机向容器平滑迁移的初衷相符, 如果你的任务开始是在虚拟机中运行的,你的虚拟机有一个 IP, 可以和项目中其他虚拟机通信。这里的模型是基本相同的。
Kubernetes 的 IP 地址存在于 Pod 范围内 —— 容器共享它们的网络命名空间 ——
包括它们的 IP 地址和 MAC 地址。
这就意味着 Pod 内的容器都可以通过 localhost 到达对方端口。
这也意味着 Pod 内的容器需要相互协调端口的使用,但是这和虚拟机中的进程似乎没有什么不同,
这也被称为“一个 Pod 一个 IP”模型。
如何实现以上需求是所使用的特定容器运行时的细节。
也可以在 Node 本身请求端口,并用这类端口转发到你的 Pod(称之为主机端口),
但这是一个很特殊的操作。转发方式如何实现也是容器运行时的细节。
Pod 自己并不知道这些主机端口的存在。
Kubernetes 网络解决四方面的问题:
- 一个 Pod 中的容器之间通过本地回路(loopback)通信。
- 集群网络在不同 Pod 之间提供通信。
- Service API
允许你向外暴露 Pod 中运行的应用,
以支持来自于集群外部的访问。
- Ingress 提供专门用于暴露 HTTP 应用程序、网站和 API 的额外功能。
- Gateway API 是一个插件, 为服务网络建模提供富有表现力、可扩展和面向角色的 API 系列类别。
- 你也可以使用 Service 来发布仅供集群内部使用的服务。
使用 Service 连接到应用教程通过一个实际的示例让你了解 Service 和 Kubernetes 如何联网。
集群网络解释了如何为集群设置网络, 还概述了所涉及的技术。
5.1 - 服务(Service)
将在集群中运行的应用通过同一个面向外界的端点公开出去,即使工作负载分散于多个后端也完全可行。
Kubernetes 中 Service 是 将运行在一个或一组 Pod 上的网络应用程序公开为网络服务的方法。
Kubernetes 中 Service 的一个关键目标是让你无需修改现有应用以使用某种不熟悉的服务发现机制。 你可以在 Pod 集合中运行代码,无论该代码是为云原生环境设计的,还是被容器化的老应用。 你可以使用 Service 让一组 Pod 可在网络上访问,这样客户端就能与之交互。
如果你使用 Deployment 来运行你的应用, Deployment 可以动态地创建和销毁 Pod。 在任何时刻,你都不知道有多少个这样的 Pod 正在工作以及它们健康与否; 你可能甚至不知道如何辨别健康的 Pod。 Kubernetes Pod 的创建和销毁是为了匹配集群的预期状态。 Pod 是临时资源(你不应该期待单个 Pod 既可靠又耐用)。
每个 Pod 会获得属于自己的 IP 地址(Kubernetes 期待网络插件来保证这一点)。 对于集群中给定的某个 Deployment,这一刻运行的 Pod 集合可能不同于下一刻运行该应用的 Pod 集合。
这就带来了一个问题:如果某组 Pod(称为“后端”)为集群内的其他 Pod(称为“前端”) 集合提供功能,前端要如何发现并跟踪要连接的 IP 地址,以便其使用负载的后端组件呢?
Kubernetes 中的 Service
Service API 是 Kubernetes 的组成部分,它是一种抽象,帮助你将 Pod 集合在网络上公开出去。 每个 Service 对象定义端点的一个逻辑集合(通常这些端点就是 Pod)以及如何访问到这些 Pod 的策略。
例如,考虑一个无状态的图像处理后端,其中运行 3 个副本(Replicas)。 这些副本是可互换的 —— 前端不需要关心它们调用的是哪个后端。 即便构成后端集合的实际 Pod 可能会发生变化,前端客户端不应该也没必要知道这些, 而且它们也不必亲自跟踪后端的状态变化。
Service 抽象使这种解耦成为可能。
Service 所对应的 Pod 集合通常由你定义的选择算符来确定。 若想了解定义 Service 端点的其他方式,可以查阅不带选择算符的 Service。
如果你的工作负载使用 HTTP 通信,你可能会选择使用 Ingress 来控制 Web 流量如何到达该工作负载。Ingress 不是一种 Service,但它可用作集群的入口点。 Ingress 能让你将路由规则整合到同一个资源内,这样你就能将工作负载的多个组件公开出去, 这些组件使用同一个侦听器,但各自独立地运行在集群中。
用于 Kubernetes 的 Gateway API 能够提供 Ingress 和 Service 所不具备的一些额外能力。 Gateway 是使用 CustomResourceDefinitions 实现的一系列扩展 API。 你可以添加 Gateway 到你的集群中,之后就可以使用它们配置如何访问集群中运行的网络服务。
云原生服务发现
如果你想要在自己的应用中使用 Kubernetes API 进行服务发现,可以查询 API 服务器, 寻找匹配的 EndpointSlice 对象。 只要 Service 中的 Pod 集合发生变化,Kubernetes 就会为其更新 EndpointSlice。
对于非本地应用,Kubernetes 提供了在应用和后端 Pod 之间放置网络端口或负载均衡器的方法。
无论采用那种方式,你的负载都可以使用这里的服务发现机制找到希望连接的目标。
定义 Service
Kubernetes 中的 Service 是一个对象
(与 Pod 或 ConfigMap 类似)。你可以使用 Kubernetes API 创建、查看或修改 Service 定义。
通常你会使用 kubectl 这类工具来替你发起这些 API 调用。
例如,假定有一组 Pod,每个 Pod 都在侦听 TCP 端口 9376,并且它们还被打上
app.kubernetes.io/name=MyApp 标签。你可以定义一个 Service 来发布该 TCP 侦听器。
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
应用上述清单时,系统将创建一个名为 "my-service" 的、
服务类型默认为 ClusterIP 的 Service。
该 Service 指向带有标签 app.kubernetes.io/name: MyApp 的所有 Pod 的 TCP 端口 9376。
Kubernetes 为该服务分配一个 IP 地址(称为 “集群 IP”),供虚拟 IP 地址机制使用。 有关该机制的更多详情,请阅读虚拟 IP 和服务代理。
此 Service 的控制器不断扫描与其选择算符匹配的 Pod 集合,然后对 Service 的 EndpointSlice 集合执行必要的更新。
Service 对象的名称必须是有效的 RFC 1035 标签名称。
说明:
Service 能够将任意入站 port 映射到某个 targetPort。
默认情况下,出于方便考虑,targetPort 会被设置为与 port 字段相同的值。
端口定义
Pod 中的端口定义是有名字的,你可以在 Service 的 targetPort 属性中引用这些名字。
例如,我们可以通过以下方式将 Service 的 targetPort 绑定到 Pod 端口:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app.kubernetes.io/name: proxy
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80
name: http-web-svc
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app.kubernetes.io/name: proxy
ports:
- name: name-of-service-port
protocol: TCP
port: 80
targetPort: http-web-svc
即使在 Service 中混合使用配置名称相同的多个 Pod,各 Pod 通过不同的端口号支持相同的网络协议, 此机制也可以工作。这一机制为 Service 的部署和演化提供了较高的灵活性。 例如,你可以在后端软件的新版本中更改 Pod 公开的端口号,但不会影响到客户端。
Service 的默认协议是 TCP; 你还可以使用其他受支持的任何协议。
由于许多 Service 需要公开多个端口,所以 Kubernetes 为同一服务定义多个端口。
每个端口定义可以具有相同的 protocol,也可以具有不同协议。
没有选择算符的 Service
由于选择算符的存在,Service 的最常见用法是为 Kubernetes Pod 集合提供访问抽象, 但是当与相应的 EndpointSlice 对象一起使用且没有设置选择算符时,Service 也可以为其他类型的后端提供抽象, 包括在集群外运行的后端。
例如:
- 你希望在生产环境中使用外部数据库集群,但在测试环境中使用自己的数据库。
- 你希望让你的 Service 指向另一个名字空间(Namespace)中或其它集群中的服务。
- 你正在将工作负载迁移到 Kubernetes 上来。在评估所采用的方法时,你仅在 Kubernetes 中运行一部分后端。
在所有这些场景中,你都可以定义不指定用来匹配 Pod 的选择算符的 Service。例如:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
由于此 Service 没有选择算符,因此不会自动创建对应的 EndpointSlice(和旧版的 Endpoints)对象。 你可以通过手动添加 EndpointSlice 对象,将 Service 映射到该服务运行位置的网络地址和端口:
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: my-service-1 # 按惯例将服务的名称用作 EndpointSlice 名称的前缀
labels:
# 你应设置 "kubernetes.io/service-name" 标签。
# 设置其值以匹配服务的名称
kubernetes.io/service-name: my-service
addressType: IPv4
ports:
- name: '' # 留空,因为 port 9376 未被 IANA 分配为已注册端口
appProtocol: http
protocol: TCP
port: 9376
endpoints: # 此列表中的 IP 地址可以按任何顺序显示
- addresses:
- "10.4.5.6"
- addresses:
- "10.1.2.3"
自定义 EndpointSlices
当为 Service 创建 EndpointSlice 对象时,可以为 EndpointSlice 使用任何名称。
一个名字空间中的各个 EndpointSlice 都必须具有一个唯一的名称。通过在 EndpointSlice 上设置
kubernetes.io/service-name 标签可以将
EndpointSlice 链接到 Service。
说明:
端点 IP 地址必须不是:本地回路地址(IPv4 的 127.0.0.0/8、IPv6 的 ::1/128) 或链路本地地址(IPv4 的 169.254.0.0/16 和 224.0.0.0/24、IPv6 的 fe80::/64)。
端点 IP 地址不能是其他 Kubernetes 服务的集群 IP,因为 kube-proxy 不支持将虚拟 IP 作为目标地址。
对于你自己或在你自己代码中创建的 EndpointSlice,你还应该为
endpointslice.kubernetes.io/managed-by
标签设置一个值。如果你创建自己的控制器代码来管理 EndpointSlice,
请考虑使用类似于 "my-domain.example/name-of-controller" 的值。
如果你使用的是第三方工具,请使用全小写的工具名称,并将空格和其他标点符号更改为短划线 (-)。
如果直接使用 kubectl 之类的工具来管理 EndpointSlice 对象,请使用用来描述这种手动管理的名称,
例如 "staff" 或 "cluster-admins"。你要避免使用保留值 "controller";
该值标识由 Kubernetes 自己的控制平面管理的 EndpointSlice。
访问没有选择算符的 Service
访问没有选择算符的 Service 与有选择算符的 Service 的原理相同。 在没有选择算符的 Service 示例中, 流量被路由到 EndpointSlice 清单中定义的两个端点之一: 通过 TCP 协议连接到 10.1.2.3 或 10.4.5.6 的端口 9376。
说明:
Kubernetes API 服务器不允许将流量代理到未被映射至 Pod 上的端点。由于此约束,当 Service
没有选择算符时,诸如 kubectl proxy <service-name> 之类的操作将会失败。这可以防止
Kubernetes API 服务器被用作调用者可能无权访问的端点的代理。
ExternalName Service 是 Service 的特例,它没有选择算符,而是使用 DNS 名称。
更多的相关信息,请参阅 ExternalName 一节。
EndpointSlices
特性状态:
Kubernetes v1.21 [stable]
EndpointSlice 对象表示某个服务的后端网络端点的子集(切片)。
你的 Kubernetes 集群会跟踪每个 EndpointSlice 所表示的端点数量。 如果 Service 的端点太多以至于达到阈值,Kubernetes 会添加另一个空的 EndpointSlice 并在其中存储新的端点信息。 默认情况下,一旦现有 EndpointSlice 都包含至少 100 个端点,Kubernetes 就会创建一个新的 EndpointSlice。 在需要添加额外的端点之前,Kubernetes 不会创建新的 EndpointSlice。
参阅 EndpointSlice 了解有关该 API 的更多信息。
Endpoints
在 Kubernetes API 中,Endpoints (该资源类别为复数形式)定义的是网络端点的列表,通常由 Service 引用, 以定义可以将流量发送到哪些 Pod。
推荐使用 EndpointSlice API 替换 Endpoints。
超出容量的端点
Kubernetes 限制单个 Endpoints 对象中可以容纳的端点数量。 当一个 Service 拥有 1000 个以上支撑端点时,Kubernetes 会截断 Endpoints 对象中的数据。 由于一个 Service 可以链接到多个 EndpointSlice 之上,所以 1000 个支撑端点的限制仅影响旧版的 Endpoints API。
如出现端点过多的情况,Kubernetes 选择最多 1000 个可能的后端端点存储到 Endpoints 对象中,
并在 Endpoints 上设置注解
endpoints.kubernetes.io/over-capacity: truncated。
如果后端 Pod 的数量降至 1000 以下,控制平面也会移除该注解。
请求流量仍会被发送到后端,但任何依赖旧版 Endpoints API 的负载均衡机制最多只能将流量发送到 1000 个可用的支撑端点。
这一 API 限制也意味着你不能手动将 Endpoints 更新为拥有超过 1000 个端点。
应用协议
特性状态:
Kubernetes v1.20 [stable]
appProtocol 字段提供了一种为每个 Service 端口设置应用协议的方式。
此字段被实现代码用作一种提示信息,以便针对实现能够理解的协议提供更为丰富的行为。
此字段的取值会被映射到对应的 Endpoints 和 EndpointSlice 对象中。
此字段遵循标准的 Kubernetes 标签语法。合法的取值值可以是以下之一:
- IANA 标准服务名称。
- 由具体实现所定义的、带有
mycompany.com/my-custom-protocol这类前缀的名称。 - Kubernetes 定义的前缀名称:
协议 描述 kubernetes.io/h2c基于明文的 HTTP/2 协议,如 RFC 7540 所述
多端口 Service
对于某些 Service,你需要公开多个端口。Kubernetes 允许你为 Service 对象配置多个端口定义。 为 Service 使用多个端口时,必须为所有端口提供名称,以使它们无歧义。 例如:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
说明:
与一般的 Kubernetes 名称一样,端口名称只能包含小写字母、数字和 -。
端口名称还必须以字母或数字开头和结尾。
例如,名称 123-abc 和 web 是合法的,但是 123_abc 和 -web 不合法。
服务类型
对一些应用的某些部分(如前端),你可能希望将其公开于某外部 IP 地址, 也就是可以从集群外部访问的某个地址。
Kubernetes Service 类型允许指定你所需要的 Service 类型。
可用的 type 值及其行为有:
ClusterIP- 通过集群的内部 IP 公开 Service,选择该值时 Service 只能够在集群内部访问。
这也是你没有为服务显式指定
type时使用的默认值。 你可以使用 Ingress 或者 Gateway API 向公共互联网公开服务。 NodePort- 通过每个节点上的 IP 和静态端口(
NodePort)公开 Service。 为了让 Service 可通过节点端口访问,Kubernetes 会为 Service 配置集群 IP 地址, 相当于你请求了type: ClusterIP的服务。
LoadBalancer- 使用云平台的负载均衡器向外部公开 Service。Kubernetes 不直接提供负载均衡组件; 你必须提供一个,或者将你的 Kubernetes 集群与某个云平台集成。
ExternalName- 将服务映射到
externalName字段的内容(例如,映射到主机名api.foo.bar.example)。 该映射将集群的 DNS 服务器配置为返回具有该外部主机名值的CNAME记录。 集群不会为之创建任何类型代理。
服务 API 中的 type 字段被设计为层层递进的形式 - 每层都建立在前一层的基础上。
但是,这种层层递进的形式有一个例外。
你可以在定义 LoadBalancer 服务时禁止负载均衡器分配 NodePort。
type: ClusterIP
此默认 Service 类型从你的集群中为此预留的 IP 地址池中分配一个 IP 地址。
其他几种 Service 类型在 ClusterIP 类型的基础上进行构建。
如果你定义的 Service 将 .spec.clusterIP 设置为 "None",则 Kubernetes
不会为其分配 IP 地址。有关详细信息,请参阅无头服务。
选择自己的 IP 地址
在创建 Service 的请求中,你可以通过设置 spec.clusterIP 字段来指定自己的集群 IP 地址。
比如,希望复用一个已存在的 DNS 条目,或者遗留系统已经配置了一个固定的 IP 且很难重新配置。
你所选择的 IP 地址必须是合法的 IPv4 或者 IPv6 地址,并且这个 IP 地址在 API 服务器上所配置的
service-cluster-ip-range CIDR 范围内。
如果你尝试创建一个带有非法 clusterIP 地址值的 Service,API 服务器会返回 HTTP 状态码 422,
表示值不合法。
请阅读避免冲突节, 以了解 Kubernetes 如何协助降低两个不同的 Service 试图使用相同 IP 地址的风险和影响。
type: NodePort
如果你将 type 字段设置为 NodePort,则 Kubernetes 控制平面将在
--service-node-port-range 标志所指定的范围内分配端口(默认值:30000-32767)。
每个节点将该端口(每个节点上的相同端口号)上的流量代理到你的 Service。
你的 Service 在其 .spec.ports[*].nodePort 字段中报告已分配的端口。
使用 NodePort 可以让你自由设置自己的负载均衡解决方案, 配置 Kubernetes 不完全支持的环境, 甚至直接公开一个或多个节点的 IP 地址。
对于 NodePort 服务,Kubernetes 额外分配一个端口(TCP、UDP 或 SCTP 以匹配 Service 的协议)。
集群中的每个节点都将自己配置为监听所分配的端口,并将流量转发到与该 Service 关联的某个就绪端点。
通过使用合适的协议(例如 TCP)和适当的端口(分配给该 Service)连接到任何一个节点,
你就能够从集群外部访问 type: NodePort 服务。
选择你自己的端口
如果需要特定的端口号,你可以在 nodePort 字段中指定一个值。
控制平面将或者为你分配该端口,或者报告 API 事务失败。
这意味着你需要自行注意可能发生的端口冲突。
你还必须使用有效的端口号,该端口号在配置用于 NodePort 的范围内。
以下是 type: NodePort 服务的一个清单示例,其中指定了 NodePort 值(在本例中为 30007):
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app.kubernetes.io/name: MyApp
ports:
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
- port: 80
targetPort: 80
# 可选字段
# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号
#(默认:30000-32767)
nodePort: 30007
预留 NodePort 端口范围以避免发生冲突
特性状态:
Kubernetes v1.29 [stable]
为 NodePort 服务分配端口的策略既适用于自动分配的情况,也适用于手动分配的场景。 当某个用于希望创建一个使用特定端口的 NodePort 服务时,该目标端口可能与另一个已经被分配的端口冲突。
为了避免这个问题,用于 NodePort 服务的端口范围被分为两段。 动态端口分配默认使用较高的端口段,并且在较高的端口段耗尽时也可以使用较低的端口段。 用户可以从较低端口段中分配端口,降低端口冲突的风险。
为 type: NodePort 服务自定义 IP 地址配置
你可以配置集群中的节点使用特定 IP 地址来支持 NodePort 服务。 如果每个节点都连接到多个网络(例如:一个网络用于应用流量,另一网络用于节点和控制平面之间的流量), 你可能想要这样做。
如果你要指定特定的 IP 地址来为端口提供代理,可以将 kube-proxy 的 --nodeport-addresses 标志或
kube-proxy 配置文件中的等效字段
nodePortAddresses 设置为特定的 IP 段。
此标志接受逗号分隔的 IP 段列表(例如 10.0.0.0/8、192.0.2.0/25),用来设置 IP 地址范围。
kube-proxy 应视将其视为所在节点的本机地址。
例如,如果你使用 --nodeport-addresses=127.0.0.0/8 标志启动 kube-proxy,
则 kube-proxy 仅选择 NodePort 服务的本地回路接口。
--nodeport-addresses 的默认值是一个空的列表。
这意味着 kube-proxy 将认为所有可用网络接口都可用于 NodePort 服务
(这也与早期的 Kubernetes 版本兼容。)
说明:
此 Service 的可见形式为 <NodeIP>:spec.ports[*].nodePort 以及 .spec.clusterIP:spec.ports[*].port。
如果设置了 kube-proxy 的 --nodeport-addresses 标志或 kube-proxy 配置文件中的等效字段,
则 <NodeIP> 将是一个被过滤的节点 IP 地址(或可能是多个 IP 地址)。
type: LoadBalancer
在使用支持外部负载均衡器的云平台时,如果将 type 设置为 "LoadBalancer",
则平台会为 Service 提供负载均衡器。
负载均衡器的实际创建过程是异步进行的,关于所制备的负载均衡器的信息将会通过 Service 的
status.loadBalancer 字段公开出来。
例如:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
clusterIP: 10.0.171.239
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 192.0.2.127
来自外部负载均衡器的流量将被直接重定向到后端各个 Pod 上,云平台决定如何进行负载平衡。
要实现 type: LoadBalancer 的服务,Kubernetes 通常首先进行与请求 type: NodePort
服务类似的更改。cloud-controller-manager 组件随后配置外部负载均衡器,
以将流量转发到所分配的节点端口。
你可以将负载均衡 Service 配置为忽略分配节点端口, 前提是云平台实现支持这点。
某些云平台允许你设置 loadBalancerIP。这时,平台将使用用户指定的 loadBalancerIP
来创建负载均衡器。如果没有设置 loadBalancerIP 字段,平台将会给负载均衡器分配一个临时 IP。
如果设置了 loadBalancerIP,但云平台并不支持这一特性,所设置的 loadBalancerIP 值将会被忽略。
说明:
针对 Service 的 .spec.loadBalancerIP 字段已在 Kubernetes v1.24 中被弃用。
此字段的定义模糊,其含义因实现而异。它也不支持双协议栈联网。 此字段可能会在未来的 API 版本中被移除。
如果你正在集成某云平台,该平台通过(特定于平台的)注解为 Service 指定负载均衡器 IP 地址, 你应该切换到这种做法。
如果你正在为集成到 Kubernetes 的负载均衡器编写代码,请避免使用此字段。 你可以与 Gateway 而不是 Service 集成, 或者你可以在 Service 上定义自己的(特定于提供商的)注解,以指定等效的细节。
混合协议类型的负载均衡器
特性状态:
Kubernetes v1.26 [stable]
默认情况下,对于 LoadBalancer 类型的 Service,当其中定义了多个端口时, 所有端口必须使用相同的协议,并且该协议必须是被云平台支持的。
当服务中定义了多个端口时,特性门控 MixedProtocolLBService(从 kube-apiserver 1.24
版本起默认为启用)允许 LoadBalancer 类型的服务使用不同的协议。
说明:
可用于负载均衡服务的协议集合由你的云平台决定,他们可能在 Kubernetes API 强制执行的限制之外另加一些约束。
禁用负载均衡服务的节点端口分配
特性状态:
Kubernetes v1.24 [stable]
通过设置 Service 的 spec.allocateLoadBalancerNodePorts 为 false,你可以对 LoadBalancer
类型的 Service 禁用节点端口分配操作。
这仅适用于负载均衡器的实现能够直接将流量路由到 Pod 而不是使用节点端口的情况。
默认情况下,spec.allocateLoadBalancerNodePorts 为 true,LoadBalancer 类型的 Service
也会继续分配节点端口。如果某已有 Service 已被分配节点端口,如果将其属性
spec.allocateLoadBalancerNodePorts 设置为 false,这些节点端口不会被自动释放。
你必须显式地在每个 Service 端口中删除 nodePorts 项以释放对应的端口。
设置负载均衡器实现的类别
特性状态:
Kubernetes v1.24 [stable]
对于 type 设置为 LoadBalancer 的 Service,spec.loadBalancerClass
字段允许你使用有别于云平台的默认负载均衡器的实现。
默认情况下,.spec.loadBalancerClass 是未设置的,如果集群使用 --cloud-provider
件标志配置了云平台,LoadBalancer 类型 Service 会使用云平台的默认负载均衡器实现。
如果你设置了 .spec.loadBalancerClass,则假定存在某个与所指定的类相匹配的负载均衡器实现在监视
Service 变更。所有默认的负载均衡器实现(例如,由云平台所提供的)都会忽略设置了此字段的 Service。
.spec.loadBalancerClass 只能设置到类型为 LoadBalancer 的 Service 之上,
而且一旦设置之后不可变更。
.spec.loadBalancerClass 的值必须是一个标签风格的标识符,
可以有选择地带有类似 "internal-vip" 或 "example.com/internal-vip" 这类前缀。
没有前缀的名字是保留给最终用户的。
指定负载均衡器状态的 IPMode
特性状态:
Kubernetes v1.29 [alpha]
这是从 Kubernetes 1.29 开始的一个 Alpha 级别特性,通过名为 LoadBalancerIPMode
的特性门控允许你为
type 为 LoadBalancer 的服务设置 .status.loadBalancer.ingress.ipMode。
.status.loadBalancer.ingress.ipMode 指定负载均衡器 IP 的行为方式。
此字段只能在 .status.loadBalancer.ingress.ip 字段也被指定时才能指定。
.status.loadBalancer.ingress.ipMode 有两个可能的值:"VIP" 和 "Proxy"。
默认值是 "VIP",意味着流量被传递到目的地设置为负载均衡器 IP 和端口的节点上。
将此字段设置为 "Proxy" 时会出现两种情况,具体取决于云驱动提供的负载均衡器如何传递流量:
- 如果流量被传递到节点,然后 DNAT 到 Pod,则目的地将被设置为节点的 IP 和节点端口;
- 如果流量被直接传递到 Pod,则目的地将被设置为 Pod 的 IP 和端口。
服务实现可以使用此信息来调整流量路由。
内部负载均衡器
在混合环境中,有时有必要在同一(虚拟)网络地址段内路由来自 Service 的流量。
在水平分割(Split-Horizon)DNS 环境中,你需要两个 Service 才能将内部和外部流量都路由到你的端点。
如要设置内部负载均衡器,请根据你所使用的云平台,为 Service 添加以下注解之一:
选择一个标签。
metadata:
name: my-service
annotations:
networking.gke.io/load-balancer-type: "Internal"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-internal: "true"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/azure-load-balancer-internal: "true"
metadata:
name: my-service
annotations:
service.kubernetes.io/ibm-load-balancer-cloud-provider-ip-type: "private"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/cce-load-balancer-internal-vpc: "true"
metadata:
annotations:
service.kubernetes.io/qcloud-loadbalancer-internal-subnetid: subnet-xxxxx
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "intranet"
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/oci-load-balancer-internal: true
ExternalName 类型
类型为 ExternalName 的 Service 将 Service 映射到 DNS 名称,而不是典型的选择算符,
例如 my-service 或者 cassandra。你可以使用 spec.externalName 参数指定这些服务。
例如,以下 Service 定义将 prod 名字空间中的 my-service 服务映射到 my.database.example.com:
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
说明:
type: ExternalName 的服务接受 IPv4 地址字符串,但将该字符串视为由数字组成的 DNS 名称,
而不是 IP 地址(然而,互联网不允许在 DNS 中使用此类名称)。
类似于 IPv4 地址的外部名称无法被 DNS 服务器解析。
如果你想要将服务直接映射到某特定 IP 地址,请考虑使用无头服务。
当查找主机 my-service.prod.svc.cluster.local 时,集群 DNS 服务返回 CNAME 记录,
其值为 my.database.example.com。访问 my-service 的方式与访问其他 Service 的方式相同,
主要区别在于重定向发生在 DNS 级别,而不是通过代理或转发来完成。
如果后来你决定将数据库移到集群中,则可以启动其 Pod,添加适当的选择算符或端点并更改
Service 的 type。
注意:
针对 ExternalName 服务使用一些常见的协议,包括 HTTP 和 HTTPS,可能会有问题。 如果你使用 ExternalName 服务,那么集群内客户端使用的主机名与 ExternalName 引用的名称不同。
对于使用主机名的协议,这一差异可能会导致错误或意外响应。
HTTP 请求将具有源服务器无法识别的 Host: 标头;
TLS 服务器将无法提供与客户端连接的主机名匹配的证书。
无头服务(Headless Services)
有时你并不需要负载均衡,也不需要单独的 Service IP。遇到这种情况,可以通过显式设置
集群 IP(spec.clusterIP)的值为 "None" 来创建无头服务(Headless Service)。
你可以使用无头 Service 与其他服务发现机制交互,而不必绑定到 Kubernetes 的实现。
无头 Service 不会获得集群 IP,kube-proxy 不会处理这类 Service, 而且平台也不会为它们提供负载均衡或路由支持。 取决于 Service 是否定义了选择算符,DNS 会以不同的方式被自动配置。
带选择算符的服务
对定义了选择算符的无头 Service,Kubernetes 控制平面在 Kubernetes API 中创建 EndpointSlice 对象,并且修改 DNS 配置返回 A 或 AAAA 记录(IPv4 或 IPv6 地址), 这些记录直接指向 Service 的后端 Pod 集合。
无选择算符的服务
对没有定义选择算符的无头 Service,控制平面不会创建 EndpointSlice 对象。 然而 DNS 系统会执行以下操作之一:
- 对于
type: ExternalNameService,查找和配置其 CNAME 记录; - 对所有其他类型的 Service,针对 Service 的就绪端点的所有 IP 地址,查找和配置
DNS A / AAAA 记录:
- 对于 IPv4 端点,DNS 系统创建 A 记录。
- 对于 IPv6 端点,DNS 系统创建 AAAA 记录。
当你定义无选择算符的无头 Service 时,port 必须与 targetPort 匹配。
服务发现
对于在集群内运行的客户端,Kubernetes 支持两种主要的服务发现模式:环境变量和 DNS。
环境变量
当 Pod 运行在某 Node 上时,kubelet 会在其中为每个活跃的 Service 添加一组环境变量。
kubelet 会添加环境变量 {SVCNAME}_SERVICE_HOST 和 {SVCNAME}_SERVICE_PORT。
这里 Service 的名称被转为大写字母,横线被转换成下划线。
例如,一个 Service redis-primary 公开了 TCP 端口 6379,
同时被分配了集群 IP 地址 10.0.0.11,这个 Service 生成的环境变量如下:
REDIS_PRIMARY_SERVICE_HOST=10.0.0.11
REDIS_PRIMARY_SERVICE_PORT=6379
REDIS_PRIMARY_PORT=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP_PROTO=tcp
REDIS_PRIMARY_PORT_6379_TCP_PORT=6379
REDIS_PRIMARY_PORT_6379_TCP_ADDR=10.0.0.11
说明:
当你的 Pod 需要访问某 Service,并且你在使用环境变量方法将端口和集群 IP 发布到客户端 Pod 时,必须在客户端 Pod 出现之前创建该 Service。 否则,这些客户端 Pod 中将不会出现对应的环境变量。
如果仅使用 DNS 来发现 Service 的集群 IP,则无需担心此顺序问题。
Kubernetes 还支持并提供与 Docker Engine 的 "legacy container links" 兼容的变量。 你可以阅读 makeLinkVariables 来了解这是如何在 Kubernetes 中实现的。
DNS
你可以(并且几乎总是应该)使用插件(add-on) 来为 Kubernetes 集群安装 DNS 服务。
能够感知集群的 DNS 服务器(例如 CoreDNS)会监视 Kubernetes API 中的新 Service, 并为每个 Service 创建一组 DNS 记录。如果在整个集群中都启用了 DNS,则所有 Pod 都应该能够通过 DNS 名称自动解析 Service。
例如,如果你在 Kubernetes 命名空间 my-ns 中有一个名为 my-service 的 Service,
则控制平面和 DNS 服务共同为 my-service.my-ns 生成 DNS 记录。
名字空间 my-ns 中的 Pod 应该能够通过按名检索 my-service 来找到服务
(my-service.my-ns 也可以)。
其他名字空间中的 Pod 必须将名称限定为 my-service.my-ns。
这些名称将解析为分配给 Service 的集群 IP。
Kubernetes 还支持命名端口的 DNS SRV(Service)记录。
如果 Service my-service.my-ns 具有名为 http 的端口,且协议设置为 TCP,
则可以用 _http._tcp.my-service.my-ns 执行 DNS SRV 查询以发现 http 的端口号以及 IP 地址。
Kubernetes DNS 服务器是唯一的一种能够访问 ExternalName 类型的 Service 的方式。
关于 ExternalName 解析的更多信息可以查看
Service 与 Pod 的 DNS。
虚拟 IP 寻址机制
阅读虚拟 IP 和 Service 代理以了解 Kubernetes 提供的使用虚拟 IP 地址公开服务的机制。
流量策略
你可以设置 .spec.internalTrafficPolicy 和 .spec.externalTrafficPolicy
字段来控制 Kubernetes 如何将流量路由到健康(“就绪”)的后端。
有关详细信息,请参阅流量策略。
会话的黏性
如果你想确保来自特定客户端的连接每次都传递到同一个 Pod,你可以配置基于客户端 IP 地址的会话亲和性。可阅读会话亲和性 来进一步学习。
外部 IP
如果有外部 IP 能够路由到一个或多个集群节点上,则 Kubernetes Service 可以在这些 externalIPs
上公开出去。当网络流量进入集群时,如果外部 IP(作为目的 IP 地址)和端口都与该 Service 匹配,
Kubernetes 所配置的规则和路由会确保流量被路由到该 Service 的端点之一。
定义 Service 时,你可以为任何服务类型指定 externalIPs。
在下面的例子中,名为 my-service 的服务可以在 "198.51.100.32:80"
(根据 .spec.externalIPs[] 和 .spec.ports[].port 得出)上被客户端使用 TCP 协议访问。
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 49152
externalIPs:
- 198.51.100.32
说明:
Kubernetes 不负责管理 externalIPs 的分配,这一工作是集群管理员的职责。
API 对象
Service 是 Kubernetes REST API 中的顶级资源。你可以找到有关 Service 对象 API 的更多详细信息。
接下来
进一步学习 Service 及其在 Kubernetes 中所发挥的作用:
- 完成使用 Service 连接到应用教程。
- 阅读 Ingress 文档。Ingress 负责将来自集群外部的 HTTP 和 HTTPS 请求路由给集群内的服务。
- 阅读 Gateway 文档。Gateway 作为 Kubernetes 的扩展提供比 Ingress 更高的灵活性。
更多上下文,可以阅读以下内容:
5.2 - Ingress
使用一种能感知协议配置的机制来解析 URI、主机名称、路径等 Web 概念, 让你的 HTTP(或 HTTPS)网络服务可被访问。 Ingress 概念允许你通过 Kubernetes API 定义的规则将流量映射到不同后端。
特性状态:
Kubernetes v1.19 [stable]
Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。
Ingress 可以提供负载均衡、SSL 终结和基于名称的虚拟托管。
说明:
入口(Ingress)目前已停止更新。新的功能正在集成至网关 API 中。
术语
为了表达更加清晰,本指南定义以下术语:
- 节点(Node): Kubernetes 集群中的一台工作机器,是集群的一部分。
- 集群(Cluster): 一组运行容器化应用程序的 Node,这些应用由 Kubernetes 管理。 在此示例和在大多数常见的 Kubernetes 部署环境中,集群中的节点都不在公共网络中。
- 边缘路由器(Edge Router): 在集群中强制执行防火墙策略的路由器。 可以是由云提供商管理的网关,也可以是物理硬件。
- 集群网络(Cluster Network): 一组逻辑的或物理的连接,基于 Kubernetes 网络模型实现集群内的通信。
- 服务(Service):Kubernetes 服务(Service), 使用标签选择算符(Selectors) 来选择一组 Pod。除非另作说明,否则假定 Service 具有只能在集群网络内路由的虚拟 IP。
Ingress 是什么?
Ingress 提供从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源所定义的规则来控制。
下面是 Ingress 的一个简单示例,可将所有流量都发送到同一 Service:

图. Ingress
通过配置,Ingress 可为 Service 提供外部可访问的 URL、对其流量作负载均衡、 终止 SSL/TLS,以及基于名称的虚拟托管等能力。 Ingress 控制器 负责完成 Ingress 的工作,具体实现上通常会使用某个负载均衡器, 不过也可以配置边缘路由器或其他前端来帮助处理流量。
Ingress 不会随意公开端口或协议。 将 HTTP 和 HTTPS 以外的服务开放到 Internet 时,通常使用 Service.Type=NodePort 或 Service.Type=LoadBalancer 类型的 Service。
环境准备
你必须拥有一个 Ingress 控制器 才能满足 Ingress 的要求。仅创建 Ingress 资源本身没有任何效果。
你可能需要部署一个 Ingress 控制器,例如 ingress-nginx。 你可以从许多 Ingress 控制器中进行选择。
理想情况下,所有 Ingress 控制器都应遵从参考规范。 但实际上,各个 Ingress 控制器操作略有不同。
说明:
确保你查看了 Ingress 控制器的文档,以了解选择它的注意事项。
Ingress 资源
一个最小的 Ingress 资源示例:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx-example
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80
Ingress 需要指定 apiVersion、kind、 metadata和 spec 字段。
Ingress 对象的命名必须是合法的 DNS 子域名名称。
关于如何使用配置文件的一般性信息,请参见部署应用、
配置容器、
管理资源。
Ingress 经常使用注解(Annotations)来配置一些选项,具体取决于 Ingress 控制器,
例如 rewrite-target 注解。
不同的 Ingress 控制器支持不同的注解。
查看你所选的 Ingress 控制器的文档,以了解其所支持的注解。
Ingress 规约 提供了配置负载均衡器或者代理服务器所需要的所有信息。 最重要的是,其中包含对所有入站请求进行匹配的规则列表。 Ingress 资源仅支持用于转发 HTTP(S) 流量的规则。
如果 ingressClassName 被省略,那么你应该定义一个默认的 Ingress 类。
有些 Ingress 控制器不需要定义默认的 IngressClass。比如:Ingress-NGINX
控制器可以通过参数
--watch-ingress-without-class 来配置。
不过仍然推荐
按下文所示来设置默认的 IngressClass。
Ingress 规则
每个 HTTP 规则都包含以下信息:
- 可选的
host。在此示例中,未指定host,因此该规则基于所指定 IP 地址来匹配所有入站 HTTP 流量。 如果提供了host(例如foo.bar.com),则rules适用于所指定的主机。 - 路径列表(例如
/testpath)。每个路径都有一个由service.name和service.port.name或service.port.number确定的关联后端。 主机和路径都必须与入站请求的内容相匹配,负载均衡器才会将流量引导到所引用的 Service, backend(后端)是 Service 文档中所述的 Service 和端口名称的组合, 或者是通过 CRD 方式来实现的自定义资源后端。 对于发往 Ingress 的 HTTP(和 HTTPS)请求,如果与规则中的主机和路径匹配, 则会被发送到所列出的后端。
通常会在 Ingress 控制器中配置 defaultBackend(默认后端),
以便为无法与规约中任何路径匹配的所有请求提供服务。
默认后端
没有设置规则的 Ingress 将所有流量发送到同一个默认后端,而在这种情况下
.spec.defaultBackend 则是负责处理请求的那个默认后端。
defaultBackend 通常是
Ingress 控制器的配置选项,
而非在 Ingress 资源中设置。
如果未设置 .spec.rules,则必须设置 .spec.defaultBackend。
如果未设置 defaultBackend,那么如何处理与所有规则都不匹配的流量将交由
Ingress 控制器决定(请参考你的 Ingress 控制器的文档以了解它是如何处理这种情况的)。
如果 Ingress 对象中主机和路径都没有与 HTTP 请求匹配,则流量将被路由到默认后端。
资源后端
Resource 后端是一个 ObjectRef 对象,指向同一名字空间中的另一个 Kubernetes 资源,
将其视为 Ingress 对象。
Resource 后端与 Service 后端是互斥的,在二者均被设置时会无法通过合法性检查。
Resource 后端的一种常见用法是将所有入站数据导向保存静态资产的对象存储后端。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-resource-backend
spec:
defaultBackend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: static-assets
rules:
- http:
paths:
- path: /icons
pathType: ImplementationSpecific
backend:
resource:
apiGroup: k8s.example.com
kind: StorageBucket
name: icon-assets
创建了如上的 Ingress 之后,你可以使用下面的命令查看它:
kubectl describe ingress ingress-resource-backend
Name: ingress-resource-backend
Namespace: default
Address:
Default backend: APIGroup: k8s.example.com, Kind: StorageBucket, Name: static-assets
Rules:
Host Path Backends
---- ---- --------
*
/icons APIGroup: k8s.example.com, Kind: StorageBucket, Name: icon-assets
Annotations: <none>
Events: <none>
路径类型
Ingress 中的每个路径都需要有对应的路径类型(Path Type)。未明确设置 pathType
的路径无法通过合法性检查。当前支持的路径类型有三种:
-
ImplementationSpecific:对于这种路径类型,匹配方法取决于 IngressClass。 具体实现可以将其作为单独的pathType处理或者作与Prefix或Exact类型相同的处理。 -
Exact:精确匹配 URL 路径,且区分大小写。 -
Prefix:基于以/分隔的 URL 路径前缀匹配。匹配区分大小写, 并且对路径中各个元素逐个执行匹配操作。 路径元素指的是由/分隔符分隔的路径中的标签列表。 如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。说明: 如果路径的最后一个元素是请求路径中最后一个元素的子字符串,则不会被视为匹配 (例如:/foo/bar匹配/foo/bar/baz, 但不匹配/foo/barbaz)。
示例
| 类型 | 路径 | 请求路径 | 匹配与否? |
|---|---|---|---|
| Prefix | / |
(所有路径) | 是 |
| Exact | /foo |
/foo |
是 |
| Exact | /foo |
/bar |
否 |
| Exact | /foo |
/foo/ |
否 |
| Exact | /foo/ |
/foo |
否 |
| Prefix | /foo |
/foo, /foo/ |
是 |
| Prefix | /foo/ |
/foo, /foo/ |
是 |
| Prefix | /aaa/bb |
/aaa/bbb |
否 |
| Prefix | /aaa/bbb |
/aaa/bbb |
是 |
| Prefix | /aaa/bbb/ |
/aaa/bbb |
是,忽略尾部斜线 |
| Prefix | /aaa/bbb |
/aaa/bbb/ |
是,匹配尾部斜线 |
| Prefix | /aaa/bbb |
/aaa/bbb/ccc |
是,匹配子路径 |
| Prefix | /aaa/bbb |
/aaa/bbbxyz |
否,字符串前缀不匹配 |
| Prefix | /, /aaa |
/aaa/ccc |
是,匹配 /aaa 前缀 |
| Prefix | /, /aaa, /aaa/bbb |
/aaa/bbb |
是,匹配 /aaa/bbb 前缀 |
| Prefix | /, /aaa, /aaa/bbb |
/ccc |
是,匹配 / 前缀 |
| Prefix | /aaa |
/ccc |
否,使用默认后端 |
| 混合 | /foo (Prefix), /foo (Exact) |
/foo |
是,优选 Exact 类型 |
多重匹配
在某些情况下,Ingress 中会有多条路径与同一个请求匹配。这时匹配路径最长者优先。 如果仍然有两条同等的匹配路径,则精确路径类型优先于前缀路径类型。
主机名通配符
主机名可以是精确匹配(例如 “foo.bar.com”)或者使用通配符来匹配
(例如 “*.foo.com”)。
精确匹配要求 HTTP host 头部字段与 host 字段值完全匹配。
通配符匹配则要求 HTTP host 头部字段与通配符规则中的后缀部分相同。
| 主机 | host 头部 | 匹配与否? |
|---|---|---|
*.foo.com |
bar.foo.com |
基于相同的后缀匹配 |
*.foo.com |
baz.bar.foo.com |
不匹配,通配符仅覆盖了一个 DNS 标签 |
*.foo.com |
foo.com |
不匹配,通配符仅覆盖了一个 DNS 标签 |
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80
Ingress 类
Ingress 可以由不同的控制器实现,通常使用不同的配置。 每个 Ingress 应当指定一个类,也就是一个对 IngressClass 资源的引用。 IngressClass 资源包含额外的配置,其中包括应当实现该类的控制器名称。
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com
kind: IngressParameters
name: external-lb
IngressClass 中的 .spec.parameters 字段可用于引用其他资源以提供与该
IngressClass 相关的配置。
参数(parameters)的具体类型取决于你在 IngressClass 的 .spec.controller
字段中指定的 Ingress 控制器。
IngressClass 的作用域
取决于你所使用的 Ingress 控制器,你可能可以使用集群作用域的参数或某个名字空间作用域的参数。
IngressClass 参数的默认作用域是集群范围。
如果你设置了 .spec.parameters 字段且未设置 .spec.parameters.scope
字段,或是将 .spec.parameters.scope 字段设为了 Cluster,
那么该 IngressClass 所引用的即是一个集群作用域的资源。
参数的 kind(和 apiGroup 一起)指向一个集群作用域的 API 类型
(可能是一个定制资源(Custom Resource)),而其 name 字段则进一步确定
该 API 类型的一个具体的、集群作用域的资源。
示例:
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb-1
spec:
controller: example.com/ingress-controller
parameters:
# 此 IngressClass 的配置定义在一个名为 “external-config-1” 的
# ClusterIngressParameter(API 组为 k8s.example.net)资源中。
# 这项定义告诉 Kubernetes 去寻找一个集群作用域的参数资源。
scope: Cluster
apiGroup: k8s.example.net
kind: ClusterIngressParameter
name: external-config-1
特性状态:
Kubernetes v1.23 [stable]
如果你设置了 .spec.parameters 字段且将 .spec.parameters.scope
字段设为了 Namespace,那么该 IngressClass 将会引用一个名字空间作用域的资源。
.spec.parameters.namespace 必须和此资源所处的名字空间相同。
参数的 kind(和 apiGroup 一起)指向一个命名空间作用域的 API 类型
(例如:ConfigMap),而其 name 则进一步确定指定 API 类型的、
位于你指定的命名空间中的具体资源。
名字空间作用域的参数帮助集群操作者将对工作负载所需的配置数据(比如:负载均衡设置、 API 网关定义)的控制权力委派出去。如果你使用集群作用域的参数,那么你将面临一下情况之一:
- 每次应用一项新的配置变更时,集群操作团队需要批准其他团队所作的修改。
- 集群操作团队必须定义具体的准入控制规则,比如 RBAC 角色与角色绑定,以使得应用程序团队可以修改集群作用域的配置参数资源。
IngressClass API 本身是集群作用域的。
这里是一个引用名字空间作用域配置参数的 IngressClass 的示例:
---
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: external-lb-2
spec:
controller: example.com/ingress-controller
parameters:
# 此 IngressClass 的配置定义在一个名为 “external-config” 的
# IngressParameter(API 组为 k8s.example.com)资源中,
# 该资源位于 “external-configuration” 名字空间中。
scope: Namespace
apiGroup: k8s.example.com
kind: IngressParameter
namespace: external-configuration
name: external-config
已废弃的注解
在 Kubernetes 1.18 版本引入 IngressClass 资源和 ingressClassName 字段之前,
Ingress 类是通过 Ingress 中的一个 kubernetes.io/ingress.class 注解来指定的。
这个注解从未被正式定义过,但是得到了 Ingress 控制器的广泛支持。
Ingress 中新的 ingressClassName 字段用来替代该注解,但并非完全等价。
注解通常用于引用实现该 Ingress 的控制器的名称,而这个新的字段则是对一个包含额外
Ingress 配置的 IngressClass 资源的引用,其中包括了 Ingress 控制器的名称。
默认 Ingress 类
你可以将一个特定的 IngressClass 标记为集群默认 Ingress 类。
将某个 IngressClass 资源的 ingressclass.kubernetes.io/is-default-class 注解设置为
true 将确保新的未指定 ingressClassName 字段的 Ingress 能够被赋予这一默认
IngressClass.
注意:
如果集群中有多个 IngressClass 被标记为默认,准入控制器将阻止创建新的未指定
ingressClassName 的 Ingress 对象。
解决这个问题需要确保集群中最多只能有一个 IngressClass 被标记为默认。
有一些 Ingress 控制器不需要定义默认的 IngressClass。比如:Ingress-NGINX
控制器可以通过参数
--watch-ingress-without-class 来配置。
不过仍然推荐
设置默认的 IngressClass。
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
labels:
app.kubernetes.io/component: controller
name: nginx-example
annotations:
ingressclass.kubernetes.io/is-default-class: "true"
spec:
controller: k8s.io/ingress-nginx
Ingress 类型
由单个 Service 来支持的 Ingress
现有的 Kubernetes 概念允许你暴露单个 Service(参见替代方案)。 你也可以使用 Ingress 并设置无规则的默认后端来完成这类操作。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: test-ingress
spec:
defaultBackend:
service:
name: test
port:
number: 80
如果使用 kubectl apply -f 创建此 Ingress,则应该能够查看刚刚添加的 Ingress 的状态:
kubectl get ingress test-ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test-ingress external-lb * 203.0.113.123 80 59s
其中 203.0.113.123 是由 Ingress 控制器分配的 IP,用以服务于此 Ingress。
说明:
Ingress 控制器和负载平衡器的 IP 地址分配操作可能需要一两分钟。
在此之前,你通常会看到地址字段的取值为 <pending>。
简单扇出
一个扇出(Fanout)配置根据请求的 HTTP URI 将来自同一 IP 地址的流量路由到多个 Service。 Ingress 允许你将负载均衡器的数量降至最低。例如,这样的设置:

图. Ingress 扇出
这将需要一个如下所示的 Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-fanout-example
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: service1
port:
number: 4200
- path: /bar
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080
当你使用 kubectl apply -f 创建 Ingress 时:
kubectl describe ingress simple-fanout-example
Name: simple-fanout-example
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:4200 (10.8.0.90:4200)
/bar service2:8080 (10.8.0.91:8080)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 22s loadbalancer-controller default/test
此 Ingress 控制器构造一个特定于实现的负载均衡器来供 Ingress 使用,
前提是 Service (service1、service2)存在。
当它完成负载均衡器的创建时,你会在 Address 字段看到负载均衡器的地址。
说明:
取决于你所使用的 Ingress 控制器, 你可能需要创建默认 HTTP 后端服务。
基于名称的虚拟主机服务
基于名称的虚拟主机支持将针对多个主机名的 HTTP 流量路由到同一 IP 地址上。

图. 基于名称实现虚拟托管的 Ingress
以下 Ingress 让后台负载均衡器基于 host 头部字段来路由请求。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress
spec:
rules:
- host: foo.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: bar.foo.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
如果你所创建的 Ingress 资源没有在 rules 中定义主机,则规则可以匹配指向
Ingress 控制器 IP 地址的所有网络流量,而无需基于名称的虚拟主机。
例如,下面的 Ingress 对象会将请求 first.bar.com 的流量路由到 service1,将请求
second.bar.com 的流量路由到 service2,而将所有其他流量路由到 service3。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress-no-third-host
spec:
rules:
- host: first.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: second.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
- http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service3
port:
number: 80
TLS
你可以通过设定包含 TLS 私钥和证书的Secret
来保护 Ingress。
Ingress 资源只支持一个 TLS 端口 443,并假定 TLS 连接终止于 Ingress 节点
(与 Service 及其 Pod 间的流量都以明文传输)。
如果 Ingress 中的 TLS 配置部分指定了不同主机,那么它们将通过
SNI TLS 扩展指定的主机名(如果 Ingress 控制器支持 SNI)在同一端口上进行复用。
TLS Secret 的数据中必须包含键名为 tls.crt 的证书和键名为 tls.key 的私钥,
才能用于 TLS 目的。例如:
apiVersion: v1
kind: Secret
metadata:
name: testsecret-tls
namespace: default
data:
tls.crt: base64 编码的证书
tls.key: base64 编码的私钥
type: kubernetes.io/tls
在 Ingress 中引用此 Secret 将会告诉 Ingress 控制器使用 TLS 加密从客户端到负载均衡器的通道。
你要确保所创建的 TLS Secret 创建自包含 https-example.foo.com 的公共名称
(Common Name,CN)的证书。这里的公共名称也被称为全限定域名(Fully Qualified Domain Name,FQDN)。
说明:
注意,不能针对默认规则使用 TLS,因为这样做需要为所有可能的子域名签发证书。
因此,tls 字段中的 hosts 的取值需要与 rules 字段中的 host 完全匹配。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: tls-example-ingress
spec:
tls:
- hosts:
- https-example.foo.com
secretName: testsecret-tls
rules:
- host: https-example.foo.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service1
port:
number: 80
说明:
各种 Ingress 控制器在所支持的 TLS 特性上参差不齐。请参阅与 nginx、 GCE 或者任何其他平台特定的 Ingress 控制器有关的文档,以了解 TLS 如何在你的环境中工作。
负载均衡
Ingress 控制器启动引导时使用一些适用于所有 Ingress 的负载均衡策略设置, 例如负载均衡算法、后端权重方案等。 更高级的负载均衡概念(例如持久会话、动态权重)尚未通过 Ingress 公开。 你可以通过用于 Service 的负载均衡器来获取这些功能。
值得注意的是,尽管健康检查不是通过 Ingress 直接暴露的,在 Kubernetes 中存在就绪态探针 这类等价的概念,供你实现相同的目的。 请查阅特定控制器的说明文档(例如:nginx、 GCE) 以了解它们是怎样处理健康检查的。
更新 Ingress
要更新现有的 Ingress 以添加新的 Host,可以通过编辑资源来更新它:
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 35s loadbalancer-controller default/test
kubectl edit ingress test
这一命令将打开编辑器,允许你以 YAML 格式编辑现有配置。 修改它来增加新的主机:
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
service:
name: service1
port:
number: 80
path: /foo
pathType: Prefix
- host: bar.baz.com
http:
paths:
- backend:
service:
name: service2
port:
number: 80
path: /foo
pathType: Prefix
..
保存更改后,kubectl 将更新 API 服务器上的资源,该资源将告诉 Ingress 控制器重新配置负载均衡器。
验证:
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
bar.baz.com
/foo service2:80 (10.8.0.91:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 45s loadbalancer-controller default/test
你也可以针对修改后的 Ingress YAML 文件,通过 kubectl replace -f 命令获得同样结果。
跨可用区的失效
不同的云厂商使用不同的技术来实现跨故障域的流量分布。 请查看相关 Ingress 控制器的文档以了解详细信息。
替代方案
不直接使用 Ingress 资源,也有多种方法暴露 Service:
接下来
- 进一步了解 Ingress API
- 进一步了解 Ingress 控制器
- 使用 NGINX 控制器在 Minikube 上安装 Ingress
5.3 - Ingress 控制器
为了让 Ingress 在你的集群中工作, 必须有一个 Ingress 控制器正在运行。你需要选择至少一个 Ingress 控制器并确保其已被部署到你的集群中。 本页列出了你可以部署的常见 Ingress 控制器。
为了让 Ingress 资源工作,集群必须有一个正在运行的 Ingress 控制器。
与作为 kube-controller-manager 可执行文件的一部分运行的其他类型的控制器不同,
Ingress 控制器不是随集群自动启动的。
基于此页面,你可选择最适合你的集群的 ingress 控制器实现。
Kubernetes 作为一个项目,目前支持和维护 AWS、 GCE 和 Nginx Ingress 控制器。
其他控制器
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
- AKS 应用程序网关 Ingress 控制器 是一个配置 Azure 应用程序网关 的 Ingress 控制器。
- 阿里云 MSE Ingress 是一个 Ingress 控制器,它负责配置阿里云原生网关, 也是 Higress 的商业版本。
- Apache APISIX Ingress 控制器 是一个基于 Apache APISIX 网关 的 Ingress 控制器。
- Avi Kubernetes Operator 使用 VMware NSX Advanced Load Balancer 提供第 4 到第 7 层的负载均衡。
- BFE Ingress 控制器是一个基于 BFE 的 Ingress 控制器。
- Cilium Ingress 控制器是一个由 Cilium 出品支持的 Ingress 控制器。
- Citrix Ingress 控制器 可以用来与 Citrix Application Delivery Controller 一起使用。
- Contour 是一个基于 Envoy 的 Ingress 控制器。
- Emissary-Ingress API 网关是一个基于 Envoy 的入口控制器。
- EnRoute 是一个基于 Envoy 的 API 网关,可以用作 Ingress 控制器。
- Easegress IngressController 是一个基于 Easegress 的 API 网关,可以用作 Ingress 控制器。
- F5 BIG-IP 的 用于 Kubernetes 的容器 Ingress 服务 让你能够使用 Ingress 来配置 F5 BIG-IP 虚拟服务器。
- FortiADC Ingress 控制器 支持 Kubernetes Ingress 资源,并允许你从 Kubernetes 管理 FortiADC 对象。
- Gloo 是一个开源的、基于 Envoy 的 Ingress 控制器,能够提供 API 网关功能。
- HAProxy Ingress 是一个针对 HAProxy 的 Ingress 控制器。
- Higress 是一个基于 Envoy 的 API 网关, 可以作为一个 Ingress 控制器运行。
- 用于 Kubernetes 的 HAProxy Ingress 控制器 也是一个针对 HAProxy 的 Ingress 控制器。
- Istio Ingress 是一个基于 Istio 的 Ingress 控制器。
- 用于 Kubernetes 的 Kong Ingress 控制器 是一个用来驱动 Kong Gateway 的 Ingress 控制器。
- Kusk Gateway 是一个基于 Envoy 的、 OpenAPI 驱动的 Ingress 控制器。
- 用于 Kubernetes 的 NGINX Ingress 控制器 能够与 NGINX 网页服务器(作为代理)一起使用。
- ngrok Kubernetes Ingress 控制器 是一个开源控制器,通过使用 ngrok 平台为你的 K8s 服务添加安全的公开访问权限。
- OCI Native Ingress Controller 是一个适用于 Oracle Cloud Infrastructure 的 Ingress 控制器,可帮助你管理 OCI 负载均衡。
- Pomerium Ingress 控制器 基于 Pomerium,能提供上下文感知的准入策略。
- Skipper HTTP 路由器和反向代理可用于服务组装,支持包括 Kubernetes Ingress 这类使用场景,是一个用以构造你自己的定制代理的库。
- Traefik Kubernetes Ingress 提供程序 是一个用于 Traefik 代理的 Ingress 控制器。
- Tyk Operator 使用自定义资源扩展 Ingress,为之带来 API 管理能力。Tyk Operator 使用开源的 Tyk Gateway & Tyk Cloud 控制面。
- Voyager 是一个针对 HAProxy 的 Ingress 控制器。
- Wallarm Ingress Controller 是提供 WAAP(WAF) 和 API 安全功能的 Ingress Controller。
使用多个 Ingress 控制器
你可以使用
Ingress 类在集群中部署任意数量的
Ingress 控制器。
请注意你的 Ingress 类资源的 .metadata.name 字段。
当你创建 Ingress 时,你需要用此字段的值来设置 Ingress 对象的 ingressClassName 字段(请参考
IngressSpec v1 reference)。
ingressClassName
是之前的注解做法的替代。
如果你不为 Ingress 指定 IngressClass,并且你的集群中只有一个 IngressClass 被标记为默认,那么
Kubernetes 会将此集群的默认 IngressClass
应用到 Ingress 上。
IngressClass。
你可以通过将
ingressclass.kubernetes.io/is-default-class 注解
的值设置为 "true" 来将一个 IngressClass 标记为集群默认。
理想情况下,所有 Ingress 控制器都应满足此规范,但各种 Ingress 控制器的操作略有不同。
说明: 确保你查看了 ingress 控制器的文档,以了解选择它的注意事项。
接下来
5.4 - Gateway API
网关(Gateway)API 是一组 API 类别,可提供动态基础设施配置和高级流量路由。
Gateway API 通过使用可扩展的、角色导向的、 协议感知的配置机制来提供网络服务。它是一个附加组件, 包含可提供动态基础设施配置和高级流量路由的 API 类别。
设计原则
Gateway API 的设计和架构遵从以下原则:
- 角色导向: Gateway API 类别是基于负责管理 Kubernetes 服务网络的组织角色建模的:
- 基础设施提供者: 管理使用多个独立集群为多个租户提供服务的基础设施,例如,云提供商。
- 集群操作员: 管理集群,通常关注策略、网络访问、应用程序权限等。
- 应用程序开发人员: 管理在集群中运行的应用程序,通常关注应用程序级配置和 Service 组合。
- 可移植: Gateway API 规范用自定义资源来定义, 并受到许多实现的支持。
- 表达能力强: Gateway API 类别支持常见流量路由场景的功能,例如基于标头的匹配、流量加权以及其他只能在 Ingress 中使用自定义注解才能实现的功能。
- 可扩展的: Gateway 允许在 API 的各个层链接自定义资源。这使得在 API 结构内的适当位置进行精细定制成为可能。
资源模型
Gateway API 具有三种稳定的 API 类别:
-
GatewayClass: 定义一组具有配置相同的网关,由实现该类的控制器管理。
-
Gateway: 定义流量处理基础设施(例如云负载均衡器)的一个实例。
-
HTTPRoute: 定义特定于 HTTP 的规则,用于将流量从网关监听器映射到后端网络端点的表示。 这些端点通常表示为 Service。
Gateway API 被组织成不同的 API 类别,这些 API 类别具有相互依赖的关系,以支持组织中角色导向的特点。
一个 Gateway 对象只能与一个 GatewayClass 相关联;GatewayClass 描述负责管理此类 Gateway 的网关控制器。
各个(可以是多个)路由类别(例如 HTTPRoute)可以关联到此 Gateway 对象。
Gateway 可以对能够挂接到其 listeners 的路由进行过滤,从而与路由形成双向信任模型。
下图说明这三个稳定的 Gateway API 类别之间的关系:

GatewayClass
Gateway 可以由不同的控制器实现,通常具有不同的配置。 Gateway 必须引用某 GatewayClass,而后者中包含实现该类的控制器的名称。
下面是一个最精简的 GatewayClass 示例:
apiVersion: gateway.networking.k8s.io/v1
kind: GatewayClass
metadata:
name: example-class
spec:
controllerName: example.com/gateway-controller
在此示例中,一个实现了 Gateway API 的控制器被配置为管理某些 GatewayClass 对象,
这些对象的控制器名为 example.com/gateway-controller。
归属于此类的 Gateway 对象将由此实现的控制器来管理。
有关此 API 类别的完整定义,请参阅 GatewayClass。
Gateway
Gateway 用来描述流量处理基础设施的一个实例。Gateway 定义了一个网络端点,该端点可用于处理流量, 即对 Service 等后端进行过滤、平衡、拆分等。 例如,Gateway 可以代表某个云负载均衡器,或配置为接受 HTTP 流量的集群内代理服务器。
下面是一个精简的 Gateway 资源示例:
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: example-gateway
spec:
gatewayClassName: example-class
listeners:
- name: http
protocol: HTTP
port: 80
在此示例中,流量处理基础设施的实例被编程为监听 80 端口上的 HTTP 流量。
由于未指定 addresses 字段,因此对应实现的控制器负责将地址或主机名设置到 Gateway 之上。
该地址用作网络端点,用于处理路由中定义的后端网络端点的流量。
有关此类 API 的完整定义,请参阅 Gateway。
HTTPRoute
HTTPRoute 类别指定从 Gateway 监听器到后端网络端点的 HTTP 请求的路由行为。 对于服务后端,实现可以将后端网络端点表示为服务 IP 或服务的支持端点。 HTTPRoute 表示将被应用到下层 Gateway 实现的配置。 例如,定义新的 HTTPRoute 可能会导致在云负载均衡器或集群内代理服务器中配置额外的流量路由。
下面是一个最精简的 HTTPRoute 示例:
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: example-httproute
spec:
parentRefs:
- name: example-gateway
hostnames:
- "www.example.com"
rules:
- matches:
- path:
type: PathPrefix
value: /login
backendRefs:
- name: example-svc
port: 8080
在此示例中,来自 Gateway example-gateway 的 HTTP 流量,
如果 Host 的标头设置为 www.example.com 且请求路径指定为 /login,
将被路由到 Service example-svc 的 8080 端口。
有关此类 API 的完整定义,请参阅 HTTPRoute。
请求数据流
以下是使用 Gateway 和 HTTPRoute 将 HTTP 流量路由到服务的简单示例:

在此示例中,实现为反向代理的 Gateway 的请求数据流如下:
- 客户端开始准备 URL 为
http://www.example.com的 HTTP 请求 - 客户端的 DNS 解析器查询目标名称并了解与 Gateway 关联的一个或多个 IP 地址的映射。
- 客户端向 Gateway IP 地址发送请求;反向代理接收 HTTP 请求并使用 Host: 标头来匹配基于 Gateway 和附加的 HTTPRoute 所获得的配置。
- 可选的,反向代理可以根据 HTTPRoute 的匹配规则进行请求头和(或)路径匹配。
- 可选地,反向代理可以修改请求;例如,根据 HTTPRoute 的过滤规则添加或删除标头。
- 最后,反向代理将请求转发到一个或多个后端。
标准合规性
Gateway API 涵盖广泛的功能并得到广泛实现。 这种组合需要明确的标准合规性定义和测试,以确保 API 在任何地方使用时都能提供一致的体验。
请参阅合规性相关的文档, 以了解发布渠道、支持级别和运行合规性测试等详细信息。
从 Ingress 迁移
Gateway API 是 Ingress API 的后继者。 但是其中不包括 Ingress 类型。因此,需要将现有 Ingress 资源一次性转换为 Gateway API 资源。
有关将 Ingress 资源迁移到 Gateway API 资源的详细信息,请参阅 Ingress 迁移指南。
接下来
Gateway API 资源不是由 Kubernetes 原生实现的, 而是被定义为受广泛实现支持的自定义资源。 用户需要安装 Gateway API CRD 或按照所选实现的安装说明进行操作。 安装完成后,使用入门指南来帮助你快速开始使用 Gateway API。
说明:
请务必查看所选实现的文档以了解可能存在的注意事项。
有关所有 Gateway API 类型的其他详细信息,请参阅 API 规范。
5.5 - EndpointSlice
EndpointSlice API 是 Kubernetes 用于扩缩 Service 以处理大量后端的机制,还允许集群高效更新其健康后端的列表。
特性状态:
Kubernetes v1.21 [stable]
Kubernetes 的 EndpointSlice API 提供了一种简单的方法来跟踪 Kubernetes 集群中的网络端点(network endpoints)。EndpointSlices 为 Endpoints 提供了一种可扩缩和可拓展的替代方案。
EndpointSlice API
在 Kubernetes 中,EndpointSlice 包含对一组网络端点的引用。
控制面会自动为设置了选择算符的
Kubernetes Service 创建 EndpointSlice。
这些 EndpointSlice 将包含对与 Service 选择算符匹配的所有 Pod 的引用。
EndpointSlice 通过唯一的协议、端口号和 Service 名称将网络端点组织在一起。
EndpointSlice 的名称必须是合法的
DNS 子域名。
例如,下面是 Kubernetes Service example 所拥有的 EndpointSlice 对象示例。
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
nodeName: node-1
zone: us-west2-a
默认情况下,控制面创建和管理的 EndpointSlice 将包含不超过 100 个端点。
你可以使用 kube-controller-manager
的 --max-endpoints-per-slice 标志设置此值,最大值为 1000。
当涉及如何路由内部流量时,EndpointSlice 可以充当 kube-proxy 的决策依据。
地址类型
EndpointSlice 支持三种地址类型:
- IPv4
- IPv6
- FQDN (完全合格的域名)
每个 EndpointSlice 对象代表一个特定的 IP 地址类型。如果你有一个支持 IPv4 和 IPv6 的 Service,
那么将至少有两个 EndpointSlice 对象(一个用于 IPv4,一个用于 IPv6)。
状况
EndpointSlice API 存储了可能对使用者有用的、有关端点的状况。
这三个状况分别是 ready、serving 和 terminating。
Ready(就绪)
ready 状况是映射 Pod 的 Ready 状况的。
对于处于运行中的 Pod,它的 Ready 状况被设置为 True,应该将此 EndpointSlice 状况也设置为 true。
出于兼容性原因,当 Pod 处于终止过程中,ready 永远不会为 true。
消费者应参考 serving 状况来检查处于终止中的 Pod 的就绪情况。
该规则的唯一例外是将 spec.publishNotReadyAddresses 设置为 true 的 Service。
这些 Service 的端点将始终将 ready 状况设置为 true。
Serving(服务中)
特性状态:
Kubernetes v1.26 [stable]
serving 状况几乎与 ready 状况相同,不同之处在于它不考虑终止状态。
如果 EndpointSlice API 的使用者关心 Pod 终止时的就绪情况,就应检查 serving 状况。
说明:
尽管 serving 与 ready 几乎相同,但是它是为防止破坏 ready 的现有含义而增加的。
如果对于处于终止中的端点,ready 可能是 true,那么对于现有的客户端来说可能是有些意外的,
因为从始至终,Endpoints 或 EndpointSlice API 从未包含处于终止中的端点。
出于这个原因,ready 对于处于终止中的端点 总是 false,
并且在 v1.20 中添加了新的状况 serving,以便客户端可以独立于 ready
的现有语义来跟踪处于终止中的 Pod 的就绪情况。
Terminating(终止中)
特性状态:
Kubernetes v1.22 [beta]
Terminating 是表示端点是否处于终止中的状况。
对于 Pod 来说,这是设置了删除时间戳的 Pod。
拓扑信息
EndpointSlice 中的每个端点都可以包含一定的拓扑信息。 拓扑信息包括端点的位置,对应节点、可用区的信息。 这些信息体现为 EndpointSlices 的如下端点字段:
nodeName- 端点所在的 Node 名称;zone- 端点所处的可用区。
说明:
在 v1 API 中,逐个端点设置的 topology 实际上被去除,
以鼓励使用专用的字段 nodeName 和 zone。
对 EndpointSlice 对象的 endpoint 字段设置任意的拓扑结构信息这一操作已被废弃,
不再被 v1 API 所支持。取而代之的是 v1 API 所支持的 nodeName 和 zone
这些独立的字段。这些字段可以在不同的 API 版本之间自动完成转译。
例如,v1beta1 API 中 topology 字段的 topology.kubernetes.io/zone
取值可以在 v1 API 中通过 zone 字段访问。
管理
通常,控制面(尤其是端点切片的控制器) 会创建和管理 EndpointSlice 对象。EndpointSlice 对象还有一些其他使用场景, 例如作为服务网格(Service Mesh)的实现。 这些场景都会导致有其他实体或者控制器负责管理额外的 EndpointSlice 集合。
为了确保多个实体可以管理 EndpointSlice 而且不会相互产生干扰,
Kubernetes 定义了标签
endpointslice.kubernetes.io/managed-by,用来标明哪个实体在管理某个 EndpointSlice。
端点切片控制器会在自己所管理的所有 EndpointSlice 上将该标签值设置为
endpointslice-controller.k8s.io。
管理 EndpointSlice 的其他实体也应该为此标签设置一个唯一值。
属主关系
在大多数场合下,EndpointSlice 都由某个 Service 所有,
(因为)该端点切片正是为该服务跟踪记录其端点。这一属主关系是通过为每个 EndpointSlice
设置一个属主(owner)引用,同时设置 kubernetes.io/service-name 标签来标明的,
目的是方便查找隶属于某 Service 的所有 EndpointSlice。
EndpointSlice 镜像
在某些场合,应用会创建定制的 Endpoints 资源。为了保证这些应用不需要并发的更改 Endpoints 和 EndpointSlice 资源,集群的控制面将大多数 Endpoints 映射到对应的 EndpointSlice 之上。
控制面对 Endpoints 资源进行映射的例外情况有:
- Endpoints 资源上标签
endpointslice.kubernetes.io/skip-mirror值为true。 - Endpoints 资源包含标签
control-plane.alpha.kubernetes.io/leader。 - 对应的 Service 资源不存在。
- 对应的 Service 的选择算符不为空。
每个 Endpoints 资源可能会被转译到多个 EndpointSlices 中去。 当 Endpoints 资源中包含多个子网或者包含多个 IP 协议族(IPv4 和 IPv6)的端点时, 就有可能发生这种状况。 每个子网最多有 1000 个地址会被镜像到 EndpointSlice 中。
EndpointSlices 的分布问题
每个 EndpointSlice 都有一组端口值,适用于资源内的所有端点。 当为 Service 使用命名端口时,Pod 可能会就同一命名端口获得不同的端口号, 因而需要不同的 EndpointSlice。这有点像 Endpoints 用来对子网进行分组的逻辑。
控制面尝试尽量将 EndpointSlice 填满,不过不会主动地在若干 EndpointSlice 之间执行再平衡操作。这里的逻辑也是相对直接的:
- 列举所有现有的 EndpointSlices,移除那些不再需要的端点并更新那些已经变化的端点。
- 列举所有在第一步中被更改过的 EndpointSlices,用新增加的端点将其填满。
- 如果还有新的端点未被添加进去,尝试将这些端点添加到之前未更改的切片中, 或者创建新切片。
这里比较重要的是,与在 EndpointSlice 之间完成最佳的分布相比,第三步中更看重限制 EndpointSlice 更新的操作次数。例如,如果有 10 个端点待添加,有两个 EndpointSlice 中各有 5 个空位,上述方法会创建一个新的 EndpointSlice 而不是将现有的两个 EndpointSlice 都填满。换言之,与执行多个 EndpointSlice 更新操作相比较, 方法会优先考虑执行一个 EndpointSlice 创建操作。
由于 kube-proxy 在每个节点上运行并监视 EndpointSlice 状态,EndpointSlice 的每次变更都变得相对代价较高,因为这些状态变化要传递到集群中每个节点上。 这一方法尝试限制要发送到所有节点上的变更消息个数,即使这样做可能会导致有多个 EndpointSlice 没有被填满。
在实践中,上面这种并非最理想的分布是很少出现的。大多数被 EndpointSlice 控制器处理的变更都是足够小的,可以添加到某已有 EndpointSlice 中去的。 并且,假使无法添加到已有的切片中,不管怎样都很快就会创建一个新的 EndpointSlice 对象。Deployment 的滚动更新为重新为 EndpointSlice 打包提供了一个自然的机会,所有 Pod 及其对应的端点在这一期间都会被替换掉。
重复的端点
由于 EndpointSlice 变化的自身特点,端点可能会同时出现在不止一个 EndpointSlice 中。鉴于不同的 EndpointSlice 对象在不同时刻到达 Kubernetes 的监视/缓存中, 这种情况的出现是很自然的。
说明:
EndpointSlice API 的客户端必须遍历与 Service 关联的所有现有 EndpointSlices, 并构建唯一网络端点的完整列表。值得一提的是端点可能在不同的 EndpointSlices 中重复。
你可以在 kube-proxy 中的 EndpointSliceCache 代码中找到有关如何执行此端点聚合和重复数据删除的参考实现。
与 Endpoints 的比较
原来的 Endpoints API 提供了在 Kubernetes 中跟踪网络端点的一种简单而直接的方法。随着 Kubernetes 集群和服务逐渐开始为更多的后端 Pod 处理和发送请求, 原来的 API 的局限性变得越来越明显。最明显的是那些因为要处理大量网络端点而带来的挑战。
由于任一 Service 的所有网络端点都保存在同一个 Endpoints 对象中,这些 Endpoints 对象可能变得非常巨大。对于保持稳定的服务(长时间使用同一组端点),影响不太明显; 即便如此,Kubernetes 的一些使用场景也没有得到很好的服务。
当某 Service 存在很多后端端点并且该工作负载频繁扩缩或上线新更改时,对该 Service 的单个 Endpoints 对象的每次更新都意味着(在控制平面内以及在节点和 API 服务器之间)Kubernetes 集群组件之间会出现大量流量。 这种额外的流量在 CPU 使用方面也有开销。
使用 EndpointSlices 时,添加或移除单个 Pod 对于正监视变更的客户端会触发相同数量的更新, 但这些更新消息的大小在大规模场景下要小得多。
EndpointSlices 还支持围绕双栈网络和拓扑感知路由等新功能的创新。
接下来
- 遵循使用 Service 连接到应用教程
- 阅读 EndpointSlice API 的 API 参考
- 阅读 Endpoints API 的 API 参考
5.6 - 网络策略
如果你希望在 IP 地址或端口层面(OSI 第 3 层或第 4 层)控制网络流量, NetworkPolicy 可以让你为集群内以及 Pod 与外界之间的网络流量指定规则。 你的集群必须使用支持 NetworkPolicy 实施的网络插件。
如果你希望针对 TCP、UDP 和 SCTP 协议在 IP 地址或端口层面控制网络流量, 则你可以考虑为集群中特定应用使用 Kubernetes 网络策略(NetworkPolicy)。 NetworkPolicy 是一种以应用为中心的结构,允许你设置如何允许 Pod 与网络上的各类网络“实体” (我们这里使用实体以避免过度使用诸如“端点”和“服务”这类常用术语, 这些术语在 Kubernetes 中有特定含义)通信。 NetworkPolicy 适用于一端或两端与 Pod 的连接,与其他连接无关。
Pod 可以与之通信的实体是通过如下三个标识符的组合来辩识的:
- 其他被允许的 Pod(例外:Pod 无法阻塞对自身的访问)
- 被允许的名字空间
- IP 组块(例外:与 Pod 运行所在的节点的通信总是被允许的, 无论 Pod 或节点的 IP 地址)
在定义基于 Pod 或名字空间的 NetworkPolicy 时, 你会使用选择算符来设定哪些流量可以进入或离开与该算符匹配的 Pod。
另外,当创建基于 IP 的 NetworkPolicy 时,我们基于 IP 组块(CIDR 范围)来定义策略。
前置条件
网络策略通过网络插件来实现。 要使用网络策略,你必须使用支持 NetworkPolicy 的网络解决方案。 创建一个 NetworkPolicy 资源对象而没有控制器来使它生效的话,是没有任何作用的。
Pod 隔离的两种类型
Pod 有两种隔离:出口的隔离和入口的隔离。它们涉及到可以建立哪些连接。 这里的“隔离”不是绝对的,而是意味着“有一些限制”。 另外的,“非隔离方向”意味着在所述方向上没有限制。这两种隔离(或不隔离)是独立声明的, 并且都与从一个 Pod 到另一个 Pod 的连接有关。
默认情况下,一个 Pod 的出口是非隔离的,即所有外向连接都是被允许的。如果有任何的 NetworkPolicy
选择该 Pod 并在其 policyTypes 中包含 "Egress",则该 Pod 是出口隔离的,
我们称这样的策略适用于该 Pod 的出口。当一个 Pod 的出口被隔离时,
唯一允许的来自 Pod 的连接是适用于出口的 Pod 的某个 NetworkPolicy 的 egress 列表所允许的连接。
针对那些允许连接的应答流量也将被隐式允许。
这些 egress 列表的效果是相加的。
默认情况下,一个 Pod 对入口是非隔离的,即所有入站连接都是被允许的。如果有任何的 NetworkPolicy
选择该 Pod 并在其 policyTypes 中包含 “Ingress”,则该 Pod 被隔离入口,
我们称这种策略适用于该 Pod 的入口。当一个 Pod 的入口被隔离时,唯一允许进入该 Pod
的连接是来自该 Pod 节点的连接和适用于入口的 Pod 的某个 NetworkPolicy 的 ingress
列表所允许的连接。针对那些允许连接的应答流量也将被隐式允许。这些 ingress 列表的效果是相加的。
网络策略是相加的,所以不会产生冲突。如果策略适用于 Pod 某一特定方向的流量, Pod 在对应方向所允许的连接是适用的网络策略所允许的集合。 因此,评估的顺序不影响策略的结果。
要允许从源 Pod 到目的 Pod 的某个连接,源 Pod 的出口策略和目的 Pod 的入口策略都需要允许此连接。 如果任何一方不允许此连接,则连接将会失败。
NetworkPolicy 资源
参阅 NetworkPolicy 来了解资源的完整定义。
下面是一个 NetworkPolicy 的示例:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
说明:
除非选择支持网络策略的网络解决方案,否则将上述示例发送到 API 服务器没有任何效果。
必需字段:与所有其他的 Kubernetes 配置一样,NetworkPolicy 需要 apiVersion、
kind 和 metadata 字段。关于配置文件操作的一般信息,
请参考配置 Pod 以使用 ConfigMap
和对象管理。
spec:NetworkPolicy 规约 中包含了在一个名字空间中定义特定网络策略所需的所有信息。
podSelector:每个 NetworkPolicy 都包括一个 podSelector,
它对该策略所适用的一组 Pod 进行选择。示例中的策略选择带有 "role=db" 标签的 Pod。
空的 podSelector 选择名字空间下的所有 Pod。
policyTypes:每个 NetworkPolicy 都包含一个 policyTypes 列表,其中包含
Ingress 或 Egress 或两者兼具。policyTypes 字段表示给定的策略是应用于进入所选
Pod 的入站流量还是来自所选 Pod 的出站流量,或两者兼有。
如果 NetworkPolicy 未指定 policyTypes 则默认情况下始终设置 Ingress;
如果 NetworkPolicy 有任何出口规则的话则设置 Egress。
ingress:每个 NetworkPolicy 可包含一个 ingress 规则的白名单列表。
每个规则都允许同时匹配 from 和 ports 部分的流量。示例策略中包含一条简单的规则:
它匹配某个特定端口,来自三个来源中的一个,第一个通过 ipBlock
指定,第二个通过 namespaceSelector 指定,第三个通过 podSelector 指定。
egress:每个 NetworkPolicy 可包含一个 egress 规则的白名单列表。
每个规则都允许匹配 to 和 port 部分的流量。该示例策略包含一条规则,
该规则将指定端口上的流量匹配到 10.0.0.0/24 中的任何目的地。
所以,该网络策略示例:
-
隔离
default名字空间下role=db的 Pod (如果它们不是已经被隔离的话)。 -
(Ingress 规则)允许以下 Pod 连接到
default名字空间下的带有role=db标签的所有 Pod 的 6379 TCP 端口:default名字空间下带有role=frontend标签的所有 Pod- 带有
project=myproject标签的所有名字空间中的 Pod - IP 地址范围为
172.17.0.0–172.17.0.255和172.17.2.0–172.17.255.255(即,除了172.17.1.0/24之外的所有172.17.0.0/16)
-
(Egress 规则)允许
default名字空间中任何带有标签role=db的 Pod 到 CIDR10.0.0.0/24下 5978 TCP 端口的连接。
有关更多示例,请参阅声明网络策略演练。
选择器 to 和 from 的行为
可以在 ingress 的 from 部分或 egress 的 to 部分中指定四种选择器:
podSelector:此选择器将在与 NetworkPolicy 相同的名字空间中选择特定的 Pod,应将其允许作为入站流量来源或出站流量目的地。
namespaceSelector:此选择器将选择特定的名字空间,应将所有 Pod 用作其入站流量来源或出站流量目的地。
namespaceSelector 和 podSelector:一个指定 namespaceSelector
和 podSelector 的 to/from 条目选择特定名字空间中的特定 Pod。
注意使用正确的 YAML 语法;下面的策略:
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
podSelector:
matchLabels:
role: client
...
此策略在 from 数组中仅包含一个元素,只允许来自标有 role=client 的 Pod
且该 Pod 所在的名字空间中标有 user=alice 的连接。但是这项策略:
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
- podSelector:
matchLabels:
role: client
...
它在 from 数组中包含两个元素,允许来自本地名字空间中标有 role=client 的
Pod 的连接,或来自任何名字空间中标有 user=alice 的任何 Pod 的连接。
如有疑问,请使用 kubectl describe 查看 Kubernetes 如何解释该策略。
ipBlock:此选择器将选择特定的 IP CIDR 范围以用作入站流量来源或出站流量目的地。 这些应该是集群外部 IP,因为 Pod IP 存在时间短暂的且随机产生。
集群的入站和出站机制通常需要重写数据包的源 IP 或目标 IP。
在发生这种情况时,不确定在 NetworkPolicy 处理之前还是之后发生,
并且对于网络插件、云提供商、Service 实现等的不同组合,其行为可能会有所不同。
对入站流量而言,这意味着在某些情况下,你可以根据实际的原始源 IP 过滤传入的数据包,
而在其他情况下,NetworkPolicy 所作用的 源IP 则可能是 LoadBalancer 或
Pod 的节点等。
对于出站流量而言,这意味着从 Pod 到被重写为集群外部 IP 的 Service IP
的连接可能会或可能不会受到基于 ipBlock 的策略的约束。
默认策略
默认情况下,如果名字空间中不存在任何策略,则所有进出该名字空间中 Pod 的流量都被允许。 以下示例使你可以更改该名字空间中的默认行为。
默认拒绝所有入站流量
你可以通过创建选择所有 Pod 但不允许任何进入这些 Pod 的入站流量的 NetworkPolicy 来为名字空间创建 "default" 隔离策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
这确保即使没有被任何其他 NetworkPolicy 选择的 Pod 仍将被隔离以进行入口。 此策略不影响任何 Pod 的出口隔离。
允许所有入站流量
如果你想允许一个名字空间中所有 Pod 的所有入站连接,你可以创建一个明确允许的策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress
有了这个策略,任何额外的策略都不会导致到这些 Pod 的任何入站连接被拒绝。 此策略对任何 Pod 的出口隔离没有影响。
默认拒绝所有出站流量
你可以通过创建选择所有容器但不允许来自这些容器的任何出站流量的 NetworkPolicy 来为名字空间创建 "default" 隔离策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
spec:
podSelector: {}
policyTypes:
- Egress
此策略可以确保即使没有被其他任何 NetworkPolicy 选择的 Pod 也不会被允许流出流量。 此策略不会更改任何 Pod 的入站流量隔离行为。
允许所有出站流量
如果要允许来自名字空间中所有 Pod 的所有连接, 则可以创建一个明确允许来自该名字空间中 Pod 的所有出站连接的策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
有了这个策略,任何额外的策略都不会导致来自这些 Pod 的任何出站连接被拒绝。 此策略对进入任何 Pod 的隔离没有影响。
默认拒绝所有入站和所有出站流量
你可以为名字空间创建 "default" 策略,以通过在该名字空间中创建以下 NetworkPolicy 来阻止所有入站和出站流量。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
此策略可以确保即使没有被其他任何 NetworkPolicy 选择的 Pod 也不会被允许入站或出站流量。
网络流量过滤
NetworkPolicy 是为第 4 层连接 (TCP、UDP 和可选的 SCTP)所定义的。对于所有其他协议,这种网络流量过滤的行为可能因网络插件而异。
说明:
你必须使用支持 SCTP 协议 NetworkPolicy 的 CNI 插件。
当 deny all 网络策略被定义时,此策略只能保证拒绝 TCP、UDP 和 SCTP 连接。
对于 ARP 或 ICMP 这类其他协议,这种网络流量过滤行为是未定义的。
相同的情况也适用于 allow 规则:当特定 Pod 被允许作为入口源或出口目的地时,
对于(例如)ICMP 数据包会发生什么是未定义的。
ICMP 这类协议可能被某些网络插件所允许,而被另一些网络插件所拒绝。
针对某个端口范围
特性状态:
Kubernetes v1.25 [stable]
在编写 NetworkPolicy 时,你可以针对一个端口范围而不是某个固定端口。
这一目的可以通过使用 endPort 字段来实现,如下例所示:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: multi-port-egress
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 32000
endPort: 32768
上面的规则允许名字空间 default 中所有带有标签 role=db 的 Pod 使用 TCP 协议与
10.0.0.0/24 范围内的 IP 通信,只要目标端口介于 32000 和 32768 之间就可以。
使用此字段时存在以下限制:
endPort字段必须等于或者大于port字段的值。- 只有在定义了
port时才能定义endPort。 - 两个字段的设置值都只能是数字。
说明:
你的集群所使用的 CNI 插件必须支持在
NetworkPolicy 规约中使用 endPort 字段。
如果你的网络插件不支持
endPort 字段,而你指定了一个包含 endPort 字段的 NetworkPolicy,
策略只对单个 port 字段生效。
按标签选择多个名字空间
在这种情况下,你的 Egress NetworkPolicy 使用名字空间的标签名称来将多个名字空间作为其目标。
为此,你需要为目标名字空间设置标签。例如:
kubectl label namespace frontend namespace=frontend
kubectl label namespace backend namespace=backend
在 NetworkPolicy 文档中的 namespaceSelector 下添加标签。例如:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: egress-namespaces
spec:
podSelector:
matchLabels:
app: myapp
policyTypes:
- Egress
egress:
- to:
- namespaceSelector:
matchExpressions:
- key: namespace
operator: In
values: ["frontend", "backend"]
说明:
你不可以在 NetworkPolicy 中直接指定名字空间的名称。
你必须使用带有 matchLabels 或 matchExpressions 的 namespaceSelector
来根据标签选择名字空间。
基于名字指向某名字空间
Kubernetes 控制面会在所有名字空间上设置一个不可变更的标签
kubernetes.io/metadata.name。该标签的值是名字空间的名称。
如果 NetworkPolicy 无法在某些对象字段中指向某名字空间, 你可以使用标准的标签方式来指向特定名字空间。
Pod 生命周期
说明:
以下内容适用于使用了合规网络插件和 NetworkPolicy 合规实现的集群。
当新的 NetworkPolicy 对象被创建时,网络插件可能需要一些时间来处理这个新对象。 如果受到 NetworkPolicy 影响的 Pod 在网络插件完成 NetworkPolicy 处理之前就被创建了, 那么该 Pod 可能会最初处于无保护状态,而在 NetworkPolicy 处理完成后被应用隔离规则。
一旦 NetworkPolicy 被网络插件处理,
- 所有受给定 NetworkPolicy 影响的新建 Pod 都将在启动前被隔离。 NetworkPolicy 的实现必须确保过滤规则在整个 Pod 生命周期内是有效的, 这个生命周期要从该 Pod 的任何容器启动的第一刻算起。 因为 NetworkPolicy 在 Pod 层面被应用,所以 NetworkPolicy 同样适用于 Init 容器、边车容器和常规容器。
- Allow 规则最终将在隔离规则之后被应用(或者可能同时被应用)。 在最糟的情况下,如果隔离规则已被应用,但 allow 规则尚未被应用, 那么新建的 Pod 在初始启动时可能根本没有网络连接。
用户所创建的每个 NetworkPolicy 最终都会被网络插件处理,但无法使用 Kubernetes API 来获知确切的处理时间。
因此,若 Pod 启动时使用非预期的网络连接,它必须保持稳定。 如果你需要确保 Pod 在启动之前能够访问特定的目标,可以使用 Init 容器在 kubelet 启动应用容器之前等待这些目的地变得可达。
每个 NetworkPolicy 最终都会被应用到所选定的所有 Pod 之上。 由于网络插件可能以分布式的方式实现 NetworkPolicy,所以当 Pod 被首次创建时或当 Pod 或策略发生变化时,Pod 可能会看到稍微不一致的网络策略视图。 例如,新建的 Pod 本来应能立即访问 Node 1 上的 Pod A 和 Node 2 上的 Pod B, 但可能你会发现新建的 Pod 可以立即访问 Pod A,但要在几秒后才能访问 Pod B。
NetworkPolicy 和 hostNetwork Pod
针对 hostNetwork Pod 的 NetworkPolicy 行为是未定义的,但应限制为以下两种可能:
- 网络插件可以从所有其他流量中辨别出
hostNetworkPod 流量 (包括能够从同一节点上的不同hostNetworkPod 中辨别流量), 网络插件还可以像处理 Pod 网络流量一样,对hostNetworkPod 应用 NetworkPolicy。
- 网络插件无法正确辨别
hostNetworkPod 流量,因此在匹配podSelector和namespaceSelector时会忽略hostNetworkPod。流向/来自hostNetworkPod 的流量的处理方式与流向/来自节点 IP 的所有其他流量一样。(这是最常见的实现方式。)
这适用于以下情形:
-
hostNetworkPod 被spec.podSelector选中。... spec: podSelector: matchLabels: role: client ...
-
hostNetworkPod 在ingress或egress规则中被podSelector或namespaceSelector选中。... ingress: - from: - podSelector: matchLabels: role: client ...
同时,由于 hostNetwork Pod 具有与其所在节点相同的 IP 地址,所以它们的连接将被视为节点连接。
例如,你可以使用 ipBlock 规则允许来自 hostNetwork Pod 的流量。
通过网络策略(至少目前还)无法完成的工作
到 Kubernetes 1.29 为止,NetworkPolicy API 还不支持以下功能, 不过你可能可以使用操作系统组件(如 SELinux、OpenVSwitch、IPTables 等等) 或者第七层技术(Ingress 控制器、服务网格实现)或准入控制器来实现一些替代方案。 如果你对 Kubernetes 中的网络安全性还不太了解,了解使用 NetworkPolicy API 还无法实现下面的用户场景是很值得的。
- 强制集群内部流量经过某公用网关(这种场景最好通过服务网格或其他代理来实现);
- 与 TLS 相关的场景(考虑使用服务网格或者 Ingress 控制器);
- 特定于节点的策略(你可以使用 CIDR 来表达这一需求不过你无法使用节点在 Kubernetes 中的其他标识信息来辩识目标节点);
- 基于名字来选择服务(不过,你可以使用 标签 来选择目标 Pod 或名字空间,这也通常是一种可靠的替代方案);
- 创建或管理由第三方来实际完成的“策略请求”;
- 实现适用于所有名字空间或 Pod 的默认策略(某些第三方 Kubernetes 发行版本或项目可以做到这点);
- 高级的策略查询或者可达性相关工具;
- 生成网络安全事件日志的能力(例如,被阻塞或接收的连接请求);
- 显式地拒绝策略的能力(目前,NetworkPolicy 的模型默认采用拒绝操作, 其唯一的能力是添加允许策略);
- 禁止本地回路或指向宿主的网络流量(Pod 目前无法阻塞 localhost 访问, 它们也无法禁止来自所在节点的访问请求)。
NetworkPolicy 对现有连接的影响
当应用到现有连接的 NetworkPolicy 集合发生变化时,这可能是由于 NetworkPolicy 发生变化或者在现有连接过程中(主体和对等方)策略所选择的名字空间或 Pod 的相关标签发生变化, 此时是否对该现有连接生效是由实现定义的。例如:某个策略的创建导致之前允许的连接被拒绝, 底层网络插件的实现负责定义这个新策略是否会关闭现有的连接。 建议不要以可能影响现有连接的方式修改策略、Pod 或名字空间。
接下来
5.7 - Service 与 Pod 的 DNS
你的工作负载可以使用 DNS 发现集群内的 Service,本页说明具体工作原理。
Kubernetes 为 Service 和 Pod 创建 DNS 记录。 你可以使用一致的 DNS 名称而非 IP 地址访问 Service。
Kubernetes 发布有关 Pod 和 Service 的信息,这些信息被用来对 DNS 进行编程。 Kubelet 配置 Pod 的 DNS,以便运行中的容器可以通过名称而不是 IP 来查找服务。
集群中定义的 Service 被赋予 DNS 名称。 默认情况下,客户端 Pod 的 DNS 搜索列表会包含 Pod 自身的名字空间和集群的默认域。
Service 的名字空间
DNS 查询可能因为执行查询的 Pod 所在的名字空间而返回不同的结果。 不指定名字空间的 DNS 查询会被限制在 Pod 所在的名字空间内。 要访问其他名字空间中的 Service,需要在 DNS 查询中指定名字空间。
例如,假定名字空间 test 中存在一个 Pod,prod 名字空间中存在一个服务
data。
Pod 查询 data 时没有返回结果,因为使用的是 Pod 的名字空间 test。
Pod 查询 data.prod 时则会返回预期的结果,因为查询中指定了名字空间。
DNS 查询可以使用 Pod 中的 /etc/resolv.conf 展开。
Kubelet 为每个 Pod 配置此文件。
例如,对 data 的查询可能被展开为 data.test.svc.cluster.local。
search 选项的取值会被用来展开查询。要进一步了解 DNS 查询,可参阅
resolv.conf 手册页面。
nameserver 10.32.0.10
search <namespace>.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
概括起来,名字空间 test 中的 Pod 可以成功地解析 data.prod 或者
data.prod.svc.cluster.local。
DNS 记录
哪些对象会获得 DNS 记录呢?
- Services
- Pods
以下各节详细介绍已支持的 DNS 记录类型和布局。 其它布局、名称或者查询即使碰巧可以工作,也应视为实现细节, 将来很可能被更改而且不会因此发出警告。 有关最新规范请查看 Kubernetes 基于 DNS 的服务发现。
Service
A/AAAA 记录
除了无头 Service 之外的 “普通” Service 会被赋予一个形如 my-svc.my-namespace.svc.cluster-domain.example
的 DNS A 和/或 AAAA 记录,取决于 Service 的 IP 协议族(可能有多个)设置。
该名称会解析成对应 Service 的集群 IP。
没有集群 IP 的无头 Service
也会被赋予一个形如 my-svc.my-namespace.svc.cluster-domain.example 的 DNS A 和/或 AAAA 记录。
与普通 Service 不同,这一记录会被解析成对应 Service 所选择的 Pod IP 的集合。
客户端要能够使用这组 IP,或者使用标准的轮转策略从这组 IP 中进行选择。
SRV 记录
Kubernetes 根据普通 Service 或无头 Service
中的命名端口创建 SRV 记录。每个命名端口,
SRV 记录格式为 _port-name._port-protocol.my-svc.my-namespace.svc.cluster-domain.example。
普通 Service,该记录会被解析成端口号和域名:my-svc.my-namespace.svc.cluster-domain.example。
无头 Service,该记录会被解析成多个结果,及该服务的每个后端 Pod 各一个 SRV 记录,
其中包含 Pod 端口号和格式为 hostname.my-svc.my-namespace.svc.cluster-domain.example
的域名。
Pod
A/AAAA 记录
在实现 DNS 规范之前, Kube-DNS 版本使用以下 DNS 解析:
pod-ipv4-address.my-namespace.pod.cluster-domain.example
例如,对于一个位于 default 名字空间,IP 地址为 172.17.0.3 的 Pod,
如果集群的域名为 cluster.local,则 Pod 会对应 DNS 名称:
172-17-0-3.default.pod.cluster.local
通过 Service 暴露出来的所有 Pod 都会有如下 DNS 解析名称可用:
pod-ipv4-address.service-name.my-namespace.svc.cluster-domain.example
Pod 的 hostname 和 subdomain 字段
当前,创建 Pod 时其主机名(从 Pod 内部观察)取自 Pod 的 metadata.name 值。
Pod 规约中包含一个可选的 hostname 字段,可以用来指定一个不同的主机名。
当这个字段被设置时,它将优先于 Pod 的名字成为该 Pod 的主机名(同样是从 Pod 内部观察)。
举个例子,给定一个 spec.hostname 设置为 “my-host” 的 Pod,
该 Pod 的主机名将被设置为 “my-host”。
Pod 规约还有一个可选的 subdomain 字段,可以用来表明该 Pod 是名字空间的子组的一部分。
举个例子,某 Pod 的 spec.hostname 设置为 “foo”,spec.subdomain 设置为 “bar”,
在名字空间 “my-namespace” 中,主机名称被设置成 “foo” 并且对应的完全限定域名(FQDN)为
“foo.bar.my-namespace.svc.cluster-domain.example”(还是从 Pod 内部观察)。
如果 Pod 所在的名字空间中存在一个无头服务,其名称与子域相同, 则集群的 DNS 服务器还会为 Pod 的完全限定主机名返回 A 和/或 AAAA 记录。
示例:
apiVersion: v1
kind: Service
metadata:
name: busybox-subdomain
spec:
selector:
name: busybox
clusterIP: None
ports:
- name: foo # 实际上不需要指定端口号
port: 1234
---
apiVersion: v1
kind: Pod
metadata:
name: busybox1
labels:
name: busybox
spec:
hostname: busybox-1
subdomain: busybox-subdomain
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
name: busybox
---
apiVersion: v1
kind: Pod
metadata:
name: busybox2
labels:
name: busybox
spec:
hostname: busybox-2
subdomain: busybox-subdomain
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
name: busybox
鉴于上述服务 “busybox-subdomain” 和将 spec.subdomain 设置为 “busybox-subdomain” 的 Pod,
第一个 Pod 将看到自己的 FQDN 为 “busybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.example”。
DNS 会为此名字提供一个 A 记录和/或 AAAA 记录,指向该 Pod 的 IP。
Pod “busybox1” 和 “busybox2” 都将有自己的地址记录。
EndpointSlice
对象可以为任何端点地址及其 IP 指定 hostname。
说明: 由于 A 和 AAAA 记录不是基于 Pod 名称创建,因此需要设置了
hostname 才会生成 Pod 的 A 或 AAAA 记录。
没有设置 hostname 但设置了 subdomain 的 Pod 只会为
无头 Service 创建 A 或 AAAA 记录(busybox-subdomain.my-namespace.svc.cluster-domain.example)
指向 Pod 的 IP 地址。
另外,除非在服务上设置了 publishNotReadyAddresses=True,否则只有 Pod 准备就绪
才会有与之对应的记录。
Pod 的 setHostnameAsFQDN 字段
特性状态:
Kubernetes v1.22 [stable]
当 Pod 配置为具有全限定域名 (FQDN) 时,其主机名是短主机名。
例如,如果你有一个具有完全限定域名 busybox-1.busybox-subdomain.my-namespace.svc.cluster-domain.example 的 Pod,
则默认情况下,该 Pod 内的 hostname 命令返回 busybox-1,而 hostname --fqdn 命令返回 FQDN。
当你在 Pod 规约中设置了 setHostnameAsFQDN: true 时,kubelet 会将 Pod
的全限定域名(FQDN)作为该 Pod 的主机名记录到 Pod 所在名字空间。
在这种情况下,hostname 和 hostname --fqdn 都会返回 Pod 的全限定域名。
说明:
在 Linux 中,内核的主机名字段(struct utsname 的 nodename 字段)限定最多 64 个字符。
如果 Pod 启用这一特性,而其 FQDN 超出 64 字符,Pod 的启动会失败。
Pod 会一直出于 Pending 状态(通过 kubectl 所看到的 ContainerCreating),
并产生错误事件,例如
"Failed to construct FQDN from Pod hostname and cluster domain, FQDN
long-FQDN is too long (64 characters is the max, 70 characters requested)."
(无法基于 Pod 主机名和集群域名构造 FQDN,FQDN long-FQDN 过长,至多 64 个字符,请求字符数为 70)。
对于这种场景而言,改善用户体验的一种方式是创建一个
准入 Webhook 控制器,
在用户创建顶层对象(如 Deployment)的时候控制 FQDN 的长度。
Pod 的 DNS 策略
DNS 策略可以逐个 Pod 来设定。目前 Kubernetes 支持以下特定 Pod 的 DNS 策略。
这些策略可以在 Pod 规约中的 dnsPolicy 字段设置:
- "
Default": Pod 从运行所在的节点继承名称解析配置。 参考相关讨论获取更多信息。 - "
ClusterFirst": 与配置的集群域后缀不匹配的任何 DNS 查询(例如 "www.kubernetes.io") 都会由 DNS 服务器转发到上游名称服务器。集群管理员可能配置了额外的存根域和上游 DNS 服务器。 参阅相关讨论 了解在这些场景中如何处理 DNS 查询的信息。 - "
ClusterFirstWithHostNet": 对于以 hostNetwork 方式运行的 Pod,应将其 DNS 策略显式设置为 "ClusterFirstWithHostNet"。否则,以 hostNetwork 方式和"ClusterFirst"策略运行的 Pod 将会做出回退至"Default"策略的行为。- 注意:这在 Windows 上不支持。 有关详细信息,请参见下文。
- "
None": 此设置允许 Pod 忽略 Kubernetes 环境中的 DNS 设置。Pod 会使用其dnsConfig字段所提供的 DNS 设置。 参见 Pod 的 DNS 配置节。
说明:
"Default" 不是默认的 DNS 策略。如果未明确指定 dnsPolicy,则使用 "ClusterFirst"。
下面的示例显示了一个 Pod,其 DNS 策略设置为 "ClusterFirstWithHostNet",
因为它已将 hostNetwork 设置为 true。
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: busybox:1.28
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
Pod 的 DNS 配置
特性状态:
Kubernetes v1.14 [stable]
Pod 的 DNS 配置可让用户对 Pod 的 DNS 设置进行更多控制。
dnsConfig 字段是可选的,它可以与任何 dnsPolicy 设置一起使用。
但是,当 Pod 的 dnsPolicy 设置为 "None" 时,必须指定 dnsConfig 字段。
用户可以在 dnsConfig 字段中指定以下属性:
-
nameservers:将用作于 Pod 的 DNS 服务器的 IP 地址列表。 最多可以指定 3 个 IP 地址。当 Pod 的dnsPolicy设置为 "None" 时, 列表必须至少包含一个 IP 地址,否则此属性是可选的。 所列出的服务器将合并到从指定的 DNS 策略生成的基本名称服务器,并删除重复的地址。 -
searches:用于在 Pod 中查找主机名的 DNS 搜索域的列表。此属性是可选的。 指定此属性时,所提供的列表将合并到根据所选 DNS 策略生成的基本搜索域名中。 重复的域名将被删除。Kubernetes 最多允许 32 个搜索域。 -
options:可选的对象列表,其中每个对象可能具有name属性(必需)和value属性(可选)。 此属性中的内容将合并到从指定的 DNS 策略生成的选项。 重复的条目将被删除。
以下是具有自定义 DNS 设置的 Pod 示例:
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: dns-example
spec:
containers:
- name: test
image: nginx
dnsPolicy: "None"
dnsConfig:
nameservers:
- 192.0.2.1 # 这是一个示例
searches:
- ns1.svc.cluster-domain.example
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0
创建上面的 Pod 后,容器 test 会在其 /etc/resolv.conf 文件中获取以下内容:
nameserver 192.0.2.1
search ns1.svc.cluster-domain.example my.dns.search.suffix
options ndots:2 edns0
对于 IPv6 设置,搜索路径和名称服务器应按以下方式设置:
kubectl exec -it dns-example -- cat /etc/resolv.conf
输出类似于:
nameserver 2001:db8:30::a
search default.svc.cluster-domain.example svc.cluster-domain.example cluster-domain.example
options ndots:5
DNS 搜索域列表限制
特性状态:
Kubernetes 1.28 [stable]
Kubernetes 本身不限制 DNS 配置,最多可支持 32 个搜索域列表,所有搜索域的总长度不超过 2048。 此限制分别适用于节点的解析器配置文件、Pod 的 DNS 配置和合并的 DNS 配置。
说明:
早期版本的某些容器运行时可能对 DNS 搜索域的数量有自己的限制。 根据容器运行环境,那些具有大量 DNS 搜索域的 Pod 可能会卡在 Pending 状态。
众所周知 containerd v1.5.5 或更早版本和 CRI-O v1.21 或更早版本都有这个问题。
Windows 节点上的 DNS 解析
- 在 Windows 节点上运行的 Pod 不支持 ClusterFirstWithHostNet。
Windows 将所有带有
.的名称视为全限定域名(FQDN)并跳过全限定域名(FQDN)解析。 - 在 Windows 上,可以使用的 DNS 解析器有很多。
由于这些解析器彼此之间会有轻微的行为差别,建议使用
Resolve-DNSNamepowershell cmdlet 进行名称查询解析。 - 在 Linux 上,有一个 DNS 后缀列表,当解析全名失败时可以使用。
在 Windows 上,你只能有一个 DNS 后缀,
即与该 Pod 的命名空间相关联的 DNS 后缀(例如:
mydns.svc.cluster.local)。 Windows 可以解析全限定域名(FQDN),和使用了该 DNS 后缀的 Services 或者网络名称。 例如,在default命名空间中生成一个 Pod,该 Pod 会获得的 DNS 后缀为default.svc.cluster.local。 在 Windows 的 Pod 中,你可以解析kubernetes.default.svc.cluster.local和kubernetes, 但是不能解析部分限定名称(kubernetes.default和kubernetes.default.svc)。
接下来
有关管理 DNS 配置的指导, 请查看配置 DNS 服务
5.8 - IPv4/IPv6 双协议栈
Kubernetes 允许你配置单协议栈 IPv4 网络、单协议栈 IPv6 网络或同时激活这两种网络的双协议栈网络。本页说明具体配置方法。
特性状态:
Kubernetes v1.23 [stable]
IPv4/IPv6 双协议栈网络能够将 IPv4 和 IPv6 地址分配给 Pod 和 Service。
从 1.21 版本开始,Kubernetes 集群默认启用 IPv4/IPv6 双协议栈网络, 以支持同时分配 IPv4 和 IPv6 地址。
支持的功能
Kubernetes 集群的 IPv4/IPv6 双协议栈可提供下面的功能:
- 双协议栈 Pod 网络(每个 Pod 分配一个 IPv4 和 IPv6 地址)
- IPv4 和 IPv6 启用的 Service
- Pod 的集群外出口通过 IPv4 和 IPv6 路由
先决条件
为了使用 IPv4/IPv6 双栈的 Kubernetes 集群,需要满足以下先决条件:
- Kubernetes 1.20 版本或更高版本,有关更早 Kubernetes 版本的使用双栈 Service 的信息, 请参考对应版本的 Kubernetes 文档。
- 提供商支持双协议栈网络(云提供商或其他提供商必须能够为 Kubernetes 节点提供可路由的 IPv4/IPv6 网络接口)。
- 支持双协议栈的网络插件。
配置 IPv4/IPv6 双协议栈
如果配置 IPv4/IPv6 双栈,请分配双栈集群网络:
- kube-apiserver:
--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>
- kube-controller-manager:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>--node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6对于 IPv4 默认为 /24, 对于 IPv6 默认为 /64
- kube-proxy:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>
- kubelet:
--node-ip=<IPv4 IP>,<IPv6 IP>- 裸机双栈节点(未使用
--cloud-provider标志定义云平台的节点)需要此选项。 如果你使用了某个云平台并选择覆盖云平台所选择的节点 IP,请设置--node-ip选项。 - (传统的内置云平台实现不支持双栈
--node-ip。)
- 裸机双栈节点(未使用
说明:
IPv4 CIDR 的一个例子:10.244.0.0/16(尽管你会提供你自己的地址范围)。
IPv6 CIDR 的一个例子:fdXY:IJKL:MNOP:15::/64
(这里演示的是格式而非有效地址 - 请看 RFC 4193)。
特性状态:
Kubernetes v1.27 [alpha]
Service
你可以使用 IPv4 或 IPv6 地址来创建 Service。
Service 的地址族默认为第一个服务集群 IP 范围的地址族(通过 kube-apiserver 的
--service-cluster-ip-range 参数配置)。
当你定义 Service 时,可以选择将其配置为双栈。若要指定所需的行为,你可以设置
.spec.ipFamilyPolicy 字段为以下值之一:
SingleStack:单栈 Service。控制面使用第一个配置的服务集群 IP 范围为 Service 分配集群 IP。PreferDualStack:- 为 Service 分配 IPv4 和 IPv6 集群 IP 地址。
RequireDualStack:从 IPv4 和 IPv6 的地址范围分配 Service 的.spec.ClusterIPs- 从基于在
.spec.ipFamilies数组中第一个元素的地址族的.spec.ClusterIPs列表中选择.spec.ClusterIP
- 从基于在
如果你想要定义哪个 IP 族用于单栈或定义双栈 IP 族的顺序,可以通过设置
Service 上的可选字段 .spec.ipFamilies 来选择地址族。
说明:
.spec.ipFamilies 字段修改是有条件的:你可以添加或删除第二个 IP 地址族,
但你不能更改现有 Service 的主要 IP 地址族。
你可以设置 .spec.ipFamily 为以下任何数组值:
["IPv4"]["IPv6"]["IPv4","IPv6"](双栈)["IPv6","IPv4"](双栈)
你所列出的第一个地址族用于原来的 .spec.ClusterIP 字段。
双栈 Service 配置场景
以下示例演示多种双栈 Service 配置场景下的行为。
新 Service 的双栈选项
-
此 Service 规约中没有显式设定
.spec.ipFamilyPolicy。当你创建此 Service 时,Kubernetes 从所配置的第一个service-cluster-ip-range中为 Service 分配一个集群 IP,并设置.spec.ipFamilyPolicy为SingleStack。 (无选择算符的 Service 和无头服务(Headless Service)的行为方式与此相同。)apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80
-
此 Service 规约显式地将
.spec.ipFamilyPolicy设置为PreferDualStack。 当你在双栈集群上创建此 Service 时,Kubernetes 会为此 Service 分配 IPv4 和 IPv6 地址。 控制平面更新 Service 的.spec以记录 IP 地址分配。 字段.spec.ClusterIPs是主要字段,包含两个分配的 IP 地址;.spec.ClusterIP是次要字段, 其取值从.spec.ClusterIPs计算而来。- 对于
.spec.ClusterIP字段,控制面记录来自第一个服务集群 IP 范围对应的地址族的 IP 地址。 - 对于单协议栈的集群,
.spec.ClusterIPs和.spec.ClusterIP字段都 仅仅列出一个地址。 - 对于启用了双协议栈的集群,将
.spec.ipFamilyPolicy设置为RequireDualStack时,其行为与PreferDualStack相同。
apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: ipFamilyPolicy: PreferDualStack selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80 - 对于
-
下面的 Service 规约显式地在
.spec.ipFamilies中指定IPv6和IPv4,并将.spec.ipFamilyPolicy设定为PreferDualStack。 当 Kubernetes 为.spec.ClusterIPs分配一个 IPv6 和一个 IPv4 地址时,.spec.ClusterIP被设置成 IPv6 地址,因为它是.spec.ClusterIPs数组中的第一个元素, 覆盖其默认值。apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: ipFamilyPolicy: PreferDualStack ipFamilies: - IPv6 - IPv4 selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80
现有 Service 的双栈默认值
下面示例演示了在 Service 已经存在的集群上新启用双栈时的默认行为。 (将现有集群升级到 1.21 或者更高版本会启用双协议栈支持。)
-
在集群上启用双栈时,控制面会将现有 Service(无论是
IPv4还是IPv6)配置.spec.ipFamilyPolicy为SingleStack并设置.spec.ipFamilies为 Service 的当前地址族。apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80你可以通过使用 kubectl 检查现有 Service 来验证此行为。
kubectl get svc my-service -o yamlapiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: MyApp name: my-service spec: clusterIP: 10.0.197.123 clusterIPs: - 10.0.197.123 ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - port: 80 protocol: TCP targetPort: 80 selector: app.kubernetes.io/name: MyApp type: ClusterIP status: loadBalancer: {}
-
在集群上启用双栈时,带有选择算符的现有 无头服务 由控制面设置
.spec.ipFamilyPolicy为SingleStack并设置.spec.ipFamilies为第一个服务集群 IP 范围的地址族(通过配置 kube-apiserver 的--service-cluster-ip-range参数),即使.spec.ClusterIP的设置值为None也如此。apiVersion: v1 kind: Service metadata: name: my-service labels: app.kubernetes.io/name: MyApp spec: selector: app.kubernetes.io/name: MyApp ports: - protocol: TCP port: 80你可以通过使用 kubectl 检查带有选择算符的现有无头服务来验证此行为。
kubectl get svc my-service -o yamlapiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: MyApp name: my-service spec: clusterIP: None clusterIPs: - None ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - port: 80 protocol: TCP targetPort: 80 selector: app.kubernetes.io/name: MyApp
在单栈和双栈之间切换 Service
Service 可以从单栈更改为双栈,也可以从双栈更改为单栈。
-
要将 Service 从单栈更改为双栈,根据需要将
.spec.ipFamilyPolicy从SingleStack改为PreferDualStack或RequireDualStack。 当你将此 Service 从单栈更改为双栈时,Kubernetes 将分配缺失的地址族, 以便现在此 Service具有 IPv4 和 IPv6 地址。 编辑 Service 规约将.spec.ipFamilyPolicy从SingleStack改为PreferDualStack。之前:
spec: ipFamilyPolicy: SingleStack之后:
spec: ipFamilyPolicy: PreferDualStack
- 要将 Service 从双栈更改为单栈,请将
.spec.ipFamilyPolicy从PreferDualStack或RequireDualStack改为SingleStack。 当你将此 Service 从双栈更改为单栈时,Kubernetes 只保留.spec.ClusterIPs数组中的第一个元素,并设置.spec.ClusterIP为那个 IP 地址, 并设置.spec.ipFamilies为.spec.ClusterIPs地址族。
无选择算符的无头服务
对于不带选择算符的无头服务,
若没有显式设置 .spec.ipFamilyPolicy,则 .spec.ipFamilyPolicy
字段默认设置为 RequireDualStack。
LoadBalancer 类型 Service
要为你的 Service 提供双栈负载均衡器:
- 将
.spec.type字段设置为LoadBalancer - 将
.spec.ipFamilyPolicy字段设置为PreferDualStack或者RequireDualStack
说明:
为了使用双栈的负载均衡器类型 Service,你的云驱动必须支持 IPv4 和 IPv6 的负载均衡器。
出站流量
如果你要启用出站流量,以便使用非公开路由 IPv6 地址的 Pod 到达集群外地址 (例如公网),则需要通过透明代理或 IP 伪装等机制使 Pod 使用公共路由的 IPv6 地址。 ip-masq-agent项目 支持在双栈集群上进行 IP 伪装。
说明:
确认你的 CNI 驱动支持 IPv6。
Windows 支持
Windows 上的 Kubernetes 不支持单栈“仅 IPv6” 网络。 然而, 对于 Pod 和节点而言,仅支持单栈形式 Service 的双栈 IPv4/IPv6 网络是被支持的。
你可以使用 l2bridge 网络来实现 IPv4/IPv6 双栈联网。
说明:
Windows 上的 Overlay(VXLAN)网络不支持双栈网络。
关于 Windows 的不同网络模式,你可以进一步阅读 Windows 上的网络。
接下来
5.9 - 拓扑感知路由
拓扑感知路由提供了一种机制帮助保持网络流量处于流量发起的区域内。 在集群中 Pod 之间优先使用相同区域的流量有助于提高可靠性、性能(网络延迟和吞吐量)或降低成本。
特性状态:
Kubernetes v1.23 [beta]
说明:
在 Kubernetes 1.27 之前,此特性称为拓扑感知提示(Topology Aware Hint)。
拓扑感知路由(Toplogy Aware Routing) 调整路由行为,以优先保持流量在其发起区域内。 在某些情况下,这有助于降低成本或提高网络性能。
动机
Kubernetes 集群越来越多地部署在多区域环境中。 拓扑感知路由 提供了一种机制帮助流量保留在其发起所在的区域内。 计算 服务(Service) 的端点时, EndpointSlice 控制器考虑每个端点的物理拓扑(地区和区域),并填充提示字段以将其分配到区域。 诸如 kube-proxy 等集群组件可以使用这些提示,影响流量的路由方式(优先考虑物理拓扑上更近的端点)。
启用拓扑感知路由
说明:
在 Kubernetes 1.27 之前,此行为是通过 service.kubernetes.io/topology-aware-hints 注解来控制的。
你可以通过将 service.kubernetes.io/topology-mode 注解设置为 Auto 来启用 Service 的拓扑感知路由。
当每个区域中有足够的端点可用时,系统将为 EndpointSlices 填充拓扑提示,把每个端点分配给特定区域,
从而使流量被路由到更接近其来源的位置。
何时效果最佳
此特性在以下场景中的工作效果最佳:
1. 入站流量均匀分布
如果大部分流量源自同一个区域,则该流量可能会使分配到该区域的端点子集过载。 当预计入站流量源自同一区域时,不建议使用此特性。
2. 服务在每个区域具有至少 3 个端点
在一个三区域的集群中,这意味着有至少 9 个端点。如果每个区域的端点少于 3 个, 则 EndpointSlice 控制器很大概率(约 50%)无法平均分配端点,而是回退到默认的集群范围的路由方法。
工作原理
“自动”启发式算法会尝试按比例分配一定数量的端点到每个区域。 请注意,这种启发方式对具有大量端点的 Service 效果最佳。
EndpointSlice 控制器
当启用此启发方式时,EndpointSlice 控制器负责在各个 EndpointSlice 上设置提示信息。 控制器按比例给每个区域分配一定比例数量的端点。 这个比例基于在该区域中运行的节点的可分配 CPU 核心数。例如,如果一个区域有 2 个 CPU 核心,而另一个区域只有 1 个 CPU 核心, 那么控制器将给那个有 2 CPU 的区域分配两倍数量的端点。
以下示例展示了提供提示信息后 EndpointSlice 的样子:
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-hints
labels:
kubernetes.io/service-name: example-svc
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
zone: zone-a
hints:
forZones:
- name: "zone-a"
kube-proxy
kube-proxy 组件依据 EndpointSlice 控制器设置的提示,过滤由它负责路由的端点。 在大多数场合,这意味着 kube-proxy 可以把流量路由到同一个区域的端点。 有时,控制器在另一不同的区域中分配端点,以确保在多个区域之间更平均地分配端点。 这会导致部分流量被路由到其他区域。
保护措施
Kubernetes 控制平面和每个节点上的 kube-proxy 在使用拓扑感知提示信息前,会应用一些保护措施规则。 如果规则无法顺利通过,kube-proxy 将无视区域限制,从集群中的任意位置选择端点。
- 端点数量不足: 如果一个集群中,端点数量少于区域数量,控制器不创建任何提示。
- 不可能实现均衡分配: 在一些场合中,不可能实现端点在区域中的平衡分配。 例如,假设 zone-a 比 zone-b 大两倍,但只有 2 个端点, 那分配到 zone-a 的端点可能收到比 zone-b 多两倍的流量。 如果控制器不能确保此“期望的过载”值低于每一个区域可接受的阈值,控制器将不添加提示信息。 重要的是,这不是基于实时反馈。所以对于特定的端点仍有可能超载。
- 一个或多个 Node 信息不足: 如果任一节点没有设置标签
topology.kubernetes.io/zone, 或没有上报可分配的 CPU 数据,控制平面将不会设置任何拓扑感知提示, 进而 kube-proxy 也就不能根据区域来过滤端点。
- 至少一个端点没有设置区域提示: 当这种情况发生时, kube-proxy 会假设从拓扑感知提示到拓扑感知路由(或反方向)的迁移仍在进行中, 在这种场合下过滤 Service 的端点是有风险的,所以 kube-proxy 回退到使用所有端点。
- 提示中不存在某区域: 如果 kube-proxy 无法找到提示中指向它当前所在的区域的端点, 它将回退到使用来自所有区域的端点。当你向现有集群新增新的区域时,这种情况发生概率很高。
限制
- 当 Service 的
internalTrafficPolicy值设置为Local时, 系统将不使用拓扑感知提示信息。你可以在同一集群中的不同 Service 上使用这两个特性, 但不能在同一个 Service 上这么做。
- 这种方法不适用于大部分流量来自于一部分区域的 Service。 相反,这项技术的假设是入站流量与各区域中节点的服务能力成比例关系。
- EndpointSlice 控制器在计算各区域的比例时,会忽略未就绪的节点。 在大部分节点未就绪的场景下,这样做会带来非预期的结果。
- EndpointSlice 控制器忽略设置了
node-role.kubernetes.io/control-plane或node-role.kubernetes.io/master标签的节点。如果工作负载也在这些节点上运行,也可能会产生问题。
- EndpointSlice 控制器在分派或计算各区域的比例时,并不会考虑 容忍度。 如果 Service 背后的各 Pod 被限制只能运行在集群节点的一个子集上,计算比例时不会考虑这点。
- 这项技术和自动扩缩容机制之间可能存在冲突。例如,如果大量流量来源于同一个区域, 那只有分配到该区域的端点才可用来处理流量。这会导致 Pod 自动水平扩缩容 要么不能处理这种场景,要么会在别的区域添加 Pod。
自定义启发方式
Kubernetes 的部署方式有很多种,没有一种按区域分配端点的启发式方法能够适用于所有场景。 此特性的一个关键目标是:如果内置的启发方式不能满足你的使用场景,则可以开发自定义的启发方式。 启用自定义启发方式的第一步包含在了 1.27 版本中。 这是一个限制性较强的实现,可能尚未涵盖一些重要的、可进一步探索的场景。
接下来
- 参阅使用 Service 连接到应用教程
5.10 - Windows 网络
Kubernetes 支持运行 Linux 或 Windows 节点。 你可以在统一集群内混布这两种节点。 本页提供了特定于 Windows 操作系统的网络概述。
Windows 容器网络
Windows 容器网络通过 CNI 插件暴露。 Windows 容器网络的工作方式与虚拟机类似。 每个容器都有一个连接到 Hyper-V 虚拟交换机(vSwitch)的虚拟网络适配器(vNIC)。 主机网络服务(Host Networking Service,HNS)和主机计算服务(Host Compute Service,HCS) 协同创建容器并将容器 vNIC 挂接到网络。 HCS 负责管理容器,而 HNS 负责管理以下网络资源:
- 虚拟网络(包括创建 vSwitch)
- Endpoint / vNIC
- 命名空间
- 包括数据包封装、负载均衡规则、ACL 和 NAT 规则在内的策略。
Windows HNS 和 vSwitch 实现命名空间划分,且可以按需为 Pod 或容器创建虚拟 NIC。
然而,诸如 DNS、路由和指标等许多配置将存放在 Windows 注册表数据库中,
而不是像 Linux 将这些配置作为文件存放在 /etc 内。
针对容器的 Windows 注册表与主机的注册表是分开的,因此将 /etc/resolv.conf
从主机映射到一个容器的类似概念与 Linux 上的效果不同。
这些必须使用容器环境中运行的 Windows API 进行配置。
因此,实现 CNI 时需要调用 HNS,而不是依赖文件映射将网络详情传递到 Pod 或容器中。
网络模式
Windows 支持五种不同的网络驱动/模式:L2bridge、L2tunnel、Overlay (Beta)、Transparent 和 NAT。 在 Windows 和 Linux 工作节点组成的异构集群中,你需要选择一个同时兼容 Windows 和 Linux 的网络方案。 下表列出了 Windows 支持的树外插件,并给出了何时使用每种 CNI 的建议:
| 网络驱动 | 描述 | 容器数据包修改 | 网络插件 | 网络插件特点 |
|---|---|---|---|---|
| L2bridge | 容器挂接到一个外部 vSwitch。容器挂接到下层网络,但物理网络不需要了解容器的 MAC,因为这些 MAC 在入站/出站时被重写。 | MAC 被重写为主机 MAC,可使用 HNS OutboundNAT 策略将 IP 重写为主机 IP。 | win-bridge、Azure-CNI、Flannel host-gateway 使用 win-bridge | win-bridge 使用 L2bridge 网络模式,将容器连接到主机的下层,提供最佳性能。节点间连接需要用户定义的路由(UDR)。 |
| L2Tunnel | 这是 L2bridge 的一种特例,但仅用在 Azure 上。所有数据包都会被发送到应用了 SDN 策略的虚拟化主机。 | MAC 被重写,IP 在下层网络上可见。 | Azure-CNI | Azure-CNI 允许将容器集成到 Azure vNET,允许容器充分利用 Azure 虚拟网络所提供的能力集合。例如,安全地连接到 Azure 服务或使用 Azure NSG。参考 azure-cni 了解有关示例。 |
| Overlay | 容器被赋予一个 vNIC,连接到外部 vSwitch。每个上层网络都有自己的 IP 子网,由自定义 IP 前缀进行定义。该上层网络驱动使用 VXLAN 封装。 | 用外部头进行封装。 | win-overlay、Flannel VXLAN(使用 win-overlay) | 当需要将虚拟容器网络与主机的下层隔离时(例如出于安全原因),应使用 win-overlay。如果你的数据中心的 IP 个数有限,可以将 IP 在不同的上层网络中重用(带有不同的 VNID 标记)。在 Windows Server 2019 上这个选项需要 KB4489899。 |
| Transparent(ovn-kubernetes 的特殊用例) | 需要一个外部 vSwitch。容器挂接到一个外部 vSwitch,由后者通过逻辑网络(逻辑交换机和路由器)实现 Pod 内通信。 | 数据包通过 GENEVE 或 STT 隧道进行封装,以到达其它主机上的 Pod。 数据包基于 OVN 网络控制器提供的隧道元数据信息被转发或丢弃。 南北向通信使用 NAT。 |
ovn-kubernetes | 通过 ansible 部署。通过 Kubernetes 策略可以实施分布式 ACL。支持 IPAM。无需 kube-proxy 即可实现负载均衡。无需 iptables/netsh 即可进行 NAT。 |
| NAT(Kubernetes 中未使用) | 容器被赋予一个 vNIC,连接到内部 vSwitch。DNS/DHCP 是使用一个名为 WinNAT 的内部组件实现的 | MAC 和 IP 重写为主机 MAC/IP。 | nat | 放在此处保持完整性。 |
如上所述,Windows 通过 VXLAN 网络后端(Beta 支持;委派给 win-overlay) 和 host-gateway 网络后端(稳定支持;委派给 win-bridge) 也支持 Flannel 的 CNI 插件。
此插件支持委派给参考 CNI 插件(win-overlay、win-bridge)之一,配合使用 Windows
上的 Flannel 守护程序(Flanneld),以便自动分配节点子网租赁并创建 HNS 网络。
该插件读取自己的配置文件(cni.conf),并聚合 FlannelD 生成的 subnet.env 文件中的环境变量。
然后,委派给网络管道的参考 CNI 插件之一,并将包含节点分配子网的正确配置发送给 IPAM 插件(例如:host-local)。
对于 Node、Pod 和 Service 对象,TCP/UDP 流量支持以下网络流:
- Pod → Pod(IP)
- Pod → Pod(名称)
- Pod → Service(集群 IP)
- Pod → Service(PQDN,但前提是没有 ".")
- Pod → Service(FQDN)
- Pod → 外部(IP)
- Pod → 外部(DNS)
- Node → Pod
- Pod → Node
IP 地址管理(IPAM)
Windows 支持以下 IPAM 选项:
- host-local
- azure-vnet-ipam(仅适用于 azure-cni)
- Windows Server IPAM(未设置 IPAM 时的回滚选项)
负载均衡和 Service
Kubernetes Service 是一种抽象:定义了逻辑上的一组 Pod 和一种通过网络访问这些 Pod 的方式。 在包含 Windows 节点的集群中,你可以使用以下类别的 Service:
NodePortClusterIPLoadBalancerExternalName
Windows 容器网络与 Linux 网络有着很重要的差异。 更多细节和背景信息,参考 Microsoft Windows 容器网络文档。
在 Windows 上,你可以使用以下设置来配置 Service 和负载均衡行为:
| 功能特性 | 描述 | 支持的 Windows 操作系统最低版本 | 启用方式 |
|---|---|---|---|
| 会话亲和性 | 确保每次都将来自特定客户端的连接传递到同一个 Pod。 | Windows Server 2022 | 将 service.spec.sessionAffinity 设为 “ClientIP” |
| Direct Server Return (DSR) | 在负载均衡模式中 IP 地址修正和 LBNAT 直接发生在容器 vSwitch 端口;服务流量到达时源 IP 设置为原始 Pod IP。 | Windows Server 2019 | 在 kube-proxy 中设置以下标志:--feature-gates="WinDSR=true" --enable-dsr=true |
| 保留目标(Preserve-Destination) | 跳过服务流量的 DNAT,从而在到达后端 Pod 的数据包中保留目标服务的虚拟 IP。也会禁用节点间的转发。 | Windows Server,version 1903 | 在服务注解中设置 "preserve-destination": "true" 并在 kube-proxy 中启用 DSR。 |
| IPv4/IPv6 双栈网络 | 进出集群和集群内通信都支持原生的 IPv4 间与 IPv6 间流量 | Windows Server 2019 | 参考 IPv4/IPv6 双栈。 |
| 客户端 IP 保留 | 确保入站流量的源 IP 得到保留。也会禁用节点间转发。 | Windows Server 2019 | 将 service.spec.externalTrafficPolicy 设置为 “Local” 并在 kube-proxy 中启用 DSR。 |
警告:
如果目的地节点在运行 Windows Server 2022,则上层网络的 NodePort Service 存在已知问题。
要完全避免此问题,可以使用 externalTrafficPolicy: Local 配置服务。
在安装了 KB5005619 的 Windows Server 2022 或更高版本上,采用 L2bridge 网络时 Pod 间连接存在已知问题。 要解决此问题并恢复 Pod 间连接,你可以在 kube-proxy 中禁用 WinDSR 功能。
这些问题需要操作系统修复。 有关更新,请参考 https://github.com/microsoft/Windows-Containers/issues/204。
限制
Windows 节点不支持以下网络功能:
- 主机网络模式
- 从节点本身访问本地 NodePort(可以从其他节点或外部客户端进行访问)
- 为同一 Service 提供 64 个以上后端 Pod(或不同目的地址)
- 在连接到上层网络的 Windows Pod 之间使用 IPv6 通信
- 非 DSR 模式中的本地流量策略(Local Traffic Policy)
- 通过
win-overlay、win-bridge使用 ICMP 协议,或使用 Azure-CNI 插件进行出站通信。
具体而言,Windows 数据平面(VFP)不支持 ICMP 数据包转换,这意味着:- 指向同一网络内目的地址的 ICMP 数据包(例如 Pod 间的 ping 通信)可正常工作;
- TCP/UDP 数据包可正常工作;
- 通过远程网络指向其它地址的 ICMP 数据包(例如通过 ping 从 Pod 到外部公网的通信)无法被转换, 因此无法被路由回到这些数据包的源点;
- 由于 TCP/UDP 数据包仍可被转换,所以在调试与外界的连接时,
你可以将
ping <destination>替换为curl <destination>。
其他限制:
- 由于缺少
CHECK实现,Windows 参考网络插件 win-bridge 和 win-overlay 未实现 CNI 规约 的 v0.4.0 版本。 - Flannel VXLAN CNI 插件在 Windows 上有以下限制:
- 使用 Flannel v0.12.0(或更高版本)时,节点到 Pod 的连接仅适用于本地 Pod。
- Flannel 仅限于使用 VNI 4096 和 UDP 端口 4789。 有关这些参数的更多详细信息,请参考官方的 Flannel VXLAN 后端文档。
5.11 - Service ClusterIP 分配
在 Kubernetes 中,Service 是一种抽象的方式,
用于公开在一组 Pod 上运行的应用。
Service 可以具有集群作用域的虚拟 IP 地址(使用 type: ClusterIP 的 Service)。
客户端可以使用该虚拟 IP 地址进行连接,Kubernetes 通过不同的后台 Pod 对该 Service 的流量进行负载均衡。
Service ClusterIP 是如何分配的?
当 Kubernetes 需要为 Service 分配虚拟 IP 地址时,该分配会通过以下两种方式之一进行:
- 动态分配
- 集群的控制面自动从所配置的 IP 范围内为
type: ClusterIP选择一个空闲 IP 地址。 - 静态分配
- 根据为 Service 所配置的 IP 范围,选定并设置你的 IP 地址。
在整个集群中,每个 Service 的 ClusterIP 都必须是唯一的。
尝试使用已分配的 ClusterIP 创建 Service 将返回错误。
为什么需要预留 Service 的 ClusterIP ?
有时你可能希望 Services 在众所周知的 IP 上面运行,以便集群中的其他组件和用户可以使用它们。
最好的例子是集群的 DNS Service。作为一种非强制性的约定,一些 Kubernetes 安装程序 将 Service IP 范围中的第 10 个 IP 地址分配给 DNS 服务。假设将集群的 Service IP 范围配置为 10.96.0.0/16,并且希望 DNS Service IP 为 10.96.0.10,则必须创建如下 Service:
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: CoreDNS
name: kube-dns
namespace: kube-system
spec:
clusterIP: 10.96.0.10
ports:
- name: dns
port: 53
protocol: UDP
targetPort: 53
- name: dns-tcp
port: 53
protocol: TCP
targetPort: 53
selector:
k8s-app: kube-dns
type: ClusterIP
但如前所述,IP 地址 10.96.0.10 尚未被保留。如果在 DNS 启动之前或同时采用动态分配机制创建其他 Service, 则它们有可能被分配此 IP,因此,你将无法创建 DNS Service,因为它会因冲突错误而失败。
如何避免 Service ClusterIP 冲突?
Kubernetes 中用來将 ClusterIP 分配给 Service 的分配策略降低了冲突的风险。
ClusterIP 范围根据公式 min(max(16, cidrSize / 16), 256) 进行划分,
描述为不小于 16 且不大于 256,并在二者之间有一个渐进的步长。
默认情况下,动态 IP 分配使用地址较高的一段,一旦用完,它将使用较低范围。 这将允许用户在冲突风险较低的较低地址段上使用静态分配。
示例
示例 1
此示例使用 IP 地址范围:10.96.0.0/24(CIDR 表示法)作为 Service 的 IP 地址。
范围大小:28 - 2 = 254
带宽偏移量:min(max(16, 256/16), 256) = min(16, 256) = 16
静态带宽起始地址:10.96.0.1
静态带宽结束地址:10.96.0.16
范围结束地址:10.96.0.254
pie showData
title 10.96.0.0/24
"静态分配" : 16
"动态分配" : 238
示例 2
此示例使用 IP 地址范围 10.96.0.0/20(CIDR 表示法)作为 Service 的 IP 地址。
范围大小:212 - 2 = 4094
带宽偏移量:min(max(16, 4096/16), 256) = min(256, 256) = 256
静态带宽起始地址:10.96.0.1
静态带宽结束地址:10.96.1.0
范围结束地址:10.96.15.254
pie showData
title 10.96.0.0/20
"静态分配" : 256
"动态分配" : 3838
示例 3
此示例使用 IP 地址范围 10.96.0.0/16(CIDR 表示法)作为 Service 的 IP 地址。
范围大小:216 - 2 = 65534
带宽偏移量:min(max(16, 65536/16), 256) = min(4096, 256) = 256
静态带宽起始地址:10.96.0.1
静态带宽结束地址:10.96.1.0
范围结束地址:10.96.255.254
pie showData
title 10.96.0.0/16
"静态分配" : 256
"动态分配" : 65278
接下来
5.12 - 服务内部流量策略
如果集群中的两个 Pod 想要通信,并且两个 Pod 实际上都在同一节点运行, 服务内部流量策略 可以将网络流量限制在该节点内。 通过集群网络避免流量往返有助于提高可靠性、增强性能(网络延迟和吞吐量)或降低成本。
特性状态:
Kubernetes v1.26 [stable]
服务内部流量策略开启了内部流量限制,将内部流量只路由到发起方所处节点内的服务端点。 这里的”内部“流量指当前集群中的 Pod 所发起的流量。 这种机制有助于节省开销,提升效率。
使用服务内部流量策略
你可以通过将 Service 的
.spec.internalTrafficPolicy 项设置为 Local,
来为它指定一个内部专用的流量策略。
此设置就相当于告诉 kube-proxy 对于集群内部流量只能使用节点本地的服务端口。
说明: 如果某节点上的 Pod 均不提供指定 Service 的服务端点,
即使该 Service 在其他节点上有可用的服务端点,
Service 的行为看起来也像是它只有 0 个服务端点(只针对此节点上的 Pod)。
以下示例展示了把 Service 的 .spec.internalTrafficPolicy 项设为 Local 时,
Service 的样子:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
internalTrafficPolicy: Local
工作原理
kube-proxy 基于 spec.internalTrafficPolicy 的设置来过滤路由的目标服务端点。
当它的值设为 Local 时,只会选择节点本地的服务端点。
当它的值设为 Cluster 或缺省时,Kubernetes 会选择所有的服务端点。
接下来
- 请阅读拓扑感知路由
- 请阅读 Service 的外部流量策略
- 遵循使用 Service 连接到应用教程
6 - 存储
为集群中的 Pods 提供长期和临时存储的方法。
6.1 - 卷
容器中的文件在磁盘上是临时存放的,这给在容器中运行较重要的应用带来一些问题。 当容器崩溃或停止时会出现一个问题。此时容器状态未保存, 因此在容器生命周期内创建或修改的所有文件都将丢失。 在崩溃期间,kubelet 会以干净的状态重新启动容器。 当多个容器在一个 Pod 中运行并且需要共享文件时,会出现另一个问题。 跨所有容器设置和访问共享文件系统具有一定的挑战性。
Kubernetes 卷(Volume) 这一抽象概念能够解决这两个问题。
阅读本文前建议你熟悉一下 Pod。
背景
Kubernetes 支持很多类型的卷。 Pod 可以同时使用任意数目的卷类型。 临时卷类型的生命周期与 Pod 相同, 但持久卷可以比 Pod 的存活期长。 当 Pod 不再存在时,Kubernetes 也会销毁临时卷;不过 Kubernetes 不会销毁持久卷。 对于给定 Pod 中任何类型的卷,在容器重启期间数据都不会丢失。
卷的核心是一个目录,其中可能存有数据,Pod 中的容器可以访问该目录中的数据。 所采用的特定的卷类型将决定该目录如何形成的、使用何种介质保存数据以及目录中存放的内容。
使用卷时, 在 .spec.volumes 字段中设置为 Pod 提供的卷,并在
.spec.containers[*].volumeMounts 字段中声明卷在容器中的挂载位置。
容器中的进程看到的文件系统视图是由它们的容器镜像
的初始内容以及挂载在容器中的卷(如果定义了的话)所组成的。
其中根文件系统同容器镜像的内容相吻合。
任何在该文件系统下的写入操作,如果被允许的话,都会影响接下来容器中进程访问文件系统时所看到的内容。
卷挂载在镜像中的指定路径下。 Pod 配置中的每个容器必须独立指定各个卷的挂载位置。
卷不能挂载到其他卷之上(不过存在一种使用 subPath 的相关机制),也不能与其他卷有硬链接。
卷类型
Kubernetes 支持下列类型的卷:
awsElasticBlockStore (已移除)
Kubernetes 1.29 不包含 awsElasticBlockStore 卷类型。
AWSElasticBlockStore 树内存储驱动已在 Kubernetes v1.19 版本中废弃, 并在 v1.27 版本中被完全移除。
Kubernetes 项目建议你转为使用 AWS EBS 第三方存储驱动插件。
azureDisk (已移除)
Kubernetes 1.29 不包含 azureDisk 卷类型。
AzureDisk 树内存储驱动已在 Kubernetes v1.19 版本中废弃,并在 v1.27 版本中被完全移除。
Kubernetes 项目建议你转为使用 Azure Disk 第三方存储驱动插件。
azureFile (已弃用)
特性状态:
Kubernetes v1.21 [deprecated]
azureFile 卷类型用来在 Pod 上挂载 Microsoft Azure 文件卷(File Volume)(SMB 2.1 和 3.0)。
更多详情请参考 azureFile 卷插件。
azureFile CSI 迁移
特性状态:
Kubernetes v1.26 [stable]
启用 azureFile 的 CSIMigration 特性后,所有插件操作将从现有的树内插件重定向到
file.csi.azure.com 容器存储接口(CSI)驱动程序。要使用此特性,必须在集群中安装
Azure 文件 CSI 驱动程序,
并且 CSIMigrationAzureFile
特性门控
必须被启用。
Azure 文件 CSI 驱动尚不支持为同一卷设置不同的 fsgroup。
如果 CSIMigrationAzureFile 特性被启用,用不同的 fsgroup 来使用同一卷也是不被支持的。
azureFile CSI 迁移完成
特性状态:
Kubernetes v1.21 [alpha]
要禁止控制器管理器和 kubelet 加载 azureFile 存储插件,
请将 InTreePluginAzureFileUnregister 标志设置为 true。
cephfs
特性状态:
Kubernetes v1.28 [deprecated]
说明:
Kubernetes 项目建议你转为使用 CephFS CSI 第三方存储驱动插件。
cephfs 卷允许你将现存的 CephFS 卷挂载到 Pod 中。
不像 emptyDir 那样会在 Pod 被删除的同时也会被删除,cephfs
卷的内容在 Pod 被删除时会被保留,只是卷被卸载了。
这意味着 cephfs 卷可以被预先填充数据,且这些数据可以在
Pod 之间共享。同一 cephfs 卷可同时被多个写者挂载。
说明:
在使用 Ceph 卷之前,你的 Ceph 服务器必须已经运行并将要使用的 share 导出(exported)。
更多信息请参考 CephFS 示例。
cinder(已移除)
Kubernetes 1.29 不包含 cinder 卷类型。
OpenStack Cinder 树内存储驱动已在 Kubernetes v1.11 版本中废弃, 并在 v1.26 版本中被完全移除。
Kubernetes 项目建议你转为使用 OpenStack Cinder 第三方存储驱动插件。
configMap
configMap
卷提供了向 Pod 注入配置数据的方法。
ConfigMap 对象中存储的数据可以被 configMap 类型的卷引用,然后被 Pod 中运行的容器化应用使用。
引用 configMap 对象时,你可以在卷中通过它的名称来引用。
你可以自定义 ConfigMap 中特定条目所要使用的路径。
下面的配置显示了如何将名为 log-config 的 ConfigMap 挂载到名为 configmap-pod
的 Pod 中:
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod
spec:
containers:
- name: test
image: busybox:1.28
command: ['sh', '-c', 'echo "The app is running!" && tail -f /dev/null']
volumeMounts:
- name: config-vol
mountPath: /etc/config
volumes:
- name: config-vol
configMap:
name: log-config
items:
- key: log_level
path: log_level
log-config ConfigMap 以卷的形式挂载,并且存储在 log_level
条目中的所有内容都被挂载到 Pod 的 /etc/config/log_level 路径下。
请注意,这个路径来源于卷的 mountPath 和 log_level 键对应的 path。
说明:
downwardAPI
downwardAPI 卷用于为应用提供 downward API 数据。
在这类卷中,所公开的数据以纯文本格式的只读文件形式存在。
说明: 容器以 subPath 卷挂载方式使用 downward API 时,在字段值更改时将不能接收到它的更新。
更多详细信息请参考通过文件将 Pod 信息呈现给容器。
emptyDir
对于定义了 emptyDir 卷的 Pod,在 Pod 被指派到某节点时此卷会被创建。
就像其名称所表示的那样,emptyDir 卷最初是空的。尽管 Pod 中的容器挂载 emptyDir
卷的路径可能相同也可能不同,但这些容器都可以读写 emptyDir 卷中相同的文件。
当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会被永久删除。
说明:
容器崩溃并不会导致 Pod 被从节点上移除,因此容器崩溃期间 emptyDir 卷中的数据是安全的。
emptyDir 的一些用途:
- 缓存空间,例如基于磁盘的归并排序。
- 为耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
- 在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
emptyDir.medium 字段用来控制 emptyDir 卷的存储位置。
默认情况下,emptyDir 卷存储在该节点所使用的介质上;
此处的介质可以是磁盘、SSD 或网络存储,这取决于你的环境。
你可以将 emptyDir.medium 字段设置为 "Memory",
以告诉 Kubernetes 为你挂载 tmpfs(基于 RAM 的文件系统)。
虽然 tmpfs 速度非常快,但是要注意它与磁盘不同,
并且你所写入的所有文件都会计入容器的内存消耗,受容器内存限制约束。
你可以通过为默认介质指定大小限制,来限制 emptyDir 卷的存储容量。
此存储是从节点临时存储中分配的。
如果来自其他来源(如日志文件或镜像分层数据)的数据占满了存储,emptyDir
可能会在达到此限制之前发生存储容量不足的问题。
说明:
当启用 SizeMemoryBackedVolumes 特性门控时,
你可以为基于内存提供的卷指定大小。
如果未指定大小,内存提供的卷的大小根据节点可分配内存进行调整。
emptyDir 配置示例
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi
fc (光纤通道)
fc 卷类型允许将现有的光纤通道块存储卷挂载到 Pod 中。
可以使用卷配置中的参数 targetWWNs 来指定单个或多个目标 WWN(World Wide Names)。
如果指定了多个 WWN,targetWWNs 期望这些 WWN 来自多路径连接。
说明:
你必须配置 FC SAN Zoning,以便预先向目标 WWN 分配和屏蔽这些 LUN(卷),这样 Kubernetes 主机才可以访问它们。
更多详情请参考 FC 示例。
gcePersistentDisk(已移除)
Kubernetes 1.29 不包含 gcePersistentDisk 卷类型。
gcePersistentDisk 源代码树内卷存储驱动在 Kubernetes v1.17 版本中被弃用,在 v1.28 版本中被完全移除。
Kubernetes 项目建议你转为使用 Google Compute Engine Persistent Disk CSI 第三方存储驱动插件。
GCE CSI 迁移
特性状态:
Kubernetes v1.25 [stable]
启用 GCE PD 的 CSIMigration 特性后,所有插件操作将从现有的树内插件重定向到
pd.csi.storage.gke.io 容器存储接口(CSI)驱动程序。
为了使用此特性,必须在集群中上安装
GCE PD CSI 驱动程序。
gitRepo (已弃用)
警告:
gitRepo 卷类型已经被废弃。如果需要在容器中提供 git 仓库,请将一个
EmptyDir 卷挂载到 InitContainer 中,使用 git
命令完成仓库的克隆操作,然后将 EmptyDir 卷挂载到 Pod 的容器中。
gitRepo 卷是一个卷插件的例子。
该查卷挂载一个空目录,并将一个 Git 代码仓库克隆到这个目录中供 Pod 使用。
下面给出一个 gitRepo 卷的示例:
apiVersion: v1
kind: Pod
metadata:
name: server
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /mypath
name: git-volume
volumes:
- name: git-volume
gitRepo:
repository: "git@somewhere:me/my-git-repository.git"
revision: "22f1d8406d464b0c0874075539c1f2e96c253775"
glusterfs(已移除)
Kubernetes 1.29 不包含 glusterfs 卷类型。
GlusterFS 树内存储驱动程序在 Kubernetes v1.25 版本中被弃用,然后在 v1.26 版本中被完全移除。
hostPath
警告:
HostPath 卷存在许多安全风险,最佳做法是尽可能避免使用 HostPath。 当必须使用 HostPath 卷时,它的范围应仅限于所需的文件或目录,并以只读方式挂载。
如果通过 AdmissionPolicy 限制 HostPath 对特定目录的访问,则必须要求
volumeMounts 使用 readOnly 挂载以使策略生效。
hostPath 卷能将主机节点文件系统上的文件或目录挂载到你的 Pod 中。
虽然这不是大多数 Pod 需要的,但是它为一些应用程序提供了强大的逃生舱。
例如,hostPath 的一些用法有:
- 运行一个需要访问 Docker 内部机制的容器;可使用
hostPath挂载/var/lib/docker路径。 - 在容器中运行 cAdvisor 时,以
hostPath方式挂载/sys。 - 允许 Pod 指定给定的
hostPath在运行 Pod 之前是否应该存在,是否应该创建以及应该以什么方式存在。
除了必需的 path 属性之外,你可以选择性地为 hostPath 卷指定 type。
支持的 type 值如下:
| 取值 | 行为 |
|---|---|
| 空字符串(默认)用于向后兼容,这意味着在安装 hostPath 卷之前不会执行任何检查。 | |
DirectoryOrCreate |
如果在给定路径上什么都不存在,那么将根据需要创建空目录,权限设置为 0755,具有与 kubelet 相同的组和属主信息。 |
Directory |
在给定路径上必须存在的目录。 |
FileOrCreate |
如果在给定路径上什么都不存在,那么将在那里根据需要创建空文件,权限设置为 0644,具有与 kubelet 相同的组和所有权。 |
File |
在给定路径上必须存在的文件。 |
Socket |
在给定路径上必须存在的 UNIX 套接字。 |
CharDevice |
在给定路径上必须存在的字符设备。 |
BlockDevice |
在给定路径上必须存在的块设备。 |
当使用这种类型的卷时要小心,因为:
- HostPath 卷可能会暴露特权系统凭据(例如 Kubelet)或特权 API(例如容器运行时套接字),可用于容器逃逸或攻击集群的其他部分。
- 具有相同配置(例如基于同一 PodTemplate 创建)的多个 Pod 会由于节点上文件的不同而在不同节点上有不同的行为。
- 下层主机上创建的文件或目录只能由 root 用户写入。
你需要在特权容器中以
root 身份运行进程,或者修改主机上的文件权限以便容器能够写入
hostPath卷。
hostPath 配置示例
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# 宿主机上目录位置
path: /data
# 此字段为可选
type: Directory
注意:
FileOrCreate 模式不会负责创建文件的父目录。
如果欲挂载的文件的父目录不存在,Pod 启动会失败。
为了确保这种模式能够工作,可以尝试把文件和它对应的目录分开挂载,如
FileOrCreate 配置所示。
hostPath FileOrCreate 配置示例
apiVersion: v1
kind: Pod
metadata:
name: test-webserver
spec:
containers:
- name: test-webserver
image: registry.k8s.io/test-webserver:latest
volumeMounts:
- mountPath: /var/local/aaa
name: mydir
- mountPath: /var/local/aaa/1.txt
name: myfile
volumes:
- name: mydir
hostPath:
# 确保文件所在目录成功创建。
path: /var/local/aaa
type: DirectoryOrCreate
- name: myfile
hostPath:
path: /var/local/aaa/1.txt
type: FileOrCreate
iscsi
iscsi 卷能将 iSCSI (基于 IP 的 SCSI) 卷挂载到你的 Pod 中。
不像 emptyDir 那样会在删除 Pod 的同时也会被删除,iscsi
卷的内容在删除 Pod 时会被保留,卷只是被卸载。
这意味着 iscsi 卷可以被预先填充数据,并且这些数据可以在 Pod 之间共享。
说明:
在使用 iSCSI 卷之前,你必须拥有自己的 iSCSI 服务器,并在上面创建卷。
iSCSI 的一个特点是它可以同时被多个用户以只读方式挂载。 这意味着你可以用数据集预先填充卷,然后根据需要在尽可能多的 Pod 上使用它。 不幸的是,iSCSI 卷只能由单个使用者以读写模式挂载。不允许同时写入。
更多详情请参考 iSCSI 示例。
local
local 卷所代表的是某个被挂载的本地存储设备,例如磁盘、分区或者目录。
local 卷只能用作静态创建的持久卷。不支持动态配置。
与 hostPath 卷相比,local 卷能够以持久和可移植的方式使用,而无需手动将 Pod
调度到节点。系统通过查看 PersistentVolume 的节点亲和性配置,就能了解卷的节点约束。
然而,local 卷仍然取决于底层节点的可用性,并不适合所有应用程序。
如果节点变得不健康,那么 local 卷也将变得不可被 Pod 访问。使用它的 Pod 将不能运行。
使用 local 卷的应用程序必须能够容忍这种可用性的降低,以及因底层磁盘的耐用性特征而带来的潜在的数据丢失风险。
下面是一个使用 local 卷和 nodeAffinity 的持久卷示例:
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
spec:
capacity:
storage: 100Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- example-node
使用 local 卷时,你需要设置 PersistentVolume 对象的 nodeAffinity 字段。
Kubernetes 调度器使用 PersistentVolume 的 nodeAffinity 信息来将使用 local
卷的 Pod 调度到正确的节点。
PersistentVolume 对象的 volumeMode 字段可被设置为 "Block"
(而不是默认值 "Filesystem"),以将 local 卷作为原始块设备暴露出来。
使用 local 卷时,建议创建一个 StorageClass 并将其 volumeBindingMode 设置为
WaitForFirstConsumer。要了解更多详细信息,请参考
local StorageClass 示例。
延迟卷绑定的操作可以确保 Kubernetes 在为 PersistentVolumeClaim 作出绑定决策时,会评估
Pod 可能具有的其他节点约束,例如:如节点资源需求、节点选择器、Pod 亲和性和 Pod 反亲和性。
你可以在 Kubernetes 之外单独运行静态驱动以改进对 local 卷的生命周期管理。
请注意,此驱动尚不支持动态配置。
有关如何运行外部 local 卷驱动,请参考
local 卷驱动用户指南。
说明:
如果不使用外部静态驱动来管理卷的生命周期,用户需要手动清理和删除 local 类型的持久卷。
nfs
nfs 卷能将 NFS (网络文件系统) 挂载到你的 Pod 中。
不像 emptyDir 那样会在删除 Pod 的同时也会被删除,nfs 卷的内容在删除 Pod
时会被保存,卷只是被卸载。
这意味着 nfs 卷可以被预先填充数据,并且这些数据可以在 Pod 之间共享。
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /my-nfs-data
name: test-volume
volumes:
- name: test-volume
nfs:
server: my-nfs-server.example.com
path: /my-nfs-volume
readOnly: true
说明:
在使用 NFS 卷之前,你必须运行自己的 NFS 服务器并将目标 share 导出备用。
还需要注意,不能在 Pod spec 中指定 NFS 挂载可选项。 可以选择设置服务端的挂载可选项,或者使用 /etc/nfsmount.conf。 此外,还可以通过允许设置挂载可选项的持久卷挂载 NFS 卷。
如需了解用持久卷挂载 NFS 卷的示例,请参考 NFS 示例。
persistentVolumeClaim
persistentVolumeClaim 卷用来将持久卷(PersistentVolume)挂载到 Pod 中。
持久卷申领(PersistentVolumeClaim)是用户在不知道特定云环境细节的情况下“申领”持久存储(例如 iSCSI 卷)的一种方法。
更多详情请参考持久卷。
portworxVolume(已弃用)
特性状态:
Kubernetes v1.25 [deprecated]
portworxVolume 是一个可伸缩的块存储层,能够以超融合(hyperconverged)的方式与 Kubernetes 一起运行。
Portworx
支持对服务器上存储的指纹处理、基于存储能力进行分层以及跨多个服务器整合存储容量。
Portworx 可以以 in-guest 方式在虚拟机中运行,也可以在裸金属 Linux 节点上运行。
portworxVolume 类型的卷可以通过 Kubernetes 动态创建,也可以预先配备并在 Pod 内引用。
下面是一个引用预先配备的 Portworx 卷的示例 Pod:
apiVersion: v1
kind: Pod
metadata:
name: test-portworx-volume-pod
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /mnt
name: pxvol
volumes:
- name: pxvol
# 此 Portworx 卷必须已经存在
portworxVolume:
volumeID: "pxvol"
fsType: "<fs-type>"
说明:
在 Pod 中使用 portworxVolume 之前,你要确保有一个名为 pxvol 的 PortworxVolume 存在。
更多详情可以参考 Portworx 卷。
Portworx CSI 迁移
特性状态:
Kubernetes v1.25 [beta]
已针对 Portworx 添加 CSIMigration 特性,但在 Kubernetes 1.23 中默认禁用,因为它处于 Alpha 状态。
自 v1.25 以来它已进入 Beta 阶段,但默认仍关闭。
它将所有插件操作不再指向树内插件(In-Tree Plugin),转而指向
pxd.portworx.com 容器存储接口(Container Storage Interface,CSI)驱动。
Portworx CSI 驱动程序必须安装在集群上。
要启用此特性,需在 kube-controller-manager 和 kubelet 中设置 CSIMigrationPortworx=true。
投射(projected)
投射卷能将若干现有的卷来源映射到同一目录上。更多详情请参考投射卷。
rbd
特性状态:
Kubernetes v1.28 [deprecated]
说明:
Kubernetes 项目建议你转为以 RBD 模式使用 Ceph CSI 第三方存储驱动插件。
rbd 卷允许将 Rados 块设备卷挂载到你的 Pod 中。
不像 emptyDir 那样会在删除 Pod 的同时也会被删除,rbd 卷的内容在删除 Pod 时会被保存,卷只是被卸载。
这意味着 rbd 卷可以被预先填充数据,并且这些数据可以在 Pod 之间共享。
说明:
在使用 RBD 之前,你必须安装运行 Ceph。
RBD 的一个特性是它可以同时被多个用户以只读方式挂载。 这意味着你可以用数据集预先填充卷,然后根据需要在尽可能多的 Pod 中并行地使用卷。 不幸的是,RBD 卷只能由单个使用者以读写模式安装。不允许同时写入。
更多详情请参考 RBD 示例。
RBD CSI 迁移
特性状态:
Kubernetes v1.28 [deprecated]
启用 RBD 的 CSIMigration 特性后,所有插件操作从现有的树内插件重定向到
rbd.csi.ceph.com CSI 驱动程序。
要使用该特性,必须在集群内安装
Ceph CSI 驱动,并启用 csiMigrationRBD
特性门控。
(请注意,csiMigrationRBD 标志已在 v1.24 版本中移除且替换为 CSIMigrationRBD。)
说明:
作为一位管理存储的 Kubernetes 集群操作者,在尝试迁移到 RBD CSI 驱动前,你必须完成下列先决事项:
- 你必须在集群中安装 v3.5.0 或更高版本的 Ceph CSI 驱动(
rbd.csi.ceph.com)。 - 因为
clusterID是 CSI 驱动程序必需的参数,而树内存储类又将monitors作为一个必需的参数,所以 Kubernetes 存储管理者需要根据monitors的哈希值(例如:#echo -n '<monitors_string>' | md5sum)来创建clusterID,并保持该monitors存在于该clusterID的配置中。 - 同时,如果树内存储类的
adminId的值不是admin,那么其adminSecretName就需要被修改成adminId参数的 base64 编码值。
secret
secret 卷用来给 Pod 传递敏感信息,例如密码。你可以将 Secret 存储在 Kubernetes
API 服务器上,然后以文件的形式挂载到 Pod 中,无需直接与 Kubernetes 耦合。
secret 卷由 tmpfs(基于 RAM 的文件系统)提供存储,因此它们永远不会被写入非易失性(持久化的)存储器。
说明:
- 使用前你必须在 Kubernetes API 中创建 Secret。
- Secret 总是以
readOnly的模式挂载。 - 容器以
subPath卷挂载方式使用 Secret 时,将无法接收 Secret 的更新。
更多详情请参考配置 Secrets。
vsphereVolume(已弃用)
说明:
Kubernetes 项目建议转为使用 vSphere CSI 树外存储驱动。
vsphereVolume 用来将 vSphere VMDK 卷挂载到你的 Pod 中。
在卸载卷时,卷的内容会被保留。
vSphereVolume 卷类型支持 VMFS 和 VSAN 数据仓库。
进一步信息可参考 vSphere 卷。
vSphere CSI 迁移
特性状态:
Kubernetes v1.26 [stable]
在 Kubernetes 1.29 中,对树内 vsphereVolume
类的所有操作都会被重定向至 csi.vsphere.vmware.com CSI 驱动程序。
vSphere CSI 驱动必须安装到集群上。
你可以在 VMware 的文档页面迁移树内 vSphere 卷插件到 vSphere 容器存储插件
中找到有关如何迁移树内 vsphereVolume 的其他建议。
如果未安装 vSphere CSI 驱动程序,则无法对由树内 vsphereVolume 类型创建的 PV 执行卷操作。
你必须运行 vSphere 7.0u2 或更高版本才能迁移到 vSphere CSI 驱动程序。
如果你正在运行 Kubernetes v1.29,请查阅该 Kubernetes 版本的文档。
说明:
vSphere CSI 驱动不支持内置 vsphereVolume 的以下 StorageClass 参数:
diskformathostfailurestotolerateforceprovisioningcachereservationdiskstripesobjectspacereservationiopslimit
使用这些参数创建的现有卷将被迁移到 vSphere CSI 驱动,不过使用 vSphere CSI 驱动所创建的新卷都不会理会这些参数。
vSphere CSI 迁移完成
特性状态:
Kubernetes v1.19 [beta]
为了避免控制器管理器和 kubelet 加载 vsphereVolume 插件,你需要将
InTreePluginvSphereUnregister 特性设置为 true。你还必须在所有工作节点上安装
csi.vsphere.vmware.com CSI 驱动。
使用 subPath
有时,在单个 Pod 中共享卷以供多方使用是很有用的。
volumeMounts.subPath 属性可用于指定所引用的卷内的子路径,而不是其根路径。
下面例子展示了如何配置某包含 LAMP 堆栈(Linux Apache MySQL PHP)的 Pod 使用同一共享卷。
此示例中的 subPath 配置不建议在生产环境中使用。
PHP 应用的代码和相关数据映射到卷的 html 文件夹,MySQL 数据库存储在卷的 mysql 文件夹中:
apiVersion: v1
kind: Pod
metadata:
name: my-lamp-site
spec:
containers:
- name: mysql
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "rootpasswd"
volumeMounts:
- mountPath: /var/lib/mysql
name: site-data
subPath: mysql
- name: php
image: php:7.0-apache
volumeMounts:
- mountPath: /var/www/html
name: site-data
subPath: html
volumes:
- name: site-data
persistentVolumeClaim:
claimName: my-lamp-site-data
使用带有扩展环境变量的 subPath
特性状态:
Kubernetes v1.17 [stable]
使用 subPathExpr 字段可以基于 downward API 环境变量来构造 subPath 目录名。
subPath 和 subPathExpr 属性是互斥的。
在这个示例中,Pod 使用 subPathExpr 来 hostPath 卷 /var/log/pods 中创建目录 pod1。
hostPath 卷采用来自 downwardAPI 的 Pod 名称生成目录名。
宿主机目录 /var/log/pods/pod1 被挂载到容器的 /logs 中。
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: container1
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
image: busybox:1.28
command: [ "sh", "-c", "while [ true ]; do echo 'Hello'; sleep 10; done | tee -a /logs/hello.txt" ]
volumeMounts:
- name: workdir1
mountPath: /logs
# 包裹变量名的是小括号,而不是大括号
subPathExpr: $(POD_NAME)
restartPolicy: Never
volumes:
- name: workdir1
hostPath:
path: /var/log/pods
资源
emptyDir 卷的存储介质(例如磁盘、SSD 等)是由保存 kubelet
数据的根目录(通常是 /var/lib/kubelet)的文件系统的介质确定。
Kubernetes 对 emptyDir 卷或者 hostPath 卷可以消耗的空间没有限制,容器之间或 Pod 之间也没有隔离。
要了解如何使用资源规约来请求空间, 可参考如何管理资源。
树外(Out-of-Tree)卷插件
Out-of-Tree 卷插件包括容器存储接口(CSI)和 FlexVolume(已弃用)。它们使存储供应商能够创建自定义存储插件,而无需将插件源码添加到 Kubernetes 代码仓库。
以前,所有卷插件(如上面列出的卷类型)都是“树内(In-Tree)”的。 “树内”插件是与 Kubernetes 的核心组件一同构建、链接、编译和交付的。 这意味着向 Kubernetes 添加新的存储系统(卷插件)需要将代码合并到 Kubernetes 核心代码库中。
CSI 和 FlexVolume 都允许独立于 Kubernetes 代码库开发卷插件,并作为扩展部署(安装)在 Kubernetes 集群上。
对于希望创建树外(Out-Of-Tree)卷插件的存储供应商, 请参考卷插件常见问题。
CSI
容器存储接口 (CSI) 为容器编排系统(如 Kubernetes)定义标准接口,以将任意存储系统暴露给它们的容器工作负载。
更多详情请阅读 CSI 设计方案。
说明:
Kubernetes v1.13 废弃了对 CSI 规范版本 0.2 和 0.3 的支持,并将在以后的版本中删除。
说明:
CSI 驱动可能并非兼容所有的 Kubernetes 版本。 请查看特定 CSI 驱动的文档,以了解各个 Kubernetes 版本所支持的部署步骤以及兼容性列表。
一旦在 Kubernetes 集群上部署了 CSI 兼容卷驱动程序,用户就可以使用
csi 卷类型来挂接、挂载 CSI 驱动所提供的卷。
csi 卷可以在 Pod 中以三种方式使用:
- 通过 PersistentVolumeClaim 对象引用
- 使用一般性的临时卷
- 使用 CSI 临时卷, 前提是驱动支持这种用法
存储管理员可以使用以下字段来配置 CSI 持久卷:
driver:指定要使用的卷驱动名称的字符串值。 这个值必须与 CSI 驱动程序在GetPluginInfoResponse中返回的值相对应;该接口定义在 CSI 规范中。 Kubernetes 使用所给的值来标识要调用的 CSI 驱动程序;CSI 驱动程序也使用该值来辨识哪些 PV 对象属于该 CSI 驱动程序。
volumeHandle:唯一标识卷的字符串值。 该值必须与 CSI 驱动在CreateVolumeResponse的volume_id字段中返回的值相对应;接口定义在 CSI 规范 中。 在所有对 CSI 卷驱动程序的调用中,引用该 CSI 卷时都使用此值作为volume_id参数。
readOnly:一个可选的布尔值,指示通过ControllerPublished关联该卷时是否设置该卷为只读。默认值是 false。 该值通过ControllerPublishVolumeRequest中的readonly字段传递给 CSI 驱动。
fsType:如果 PV 的VolumeMode为Filesystem,那么此字段指定挂载卷时应该使用的文件系统。 如果卷尚未格式化,并且支持格式化,此值将用于格式化卷。 此值可以通过ControllerPublishVolumeRequest、NodeStageVolumeRequest和NodePublishVolumeRequest的VolumeCapability字段传递给 CSI 驱动。
volumeAttributes:一个字符串到字符串的映射表,用来设置卷的静态属性。 该映射必须与 CSI 驱动程序返回的CreateVolumeResponse中的volume.attributes字段的映射相对应; CSI 规范中有相应的定义。 该映射通过ControllerPublishVolumeRequest、NodeStageVolumeRequest和NodePublishVolumeRequest中的volume_context字段传递给 CSI 驱动。
controllerPublishSecretRef:对包含敏感信息的 Secret 对象的引用; 该敏感信息会被传递给 CSI 驱动来完成 CSIControllerPublishVolume和ControllerUnpublishVolume调用。 此字段是可选的;在不需要 Secret 时可以是空的。 如果 Secret 包含多个 Secret 条目,则所有的 Secret 条目都会被传递。
nodeExpandSecretRef:对包含敏感信息的 Secret 对象的引用, 该信息会传递给 CSI 驱动以完成 CSINodeExpandVolume调用。 此字段是可选的,如果不需要 Secret,则可能是空的。 如果 Secret 包含多个 Secret 条目,则传递所有 Secret 条目。 当你为节点初始化的卷扩展配置 Secret 数据时,kubelet 会通过NodeExpandVolume()调用将该数据传递给 CSI 驱动。为了使用nodeExpandSecretRef字段, 你的集群应运行 Kubernetes 1.25 或更高版本, 如果你所运行的 Kubernetes 是 1.25 或 1.26,你必须为每个 kube-apiserver 和每个节点上的 kubelet 启用名为CSINodeExpandSecret的特性门控。 在 Kubernetes 1.27 版本中,此特性已默认启用,无需显式启用特性门控。 在节点初始化的存储大小调整操作期间,你还必须使用支持或需要 Secret 数据的 CSI 驱动。
nodePublishSecretRef:对包含敏感信息的 Secret 对象的引用。 该信息传递给 CSI 驱动来完成 CSINodePublishVolume调用。 此字段是可选的,如果不需要 Secret,则可能是空的。 如果 Secret 对象包含多个 Secret 条目,则传递所有 Secret 条目。
nodeStageSecretRef:对包含敏感信息的 Secret 对象的引用, 该信息会传递给 CSI 驱动以完成 CSINodeStageVolume调用。 此字段是可选的,如果不需要 Secret,则可能是空的。 如果 Secret 包含多个 Secret 条目,则传递所有 Secret 条目。
CSI 原始块卷支持
特性状态:
Kubernetes v1.18 [stable]
具有外部 CSI 驱动程序的供应商能够在 Kubernetes 工作负载中实现原始块卷支持。
你可以和以前一样, 安装自己的带有原始块卷支持的 PV/PVC, 采用 CSI 对此过程没有影响。
CSI 临时卷
特性状态:
Kubernetes v1.25 [stable]
你可以直接在 Pod 规约中配置 CSI 卷。采用这种方式配置的卷都是临时卷, 无法在 Pod 重新启动后继续存在。 进一步的信息可参阅临时卷。
有关如何开发 CSI 驱动的更多信息,请参考 kubernetes-csi 文档。
Windows CSI 代理
特性状态:
Kubernetes v1.22 [stable]
CSI 节点插件需要执行多种特权操作,例如扫描磁盘设备和挂载文件系统等。 这些操作在每个宿主机操作系统上都是不同的。对于 Linux 工作节点而言,容器化的 CSI 节点插件通常部署为特权容器。对于 Windows 工作节点而言,容器化 CSI 节点插件的特权操作是通过 csi-proxy 来支持的。csi-proxy 是一个由社区管理的、独立的可执行二进制文件, 需要被预安装到每个 Windows 节点上。
要了解更多的细节,可以参考你要部署的 CSI 插件的部署指南。
从树内插件迁移到 CSI 驱动程序
特性状态:
Kubernetes v1.25 [stable]
CSIMigration 特性针对现有树内插件的操作会被定向到相应的 CSI 插件(应已安装和配置)。
因此,操作员在过渡到取代树内插件的 CSI 驱动时,无需对现有存储类、PV 或 PVC(指树内插件)进行任何配置更改。
所支持的操作和特性包括:配备(Provisioning)/删除、挂接(Attach)/解挂(Detach)、 挂载(Mount)/卸载(Unmount)和调整卷大小。
上面的卷类型节列出了支持 CSIMigration 并已实现相应 CSI
驱动程序的树内插件。
下面是支持 Windows 节点上持久性存储的树内插件:
flexVolume(已弃用)
特性状态:
Kubernetes v1.23 [deprecated]
FlexVolume 是一个使用基于 exec 的模型来与驱动程序对接的树外插件接口。 用户必须在每个节点上的预定义卷插件路径中安装 FlexVolume 驱动程序可执行文件,在某些情况下,控制平面节点中也要安装。
Pod 通过 flexvolume 树内插件与 FlexVolume 驱动程序交互。
更多详情请参考 FlexVolume
README 文档。
下面的 FlexVolume 插件 以 PowerShell 脚本的形式部署在宿主机系统上,支持 Windows 节点:
说明:
FlexVolume 已被弃用。推荐使用树外 CSI 驱动来将外部存储整合进 Kubernetes。
FlexVolume 驱动的维护者应开发一个 CSI 驱动并帮助用户从 FlexVolume 驱动迁移到 CSI。 FlexVolume 用户应迁移工作负载以使用对等的 CSI 驱动。
挂载卷的传播
挂载卷的传播能力允许将容器安装的卷共享到同一 Pod 中的其他容器,甚至共享到同一节点上的其他 Pod。
卷的挂载传播特性由 Container.volumeMounts 中的 mountPropagation 字段控制。
它的值包括:
-
None- 此卷挂载将不会感知到主机后续在此卷或其任何子目录上执行的挂载变化。 类似的,容器所创建的卷挂载在主机上是不可见的。这是默认模式。该模式等同于
mount(8)中描述的rprivate挂载传播选项。然而,当
rprivate传播选项不适用时,CRI 运行时可以转为选择rslave挂载传播选项 (即HostToContainer)。当挂载源包含 Docker 守护进程的根目录(/var/lib/docker)时, cri-dockerd (Docker) 已知可以选择rslave挂载传播选项。
-
HostToContainer- 此卷挂载将会感知到主机后续针对此卷或其任何子目录的挂载操作。换句话说,如果主机在此挂载卷中挂载任何内容,容器将能看到它被挂载在那里。
类似的,配置了
Bidirectional挂载传播选项的 Pod 如果在同一卷上挂载了内容,挂载传播设置为HostToContainer的容器都将能看到这一变化。该模式等同于
mount(8)中描述的rslave挂载传播选项。
-
Bidirectional- 这种卷挂载和HostToContainer挂载表现相同。 另外,容器创建的卷挂载将被传播回至主机和使用同一卷的所有 Pod 的所有容器。该模式等同于
mount(8)中描述的rshared挂载传播选项。警告:Bidirectional形式的挂载传播可能比较危险。 它可以破坏主机操作系统,因此它只被允许在特权容器中使用。 强烈建议你熟悉 Linux 内核行为。 此外,由 Pod 中的容器创建的任何卷挂载必须在终止时由容器销毁(卸载)。
接下来
6.2 - 持久卷
本文描述 Kubernetes 中的持久卷(Persistent Volumes)。 建议先熟悉卷(volume)、 存储类(StorageClass)和 卷属性类(VolumeAttributesClass)。
介绍
存储的管理是一个与计算实例的管理完全不同的问题。 PersistentVolume 子系统为用户和管理员提供了一组 API, 将存储如何制备的细节从其如何被使用中抽象出来。 为了实现这点,我们引入了两个新的 API 资源:PersistentVolume 和 PersistentVolumeClaim。
持久卷(PersistentVolume,PV) 是集群中的一块存储,可以由管理员事先制备, 或者使用存储类(Storage Class)来动态制备。 持久卷是集群资源,就像节点也是集群资源一样。PV 持久卷和普通的 Volume 一样, 也是使用卷插件来实现的,只是它们拥有独立于任何使用 PV 的 Pod 的生命周期。 此 API 对象中记述了存储的实现细节,无论其背后是 NFS、iSCSI 还是特定于云平台的存储系统。
持久卷申领(PersistentVolumeClaim,PVC) 表达的是用户对存储的请求。概念上与 Pod 类似。 Pod 会耗用节点资源,而 PVC 申领会耗用 PV 资源。Pod 可以请求特定数量的资源(CPU 和内存)。同样 PVC 申领也可以请求特定的大小和访问模式 (例如,可以挂载为 ReadWriteOnce、ReadOnlyMany、ReadWriteMany 或 ReadWriteOncePod, 请参阅访问模式)。
尽管 PersistentVolumeClaim 允许用户消耗抽象的存储资源, 常见的情况是针对不同的问题用户需要的是具有不同属性(如,性能)的 PersistentVolume 卷。 集群管理员需要能够提供不同性质的 PersistentVolume, 并且这些 PV 卷之间的差别不仅限于卷大小和访问模式,同时又不能将卷是如何实现的这些细节暴露给用户。 为了满足这类需求,就有了存储类(StorageClass) 资源。
参见基于运行示例的详细演练。
卷和申领的生命周期
PV 卷是集群中的资源。PVC 申领是对这些资源的请求,也被用来执行对资源的申领检查。 PV 卷和 PVC 申领之间的互动遵循如下生命周期:
制备
PV 卷的制备有两种方式:静态制备或动态制备。
静态制备
集群管理员创建若干 PV 卷。这些卷对象带有真实存储的细节信息, 并且对集群用户可用(可见)。PV 卷对象存在于 Kubernetes API 中,可供用户消费(使用)。
动态制备
如果管理员所创建的所有静态 PV 卷都无法与用户的 PersistentVolumeClaim 匹配,
集群可以尝试为该 PVC 申领动态制备一个存储卷。
这一制备操作是基于 StorageClass 来实现的:PVC 申领必须请求某个
存储类,
同时集群管理员必须已经创建并配置了该类,这样动态制备卷的动作才会发生。
如果 PVC 申领指定存储类为 "",则相当于为自身禁止使用动态制备的卷。
为了基于存储类完成动态的存储制备,集群管理员需要在 API 服务器上启用 DefaultStorageClass
准入控制器。
举例而言,可以通过保证 DefaultStorageClass 出现在 API 服务器组件的
--enable-admission-plugins 标志值中实现这点;该标志的值可以是逗号分隔的有序列表。
关于 API 服务器标志的更多信息,可以参考
kube-apiserver
文档。
绑定
用户创建一个带有特定存储容量和特定访问模式需求的 PersistentVolumeClaim 对象; 在动态制备场景下,这个 PVC 对象可能已经创建完毕。 控制平面中的控制回路监测新的 PVC 对象,寻找与之匹配的 PV 卷(如果可能的话), 并将二者绑定到一起。 如果为了新的 PVC 申领动态制备了 PV 卷,则控制回路总是将该 PV 卷绑定到这一 PVC 申领。 否则,用户总是能够获得他们所请求的资源,只是所获得的 PV 卷可能会超出所请求的配置。 一旦绑定关系建立,则 PersistentVolumeClaim 绑定就是排他性的, 无论该 PVC 申领是如何与 PV 卷建立的绑定关系。 PVC 申领与 PV 卷之间的绑定是一种一对一的映射,实现上使用 ClaimRef 来记述 PV 卷与 PVC 申领间的双向绑定关系。
如果找不到匹配的 PV 卷,PVC 申领会无限期地处于未绑定状态。 当与之匹配的 PV 卷可用时,PVC 申领会被绑定。 例如,即使某集群上制备了很多 50 Gi 大小的 PV 卷,也无法与请求 100 Gi 大小的存储的 PVC 匹配。当新的 100 Gi PV 卷被加入到集群时, 该 PVC 才有可能被绑定。
使用
Pod 将 PVC 申领当做存储卷来使用。集群会检视 PVC 申领,找到所绑定的卷, 并为 Pod 挂载该卷。对于支持多种访问模式的卷, 用户要在 Pod 中以卷的形式使用申领时指定期望的访问模式。
一旦用户有了申领对象并且该申领已经被绑定,
则所绑定的 PV 卷在用户仍然需要它期间一直属于该用户。
用户通过在 Pod 的 volumes 块中包含 persistentVolumeClaim
节区来调度 Pod,访问所申领的 PV 卷。
相关细节可参阅使用申领作为卷。
保护使用中的存储对象
保护使用中的存储对象(Storage Object in Use Protection) 这一功能特性的目的是确保仍被 Pod 使用的 PersistentVolumeClaim(PVC) 对象及其所绑定的 PersistentVolume(PV)对象在系统中不会被删除,因为这样做可能会引起数据丢失。
说明:
当使用某 PVC 的 Pod 对象仍然存在时,认为该 PVC 仍被此 Pod 使用。
如果用户删除被某 Pod 使用的 PVC 对象,该 PVC 申领不会被立即移除。 PVC 对象的移除会被推迟,直至其不再被任何 Pod 使用。 此外,如果管理员删除已绑定到某 PVC 申领的 PV 卷,该 PV 卷也不会被立即移除。 PV 对象的移除也要推迟到该 PV 不再绑定到 PVC。
你可以看到当 PVC 的状态为 Terminating 且其 Finalizers 列表中包含
kubernetes.io/pvc-protection 时,PVC 对象是处于被保护状态的。
kubectl describe pvc hostpath
Name: hostpath
Namespace: default
StorageClass: example-hostpath
Status: Terminating
Volume:
Labels: <none>
Annotations: volume.beta.kubernetes.io/storage-class=example-hostpath
volume.beta.kubernetes.io/storage-provisioner=example.com/hostpath
Finalizers: [kubernetes.io/pvc-protection]
...
你也可以看到当 PV 对象的状态为 Terminating 且其 Finalizers 列表中包含
kubernetes.io/pv-protection 时,PV 对象是处于被保护状态的。
kubectl describe pv task-pv-volume
Name: task-pv-volume
Labels: type=local
Annotations: <none>
Finalizers: [kubernetes.io/pv-protection]
StorageClass: standard
Status: Terminating
Claim:
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1Gi
Message:
Source:
Type: HostPath (bare host directory volume)
Path: /tmp/data
HostPathType:
Events: <none>
回收(Reclaiming)
当用户不再使用其存储卷时,他们可以从 API 中将 PVC 对象删除, 从而允许该资源被回收再利用。PersistentVolume 对象的回收策略告诉集群, 当其被从申领中释放时如何处理该数据卷。 目前,数据卷可以被 Retained(保留)、Recycled(回收)或 Deleted(删除)。
保留(Retain)
回收策略 Retain 使得用户可以手动回收资源。当 PersistentVolumeClaim
对象被删除时,PersistentVolume 卷仍然存在,对应的数据卷被视为"已释放(released)"。
由于卷上仍然存在这前一申领人的数据,该卷还不能用于其他申领。
管理员可以通过下面的步骤来手动回收该卷:
- 删除 PersistentVolume 对象。与之相关的、位于外部基础设施中的存储资产在 PV 删除之后仍然存在。
- 根据情况,手动清除所关联的存储资产上的数据。
- 手动删除所关联的存储资产。
如果你希望重用该存储资产,可以基于存储资产的定义创建新的 PersistentVolume 卷对象。
删除(Delete)
对于支持 Delete 回收策略的卷插件,删除动作会将 PersistentVolume 对象从
Kubernetes 中移除,同时也会从外部基础设施中移除所关联的存储资产。
动态制备的卷会继承其 StorageClass 中设置的回收策略,
该策略默认为 Delete。管理员需要根据用户的期望来配置 StorageClass;
否则 PV 卷被创建之后必须要被编辑或者修补。
参阅更改 PV 卷的回收策略。
回收(Recycle)
警告:
回收策略 Recycle 已被废弃。取而代之的建议方案是使用动态制备。
如果下层的卷插件支持,回收策略 Recycle 会在卷上执行一些基本的擦除
(rm -rf /thevolume/*)操作,之后允许该卷用于新的 PVC 申领。
不过,管理员可以按参考资料中所述,
使用 Kubernetes 控制器管理器命令行参数来配置一个定制的回收器(Recycler)
Pod 模板。此定制的回收器 Pod 模板必须包含一个 volumes 规约,如下例所示:
apiVersion: v1
kind: Pod
metadata:
name: pv-recycler
namespace: default
spec:
restartPolicy: Never
volumes:
- name: vol
hostPath:
path: /any/path/it/will/be/replaced
containers:
- name: pv-recycler
image: "registry.k8s.io/busybox"
command: ["/bin/sh", "-c", "test -e /scrub && rm -rf /scrub/..?* /scrub/.[!.]* /scrub/* && test -z \"$(ls -A /scrub)\" || exit 1"]
volumeMounts:
- name: vol
mountPath: /scrub
定制回收器 Pod 模板中在 volumes 部分所指定的特定路径要替换为正被回收的卷的路径。
PersistentVolume 删除保护 finalizer
特性状态:
Kubernetes v1.23 [alpha]
可以在 PersistentVolume 上添加终结器(Finalizer),
以确保只有在删除对应的存储后才删除具有 Delete 回收策略的 PersistentVolume。
新引入的 kubernetes.io/pv-controller 和 external-provisioner.volume.kubernetes.io/finalizer
终结器仅会被添加到动态制备的卷上。
终结器 kubernetes.io/pv-controller 会被添加到树内插件卷上。
下面是一个例子:
kubectl describe pv pvc-74a498d6-3929-47e8-8c02-078c1ece4d78
Name: pvc-74a498d6-3929-47e8-8c02-078c1ece4d78
Labels: <none>
Annotations: kubernetes.io/createdby: vsphere-volume-dynamic-provisioner
pv.kubernetes.io/bound-by-controller: yes
pv.kubernetes.io/provisioned-by: kubernetes.io/vsphere-volume
Finalizers: [kubernetes.io/pv-protection kubernetes.io/pv-controller]
StorageClass: vcp-sc
Status: Bound
Claim: default/vcp-pvc-1
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 1Gi
Node Affinity: <none>
Message:
Source:
Type: vSphereVolume (a Persistent Disk resource in vSphere)
VolumePath: [vsanDatastore] d49c4a62-166f-ce12-c464-020077ba5d46/kubernetes-dynamic-pvc-74a498d6-3929-47e8-8c02-078c1ece4d78.vmdk
FSType: ext4
StoragePolicyName: vSAN Default Storage Policy
Events: <none>
终结器 external-provisioner.volume.kubernetes.io/finalizer 会被添加到 CSI 卷上。下面是一个例子:
Name: pvc-2f0bab97-85a8-4552-8044-eb8be45cf48d
Labels: <none>
Annotations: pv.kubernetes.io/provisioned-by: csi.vsphere.vmware.com
Finalizers: [kubernetes.io/pv-protection external-provisioner.volume.kubernetes.io/finalizer]
StorageClass: fast
Status: Bound
Claim: demo-app/nginx-logs
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 200Mi
Node Affinity: <none>
Message:
Source:
Type: CSI (a Container Storage Interface (CSI) volume source)
Driver: csi.vsphere.vmware.com
FSType: ext4
VolumeHandle: 44830fa8-79b4-406b-8b58-621ba25353fd
ReadOnly: false
VolumeAttributes: storage.kubernetes.io/csiProvisionerIdentity=1648442357185-8081-csi.vsphere.vmware.com
type=vSphere CNS Block Volume
Events: <none>
当为特定的树内卷插件启用了 CSIMigration{provider} 特性标志时,kubernetes.io/pv-controller
终结器将被替换为 external-provisioner.volume.kubernetes.io/finalizer 终结器。
预留 PersistentVolume
控制平面可以在集群中将 PersistentVolumeClaims 绑定到匹配的 PersistentVolumes。 但是,如果你希望 PVC 绑定到特定 PV,则需要预先绑定它们。
通过在 PersistentVolumeClaim 中指定 PersistentVolume,你可以声明该特定
PV 与 PVC 之间的绑定关系。如果该 PersistentVolume 存在且未被通过其
claimRef 字段预留给 PersistentVolumeClaim,则该 PersistentVolume
会和该 PersistentVolumeClaim 绑定到一起。
绑定操作不会考虑某些卷匹配条件是否满足,包括节点亲和性等等。 控制面仍然会检查存储类、 访问模式和所请求的存储尺寸都是合法的。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc
namespace: foo
spec:
storageClassName: "" # 此处须显式设置空字符串,否则会被设置为默认的 StorageClass
volumeName: foo-pv
...
此方法无法对 PersistentVolume 的绑定特权做出任何形式的保证。
如果有其他 PersistentVolumeClaim 可以使用你所指定的 PV,
则你应该首先预留该存储卷。你可以将 PV 的 claimRef 字段设置为相关的
PersistentVolumeClaim 以确保其他 PVC 不会绑定到该 PV 卷。
apiVersion: v1
kind: PersistentVolume
metadata:
name: foo-pv
spec:
storageClassName: ""
claimRef:
name: foo-pvc
namespace: foo
...
如果你想要使用 persistentVolumeReclaimPolicy 属性设置为 Retain 的 PersistentVolume 卷时,
包括你希望复用现有的 PV 卷时,这点是很有用的
扩充 PVC 申领
特性状态:
Kubernetes v1.24 [stable]
现在,对扩充 PVC 申领的支持默认处于被启用状态。你可以扩充以下类型的卷:
- azureFile(已弃用)
- csi
- flexVolume(已弃用)
- rbd
- portworxVolume(已弃用)
只有当 PVC 的存储类中将 allowVolumeExpansion 设置为 true 时,你才可以扩充该 PVC 申领。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: example-vol-default
provisioner: vendor-name.example/magicstorage
parameters:
resturl: "http://192.168.10.100:8080"
restuser: ""
secretNamespace: ""
secretName: ""
allowVolumeExpansion: true
如果要为某 PVC 请求较大的存储卷,可以编辑 PVC 对象,设置一个更大的尺寸值。 这一编辑操作会触发为下层 PersistentVolume 提供存储的卷的扩充。 Kubernetes 不会创建新的 PV 卷来满足此申领的请求。 与之相反,现有的卷会被调整大小。
警告:
直接编辑 PersistentVolume 的大小可以阻止该卷自动调整大小。
如果对 PersistentVolume 的容量进行编辑,然后又将其所对应的
PersistentVolumeClaim 的 .spec 进行编辑,使该 PersistentVolumeClaim
的大小匹配 PersistentVolume 的话,则不会发生存储大小的调整。
Kubernetes 控制平面将看到两个资源的所需状态匹配,
并认为其后备卷的大小已被手动增加,无需调整。
CSI 卷的扩充
特性状态:
Kubernetes v1.24 [stable]
对 CSI 卷的扩充能力默认是被启用的,不过扩充 CSI 卷要求 CSI 驱动支持卷扩充操作。可参阅特定 CSI 驱动的文档了解更多信息。
重设包含文件系统的卷的大小
只有卷中包含的文件系统是 XFS、Ext3 或者 Ext4 时,你才可以重设卷的大小。
当卷中包含文件系统时,只有在 Pod 使用 ReadWrite 模式来使用 PVC
申领的情况下才能重设其文件系统的大小。文件系统扩充的操作或者是在 Pod
启动期间完成,或者在下层文件系统支持在线扩充的前提下在 Pod 运行期间完成。
如果 FlexVolumes 的驱动将 RequiresFSResize 能力设置为 true,
则该 FlexVolume 卷(于 Kubernetes v1.23 弃用)可以在 Pod 重启期间调整大小。
重设使用中 PVC 申领的大小
特性状态:
Kubernetes v1.24 [stable]
在这种情况下,你不需要删除和重建正在使用某现有 PVC 的 Pod 或 Deployment。 所有使用中的 PVC 在其文件系统被扩充之后,立即可供其 Pod 使用。 此功能特性对于没有被 Pod 或 Deployment 使用的 PVC 而言没有效果。 你必须在执行扩展操作之前创建一个使用该 PVC 的 Pod。
与其他卷类型类似,FlexVolume 卷也可以在被 Pod 使用期间执行扩充操作。
说明:
FlexVolume 卷的重设大小只能在下层驱动支持重设大小的时候才可进行。
处理扩充卷过程中的失败
如果用户指定的新大小过大,底层存储系统无法满足,PVC 的扩展将不断重试, 直到用户或集群管理员采取一些措施。这种情况是不希望发生的,因此 Kubernetes 提供了以下从此类故障中恢复的方法。
如果扩充下层存储的操作失败,集群管理员可以手动地恢复 PVC 申领的状态并取消重设大小的请求。否则,在没有管理员干预的情况下, 控制器会反复重试重设大小的操作。
- 将绑定到 PVC 申领的 PV 卷标记为
Retain回收策略。 - 删除 PVC 对象。由于 PV 的回收策略为
Retain,我们不会在重建 PVC 时丢失数据。 - 删除 PV 规约中的
claimRef项,这样新的 PVC 可以绑定到该卷。 这一操作会使得 PV 卷变为 "可用(Available)"。 - 使用小于 PV 卷大小的尺寸重建 PVC,设置 PVC 的
volumeName字段为 PV 卷的名称。 这一操作将把新的 PVC 对象绑定到现有的 PV 卷。 - 不要忘记恢复 PV 卷上设置的回收策略。
特性状态:
Kubernetes v1.23 [alpha]
说明:
Kubernetes 从 1.23 版本开始将允许用户恢复失败的 PVC 扩展这一能力作为
Alpha 特性支持。RecoverVolumeExpansionFailure 必须被启用以允许使用此特性。
可参考特性门控
文档了解更多信息。
如果集群中的特性门控 RecoverVolumeExpansionFailure
已启用,在 PVC 的扩展发生失败时,你可以使用比先前请求的值更小的尺寸来重试扩展。
要使用一个更小的尺寸尝试请求新的扩展,请编辑该 PVC 的 .spec.resources
并选择一个比你之前所尝试的值更小的值。
如果由于容量限制而无法成功扩展至更高的值,这将很有用。
如果发生了这种情况,或者你怀疑可能发生了这种情况,
你可以通过指定一个在底层存储制备容量限制内的尺寸来重试扩展。
你可以通过查看 .status.allocatedResourceStatuses 以及 PVC 上的事件来监控调整大小操作的状态。
请注意,
尽管你可以指定比之前的请求更低的存储量,新值必须仍然高于 .status.capacity。
Kubernetes 不支持将 PVC 缩小到小于其当前的尺寸。
持久卷的类型
PV 持久卷是用插件的形式来实现的。Kubernetes 目前支持以下插件:
csi- 容器存储接口 (CSI)fc- Fibre Channel (FC) 存储hostPath- HostPath 卷 (仅供单节点测试使用;不适用于多节点集群;请尝试使用local卷作为替代)iscsi- iSCSI (SCSI over IP) 存储local- 节点上挂载的本地存储设备nfs- 网络文件系统 (NFS) 存储
以下的持久卷已被弃用。这意味着当前仍是支持的,但是 Kubernetes 将来的发行版会将其移除。
azureFile- Azure File (于 v1.21 弃用)flexVolume- FlexVolume (于 v1.23 弃用)portworxVolume- Portworx 卷 (于 v1.25 弃用)vsphereVolume- vSphere VMDK 卷 (于 v1.19 弃用)cephfs- CephFS 卷 (于 v1.28 弃用)rbd- Rados Block Device (RBD) 卷 (于 v1.28 弃用)
旧版本的 Kubernetes 仍支持这些“树内(In-Tree)”持久卷类型:
awsElasticBlockStore- AWS Elastic Block Store (EBS) (v1.27 开始不可用)azureDisk- Azure Disk (v1.27 开始不可用)cinder- Cinder (OpenStack block storage) (v1.27 开始不可用)photonPersistentDisk- Photon 控制器持久化盘。(从 v1.15 版本开始将不可用)scaleIO- ScaleIO 卷(v1.21 之后不可用)flocker- Flocker 存储 (v1.25 之后不可用)quobyte- Quobyte 卷 (v1.25 之后不可用)storageos- StorageOS 卷 (v1.25 之后不可用)
持久卷
每个 PV 对象都包含 spec 部分和 status 部分,分别对应卷的规约和状态。
PersistentVolume 对象的名称必须是合法的
DNS 子域名.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2
说明:
在集群中使用持久卷存储通常需要一些特定于具体卷类型的辅助程序。
在这个例子中,PersistentVolume 是 NFS 类型的,因此需要辅助程序 /sbin/mount.nfs
来支持挂载 NFS 文件系统。
容量
一般而言,每个 PV 卷都有确定的存储容量。
这是通过 PV 的 capacity 属性设置的,
该属性是一个量纲(Quantity)。
目前,存储大小是可以设置和请求的唯一资源。 未来可能会包含 IOPS、吞吐量等属性。
卷模式
特性状态:
Kubernetes v1.18 [stable]
针对 PV 持久卷,Kubernetes
支持两种卷模式(volumeModes):Filesystem(文件系统) 和 Block(块)。
volumeMode 是一个可选的 API 参数。
如果该参数被省略,默认的卷模式是 Filesystem。
volumeMode 属性设置为 Filesystem 的卷会被 Pod 挂载(Mount) 到某个目录。
如果卷的存储来自某块设备而该设备目前为空,Kuberneretes 会在第一次挂载卷之前在设备上创建文件系统。
你可以将 volumeMode 设置为 Block,以便将卷作为原始块设备来使用。
这类卷以块设备的方式交给 Pod 使用,其上没有任何文件系统。
这种模式对于为 Pod 提供一种使用最快可能方式来访问卷而言很有帮助,
Pod 和卷之间不存在文件系统层。另外,Pod 中运行的应用必须知道如何处理原始块设备。
关于如何在 Pod 中使用 volumeMode: Block 的卷,
可参阅原始块卷支持。
访问模式
PersistentVolume 卷可以用资源提供者所支持的任何方式挂载到宿主系统上。 如下表所示,提供者(驱动)的能力不同,每个 PV 卷的访问模式都会设置为对应卷所支持的模式值。 例如,NFS 可以支持多个读写客户,但是某个特定的 NFS PV 卷可能在服务器上以只读的方式导出。 每个 PV 卷都会获得自身的访问模式集合,描述的是特定 PV 卷的能力。
访问模式有:
ReadWriteOnce- 卷可以被一个节点以读写方式挂载。 ReadWriteOnce 访问模式仍然可以在同一节点上运行的多个 Pod 访问该卷。 对于单个 Pod 的访问,请参考 ReadWriteOncePod 访问模式。
ReadOnlyMany- 卷可以被多个节点以只读方式挂载。
ReadWriteMany- 卷可以被多个节点以读写方式挂载。
ReadWriteOncePod-
特性状态:卷可以被单个 Pod 以读写方式挂载。 如果你想确保整个集群中只有一个 Pod 可以读取或写入该 PVC, 请使用 ReadWriteOncePod 访问模式。
Kubernetes v1.29 [stable]
在命令行接口(CLI)中,访问模式也使用以下缩写形式:
- RWO - ReadWriteOnce
- ROX - ReadOnlyMany
- RWX - ReadWriteMany
- RWOP - ReadWriteOncePod
说明:
Kubernetes 使用卷访问模式来匹配 PersistentVolumeClaim 和 PersistentVolume。 在某些场合下,卷访问模式也会限制 PersistentVolume 可以挂载的位置。 卷访问模式并不会在存储已经被挂载的情况下为其实施写保护。 即使访问模式设置为 ReadWriteOnce、ReadOnlyMany 或 ReadWriteMany,它们也不会对卷形成限制。 例如,即使某个卷创建时设置为 ReadOnlyMany,也无法保证该卷是只读的。 如果访问模式设置为 ReadWriteOncePod,则卷会被限制起来并且只能挂载到一个 Pod 上。
重要提醒! 每个卷同一时刻只能以一种访问模式挂载,即使该卷能够支持多种访问模式。
| 卷插件 | ReadWriteOnce | ReadOnlyMany | ReadWriteMany | ReadWriteOncePod |
|---|---|---|---|---|
| AzureFile | ✓ | ✓ | ✓ | - |
| CephFS | ✓ | ✓ | ✓ | - |
| CSI | 取决于驱动 | 取决于驱动 | 取决于驱动 | 取决于驱动 |
| FC | ✓ | ✓ | - | - |
| FlexVolume | ✓ | ✓ | 取决于驱动 | - |
| GCEPersistentDisk | ✓ | ✓ | - | - |
| Glusterfs | ✓ | ✓ | ✓ | - |
| HostPath | ✓ | - | - | - |
| iSCSI | ✓ | ✓ | - | - |
| NFS | ✓ | ✓ | ✓ | - |
| RBD | ✓ | ✓ | - | - |
| VsphereVolume | ✓ | - | -(Pod 运行于同一节点上时可行) | - |
| PortworxVolume | ✓ | - | ✓ | - |
类
每个 PV 可以属于某个类(Class),通过将其 storageClassName 属性设置为某个
StorageClass 的名称来指定。
特定类的 PV 卷只能绑定到请求该类存储卷的 PVC 申领。
未设置 storageClassName 的 PV 卷没有类设定,只能绑定到那些没有指定特定存储类的 PVC 申领。
早前,Kubernetes 使用注解 volume.beta.kubernetes.io/storage-class 而不是
storageClassName 属性。这一注解目前仍然起作用,不过在将来的 Kubernetes
发布版本中该注解会被彻底废弃。
回收策略
目前的回收策略有:
- Retain -- 手动回收
- Recycle -- 简单擦除 (
rm -rf /thevolume/*) - Delete -- 删除存储卷
对于 Kubernetes 1.29 来说,只有
nfs 和 hostPath 卷类型支持回收(Recycle)。
挂载选项
Kubernetes 管理员可以指定持久卷被挂载到节点上时使用的附加挂载选项。
说明:
并非所有持久卷类型都支持挂载选项。
以下卷类型支持挂载选项:
azureFilecephfs(于 v1.28 中弃用)cinder(于 v1.18 中弃用)iscsinfsrbd(于 v1.28 中弃用)vsphereVolume
Kubernetes 不对挂载选项执行合法性检查。如果挂载选项是非法的,挂载就会失败。
早前,Kubernetes 使用注解 volume.beta.kubernetes.io/mount-options 而不是
mountOptions 属性。这一注解目前仍然起作用,不过在将来的 Kubernetes
发布版本中该注解会被彻底废弃。
节点亲和性
说明:
对大多数卷类型而言,你不需要设置节点亲和性字段。 你需要为 local 卷显式地设置此属性。
每个 PV 卷可以通过设置节点亲和性来定义一些约束,进而限制从哪些节点上可以访问此卷。
使用这些卷的 Pod 只会被调度到节点亲和性规则所选择的节点上执行。
要设置节点亲和性,配置 PV 卷 .spec 中的 nodeAffinity。
持久卷
API 参考关于该字段的更多细节。
阶段
每个持久卷会处于以下阶段(Phase)之一:
Available- 卷是一个空闲资源,尚未绑定到任何申领
Bound- 该卷已经绑定到某申领
Released- 所绑定的申领已被删除,但是关联存储资源尚未被集群回收
Failed- 卷的自动回收操作失败
你可以使用 kubectl describe persistentvolume <name> 查看已绑定到 PV 的 PVC 的名称。
阶段转换时间戳
特性状态:
Kubernetes v1.29 [beta]
持久卷的 .status 字段可以包含 Alpha 状态的 lastPhaseTransitionTime 字段。
该字段保存的是卷上次转换阶段的时间戳。
对于新创建的卷,阶段被设置为 Pending,lastPhaseTransitionTime 被设置为当前时间。
说明:
你需要启用 PersistentVolumeLastPhaseTransitionTime
特性门控以使用或查看
lastPhaseTransitionTime 字段。
PersistentVolumeClaims
每个 PVC 对象都有 spec 和 status 部分,分别对应申领的规约和状态。
PersistentVolumeClaim 对象的名称必须是合法的
DNS 子域名.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}
访问模式
申领在请求具有特定访问模式的存储时,使用与卷相同的访问模式约定。
卷模式
申领使用与卷相同的约定来表明是将卷作为文件系统还是块设备来使用。
资源
申领和 Pod 一样,也可以请求特定数量的资源。在这个上下文中,请求的资源是存储。 卷和申领都使用相同的资源模型。
选择算符
申领可以设置标签选择算符 来进一步过滤卷集合。只有标签与选择算符相匹配的卷能够绑定到申领上。 选择算符包含两个字段:
matchLabels- 卷必须包含带有此值的标签matchExpressions- 通过设定键(key)、值列表和操作符(operator) 来构造的需求。合法的操作符有 In、NotIn、Exists 和 DoesNotExist。
来自 matchLabels 和 matchExpressions 的所有需求都按逻辑与的方式组合在一起。
这些需求都必须被满足才被视为匹配。
类
申领可以通过为 storageClassName 属性设置
StorageClass 的名称来请求特定的存储类。
只有所请求的类的 PV 卷,即 storageClassName 值与 PVC 设置相同的 PV 卷,
才能绑定到 PVC 申领。
PVC 申领不必一定要请求某个类。如果 PVC 的 storageClassName 属性值设置为 "",
则被视为要请求的是没有设置存储类的 PV 卷,因此这一 PVC 申领只能绑定到未设置存储类的
PV 卷(未设置注解或者注解值为 "" 的 PersistentVolume(PV)对象在系统中不会被删除,
因为这样做可能会引起数据丢失)。未设置 storageClassName 的 PVC 与此大不相同,
也会被集群作不同处理。具体筛查方式取决于
DefaultStorageClass 准入控制器插件
是否被启用。
- 如果准入控制器插件被启用,则管理员可以设置一个默认的 StorageClass。
所有未设置
storageClassName的 PVC 都只能绑定到隶属于默认存储类的 PV 卷。 设置默认 StorageClass 的工作是通过将对应 StorageClass 对象的注解storageclass.kubernetes.io/is-default-class赋值为true来完成的。 如果管理员未设置默认存储类,集群对 PVC 创建的处理方式与未启用准入控制器插件时相同。 如果设定的默认存储类不止一个,当 PVC 被动态制备时将使用最新的默认存储类。 - 如果准入控制器插件被关闭,则不存在默认 StorageClass 的说法。
所有将
storageClassName设为""的 PVC 只能被绑定到也将storageClassName设为""的 PV。 不过,只要默认的 StorageClass 可用,就可以稍后更新缺少storageClassName的 PVC。 如果这个 PVC 更新了,它将不再绑定到也将storageClassName设为""的 PV。
参阅可追溯的默认 StorageClass 赋值了解更多详细信息。
取决于安装方法,默认的 StorageClass 可能在集群安装期间由插件管理器(Addon Manager)部署到集群中。
当某 PVC 除了请求 StorageClass 之外还设置了 selector,则这两种需求会按逻辑与关系处理:
只有隶属于所请求类且带有所请求标签的 PV 才能绑定到 PVC。
说明:
目前,设置了非空 selector 的 PVC 对象无法让集群为其动态制备 PV 卷。
早前,Kubernetes 使用注解 volume.beta.kubernetes.io/storage-class 而不是
storageClassName 属性。这一注解目前仍然起作用,不过在将来的 Kubernetes
发布版本中该注解会被彻底废弃。
可追溯的默认 StorageClass 赋值
特性状态:
Kubernetes v1.28 [stable]
你可以创建 PersistentVolumeClaim,而无需为新 PVC 指定 storageClassName。
即使你的集群中不存在默认 StorageClass,你也可以这样做。
在这种情况下,新的 PVC 会按照你的定义进行创建,并且在默认值可用之前,该 PVC 的 storageClassName 保持不设置。
当一个默认的 StorageClass 变得可用时,控制平面会识别所有未设置 storageClassName 的现有 PVC。
对于 storageClassName 为空值或没有此主键的 PVC,
控制平面会更新这些 PVC 以设置其 storageClassName 与新的默认 StorageClass 匹配。
如果你有一个现有的 PVC,其中 storageClassName 是 "",
并且你配置了默认 StorageClass,则此 PVC 将不会得到更新。
为了保持绑定到 storageClassName 设为 "" 的 PV(当存在默认 StorageClass 时),
你需要将关联 PVC 的 storageClassName 设置为 ""。
此行为可帮助管理员更改默认 StorageClass,方法是先移除旧的 PVC,然后再创建或设置另一个 PVC。
这一时间窗口内因为没有指定默认值,会导致所创建的未设置 storageClassName 的 PVC 也没有默认值设置,
但由于默认 StorageClass 赋值是可追溯的,这种更改默认值的方式是安全的。
使用申领作为卷
Pod 将申领作为卷来使用,并藉此访问存储资源。 申领必须位于使用它的 Pod 所在的同一名字空间内。 集群在 Pod 的名字空间中查找申领,并使用它来获得申领所使用的 PV 卷。 之后,卷会被挂载到宿主上并挂载到 Pod 中。
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim
关于名字空间的说明
PersistentVolume 卷的绑定是排他性的。
由于 PersistentVolumeClaim 是名字空间作用域的对象,使用
"Many" 模式(ROX、RWX)来挂载申领的操作只能在同一名字空间内进行。
类型为 hostpath 的 PersistentVolume
hostPath PersistentVolume 使用节点上的文件或目录来模拟网络附加(network-attached)存储。
相关细节可参阅 hostPath 卷示例。
原始块卷支持
特性状态:
Kubernetes v1.18 [stable]
以下卷插件支持原始块卷,包括其动态制备(如果支持的话)的卷:
- CSI
- FC(光纤通道)
- iSCSI
- Local 卷
- OpenStack Cinder
- RBD(已弃用)
- RBD(Ceph 块设备,已弃用)
- VsphereVolume
使用原始块卷的持久卷
apiVersion: v1
kind: PersistentVolume
metadata:
name: block-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
volumeMode: Block
persistentVolumeReclaimPolicy: Retain
fc:
targetWWNs: ["50060e801049cfd1"]
lun: 0
readOnly: false
申请原始块卷的 PVC 申领
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: block-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Block
resources:
requests:
storage: 10Gi
在容器中添加原始块设备路径的 Pod 规约
apiVersion: v1
kind: Pod
metadata:
name: pod-with-block-volume
spec:
containers:
- name: fc-container
image: fedora:26
command: ["/bin/sh", "-c"]
args: [ "tail -f /dev/null" ]
volumeDevices:
- name: data
devicePath: /dev/xvda
volumes:
- name: data
persistentVolumeClaim:
claimName: block-pvc
说明:
向 Pod 中添加原始块设备时,你要在容器内设置设备路径而不是挂载路径。
绑定块卷
如果用户通过 PersistentVolumeClaim 规约的 volumeMode 字段来表明对原始块设备的请求,
绑定规则与之前版本中未在规约中考虑此模式的实现略有不同。
下面列举的表格是用户和管理员可以为请求原始块设备所作设置的组合。
此表格表明在不同的组合下卷是否会被绑定。
静态制备卷的卷绑定矩阵:
| PV volumeMode | PVC volumeMode | Result |
|---|---|---|
| 未指定 | 未指定 | 绑定 |
| 未指定 | Block | 不绑定 |
| 未指定 | Filesystem | 绑定 |
| Block | 未指定 | 不绑定 |
| Block | Block | 绑定 |
| Block | Filesystem | 不绑定 |
| Filesystem | Filesystem | 绑定 |
| Filesystem | Block | 不绑定 |
| Filesystem | 未指定 | 绑定 |
说明:
Alpha 发行版本中仅支持静态制备的卷。 管理员需要在处理原始块设备时小心处理这些值。
对卷快照及从卷快照中恢复卷的支持
特性状态:
Kubernetes v1.20 [stable]
卷快照(Volume Snapshot)仅支持树外 CSI 卷插件。 有关细节可参阅卷快照文档。 树内卷插件被弃用。你可以查阅卷插件 FAQ 了解已弃用的卷插件。
基于卷快照创建 PVC 申领
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: restore-pvc
spec:
storageClassName: csi-hostpath-sc
dataSource:
name: new-snapshot-test
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
卷克隆
卷克隆功能特性仅适用于 CSI 卷插件。
基于现有 PVC 创建新的 PVC 申领
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cloned-pvc
spec:
storageClassName: my-csi-plugin
dataSource:
name: existing-src-pvc-name
kind: PersistentVolumeClaim
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
卷填充器(Populator)与数据源
特性状态:
Kubernetes v1.24 [beta]
Kubernetes 支持自定义的卷填充器。要使用自定义的卷填充器,你必须为
kube-apiserver 和 kube-controller-manager 启用 AnyVolumeDataSource
特性门控。
卷填充器利用了 PVC 规约字段 dataSourceRef。
不像 dataSource 字段只能包含对另一个持久卷申领或卷快照的引用,
dataSourceRef 字段可以包含对同一命名空间中任何对象的引用(不包含除 PVC 以外的核心资源)。
对于启用了特性门控的集群,使用 dataSourceRef 比 dataSource 更好。
跨名字空间数据源
特性状态:
Kubernetes v1.26 [alpha]
Kubernetes 支持跨名字空间卷数据源。
要使用跨名字空间卷数据源,你必须为 kube-apiserver、kube-controller 管理器启用
AnyVolumeDataSource 和 CrossNamespaceVolumeDataSource
特性门控。
此外,你必须为 csi-provisioner 启用 CrossNamespaceVolumeDataSource 特性门控。
启用 CrossNamespaceVolumeDataSource 特性门控允许你在 dataSourceRef 字段中指定名字空间。
说明:
当你为卷数据源指定名字空间时,Kubernetes 在接受此引用之前在另一个名字空间中检查 ReferenceGrant。
ReferenceGrant 是 gateway.networking.k8s.io 扩展 API 的一部分。更多细节请参见 Gateway API 文档中的
ReferenceGrant。
这意味着你必须在使用此机制之前至少使用 Gateway API 的 ReferenceGrant 来扩展 Kubernetes 集群。
数据源引用
dataSourceRef 字段的行为与 dataSource 字段几乎相同。
如果其中一个字段被指定而另一个字段没有被指定,API 服务器将给两个字段相同的值。
这两个字段都不能在创建后改变,如果试图为这两个字段指定不同的值,将导致验证错误。
因此,这两个字段将总是有相同的内容。
在 dataSourceRef 字段和 dataSource 字段之间有两个用户应该注意的区别:
dataSource字段会忽略无效的值(如同是空值), 而dataSourceRef字段永远不会忽略值,并且若填入一个无效的值,会导致错误。 无效值指的是 PVC 之外的核心对象(没有 apiGroup 的对象)。dataSourceRef字段可以包含不同类型的对象,而dataSource字段只允许 PVC 和卷快照。
当 CrossNamespaceVolumeDataSource 特性被启用时,存在其他区别:
dataSource字段仅允许本地对象,而dataSourceRef字段允许任何名字空间中的对象。- 若指定了 namespace,则
dataSource和dataSourceRef不会被同步。
用户始终应该在启用了此特性门控的集群上使用 dataSourceRef,
在没有启用该特性门控的集群上使用 dataSource。
在任何情况下都没有必要查看这两个字段。
这两个字段的值看似相同但是语义稍微不一样,是为了向后兼容。
特别是混用旧版本和新版本的控制器时,它们能够互通。
使用卷填充器
卷填充器是能创建非空卷的控制器,
其卷的内容通过一个自定义资源决定。
用户通过使用 dataSourceRef 字段引用自定义资源来创建一个被填充的卷:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: populated-pvc
spec:
dataSourceRef:
name: example-name
kind: ExampleDataSource
apiGroup: example.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
因为卷填充器是外部组件,如果没有安装所有正确的组件,试图创建一个使用卷填充器的 PVC 就会失败。 外部控制器应该在 PVC 上产生事件,以提供创建状态的反馈,包括在由于缺少某些组件而无法创建 PVC 的情况下发出警告。
你可以把 alpha 版本的卷数据源验证器 控制器安装到你的集群中。 如果没有填充器处理该数据源的情况下,该控制器会在 PVC 上产生警告事件。 当一个合适的填充器被安装到 PVC 上时,该控制器的职责是上报与卷创建有关的事件,以及在该过程中发生的问题。
使用跨名字空间的卷数据源
特性状态:
Kubernetes v1.26 [alpha]
创建 ReferenceGrant 以允许名字空间属主接受引用。
你通过使用 dataSourceRef 字段指定跨名字空间卷数据源,定义填充的卷。
你必须在源名字空间中已经有一个有效的 ReferenceGrant:
apiVersion: gateway.networking.k8s.io/v1beta1
kind: ReferenceGrant
metadata:
name: allow-ns1-pvc
namespace: default
spec:
from:
- group: ""
kind: PersistentVolumeClaim
namespace: ns1
to:
- group: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: new-snapshot-demo
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-pvc
namespace: ns1
spec:
storageClassName: example
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
dataSourceRef:
apiGroup: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: new-snapshot-demo
namespace: default
volumeMode: Filesystem
编写可移植的配置
如果你要编写配置模板和示例用来在很多集群上运行并且需要持久性存储,建议你使用以下模式:
- 将 PersistentVolumeClaim 对象包含到你的配置包(Bundle)中,和 Deployment 以及 ConfigMap 等放在一起。
- 不要在配置中包含 PersistentVolume 对象,因为对配置进行实例化的用户很可能 没有创建 PersistentVolume 的权限。
- 为用户提供在实例化模板时指定存储类名称的能力。
- 仍按用户提供存储类名称,将该名称放到
persistentVolumeClaim.storageClassName字段中。 这样会使得 PVC 在集群被管理员启用了存储类支持时能够匹配到正确的存储类, - 如果用户未指定存储类名称,将
persistentVolumeClaim.storageClassName留空(nil)。 这样,集群会使用默认StorageClass为用户自动制备一个存储卷。 很多集群环境都配置了默认的StorageClass,或者管理员也可以自行创建默认的StorageClass。
- 仍按用户提供存储类名称,将该名称放到
- 在你的工具链中,监测经过一段时间后仍未被绑定的 PVC 对象,要让用户知道这些对象, 因为这可能意味着集群不支持动态存储(因而用户必须先创建一个匹配的 PV),或者 集群没有配置存储系统(因而用户无法配置需要 PVC 的工作负载配置)。
接下来
API 参考
阅读以下页面中描述的 API:
6.3 - 投射卷
本文档描述 Kubernetes 中的投射卷(Projected Volumes)。 建议先熟悉卷概念。
介绍
一个 projected 卷可以将若干现有的卷源映射到同一个目录之上。
目前,以下类型的卷源可以被投射:
所有的卷源都要求处于 Pod 所在的同一个名字空间内。更多详细信息, 可参考一体化卷设计文档。
带有 Secret、DownwardAPI 和 ConfigMap 的配置示例
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox:1.28
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "cpu_limit"
resourceFieldRef:
containerName: container-test
resource: limits.cpu
- configMap:
name: myconfigmap
items:
- key: config
path: my-group/my-config
带有非默认权限模式设置的 Secret 的配置示例
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox:1.28
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- secret:
name: mysecret2
items:
- key: password
path: my-group/my-password
mode: 511
每个被投射的卷源都列举在规约中的 sources 下面。参数几乎相同,只有两个例外:
- 对于 Secret,
secretName字段被改为name以便于 ConfigMap 的命名一致; defaultMode只能在投射层级设置,不能在卷源层级设置。不过,正如上面所展示的, 你可以显式地为每个投射单独设置mode属性。
serviceAccountToken 投射卷
你可以将当前服务账号的令牌注入到 Pod 中特定路径下。例如:
apiVersion: v1
kind: Pod
metadata:
name: sa-token-test
spec:
containers:
- name: container-test
image: busybox:1.28
volumeMounts:
- name: token-vol
mountPath: "/service-account"
readOnly: true
serviceAccountName: default
volumes:
- name: token-vol
projected:
sources:
- serviceAccountToken:
audience: api
expirationSeconds: 3600
path: token
示例 Pod 中包含一个投射卷,其中包含注入的服务账号令牌。
此 Pod 中的容器可以使用该令牌访问 Kubernetes API 服务器, 使用
Pod 的 ServiceAccount
进行身份验证。audience 字段包含令牌所针对的受众。
收到令牌的主体必须使用令牌受众中所指定的某个标识符来标识自身,否则应该拒绝该令牌。
此字段是可选的,默认值为 API 服务器的标识。
字段 expirationSeconds 是服务账号令牌预期的生命期长度。默认值为 1 小时,
必须至少为 10 分钟(600 秒)。管理员也可以通过设置 API 服务器的命令行参数
--service-account-max-token-expiration 来为其设置最大值上限。
path 字段给出与投射卷挂载点之间的相对路径。
说明:
以 subPath
形式使用投射卷源的容器无法收到对应卷源的更新。
clusterTrustBundle 投射卷
特性状态:
Kubernetes v1.29 [alpha]
说明:
要在 Kubernetes 1.29 中使用此特性,你必须通过 ClusterTrustBundle
特性门控和
--runtime-config=certificates.k8s.io/v1alpha1/clustertrustbundles=true kube-apiserver
标志启用对 ClusterTrustBundle 对象的支持,然后才能启用 ClusterTrustBundleProjection 特性门控。
clusterTrustBundle 投射卷源将一个或多个
ClusterTrustBundle
对象的内容作为一个自动更新的文件注入到容器文件系统中。
ClusterTrustBundle 可以通过名称 或签名者名称被选中。
要按名称选择,可以使用 name 字段指定单个 ClusterTrustBundle 对象。
要按签名者名称选择,可以使用 signerName 字段(也可选用 labelSelector 字段)
指定一组使用给定签名者名称的 ClusterTrustBundle 对象。
如果 labelSelector 不存在,则针对该签名者的所有 ClusterTrustBundles 将被选中。
kubelet 会对所选 ClusterTrustBundle 对象中的证书进行去重,规范化 PEM 表示(丢弃注释和头部),
重新排序证书,并将这些证书写入由 path 指定的文件中。
随着所选 ClusterTrustBundles 的集合或其内容发生变化,kubelet 会保持更新此文件。
默认情况下,如果找不到指定的 ClusterTrustBundle,或者 signerName / labelSelector
与所有 ClusterTrustBundle 都不匹配,kubelet 将阻止 Pod 启动。如果这不是你想要的行为,
可以将 optional 字段设置为 true,Pod 将使用 path 处的空白文件启动。
apiVersion: v1
kind: Pod
metadata:
name: sa-ctb-name-test
spec:
containers:
- name: container-test
image: busybox
command: ["sleep", "3600"]
volumeMounts:
- name: token-vol
mountPath: "/root-certificates"
readOnly: true
serviceAccountName: default
volumes:
- name: root-certificates-vol
projected:
sources:
- clusterTrustBundle:
name: example
path: example-roots.pem
- clusterTrustBundle:
signerName: "example.com/mysigner"
labelSelector:
matchLabels:
version: live
path: mysigner-roots.pem
optional: true
与 SecurityContext 间的关系
关于在投射的服务账号卷中处理文件访问权限的提案 介绍了如何使得所投射的文件具有合适的属主访问权限。
Linux
在包含了投射卷并在
SecurityContext
中设置了 RunAsUser 属性的 Linux Pod 中,投射文件具有正确的属主属性设置,
其中包含了容器用户属主。
当 Pod 中的所有容器在其
PodSecurityContext
或容器
SecurityContext
中设置了相同的 runAsUser 时,kubelet 将确保 serviceAccountToken
卷的内容归该用户所有,并且令牌文件的权限模式会被设置为 0600。
说明:
在某 Pod 被创建后为其添加的临时容器不会更改创建该 Pod 时设置的卷权限。
如果 Pod 的 serviceAccountToken 卷权限被设为 0600
是因为 Pod 中的其他所有容器都具有相同的 runAsUser,
则临时容器必须使用相同的 runAsUser 才能读取令牌。
Windows
在包含了投射卷并在 SecurityContext 中设置了 RunAsUsername 的 Windows Pod 中,
由于 Windows 中用户账号的管理方式问题,文件的属主无法正确设置。
Windows 在名为安全账号管理器(Security Account Manager,SAM)
的数据库中保存本地用户和组信息。每个容器会维护其自身的 SAM 数据库实例,
宿主系统无法窥视到容器运行期间数据库内容。Windows 容器被设计用来运行操作系统的用户态部分,
与宿主系统之间隔离,因此维护了一个虚拟的 SAM 数据库。
所以,在宿主系统上运行的 kubelet 无法动态为虚拟的容器账号配置宿主文件的属主。
如果需要将宿主机器上的文件与容器共享,建议将它们放到挂载于 C:\ 之外的独立卷中。
默认情况下,所投射的文件会具有如下例所示的属主属性设置:
PS C:\> Get-Acl C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061\ca.crt | Format-List
Path : Microsoft.PowerShell.Core\FileSystem::C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061\ca.crt
Owner : BUILTIN\Administrators
Group : NT AUTHORITY\SYSTEM
Access : NT AUTHORITY\SYSTEM Allow FullControl
BUILTIN\Administrators Allow FullControl
BUILTIN\Users Allow ReadAndExecute, Synchronize
Audit :
Sddl : O:BAG:SYD:AI(A;ID;FA;;;SY)(A;ID;FA;;;BA)(A;ID;0x1200a9;;;BU)
这意味着,所有类似 ContainerAdministrator 的管理员用户都具有读、写和执行访问权限,
而非管理员用户将具有读和执行访问权限。
说明:
总体而言,为容器授予访问宿主系统的权限这种做法是不推荐的,因为这样做可能会打开潜在的安全性攻击之门。
在创建 Windows Pod 时,如果在其 SecurityContext 中设置了 RunAsUser,
Pod 会一直阻塞在 ContainerCreating 状态。因此,建议不要在 Windows
节点上使用仅针对 Linux 的 RunAsUser 选项。
6.4 - 临时卷
本文档描述 Kubernetes 中的 临时卷(Ephemeral Volume)。 建议先了解卷,特别是 PersistentVolumeClaim 和 PersistentVolume。
有些应用程序需要额外的存储,但并不关心数据在重启后是否仍然可用。 例如,缓存服务经常受限于内存大小,而且可以将不常用的数据转移到比内存慢的存储中,对总体性能的影响并不大。
另有些应用程序需要以文件形式注入的只读数据,比如配置数据或密钥。
临时卷 就是为此类用例设计的。因为卷会遵从 Pod 的生命周期,与 Pod 一起创建和删除, 所以停止和重新启动 Pod 时,不会受持久卷在何处可用的限制。
临时卷在 Pod 规约中以 内联 方式定义,这简化了应用程序的部署和管理。
临时卷的类型
Kubernetes 为了不同的用途,支持几种不同类型的临时卷:
- emptyDir: Pod 启动时为空,存储空间来自本地的 kubelet 根目录(通常是根磁盘)或内存
- configMap、 downwardAPI、 secret: 将不同类型的 Kubernetes 数据注入到 Pod 中
- CSI 临时卷: 类似于前面的卷类型,但由专门支持此特性 的指定 CSI 驱动程序提供
- 通用临时卷: 它可以由所有支持持久卷的存储驱动程序提供
emptyDir、configMap、downwardAPI、secret 是作为
本地临时存储
提供的。它们由各个节点上的 kubelet 管理。
CSI 临时卷 必须 由第三方 CSI 存储驱动程序提供。
通用临时卷 可以 由第三方 CSI 存储驱动程序提供,也可以由支持动态制备的任何其他存储驱动程序提供。 一些专门为 CSI 临时卷编写的 CSI 驱动程序,不支持动态制备:因此这些驱动程序不能用于通用临时卷。
使用第三方驱动程序的优势在于,它们可以提供 Kubernetes 本身不支持的功能, 例如,与 kubelet 管理的磁盘具有不同性能特征的存储,或者用来注入不同的数据。
CSI 临时卷
特性状态:
Kubernetes v1.25 [stable]
说明: 只有一部分 CSI 驱动程序支持 CSI 临时卷。Kubernetes CSI
驱动程序列表
显示了支持临时卷的驱动程序。
从概念上讲,CSI 临时卷类似于 configMap、downwardAPI 和 secret 类型的卷:
在各个本地节点管理卷的存储,并在 Pod 调度到节点后与其他本地资源一起创建。
在这个阶段,Kubernetes 没有重新调度 Pod 的概念。卷创建不太可能失败,否则 Pod 启动将会受阻。
特别是,这些卷 不 支持感知存储容量的 Pod 调度。
它们目前也没包括在 Pod 的存储资源使用限制中,因为 kubelet 只能对它自己管理的存储强制执行。
下面是使用 CSI 临时存储的 Pod 的示例清单:
kind: Pod
apiVersion: v1
metadata:
name: my-csi-app
spec:
containers:
- name: my-frontend
image: busybox:1.28
volumeMounts:
- mountPath: "/data"
name: my-csi-inline-vol
command: [ "sleep", "1000000" ]
volumes:
- name: my-csi-inline-vol
csi:
driver: inline.storage.kubernetes.io
volumeAttributes:
foo: bar
volumeAttributes 决定驱动程序准备什么样的卷。每个驱动程序的属性不尽相同,没有实现标准化。
有关进一步的说明,请参阅每个 CSI 驱动程序的文档。
CSI 驱动程序限制
CSI 临时卷允许用户直接向 CSI 驱动程序提供 volumeAttributes,它会作为 Pod 规约的一部分。
有些 volumeAttributes 通常仅限于管理员使用,允许这一类 volumeAttributes 的 CSI 驱动程序不适合在内联临时卷中使用。
例如,通常在 StorageClass 中定义的参数不应通过使用内联临时卷向用户公开。
如果集群管理员需要限制在 Pod 规约中作为内联卷使用的 CSI 驱动程序,可以这样做:
- 从 CSIDriver 规约的
volumeLifecycleModes中删除Ephemeral,这可以防止驱动程序被用作内联临时卷。 - 使用准入 Webhook 来限制如何使用此驱动程序。
通用临时卷
特性状态:
Kubernetes v1.23 [stable]
通用临时卷类似于 emptyDir 卷,因为它为每个 Pod 提供临时数据存放目录,
在最初制备完毕时一般为空。不过通用临时卷也有一些额外的功能特性:
- 存储可以是本地的,也可以是网络连接的。
- 卷可以有固定的大小,Pod 不能超量使用。
- 卷可能有一些初始数据,这取决于驱动程序和参数。
示例:
kind: Pod
apiVersion: v1
metadata:
name: my-app
spec:
containers:
- name: my-frontend
image: busybox:1.28
volumeMounts:
- mountPath: "/scratch"
name: scratch-volume
command: [ "sleep", "1000000" ]
volumes:
- name: scratch-volume
ephemeral:
volumeClaimTemplate:
metadata:
labels:
type: my-frontend-volume
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "scratch-storage-class"
resources:
requests:
storage: 1Gi
生命周期和 PersistentVolumeClaim
关键的设计思想是在 Pod 的卷来源中允许使用 卷申领的参数。 PersistentVolumeClaim 的标签、注解和整套字段集均被支持。 创建这样一个 Pod 后,临时卷控制器在 Pod 所属的命名空间中创建一个实际的 PersistentVolumeClaim 对象,并确保删除 Pod 时,同步删除 PersistentVolumeClaim。
如上设置将触发卷的绑定与/或制备,相应动作或者在
StorageClass
使用即时卷绑定时立即执行,或者当 Pod 被暂时性调度到某节点时执行 (WaitForFirstConsumer 卷绑定模式)。
对于通用的临时卷,建议采用后者,这样调度器就可以自由地为 Pod 选择合适的节点。
对于即时绑定,调度器则必须选出一个节点,使得在卷可用时,能立即访问该卷。
就资源所有权而言,
拥有通用临时存储的 Pod 是提供临时存储 (ephemeral storage) 的 PersistentVolumeClaim 的所有者。
当 Pod 被删除时,Kubernetes 垃圾收集器会删除 PVC,
然后 PVC 通常会触发卷的删除,因为存储类的默认回收策略是删除卷。
你可以使用带有 retain 回收策略的 StorageClass 创建准临时 (Quasi-Ephemeral) 本地存储:
该存储比 Pod 寿命长,所以在这种情况下,你需要确保单独进行卷清理。
当这些 PVC 存在时,它们可以像其他 PVC 一样使用。 特别是,它们可以被引用作为批量克隆或快照的数据源。 PVC 对象还保持着卷的当前状态。
PersistentVolumeClaim 的命名
自动创建的 PVC 采取确定性的命名机制:名称是 Pod 名称和卷名称的组合,中间由连字符(-)连接。
在上面的示例中,PVC 将被命名为 my-app-scratch-volume 。
这种确定性的命名机制使得与 PVC 交互变得更容易,因为一旦知道 Pod 名称和卷名,就不必搜索它。
这种命名机制也引入了潜在的冲突,不同的 Pod 之间(名为 “Pod-a” 的 Pod 挂载名为 "scratch" 的卷,和名为 "pod" 的 Pod 挂载名为 “a-scratch” 的卷, 这两者均会生成名为 "pod-a-scratch" 的 PVC),或者在 Pod 和手工创建的 PVC 之间可能出现冲突。
这类冲突会被检测到:如果 PVC 是为 Pod 创建的,那么它只用于临时卷。 此检测基于所有权关系。现有的 PVC 不会被覆盖或修改。 但这并不能解决冲突,因为如果没有正确的 PVC,Pod 就无法启动。
注意:
当同一个命名空间中命名 Pod 和卷时,要小心,以防止发生此类冲突。
安全
只要用户有权限创建 Pod,就可以使用通用的临时卷间接地创建持久卷申领(PVCs), 即使他们没有权限直接创建 PVCs。集群管理员必须注意这一点。如果这与他们的安全模型相悖, 他们应该使用准入 Webhook。
正常的 PVC 的名字空间配额 仍然有效,因此即使允许用户使用这种新机制,他们也不能使用它来规避其他策略。
接下来
kubelet 管理的临时卷
参阅本地临时存储。
CSI 临时卷
- 有关设计的更多信息,参阅 Ephemeral Inline CSI volumes KEP。
- 关于本特性下一步开发的更多信息,参阅 enhancement tracking issue #596。
通用临时卷
- 有关设计的更多信息,参阅 Generic ephemeral inline volumes KEP。
6.5 - 存储类
本文描述了 Kubernetes 中 StorageClass 的概念。 建议先熟悉卷和持久卷的概念。
StorageClass 为管理员提供了描述存储"类"的方法。 不同的类型可能会映射到不同的服务质量等级或备份策略,或是由集群管理员制定的任意策略。 Kubernetes 本身并不清楚各种类代表的什么。这个类的概念在其他存储系统中有时被称为"配置文件"。
StorageClass API
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段,
这些字段会在 StorageClass 需要动态制备 PersistentVolume 时会使用到。
StorageClass 对象的命名很重要,用户使用这个命名来请求生成一个特定的类。 当创建 StorageClass 对象时,管理员设置 StorageClass 对象的命名和其他参数。
管理员可以为没有申请绑定到特定 StorageClass 的 PVC 指定一个默认的存储类: 更多详情请参阅 PersistentVolumeClaim 章节。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:
- debug
volumeBindingMode: Immediate
默认 StorageClass
当一个 PVC 没有指定 storageClassName 时,会使用默认的 StorageClass。
集群中只能有一个默认的 StorageClass。如果不小心设置了多个默认的 StorageClass,
在动态制备 PVC 时将使用其中最新的默认设置的 StorageClass。
关于如何设置默认的 StorageClass, 请参见更改默认 StorageClass。 请注意,某些云服务提供商可能已经定义了一个默认的 StorageClass。
存储制备器
每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件制备 PV。 该字段必须指定。
| 卷插件 | 内置制备器 | 配置示例 |
|---|---|---|
| AzureFile | ✓ | Azure File |
| CephFS | - | - |
| FC | - | - |
| FlexVolume | - | - |
| iSCSI | - | - |
| NFS | - | NFS |
| RBD | ✓ | Ceph RBD |
| VsphereVolume | ✓ | vSphere |
| PortworxVolume | ✓ | Portworx Volume |
| Local | - | Local |
你不限于指定此处列出的 "内置" 制备器(其名称前缀为 "kubernetes.io" 并打包在 Kubernetes 中)。 你还可以运行和指定外部制备器,这些独立的程序遵循由 Kubernetes 定义的规范。 外部供应商的作者完全可以自由决定他们的代码保存于何处、打包方式、运行方式、使用的插件(包括 Flex)等。 代码仓库 kubernetes-sigs/sig-storage-lib-external-provisioner 包含一个用于为外部制备器编写功能实现的类库。你可以访问代码仓库 kubernetes-sigs/sig-storage-lib-external-provisioner 了解外部驱动列表。
例如,NFS 没有内部制备器,但可以使用外部制备器。 也有第三方存储供应商提供自己的外部制备器。
回收策略
由 StorageClass 动态创建的 PersistentVolume 会在类的
reclaimPolicy
字段中指定回收策略,可以是 Delete 或者 Retain。
如果 StorageClass 对象被创建时没有指定 reclaimPolicy,它将默认为 Delete。
通过 StorageClass 手动创建并管理的 PersistentVolume 会使用它们被创建时指定的回收策略。
允许卷扩展
特性状态:
Kubernetes v1.11 [beta]
PersistentVolume 可以配置为可扩展。将此功能设置为 true 时,允许用户通过编辑相应的 PVC 对象来调整卷大小。
当下层 StorageClass 的 allowVolumeExpansion 字段设置为 true 时,以下类型的卷支持卷扩展。
| 卷类型 | Kubernetes 版本要求 |
|---|---|
| rbd | 1.11 |
| Azure File | 1.11 |
| Portworx | 1.11 |
| FlexVolume | 1.13 |
| CSI | 1.14 (alpha), 1.16 (beta) |
说明:
此功能仅可用于扩容卷,不能用于缩小卷。
挂载选项
由 StorageClass 动态创建的 PersistentVolume 将使用类中 mountOptions 字段指定的挂载选项。
如果卷插件不支持挂载选项,却指定了挂载选项,则制备操作会失败。 挂载选项在 StorageClass 和 PV 上都不会做验证。如果其中一个挂载选项无效,那么这个 PV 挂载操作就会失败。
卷绑定模式
volumeBindingMode
字段控制了卷绑定和动态制备应该发生在什么时候。
当未设置时,默认使用 Immediate 模式。
Immediate 模式表示一旦创建了 PersistentVolumeClaim 也就完成了卷绑定和动态制备。
对于由于拓扑限制而非集群所有节点可达的存储后端,PersistentVolume
会在不知道 Pod 调度要求的情况下绑定或者制备。
集群管理员可以通过指定 WaitForFirstConsumer 模式来解决此问题。
该模式将延迟 PersistentVolume 的绑定和制备,直到使用该 PersistentVolumeClaim 的 Pod 被创建。
PersistentVolume 会根据 Pod 调度约束指定的拓扑来选择或制备。
这些包括但不限于资源需求、
节点筛选器、
Pod 亲和性和互斥性、
以及污点和容忍度。
以下插件支持预创建绑定 PersistentVolume 的 WaitForFirstConsumer 模式:
特性状态:
Kubernetes v1.17 [stable]
动态制备和预先创建的 PV 也支持 CSI 卷, 但是你需要查看特定 CSI 驱动的文档以查看其支持的拓扑键名和例子。
说明:
如果你选择使用 WaitForFirstConsumer,请不要在 Pod 规约中使用 nodeName 来指定节点亲和性。
如果在这种情况下使用 nodeName,Pod 将会绕过调度程序,PVC 将停留在 pending 状态。
相反,在这种情况下,你可以使用节点选择器作为主机名,如下所示。
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
nodeSelector:
kubernetes.io/hostname: kube-01
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
允许的拓扑结构
当集群操作人员使用了 WaitForFirstConsumer 的卷绑定模式,
在大部分情况下就没有必要将制备限制为特定的拓扑结构。
然而,如果还有需要的话,可以使用 allowedTopologies。
这个例子描述了如何将制备卷的拓扑限制在特定的区域,
在使用时应该根据插件支持情况替换 zone 和 zones 参数。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
volumeBindingMode: WaitForFirstConsumer
allowedTopologies:
- matchLabelExpressions:
- key: topology.kubernetes.io/zone
values:
- us-central-1a
- us-central-1b
参数
Storage Classes 的参数描述了存储类的卷。取决于制备器,可以接受不同的参数。 例如,参数 type 的值 io1 和参数 iopsPerGB 特定于 EBS PV。 当参数被省略时,会使用默认值。
一个 StorageClass 最多可以定义 512 个参数。这些参数对象的总长度不能超过 256 KiB,包括参数的键和值。
AWS EBS
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "10"
fsType: ext4
type:io1、gp2、sc1、st1。详细信息参见 AWS 文档。默认值:gp2。zone(已弃用):AWS 区域。如果没有指定zone和zones, 通常卷会在 Kubernetes 集群节点所在的活动区域中轮询调度分配。zone和zones参数不能同时使用。zones(已弃用):以逗号分隔的 AWS 区域列表。 如果没有指定zone和zones,通常卷会在 Kubernetes 集群节点所在的活动区域中轮询调度分配。zone和zones参数不能同时使用。iopsPerGB:只适用于io1卷。每 GiB 每秒 I/O 操作。 AWS 卷插件将其与请求卷的大小相乘以计算 IOPS 的容量, 并将其限制在 20000 IOPS(AWS 支持的最高值,请参阅 AWS 文档)。 这里需要输入一个字符串,即"10",而不是10。fsType:受 Kubernetes 支持的文件类型。默认值:"ext4"。encrypted:指定 EBS 卷是否应该被加密。合法值为"true"或者"false"。 这里需要输入字符串,即"true",而非true。kmsKeyId:可选。加密卷时使用密钥的完整 Amazon 资源名称。 如果没有提供,但encrypted值为 true,AWS 生成一个密钥。关于有效的 ARN 值,请参阅 AWS 文档。
说明:
zone 和 zones 已被弃用并被允许的拓扑结构取代。
NFS
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: example-nfs
provisioner: example.com/external-nfs
parameters:
server: nfs-server.example.com
path: /share
readOnly: "false"
server:NFS 服务器的主机名或 IP 地址。path:NFS 服务器导出的路径。readOnly:是否将存储挂载为只读的标志(默认为 false)。
Kubernetes 不包含内部 NFS 驱动。你需要使用外部驱动为 NFS 创建 StorageClass。 这里有些例子:
vSphere
vSphere 存储类有两种制备器:
树内制备器已经被 弃用。 更多关于 CSI 制备器的详情,请参阅 Kubernetes vSphere CSI 驱动 和 vSphereVolume CSI 迁移。
CSI 制备器
vSphere CSI StorageClass 制备器在 Tanzu Kubernetes 集群下运行。示例请参阅 vSphere CSI 仓库。
vCP 制备器
以下示例使用 VMware Cloud Provider(vCP)StorageClass 制备器。
-
使用用户指定的磁盘格式创建一个 StorageClass。
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/vsphere-volume parameters: diskformat: zeroedthickdiskformat:thin、zeroedthick和eagerzeroedthick。默认值:"thin"。
-
在用户指定的数据存储上创建磁盘格式的 StorageClass。
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/vsphere-volume parameters: diskformat: zeroedthick datastore: VSANDatastoredatastore:用户也可以在 StorageClass 中指定数据存储。 卷将在 StorageClass 中指定的数据存储上创建,在这种情况下是VSANDatastore。 该字段是可选的。 如果未指定数据存储,则将在用于初始化 vSphere Cloud Provider 的 vSphere 配置文件中指定的数据存储上创建该卷。
-
Kubernetes 中的存储策略管理
-
使用现有的 vCenter SPBM 策略
vSphere 用于存储管理的最重要特性之一是基于策略的管理。 基于存储策略的管理(SPBM)是一个存储策略框架,提供单一的统一控制平面的跨越广泛的数据服务和存储解决方案。 SPBM 使得 vSphere 管理员能够克服先期的存储配置挑战,如容量规划、差异化服务等级和管理容量空间。
SPBM 策略可以在 StorageClass 中使用
storagePolicyName参数声明。
-
Kubernetes 内的 Virtual SAN 策略支持
Vsphere Infrastructure(VI)管理员将能够在动态卷配置期间指定自定义 Virtual SAN 存储功能。你现在可以在动态制备卷期间以存储能力的形式定义存储需求,例如性能和可用性。 存储能力需求会转换为 Virtual SAN 策略,之后当持久卷(虚拟磁盘)被创建时, 会将其推送到 Virtual SAN 层。虚拟磁盘分布在 Virtual SAN 数据存储中以满足要求。
你可以参考基于存储策略的动态制备卷管理, 进一步了解有关持久卷管理的存储策略的详细信息。
-
有几个 vSphere 例子供你在 Kubernetes for vSphere 中尝试进行持久卷管理。
Ceph RBD
说明:
特性状态:
Kubernetes v1.28 [deprecated]
Ceph RBD 的内部驱动程序已被弃用。请使用 CephFS RBD CSI驱动程序。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/rbd
parameters:
monitors: 10.16.153.105:6789
adminId: kube
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-secret-user
userSecretNamespace: default
fsType: ext4
imageFormat: "2"
imageFeatures: "layering"
monitors:Ceph monitor,逗号分隔。该参数是必需的。adminId:Ceph 客户端 ID,用于在池 ceph 池中创建映像。默认是 "admin"。adminSecret:adminId的 Secret 名称。该参数是必需的。 提供的 secret 必须有值为 "kubernetes.io/rbd" 的 type 参数。adminSecretNamespace:adminSecret的命名空间。默认是 "default"。pool:Ceph RBD 池。默认是 "rbd"。userId:Ceph 客户端 ID,用于映射 RBD 镜像。默认与adminId相同。
-
userSecretName:用于映射 RBD 镜像的userId的 Ceph Secret 的名字。 它必须与 PVC 存在于相同的 namespace 中。该参数是必需的。 提供的 secret 必须具有值为 "kubernetes.io/rbd" 的 type 参数,例如以这样的方式创建:kubectl create secret generic ceph-secret --type="kubernetes.io/rbd" \ --from-literal=key='QVFEQ1pMdFhPUnQrSmhBQUFYaERWNHJsZ3BsMmNjcDR6RFZST0E9PQ==' \ --namespace=kube-system
userSecretNamespace:userSecretName的命名空间。fsType:Kubernetes 支持的 fsType。默认:"ext4"。imageFormat:Ceph RBD 镜像格式,"1" 或者 "2"。默认值是 "1"。imageFeatures:这个参数是可选的,只能在你将imageFormat设置为 "2" 才使用。 目前支持的功能只是layering。默认是 "",没有功能打开。
Azure 磁盘
Azure Unmanaged Disk Storage Class(非托管磁盘存储类)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/azure-disk
parameters:
skuName: Standard_LRS
location: eastus
storageAccount: azure_storage_account_name
skuName:Azure 存储帐户 Sku 层。默认为空。location:Azure 存储帐户位置。默认为空。storageAccount:Azure 存储帐户名称。 如果提供存储帐户,它必须位于与集群相同的资源组中,并且location是被忽略的。如果未提供存储帐户,则会在与集群相同的资源组中创建新的存储帐户。
Azure 磁盘 Storage Class(从 v1.7.2 开始)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/azure-disk
parameters:
storageaccounttype: Standard_LRS
kind: managed
storageaccounttype:Azure 存储帐户 Sku 层。默认为空。kind:可能的值是shared、dedicated和managed(默认)。 当kind的值是shared时,所有非托管磁盘都在集群的同一个资源组中的几个共享存储帐户中创建。 当kind的值是dedicated时,将为在集群的同一个资源组中新的非托管磁盘创建新的专用存储帐户。resourceGroup:指定要创建 Azure 磁盘所属的资源组。必须是已存在的资源组名称。 若未指定资源组,磁盘会默认放入与当前 Kubernetes 集群相同的资源组中。
- Premium VM 可以同时添加 Standard_LRS 和 Premium_LRS 磁盘,而 Standard 虚拟机只能添加 Standard_LRS 磁盘。
- 托管虚拟机只能连接托管磁盘,非托管虚拟机只能连接非托管磁盘。
Azure 文件
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: azurefile
provisioner: kubernetes.io/azure-file
parameters:
skuName: Standard_LRS
location: eastus
storageAccount: azure_storage_account_name
skuName:Azure 存储帐户 Sku 层。默认为空。location:Azure 存储帐户位置。默认为空。storageAccount:Azure 存储帐户名称。默认为空。 如果不提供存储帐户,会搜索所有与资源相关的存储帐户,以找到一个匹配skuName和location的账号。 如果提供存储帐户,它必须存在于与集群相同的资源组中,skuName和location会被忽略。secretNamespace:包含 Azure 存储帐户名称和密钥的密钥的名字空间。 默认值与 Pod 相同。secretName:包含 Azure 存储帐户名称和密钥的密钥的名称。 默认值为azure-storage-account-<accountName>-secretreadOnly:指示是否将存储安装为只读的标志。默认为 false,表示"读/写"挂载。 该设置也会影响 VolumeMounts 中的ReadOnly设置。
在存储制备期间,为挂载凭证创建一个名为 secretName 的 Secret。如果集群同时启用了
RBAC
和控制器角色,
为 system:controller:persistent-volume-binder 的 clusterrole 添加
Secret 资源的 create 权限。
在多租户上下文中,强烈建议显式设置 secretNamespace 的值,否则其他用户可能会读取存储帐户凭据。
Portworx 卷
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: portworx-io-priority-high
provisioner: kubernetes.io/portworx-volume
parameters:
repl: "1"
snap_interval: "70"
priority_io: "high"
fs:选择的文件系统:none/xfs/ext4(默认:ext4)。block_size:以 Kbytes 为单位的块大小(默认值:32)。repl:同步副本数量,以复制因子1..3(默认值:1)的形式提供。 这里需要填写字符串,即,"1"而不是1。io_priority:决定是否从更高性能或者较低优先级存储创建卷high/medium/low(默认值:low)。snap_interval:触发快照的时钟/时间间隔(分钟)。 快照是基于与先前快照的增量变化,0 是禁用快照(默认:0)。 这里需要填写字符串,即,是"70"而不是70。aggregation_level:指定卷分配到的块数量,0 表示一个非聚合卷(默认:0)。 这里需要填写字符串,即,是"0"而不是0。ephemeral:指定卷在卸载后进行清理还是持久化。emptyDir的使用场景可以将这个值设置为 true,persistent volumes的使用场景可以将这个值设置为 false (例如 Cassandra 这样的数据库)true/false(默认为false)。这里需要填写字符串,即, 是"true"而不是true。
本地
特性状态:
Kubernetes v1.14 [stable]
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
本地卷还不支持动态制备,然而还是需要创建 StorageClass 以延迟卷绑定,
直到完成 Pod 的调度。这是由 WaitForFirstConsumer 卷绑定模式指定的。
延迟卷绑定使得调度器在为 PersistentVolumeClaim 选择一个合适的 PersistentVolume 时能考虑到所有 Pod 的调度限制。
6.6 - 动态卷制备
动态卷制备允许按需创建存储卷。
如果没有动态制备,集群管理员必须手动地联系他们的云或存储提供商来创建新的存储卷,
然后在 Kubernetes 集群创建
PersistentVolume 对象来表示这些卷。
动态制备功能消除了集群管理员预先配置存储的需要。相反,它在用户请求时自动制备存储。
背景
动态卷制备的实现基于 storage.k8s.io API 组中的 StorageClass API 对象。
集群管理员可以根据需要定义多个 StorageClass 对象,每个对象指定一个卷插件(又名 provisioner),
卷插件向卷制备商提供在创建卷时需要的数据卷信息及相关参数。
集群管理员可以在集群中定义和公开多种存储(来自相同或不同的存储系统),每种都具有自定义参数集。 该设计也确保终端用户不必担心存储制备的复杂性和细微差别,但仍然能够从多个存储选项中进行选择。
点击这里查阅有关存储类的更多信息。
启用动态卷制备
要启用动态制备功能,集群管理员需要为用户预先创建一个或多个 StorageClass 对象。
StorageClass 对象定义当动态制备被调用时,哪一个驱动将被使用和哪些参数将被传递给驱动。
StorageClass 对象的名字必须是一个合法的
DNS 子域名。
以下清单创建了一个 StorageClass 存储类 "slow",它提供类似标准磁盘的永久磁盘。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
以下清单创建了一个 "fast" 存储类,它提供类似 SSD 的永久磁盘。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
使用动态卷制备
用户通过在 PersistentVolumeClaim 中包含存储类来请求动态制备的存储。
在 Kubernetes v1.9 之前,这通过 volume.beta.kubernetes.io/storage-class 注解实现。
然而,这个注解自 v1.6 起就不被推荐使用了。
用户现在能够而且应该使用 PersistentVolumeClaim 对象的 storageClassName 字段。
这个字段的值必须能够匹配到集群管理员配置的 StorageClass 名称(见下面)。
例如,要选择 “fast” 存储类,用户将创建如下的 PersistentVolumeClaim:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: fast
resources:
requests:
storage: 30Gi
该声明会自动制备一块类似 SSD 的永久磁盘。 在删除该声明后,这个卷也会被销毁。
设置默认值的行为
可以在集群上启用动态卷制备,以便在未指定存储类的情况下动态设置所有声明。 集群管理员可以通过以下方式启用此行为:
- 标记一个
StorageClass为 默认; - 确保
DefaultStorageClass准入控制器在 API 服务器端被启用。
管理员可以通过向其添加
storageclass.kubernetes.io/is-default-class 注解
来将特定的 StorageClass 标记为默认。
当集群中存在默认的 StorageClass 并且用户创建了一个未指定 storageClassName 的 PersistentVolumeClaim 时,
DefaultStorageClass 准入控制器会自动向其中添加指向默认存储类的 storageClassName 字段。
请注意,如果你在集群的多个 StorageClass 设置 storageclass.kubernetes.io/is-default-class 注解为 true,
并之后创建了未指定 storageClassName 的 PersistentVolumeClaim,
Kubernetes 会使用最新创建的默认 StorageClass。
拓扑感知
在多可用区集群中,Pod 可以被分散到某个区域的多个可用区。 单可用区存储后端应该被制备到 Pod 被调度到的可用区。 这可以通过设置卷绑定模式来实现。
6.7 - 卷快照
在 Kubernetes 中,卷快照 是一个存储系统上卷的快照,本文假设你已经熟悉了 Kubernetes 的持久卷。
介绍
与 PersistentVolume 和 PersistentVolumeClaim 这两个 API 资源用于给用户和管理员制备卷类似,
VolumeSnapshotContent 和 VolumeSnapshot 这两个 API 资源用于给用户和管理员创建卷快照。
VolumeSnapshotContent 是从一个卷获取的一种快照,该卷由管理员在集群中进行制备。
就像持久卷(PersistentVolume)是集群的资源一样,它也是集群中的资源。
VolumeSnapshot 是用户对于卷的快照的请求。它类似于持久卷声明(PersistentVolumeClaim)。
VolumeSnapshotClass 允许指定属于 VolumeSnapshot 的不同属性。在从存储系统的相同卷上获取的快照之间,
这些属性可能有所不同,因此不能通过使用与 PersistentVolumeClaim 相同的 StorageClass 来表示。
卷快照能力为 Kubernetes 用户提供了一种标准的方式来在指定时间点复制卷的内容,并且不需要创建全新的卷。 例如,这一功能使得数据库管理员能够在执行编辑或删除之类的修改之前对数据库执行备份。
当使用该功能时,用户需要注意以下几点:
- API 对象
VolumeSnapshot,VolumeSnapshotContent和VolumeSnapshotClass是 CRD, 不属于核心 API。 VolumeSnapshot支持仅可用于 CSI 驱动。- 作为
VolumeSnapshot部署过程的一部分,Kubernetes 团队提供了一个部署于控制平面的快照控制器, 并且提供了一个叫做csi-snapshotter的边车(Sidecar)辅助容器,和 CSI 驱动程序一起部署。 快照控制器监视VolumeSnapshot和VolumeSnapshotContent对象, 并且负责创建和删除VolumeSnapshotContent对象。 边车 csi-snapshotter 监视VolumeSnapshotContent对象, 并且触发针对 CSI 端点的CreateSnapshot和DeleteSnapshot的操作。 - 还有一个验证性质的 Webhook 服务器,可以对快照对象进行更严格的验证。 Kubernetes 发行版应将其与快照控制器和 CRD(而非 CSI 驱动程序)一起安装。 此服务器应该安装在所有启用了快照功能的 Kubernetes 集群中。
- CSI 驱动可能实现,也可能没有实现卷快照功能。CSI 驱动可能会使用 csi-snapshotter 来提供对卷快照的支持。详见 CSI 驱动程序文档
- Kubernetes 负责 CRD 和快照控制器的安装。
卷快照和卷快照内容的生命周期
VolumeSnapshotContents 是集群中的资源。VolumeSnapshots 是对于这些资源的请求。
VolumeSnapshotContents 和 VolumeSnapshots 之间的交互遵循以下生命周期:
制备卷快照
快照可以通过两种方式进行制备:预制备或动态制备。
预制备
集群管理员创建多个 VolumeSnapshotContents。它们带有存储系统上实际卷快照的详细信息,可以供集群用户使用。
它们存在于 Kubernetes API 中,并且能够被使用。
动态制备
可以从 PersistentVolumeClaim 中动态获取快照,而不用使用已经存在的快照。
在获取快照时,卷快照类
指定要用的特定于存储提供程序的参数。
绑定
在预制备和动态制备场景下,快照控制器处理绑定 VolumeSnapshot 对象和其合适的 VolumeSnapshotContent 对象。
绑定关系是一对一的。
在预制备快照绑定场景下,VolumeSnapshotContent 对象创建之后,才会和 VolumeSnapshot 进行绑定。
快照源的持久性卷声明保护
这种保护的目的是确保在从系统中获取快照时,不会将正在使用的 PersistentVolumeClaim API 对象从系统中删除(因为这可能会导致数据丢失)。
在为某 PersistentVolumeClaim 生成快照时,该 PersistentVolumeClaim 处于被使用状态。
如果删除一个正作为快照源使用的 PersistentVolumeClaim API 对象,该 PersistentVolumeClaim 对象不会立即被移除。
相反,移除 PersistentVolumeClaim 对象的动作会被推迟,直到快照状态变为 ReadyToUse 或快照操作被中止时再执行。
删除
删除 VolumeSnapshot 对象触发删除 VolumeSnapshotContent 操作,并且 DeletionPolicy 会紧跟着执行。
如果 DeletionPolicy 是 Delete,那么底层存储快照会和 VolumeSnapshotContent 一起被删除。
如果 DeletionPolicy 是 Retain,那么底层快照和 VolumeSnapshotContent 都会被保留。
卷快照
每个 VolumeSnapshot 包含一个 spec 和一个 status。
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: new-snapshot-test
spec:
volumeSnapshotClassName: csi-hostpath-snapclass
source:
persistentVolumeClaimName: pvc-test
persistentVolumeClaimName 是 PersistentVolumeClaim 数据源对快照的名称。
这个字段是动态制备快照中的必填字段。
卷快照可以通过指定 VolumeSnapshotClass
使用 volumeSnapshotClassName 属性来请求特定类。如果没有设置,那么使用默认类(如果有)。
如下面例子所示,对于预制备的快照,需要给快照指定 volumeSnapshotContentName 作为来源。
对于预制备的快照 source 中的volumeSnapshotContentName 字段是必填的。
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: test-snapshot
spec:
source:
volumeSnapshotContentName: test-content
卷快照内容
每个 VolumeSnapshotContent 对象包含 spec 和 status。
在动态制备时,快照通用控制器创建 VolumeSnapshotContent 对象。下面是例子:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: snapcontent-72d9a349-aacd-42d2-a240-d775650d2455
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
volumeHandle: ee0cfb94-f8d4-11e9-b2d8-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotClassName: csi-hostpath-snapclass
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
uid: 72d9a349-aacd-42d2-a240-d775650d2455
volumeHandle 是存储后端创建卷的唯一标识符,在卷创建期间由 CSI 驱动程序返回。
动态设置快照需要此字段。它指出了快照的卷源。
对于预制备快照,你(作为集群管理员)要按如下命令来创建 VolumeSnapshotContent 对象。
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: new-snapshot-content-test
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
snapshotHandle 是存储后端创建卷的唯一标识符。对于预制备的快照,这个字段是必需的。
它指定此 VolumeSnapshotContent 表示的存储系统上的 CSI 快照 ID。
sourceVolumeMode 是创建快照的卷的模式。sourceVolumeMode 字段的值可以是
Filesystem 或 Block。如果没有指定源卷模式,Kubernetes 会将快照视为未知的源卷模式。
volumeSnapshotRef 字段是对相应的 VolumeSnapshot 的引用。
请注意,当 VolumeSnapshotContent 被创建为预配置快照时。
volumeSnapshotRef 中引用的 VolumeSnapshot 可能还不存在。
转换快照的卷模式
如果在你的集群上安装的 VolumeSnapshots API 支持 sourceVolumeMode
字段,则该 API 可以防止未经授权的用户转换卷的模式。
要检查你的集群是否具有此特性的能力,可以运行如下命令:
kubectl get crd volumesnapshotcontent -o yaml
如果你希望允许用户从现有的 VolumeSnapshot 创建 PersistentVolumeClaim,
但是使用与源卷不同的卷模式,则需要添加注解
snapshot.storage.kubernetes.io/allow-volume-mode-change: "true"
到对应 VolumeSnapshot 的 VolumeSnapshotContent 中。
对于预制备的快照,spec.sourceVolumeMode 需要由集群管理员填充。
启用此特性的 VolumeSnapshotContent 资源示例如下所示:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotContent
metadata:
name: new-snapshot-content-test
annotations:
- snapshot.storage.kubernetes.io/allow-volume-mode-change: "true"
spec:
deletionPolicy: Delete
driver: hostpath.csi.k8s.io
source:
snapshotHandle: 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode: Filesystem
volumeSnapshotRef:
name: new-snapshot-test
namespace: default
从快照制备卷
你可以制备一个新卷,该卷预填充了快照中的数据,在 PersistentVolumeClaim 对象中使用 dataSource 字段。
更多详细信息, 请参阅卷快照和从快照还原卷。
6.8 - 卷快照类
本文档描述了 Kubernetes 中 VolumeSnapshotClass 的概念。建议熟悉 卷快照(Volume Snapshots)和 存储类(Storage Class)。
介绍
就像 StorageClass 为管理员提供了一种在配置卷时描述存储“类”的方法, VolumeSnapshotClass 提供了一种在配置卷快照时描述存储“类”的方法。
VolumeSnapshotClass 资源
每个 VolumeSnapshotClass 都包含 driver、deletionPolicy 和 parameters 字段,
在需要动态配置属于该类的 VolumeSnapshot 时使用。
VolumeSnapshotClass 对象的名称很重要,是用户可以请求特定类的方式。 管理员在首次创建 VolumeSnapshotClass 对象时设置类的名称和其他参数, 对象一旦创建就无法更新。
说明: CRD 的安装是 Kubernetes 发行版的责任。 如果不存在所需的 CRD,则 VolumeSnapshotClass 的创建将失败。
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-hostpath-snapclass
driver: hostpath.csi.k8s.io
deletionPolicy: Delete
parameters:
管理员可以为未请求任何特定类绑定的 VolumeSnapshots 指定默认的 VolumeSnapshotClass,
方法是设置注解 snapshot.storage.kubernetes.io/is-default-class: "true":
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-hostpath-snapclass
annotations:
snapshot.storage.kubernetes.io/is-default-class: "true"
driver: hostpath.csi.k8s.io
deletionPolicy: Delete
parameters:
驱动程序
卷快照类有一个驱动程序,用于确定配置 VolumeSnapshot 的 CSI 卷插件。 此字段必须指定。
删除策略
卷快照类具有 deletionPolicy 属性。
用户可以配置当所绑定的 VolumeSnapshot 对象将被删除时,如何处理 VolumeSnapshotContent 对象。
卷快照类的这个策略可以是 Retain 或者 Delete。这个策略字段必须指定。
如果删除策略是 Delete,那么底层的存储快照会和 VolumeSnapshotContent 对象
一起删除。如果删除策略是 Retain,那么底层快照和 VolumeSnapshotContent
对象都会被保留。
参数
卷快照类具有描述属于该卷快照类的卷快照的参数,可根据 driver 接受不同的参数。
6.9 - CSI 卷克隆
本文档介绍 Kubernetes 中克隆现有 CSI 卷的概念。阅读前建议先熟悉 卷。
介绍
CSI 卷克隆功能增加了通过在
dataSource 字段中指定存在的
PVC,
来表示用户想要克隆的 卷(Volume)。
克隆(Clone),意思是为已有的 Kubernetes 卷创建副本,它可以像任何其它标准卷一样被使用。 唯一的区别就是配置后,后端设备将创建指定完全相同的副本,而不是创建一个“新的”空卷。
从 Kubernetes API 的角度看,克隆的实现只是在创建新的 PVC 时, 增加了指定一个现有 PVC 作为数据源的能力。源 PVC 必须是 bound 状态且可用的(不在使用中)。
用户在使用该功能时,需要注意以下事项:
- 克隆支持(
VolumePVCDataSource)仅适用于 CSI 驱动。 - 克隆支持仅适用于 动态供应器。
- CSI 驱动可能实现,也可能未实现卷克隆功能。
- 仅当 PVC 与目标 PVC 存在于同一命名空间(源和目标 PVC 必须在相同的命名空间)时,才可以克隆 PVC。
- 支持用一个不同存储类进行克隆。
- 目标卷和源卷可以是相同的存储类,也可以不同。
- 可以使用默认的存储类,也可以在 spec 中省略 storageClassName 字段。
- 克隆只能在两个使用相同 VolumeMode 设置的卷中进行 (如果请求克隆一个块存储模式的卷,源卷必须也是块存储模式)。
制备
克隆卷与其他任何 PVC 一样配置,除了需要增加 dataSource 来引用同一命名空间中现有的 PVC。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: clone-of-pvc-1
namespace: myns
spec:
accessModes:
- ReadWriteOnce
storageClassName: cloning
resources:
requests:
storage: 5Gi
dataSource:
kind: PersistentVolumeClaim
name: pvc-1
说明:
你必须为 spec.resources.requests.storage 指定一个值,并且你指定的值必须大于或等于源卷的值。
结果是一个名称为 clone-of-pvc-1 的新 PVC 与指定的源 pvc-1 拥有相同的内容。
使用
一旦新的 PVC 可用,被克隆的 PVC 像其他 PVC 一样被使用。 可以预期的是,新创建的 PVC 是一个独立的对象。 可以独立使用、克隆、快照或删除它,而不需要考虑它的原始数据源 PVC。 这也意味着,源没有以任何方式链接到新创建的 PVC,它也可以被修改或删除,而不会影响到新创建的克隆。
6.10 - 存储容量
存储容量是有限的,并且会因为运行 Pod 的节点不同而变化: 网络存储可能并非所有节点都能够访问,或者对于某个节点存储是本地的。
特性状态:
Kubernetes v1.24 [stable]
本页面描述了 Kubernetes 如何跟踪存储容量以及调度程序如何为了余下的尚未挂载的卷使用该信息将 Pod 调度到能够访问到足够存储容量的节点上。 如果没有跟踪存储容量,调度程序可能会选择一个没有足够容量来提供卷的节点,并且需要多次调度重试。
准备开始
Kubernetes v1.29 包含了对存储容量跟踪的集群级 API 支持。 要使用它,你还必须使用支持容量跟踪的 CSI 驱动程序。请查阅你使用的 CSI 驱动程序的文档, 以了解此支持是否可用,如果可用,该如何使用它。如果你运行的不是 Kubernetes v1.29,请查看对应版本的 Kubernetes 文档。
API
这个特性有两个 API 扩展接口:
- CSIStorageCapacity 对象:这些对象由 CSI 驱动程序在安装驱动程序的命名空间中产生。 每个对象都包含一个存储类的容量信息,并定义哪些节点可以访问该存储。
CSIDriverSpec.StorageCapacity字段: 设置为 true 时,Kubernetes 调度程序将考虑使用 CSI 驱动程序的卷的存储容量。
调度
如果有以下情况,存储容量信息将会被 Kubernetes 调度程序使用:
- Pod 使用的卷还没有被创建,
- 卷使用引用了 CSI 驱动的 StorageClass,
并且使用了
WaitForFirstConsumer卷绑定模式, - 驱动程序的
CSIDriver对象的StorageCapacity被设置为 true。
在这种情况下,调度程序仅考虑将 Pod 调度到有足够存储容量的节点上。这个检测非常简单,
仅将卷的大小与 CSIStorageCapacity 对象中列出的容量进行比较,并使用包含该节点的拓扑。
对于具有 Immediate 卷绑定模式的卷,存储驱动程序将决定在何处创建该卷,而不取决于将使用该卷的 Pod。
然后,调度程序将 Pod 调度到创建卷后可使用该卷的节点上。
对于 CSI 临时卷, 调度总是在不考虑存储容量的情况下进行。 这是基于这样的假设:该卷类型仅由节点本地的特殊 CSI 驱动程序使用,并且不需要大量资源。
重新调度
当为带有 WaitForFirstConsumer 的卷的 Pod 来选择节点时,该决定仍然是暂定的。
下一步是要求 CSI 存储驱动程序创建卷,并提示该卷在被选择的节点上可用。
因为 Kubernetes 可能会根据已经过时的存储容量信息来选择一个节点,因此可能无法真正创建卷。 然后就会重置节点选择,Kubernetes 调度器会再次尝试为 Pod 查找节点。
限制
存储容量跟踪增加了调度器第一次尝试即成功的机会,但是并不能保证这一点,因为调度器必须根据可能过期的信息来进行决策。 通常,与没有任何存储容量信息的调度相同的重试机制可以处理调度失败。
当 Pod 使用多个卷时,调度可能会永久失败:一个卷可能已经在拓扑段中创建,而该卷又没有足够的容量来创建另一个卷, 要想从中恢复,必须要进行手动干预,比如通过增加存储容量或者删除已经创建的卷。
接下来
- 想要获得更多该设计的信息,查看 Storage Capacity Constraints for Pod Scheduling KEP。
6.11 - 特定于节点的卷数限制
此页面描述了各个云供应商可关联至一个节点的最大卷数。
谷歌、亚马逊和微软等云供应商通常对可以关联到节点的卷数量进行限制。 Kubernetes 需要尊重这些限制。否则,在节点上调度的 Pod 可能会卡住去等待卷的关联。
Kubernetes 的默认限制
The Kubernetes 调度器对关联于一个节点的卷数有默认限制:
| 云服务 | 每节点最大卷数 |
|---|---|
| Amazon Elastic Block Store (EBS) | 39 |
| Google Persistent Disk | 16 |
| Microsoft Azure Disk Storage | 16 |
自定义限制
你可以通过设置 KUBE_MAX_PD_VOLS 环境变量的值来设置这些限制,然后再启动调度器。
CSI 驱动程序可能具有不同的过程,关于如何自定义其限制请参阅相关文档。
如果设置的限制高于默认限制,请谨慎使用。请参阅云提供商的文档以确保节点可支持你设置的限制。
此限制应用于整个集群,所以它会影响所有节点。
动态卷限制
特性状态:
Kubernetes v1.17 [stable]
以下卷类型支持动态卷限制。
- Amazon EBS
- Google Persistent Disk
- Azure Disk
- CSI
对于由内建插件管理的卷,Kubernetes 会自动确定节点类型并确保节点上可关联的卷数目合规。例如:
-
在 Google Compute Engine环境中, 根据节点类型最多可以将 127 个卷关联到节点。
-
对于 M5、C5、R5、T3 和 Z1D 类型实例的 Amazon EBS 磁盘,Kubernetes 仅允许 25 个卷关联到节点。 对于 ec2 上的其他实例类型 Amazon Elastic Compute Cloud (EC2), Kubernetes 允许 39 个卷关联至节点。
-
在 Azure 环境中, 根据节点类型,最多 64 个磁盘可以关联至一个节点。 更多详细信息,请参阅 Azure 虚拟机的数量大小。
-
如果 CSI 存储驱动程序(使用
NodeGetInfo)为节点通告卷数上限,则 kube-scheduler 将遵守该限制值。 参考 CSI 规范 获取更多详细信息。 -
对于由已迁移到 CSI 驱动程序的树内插件管理的卷,最大卷数将是 CSI 驱动程序报告的卷数。
6.12 - 卷健康监测
特性状态:
Kubernetes v1.21 [alpha]
CSI 卷健康监测支持 CSI 驱动从底层的存储系统着手, 探测异常的卷状态,并以事件的形式上报到 PVC 或 Pod.
卷健康监测
Kubernetes 卷健康监测是 Kubernetes 容器存储接口(CSI)实现的一部分。 卷健康监测特性由两个组件实现:外部健康监测控制器和 kubelet。
如果 CSI 驱动器通过控制器的方式支持卷健康监测特性,那么只要在 CSI 卷上监测到异常卷状态,就会在 PersistentVolumeClaim (PVC) 中上报一个事件。
外部健康监测控制器也会监测节点失效事件。
如果要启动节点失效监测功能,你可以设置标志 enable-node-watcher 为 true。
当外部健康监测器检测到节点失效事件,控制器会报送一个事件,该事件会在 PVC 上继续上报,
以表明使用此 PVC 的 Pod 正位于一个失效的节点上。
如果 CSI 驱动程序支持节点测的卷健康检测,那当在 CSI 卷上检测到异常卷时,
会在使用该 PVC 的每个 Pod 上触发一个事件。
此外,卷运行状况信息作为 Kubelet VolumeStats 指标公开。
添加了一个新的指标 kubelet_volume_stats_health_status_abnormal。
该指标包括两个标签:namespace 和 persistentvolumeclaim。
计数为 1 或 0。1 表示卷不正常,0 表示卷正常。更多信息请访问
KEP。
说明: 你需要启用
CSIVolumeHealth
特性门控,
才能在节点上使用此特性。
接下来
参阅 CSI 驱动程序文档, 可以找出有哪些 CSI 驱动程序实现了此特性。
6.13 - Windows 存储
此页面提供特定于 Windows 操作系统的存储概述。
持久存储
Windows 有一个分层文件系统驱动程序用来挂载容器层和创建基于 NTFS 的文件系统拷贝。 容器中的所有文件路径仅在该容器的上下文中解析。
- 使用 Docker 时,卷挂载只能是容器中的目录,而不能是单个文件。此限制不适用于 containerd。
- 卷挂载不能将文件或目录映射回宿主文件系统。
- 不支持只读文件系统,因为 Windows 注册表和 SAM 数据库始终需要写访问权限。不过,Windows 支持只读的卷。
- 不支持卷的用户掩码和访问许可,因为宿主与容器之间并不共享 SAM,二者之间不存在映射关系。 所有访问许可都是在容器上下文中解析的。
因此,Windows 节点不支持以下存储功能:
- 卷子路径挂载:只能在 Windows 容器上挂载整个卷
- Secret 的子路径挂载
- 宿主挂载映射
- 只读的根文件系统(映射的卷仍然支持
readOnly) - 块设备映射
- 内存作为存储介质(例如
emptyDir.medium设置为Memory) - 类似 UID/GID、各用户不同的 Linux 文件系统访问许可等文件系统特性
- 使用 DefaultMode 设置 Secret 权限 (因为该特性依赖 UID/GID)
- 基于 NFS 的存储和卷支持
- 扩展已挂载卷(resizefs)
使用 Kubernetes 卷, 对数据持久性和 Pod 卷共享有需求的复杂应用也可以部署到 Kubernetes 上。 管理与特定存储后端或协议相关的持久卷时,相关的操作包括:对卷的制备(Provisioning)、 去配(De-provisioning)和调整大小,将卷挂接到 Kubernetes 节点或从节点上解除挂接, 将卷挂载到需要持久数据的 Pod 中的某容器上或从容器上卸载。
卷管理组件作为 Kubernetes 卷插件发布。 Windows 支持以下类型的 Kubernetes 卷插件:
FlexVolume plugins- 请注意自 1.23 版本起,FlexVolume 已被弃用
CSI Plugins
树内(In-Tree)卷插件
以下树内(In-Tree)插件支持 Windows 节点上的持久存储:
7 - 配置
Kubernetes 为配置 Pods 提供的资源。
7.1 - 配置最佳实践
本文档重点介绍并整合了整个用户指南、入门文档和示例中介绍的配置最佳实践。
这是一份不断改进的文件。 如果你认为某些内容缺失但可能对其他人有用,请不要犹豫,提交 Issue 或提交 PR。
一般配置提示
- 定义配置时,请指定最新的稳定 API 版本。
- 在推送到集群之前,配置文件应存储在版本控制中。 这允许你在必要时快速回滚配置更改。 它还有助于集群重新创建和恢复。
- 使用 YAML 而不是 JSON 编写配置文件。虽然这些格式几乎可以在所有场景中互换使用,但 YAML 往往更加用户友好。
- 只要有意义,就将相关对象分组到一个文件中。一个文件通常比几个文件更容易管理。 请参阅 guestbook-all-in-one.yaml 文件作为此语法的示例。
- 另请注意,可以在目录上调用许多
kubectl命令。 例如,你可以在配置文件的目录中调用kubectl apply。
- 除非必要,否则不指定默认值:简单的最小配置会降低错误的可能性。
- 将对象描述放在注释中,以便更好地进行内省。
说明:
相较于 YAML 1.1, YAML 1.2 在布尔值规范中引入了一个破坏性的变更。 这是 Kubernetes 中的一个已知问题。 YAML 1.2 仅识别 true 和 false 作为有效的布尔值,而 YAML 1.1 还可以接受 yes、no、on 和 off 作为布尔值。 然而,Kubernetes 正在使用的 YAML 解析器 与 YAML 1.1 基本兼容, 这意味着在 YAML 清单中使用 yes 或 no 而不是 true 或 false 可能会导致意外的错误或行为。 为避免此类问题,建议在 YAML 清单中始终使用 true 或 false 作为布尔值, 并对任何可能与布尔值混淆的字符串进行引号标记,例如 "yes" 或 "no"。
除了布尔值之外,YAML 版本之间还存在其他的规范变化。 请参考 YAML 规范变更文档来获取完整列表。
“独立的“ Pod 与 ReplicaSet、Deployment 和 Job
-
如果可能,不要使用独立的 Pod(即,未绑定到 ReplicaSet 或 Deployment 的 Pod)。 如果节点发生故障,将不会重新调度这些独立的 Pod。
Deployment 既可以创建一个 ReplicaSet 来确保预期个数的 Pod 始终可用,也可以指定替换 Pod 的策略(例如 RollingUpdate)。 除了一些显式的
restartPolicy: Never场景外,Deployment 通常比直接创建 Pod 要好得多。 Job 也可能是合适的选择。
服务
-
在创建相应的后端工作负载(Deployment 或 ReplicaSet),以及在需要访问它的任何工作负载之前创建 服务。 当 Kubernetes 启动容器时,它提供指向启动容器时正在运行的所有服务的环境变量。 例如,如果存在名为
foo的服务,则所有容器将在其初始环境中获得以下变量。FOO_SERVICE_HOST=<the host the Service is running on> FOO_SERVICE_PORT=<the port the Service is running on>这确实意味着在顺序上的要求 - 必须在
Pod本身被创建之前创建Pod想要访问的任何Service, 否则将环境变量不会生效。DNS 没有此限制。
- 一个可选(尽管强烈推荐)的集群插件
是 DNS 服务器。DNS 服务器为新的
Services监视 Kubernetes API,并为每个创建一组 DNS 记录。 如果在整个集群中启用了 DNS,则所有Pod应该能够自动对Services进行名称解析。
-
不要为 Pod 指定
hostPort,除非非常有必要这样做。 当你为 Pod 绑定了hostPort,那么能够运行该 Pod 的节点就有限了,因为每个<hostIP, hostPort, protocol>组合必须是唯一的。 如果你没有明确指定hostIP和protocol, Kubernetes 将使用0.0.0.0作为默认的hostIP,使用TCP作为默认的protocol。如果你只需要访问端口以进行调试,则可以使用 apiserver proxy 或
kubectl port-forward。如果你明确需要在节点上公开 Pod 的端口,请在使用
hostPort之前考虑使用 NodePort 服务。
- 避免使用
hostNetwork,原因与hostPort相同。
- 当你不需要
kube-proxy负载均衡时, 使用无头服务 (ClusterIP被设置为None)进行服务发现。
使用标签
-
定义并使用标签来识别应用程序 或 Deployment 的语义属性,例如
{ app.kubernetes.io/name: MyApp, tier: frontend, phase: test, deployment: v3 }。 你可以使用这些标签为其他资源选择合适的 Pod; 例如,一个选择所有tier: frontendPod 的服务,或者app.kubernetes.io/name: MyApp的所有phase: test组件。 有关此方法的示例,请参阅 guestbook 。通过从选择器中省略特定发行版的标签,可以使服务跨越多个 Deployment。 当你需要不停机的情况下更新正在运行的服务,可以使用 Deployment。
Deployment 描述了对象的期望状态,并且如果对该规约的更改被成功应用,则 Deployment 控制器以受控速率将实际状态改变为期望状态。
- 对于常见场景,应使用 Kubernetes 通用标签。
这些标准化的标签丰富了对象的元数据,使得包括
kubectl和 仪表板(Dashboard) 这些工具能够以可互操作的方式工作。
- 你可以操纵标签进行调试。
由于 Kubernetes 控制器(例如 ReplicaSet)和服务使用选择器标签来匹配 Pod,
从 Pod 中删除相关标签将阻止其被控制器考虑或由服务提供服务流量。
如果删除现有 Pod 的标签,其控制器将创建一个新的 Pod 来取代它。
这是在“隔离“环境中调试先前“活跃“的 Pod 的有用方法。
要以交互方式删除或添加标签,请使用
kubectl label。
使用 kubectl
- 使用
kubectl apply -f <目录>。 它在<目录>中的所有.yaml、.yml和.json文件中查找 Kubernetes 配置,并将其传递给apply。
- 使用
kubectl create deployment和kubectl expose来快速创建单容器 Deployment 和 Service。 有关示例,请参阅使用服务访问集群中的应用程序。
7.2 - ConfigMap
ConfigMap 是一种 API 对象,用来将非机密性的数据保存到键值对中。使用时, Pod 可以将其用作环境变量、命令行参数或者存储卷中的配置文件。
ConfigMap 将你的环境配置信息和容器镜像解耦,便于应用配置的修改。
注意:
ConfigMap 并不提供保密或者加密功能。 如果你想存储的数据是机密的,请使用 Secret, 或者使用其他第三方工具来保证你的数据的私密性,而不是用 ConfigMap。
动机
使用 ConfigMap 来将你的配置数据和应用程序代码分开。
比如,假设你正在开发一个应用,它可以在你自己的电脑上(用于开发)和在云上
(用于实际流量)运行。
你的代码里有一段是用于查看环境变量 DATABASE_HOST,在本地运行时,
你将这个变量设置为 localhost,在云上,你将其设置为引用 Kubernetes 集群中的
公开数据库组件的 服务。
这让你可以获取在云中运行的容器镜像,并且如果有需要的话,在本地调试完全相同的代码。
说明:
ConfigMap 在设计上不是用来保存大量数据的。在 ConfigMap 中保存的数据不可超过 1 MiB。如果你需要保存超出此尺寸限制的数据,你可能希望考虑挂载存储卷 或者使用独立的数据库或者文件服务。
ConfigMap 对象
ConfigMap 是一个让你可以存储其他对象所需要使用的配置的 API 对象。
和其他 Kubernetes 对象都有一个 spec 不同的是,ConfigMap 使用 data 和
binaryData 字段。这些字段能够接收键-值对作为其取值。data 和 binaryData
字段都是可选的。data 字段设计用来保存 UTF-8 字符串,而 binaryData
则被设计用来保存二进制数据作为 base64 编码的字串。
ConfigMap 的名字必须是一个合法的 DNS 子域名。
data 或 binaryData 字段下面的每个键的名称都必须由字母数字字符或者
-、_ 或 . 组成。在 data 下保存的键名不可以与在 binaryData
下出现的键名有重叠。
从 v1.19 开始,你可以添加一个 immutable 字段到 ConfigMap 定义中,
创建不可变更的 ConfigMap。
ConfigMaps 和 Pods
你可以写一个引用 ConfigMap 的 Pod 的 spec,并根据 ConfigMap 中的数据在该
Pod 中配置容器。这个 Pod 和 ConfigMap 必须要在同一个
名字空间 中。
说明: 静态 Pod 中的
spec
字段不能引用 ConfigMap 或任何其他 API 对象。
这是一个 ConfigMap 的示例,它的一些键只有一个值,其他键的值看起来像是 配置的片段格式。
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# 类属性键;每一个键都映射到一个简单的值
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# 类文件键
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
你可以使用四种方式来使用 ConfigMap 配置 Pod 中的容器:
- 在容器命令和参数内
- 容器的环境变量
- 在只读卷里面添加一个文件,让应用来读取
- 编写代码在 Pod 中运行,使用 Kubernetes API 来读取 ConfigMap
这些不同的方法适用于不同的数据使用方式。 对前三个方法,kubelet 使用 ConfigMap 中的数据在 Pod 中启动容器。
第四种方法意味着你必须编写代码才能读取 ConfigMap 和它的数据。然而, 由于你是直接使用 Kubernetes API,因此只要 ConfigMap 发生更改, 你的应用就能够通过订阅来获取更新,并且在这样的情况发生的时候做出反应。 通过直接进入 Kubernetes API,这个技术也可以让你能够获取到不同的名字空间里的 ConfigMap。
下面是一个 Pod 的示例,它通过使用 game-demo 中的值来配置一个 Pod:
apiVersion: v1
kind: Pod
metadata:
name: configmap-demo-pod
spec:
containers:
- name: demo
image: alpine
command: ["sleep", "3600"]
env:
# 定义环境变量
- name: PLAYER_INITIAL_LIVES # 请注意这里和 ConfigMap 中的键名是不一样的
valueFrom:
configMapKeyRef:
name: game-demo # 这个值来自 ConfigMap
key: player_initial_lives # 需要取值的键
- name: UI_PROPERTIES_FILE_NAME
valueFrom:
configMapKeyRef:
name: game-demo
key: ui_properties_file_name
volumeMounts:
- name: config
mountPath: "/config"
readOnly: true
volumes:
# 你可以在 Pod 级别设置卷,然后将其挂载到 Pod 内的容器中
- name: config
configMap:
# 提供你想要挂载的 ConfigMap 的名字
name: game-demo
# 来自 ConfigMap 的一组键,将被创建为文件
items:
- key: "game.properties"
path: "game.properties"
- key: "user-interface.properties"
path: "user-interface.properties"
ConfigMap 不会区分单行属性值和多行类似文件的值,重要的是 Pods 和其他对象如何使用这些值。
上面的例子定义了一个卷并将它作为 /config 文件夹挂载到 demo 容器内,
创建两个文件,/config/game.properties 和
/config/user-interface.properties,
尽管 ConfigMap 中包含了四个键。
这是因为 Pod 定义中在 volumes 节指定了一个 items 数组。
如果你完全忽略 items 数组,则 ConfigMap 中的每个键都会变成一个与该键同名的文件,
因此你会得到四个文件。
使用 ConfigMap
ConfigMap 可以作为数据卷挂载。ConfigMap 也可被系统的其他组件使用, 而不一定直接暴露给 Pod。例如,ConfigMap 可以保存系统中其他组件要使用的配置数据。
ConfigMap 最常见的用法是为同一命名空间里某 Pod 中运行的容器执行配置。 你也可以单独使用 ConfigMap。
比如,你可能会遇到基于 ConfigMap 来调整其行为的 插件 或者 operator。
在 Pod 中将 ConfigMap 当做文件使用
要在一个 Pod 的存储卷中使用 ConfigMap:
- 创建一个 ConfigMap 对象或者使用现有的 ConfigMap 对象。多个 Pod 可以引用同一个 ConfigMap。
- 修改 Pod 定义,在
spec.volumes[]下添加一个卷。 为该卷设置任意名称,之后将spec.volumes[].configMap.name字段设置为对你的 ConfigMap 对象的引用。 - 为每个需要该 ConfigMap 的容器添加一个
.spec.containers[].volumeMounts[]。 设置.spec.containers[].volumeMounts[].readOnly=true并将.spec.containers[].volumeMounts[].mountPath设置为一个未使用的目录名, ConfigMap 的内容将出现在该目录中。 - 更改你的镜像或者命令行,以便程序能够从该目录中查找文件。ConfigMap 中的每个
data键会变成mountPath下面的一个文件名。
下面是一个将 ConfigMap 以卷的形式进行挂载的 Pod 示例:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
configMap:
name: myconfigmap
你希望使用的每个 ConfigMap 都需要在 spec.volumes 中被引用到。
如果 Pod 中有多个容器,则每个容器都需要自己的 volumeMounts 块,但针对每个
ConfigMap,你只需要设置一个 spec.volumes 块。
被挂载的 ConfigMap 内容会被自动更新
当卷中使用的 ConfigMap 被更新时,所投射的键最终也会被更新。
kubelet 组件会在每次周期性同步时检查所挂载的 ConfigMap 是否为最新。
不过,kubelet 使用的是其本地的高速缓存来获得 ConfigMap 的当前值。
高速缓存的类型可以通过
KubeletConfiguration 结构.
的 configMapAndSecretChangeDetectionStrategy 字段来配置。
ConfigMap 既可以通过 watch 操作实现内容传播(默认形式),也可实现基于 TTL 的缓存,还可以直接经过所有请求重定向到 API 服务器。 因此,从 ConfigMap 被更新的那一刻算起,到新的主键被投射到 Pod 中去, 这一时间跨度可能与 kubelet 的同步周期加上高速缓存的传播延迟相等。 这里的传播延迟取决于所选的高速缓存类型 (分别对应 watch 操作的传播延迟、高速缓存的 TTL 时长或者 0)。
以环境变量方式使用的 ConfigMap 数据不会被自动更新。 更新这些数据需要重新启动 Pod。
说明: 使用 ConfigMap 作为 subPath 卷挂载的容器将不会收到 ConfigMap 的更新。
不可变更的 ConfigMap
特性状态:
Kubernetes v1.21 [stable]
Kubernetes 特性 Immutable Secret 和 ConfigMaps 提供了一种将各个 Secret 和 ConfigMap 设置为不可变更的选项。对于大量使用 ConfigMap 的集群 (至少有数万个各不相同的 ConfigMap 给 Pod 挂载)而言,禁止更改 ConfigMap 的数据有以下好处:
- 保护应用,使之免受意外(不想要的)更新所带来的负面影响。
- 通过大幅降低对 kube-apiserver 的压力提升集群性能, 这是因为系统会关闭对已标记为不可变更的 ConfigMap 的监视操作。
你可以通过将 immutable 字段设置为 true 创建不可变更的 ConfigMap。
例如:
apiVersion: v1
kind: ConfigMap
metadata:
...
data:
...
immutable: true
一旦某 ConfigMap 被标记为不可变更,则 无法 逆转这一变化,,也无法更改
data 或 binaryData 字段的内容。你只能删除并重建 ConfigMap。
因为现有的 Pod 会维护一个已被删除的 ConfigMap 的挂载点,建议重新创建这些 Pods。
接下来
- 阅读 Secret。
- 阅读配置 Pod 使用 ConfigMap。
- 阅读修改 ConfigMap(或任何其他 Kubernetes 对象)。
- 阅读 Twelve-Factor 应用来了解将代码和配置分开的动机。
7.3 - Secret
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象。 这样的信息可能会被放在 Pod 规约中或者镜像中。 使用 Secret 意味着你不需要在应用程序代码中包含机密数据。
由于创建 Secret 可以独立于使用它们的 Pod, 因此在创建、查看和编辑 Pod 的工作流程中暴露 Secret(及其数据)的风险较小。 Kubernetes 和在集群中运行的应用程序也可以对 Secret 采取额外的预防措施, 例如避免将敏感数据写入非易失性存储。
Secret 类似于 ConfigMap 但专门用于保存机密数据。
注意:
默认情况下,Kubernetes Secret 未加密地存储在 API 服务器的底层数据存储(etcd)中。 任何拥有 API 访问权限的人都可以检索或修改 Secret,任何有权访问 etcd 的人也可以。 此外,任何有权限在命名空间中创建 Pod 的人都可以使用该访问权限读取该命名空间中的任何 Secret; 这包括间接访问,例如创建 Deployment 的能力。
为了安全地使用 Secret,请至少执行以下步骤:
- 为 Secret 启用静态加密。
- 以最小特权访问 Secret 并启用或配置 RBAC 规则。
- 限制 Secret 对特定容器的访问。
- 考虑使用外部 Secret 存储驱动。
有关管理和提升 Secret 安全性的指南,请参阅 Kubernetes Secret 良好实践。
参见 Secret 的信息安全了解详情。
Secret 的使用
你可以将 Secret 用于以下场景:
Kubernetes 控制面也使用 Secret; 例如,引导令牌 Secret 是一种帮助自动化节点注册的机制。
使用场景:在 Secret 卷中带句点的文件
通过定义以句点(.)开头的主键,你可以“隐藏”你的数据。
这些主键代表的是以句点开头的文件或“隐藏”文件。
例如,当以下 Secret 被挂载到 secret-volume 卷上时,该卷中会包含一个名为
.secret-file 的文件,并且容器 dotfile-test-container
中此文件位于路径 /etc/secret-volume/.secret-file 处。
说明:
以句点开头的文件会在 ls -l 的输出中被隐藏起来;
列举目录内容时你必须使用 ls -la 才能看到它们。
apiVersion: v1
kind: Secret
metadata:
name: dotfile-secret
data:
.secret-file: dmFsdWUtMg0KDQo=
---
apiVersion: v1
kind: Pod
metadata:
name: secret-dotfiles-pod
spec:
volumes:
- name: secret-volume
secret:
secretName: dotfile-secret
containers:
- name: dotfile-test-container
image: registry.k8s.io/busybox
command:
- ls
- "-l"
- "/etc/secret-volume"
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"使用场景:仅对 Pod 中一个容器可见的 Secret
考虑一个需要处理 HTTP 请求,执行某些复杂的业务逻辑,之后使用 HMAC 来对某些消息进行签名的程序。因为这一程序的应用逻辑很复杂, 其中可能包含未被注意到的远程服务器文件读取漏洞, 这种漏洞可能会把私钥暴露给攻击者。
这一程序可以分隔成两个容器中的两个进程:前端容器要处理用户交互和业务逻辑, 但无法看到私钥;签名容器可以看到私钥,并对来自前端的简单签名请求作出响应 (例如,通过本地主机网络)。
采用这种划分的方法,攻击者现在必须欺骗应用服务器来做一些其他操作, 而这些操作可能要比读取一个文件要复杂很多。
Secret 的替代方案
除了使用 Secret 来保护机密数据,你也可以选择一些替代方案。
下面是一些选项:
- 如果你的云原生组件需要执行身份认证来访问你所知道的、在同一 Kubernetes 集群中运行的另一个应用, 你可以使用 ServiceAccount 及其令牌来标识你的客户端身份。
- 你可以运行的第三方工具也有很多,这些工具可以运行在集群内或集群外,提供机密数据管理。 例如,这一工具可能是 Pod 通过 HTTPS 访问的一个服务,该服务在客户端能够正确地通过身份认证 (例如,通过 ServiceAccount 令牌)时,提供机密数据内容。
- 就身份认证而言,你可以为 X.509 证书实现一个定制的签名者,并使用 CertificateSigningRequest 来让该签名者为需要证书的 Pod 发放证书。
- 你可以使用一个设备插件 来将节点本地的加密硬件暴露给特定的 Pod。例如,你可以将可信任的 Pod 调度到提供可信平台模块(Trusted Platform Module,TPM)的节点上。 这类节点是另行配置的。
你还可以将如上选项的两种或多种进行组合,包括直接使用 Secret 对象本身也是一种选项。
例如:实现(或部署)一个 operator, 从外部服务取回生命期很短的会话令牌,之后基于这些生命期很短的会话令牌来创建 Secret。 运行在集群中的 Pod 可以使用这些会话令牌,而 Operator 则确保这些令牌是合法的。 这种责权分离意味着你可以运行那些不了解会话令牌如何发放与刷新的确切机制的 Pod。
Secret 的类型
创建 Secret 时,你可以使用 Secret
资源的 type 字段,或者与其等价的 kubectl 命令行参数(如果有的话)为其设置类型。
Secret 类型有助于对 Secret 数据进行编程处理。
Kubernetes 提供若干种内置的类型,用于一些常见的使用场景。 针对这些类型,Kubernetes 所执行的合法性检查操作以及对其所实施的限制各不相同。
| 内置类型 | 用法 |
|---|---|
Opaque |
用户定义的任意数据 |
kubernetes.io/service-account-token |
服务账号令牌 |
kubernetes.io/dockercfg |
~/.dockercfg 文件的序列化形式 |
kubernetes.io/dockerconfigjson |
~/.docker/config.json 文件的序列化形式 |
kubernetes.io/basic-auth |
用于基本身份认证的凭据 |
kubernetes.io/ssh-auth |
用于 SSH 身份认证的凭据 |
kubernetes.io/tls |
用于 TLS 客户端或者服务器端的数据 |
bootstrap.kubernetes.io/token |
启动引导令牌数据 |
通过为 Secret 对象的 type 字段设置一个非空的字符串值,你也可以定义并使用自己
Secret 类型(如果 type 值为空字符串,则被视为 Opaque 类型)。
Kubernetes 并不对类型的名称作任何限制。不过,如果你要使用内置类型之一, 则你必须满足为该类型所定义的所有要求。
如果你要定义一种公开使用的 Secret 类型,请遵守 Secret 类型的约定和结构,
在类型名前面添加域名,并用 / 隔开。
例如:cloud-hosting.example.net/cloud-api-credentials。
Opaque Secret
当你未在 Secret 清单中显式指定类型时,默认的 Secret 类型是 Opaque。
当你使用 kubectl 来创建一个 Secret 时,你必须使用 generic
子命令来标明要创建的是一个 Opaque 类型的 Secret。
例如,下面的命令会创建一个空的 Opaque 类型的 Secret:
kubectl create secret generic empty-secret
kubectl get secret empty-secret
输出类似于:
NAME TYPE DATA AGE
empty-secret Opaque 0 2m6s
DATA 列显示 Secret 中保存的数据条目个数。
在这个例子中,0 意味着你刚刚创建了一个空的 Secret。
ServiceAccount 令牌 Secret
类型为 kubernetes.io/service-account-token 的 Secret 用来存放标识某
ServiceAccount 的令牌凭据。
这是为 Pod 提供长期有效 ServiceAccount 凭据的传统机制。
在 Kubernetes v1.22 及更高版本中,推荐的方法是通过使用
TokenRequest API
来获取短期自动轮换的 ServiceAccount 令牌。你可以使用以下方法获取这些短期令牌:
- 直接调用
TokenRequestAPI,或者使用像kubectl这样的 API 客户端。 例如,你可以使用kubectl create token命令。 - 在 Pod 清单中请求使用投射卷挂载的令牌。 Kubernetes 会创建令牌并将其挂载到 Pod 中。 当挂载令牌的 Pod 被删除时,此令牌会自动失效。 更多细节参阅启动使用服务账号令牌投射的 Pod。
说明:
只有在你无法使用 TokenRequest API 来获取令牌,
并且你能够接受因为将永不过期的令牌凭据写入到可读取的 API 对象而带来的安全风险时,
才应该创建 ServiceAccount 令牌 Secret。
更多细节参阅为 ServiceAccount 手动创建长期有效的 API 令牌。
使用这种 Secret 类型时,你需要确保对象的注解 kubernetes.io/service-account-name
被设置为某个已有的 ServiceAccount 名称。
如果你同时创建 ServiceAccount 和 Secret 对象,应该先创建 ServiceAccount 对象。
当 Secret 对象被创建之后,某个 Kubernetes
控制器会填写
Secret 的其它字段,例如 kubernetes.io/service-account.uid 注解和
data 字段中的 token 键值(该键包含一个身份认证令牌)。
下面的配置实例声明了一个 ServiceAccount 令牌 Secret:
apiVersion: v1
kind: Secret
metadata:
name: secret-sa-sample
annotations:
kubernetes.io/service-account.name: "sa-name"
type: kubernetes.io/service-account-token
data:
extra: YmFyCg==创建了 Secret 之后,等待 Kubernetes 在 data 字段中填充 token 主键。
参考 ServiceAccount
文档了解 ServiceAccount 的工作原理。你也可以查看
Pod
资源中的 automountServiceAccountToken 和 serviceAccountName 字段文档,
进一步了解从 Pod 中引用 ServiceAccount 凭据。
Docker 配置 Secret
如果你要创建 Secret 用来存放用于访问容器镜像仓库的凭据,则必须选用以下 type
值之一来创建 Secret:
kubernetes.io/dockercfg:存放~/.dockercfg文件的序列化形式,它是配置 Docker 命令行的一种老旧形式。Secret 的data字段包含名为.dockercfg的主键, 其值是用 base64 编码的某~/.dockercfg文件的内容。kubernetes.io/dockerconfigjson:存放 JSON 数据的序列化形式, 该 JSON 也遵从~/.docker/config.json文件的格式规则,而后者是~/.dockercfg的新版本格式。使用此 Secret 类型时,Secret 对象的data字段必须包含.dockerconfigjson键,其键值为 base64 编码的字符串包含~/.docker/config.json文件的内容。
下面是一个 kubernetes.io/dockercfg 类型 Secret 的示例:
apiVersion: v1
kind: Secret
metadata:
name: secret-dockercfg
type: kubernetes.io/dockercfg
data:
.dockercfg: |
eyJhdXRocyI6eyJodHRwczovL2V4YW1wbGUvdjEvIjp7ImF1dGgiOiJvcGVuc2VzYW1lIn19fQo=
说明:
如果你不希望执行 base64 编码转换,可以使用 stringData 字段代替。
当你使用清单文件通过 Docker 配置来创建 Secret 时,API 服务器会检查 data 字段中是否存在所期望的主键,
并且验证其中所提供的键值是否是合法的 JSON 数据。
不过,API 服务器不会检查 JSON 数据本身是否是一个合法的 Docker 配置文件内容。
你还可以使用 kubectl 创建一个 Secret 来访问容器仓库时,
当你没有 Docker 配置文件时你可以这样做:
kubectl create secret docker-registry secret-tiger-docker \
--docker-email=tiger@acme.example \
--docker-username=tiger \
--docker-password=pass1234 \
--docker-server=my-registry.example:5000
此命令创建一个类型为 kubernetes.io/dockerconfigjson 的 Secret。
从这个新的 Secret 中获取 .data.dockerconfigjson 字段并执行数据解码:
kubectl get secret secret-tiger-docker -o jsonpath='{.data.*}' | base64 -d
输出等价于以下 JSON 文档(这也是一个有效的 Docker 配置文件):
{
"auths": {
"my-registry.example:5000": {
"username": "tiger",
"password": "pass1234",
"email": "tiger@acme.example",
"auth": "dGlnZXI6cGFzczEyMzQ="
}
}
}
注意:
auths 值是 base64 编码的,其内容被屏蔽但未被加密。
任何能够读取该 Secret 的人都可以了解镜像库的访问令牌。
建议使用凭据提供程序来动态、 安全地按需提供拉取 Secret。
基本身份认证 Secret
kubernetes.io/basic-auth 类型用来存放用于基本身份认证所需的凭据信息。
使用这种 Secret 类型时,Secret 的 data 字段必须包含以下两个键之一:
username: 用于身份认证的用户名;password: 用于身份认证的密码或令牌。
以上两个键的键值都是 base64 编码的字符串。
当然你也可以在 Secret 清单中的使用 stringData 字段来提供明文形式的内容。
以下清单是基本身份验证 Secret 的示例:
apiVersion: v1
kind: Secret
metadata:
name: secret-basic-auth
type: kubernetes.io/basic-auth
stringData:
username: admin # kubernetes.io/basic-auth 类型的必需字段
password: t0p-Secret # kubernetes.io/basic-auth 类型的必需字段
说明:
Secret 的 stringData 字段不能很好地与服务器端应用配合使用。
提供基本身份认证类型的 Secret 仅仅是出于方便性考虑。
你也可以使用 Opaque 类型来保存用于基本身份认证的凭据。
不过,使用预定义的、公开的 Secret 类型(kubernetes.io/basic-auth)
有助于帮助其他用户理解 Secret 的目的,并且对其中存在的主键形成一种约定。
API 服务器会检查 Secret 配置中是否提供了所需要的主键。
SSH 身份认证 Secret
Kubernetes 所提供的内置类型 kubernetes.io/ssh-auth 用来存放 SSH 身份认证中所需要的凭据。
使用这种 Secret 类型时,你就必须在其 data (或 stringData)
字段中提供一个 ssh-privatekey 键值对,作为要使用的 SSH 凭据。
下面的清单是一个 SSH 公钥/私钥身份认证的 Secret 示例:
apiVersion: v1
kind: Secret
metadata:
name: secret-ssh-auth
type: kubernetes.io/ssh-auth
data:
# 此例中的实际数据被截断
ssh-privatekey: |
MIIEpQIBAAKCAQEAulqb/Y ... 提供 SSH 身份认证类型的 Secret 仅仅是出于方便性考虑。
你可以使用 Opaque 类型来保存用于 SSH 身份认证的凭据。
不过,使用预定义的、公开的 Secret 类型(kubernetes.io/tls)
有助于其他人理解你的 Secret 的用途,也可以就其中包含的主键名形成约定。
Kubernetes API 会验证这种类型的 Secret 中是否设定了所需的主键。
注意:
SSH 私钥自身无法建立 SSH 客户端与服务器端之间的可信连接。
需要其它方式来建立这种信任关系,以缓解“中间人(Man In The Middle)”
攻击,例如向 ConfigMap 中添加一个 known_hosts 文件。
TLS Secret
kubernetes.io/tls Secret 类型用来存放 TLS 场合通常要使用的证书及其相关密钥。
TLS Secret 的一种典型用法是为 Ingress
资源配置传输过程中的数据加密,不过也可以用于其他资源或者直接在负载中使用。
当使用此类型的 Secret 时,Secret 配置中的 data (或 stringData)字段必须包含
tls.key 和 tls.crt 主键,尽管 API 服务器实际上并不会对每个键的取值作进一步的合法性检查。
作为使用 stringData 的替代方法,你可以使用 data 字段来指定 base64 编码的证书和私钥。
有关详细信息,请参阅 Secret 名称和数据的限制。
下面的 YAML 包含一个 TLS Secret 的配置示例:
apiVersion: v1
kind: Secret
metadata:
name: secret-tls
type: kubernetes.io/tls
data:
# 值为 base64 编码,这样会掩盖它们,但不会提供任何有用的机密性级别
tls.crt: |
LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUNVakNDQWJzQ0FnMytNQTBHQ1NxR1NJYjNE
UUVCQlFVQU1JR2JNUXN3Q1FZRFZRUUdFd0pLVURFT01Bd0cKQTFVRUNCTUZWRzlyZVc4eEVEQU9C
Z05WQkFjVEIwTm9kVzh0YTNVeEVUQVBCZ05WQkFvVENFWnlZVzVyTkVSRQpNUmd3RmdZRFZRUUxF
dzlYWldKRFpYSjBJRk4xY0hCdmNuUXhHREFXQmdOVkJBTVREMFp5WVc1ck5FUkVJRmRsCllpQkRR
VEVqTUNFR0NTcUdTSWIzRFFFSkFSWVVjM1Z3Y0c5eWRFQm1jbUZ1YXpSa1pDNWpiMjB3SGhjTk1U
TXcKTVRFeE1EUTFNVE01V2hjTk1UZ3dNVEV3TURRMU1UTTVXakJMTVFzd0NRWURWUVFHREFKS1VE
RVBNQTBHQTFVRQpDQXdHWEZSdmEzbHZNUkV3RHdZRFZRUUtEQWhHY21GdWF6UkVSREVZTUJZR0Ex
VUVBd3dQZDNkM0xtVjRZVzF3CmJHVXVZMjl0TUlHYU1BMEdDU3FHU0liM0RRRUJBUVVBQTRHSUFE
Q0JoQUo5WThFaUhmeHhNL25PbjJTbkkxWHgKRHdPdEJEVDFKRjBReTliMVlKanV2YjdjaTEwZjVN
Vm1UQllqMUZTVWZNOU1vejJDVVFZdW4yRFljV29IcFA4ZQpqSG1BUFVrNVd5cDJRN1ArMjh1bklI
QkphVGZlQ09PekZSUFY2MEdTWWUzNmFScG04L3dVVm16eGFLOGtCOWVaCmhPN3F1TjdtSWQxL2pW
cTNKODhDQXdFQUFUQU5CZ2txaGtpRzl3MEJBUVVGQUFPQmdRQU1meTQzeE15OHh3QTUKVjF2T2NS
OEtyNWNaSXdtbFhCUU8xeFEzazlxSGtyNFlUY1JxTVQ5WjVKTm1rWHYxK2VSaGcwTi9WMW5NUTRZ
RgpnWXcxbnlESnBnOTduZUV4VzQyeXVlMFlHSDYyV1hYUUhyOVNVREgrRlowVnQvRGZsdklVTWRj
UUFEZjM4aU9zCjlQbG1kb3YrcE0vNCs5a1h5aDhSUEkzZXZ6OS9NQT09Ci0tLS0tRU5EIENFUlRJ
RklDQVRFLS0tLS0K
# 在这个例子中,密钥数据不是真正的 PEM 编码的私钥
tls.key: |
RXhhbXBsZSBkYXRhIGZvciB0aGUgVExTIGNydCBmaWVsZA== 提供 TLS 类型的 Secret 仅仅是出于方便性考虑。
你可以创建 Opaque 类型的 Secret 来保存用于 TLS 身份认证的凭据。
不过,使用已定义和公开的 Secret 类型(kubernetes.io/tls)有助于确保你自己项目中的 Secret 格式的一致性。
API 服务器会验证这种类型的 Secret 是否设定了所需的主键。
要使用 kubectl 创建 TLS Secret,你可以使用 tls 子命令:
kubectl create secret tls my-tls-secret \
--cert=path/to/cert/file \
--key=path/to/key/file
公钥/私钥对必须事先存在,--cert 的公钥证书必须采用 .PEM 编码,
并且必须与 --key 的给定私钥匹配。
启动引导令牌 Secret
bootstrap.kubernetes.io/token Secret 类型针对的是节点启动引导过程所用的令牌。
其中包含用来为周知的 ConfigMap 签名的令牌。
启动引导令牌 Secret 通常创建于 kube-system 名字空间内,并以
bootstrap-token-<令牌 ID> 的形式命名;
其中 <令牌 ID> 是一个由 6 个字符组成的字符串,用作令牌的标识。
以 Kubernetes 清单文件的形式,某启动引导令牌 Secret 可能看起来像下面这样:
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-5emitj
namespace: kube-system
type: bootstrap.kubernetes.io/token
data:
auth-extra-groups: c3lzdGVtOmJvb3RzdHJhcHBlcnM6a3ViZWFkbTpkZWZhdWx0LW5vZGUtdG9rZW4=
expiration: MjAyMC0wOS0xM1QwNDozOToxMFo=
token-id: NWVtaXRq
token-secret: a3E0Z2lodnN6emduMXAwcg==
usage-bootstrap-authentication: dHJ1ZQ==
usage-bootstrap-signing: dHJ1ZQ==启动引导令牌类型的 Secret 会在 data 字段中包含如下主键:
token-id:由 6 个随机字符组成的字符串,作为令牌的标识符。必需。token-secret:由 16 个随机字符组成的字符串,包含实际的令牌机密。必需。description:供用户阅读的字符串,描述令牌的用途。可选。expiration:一个使用 RFC3339 来编码的 UTC 绝对时间,给出令牌要过期的时间。可选。usage-bootstrap-<usage>:布尔类型的标志,用来标明启动引导令牌的其他用途。auth-extra-groups:用逗号分隔的组名列表,身份认证时除被认证为system:bootstrappers组之外,还会被添加到所列的用户组中。
你也可以在 Secret 的 stringData 字段中提供值,而无需对其进行 base64 编码:
apiVersion: v1
kind: Secret
metadata:
# 注意 Secret 的命名方式
name: bootstrap-token-5emitj
# 启动引导令牌 Secret 通常位于 kube-system 名字空间
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
auth-extra-groups: "system:bootstrappers:kubeadm:default-node-token"
expiration: "2020-09-13T04:39:10Z"
# 此令牌 ID 被用于生成 Secret 名称
token-id: "5emitj"
token-secret: "kq4gihvszzgn1p0r"
# 此令牌还可用于 authentication (身份认证)
usage-bootstrap-authentication: "true"
# 且可用于 signing (证书签名)
usage-bootstrap-signing: "true"
说明:
Secret 的 stringData 字段不能很好地与服务器端应用配合使用。
使用 Secret
创建 Secret
创建 Secret 有以下几种可选方式:
对 Secret 名称与数据的约束
Secret 对象的名称必须是合法的 DNS 子域名。
在为创建 Secret 编写配置文件时,你可以设置 data 与/或 stringData 字段。
data 和 stringData 字段都是可选的。data 字段中所有键值都必须是 base64
编码的字符串。如果不希望执行这种 base64 字符串的转换操作,你可以选择设置
stringData 字段,其中可以使用任何字符串作为其取值。
data 和 stringData 中的键名只能包含字母、数字、-、_ 或 . 字符。
stringData 字段中的所有键值对都会在内部被合并到 data 字段中。
如果某个主键同时出现在 data 和 stringData 字段中,stringData
所指定的键值具有高优先级。
尺寸限制
每个 Secret 的尺寸最多为 1MiB。施加这一限制是为了避免用户创建非常大的 Secret, 进而导致 API 服务器和 kubelet 内存耗尽。不过创建很多小的 Secret 也可能耗尽内存。 你可以使用资源配额来约束每个名字空间中 Secret(或其他资源)的个数。
编辑 Secret
你可以编辑一个已有的 Secret,除非它是不可变更的。 要编辑一个 Secret,可使用以下方法之一:
你也可以使用
Kustomize 工具编辑数据。
然而这种方法会用编辑过的数据创建新的 Secret 对象。
根据你创建 Secret 的方式以及该 Secret 在 Pod 中被使用的方式,对已有 Secret
对象的更新将自动扩散到使用此数据的 Pod。有关更多信息,
请参阅在 Pod 以文件形式使用 Secret。
使用 Secret
Secret 可以以数据卷的形式挂载,也可以作为环境变量 暴露给 Pod 中的容器使用。Secret 也可用于系统中的其他部分,而不是一定要直接暴露给 Pod。 例如,Secret 也可以包含系统中其他部分在替你与外部系统交互时要使用的凭证数据。
Kubernetes 会检查 Secret 的卷数据源,确保所指定的对象引用确实指向类型为 Secret 的对象。因此,如果 Pod 依赖于某 Secret,该 Secret 必须先于 Pod 被创建。
如果 Secret 内容无法取回(可能因为 Secret 尚不存在或者临时性地出现 API 服务器网络连接问题),kubelet 会周期性地重试 Pod 运行操作。kubelet 也会为该 Pod 报告 Event 事件,给出读取 Secret 时遇到的问题细节。
可选的 Secret
当你在 Pod 中引用 Secret 时,你可以将该 Secret 标记为可选,就像下面例子中所展示的那样。 如果可选的 Secret 不存在,Kubernetes 将忽略它。
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
optional: true默认情况下,Secret 是必需的。在所有非可选的 Secret 都可用之前,Pod 的所有容器都不会启动。
如果 Pod 引用了非可选 Secret 中的特定键,并且该 Secret 确实存在,但缺少所指定的键, 则 Pod 在启动期间会失败。
在 Pod 以文件形式使用 Secret
如果你要在 Pod 中访问来自 Secret 的数据,一种方式是让 Kubernetes 将该 Secret 的值以 文件的形式呈现,该文件存在于 Pod 中一个或多个容器内的文件系统内。
相关的指示说明, 可以参阅使用 Secret 安全地分发凭据。
当卷中包含来自 Secret 的数据,而对应的 Secret 被更新,Kubernetes 会跟踪到这一操作并更新卷中的数据。更新的方式是保证最终一致性。
说明:
对于以 subPath 形式挂载 Secret 卷的容器而言, 它们无法收到自动的 Secret 更新。
Kubelet 组件会维护一个缓存,在其中保存节点上 Pod 卷中使用的 Secret 的当前主键和取值。
你可以配置 kubelet 如何检测所缓存数值的变化。
kubelet 配置中的
configMapAndSecretChangeDetectionStrategy 字段控制 kubelet 所采用的策略。
默认的策略是 Watch。
对 Secret 的更新操作既可以通过 API 的 watch 机制(默认)来传播, 基于设置了生命期的缓存获取,也可以通过 kubelet 的同步回路来从集群的 API 服务器上轮询获取。
因此,从 Secret 被更新到新的主键被投射到 Pod 中,中间存在一个延迟。 这一延迟的上限是 kubelet 的同步周期加上缓存的传播延迟, 其中缓存的传播延迟取决于所选择的缓存类型。 对应上一段中提到的几种传播机制,延迟时长为 watch 的传播延迟、所配置的缓存 TTL 或者对于直接轮询而言是零。
以环境变量的方式使用 Secret
如果需要在 Pod 中以环境变量的形式使用 Secret:
- 对于 Pod 规约中的每个容器,针对你要使用的每个 Secret 键,将对应的环境变量添加到
env[].valueFrom.secretKeyRef中。 - 更改你的镜像或命令行,以便程序能够从指定的环境变量找到所需要的值。
相关的指示说明, 可以参阅使用 Secret 数据定义容器变量。
非法环境变量
如果 Pod 规约中环境变量定义会被视为非法的环境变量名,这些主键将在你的容器中不可用。 Pod 仍然可以启动。
Kubernetes 添加一个 Event,其 reason 设置为 InvalidVariableNames,其消息将列举被略过的非法主键。
下面的例子中展示了一个 Pod,引用的是名为 mysecret 的 Secret,
其中包含两个非法的主键:1badkey 和 2alsobad。
kubectl get events
输出类似于:
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames kubelet, 127.0.0.1 Keys [1badkey, 2alsobad] from the EnvFrom secret default/mysecret were skipped since they are considered invalid environment variable names.
容器镜像拉取 Secret
如果你尝试从私有仓库拉取容器镜像,你需要一种方式让每个节点上的 kubelet 能够完成与镜像库的身份认证。你可以配置 镜像拉取 Secret 来实现这点。 Secret 是在 Pod 层面来配置的。
使用 imagePullSecrets
imagePullSecrets 字段是一个列表,包含对同一名字空间中 Secret 的引用。
你可以使用 imagePullSecrets 将包含 Docker(或其他)镜像仓库密码的 Secret
传递给 kubelet。kubelet 使用此信息来替 Pod 拉取私有镜像。
参阅 PodSpec API
进一步了解 imagePullSecrets 字段。
手动设定 imagePullSecret
你可以通过阅读容器镜像
文档了解如何设置 imagePullSecrets。
设置 imagePullSecrets 为自动挂载
你可以手动创建 imagePullSecret,并在一个 ServiceAccount 中引用它。
对使用该 ServiceAccount 创建的所有 Pod,或者默认使用该 ServiceAccount 创建的 Pod
而言,其 imagePullSecrets 字段都会设置为该服务账号。
请阅读向服务账号添加 ImagePullSecrets
来详细了解这一过程。
在静态 Pod 中使用 Secret
你不可以在静态 Pod 中使用 ConfigMap 或 Secret。
使用场景
使用场景:作为容器环境变量
你可以创建 Secret 并使用它为容器设置环境变量。
使用场景:带 SSH 密钥的 Pod
创建包含一些 SSH 密钥的 Secret:
kubectl create secret generic ssh-key-secret --from-file=ssh-privatekey=/path/to/.ssh/id_rsa --from-file=ssh-publickey=/path/to/.ssh/id_rsa.pub
输出类似于:
secret "ssh-key-secret" created
你也可以创建一个 kustomization.yaml 文件,在其 secretGenerator
字段中包含 SSH 密钥。
注意:
在提供你自己的 SSH 密钥之前要仔细思考:集群的其他用户可能有权访问该 Secret。
你也可以创建一个 SSH 私钥,代表一个你希望与你共享 Kubernetes 集群的其他用户分享的服务标识。 当凭据信息被泄露时,你可以收回该访问权限。
现在你可以创建一个 Pod,在其中访问包含 SSH 密钥的 Secret,并通过卷的方式来使用它:
apiVersion: v1
kind: Pod
metadata:
name: secret-test-pod
labels:
name: secret-test
spec:
volumes:
- name: secret-volume
secret:
secretName: ssh-key-secret
containers:
- name: ssh-test-container
image: mySshImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
容器命令执行时,秘钥的数据可以在下面的位置访问到:
/etc/secret-volume/ssh-publickey
/etc/secret-volume/ssh-privatekey
容器就可以随便使用 Secret 数据来建立 SSH 连接。
使用场景:带有生产、测试环境凭据的 Pod
这一示例所展示的一个 Pod 会使用包含生产环境凭据的 Secret,另一个 Pod 使用包含测试环境凭据的 Secret。
你可以创建一个带有 secretGenerator 字段的 kustomization.yaml 文件或者运行
kubectl create secret 来创建 Secret。
kubectl create secret generic prod-db-secret --from-literal=username=produser --from-literal=password=Y4nys7f11
输出类似于:
secret "prod-db-secret" created
你也可以创建一个包含测试环境凭据的 Secret:
kubectl create secret generic test-db-secret --from-literal=username=testuser --from-literal=password=iluvtests
输出类似于:
secret "test-db-secret" created
说明:
特殊字符(例如 $、\、*、= 和 !)会被你的
Shell 解释,因此需要转义。
在大多数 Shell 中,对密码进行转义的最简单方式是用单引号(')将其括起来。
例如,如果你的实际密码是 S!B\*d$zDsb,则应通过以下方式执行命令:
kubectl create secret generic dev-db-secret --from-literal=username=devuser --from-literal=password='S!B\*d$zDsb='
你无需对文件中的密码(--from-file)中的特殊字符进行转义。
现在生成 Pod:
cat <<EOF > pod.yaml
apiVersion: v1
kind: List
items:
- kind: Pod
apiVersion: v1
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: prod-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
- kind: Pod
apiVersion: v1
metadata:
name: test-db-client-pod
labels:
name: test-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: test-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
EOF
将 Pod 添加到同一 kustomization.yaml 文件中:
cat <<EOF >> kustomization.yaml
resources:
- pod.yaml
EOF
通过下面的命令在 API 服务器上应用所有这些对象:
kubectl apply -k .
两个文件都会在其文件系统中出现下面的文件,文件中内容是各个容器的环境值:
/etc/secret-volume/username
/etc/secret-volume/password
注意这两个 Pod 的规约中只有一个字段不同。 这便于基于相同的 Pod 模板生成具有不同能力的 Pod。
你可以通过使用两个服务账号来进一步简化这一基本的 Pod 规约:
prod-user服务账号使用prod-db-secrettest-user服务账号使用test-db-secret
Pod 规约简化为:
apiVersion: v1
kind: Pod
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
serviceAccount: prod-db-client
containers:
- name: db-client-container
image: myClientImage
不可更改的 Secret
特性状态:
Kubernetes v1.21 [stable]
Kubernetes 允许你将特定的 Secret(和 ConfigMap)标记为 不可更改(Immutable)。 禁止更改现有 Secret 的数据有下列好处:
- 防止意外(或非预期的)更新导致应用程序中断
- (对于大量使用 Secret 的集群而言,至少数万个不同的 Secret 供 Pod 挂载), 通过将 Secret 标记为不可变,可以极大降低 kube-apiserver 的负载,提升集群性能。 kubelet 不需要监视那些被标记为不可更改的 Secret。
将 Secret 标记为不可更改
你可以通过将 Secret 的 immutable 字段设置为 true 创建不可更改的 Secret。
例如:
apiVersion: v1
kind: Secret
metadata:
...
data:
...
immutable: true
你也可以更改现有的 Secret,令其不可更改。
说明:
一旦一个 Secret 或 ConfigMap 被标记为不可更改,撤销此操作或者更改 data
字段的内容都是 不 可能的。
只能删除并重新创建这个 Secret。现有的 Pod 将维持对已删除 Secret 的挂载点 --
建议重新创建这些 Pod。
Secret 的信息安全问题
尽管 ConfigMap 和 Secret 的工作方式类似,但 Kubernetes 对 Secret 有一些额外的保护。
Secret 通常保存重要性各异的数值,其中很多都可能会导致 Kubernetes 中 (例如,服务账号令牌)或对外部系统的特权提升。 即使某些个别应用能够推导它期望使用的 Secret 的能力, 同一名字空间中的其他应用可能会让这种假定不成立。
只有当某个节点上的 Pod 需要某 Secret 时,对应的 Secret 才会被发送到该节点上。
如果将 Secret 挂载到 Pod 中,kubelet 会将数据的副本保存在在 tmpfs 中,
这样机密的数据不会被写入到持久性存储中。
一旦依赖于该 Secret 的 Pod 被删除,kubelet 会删除来自于该 Secret 的机密数据的本地副本。
同一个 Pod 中可能包含多个容器。默认情况下,你所定义的容器只能访问默认 ServiceAccount 及其相关 Secret。你必须显式地定义环境变量或者将卷映射到容器中,才能为容器提供对其他 Secret 的访问。
针对同一节点上的多个 Pod 可能有多个 Secret。不过,只有某个 Pod 所请求的 Secret 才有可能对 Pod 中的容器可见。因此,一个 Pod 不会获得访问其他 Pod 的 Secret 的权限。
配置 Secret 资源的最小特权访问
为了加强对 Secret 的安全措施,Kubernetes 提供了一种机制:
你可以为 ServiceAccount 添加 kubernetes.io/enforce-mountable-secrets: "true" 注解。
想了解更多信息,你可以参考此注解的文档。
警告:
在一个节点上以 privileged: true 运行的所有容器可以访问该节点上使用的所有 Secret。
接下来
- 有关管理和提升 Secret 安全性的指南,请参阅 Kubernetes Secret 良好实践
- 学习如何使用
kubectl管理 Secret - 学习如何使用配置文件管理 Secret
- 学习如何使用 kustomize 管理 Secret
- 阅读 API 参考了解
Secret
7.4 - 为 Pod 和容器管理资源
当你定义 Pod 时可以选择性地为每个 容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存(RAM)大小;此外还有其他类型的资源。
当你为 Pod 中的 Container 指定了资源 request(请求) 时, kube-scheduler 就利用该信息决定将 Pod 调度到哪个节点上。 当你为 Container 指定了资源 limit(限制) 时,kubelet 就可以确保运行的容器不会使用超出所设限制的资源。 kubelet 还会为容器预留所 request(请求) 数量的系统资源,供其使用。
请求和限制
如果 Pod 运行所在的节点具有足够的可用资源,容器可能(且可以)使用超出对应资源
request 属性所设置的资源量。不过,容器不可以使用超出其资源 limit
属性所设置的资源量。
例如,如果你将容器的 memory 的请求量设置为 256 MiB,而该容器所处的 Pod
被调度到一个具有 8 GiB 内存的节点上,并且该节点上没有其他 Pod
运行,那么该容器就可以尝试使用更多的内存。
如果你将某容器的 memory 限制设置为 4 GiB,kubelet
(和容器运行时)就会确保该限制生效。
容器运行时会禁止容器使用超出所设置资源限制的资源。
例如:当容器中进程尝试使用超出所允许内存量的资源时,系统内核会将尝试申请内存的进程终止,
并引发内存不足(OOM)错误。
限制可以以被动方式来实现(系统会在发现违例时进行干预),或者通过强制生效的方式实现 (系统会避免容器用量超出限制)。不同的容器运行时采用不同方式来实现相同的限制。
说明:
如果你为某个资源指定了限制,但不指定请求, 并且没有应用准入时机制为该资源设置默认请求, 然后 Kubernetes 复制你所指定的限制值,将其用作资源的请求值。
资源类型
CPU 和 内存 都是 资源类型。每种资源类型具有其基本单位。 CPU 表达的是计算处理能力,其单位是 Kubernetes CPU。 内存的单位是字节。 对于 Linux 负载,则可以指定巨页(Huge Page)资源。 巨页是 Linux 特有的功能,节点内核在其中分配的内存块比默认页大小大得多。
例如,在默认页面大小为 4KiB 的系统上,你可以指定限制 hugepages-2Mi: 80Mi。
如果容器尝试分配 40 个 2MiB 大小的巨页(总共 80 MiB ),则分配请求会失败。
说明:
你不能过量使用 hugepages- * 资源。
这与 memory 和 cpu 资源不同。
CPU 和内存统称为 计算资源,或简称为 资源。 计算资源的数量是可测量的,可以被请求、被分配、被消耗。 它们与 API 资源不同。 API 资源(如 Pod 和 Service)是可通过 Kubernetes API 服务器读取和修改的对象。
Pod 和 容器的资源请求和限制
针对每个容器,你都可以指定其资源限制和请求,包括如下选项:
spec.containers[].resources.limits.cpuspec.containers[].resources.limits.memoryspec.containers[].resources.limits.hugepages-<size>spec.containers[].resources.requests.cpuspec.containers[].resources.requests.memoryspec.containers[].resources.requests.hugepages-<size>
尽管你只能逐个容器地指定请求和限制值,考虑 Pod 的总体资源请求和限制也是有用的。 对特定资源而言,Pod 的资源请求/限制 是 Pod 中各容器对该类型资源的请求/限制的总和。
Kubernetes 中的资源单位
CPU 资源单位
CPU 资源的限制和请求以 “cpu” 为单位。 在 Kubernetes 中,一个 CPU 等于 1 个物理 CPU 核 或者 1 个虚拟核, 取决于节点是一台物理主机还是运行在某物理主机上的虚拟机。
你也可以表达带小数 CPU 的请求。
当你定义一个容器,将其 spec.containers[].resources.requests.cpu 设置为 0.5 时,
你所请求的 CPU 是你请求 1.0 CPU 时的一半。
对于 CPU 资源单位,数量
表达式 0.1 等价于表达式 100m,可以看作 “100 millicpu”。
有些人说成是“一百毫核”,其实说的是同样的事情。
CPU 资源总是设置为资源的绝对数量而非相对数量值。
例如,无论容器运行在单核、双核或者 48-核的机器上,500m CPU 表示的是大约相同的计算能力。
说明:
Kubernetes 不允许设置精度小于 1m 或 0.001 的 CPU 资源。
为了避免意外使用无效的 CPU 数量,当使用少于 1 个 CPU 单元时,使用
milliCPU 形式而不是十进制形式指定 CPU 单元非常有用。
例如,你有一个使用 5m 或 0.005 核 CPU 的 Pod,并且希望减少其 CPU 资源。
通过使用十进制形式,更难发现 0.0005 CPU 是无效值,而通过使用 milliCPU 形式,
更容易发现 0.5m 是无效值。
内存资源单位
memory 的限制和请求以字节为单位。
你可以使用普通的整数,或者带有以下
数量后缀
的定点数字来表示内存:E、P、T、G、M、k。
你也可以使用对应的 2 的幂数:Ei、Pi、Ti、Gi、Mi、Ki。
例如,以下表达式所代表的是大致相同的值:
128974848、129e6、129M、128974848000m、123Mi
请注意后缀的大小写。如果你请求 400m 临时存储,实际上所请求的是 0.4 字节。
如果有人这样设定资源请求或限制,可能他的实际想法是申请 400Mi 字节(400Mi)
或者 400M 字节。
容器资源示例
以下 Pod 有两个容器。每个容器的请求为 0.25 CPU 和 64MiB(226 字节)内存, 每个容器的资源限制为 0.5 CPU 和 128MiB 内存。 你可以认为该 Pod 的资源请求为 0.5 CPU 和 128 MiB 内存,资源限制为 1 CPU 和 256MiB 内存。
---
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
带资源请求的 Pod 如何调度
当你创建一个 Pod 时,Kubernetes 调度程序将为 Pod 选择一个节点。 每个节点对每种资源类型都有一个容量上限:可为 Pod 提供的 CPU 和内存量。 调度程序确保对于每种资源类型,所调度的容器的资源请求的总和小于节点的容量。 请注意,尽管节点上的实际内存或 CPU 资源使用量非常低,如果容量检查失败, 调度程序仍会拒绝在该节点上放置 Pod。 当稍后节点上资源用量增加,例如到达请求率的每日峰值区间时,节点上也不会出现资源不足的问题。
Kubernetes 应用资源请求与限制的方式
当 kubelet 将容器作为 Pod 的一部分启动时,它会将容器的 CPU 和内存请求与限制信息传递给容器运行时。
在 Linux 系统上,容器运行时通常会配置内核 CGroups,负责应用并实施所定义的请求。
- CPU 限制定义的是容器可使用的 CPU 时间的硬性上限。 在每个调度周期(时间片)期间,Linux 内核检查是否已经超出该限制; 内核会在允许该 cgroup 恢复执行之前会等待。
- CPU 请求值定义的是一个权重值。如果若干不同的容器(CGroups)需要在一个共享的系统上竞争运行, CPU 请求值大的负载会获得比请求值小的负载更多的 CPU 时间。
- 内存请求值主要用于(Kubernetes)Pod 调度期间。在一个启用了 CGroup v2 的节点上,
容器运行时可能会使用内存请求值作为设置
memory.min和memory.low的提示值。
- 内存限制定义的是 cgroup 的内存限制。如果容器尝试分配的内存量超出限制, 则 Linux 内核的内存不足处理子系统会被激活,并停止尝试分配内存的容器中的某个进程。 如果该进程在容器中 PID 为 1,而容器被标记为可重新启动,则 Kubernetes 会重新启动该容器。
- Pod 或容器的内存限制也适用于通过内存供应的卷,例如
emptyDir卷。 kubelet 会跟踪tmpfs形式的 emptyDir 卷用量,将其作为容器的内存用量, 而不是临时存储用量。
如果某容器内存用量超过其内存请求值并且所在节点内存不足时,容器所处的 Pod 可能被逐出。
每个容器可能被允许也可能不被允许使用超过其 CPU 限制的处理时间。 但是,容器运行时不会由于 CPU 使用率过高而杀死 Pod 或容器。
要确定某容器是否会由于资源限制而无法调度或被杀死,请参阅疑难解答节。
监控计算和内存资源用量
kubelet 会将 Pod 的资源使用情况作为 Pod
status
的一部分来报告的。
如果为集群配置了可选的监控工具, 则可以直接从指标 API 或者监控工具获得 Pod 的资源使用情况。
本地临时存储
特性状态:
Kubernetes v1.25 [stable]
节点通常还可以具有本地的临时性存储,由本地挂接的可写入设备或者有时也用 RAM 来提供支持。 “临时(Ephemeral)”意味着对所存储的数据不提供长期可用性的保证。
Pods 通常可以使用临时性本地存储来实现缓冲区、保存日志等功能。
kubelet 可以为使用本地临时存储的 Pods 提供这种存储空间,允许后者使用
emptyDir
类型的卷将其挂载到容器中。
kubelet 也使用此类存储来保存节点层面的容器日志、 容器镜像文件以及运行中容器的可写入层。
注意:
如果节点失效,存储在临时性存储中的数据会丢失。 你的应用不能对本地临时性存储的性能 SLA(例如磁盘 IOPS)作任何假定。
说明:
为了使临时性存储的资源配额生效,需要完成以下两个步骤:
- 管理员在命名空间中设置临时性存储的资源配额。
- 用户需要在 Pod spec 中指定临时性存储资源的限制。
如果用户在 Pod spec 中未指定临时性存储资源的限制, 则临时性存储的资源配额不会生效。
Kubernetes 允许你跟踪、预留和限制 Pod 可消耗的临时性本地存储数量。
本地临时性存储的配置
Kubernetes 有两种方式支持节点上配置本地临时性存储:
采用这种配置时,你会把所有类型的临时性本地数据(包括 emptyDir
卷、可写入容器层、容器镜像、日志等)放到同一个文件系统中。
作为最有效的 kubelet 配置方式,这意味着该文件系统是专门提供给 Kubernetes
(kubelet)来保存数据的。
kubelet 也会生成节点层面的容器日志, 并按临时性本地存储的方式对待之。
kubelet 会将日志写入到所配置的日志目录(默认为 /var/log)下的文件中;
还会针对其他本地存储的数据使用同一个基础目录(默认为 /var/lib/kubelet)。
通常,/var/lib/kubelet 和 /var/log 都是在系统的根文件系统中。kubelet
的设计也考虑到这一点。
你的集群节点当然可以包含其他的、并非用于 Kubernetes 的很多文件系统。
你使用节点上的某个文件系统来保存运行 Pods 时产生的临时性数据:日志和
emptyDir 卷等。你可以使用这个文件系统来保存其他数据(例如:与 Kubernetes
无关的其他系统日志);这个文件系统还可以是根文件系统。
kubelet 也将节点层面的容器日志 写入到第一个文件系统中,并按临时性本地存储的方式对待之。
同时你使用另一个由不同逻辑存储设备支持的文件系统。在这种配置下,你会告诉 kubelet 将容器镜像层和可写层保存到这第二个文件系统上的某个目录中。
第一个文件系统中不包含任何镜像层和可写层数据。
当然,你的集群节点上还可以有很多其他与 Kubernetes 没有关联的文件系统。
kubelet 能够度量其本地存储的用量。 实现度量机制的前提是你已使用本地临时存储所支持的配置之一对节点进行配置。
如果你的节点配置不同于以上预期,kubelet 就无法对临时性本地存储实施资源限制。
说明:
kubelet 会将 tmpfs emptyDir 卷的用量当作容器内存用量,而不是本地临时性存储来统计。
说明:
kubelet 将仅跟踪临时存储的根文件系统。
挂载一个单独磁盘到 /var/lib/kubelet 或 /var/lib/containers 的操作系统布局将不会正确地报告临时存储。
为本地临时性存储设置请求和限制
你可以指定 ephemeral-storage 来管理本地临时性存储。
Pod 中的每个容器可以设置以下属性:
spec.containers[].resources.limits.ephemeral-storagespec.containers[].resources.requests.ephemeral-storage
ephemeral-storage 的请求和限制是按量纲计量的。
你可以使用一般整数或者定点数字加上下面的后缀来表达存储量:E、P、T、G、M、k。
你也可以使用对应的 2 的幂级数来表达:Ei、Pi、Ti、Gi、Mi、Ki。
例如,下面的表达式所表达的大致是同一个值:
128974848129e6129M123Mi
请注意后缀的大小写。如果你请求 400m 临时存储,实际上所请求的是 0.4 字节。
如果有人这样设定资源请求或限制,可能他的实际想法是申请 400Mi 字节(400Mi)
或者 400M 字节。
在下面的例子中,Pod 包含两个容器。每个容器请求 2 GiB 大小的本地临时性存储。
每个容器都设置了 4 GiB 作为其本地临时性存储的限制。
因此,整个 Pod 的本地临时性存储请求是 4 GiB,且其本地临时性存储的限制为 8 GiB。
该限制值中有 500Mi 可供 emptyDir 卷使用。
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:
- name: ephemeral
mountPath: "/tmp"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:
- name: ephemeral
mountPath: "/tmp"
volumes:
- name: ephemeral
emptyDir:
sizeLimit: 500Mi
带临时性存储的 Pods 的调度行为
当你创建一个 Pod 时,Kubernetes 调度器会为 Pod 选择一个节点来运行之。 每个节点都有一个本地临时性存储的上限,是其可提供给 Pod 使用的总量。 欲了解更多信息, 可参考节点可分配资源节。
调度器会确保所调度的容器的资源请求总和不会超出节点的资源容量。
临时性存储消耗的管理
如果 kubelet 将本地临时性存储作为资源来管理,则 kubelet 会度量以下各处的存储用量:
emptyDir卷,除了 tmpfsemptyDir卷- 保存节点层面日志的目录
- 可写入的容器镜像层
如果某 Pod 的临时存储用量超出了你所允许的范围,kubelet 会向其发出逐出(eviction)信号,触发该 Pod 被逐出所在节点。
就容器层面的隔离而言,如果某容器的可写入镜像层和日志用量超出其存储限制, kubelet 也会将所在的 Pod 标记为逐出候选。
就 Pod 层面的隔离而言,kubelet 会将 Pod 中所有容器的限制相加,得到 Pod
存储限制的总值。如果所有容器的本地临时性存储用量总和加上 Pod 的 emptyDir
卷的用量超出 Pod 存储限制,kubelet 也会将该 Pod 标记为逐出候选。
注意:
如果 kubelet 没有度量本地临时性存储的用量,即使 Pod 的本地存储用量超出其限制也不会被逐出。
不过,如果用于可写入容器镜像层、节点层面日志或者 emptyDir 卷的文件系统中可用空间太少,
节点会为自身设置本地存储不足的污点标签。
这一污点会触发对那些无法容忍该污点的 Pod 的逐出操作。
关于临时性本地存储的配置信息,请参考这里
kubelet 支持使用不同方式来度量 Pod 的存储用量:
kubelet 按预定周期执行扫描操作,检查 emptyDir 卷、容器日志目录以及可写入容器镜像层。
这一扫描会度量存储空间用量。
说明:
项目配额(Project Quota)是一个操作系统层的功能特性,用来管理文件系统中的存储用量。
在 Kubernetes 中,你可以启用项目配额以监视存储用量。
你需要确保节点上为 emptyDir 提供存储的文件系统支持项目配额。
例如,XFS 和 ext4fs 文件系统都支持项目配额。
说明:
项目配额可以帮你监视存储用量,但无法强制执行限制。
Kubernetes 所使用的项目 ID 始于 1048576。
所使用的 IDs 会注册在 /etc/projects 和 /etc/projid 文件中。
如果该范围中的项目 ID 已经在系统中被用于其他目的,则已占用的项目 ID
也必须注册到 /etc/projects 和 /etc/projid 中,这样 Kubernetes
才不会使用它们。
配额方式与目录扫描方式相比速度更快,结果更精确。当某个目录被分配给某个项目时, 该目录下所创建的所有文件都属于该项目,内核只需要跟踪该项目中的文件所使用的存储块个数。 如果某文件被创建后又被删除,但对应文件描述符仍处于打开状态, 该文件会继续耗用存储空间。配额跟踪技术能够精确第记录对应存储空间的状态, 而目录扫描方式会忽略被删除文件所占用的空间。
如果你希望使用项目配额,你需要:
-
在 kubelet 配置中使用
featureGates字段或者使用--feature-gates命令行参数启用LocalStorageCapacityIsolationFSQuotaMonitoring=true特性门控。 -
确保根文件系统(或者可选的运行时文件系统)启用了项目配额。所有 XFS 文件系统都支持项目配额。 对 extf 文件系统而言,你需要在文件系统尚未被挂载时启用项目配额跟踪特性:
# 对 ext4 而言,在 /dev/block-device 尚未被挂载时执行下面操作 sudo tune2fs -O project -Q prjquota /dev/block-device -
确保根文件系统(或者可选的运行时文件系统)在挂载时项目配额特性是被启用了的。 对于 XFS 和 ext4fs 而言,对应的挂载选项称作
prjquota。
扩展资源(Extended Resources)
扩展资源是 kubernetes.io 域名之外的标准资源名称。
它们使得集群管理员能够颁布非 Kubernetes 内置资源,而用户可以使用他们。
使用扩展资源需要两个步骤。首先,集群管理员必须颁布扩展资源。 其次,用户必须在 Pod 中请求扩展资源。
管理扩展资源
节点级扩展资源
节点级扩展资源绑定到节点。
设备插件管理的资源
有关如何颁布在各节点上由设备插件所管理的资源, 请参阅设备插件。
其他资源
为了颁布新的节点级扩展资源,集群操作员可以向 API 服务器提交 PATCH HTTP 请求,
以在集群中节点的 status.capacity 中为其配置可用数量。
完成此操作后,节点的 status.capacity 字段中将包含新资源。
kubelet 会异步地对 status.allocatable 字段执行自动更新操作,使之包含新资源。
由于调度器在评估 Pod 是否适合在某节点上执行时会使用节点的 status.allocatable 值,
调度器只会考虑异步更新之后的新值。
在更新节点容量使之包含新资源之后和请求该资源的第一个 Pod 被调度到该节点之间,
可能会有短暂的延迟。
示例:
这是一个示例,显示了如何使用 curl 构造 HTTP 请求,公告主节点为 k8s-master
的节点 k8s-node-1 上存在五个 example.com/foo 资源。
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1foo", "value": "5"}]' \
http://k8s-master:8080/api/v1/nodes/k8s-node-1/status
说明:
在前面的请求中,~1 是在 patch 路径中对字符 / 的编码。
JSON-Patch 中的操作路径的值被视为 JSON-Pointer 类型。
有关更多详细信息,请参见
IETF RFC 6901 第 3 节。
集群层面的扩展资源
集群层面的扩展资源并不绑定到具体节点。 它们通常由调度器扩展程序(Scheduler Extenders)管理,这些程序处理资源消耗和资源配额。
你可以在调度器配置 中指定由调度器扩展程序处理的扩展资源。
示例:
下面的调度器策略配置标明集群层扩展资源 "example.com/foo" 由调度器扩展程序处理。
- 仅当 Pod 请求 "example.com/foo" 时,调度器才会将 Pod 发送到调度器扩展程序。
ignoredByScheduler字段指定调度器不要在其PodFitsResources断言中检查 "example.com/foo" 资源。
{
"kind": "Policy",
"apiVersion": "v1",
"extenders": [
{
"urlPrefix": "<extender-endpoint>",
"bindVerb": "bind",
"managedResources": [
{
"name": "example.com/foo",
"ignoredByScheduler": true
}
]
}
]
}
使用扩展资源
就像 CPU 和内存一样,用户可以在 Pod 的规约中使用扩展资源。 调度器负责资源的核算,确保同时分配给 Pod 的资源总量不会超过可用数量。
API 服务器将扩展资源的数量限制为整数。
有效 数量的示例是 3、3000m 和 3Ki。
无效 数量的示例是 0.5 和 1500m。
说明:
扩展资源取代了非透明整数资源(Opaque Integer Resources,OIR)。
用户可以使用 kubernetes.io(保留)以外的任何域名前缀。
要在 Pod 中使用扩展资源,请在容器规约的 spec.containers[].resources.limits
映射中包含资源名称作为键。
说明:
扩展资源不能过量使用,因此如果容器规约中同时存在请求和限制,则它们的取值必须相同。
仅当所有资源请求(包括 CPU、内存和任何扩展资源)都被满足时,Pod 才能被调度。
在资源请求无法满足时,Pod 会保持在 PENDING 状态。
示例:
下面的 Pod 请求 2 个 CPU 和 1 个 "example.com/foo"(扩展资源)。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: myimage
resources:
requests:
cpu: 2
example.com/foo: 1
limits:
example.com/foo: 1
PID 限制
进程 ID(PID)限制允许对 kubelet 进行配置,以限制给定 Pod 可以消耗的 PID 数量。 有关信息,请参见 PID 限制。
疑难解答
我的 Pod 处于悬决状态且事件信息显示 FailedScheduling
如果调度器找不到该 Pod 可以匹配的任何节点,则该 Pod 将保持未被调度状态,
直到找到一个可以被调度到的位置。每当调度器找不到 Pod 可以调度的地方时,
会产生一个 Event。
你可以使用 kubectl 来查看 Pod 的事件;例如:
kubectl describe pod frontend | grep -A 9999999999 Events
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 23s default-scheduler 0/42 nodes available: insufficient cpu
在上述示例中,由于节点上的 CPU 资源不足,名为 “frontend” 的 Pod 无法被调度。 由于内存不足(PodExceedsFreeMemory)而导致失败时,也有类似的错误消息。 一般来说,如果 Pod 处于悬决状态且有这种类型的消息时,你可以尝试如下几件事情:
- 向集群添加更多节点。
- 终止不需要的 Pod,为悬决的 Pod 腾出空间。
- 检查 Pod 所需的资源是否超出所有节点的资源容量。例如,如果所有节点的容量都是
cpu:1, 那么一个请求为cpu: 1.1的 Pod 永远不会被调度。 - 检查节点上的污点设置。如果集群中节点上存在污点,而新的 Pod 不能容忍污点, 调度器只会考虑将 Pod 调度到不带有该污点的节点上。
你可以使用 kubectl describe nodes 命令检查节点容量和已分配的资源数量。 例如:
kubectl describe nodes e2e-test-node-pool-4lw4
Name: e2e-test-node-pool-4lw4
[ ... 这里忽略了若干行以便阅读 ...]
Capacity:
cpu: 2
memory: 7679792Ki
pods: 110
Allocatable:
cpu: 1800m
memory: 7474992Ki
pods: 110
[ ... 这里忽略了若干行以便阅读 ...]
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system fluentd-gcp-v1.38-28bv1 100m (5%) 0 (0%) 200Mi (2%) 200Mi (2%)
kube-system kube-dns-3297075139-61lj3 260m (13%) 0 (0%) 100Mi (1%) 170Mi (2%)
kube-system kube-proxy-e2e-test-... 100m (5%) 0 (0%) 0 (0%) 0 (0%)
kube-system monitoring-influxdb-grafana-v4-z1m12 200m (10%) 200m (10%) 600Mi (8%) 600Mi (8%)
kube-system node-problem-detector-v0.1-fj7m3 20m (1%) 200m (10%) 20Mi (0%) 100Mi (1%)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
680m (34%) 400m (20%) 920Mi (11%) 1070Mi (13%)
在上面的输出中,你可以看到如果 Pod 请求超过 1.120 CPU 或者 6.23Gi 内存,节点将无法满足。
通过查看 "Pods" 部分,你将看到哪些 Pod 占用了节点上的资源。
Pods 可用的资源量低于节点的资源总量,因为系统守护进程也会使用一部分可用资源。
在 Kubernetes API 中,每个 Node 都有一个 .status.allocatable 字段
(详情参见 NodeStatus)。
字段 .status.allocatable 描述节点上可以用于 Pod 的资源总量(例如:15 个虚拟
CPU、7538 MiB 内存)。关于 Kubernetes 中节点可分配资源的信息,
可参阅为系统守护进程预留计算资源。
你可以配置资源配额功能特性以限制每个名字空间可以使用的资源总量。 当某名字空间中存在 ResourceQuota 时,Kubernetes 会在该名字空间中的对象强制实施配额。 例如,如果你为不同的团队分配名字空间,你可以为这些名字空间添加 ResourceQuota。 设置资源配额有助于防止一个团队占用太多资源,以至于这种占用会影响其他团队。
你还需要考虑为这些名字空间设置授权访问: 为名字空间提供 全部 的写权限时,具有合适权限的人可能删除所有资源, 包括所配置的 ResourceQuota。
我的容器被终止了
你的容器可能因为资源紧张而被终止。要查看容器是否因为遇到资源限制而被杀死,
请针对相关的 Pod 执行 kubectl describe pod:
kubectl describe pod simmemleak-hra99
输出类似于:
Name: simmemleak-hra99
Namespace: default
Image(s): saadali/simmemleak
Node: kubernetes-node-tf0f/10.240.216.66
Labels: name=simmemleak
Status: Running
Reason:
Message:
IP: 10.244.2.75
Containers:
simmemleak:
Image: saadali/simmemleak:latest
Limits:
cpu: 100m
memory: 50Mi
State: Running
Started: Tue, 07 Jul 2019 12:54:41 -0700
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Fri, 07 Jul 2019 12:54:30 -0700
Finished: Fri, 07 Jul 2019 12:54:33 -0700
Ready: False
Restart Count: 5
Conditions:
Type Status
Ready False
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 42s default-scheduler Successfully assigned simmemleak-hra99 to kubernetes-node-tf0f
Normal Pulled 41s kubelet Container image "saadali/simmemleak:latest" already present on machine
Normal Created 41s kubelet Created container simmemleak
Normal Started 40s kubelet Started container simmemleak
Normal Killing 32s kubelet Killing container with id ead3fb35-5cf5-44ed-9ae1-488115be66c6: Need to kill Pod
在上面的例子中,Restart Count: 5 意味着 Pod 中的 simmemleak
容器被终止并且(到目前为止)重启了五次。
原因 OOMKilled 显示容器尝试使用超出其限制的内存量。
你接下来要做的或许是检查应用代码,看看是否存在内存泄露。 如果你发现应用的行为与你所预期的相同,则可以考虑为该容器设置一个更高的内存限制 (也可能需要设置请求值)。
接下来
- 获取分配内存资源给容器和 Pod 的实践经验
- 获取分配 CPU 资源给容器和 Pod 的实践经验
- 阅读 API 参考如何定义容器 及其资源请求。
- 阅读 XFS 中项目配额的文档
- 进一步阅读 kube-scheduler 配置参考(v1)
- 进一步阅读 Pod 的服务质量等级
7.5 - 使用 kubeconfig 文件组织集群访问
使用 kubeconfig 文件来组织有关集群、用户、命名空间和身份认证机制的信息。
kubectl 命令行工具使用 kubeconfig 文件来查找选择集群所需的信息,并与集群的 API 服务器进行通信。
说明:
用于配置集群访问的文件称为 kubeconfig 文件。
这是引用到配置文件的通用方法,并不意味着有一个名为 kubeconfig 的文件。
警告:
请务必仅使用来源可靠的 kubeconfig 文件。使用特制的 kubeconfig 文件可能会导致恶意代码执行或文件暴露。 如果必须使用不受信任的 kubeconfig 文件,请首先像检查 Shell 脚本一样仔细检查此文件。
默认情况下,kubectl 在 $HOME/.kube 目录下查找名为 config 的文件。
你可以通过设置 KUBECONFIG 环境变量或者设置
--kubeconfig参数来指定其他 kubeconfig 文件。
有关创建和指定 kubeconfig 文件的分步说明, 请参阅配置对多集群的访问。
支持多集群、用户和身份认证机制
假设你有多个集群,并且你的用户和组件以多种方式进行身份认证。比如:
- 正在运行的 kubelet 可能使用证书在进行认证。
- 用户可能通过令牌进行认证。
- 管理员可能拥有多个证书集合提供给各用户。
使用 kubeconfig 文件,你可以组织集群、用户和命名空间。你还可以定义上下文,以便在集群和命名空间之间快速轻松地切换。
上下文(Context)
通过 kubeconfig 文件中的 context 元素,使用简便的名称来对访问参数进行分组。
每个 context 都有三个参数:cluster、namespace 和 user。
默认情况下,kubectl 命令行工具使用 当前上下文 中的参数与集群进行通信。
选择当前上下文:
kubectl config use-context
KUBECONFIG 环境变量
KUBECONFIG 环境变量包含一个 kubeconfig 文件列表。
对于 Linux 和 Mac,此列表以英文冒号分隔。对于 Windows,此列表以英文分号分隔。
KUBECONFIG 环境变量不是必需的。
如果 KUBECONFIG 环境变量不存在,kubectl 将使用默认的 kubeconfig 文件:$HOME/.kube/config。
如果 KUBECONFIG 环境变量存在,kubectl 将使用 KUBECONFIG 环境变量中列举的文件合并后的有效配置。
合并 kubeconfig 文件
要查看配置,输入以下命令:
kubectl config view
如前所述,输出可能来自单个 kubeconfig 文件,也可能是合并多个 kubeconfig 文件的结果。
以下是 kubectl 在合并 kubeconfig 文件时使用的规则。
-
如果设置了
--kubeconfig参数,则仅使用指定的文件。不进行合并。此参数只能使用一次。否则,如果设置了
KUBECONFIG环境变量,将它用作应合并的文件列表。根据以下规则合并KUBECONFIG环境变量中列出的文件:- 忽略空文件名。
- 对于内容无法反序列化的文件,产生错误信息。
- 第一个设置特定值或者映射键的文件将生效。
- 永远不会更改值或者映射键。示例:保留第一个文件的上下文以设置
current-context。 示例:如果两个文件都指定了red-user,则仅使用第一个文件的red-user中的值。 即使第二个文件在red-user下有非冲突条目,也要丢弃它们。
有关设置
KUBECONFIG环境变量的示例, 请参阅设置 KUBECONFIG 环境变量。否则,使用默认的 kubeconfig 文件(
$HOME/.kube/config),不进行合并。
-
根据此链中的第一个匹配确定要使用的上下文。
- 如果存在上下文,则使用
--context命令行参数。 - 使用合并的 kubeconfig 文件中的
current-context。
这种场景下允许空上下文。
- 如果存在上下文,则使用
-
确定集群和用户。此时,可能有也可能没有上下文。根据此链中的第一个匹配确定集群和用户, 这将运行两次:一次用于用户,一次用于集群。
- 如果存在用户或集群,则使用命令行参数:
--user或者--cluster。 - 如果上下文非空,则从上下文中获取用户或集群。
这种场景下用户和集群可以为空。
- 如果存在用户或集群,则使用命令行参数:
-
确定要使用的实际集群信息。此时,可能有也可能没有集群信息。 基于此链构建每个集群信息;第一个匹配项会被采用:
- 如果存在集群信息,则使用命令行参数:
--server、--certificate-authority和--insecure-skip-tls-verify。 - 如果合并的 kubeconfig 文件中存在集群信息属性,则使用这些属性。
- 如果没有 server 配置,则配置无效。
- 如果存在集群信息,则使用命令行参数:
-
确定要使用的实际用户信息。使用与集群信息相同的规则构建用户信息,但对于每个用户只允许使用一种身份认证技术:
- 如果存在用户信息,则使用命令行参数:
--client-certificate、--client-key、--username、--password和--token。 - 使用合并的 kubeconfig 文件中的
user字段。 - 如果存在两种冲突技术,则配置无效。
- 如果存在用户信息,则使用命令行参数:
- 对于仍然缺失的任何信息,使用其对应的默认值,并可能提示输入身份认证信息。
文件引用
kubeconfig 文件中的文件和路径引用是相对于 kubeconfig 文件的位置。
命令行上的文件引用是相对于当前工作目录的。
在 $HOME/.kube/config 中,相对路径按相对路径存储,而绝对路径按绝对路径存储。
代理
你可以在 kubeconfig 文件中,为每个集群配置 proxy-url 来让 kubectl 使用代理,例如:
apiVersion: v1
kind: Config
clusters:
- cluster:
proxy-url: http://proxy.example.org:3128
server: https://k8s.example.org/k8s/clusters/c-xxyyzz
name: development
users:
- name: developer
contexts:
- context:
name: development
接下来
7.6 - Windows 节点的资源管理
本页概述了 Linux 和 Windows 在资源管理方式上的区别。
在 Linux 节点上,cgroup 用作资源控制的 Pod 边界。 在这个边界内创建容器以便于隔离网络、进程和文件系统。 Linux cgroup API 可用于收集 CPU、I/O 和内存使用统计数据。
与此相反,Windows 中每个容器对应一个作业对象, 与系统命名空间过滤器一起使用,将所有进程包含在一个容器中,提供与主机的逻辑隔离。 (作业对象是一种 Windows 进程隔离机制,不同于 Kubernetes 提及的 Job)。
如果没有命名空间过滤,就无法运行 Windows 容器。 这意味着在主机环境中无法让系统特权生效,因此特权容器在 Windows 上不可用。 容器不能使用来自主机的标识,因为安全帐户管理器(Security Account Manager,SAM)是独立的。
内存管理
Windows 不像 Linux 一样提供杀手(killer)机制,杀死内存不足的进程。 Windows 始终将所有用户态内存分配视为虚拟内存,并强制使用页面文件(pagefile)。
Windows 节点不会为进程过量使用内存。 最终结果是 Windows 不会像 Linux 那样达到内存不足的情况,Windows 将进程页面放到磁盘, 不会因为内存不足(OOM)而终止进程。 如果内存配置过量且所有物理内存都已耗尽,则换页性能就会降低。
CPU 管理
Windows 可以限制为不同进程分配的 CPU 时间长度,但无法保证最小的 CPU 时间长度。
在 Windows 上,kubelet 支持使用命令行标志来设置 kubelet 进程的调度优先级:
--windows-priorityclass。
与 Windows 主机上运行的其他进程相比,此标志允许 kubelet 进程获取更多的 CPU 时间片。
有关允许值及其含义的更多信息,请访问 Windows 优先级类。
为了确保运行的 Pod 不会耗尽 kubelet 的 CPU 时钟周期,
要将此标志设置为 ABOVE_NORMAL_PRIORITY_CLASS 或更高。
资源预留
为了满足操作系统、容器运行时和 kubelet 等 Kubernetes 主机进程使用的内存和 CPU,
你可以(且应该)用 --kube-reserved 和/或 --system-reserved kubelet 标志来预留内存和 CPU 资源。
在 Windows 上,这些值仅用于计算节点的可分配资源。
注意:
在你部署工作负载时,需对容器设置内存和 CPU 资源的限制。
这也会从 NodeAllocatable 中减去,帮助集群范围的调度器决定哪些 Pod 放到哪些节点上。
若调度 Pod 时未设置限制值,可能对 Windows 节点过量配置资源。 在极端情况下,这会让节点变得不健康。
在 Windows 上,一种好的做法是预留至少 2GiB 的内存。
要决定预留多少 CPU,需明确每个节点的最大 Pod 密度, 并监控节点上运行的系统服务的 CPU 使用率,然后选择一个满足工作负载需求的值。
8 - 安全
确保云原生工作负载安全的一组概念。
Kubernetes 文档的这一部分内容的旨在引导你学习如何更安全地运行工作负载, 以及维护 Kubernetes 集群的基本安全性。
Kubernetes 基于云原生架构,并借鉴了 CNCF 有关云原生信息安全良好实践的建议。
请阅读云原生安全和 Kubernetes, 了解有关如何保护集群及其上运行的应用程序的更广泛背景信息。
Kubernetes 安全机制
Kubernetes 包含多个 API 和安全组件, 以及定义策略的方法,这些策略可以作为你的信息安全管理的一部分。
控制平面保护
任何 Kubernetes 集群的一个关键安全机制是控制对 Kubernetes API 的访问。
Kubernetes 希望你配置并使用 TLS, 以便在控制平面内以及控制平面与其客户端之间提供传输中的数据加密。 你还可以为 Kubernetes 控制平面中存储的数据启用静态加密; 这与对你自己的工作负载数据使用静态加密不同,后者可能也是一个好主意。
Secret
Secret API 为需要保密的配置值提供基本保护。
工具负载保护
实施 Pod 安全标准以确保 Pod 及其容器得到适当隔离。如果需要,你还可以使用 RuntimeClass 来配置自定义隔离。
网络策略(NetworkPolicy) 可让控制 Pod 之间或 Pod 与集群外部网络之间的网络流量。
审计
Kubernetes 审计日志记录提供了一组与安全相关、 按时间顺序排列的记录,记录了集群中的操作序列。 集群审计用户、使用 Kubernetes API 的应用程序以及控制平面本身生成的活动。
云提供商安全
说明: Items on this page refer to vendors external to Kubernetes. The Kubernetes project authors aren't responsible for those third-party products or projects. To add a vendor, product or project to this list, read the content guide before submitting a change. More information.
如果你在自己的硬件或不同的云平台上运行 Kubernetes 集群,请参阅对应云平台的文档以了解安全最佳实践。 以下是一些流行云提供商的安全文档的链接:
策略
你可以使用 Kubernetes 原生机制定义安全策略,例如 NetworkPolicy(对网络数据包过滤的声明式控制) 或 [ValidatingAdmisisonPolicy](/zh-cn/docs/reference/access -authn-authz/validating-admission-policy/) (对某人可以使用 Kubernetes API 进行哪些更改的声明性限制)。
你还可以依赖 Kubernetes 周边更广泛的生态系统的策略实现。 Kubernetes 提供了扩展机制,让这些生态系统项目在源代码审查、 容器镜像审批、API 访问控制、网络等方面实施自己的策略控制。
有关策略机制和 Kubernetes 的更多信息,请阅读策略。
接下来
了解相关的 Kubernetes 安全主题:
- 保护集群
- Kubernetes 中的已知漏洞(以及更多信息的链接)
- 传输中的数据加密(针对控制平面)
- 静态数据加密
- 控制对 Kubernetes API 的访问
- Pod 的 网络策略
- Kubernetes 中的 Secret
- Pod 安全标准
- 运行时类
了解上下文:
获取认证:
- Kubernetes 安全专家认证和官方培训课程。
阅读本节的更多内容:
8.1 - Pod 安全性标准
详细了解 Pod 安全性标准(Pod Security Standards)中所定义的不同策略级别。
Pod 安全性标准定义了三种不同的策略(Policy),以广泛覆盖安全应用场景。 这些策略是叠加式的(Cumulative),安全级别从高度宽松至高度受限。 本指南概述了每个策略的要求。
| Profile | 描述 |
|---|---|
| Privileged | 不受限制的策略,提供最大可能范围的权限许可。此策略允许已知的特权提升。 |
| Baseline | 限制性最弱的策略,禁止已知的特权提升。允许使用默认的(规定最少)Pod 配置。 |
| Restricted | 限制性非常强的策略,遵循当前的保护 Pod 的最佳实践。 |
Profile 细节
Privileged
Privileged 策略是有目的地开放且完全无限制的策略。 此类策略通常针对由特权较高、受信任的用户所管理的系统级或基础设施级负载。
Privileged 策略定义中限制较少。默认允许的(Allow-by-default)实施机制(例如 gatekeeper) 可以缺省设置为 Privileged。 与此不同,对于默认拒绝(Deny-by-default)的实施机制(如 Pod 安全策略)而言, Privileged 策略应该禁止所有限制。
Baseline
Baseline 策略的目标是便于常见的容器化应用采用,同时禁止已知的特权提升。 此策略针对的是应用运维人员和非关键性应用的开发人员。 下面列举的控制应该被实施(禁止):
说明:
在下述表格中,通配符(*)意味着一个列表中的所有元素。
例如 spec.containers[*].securityContext 表示所定义的所有容器的安全性上下文对象。
如果所列出的任一容器不能满足要求,整个 Pod 将无法通过校验。
| 控制(Control) | 策略(Policy) |
| HostProcess |
Windows Pod 提供了运行 HostProcess 容器 的能力,这使得对 Windows 节点的特权访问成为可能。Baseline 策略中禁止对宿主的特权访问。
特性状态:
Kubernetes v1.26 [stable]
限制的字段
准许的取值
|
| 宿主名字空间 |
必须禁止共享宿主上的名字空间。 限制的字段
准许的取值
|
| 特权容器 |
特权 Pod 会使大多数安全性机制失效,必须被禁止。 限制的字段
准许的取值
|
| 权能 |
必须禁止添加除下列字段之外的权能。 限制的字段
准许的取值
|
| HostPath 卷 |
必须禁止 HostPath 卷。 限制的字段
准许的取值
|
| 宿主端口 |
应该完全禁止使用宿主端口(推荐)或者至少限制只能使用某确定列表中的端口。 限制的字段
准许的取值
|
| AppArmor |
在受支持的主机上,默认使用 限制的字段
准许的取值
|
| SELinux |
设置 SELinux 类型的操作是被限制的,设置自定义的 SELinux 用户或角色选项是被禁止的。 限制的字段
准许的取值
限制的字段
准许的取值
|
/proc挂载类型 |
要求使用默认的 限制的字段
准许的取值
|
| Seccomp |
Seccomp 配置必须不能显式设置为 限制的字段
准许的取值
|
| Sysctls |
Sysctls 可以禁用安全机制或影响宿主上所有容器,因此除了若干“安全”的子集之外,应该被禁止。如果某 sysctl 是受容器或 Pod 的名字空间限制,且与节点上其他 Pod 或进程相隔离,可认为是安全的。 限制的字段
准许的取值
|
Restricted
Restricted 策略旨在实施当前保护 Pod 的最佳实践,尽管这样作可能会牺牲一些兼容性。 该类策略主要针对运维人员和安全性很重要的应用的开发人员,以及不太被信任的用户。 下面列举的控制需要被实施(禁止):
说明:
在下述表格中,通配符(*)意味着一个列表中的所有元素。
例如 spec.containers[*].securityContext 表示 所定义的所有容器 的安全性上下文对象。
如果所列出的任一容器不能满足要求,整个 Pod 将无法通过校验。
| 控制 | 策略 |
| Baseline 策略的所有要求。 | |
| 卷类型 |
除了限制 HostPath 卷之外,此类策略还限制可以通过 PersistentVolumes 定义的非核心卷类型。 限制的字段
准许的取值 spec.volumes[*] 列表中的每个条目必须将下面字段之一设置为非空值:
|
| 特权提升(v1.8+) |
禁止(通过 SetUID 或 SetGID 文件模式)获得特权提升。这是 v1.25+ 中仅针对 Linux 的策略 限制的字段
允许的取值
|
| 以非 root 账号运行 |
容器必须以非 root 账号运行。 限制的字段
准许的取值
spec.securityContext.runAsNonRoot 设置为 true,则允许容器组的安全上下文字段设置为 未定义/nil。
|
| 非 root 用户(v1.23+) |
容器不可以将 runAsUser 设置为 0 限制的字段
准许的取值
|
| Seccomp (v1.19+) |
Seccomp Profile 必须被显式设置成一个允许的值。禁止使用 限制的字段
准许的取值
spec.securityContext.seccompProfile.type
已设置得当,容器级别的安全上下文字段可以为未定义/nil。
反之如果 nil。
|
| 权能(v1.22+) |
容器必须弃用 限制的字段
准许的取值
限制的字段
准许的取值
|
策略实例化
将策略定义从策略实例中解耦出来有助于形成跨集群的策略理解和语言陈述, 以免绑定到特定的下层实施机制。
随着相关机制的成熟,这些机制会按策略分别定义在下面。特定策略的实施方法不在这里定义。
替代方案
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
在 Kubernetes 生态系统中还在开发一些其他的替代方案,例如:
Pod OS 字段
Kubernetes 允许你使用运行 Linux 或 Windows 的节点。你可以在一个集群中混用两种类型的节点。
Kubernetes 中的 Windows 与基于 Linux 的工作负载相比有一些限制和差异。
具体而言,许多 Pod securityContext
字段在 Windows 上不起作用。
说明:
v1.24 之前的 Kubelet 不强制处理 Pod OS 字段,如果集群中有些节点运行早于 v1.24 的版本, 则应将限制性的策略锁定到 v1.25 之前的版本。
限制性的 Pod Security Standard 变更
Kubernetes v1.25 中的另一个重要变化是限制性的(Restricted) Pod 安全性已更新,
能够处理 pod.spec.os.name 字段。根据 OS 名称,专用于特定 OS 的某些策略对其他 OS 可以放宽限制。
OS 特定的策略控制
仅当 .spec.os.name 不是 windows 时,才需要对以下控制进行限制:
- 特权提升
- Seccomp
- Linux 权能
用户命名空间
用户命名空间是 Linux 特有的功能,可在运行工作负载时提高隔离度。 关于用户命名空间如何与 PodSecurityStandard 协同工作, 请参阅 文档 了解 Pod 如何使用用户命名空间。
常见问题
为什么不存在介于 Privileged 和 Baseline 之间的策略类型
这里定义的三种策略框架有一个明晰的线性递进关系,从最安全(Restricted)到最不安全, 并且覆盖了很大范围的工作负载。特权要求超出 Baseline 策略者通常是特定于应用的需求, 所以我们没有在这个范围内提供标准框架。 这并不意味着在这样的情形下仍然只能使用 Privileged 框架, 只是说处于这个范围的策略需要因地制宜地定义。
SIG Auth 可能会在将来考虑这个范围的框架,前提是有对其他框架的需求。
安全配置与安全上下文的区别是什么?
安全上下文在运行时配置 Pod 和容器。安全上下文是在 Pod 清单中作为 Pod 和容器规约的一部分来定义的, 所代表的是传递给容器运行时的参数。
安全策略则是控制面用来对安全上下文以及安全性上下文之外的参数实施某种设置的机制。 在 2020 年 7 月, Pod 安全性策略已被废弃, 取而代之的是内置的 Pod 安全性准入控制器。
沙箱(Sandboxed)Pod 怎么处理?
现在还没有 API 标准来控制 Pod 是否被视作沙箱化 Pod。 沙箱 Pod 可以通过其是否使用沙箱化运行时(如 gVisor 或 Kata Container)来辨别, 不过目前还没有关于什么是沙箱化运行时的标准定义。
沙箱化负载所需要的保护可能彼此各不相同。例如,当负载与下层内核直接隔离开来时, 限制特权化操作的许可就不那么重要。这使得那些需要更多许可权限的负载仍能被有效隔离。
此外,沙箱化负载的保护高度依赖于沙箱化的实现方法。 因此,现在还没有针对所有沙箱化负载的建议配置。
8.2 - 服务账号
了解 Kubernetes 中的 ServiceAccount 对象。
本页介绍 Kubernetes 中的 ServiceAccount 对象, 讲述服务账号的工作原理、使用场景、限制、替代方案,还提供了一些资源链接方便查阅更多指导信息。
什么是服务账号?
服务账号是在 Kubernetes 中一种用于非人类用户的账号,在 Kubernetes 集群中提供不同的身份标识。 应用 Pod、系统组件以及集群内外的实体可以使用特定 ServiceAccount 的凭据来将自己标识为该 ServiceAccount。 这种身份可用于许多场景,包括向 API 服务器进行身份认证或实现基于身份的安全策略。
服务账号以 ServiceAccount 对象的形式存在于 API 服务器中。服务账号具有以下属性:
-
名字空间限定: 每个服务账号都与一个 Kubernetes 名字空间绑定。 每个名字空间在创建时,会获得一个名为
default的 ServiceAccount。 -
轻量级: 服务账号存在于集群中,并在 Kubernetes API 中定义。你可以快速创建服务账号以支持特定任务。
- 可移植性: 复杂的容器化工作负载的配置包中可能包括针对系统组件的服务账号定义。 服务账号的轻量级性质和名字空间作用域的身份使得这类配置可移植。
服务账号与用户账号不同,用户账号是集群中通过了身份认证的人类用户。默认情况下, 用户账号不存在于 Kubernetes API 服务器中;相反,API 服务器将用户身份视为不透明数据。 你可以使用多种方法认证为某个用户账号。某些 Kubernetes 发行版可能会添加自定义扩展 API 来在 API 服务器中表示用户账号。
| 描述 | 服务账号 | 用户或组 |
|---|---|---|
| 位置 | Kubernetes API(ServiceAccount 对象) | 外部 |
| 访问控制 | Kubernetes RBAC 或其他鉴权机制 | Kubernetes RBAC 或其他身份和访问管理机制 |
| 目标用途 | 工作负载、自动化工具 | 人 |
默认服务账号
在你创建集群时,Kubernetes 会自动为集群中的每个名字空间创建一个名为 default 的 ServiceAccount 对象。
在启用了基于角色的访问控制(RBAC)时,Kubernetes 为所有通过了身份认证的主体赋予
默认 API 发现权限。
每个名字空间中的 default 服务账号除了这些权限之外,默认没有其他访问权限。
如果基于角色的访问控制(RBAC)被启用,当你删除名字空间中的 default ServiceAccount 对象时,
控制平面会用新的 ServiceAccount 对象替换它。
如果你在某个名字空间中部署 Pod,并且你没有手动为 Pod 指派 ServiceAccount,
Kubernetes 将该名字空间的 default 服务账号指派给这一 Pod。
Kubernetes 服务账号的使用场景
一般而言,你可以在以下场景中使用服务账号来提供身份标识:
- 你的 Pod 需要与 Kubernetes API 服务器通信,例如在以下场景中:
- 提供对存储在 Secret 中的敏感信息的只读访问。
- 授予跨名字空间访问的权限,例如允许
example名字空间中的 Pod 读取、列举和监视kube-node-lease名字空间中的 Lease 对象。
- 你的 Pod 需要与外部服务进行通信。例如,工作负载 Pod 需要一个身份来访问某商业化的云 API, 并且商业化 API 的提供商允许配置适当的信任关系。
- 使用
imagePullSecret完成在私有镜像仓库上的身份认证。
- 外部服务需要与 Kubernetes API 服务器进行通信。例如,作为 CI/CD 流水线的一部分向集群作身份认证。
- 你在集群中使用了第三方安全软件,该软件依赖不同 Pod 的 ServiceAccount 身份,按不同上下文对这些 Pod 分组。
如何使用服务账号
要使用 Kubernetes 服务账号,你需要执行以下步骤:
- 使用像
kubectl这样的 Kubernetes 客户端或定义对象的清单(manifest)创建 ServiceAccount 对象。 - 使用鉴权机制(如 RBAC)为 ServiceAccount 对象授权。
-
在创建 Pod 期间将 ServiceAccount 对象指派给 Pod。
如果你所使用的是来自外部服务的身份,可以获取 ServiceAccount 令牌,并在该服务中使用这一令牌。
有关具体操作说明,参阅为 Pod 配置服务账号。
为 ServiceAccount 授权
你可以使用 Kubernetes 内置的 基于角色的访问控制 (RBAC)机制来为每个服务账号授予所需的最低权限。 你可以创建一个用来授权的角色,然后将此角色绑定到你的 ServiceAccount 上。 RBAC 可以让你定义一组最低权限,使得服务账号权限遵循最小特权原则。 这样使用服务账号的 Pod 不会获得超出其正常运行所需的权限。
有关具体操作说明,参阅 ServiceAccount 权限。
使用 ServiceAccount 进行跨名字空间访问
你可以使用 RBAC 允许一个名字空间中的服务账号对集群中另一个名字空间的资源执行操作。
例如,假设你在 dev 名字空间中有一个服务账号和一个 Pod,并且希望该 Pod 可以查看 maintenance
名字空间中正在运行的 Job。你可以创建一个 Role 对象来授予列举 Job 对象的权限。
随后在 maintenance 名字空间中创建 RoleBinding 对象将 Role 绑定到此 ServiceAccount 对象上。
现在,dev 名字空间中的 Pod 可以使用该服务账号列出 maintenance 名字空间中的 Job 对象集合。
将 ServiceAccount 指派给 Pod
要将某 ServiceAccount 指派给某 Pod,你需要在该 Pod 的规约中设置 spec.serviceAccountName 字段。
Kubernetes 将自动为 Pod 提供该 ServiceAccount 的凭据。在 Kubernetes v1.22 及更高版本中,
Kubernetes 使用 TokenRequest API 获取一个短期的、自动轮换的令牌,
并以投射卷的形式挂载此令牌。
默认情况下,Kubernetes 会将所指派的 ServiceAccount
(无论是 default 服务账号还是你指定的定制 ServiceAccount)的凭据提供给 Pod。
要防止 Kubernetes 自动注入指定的 ServiceAccount 或 default ServiceAccount 的凭据,
可以将 Pod 规约中的 automountServiceAccountToken 字段设置为 false。
在 Kubernetes 1.22 之前的版本中,Kubernetes 会将一个长期有效的静态令牌以 Secret 形式提供给 Pod。
手动获取 ServiceAccount 凭据
如果你需要 ServiceAccount 的凭据并将其挂载到非标准位置,或者用于 API 服务器之外的受众,可以使用以下方法之一:
- TokenRequest API(推荐): 在你自己的应用代码中请求一个短期的服务账号令牌。此令牌会自动过期,并可在过期时被轮换。 如果你有一个旧的、对 Kubernetes 无感知能力的应用,你可以在同一个 Pod 内使用边车容器来获取这些令牌,并将其提供给应用工作负载。
- 令牌卷投射(同样推荐): 在 Kubernetes v1.20 及更高版本中,使用 Pod 规约告知 kubelet 将服务账号令牌作为投射卷添加到 Pod 中。 所投射的令牌会自动过期,在过期之前 kubelet 会自动轮换此令牌。
- 服务账号令牌 Secret(不推荐):
你可以将服务账号令牌以 Kubernetes Secret 的形式挂载到 Pod 中。这些令牌不会过期且不会轮换。
不推荐使用此方法,特别是在大规模场景下,这是因为静态、长期有效的凭据存在一定的风险。在 Kubernetes v1.24 及更高版本中,
LegacyServiceAccountTokenNoAutoGeneration 特性门控阻止
Kubernetes 自动为 ServiceAccount 创建这些令牌。
LegacyServiceAccountTokenNoAutoGeneration默认被启用, 也就是说,Kubernetes 不会创建这些令牌。
说明:
对于运行在 Kubernetes 集群外的应用,你可能考虑创建一个长期有效的 ServiceAccount 令牌, 并将其存储在 Secret 中。尽管这种方式可以实现身份认证,但 Kubernetes 项目建议你避免使用此方法。 长期有效的持有者令牌(Bearer Token)会带来安全风险,一旦泄露,此令牌就可能被滥用。 为此,你可以考虑使用其他替代方案。例如,你的外部应用可以使用一个保护得很好的私钥和证书进行身份认证, 或者使用你自己实现的身份认证 Webhook 这类自定义机制。
你还可以使用 TokenRequest 为外部应用获取短期的令牌。
限制对 Secret 的访问
Kubernetes 提供了名为 kubernetes.io/enforce-mountable-secrets 的注解,
你可以添加到你的 ServiceAccount 中。当应用了这个注解后,
ServiceAccount 的 Secret 只能挂载到特定类型的资源上,从而增强集群的安全性。
你可以使用以下清单将注解添加到一个 ServiceAccount 中:
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
kubernetes.io/enforce-mountable-secrets: "true"
name: my-serviceaccount
namespace: my-namespace
当此注解设置为 "true" 时,Kubernetes 控制平面确保来自该 ServiceAccount 的 Secret 受到特定挂载限制。
- 在 Pod 中作为卷挂载的每个 Secret 的名称必须列在该 Pod 中 ServiceAccount 的
secrets字段中。
- 在 Pod 中使用
envFrom引用的每个 Secret 的名称也必须列在该 Pod 中 ServiceAccount 的secrets字段中。
- 在 Pod 中使用
imagePullSecrets引用的每个 Secret 的名称也必须列在该 Pod 中 ServiceAccount 的secrets字段中。
通过理解并执行这些限制,集群管理员可以维护更严格的安全配置,并确保 Secret 仅被适当的资源访问。
对服务账号凭据进行鉴别
ServiceAccount 使用签名的 JSON Web Token (JWT) 来向 Kubernetes API
服务器以及任何其他存在信任关系的系统进行身份认证。根据令牌的签发方式
(使用 TokenRequest 限制时间或使用传统的 Secret 机制),ServiceAccount
令牌也可能有到期时间、受众和令牌开始生效的时间点。
当客户端以 ServiceAccount 的身份尝试与 Kubernetes API 服务器通信时,
客户端会在 HTTP 请求中包含 Authorization: Bearer <token> 标头。
API 服务器按照以下方式检查该持有者令牌的有效性:
- 检查令牌签名。
- 检查令牌是否已过期。
- 检查令牌申明中的对象引用是否当前有效。
- 检查令牌是否当前有效。
- 检查受众申明。
TokenRequest API 为 ServiceAccount 生成绑定令牌。这种绑定与以该 ServiceAccount 身份运行的客户端(如 Pod)的生命期相关联。有关绑定 Pod 服务账号令牌的 JWT 模式和载荷的示例, 请参阅服务账号令牌卷投射。
对于使用 TokenRequest API 签发的令牌,API 服务器还会检查正在使用 ServiceAccount 的特定对象引用是否仍然存在,
方式是通过该对象的唯一 ID 进行匹配。
对于以 Secret 形式挂载到 Pod 中的旧有令牌,API 服务器会基于 Secret 来检查令牌。
有关身份认证过程的更多信息,参考身份认证。
在自己的代码中检查服务账号凭据
如果你的服务需要检查 Kubernetes 服务账号凭据,可以使用以下方法:
- TokenReview API(推荐)
- OIDC 发现
Kubernetes 项目建议你使用 TokenReview API,因为当你删除某些 API 对象 (如 Secret、ServiceAccount、Pod 和 Node)的时候,此方法将使绑定到这些 API 对象上的令牌失效。 例如,如果删除包含投射 ServiceAccount 令牌的 Pod,则集群立即使该令牌失效, 并且 TokenReview 操作也会立即失败。 如果你使用的是 OIDC 验证,则客户端将继续将令牌视为有效,直到令牌达到其到期时间戳。
你的应用应始终定义其所接受的受众,并检查令牌的受众是否与应用期望的受众匹配。 这有助于将令牌的作用域最小化,这样它只能在你的应用内部使用,而不能在其他地方使用。
替代方案
- 使用其他机制签发你自己的令牌,然后使用 Webhook 令牌身份认证通过你自己的验证服务来验证持有者令牌。
- 为 Pod 提供你自己的身份:
-
使用 SPIFFE CSI 驱动插件将 SPIFFE SVID 作为 X.509 证书对提供给 Pod。
🛇 本条目指向第三方项目或产品,而该项目(产品)不是 Kubernetes 的一部分。更多信息
-
- 从集群外部向 API 服务器进行身份认证,而不使用服务账号令牌:
- 配置 API 服务器接受来自你自己的身份驱动的 OpenID Connect (OIDC) 令牌。
- 使用来自云提供商等外部身份和访问管理 (IAM) 服务创建的服务账号或用户账号向集群进行身份认证。
- 使用 CertificateSigningRequest API 和客户端证书。
- 配置 kubelet 从镜像仓库中获取凭据。
- 使用设备插件访问虚拟的可信平台模块 (TPM),进而可以使用私钥进行身份认证。
接下来
8.3 - Pod 安全性准入
对 Pod 安全性准入控制器的概述,Pod 安全性准入控制器可以实施 Pod 安全性标准。
特性状态:
Kubernetes v1.25 [stable]
Kubernetes Pod 安全性标准(Security Standard) 为 Pod 定义不同的隔离级别。这些标准能够让你以一种清晰、一致的方式定义如何限制 Pod 行为。
Kubernetes 提供了一个内置的 Pod Security 准入控制器来执行 Pod 安全标准 (Pod Security Standard)。 创建 Pod 时在名字空间级别应用这些 Pod 安全限制。
内置 Pod 安全准入强制执行
本页面是 Kubernetes v1.29 文档的一部分。 如果你运行的是其他版本的 Kubernetes,请查阅该版本的文档。
Pod 安全性级别
Pod 安全性准入插件对 Pod
的安全性上下文有一定的要求,
并且依据 Pod 安全性标准所定义的三个级别
(privileged、baseline 和 restricted)对其他字段也有要求。
关于这些需求的更进一步讨论,请参阅
Pod 安全性标准页面。
为名字空间设置 Pod 安全性准入控制标签
一旦特性被启用或者安装了 Webhook,你可以配置名字空间以定义每个名字空间中 Pod 安全性准入控制模式。 Kubernetes 定义了一组标签, 你可以设置这些标签来定义某个名字空间上要使用的预定义的 Pod 安全性标准级别。 你所选择的标签定义了检测到潜在违例时, 控制面要采取什么样的动作。
| 模式 | 描述 |
|---|---|
| enforce | 策略违例会导致 Pod 被拒绝 |
| audit | 策略违例会触发审计日志中记录新事件时添加审计注解;但是 Pod 仍是被接受的。 |
| warn | 策略违例会触发用户可见的警告信息,但是 Pod 仍是被接受的。 |
名字空间可以配置任何一种或者所有模式,或者甚至为不同的模式设置不同的级别。
对于每种模式,决定所使用策略的标签有两个:
# 模式的级别标签用来标示对应模式所应用的策略级别
#
# MODE 必须是 `enforce`、`audit` 或 `warn` 之一
# LEVEL 必须是 `privileged`、baseline` 或 `restricted` 之一
pod-security.kubernetes.io/<MODE>: <LEVEL>
# 可选:针对每个模式版本的版本标签可以将策略锁定到
# 给定 Kubernetes 小版本号所附带的版本(例如 v1.29)
#
# MODE 必须是 `enforce`、`audit` 或 `warn` 之一
# VERSION 必须是一个合法的 Kubernetes 小版本号或者 `latest`
pod-security.kubernetes.io/<MODE>-version: <VERSION>
关于用法示例,可参阅使用名字空间标签来强制实施 Pod 安全标准。
负载资源和 Pod 模板
Pod 通常是通过创建 Deployment 或
Job
这类工作负载对象来间接创建的。
工作负载对象为工作负载资源定义一个 Pod 模板和一个对应的负责基于该模板来创建
Pod 的控制器。
为了尽早地捕获违例状况,audit 和 warn 模式都应用到负载资源。
不过,enforce 模式并不应用到工作负载资源,仅应用到所生成的 Pod 对象上。
豁免
你可以为 Pod 安全性的实施设置豁免(Exemptions) 规则, 从而允许创建一些本来会被与给定名字空间相关的策略所禁止的 Pod。 豁免规则可以在准入控制器配置 中静态配置。
豁免规则必须显式枚举。满足豁免标准的请求会被准入控制器忽略
(所有 enforce、audit 和 warn 行为都会被略过)。
豁免的维度包括:
- Username: 来自用户名已被豁免的、已认证的(或伪装的)的用户的请求会被忽略。
- RuntimeClassName: 指定了已豁免的运行时类名称的 Pod 和负载资源会被忽略。
- Namespace: 位于被豁免的名字空间中的 Pod 和负载资源会被忽略。
注意:
大多数 Pod 是作为对工作负载资源的响应,
由控制器所创建的,这意味着为某最终用户提供豁免时,只会当该用户直接创建 Pod
时对其实施安全策略的豁免。用户创建工作负载资源时不会被豁免。
控制器服务账号(例如:system:serviceaccount:kube-system:replicaset-controller)
通常不应该被豁免,因为豁免这类服务账号隐含着对所有能够创建对应工作负载资源的用户豁免。
策略检查时会对以下 Pod 字段的更新操作予以豁免,这意味着如果 Pod 更新请求仅改变这些字段时,即使 Pod 违反了当前的策略级别,请求也不会被拒绝。
- 除了对 seccomp 或 AppArmor 注解之外的所有元数据(Metadata)更新操作:
seccomp.security.alpha.kubernetes.io/pod(已弃用)container.seccomp.security.alpha.kubernetes.io/*(已弃用)container.apparmor.security.beta.kubernetes.io/*
- 对
.spec.activeDeadlineSeconds的合法更新 - 对
.spec.tolerations的合法更新
指标
以下是 kube-apiserver 公开的 Prometheus 指标:
pod_security_errors_total:此指标表示妨碍正常评估的错误数量。 如果错误是非致命的,kube-apiserver 可能会强制实施最新的受限配置。pod_security_evaluations_total:此指标表示已发生的策略评估的数量, 不包括导出期间被忽略或豁免的请求。pod_security_exemptions_total:该指标表示豁免请求的数量, 不包括被忽略或超出范围的请求。
接下来
如果你正运行较老版本的 Kubernetes,想要升级到不包含 PodSecurityPolicy 的 Kubernetes 版本, 可以参阅从 PodSecurityPolicy 迁移到内置的 PodSecurity 准入控制器。
8.4 - Pod 安全策略
被移除的特性
PodSecurityPolicy 在 Kubernetes v1.21 中被弃用, 在 Kubernetes v1.25 中被移除。
作为替代,你可以使用下面任一方式执行类似的限制,或者同时使用下面这两种方式。
- Pod 安全准入
- 自行部署并配置第三方准入插件
有关如何迁移, 参阅从 PodSecurityPolicy 迁移到内置的 PodSecurity 准入控制器。 有关移除此 API 的更多信息,参阅 弃用 PodSecurityPolicy:过去、现在、未来。
如果所运行的 Kubernetes 不是 v1.29 版本,则需要查看你所使用的 Kubernetes 版本的对应文档。
8.5 - Windows 节点的安全性
本篇介绍特定于 Windows 操作系统的安全注意事项和最佳实践。
保护节点上的 Secret 数据
在 Windows 上,来自 Secret 的数据以明文形式写入节点的本地存储 (与在 Linux 上使用 tmpfs / 内存中文件系统不同)。 作为集群操作员,你应该采取以下两项额外措施:
- 使用文件 ACL 来保护 Secret 的文件位置。
- 使用 BitLocker 进行卷级加密。
容器用户
可以为 Windows Pod 或容器指定 RunAsUsername 以作为特定用户执行容器进程。这大致相当于 RunAsUser。
Windows 容器提供两个默认用户帐户,ContainerUser 和 ContainerAdministrator。 在微软的 Windows 容器安全 文档 何时使用 ContainerAdmin 和 ContainerUser 用户帐户 中介绍了这两个用户帐户之间的区别。
在容器构建过程中,可以将本地用户添加到容器镜像中。
说明:
- 基于 Nano Server 的镜像默认以
ContainerUser运行 - 基于 Server Core 的镜像默认以
ContainerAdministrator运行
Windows 容器还可以通过使用组管理的服务账号作为 Active Directory 身份运行。
Pod 级安全隔离
Windows 节点不支持特定于 Linux 的 Pod 安全上下文机制(例如 SELinux、AppArmor、Seccomp 或自定义 POSIX 权能字)。
Windows 上不支持特权容器。 然而,可以在 Windows 上使用 HostProcess 容器来执行 Linux 上特权容器执行的许多任务。
8.6 - Kubernetes API 访问控制
本页面概述了对 Kubernetes API 的访问控制。
用户使用 kubectl、客户端库或构造 REST 请求来访问 Kubernetes API。
人类用户和 Kubernetes 服务账号都可以被鉴权访问 API。
当请求到达 API 时,它会经历多个阶段,如下图所示:

传输安全
默认情况下,Kubernetes API 服务器在第一个非 localhost 网络接口的 6443 端口上进行监听,
受 TLS 保护。在一个典型的 Kubernetes 生产集群中,API 使用 443 端口。
该端口可以通过 --secure-port 进行变更,监听 IP 地址可以通过 --bind-address 标志进行变更。
API 服务器出示证书。该证书可以使用私有证书颁发机构(CA)签名,也可以基于链接到公认的 CA 的公钥基础架构签名。
该证书和相应的私钥可以通过使用 --tls-cert-file 和 --tls-private-key-file 标志进行设置。
如果你的集群使用私有证书颁发机构,你需要在客户端的 ~/.kube/config 文件中提供该 CA 证书的副本,
以便你可以信任该连接并确认该连接没有被拦截。
你的客户端可以在此阶段出示 TLS 客户端证书。
认证
如上图步骤 1 所示,建立 TLS 后, HTTP 请求将进入认证(Authentication)步骤。 集群创建脚本或者集群管理员配置 API 服务器,使之运行一个或多个身份认证组件。 身份认证组件在认证节中有更详细的描述。
认证步骤的输入整个 HTTP 请求;但是,通常组件只检查头部或/和客户端证书。
认证模块包含客户端证书、密码、普通令牌、引导令牌和 JSON Web 令牌(JWT,用于服务账号)。
可以指定多个认证模块,在这种情况下,服务器依次尝试每个验证模块,直到其中一个成功。
如果请求认证不通过,服务器将以 HTTP 状态码 401 拒绝该请求。
反之,该用户被认证为特定的 username,并且该用户名可用于后续步骤以在其决策中使用。
部分验证器还提供用户的组成员身份,其他则不提供。
鉴权
如上图的步骤 2 所示,将请求验证为来自特定的用户后,请求必须被鉴权。
请求必须包含请求者的用户名、请求的行为以及受该操作影响的对象。 如果现有策略声明用户有权完成请求的操作,那么该请求被鉴权通过。
例如,如果 Bob 有以下策略,那么他只能在 projectCaribou 名称空间中读取 Pod。
{
"apiVersion": "abac.authorization.kubernetes.io/v1beta1",
"kind": "Policy",
"spec": {
"user": "bob",
"namespace": "projectCaribou",
"resource": "pods",
"readonly": true
}
}
如果 Bob 执行以下请求,那么请求会被鉴权,因为允许他读取 projectCaribou 名称空间中的对象。
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"spec": {
"resourceAttributes": {
"namespace": "projectCaribou",
"verb": "get",
"group": "unicorn.example.org",
"resource": "pods"
}
}
}
如果 Bob 在 projectCaribou 名字空间中请求写(create 或 update)对象,其鉴权请求将被拒绝。
如果 Bob 在诸如 projectFish 这类其它名字空间中请求读取(get)对象,其鉴权也会被拒绝。
Kubernetes 鉴权要求使用公共 REST 属性与现有的组织范围或云提供商范围的访问控制系统进行交互。 使用 REST 格式很重要,因为这些控制系统可能会与 Kubernetes API 之外的 API 交互。
Kubernetes 支持多种鉴权模块,例如 ABAC 模式、RBAC 模式和 Webhook 模式等。 管理员创建集群时,他们配置应在 API 服务器中使用的鉴权模块。 如果配置了多个鉴权模块,则 Kubernetes 会检查每个模块,任意一个模块鉴权该请求,请求即可继续; 如果所有模块拒绝了该请求,请求将会被拒绝(HTTP 状态码 403)。
要了解更多有关 Kubernetes 鉴权的更多信息,包括有关使用支持鉴权模块创建策略的详细信息, 请参阅鉴权。
准入控制
准入控制模块是可以修改或拒绝请求的软件模块。 除鉴权模块可用的属性外,准入控制模块还可以访问正在创建或修改的对象的内容。
准入控制器对创建、修改、删除或(通过代理)连接对象的请求进行操作。 准入控制器不会对仅读取对象的请求起作用。 有多个准入控制器被配置时,服务器将依次调用它们。
这一操作如上图的步骤 3 所示。
与身份认证和鉴权模块不同,如果任何准入控制器模块拒绝某请求,则该请求将立即被拒绝。
除了拒绝对象之外,准入控制器还可以为字段设置复杂的默认值。
可用的准入控制模块在准入控制器中进行了描述。
请求通过所有准入控制器后,将使用检验例程检查对应的 API 对象,然后将其写入对象存储(如步骤 4 所示)。
审计
Kubernetes 审计提供了一套与安全相关的、按时间顺序排列的记录,其中记录了集群中的操作序列。 集群对用户、使用 Kubernetes API 的应用程序以及控制平面本身产生的活动进行审计。
更多信息请参考审计。
接下来
阅读更多有关身份认证、鉴权和 API 访问控制的文档:
你可以了解:
- Pod 如何使用 Secret 获取 API 凭据。
8.7 - 基于角色的访问控制良好实践
为集群操作人员提供的良好的 RBAC 设计原则和实践。
Kubernetes RBAC 是一项重要的安全控制措施,用于保证集群用户和工作负载只能访问履行自身角色所需的资源。 在为集群用户设计权限时,请务必确保集群管理员知道可能发生特权提级的地方, 降低因过多权限而导致安全事件的风险。
此文档的良好实践应该与通用 RBAC 文档一起阅读。
通用的良好实践
最小特权
理想情况下,分配给用户和服务帐户的 RBAC 权限应该是最小的。 仅应使用操作明确需要的权限,虽然每个集群会有所不同,但可以应用的一些常规规则:
- 尽可能在命名空间级别分配权限。授予用户在特定命名空间中的权限时使用 RoleBinding 而不是 ClusterRoleBinding。
- 尽可能避免通过通配符设置权限,尤其是对所有资源的权限。 由于 Kubernetes 是一个可扩展的系统,因此通过通配符来授予访问权限不仅会授予集群中当前的所有对象类型, 还包含所有未来被创建的所有对象类型。
- 管理员不应使用
cluster-admin账号,除非特别需要。为低特权帐户提供 伪装权限 可以避免意外修改集群资源。 - 避免将用户添加到
system:masters组。任何属于此组成员的用户都会绕过所有 RBAC 权限检查, 始终具有不受限制的超级用户访问权限,并且不能通过删除RoleBinding或ClusterRoleBinding来取消其权限。顺便说一句,如果集群使用 Webhook 鉴权,此组的成员身份也会绕过该 Webhook(来自属于该组成员的用户的请求永远不会发送到 Webhook)。
最大限度地减少特权令牌的分发
理想情况下,不应为 Pod 分配具有强大权限(例如,在特权提级的风险中列出的任一权限) 的服务帐户。如果工作负载需要比较大的权限,请考虑以下做法:
- 限制运行此类 Pod 的节点数量。确保你运行的任何 DaemonSet 都是必需的, 并且以最小权限运行,以限制容器逃逸的影响范围。
- 避免将此类 Pod 与不可信任或公开的 Pod 在一起运行。 考虑使用污点和容忍度、 节点亲和性或 Pod 反亲和性确保 Pod 不会与不可信或不太受信任的 Pod 一起运行。 特别注意可信度不高的 Pod 不符合 Restricted Pod 安全标准的情况。
加固
Kubernetes 默认提供访问权限并非是每个集群都需要的。
审查默认提供的 RBAC 权限为安全加固提供了机会。
一般来说,不应该更改 system: 帐户的某些权限,有一些方式来强化现有集群的权限:
- 审查
system:unauthenticated组的绑定,并在可能的情况下将其删除, 因为这会给所有能够访问 API 服务器的人以网络级别的权限。 - 通过设置
automountServiceAccountToken: false来避免服务账号令牌的默认自动挂载, 有关更多详细信息,请参阅使用默认服务账号令牌。 此参数可覆盖 Pod 服务账号设置,而需要服务账号令牌的工作负载仍可以挂载。
定期检查
定期检查 Kubernetes RBAC 设置是否有冗余条目和提权可能性是至关重要的。 如果攻击者能够创建与已删除用户同名的用户账号, 他们可以自动继承被删除用户的所有权限,尤其是分配给该用户的权限。
Kubernetes RBAC - 权限提权的风险
在 Kubernetes RBAC 中有许多特权,如果被授予, 用户或服务帐户可以提升其在集群中的权限并可能影响集群外的系统。
本节旨在提醒集群操作员需要注意的不同领域, 以确保他们不会无意中授予超出预期的集群访问权限。
列举 Secret
大家都很清楚,若允许对 Secrets 执行 get 访问,用户就获得了访问 Secret 内容的能力。
同样需要注意的是:list 和 watch 访问也会授权用户获取 Secret 的内容。
例如,当返回 List 响应时(例如,通过
kubectl get secrets -A -o yaml),响应包含所有 Secret 的内容。
工作负载的创建
在一个命名空间中创建工作负载(Pod 或管理 Pod 的工作负载资源) 的权限隐式地授予了对该命名空间中许多其他资源的访问权限,例如可以挂载在 Pod 中的 Secret、ConfigMap 和 PersistentVolume。 此外,由于 Pod 可以被任何服务账号运行, 因此授予创建工作负载的权限也会隐式地授予该命名空间中任何服务账号的 API 访问级别。
可以运行特权 Pod 的用户可以利用该访问权限获得节点访问权限, 并可能进一步提升他们的特权。如果你不完全信任某用户或其他主体, 不相信他们能够创建比较安全且相互隔离的 Pod,你应该强制实施 Baseline 或 Restricted Pod 安全标准。你可以使用 Pod 安全性准入或其他(第三方) 机制来强制实施这些限制。
出于这些原因,命名空间应该用于隔离不同的信任级别或不同租户所需的资源。 遵循最小特权原则并分配最小权限集仍被认为是最佳实践, 但命名空间内的边界概念应视为比较弱。
持久卷的创建
如果允许某人或某个应用创建任意的 PersistentVolume,则这种访问权限包括创建 hostPath 卷,
这意味着 Pod 将可以访问对应节点上的下层主机文件系统。授予该能力会带来安全风险。
不受限制地访问主机文件系统的容器可以通过多种方式提升特权,包括从其他容器读取数据以及滥用系统服务 (例如 kubelet)的凭据。
你应该只允许以下实体具有创建 PersistentVolume 对象的访问权限:
- 需要此访问权限才能工作的用户(集群操作员)以及你信任的人,
- Kubernetes 控制平面组件,这些组件基于已配置为自动制备的 PersistentVolumeClaim 创建 PersistentVolume。 这通常由 Kubernetes 提供商或操作员在安装 CSI 驱动程序时进行设置。
在需要访问持久存储的地方,受信任的管理员应创建 PersistentVolume,而受约束的用户应使用 PersistentVolumeClaim 来访问该存储。
访问 Node 的 proxy 子资源
有权访问 Node 对象的 proxy 子资源的用户有权访问 kubelet API, 这允许在他们有权访问的节点上的所有 Pod 上执行命令。 此访问绕过审计日志记录和准入控制,因此在授予对此资源的权限前应小心。
esclate 动词
通常,RBAC 系统会阻止用户创建比他所拥有的更多权限的 ClusterRole。
而 escalate 动词是个例外。如
RBAC 文档
中所述,拥有此权限的用户可以有效地提升他们的权限。
bind 动词
与 escalate 动作类似,授予此权限的用户可以绕过 Kubernetes
对权限提升的内置保护,用户可以创建并绑定尚不具有的权限的角色。
impersonate 动词
此动词允许用户伪装并获得集群中其他用户的权限。 授予它时应小心,以确保通过其中一个伪装账号不会获得过多的权限。
CSR 和证书颁发
CSR API 允许用户拥有 create CSR 的权限和 update
certificatesigningrequests/approval 的权限,
其中签名者是 kubernetes.io/kube-apiserver-client,
通过此签名创建的客户端证书允许用户向集群进行身份验证。
这些客户端证书可以包含任意的名称,包括 Kubernetes 系统组件的副本。
这将有利于特权提级。
令牌请求
拥有 serviceaccounts/token 的 create 权限的用户可以创建
TokenRequest 来发布现有服务帐户的令牌。
控制准入 Webhook
可以控制 validatingwebhookconfigurations 或 mutatingwebhookconfigurations
的用户可以控制能读取任何允许进入集群的对象的 webhook,
并且在有变更 webhook 的情况下,还可以变更准入的对象。
Kubernetes RBAC - 拒绝服务攻击的风险
对象创建拒绝服务
有权在集群中创建对象的用户根据创建对象的大小和数量可能会创建足够大的对象, 产生拒绝服务状况,如 Kubernetes 使用的 etcd 容易受到 OOM 攻击中的讨论。 允许太不受信任或者不受信任的用户对系统进行有限的访问在多租户集群中是特别重要的。
缓解此问题的一种选择是使用资源配额以限制可以创建的对象数量。
接下来
- 了解有关 RBAC 的更多信息,请参阅 RBAC 文档。
8.8 - Kubernetes Secret 良好实践
帮助集群管理员和应用开发者更好管理 Secret 的原理和实践。
在 Kubernetes 中,Secret 是这样一个对象: secret 用于存储敏感信息,如密码、OAuth 令牌和 SSH 密钥。
Secret 允许用户对如何使用敏感信息进行更多的控制,并减少信息意外暴露的风险。 默认情况下,Secret 值被编码为 base64 字符串并以非加密的形式存储,但可以配置为 静态加密(Encrypt at rest)。
Pod 可以通过多种方式引用 Secret, 例如在卷挂载中引用或作为环境变量引用。Secret 设计用于机密数据,而 ConfigMap 设计用于非机密数据。
以下良好实践适用于集群管理员和应用开发者。遵从这些指导方针有助于提高 Secret 对象中敏感信息的安全性,还可以更有效地管理你的 Secret。
集群管理员
本节提供了集群管理员可用于提高集群中机密信息安全性的良好实践。
配置静态加密
默认情况下,Secret 对象以非加密的形式存储在 etcd 中。
你配置对在 etcd 中存储的 Secret 数据进行加密。相关的指导信息,
请参阅静态加密 Secret 数据。
配置 Secret 资源的最小特权访问
当规划诸如 Kubernetes
基于角色的访问控制 (RBAC)
这类访问控制机制时,需要注意访问 Secret 对象的以下指导信息。
你还应遵从 RBAC 良好实践中的其他指导信息。
- 组件:限制仅最高特权的系统级组件可以执行
watch或list访问。 仅在组件的正常行为需要时才授予对 Secret 的get访问权限。 - 人员:限制对 Secret 的
get、watch或list访问权限。仅允许集群管理员访问etcd。 这包括只读访问。对于更复杂的访问控制,例如使用特定注解限制对 Secret 的访问,请考虑使用第三方鉴权机制。
注意:
授予对 Secret 的 list 访问权限将意味着允许对应主体获取 Secret 的内容。
如果一个用户可以创建使用某 Secret 的 Pod,则该用户也可以看到该 Secret 的值。 即使集群策略不允许用户直接读取 Secret,同一用户也可能有权限运行 Pod 进而暴露该 Secret。 你可以检测或限制具有此访问权限的用户有意或无意地暴露 Secret 数据所造成的影响。 这里有一些建议:
- 使用生命期短暂的 Secret
- 实现对特定事件发出警报的审计规则,例如同一用户并发读取多个 Secret 时发出警报
用于 Secret 管理的附加 ServiceAccount 注解
你还可以在 ServiceAccount 上使用 kubernetes.io/enforce-mountable-secrets
注解来强制执行有关如何在 Pod 中使用 Secret 的特定规则。
更多详细信息,请参阅有关此注解的文档。
改进 etcd 管理策略
不再使用 etcd 所使用的持久存储时,考虑擦除或粉碎这些数据。
如果存在多个 etcd 实例,则在实例之间配置加密的 SSL/TLS 通信以保护传输中的 Secret 数据。
配置对外部 Secret 的访问权限
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
你可以使用第三方 Secret 存储提供商将机密数据保存在你的集群之外,然后配置 Pod 访问该信息。 Kubernetes Secret 存储 CSI 驱动是一个 DaemonSet, 它允许 kubelet 从外部存储中检索 Secret,并将 Secret 作为卷挂载到特定的、你授权访问数据的 Pod。
有关支持的提供商列表,请参阅 Secret 存储 CSI 驱动的提供商。
开发者
本节为开发者提供了构建和部署 Kubernetes 资源时用于改进机密数据安全性的良好实践。
限制特定容器集合才能访问 Secret
如果你在一个 Pod 中定义了多个容器,且仅其中一个容器需要访问 Secret,则可以定义卷挂载或环境变量配置, 这样其他容器就不会有访问该 Secret 的权限。
读取后保护 Secret 数据
应用程序从一个环境变量或一个卷读取机密信息的值后仍然需要保护这些值。 例如,你的应用程序必须避免以明文记录 Secret 数据,还必须避免将这些数据传输给不受信任的一方。
避免共享 Secret 清单
如果你通过清单(Manifest)配置 Secret, 同时将该 Secret 数据编码为 base64, 那么共享此文件或将其检入一个源代码仓库就意味着有权读取该清单的所有人都能使用该 Secret。
注意:
Base64 编码不是一种加密方法,它没有为纯文本提供额外的保密机制。
8.9 - 多租户
此页面概述了集群多租户的可用配置选项和最佳实践。
共享集群可以节省成本并简化管理。 然而,共享集群也带来了诸如安全性、公平性和管理嘈杂邻居等挑战。
集群可以通过多种方式共享。在某些情况下,不同的应用可能会在同一个集群中运行。 在其他情况下,同一应用的多个实例可能在同一个集群中运行,每个实例对应一个最终用户。 所有这些类型的共享经常使用一个总括术语 多租户(Multi-Tenancy) 来表述。
虽然 Kubernetes 没有最终用户或租户的一阶概念, 它还是提供了几个特性来帮助管理不同的租户需求。下面将对此进行讨论。
用例
确定如何共享集群的第一步是理解用例,以便你可以评估可用的模式和工具。 一般来说,Kubernetes 集群中的多租户分为两大类,但也可以有许多变体和混合。
多团队
多租户的一种常见形式是在组织内的多个团队之间共享一个集群,每个团队可以操作一个或多个工作负载。 这些工作负载经常需要相互通信,并与位于相同或不同集群上的其他工作负载进行通信。
在这一场景中,团队成员通常可以通过类似 kubectl 等工具直接访问 Kubernetes 资源,
或者通过 GitOps 控制器或其他类型的自动化发布工具间接访问 Kubernetes 资源。
不同团队的成员之间通常存在某种程度的信任,
但 RBAC、配额和网络策略等 Kubernetes 策略对于安全、公平地共享集群至关重要。
多客户
多租户的另一种主要形式通常涉及为客户运行多个工作负载实例的软件即服务 (SaaS) 供应商。
这种业务模型与其部署风格之间的相关非常密切,以至于许多人称之为 “SaaS 租户”。
但是,更好的术语可能是“多客户租户(Multi-Customer Tenancy)”,因为 SaaS 供应商也可以使用其他部署模型,
并且这种部署模型也可以在 SaaS 之外使用。
在这种情况下,客户无权访问集群; 从他们的角度来看,Kubernetes 是不可见的,仅由供应商用于管理工作负载。 成本优化通常是一个关键问题,Kubernetes 策略用于确保工作负载彼此高度隔离。
术语
租户
在讨论 Kubernetes 中的多租户时,“租户”没有单一的定义。 相反,租户的定义将根据讨论的是多团队还是多客户租户而有所不同。
在多团队使用中,租户通常是一个团队, 每个团队通常部署少量工作负载,这些工作负载会随着服务的复杂性而发生规模伸缩。 然而,“团队”的定义本身可能是模糊的, 因为团队可能被组织成更高级别的部门或细分为更小的团队。
相反,如果每个团队为每个新客户部署专用的工作负载,那么他们使用的是多客户租户模型。 在这种情况下,“租户”只是共享单个工作负载的一组用户。 这种租户可能大到整个公司,也可能小到该公司的一个团队。
在许多情况下,同一组织可能在不同的上下文中使用“租户”的两种定义。 例如,一个平台团队可能向多个内部“客户”提供安全工具和数据库等共享服务, 而 SaaS 供应商也可能让多个团队共享一个开发集群。 最后,混合架构也是可能的, 例如,某 SaaS 提供商为每个客户的敏感数据提供独立的工作负载,同时提供多租户共享的服务。
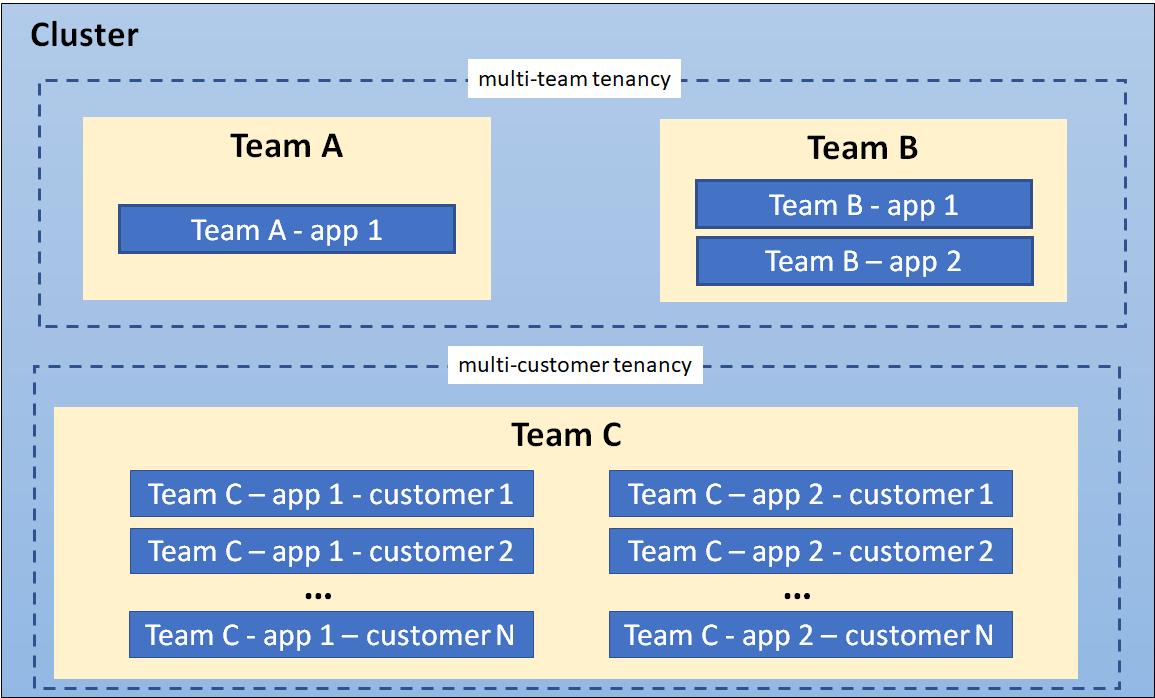
展示共存租户模型的集群
隔离
使用 Kubernetes 设计和构建多租户解决方案有多种方法。 每种方法都有自己的一组权衡,这些权衡会影响隔离级别、实现工作量、操作复杂性和服务成本。
Kubernetes 集群由运行 Kubernetes 软件的控制平面和由工作节点组成的数据平面组成, 租户工作负载作为 Pod 在工作节点上执行。 租户隔离可以根据组织要求应用于控制平面和数据平面。
所提供的隔离级别有时会使用一些术语来描述,例如 “硬性(Hard)” 多租户意味着强隔离, 而 “柔性(Soft)” 多租户意味着较弱的隔离。 特别是,“硬性”多租户通常用于描述租户彼此不信任的情况, 并且大多是从安全和资源共享的角度(例如,防范数据泄露或 DoS 攻击等)。 由于数据平面通常具有更大的攻击面,“硬性”多租户通常需要额外注意隔离数据平面, 尽管控制平面隔离也很关键。
但是,“硬性”和“柔性”这两个术语常常令人困惑,因为没有一种定义能够适用于所有用户。 相反,依据“硬度(Hardness)”或“柔度(Softness)”所定义的广泛谱系则更容易理解, 根据你的需求,可以使用许多不同的技术在集群中维护不同类型的隔离。
在更极端的情况下,彻底放弃所有集群级别的共享并为每个租户分配其专用集群可能更容易或有必要, 如果认为虚拟机所提供的安全边界还不够,甚至可以在专用硬件上运行。 对于托管的 Kubernetes 集群而言,这种方案可能更容易, 其中创建和操作集群的开销至少在一定程度上由云提供商承担。 必须根据管理多个集群的成本和复杂性来评估更强的租户隔离的好处。 Multi-Cluster SIG 负责解决这些类型的用例。
本页的其余部分重点介绍用于共享 Kubernetes 集群的隔离技术。 但是,即使你正在考虑使用专用集群,查看这些建议也可能很有价值, 因为如果你的需求或功能发生变化,它可以让你在未来比较灵活地切换到共享集群。
控制面隔离
控制平面隔离确保不同租户无法访问或影响彼此的 Kubernetes API 资源。
命名空间
在 Kubernetes 中, 命名空间提供了一种在单个集群中隔离 API 资源组的机制。 这种隔离有两个关键维度:
- 一个命名空间中的对象名称可以与其他命名空间中的名称重叠,类似于文件夹中的文件。 这允许租户命名他们的资源,而无需考虑其他租户在做什么。
- 许多 Kubernetes 安全策略的作用域是命名空间。 例如,RBAC Role 和 NetworkPolicy 是命名空间作用域的资源。 使用 RBAC,可以将用户和服务帐户限制在一个命名空间中。
在多租户环境中,命名空间有助于将租户的工作负载划分到各不相同的逻辑管理单元中。 事实上,一种常见的做法是将每个工作负载隔离在自己的命名空间中, 即使多个工作负载由同一个租户操作。 这可确保每个工作负载都有自己的身份,并且可以使用适当的安全策略进行配置。
命名空间隔离模型需要配置其他几个 Kubernetes 资源、网络插件, 并遵守安全最佳实践以正确隔离租户工作负载。 这些考虑将在下面讨论。
访问控制
控制平面最重要的隔离类型是授权。如果各个团队或其工作负载可以访问或修改彼此的 API 资源, 他们可以更改或禁用所有其他类型的策略,从而取消这些策略可能提供的任何保护。 因此,确保每个租户只对他们需要的命名空间有适当的访问权, 而不是更多,这一点至关重要。这被称为“最小特权原则(Principle of Least Privileges)”。
基于角色的访问控制 (RBAC) 通常用于在 Kubernetes 控制平面中对用户和工作负载(服务帐户)强制执行鉴权。 角色 和角色绑定是两种 Kubernetes 对象,用来在命名空间级别对应用实施访问控制; 对集群级别的对象访问鉴权也有类似的对象,不过这些对象对于多租户集群不太有用。
在多团队环境中,必须使用 RBAC 来限制租户只能访问合适的命名空间, 并确保集群范围的资源只能由集群管理员等特权用户访问或修改。
如果一个策略最终授予用户的权限比他们所需要的还多, 这可能是一个信号,表明包含受影响资源的命名空间应该被重构为更细粒度的命名空间。 命名空间管理工具可以通过将通用 RBAC 策略应用于不同的命名空间来简化这些细粒度命名空间的管理, 同时在必要时仍允许细粒度策略。
配额
Kubernetes 工作负载消耗节点资源,例如 CPU 和内存。在多租户环境中, 你可以使用资源配额来管理租户工作负载的资源使用情况。 对于多团队场景,各个租户可以访问 Kubernetes API,你可以使用资源配额来限制租户可以创建的 API 资源的数量 (例如:Pod 的数量,或 ConfigMap 的数量)。 对对象计数的限制确保了公平性,并有助于避免嘈杂邻居问题影响共享控制平面的其他租户。
资源配额是命名空间作用域的对象。 通过将租户映射到命名空间, 集群管理员可以使用配额来确保租户不能垄断集群的资源或压垮控制平面。 命名空间管理工具简化了配额的管理。 此外,虽然 Kubernetes 配额仅针对单个命名空间, 但一些命名空间管理工具允许多个命名空间组共享配额, 与内置配额相比,降低了管理员的工作量,同时为其提供了更大的灵活性。
配额可防止单个租户所消耗的资源超过其被分配的份额,从而最大限度地减少嘈杂邻居问题, 即一个租户对其他租户工作负载的性能产生负面影响。
当你对命名空间应用配额时, Kubernetes 要求你还为每个容器指定资源请求和限制。 限制是容器可以消耗的资源量的上限。 根据资源类型,尝试使用超出配置限制的资源的容器将被限制或终止。 当资源请求设置为低于限制时, 每个容器所请求的数量都可以得到保证,但可能仍然存在跨工作负载的一些潜在影响。
配额不能针对所共享的所有资源(例如网络流量)提供保护。 节点隔离(如下所述)可能是解决此问题的更好方法。
数据平面隔离
数据平面隔离确保不同租户的 Pod 和工作负载之间被充分隔离。
网络隔离
默认情况下,Kubernetes 集群中的所有 Pod 都可以相互通信,并且所有网络流量都是未加密的。 这可能导致安全漏洞,导致流量被意外或恶意发送到非预期目的地, 或被受感染节点上的工作负载拦截。
Pod 之间的通信可以使用网络策略来控制, 它使用命名空间标签或 IP 地址范围来限制 Pod 之间的通信。 在需要租户之间严格网络隔离的多租户环境中, 建议从拒绝 Pod 之间通信的默认策略入手, 然后添加一条允许所有 Pod 查询 DNS 服务器以进行名称解析的规则。 有了这样的默认策略之后,你就可以开始添加允许在命名空间内进行通信的更多规则。 另外建议不要在网络策略定义中对 namespaceSelector 字段使用空标签选择算符 “{}”, 以防需要允许在命名空间之间传输流量。 该方案可根据需要进一步细化。 请注意,这仅适用于单个控制平面内的 Pod; 属于不同虚拟控制平面的 Pod 不能通过 Kubernetes 网络相互通信。
命名空间管理工具可以简化默认或通用网络策略的创建。 此外,其中一些工具允许你在整个集群中强制实施一组一致的命名空间标签, 确保它们是你策略的可信基础。
警告:
网络策略需要一个支持网络策略实现的 CNI 插件。 否则,NetworkPolicy 资源将被忽略。
服务网格可以提供更高级的网络隔离, 除了命名空间之外,它还提供基于工作负载身份的 OSI 第 7 层策略。 这些更高层次的策略可以更轻松地管理基于命名空间的多租户, 尤其是存在多个命名空间专用于某一个租户时。 服务网格还经常使用双向 TLS 提供加密能力, 即使在存在受损节点的情况下也能保护你的数据, 并且可以跨专用或虚拟集群工作。 但是,它们的管理可能要复杂得多,并且可能并不适合所有用户。
存储隔离
Kubernetes 提供了若干类型的卷,可以用作工作负载的持久存储。 为了安全和数据隔离,建议使用动态卷制备, 并且应避免使用节点资源的卷类型。
存储类(StorageClass)允许你根据服务质量级别、 备份策略或由集群管理员确定的自定义策略描述集群提供的自定义存储“类”。
Pod 可以使用持久卷申领(PersistentVolumeClaim)请求存储。 PersistentVolumeClaim 是一种命名空间作用域的资源, 它可以隔离存储系统的不同部分,并将隔离出来的存储提供给共享 Kubernetes 集群中的租户专用。 但是,重要的是要注意 PersistentVolume 是集群作用域的资源, 并且其生命周期独立于工作负载和命名空间的生命周期。
例如,你可以为每个租户配置一个单独的 StorageClass,并使用它来加强隔离。 如果一个 StorageClass 是共享的,你应该设置一个回收策略 以确保 PersistentVolume 不能在不同的命名空间中重复使用。
沙箱容器
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
Kubernetes Pod 由在工作节点上执行的一个或多个容器组成。 容器利用操作系统级别的虚拟化, 因此提供的隔离边界比使用基于硬件虚拟化的虚拟机弱一些。
在共享环境中,攻击者可以利用应用和系统层中未修补的漏洞实现容器逃逸和远程代码执行, 从而允许访问主机资源。 在某些应用中,例如内容管理系统(CMS), 客户可能被授权上传和执行非受信的脚本或代码。 无论哪种情况,都需要使用强隔离进一步隔离和保护工作负载的机制。
沙箱提供了一种在共享集群中隔离运行中的工作负载的方法。 它通常涉及在单独的执行环境(例如虚拟机或用户空间内核)中运行每个 Pod。 当你运行不受信任的代码时(假定工作负载是恶意的),通常建议使用沙箱, 这种隔离是必要的,部分原因是由于容器是在共享内核上运行的进程。 它们从底层主机挂载像 /sys 和 /proc 这样的文件系统, 这使得它们不如在具有自己内核的虚拟机上运行的应用安全。 虽然 seccomp、AppArmor 和 SELinux 等控件可用于加强容器的安全性, 但很难将一套通用规则应用于在共享集群中运行的所有工作负载。 在沙箱环境中运行工作负载有助于将主机隔离开来,不受容器逃逸影响, 在容器逃逸场景中,攻击者会利用漏洞来访问主机系统以及在该主机上运行的所有进程/文件。
虚拟机和用户空间内核是两种流行的沙箱方法。 可以使用以下沙箱实现:
- gVisor 拦截来自容器的系统调用,并通过用户空间内核运行它们, 用户空间内核采用 Go 编写,对底层主机的访问是受限的
- Kata Containers 是符合 OCI 的运行时,允许你在 VM 中运行容器。 Kata 中提供的硬件虚拟化为运行不受信任代码的容器提供了额外的安全层。
节点隔离
节点隔离是另一种可用于将租户工作负载相互隔离的技术。 通过节点隔离,一组节点专用于运行来自特定租户的 Pod,并且禁止混合不同租户 Pod 集合。 这种配置减少了嘈杂的租户问题,因为在一个节点上运行的所有 Pod 都将属于一个租户。 节点隔离的信息泄露风险略低, 因为成功实现容器逃逸的攻击者也只能访问挂载在该节点上的容器和卷。
尽管来自不同租户的工作负载在不同的节点上运行, 仍然很重要的是要注意 kubelet 和 (除非使用虚拟控制平面)API 服务仍然是共享服务。 熟练的攻击者可以使用分配给 kubelet 或节点上运行的其他 Pod 的权限在集群内横向移动并获得对其他节点上运行的租户工作负载的访问权限。 如果这是一个主要问题,请考虑实施补偿控制, 例如使用 seccomp、AppArmor 或 SELinux,或者探索使用沙箱容器,或者为每个租户创建单独的集群。
从计费的角度来看,节点隔离比沙箱容器更容易理解, 因为你可以按节点而不是按 Pod 收费。 它的兼容性和性能问题也较少,而且可能比沙箱容器更容易实现。 例如,可以为每个租户的节点配置污点, 以便只有具有相应容忍度的 Pod 才能在其上运行。 然后可以使用变更性质的 Webhook 自动向部署到租户命名空间中的 Pod 添加容忍度和节点亲和性, 以便它们在为该租户指定的一组特定节点上运行。
节点隔离可以使用将 Pod 指派给节点或 Virtual Kubelet 来实现。
额外的注意事项
本节讨论与多租户相关的其他 Kubernetes 结构和模式。
API 优先级和公平性
API 优先级和公平性是 Kubernetes 的一个特性, 允许你为集群中运行的某些 Pod 赋予优先级。 当应用调用 Kubernetes API 时,API 服务器会评估分配给 Pod 的优先级。 来自具有较高优先级的 Pod 的调用会在具有较低优先级的 Pod 的调用之前完成。 当争用很激烈时,较低优先级的调用可以排队,直到服务器不那么忙,或者你可以拒绝请求。
使用 API 优先级和公平性在 SaaS 环境中并不常见, 除非你允许客户运行与 Kubernetes API 接口的应用,例如控制器。
服务质量 (QoS)
当你运行 SaaS 应用时, 你可能希望能够为不同的租户提供不同的服务质量 (QoS) 层级。 例如,你可能拥有具有性能保证和功能较差的免费增值服务, 以及具有一定性能保证的收费服务层。 幸运的是,有几个 Kubernetes 结构可以帮助你在共享集群中完成此任务, 包括网络 QoS、存储类以及 Pod 优先级和抢占。 这些都是为了给租户提供他们所支付的服务质量。 让我们从网络 QoS 开始。
通常,节点上的所有 Pod 共享一个网络接口。 如果没有网络 QoS,一些 Pod 可能会以牺牲其他 Pod 为代价不公平地消耗可用带宽。 Kubernetes 带宽插件为网络创建 扩展资源, 以允许你使用 Kubernetes 的 resources 结构,即 requests 和 limits 设置。 通过使用 Linux tc 队列将速率限制应用于 Pod。 请注意,根据支持流量整形文档, 该插件被认为是实验性的,在生产环境中使用之前应该进行彻底的测试。
对于存储 QoS,你可能希望创建具有不同性能特征的不同存储类或配置文件。 每个存储配置文件可以与不同的服务层相关联,该服务层针对 IO、冗余或吞吐量等不同的工作负载进行优化。 可能需要额外的逻辑来允许租户将适当的存储配置文件与其工作负载相关联。
最后,还有 Pod 优先级和抢占, 你可以在其中为 Pod 分配优先级值。 在调度 Pod 时,当没有足够的资源来调度分配了较高优先级的 Pod 时, 调度程序将尝试驱逐具有较低优先级的 Pod。 如果你有一个用例,其中租户在共享集群中具有不同的服务层,例如免费和付费, 你可能希望使用此功能为某些层级提供更高的优先级。
DNS
Kubernetes 集群包括一个域名系统(DNS)服务, 可为所有服务和 Pod 提供从名称到 IP 地址的转换。 默认情况下,Kubernetes DNS 服务允许在集群中的所有命名空间中进行查找。
在多租户环境中,租户可以访问 Pod 和其他 Kubernetes 资源, 或者在需要更强隔离的情况下,可能需要阻止 Pod 在其他名称空间中查找服务。 你可以通过为 DNS 服务配置安全规则来限制跨命名空间的 DNS 查找。 例如,CoreDNS(Kubernetes 的默认 DNS 服务)可以利用 Kubernetes 元数据来限制对命名空间内的 Pod 和服务的查询。 有关更多信息,请阅读 CoreDNS 文档中配置此功能的 示例。
当使用各租户独立虚拟控制面模型时, 必须为每个租户配置 DNS 服务或必须使用多租户 DNS 服务。参见一个 CoreDNS 的定制版本支持多租户的示例。
Operators
Operator 模式是管理应用的 Kubernetes 控制器。 Operator 可以简化应用的多个实例的管理,例如数据库服务, 这使它们成为多消费者 (SaaS) 多租户用例中的通用构建块。
在多租户环境中使用 Operators 应遵循一套更严格的准则。具体而言,Operator 应:
- 支持在不同的租户命名空间内创建资源,而不仅仅是在部署 Operator 的命名空间内。
- 确保 Pod 配置了资源请求和限制,以确保调度和公平。
- 支持节点隔离、沙箱容器等数据平面隔离技术的 Pod 配置。
实现
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
为多租户共享 Kubernetes 集群有两种主要方法: 使用命名空间(即每个租户独立的命名空间) 或虚拟化控制平面(即每个租户独立的虚拟控制平面)。
在这两种情况下,还建议对数据平面隔离和其他考虑事项,如 API 优先级和公平性,进行管理。
Kubernetes 很好地支持命名空间隔离,其资源开销可以忽略不计,并提供了允许租户适当交互的机制, 例如允许服务之间的通信。 但是,它可能很难配置,而且不适用于非命名空间作用域的 Kubernetes 资源,例如自定义资源定义、存储类和 Webhook 等。
控制平面虚拟化允许以更高的资源使用率和更困难的跨租户共享为代价隔离非命名空间作用域的资源。 当命名空间隔离不足但不希望使用专用集群时,这是一个不错的选择, 因为维护专用集群的成本很高(尤其是本地集群), 或者由于专用集群的额外开销较高且缺乏资源共享。 但是,即使在虚拟化控制平面中,你也可能会看到使用命名空间的好处。
以下各节将更详细地讨论这两个选项:
每个租户独立的命名空间
如前所述,你应该考虑将每个工作负载隔离在其自己的命名空间中, 即使你使用的是专用集群或虚拟化控制平面。 这可确保每个工作负载只能访问其自己的资源,例如 ConfigMap 和 Secret, 并允许你为每个工作负载定制专用的安全策略。 此外,最佳实践是为整个集群中的每个命名空间名称提供唯一的名称(即,即使它们位于单独的集群中), 因为这使你将来可以灵活地在专用集群和共享集群之间切换, 或者使用多集群工具,例如服务网格。
相反,在租户级别分配命名空间也有优势, 而不仅仅是工作负载级别, 因为通常有一些策略适用于单个租户拥有的所有工作负载。 然而,这种方案也有自己的问题。 首先,这使得为各个工作负载定制策略变得困难或不可能, 其次,确定应该赋予命名空间的单一级别的 “租户” 可能很困难。 例如,一个组织可能有部门、团队和子团队 - 哪些应该分配一个命名空间?
为了解决这个问题,Kubernetes 提供了 Hierarchical Namespace Controller (HNC), 它允许你将多个命名空间组织成层次结构,并在它们之间共享某些策略和资源。 它还可以帮助你管理命名空间标签、命名空间生命周期和委托管理, 并在相关命名空间之间共享资源配额。 这些功能在多团队和多客户场景中都很有用。
下面列出了提供类似功能并有助于管理命名空间资源的其他项目:
多团队租户
多客户租户
策略引擎
策略引擎提供了验证和生成租户配置的特性:
每个租户独立的虚拟控制面
控制面隔离的另一种形式是使用 Kubernetes 扩展为每个租户提供一个虚拟控制面, 以实现集群范围内 API 资源的分段。 数据平面隔离技术可以与此模型一起使用, 以安全地跨多个租户管理工作节点。
基于虚拟控制面的多租户模型通过为每个租户提供专用控制面组件来扩展基于命名空间的多租户, 从而完全控制集群范围的资源和附加服务。 工作节点在所有租户之间共享,并由租户通常无法访问的 Kubernetes 集群管理。 该集群通常被称为 超集群(Super-Cluster)(或有时称为 host-cluster)。 由于租户的控制面不直接与底层计算资源相关联,因此它被称为虚拟控制平面。
虚拟控制面通常由 Kubernetes API 服务器、控制器管理器和 etcd 数据存储组成。 它通过元数据同步控制器与超集群交互, 该控制器跨租户控制面和超集群控制面对变化进行协调。
通过使用每个租户单独的专用控制面,可以解决由于所有租户共享一个 API 服务器而导致的大部分隔离问题。 例如,控制平面中的嘈杂邻居、策略错误配置导致的不可控爆炸半径以及如 Webhook 和 CRD 等集群范围对象之间的冲突。 因此,虚拟控制平面模型特别适用于每个租户都需要访问 Kubernetes API 服务器并期望具有完整集群可管理性的情况。
改进的隔离是以每个租户运行和维护一个单独的虚拟控制平面为代价的。 此外,租户层面的控制面不能解决数据面的隔离问题, 例如节点级的嘈杂邻居或安全威胁。这些仍然必须单独解决。
Kubernetes Cluster API - Nested (CAPN) 项目提供了虚拟控制平面的实现。
其他实现
8.10 - Kubernetes API 服务器旁路风险
与 API 服务器及其他组件相关的安全架构信息
Kubernetes API 服务器是外部(用户和服务)与集群交互的主要入口。
API 服务器作为交互的主要入口,还提供了几种关键的内置安全控制, 例如审计日志和准入控制器。 但有一些方式可以绕过这些安全控制从而修改集群的配置或内容。
本页描述了绕过 Kubernetes API 服务器中内置安全控制的几种方式, 以便集群运维人员和安全架构师可以确保这些绕过方式被适当地限制。
静态 Pod
每个节点上的 kubelet 会加载并直接管理集群中存储在指定目录中或从特定 URL 获取的静态 Pod 清单。 API 服务器不管理这些静态 Pod。对该位置具有写入权限的攻击者可以修改从该位置加载的静态 Pod 的配置,或引入新的静态 Pod。
静态 Pod 被限制访问 Kubernetes API 中的其他对象。例如,你不能将静态 Pod 配置为从集群挂载 Secret。
但是,这些 Pod 可以执行其他安全敏感的操作,例如挂载来自下层节点的 hostPath 卷。
默认情况下,kubelet 会创建一个镜像 Pod(Mirror Pod), 以便静态 Pod 在 Kubernetes API 中可见。但是,如果攻击者在创建 Pod 时使用了无效的名字空间名称, 则该 Pod 将在 Kubernetes API 中不可见,只能通过对受影响主机有访问权限的工具发现。
如果静态 Pod 无法通过准入控制,kubelet 不会将 Pod 注册到 API 服务器。但该 Pod 仍然在节点上运行。 有关更多信息,请参阅 kubeadm issue #1541。
缓解措施
- 仅在节点需要时启用 kubelet 静态 Pod 清单功能。
- 如果节点使用静态 Pod 功能,请将对静态 Pod 清单目录或 URL 的文件系统的访问权限限制为需要访问的用户。
- 限制对 kubelet 配置参数和文件的访问,以防止攻击者设置静态 Pod 路径或 URL。
- 定期审计并集中报告所有对托管静态 Pod 清单和 kubelet 配置文件的目录或 Web 存储位置的访问。
kubelet API
kubelet 提供了一个 HTTP API,通常暴露在集群工作节点上的 TCP 端口 10250 上。 在某些 Kubernetes 发行版中,API 也可能暴露在控制平面节点上。 对 API 的直接访问允许公开有关运行在节点上的 Pod、这些 Pod 的日志以及在节点上运行的每个容器中执行命令的信息。
当 Kubernetes 集群用户具有对 Node 对象子资源 RBAC 访问权限时,该访问权限可用作与 kubelet API 交互的授权。
实际的访问权限取决于授予了哪些子资源访问权限,详见
kubelet 鉴权。
对 kubelet API 的直接访问不受准入控制影响,也不会被 Kubernetes 审计日志记录。 能直接访问此 API 的攻击者可能会绕过能检测或防止某些操作的控制机制。
kubelet API 可以配置为以多种方式验证请求。
默认情况下,kubelet 的配置允许匿名访问。大多数 Kubernetes 提供商将默认值更改为使用 Webhook 和证书身份认证。
这使得控制平面能够确保调用者访问 nodes API 资源或子资源是经过授权的。但控制平面不能确保默认的匿名访问也是如此。
缓解措施
- 使用 RBAC 等机制限制对
nodesAPI 对象的子资源的访问。 只在有需要时才授予此访问权限,例如监控服务。 - 限制对 kubelet 端口的访问。只允许指定和受信任的 IP 地址段访问该端口。
- 确保将 kubelet 身份验证 设置为 Webhook 或证书模式。
- 确保集群上未启用不作身份认证的“只读” Kubelet 端口。
etcd API
Kubernetes 集群使用 etcd 作为数据存储。etcd 服务监听 TCP 端口 2379。
只有 Kubernetes API 服务器和你所使用的备份工具需要访问此存储。对该 API 的直接访问允许公开或修改集群中保存的数据。
对 etcd API 的访问通常通过客户端证书身份认证来管理。 由 etcd 信任的证书颁发机构所颁发的任何证书都可以完全访问 etcd 中存储的数据。
对 etcd 的直接访问不受 Kubernetes 准入控制的影响,也不会被 Kubernetes 审计日志记录。 具有对 API 服务器的 etcd 客户端证书私钥的读取访问权限(或可以创建一个新的受信任的客户端证书) 的攻击者可以通过访问集群 Secret 或修改访问规则来获得集群管理员权限。 即使不提升其 Kubernetes RBAC 权限,可以修改 etcd 的攻击者也可以在集群内检索所有 API 对象或创建新的工作负载。
许多 Kubernetes 提供商配置 etcd 为使用双向 TLS(客户端和服务器都验证彼此的证书以进行身份验证)。 尽管存在该特性,但目前还没有被广泛接受的 etcd API 鉴权实现。 由于缺少鉴权模型,任何具有对 etcd 的客户端访问权限的证书都可以用于获得对 etcd 的完全访问权限。 通常,仅用于健康检查的 etcd 客户端证书也可以授予完全读写访问权限。
缓解措施
- 确保 etcd 所信任的证书颁发机构仅用于该服务的身份认证。
- 控制对 etcd 服务器证书的私钥以及 API 服务器的客户端证书和密钥的访问。
- 考虑在网络层面限制对 etcd 端口的访问,仅允许来自特定和受信任的 IP 地址段的访问。
容器运行时套接字
在 Kubernetes 集群中的每个节点上,与容器交互的访问都由容器运行时控制。 通常,容器运行时会公开一个 kubelet 可以访问的 UNIX 套接字。 具有此套接字访问权限的攻击者可以启动新容器或与正在运行的容器进行交互。
在集群层面,这种访问造成的影响取决于在受威胁节点上运行的容器是否可以访问 Secret 或其他机密数据, 攻击者可以使用这些机密数据将权限提升到其他工作节点或控制平面组件。
缓解措施
- 确保严格控制对容器运行时套接字所在的文件系统访问。如果可能,限制为仅
root用户可访问。 - 使用 Linux 内核命名空间等机制将 kubelet 与节点上运行的其他组件隔离。
- 确保限制或禁止使用包含容器运行时套接字的
hostPath挂载, 无论是直接挂载还是通过挂载父目录挂载。此外,hostPath挂载必须设置为只读,以降低攻击者绕过目录限制的风险。 - 限制用户对节点的访问,特别是限制超级用户对节点的访问。
8.11 - 安全检查清单
确保 Kubernetes 集群安全的基线检查清单。
本清单旨在提供一个基本的指导列表,其中包含链接,指向各个主题的更为全面的文档。 此清单不求详尽无遗,是预计会不断演化的。
关于如何阅读和使用本文档:
- 主题的顺序并不代表优先级的顺序。
- 在每章节的列表下面的段落中,都详细列举了一些检查清项目。
注意:
单靠检查清单是不够的,无法获得良好的安全态势。 实现良好的安全态势需要持续的关注和改进,实现安全上有备无患的目标道路漫长,清单可作为征程上的第一步。 对于你的特定安全需求,此清单中的某些建议可能过于严格或过于宽松。 由于 Kubernetes 的安全性并不是“一刀切”的,因此针对每一类检查清单项目都应该做价值评估。
认证和鉴权
- 在启动后
system:masters组不用于用户或组件的身份验证。 - kube-controller-manager 运行时要启用
--use-service-account-credentials参数。 - 根证书要受到保护(或离线 CA,或一个具有有效访问控制的托管型在线 CA)。
- 中级证书和叶子证书的有效期不要超过未来 3 年。
- 存在定期访问审查的流程,审查间隔不要超过 24 个月。
- 遵循基于角色的访问控制良好实践, 以获得与身份验证和授权相关的指导。
在启动后,用户和组件都不应以 system:masters 身份向 Kubernetes API 进行身份验证。
同样,应避免将任何 kube-controller-manager 以 system:masters 运行。
事实上,system:masters 应该只用作一个例外机制,而不是管理员用户。
网络安全
- 使用的 CNI 插件可支持网络策略。
- 对集群中的所有工作负载应用入站和出站的网络策略。
- 落实每个名字空间内的默认网络策略,覆盖所有 Pod,拒绝一切访问。
- 如果合适,使用服务网格来加密集群内的所有通信。
- 不在互联网上公开 Kubernetes API、kubelet API 和 etcd。
- 过滤工作负载对云元数据 API 的访问。
- 限制使用 LoadBalancer 和 ExternalIP。
许多容器网络接口(Container Network Interface,CNI)插件提供了限制 Pod 可能与之通信的网络资源的功能。 这种限制通常通过网络策略来完成, 网络策略提供了一种名字空间作用域的资源来定义规则。 在每个名字空间中,默认的网络策略会阻塞所有的出入站流量,并选择所有 Pod, 采用允许列表的方法很有用,可以确保不遗漏任何工作负载。
并非所有 CNI 插件都在传输过程中提供加密。 如果所选的插件缺少此功能,一种替代方案是可以使用服务网格来提供该功能。
控制平面的 etcd 数据存储应该实施访问限制控制,并且不要在互联网上公开。 此外,应使用双向 TLS(mTLS)与其进行安全通信。 用在这里的证书机构应该仅用于 etcd。
应该限制外部互联网对 Kubernetes API 服务器未公开的 API 的访问。 请小心,因为许多托管的 Kubernetes 发行版在默认情况下公开了 API 服务器。 当然,你可以使用堡垒机访问服务器。
对 kubelet API 的访问应该受到限制,
并且不公开,当没有使用 --config 参数来设置配置文件时,默认的身份验证和鉴权设置是过于宽松的。
如果使用云服务供应商托管的 Kubernetes,在没有明确需要的情况下,
也应该限制或阻止从 Pod 对云元数据 API 169.254.169.254 的访问,因为这可能泄露信息。
关于限制使用 LoadBalancer 和 ExternalIP 请参阅 CVE-2020-8554:中间人使用 LoadBalancer 或 ExternalIP 和 DenyServiceExternalIPs 准入控制器获取更多信息。
Pod 安全
- 仅在必要时才授予
create、update、patch、delete工作负载的 RBAC 权限。 - 对所有名字空间实施适当的 Pod 安全标准策略,并强制执行。
- 为工作负载设置内存限制值,并确保限制值等于或者不高于请求值。
- 对敏感工作负载可以设置 CPU 限制。
- 对于支持 Seccomp 的节点,可以为程序启用合适的系统调用配置文件。
- 对于支持 AppArmor 或 SELinux 的系统,可以为程序启用合适的配置文件。
RBAC 的授权是至关重要的,
但不能在足够细的粒度上对 Pod 的资源进行授权,
也不足以对管理 Pod 的任何资源进行授权。
唯一的粒度是资源本身上的 API 动作,例如,对 Pod 的 create。
在未指定额外许可的情况下,创建这些资源的权限允许直接不受限制地访问集群的可调度节点。
Pod 安全性标准定义了三种不同的策略:
特权策略(Privileged)、基线策略(Baseline)和限制策略(Restricted),它们限制了 PodSpec 中关于安全的字段的设置。
这些标准可以通过默认启用的新的
Pod 安全性准入或第三方准入 Webhook 在名字空间级别强制执行。
请注意,与它所取代的、已被移除的 PodSecurityPolicy 准入机制相反,
Pod 安全性准入可以轻松地与准入 Webhook 和外部服务相结合使用。
restricted Pod 安全准入策略是 Pod 安全性标准集中最严格的策略,
可以在多种种模式下运行,
根据最佳安全实践,逐步地采用 warn、audit 或者 enforce
模式以应用最合适的安全上下文(Security Context)。
尽管如此,对于特定的用例,应该单独审查 Pod 的安全上下文,
以限制 Pod 在预定义的安全性标准之上可能具有的特权和访问权限。
有关 Pod 安全性的实践教程, 请参阅博文 Kubernetes 1.23:Pod 安全性升级到 Beta。
为了限制一个 Pod 可以使用的内存和 CPU 资源, 应该设置 Pod 在节点上可消费的内存和 CPU 限制, 从而防止来自恶意的或已被攻破的工作负载的潜在 DoS 攻击。这种策略可以由准入控制器强制执行。 请注意,CPU 限制设置可能会影响 CPU 用量,从而可能会对自动扩缩功能或效率产生意外的影响, 换言之,系统会在可用的 CPU 资源下最大限度地运行进程。
注意:
内存限制高于请求的,可能会使整个节点面临 OOM 问题。
启用 Seccomp
Seccomp 代表安全计算模式(Secure computing mode),这是一个自 Linux 内核版本 2.6.12 被加入的特性。 它可以将进程的特权沙箱化,来限制从用户空间发起的对内核的调用。 Kubernetes 允许你将加载到节点上的 Seccomp 配置文件自动应用于你的 Pod 和容器。
Seccomp 通过减少容器内对 Linux 内核的系统调用(System Call)以缩小攻击面,从而提高工作负载的安全性。 Seccomp 过滤器模式借助 BPF 创建具体系统调用的允许清单或拒绝清单,名为配置文件(Profile)。
从 Kubernetes 1.27 开始,你可以将 RuntimeDefault 设置为工作负载的默认 Seccomp 配置。
你可以阅读相应的安全教程。
此外,Kubernetes Security Profiles Operator
是一个方便在集群中管理和使用 Seccomp 的项目。
说明:
Seccomp 仅适用于 Linux 节点。
启用 AppArmor 或 SELinux
AppArmor
AppArmor 是一个 Linux 内核安全模块, 可以提供一种简单的方法来实现强制访问控制(Mandatory Access Control, MAC)并通过系统日志进行更好地审计。 要在 Kubernetes 中启用 AppArmor,至少需要 1.4 版本。 与 Seccomp 一样,AppArmor 也通过配置文件进行配置, 其中每个配置文件要么在强制(Enforcing)模式下运行,即阻止访问不允许的资源,要么在投诉(Complaining)模式下运行,只报告违规行为。 AppArmor 配置文件是通过注解的方式,以容器为粒度强制执行的,允许进程获得刚好合适的权限。
说明:
AppArmor 仅在 Linux 节点上可用, 在一些 Linux 发行版中已启用。
SELinux
SELinux
也是一个 Linux 内核安全模块,可以提供支持访问控制安全策略的机制,包括强制访问控制(MAC)。
SELinux 标签可以通过 securityContext 节指配给容器或 Pod。
说明:
SELinux 仅在 Linux 节点上可用, 在一些 Linux 发行版中已启用。
Pod 布局
- Pod 布局是根据应用程序的敏感级别来完成的。
- 敏感应用程序在节点上隔离运行或使用特定的沙箱运行时运行。
处于不同敏感级别的 Pod,例如,应用程序 Pod 和 Kubernetes API 服务器,应该部署到不同的节点上。 节点隔离的目的是防止应用程序容器的逃逸,进而直接访问敏感度更高的应用, 甚至轻松地改变集群工作机制。 这种隔离应该被强制执行,以防止 Pod 集合被意外部署到同一节点上。 可以通过以下功能实现:
- 节点选择器(Node Selector)
- 作为 Pod 规约的一部分来设置的键值对,指定 Pod 可部署到哪些节点。 通过 PodNodeSelector 准入控制器可以在名字空间和集群级别强制实施节点选择。
- PodTolerationRestriction
- 容忍度准入控制器, 允许管理员设置在名字空间内允许使用的容忍度。 名字空间中的 Pod 只能使用名字空间对象的注解键上所指定的容忍度,这些键提供默认和允许的容忍度集合。
- RuntimeClass
- RuntimeClass 是一个用于选择容器运行时配置的特性,容器运行时配置用于运行 Pod 中的容器, 并以性能开销为代价提供或多或少的主机隔离能力。
Secrets
- 不用 ConfigMap 保存机密数据。
- 为 Secret API 配置静态加密。
- 如果合适,可以部署和使用一种机制,负责注入保存在第三方存储中的 Secret。
- 不应该将服务账号令牌挂载到不需要它们的 Pod 中。
- 使用绑定的服务账号令牌卷, 而不要使用不会过期的令牌。
Pod 所需的秘密信息应该存储在 Kubernetes Secret 中,而不是像 ConfigMap 这样的替代品中。 存储在 etcd 中的 Secret 资源应该被静态加密。
需要 Secret 的 Pod 应该通过卷自动挂载这些信息,
最好使用 emptyDir.medium 选项存储在内存中。
该机制还可以用于从第三方存储中注入 Secret 作为卷,如 Secret Store CSI 驱动。
与通过 RBAC 来允许 Pod 服务账号访问 Secret 相比,应该优先使用上述机制。这种机制允许将 Secret 作为环境变量或文件添加到 Pod 中。
请注意,与带访问权限控制的文件相比,由于日志的崩溃转储,以及 Linux 的环境变量的非机密性,环境变量方法可能更容易发生泄漏。
不应该将服务账号令牌挂载到不需要它们的 Pod 中。这可以通过在服务账号内将
automountServiceAccountToken
设置为 false 来完成整个名字空间范围的配置,或者也可以单独在 Pod 层面定制。
对于 Kubernetes v1.22 及更高版本,
请使用绑定服务账号作为有时间限制的服务账号凭证。
镜像
- 尽量减少容器镜像中不必要的内容。
- 容器镜像配置为以非特权用户身份运行。
- 对容器镜像的引用是通过 Sha256 摘要实现的,而不是标签(tags), 或者通过准入控制器在部署时验证镜像的数字签名来验证镜像的来源。
- 在创建和部署过程中定期扫描容器镜像,并对已知的漏洞软件进行修补。
容器镜像应该包含运行其所打包的程序所需要的最少内容。 最好,只使用程序及其依赖项,基于最小的基础镜像来构建镜像。 尤其是,在生产中使用的镜像不应包含 Shell 或调试工具, 因为可以使用临时调试容器进行故障排除。
构建镜像时使用 Dockerfile 中的 USER
指令直接开始使用非特权用户。
安全上下文(Security Context)
允许使用 runAsUser 和 runAsGroup 来指定使用特定的用户和组来启动容器镜像,
即使没有在镜像清单文件(Manifest)中指定这些配置信息。
不过,镜像层中的文件权限设置可能无法做到在不修改镜像的情况下,使用新的非特权用户来启动进程。
避免使用镜像标签来引用镜像,尤其是 latest 标签,因为标签对应的镜像可以在仓库中被轻松地修改。
首选使用完整的 Sha256 摘要,该摘要对特定镜像清单文件而言是唯一的。
可以通过 ImagePolicyWebhook
强制执行此策略。
镜像签名还可以在部署时由准入控制器自动验证,
以验证其真实性和完整性。
扫描容器镜像可以防止关键性的漏洞随着容器镜像一起被部署到集群中。 镜像扫描应在将容器镜像部署到集群之前完成,通常作为 CI/CD 流水线中的部署过程的一部分来完成。 镜像扫描的目的是获取有关容器镜像中可能存在的漏洞及其预防措施的信息, 例如使用公共漏洞评分系统 (Common Vulnerability Scoring System,CVSS)评分。 如果镜像扫描的结果与管道合性规则匹配,则只有经过正确修补的容器镜像才会最终进入生产环境。
准入控制器
- 选择启用适当的准入控制器。
- Pod 安全策略由 Pod 安全准入强制执行,或者和 Webhook 准入控制器一起强制执行。
- 保证准入链插件和 Webhook 的配置都是安全的。
准入控制器可以帮助提高集群的安全性。 然而,由于它们是对 API 服务器的扩展,其自身可能会带来风险, 所以它们应该得到适当的保护。
下面列出了一些准入控制器,可以考虑用这些控制器来增强集群和应用程序的安全状况。 列表中包括了可能在本文档其他部分曾提及的控制器。
第一组准入控制器包括默认启用的插件, 除非你知道自己在做什么,否则请考虑保持它们处于被启用的状态:
CertificateApproval- 执行额外的授权检查,以确保审批用户具有审批证书请求的权限。
CertificateSigning- 执行其他授权检查,以确保签名用户具有签名证书请求的权限。
CertificateSubjectRestriction- 拒绝将
group(或organization attribute)设置为system:masters的所有证书请求。
LimitRanger- 强制执行 LimitRange API 约束。
MutatingAdmissionWebhook- 允许通过 Webhook 使用自定义控制器,这些控制器可能会变更它所审查的请求。
PodSecurity- Pod Security Policy 的替代品,用于约束所部署 Pod 的安全上下文。
ResourceQuota- 强制执行资源配额,以防止资源被过度使用。
ValidatingAdmissionWebhook- 允许通过 Webhook 使用自定义控制器,这些控制器不变更它所审查的请求。
第二组包括默认情况下没有启用、但处于正式发布状态的插件,建议启用这些插件以改善你的安全状况:
DenyServiceExternalIPs- 拒绝使用
Service.spec.externalIPs字段,已有的 Service 不受影响,新增或者变更时不允许使用。 这是 CVE-2020-8554:中间人使用 LoadBalancer 或 ExternalIP 的缓解措施。
NodeRestriction- 将 kubelet 的权限限制为只能修改其拥有的 Pod API 资源或代表其自身的节点 API 资源。
此插件还可以防止 kubelet 使用
node-restriction.kubernetes.io/注解, 攻击者可以使用该注解来访问 kubelet 的凭证,从而影响所控制的节点上的 Pod 布局。
第三组包括默认情况下未启用,但可以考虑在某些场景下启用的插件:
AlwaysPullImages- 强制使用最新版本标记的镜像,并确保部署者有权使用该镜像。
ImagePolicyWebhook- 允许通过 Webhook 对镜像强制执行额外的控制。
接下来
- RBAC 良好实践提供有关授权的更多信息。
- 保护集群提供如何保护集群免受意外或恶意访问的信息。
- 集群多租户指南提供有关多租户的配置选项建议和最佳实践。
- 博文“深入了解 NSA/CISA Kubernetes 强化指南”为强化 Kubernetes 集群提供补充资源。
9 - 策略
通过策略管理安全性和最佳实践。
Kubernetes 策略是管理其他配置或运行时行为的一些配置。 Kubernetes 提供了各种形式的策略,具体如下所述:
使用 API 对象应用策略
一些 API 对象可用作策略。以下是一些示例:
- NetworkPolicy 用于限制工作负载的出入站流量。
- LimitRange 管理多个不同对象类别的资源分配约束。
- ResourceQuota 限制名字空间的资源消耗。
使用准入控制器应用策略
准入控制器运行在 API 服务器上,
可以验证或变更 API 请求。某些准入控制器用于应用策略。
例如,AlwaysPullImages
准入控制器会修改新 Pod,将镜像拉取策略设置为 Always。
Kubernetes 具有多个内置的准入控制器,可通过 API 服务器的 --enable-admission-plugins 标志进行配置。
关于准入控制器的详细信息(包括可用准入控制器的完整列表),请查阅专门的章节:
使用 ValidatingAdmissionPolicy 应用策略
验证性的准入策略允许使用通用表达式语言 (CEL) 在 API 服务器中执行可配置的验证检查。
例如,ValidatingAdmissionPolicy 可用于禁止使用 latest 镜像标签。
ValidatingAdmissionPolicy 对请求 API 进行操作,可就不合规的配置执行阻止、审计和警告用户等操作。
有关 ValidatingAdmissionPolicy API 的详细信息及示例,请查阅专门的章节:
使用动态准入控制应用策略
动态准入控制器(或准入 Webhook)作为单独的应用在 API 服务器之外运行, 这些应用注册自身后可以接收 Webhook 请求以便对 API 请求进行验证或变更。
动态准入控制器可用于在 API 请求上应用策略并触发其他基于策略的工作流。 动态准入控制器可以执行一些复杂的检查,包括需要读取其他集群资源和外部数据的复杂检查。 例如,镜像验证检查可以从 OCI 镜像仓库中查找数据,以验证容器镜像签名和证明信息。
有关动态准入控制的详细信息,请查阅专门的章节:
实现
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
Kubernetes 生态系统中正在开发作为灵活策略引擎的动态准入控制器,例如:
使用 Kubelet 配置应用策略
Kubernetes 允许在每个工作节点上配置 Kubelet。一些 Kubelet 配置可以视为策略:
- 进程 ID 限制和保留用于限制和保留可分配的 PID。
- 节点资源管理器可以为低延迟和高吞吐量工作负载管理计算、内存和设备资源。
9.1 - 限制范围
默认情况下, Kubernetes 集群上的容器运行使用的计算资源没有限制。 使用 Kubernetes 资源配额, 管理员(也称为 集群操作者)可以在一个指定的命名空间内限制集群资源的使用与创建。 在命名空间中,一个 Pod 最多能够使用命名空间的资源配额所定义的 CPU 和内存用量。 作为集群操作者或命名空间级的管理员,你可能也会担心如何确保一个 Pod 不会垄断命名空间内所有可用的资源。
LimitRange 是限制命名空间内可为每个适用的对象类别 (例如 Pod 或 PersistentVolumeClaim) 指定的资源分配量(限制和请求)的策略对象。
一个 LimitRange(限制范围) 对象提供的限制能够做到:
- 在一个命名空间中实施对每个 Pod 或 Container 最小和最大的资源使用量的限制。
- 在一个命名空间中实施对每个 PersistentVolumeClaim 能申请的最小和最大的存储空间大小的限制。
- 在一个命名空间中实施对一种资源的申请值和限制值的比值的控制。
- 设置一个命名空间中对计算资源的默认申请/限制值,并且自动的在运行时注入到多个 Container 中。
当某命名空间中有一个 LimitRange 对象时,将在该命名空间中实施 LimitRange 限制。
LimitRange 的名称必须是合法的 DNS 子域名。
资源限制和请求的约束
- 管理员在一个命名空间内创建一个
LimitRange对象。 - 用户在此命名空间内创建(或尝试创建) Pod 和 PersistentVolumeClaim 等对象。
- 首先,
LimitRange准入控制器对所有没有设置计算资源需求的所有 Pod(及其容器)设置默认请求值与限制值。 - 其次,
LimitRange跟踪其使用量以保证没有超出命名空间中存在的任意LimitRange所定义的最小、最大资源使用量以及使用量比值。 - 若尝试创建或更新的对象(Pod 和 PersistentVolumeClaim)违反了
LimitRange的约束, 向 API 服务器的请求会失败,并返回 HTTP 状态码403 Forbidden以及描述哪一项约束被违反的消息。 - 若你在命名空间中添加
LimitRange启用了对cpu和memory等计算相关资源的限制, 你必须指定这些值的请求使用量与限制使用量。否则,系统将会拒绝创建 Pod。 LimitRange的验证仅在 Pod 准入阶段进行,不对正在运行的 Pod 进行验证。 如果你添加或修改 LimitRange,命名空间中已存在的 Pod 将继续不变。- 如果命名空间中存在两个或更多
LimitRange对象,应用哪个默认值是不确定的。
Pod 的 LimitRange 和准入检查
LimitRange 不 检查所应用的默认值的一致性。
这意味着 LimitRange 设置的 limit 的默认值可能小于客户端提交给 API 服务器的规约中为容器指定的 request 值。
如果发生这种情况,最终 Pod 将无法调度。
例如,你使用如下清单定义一个 LimitRange:
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
spec:
limits:
- default: # 此处定义默认限制值
cpu: 500m
defaultRequest: # 此处定义默认请求值
cpu: 500m
max: # max 和 min 定义限制范围
cpu: "1"
min:
cpu: 100m
type: Container
以及一个声明 CPU 资源请求为 700m 但未声明限制值的 Pod:
apiVersion: v1
kind: Pod
metadata:
name: example-conflict-with-limitrange-cpu
spec:
containers:
- name: demo
image: registry.k8s.io/pause:2.0
resources:
requests:
cpu: 700m
那么该 Pod 将不会被调度,失败并出现类似以下的错误:
Pod "example-conflict-with-limitrange-cpu" is invalid: spec.containers[0].resources.requests: Invalid value: "700m": must be less than or equal to cpu limit
如果你同时设置了 request 和 limit,那么即使使用相同的 LimitRange,新 Pod 也会被成功调度:
apiVersion: v1
kind: Pod
metadata:
name: example-no-conflict-with-limitrange-cpu
spec:
containers:
- name: demo
image: registry.k8s.io/pause:2.0
resources:
requests:
cpu: 700m
limits:
cpu: 700m
资源约束示例
能够使用限制范围创建的策略示例有:
- 在一个有两个节点,8 GiB 内存与16个核的集群中,限制一个命名空间的 Pod 申请 100m 单位,最大 500m 单位的 CPU,以及申请 200Mi,最大 600Mi 的内存。
- 为 spec 中没有 cpu 和内存需求值的 Container 定义默认 CPU 限制值与需求值 150m,内存默认需求值 300Mi。
在命名空间的总限制值小于 Pod 或 Container 的限制值的总和的情况下,可能会产生资源竞争。 在这种情况下,将不会创建 Container 或 Pod。
竞争和对 LimitRange 的改变都不会影响任何已经创建了的资源。
接下来
关于使用限值的例子,可参阅:
- 如何配置每个命名空间最小和最大的 CPU 约束。
- 如何配置每个命名空间最小和最大的内存约束。
- 如何配置每个命名空间默认的 CPU 申请值和限制值。
- 如何配置每个命名空间默认的内存申请值和限制值。
- 如何配置每个命名空间最小和最大存储使用量。
- 配置每个命名空间的配额的详细例子。
有关上下文和历史信息,请参阅 LimitRanger 设计文档。
9.2 - 资源配额
当多个用户或团队共享具有固定节点数目的集群时,人们会担心有人使用超过其基于公平原则所分配到的资源量。
资源配额是帮助管理员解决这一问题的工具。
资源配额,通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。
它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命名空间中的 Pod 可以使用的计算资源的总上限。
资源配额的工作方式如下:
-
不同的团队可以在不同的命名空间下工作。这可以通过 RBAC 强制执行。
-
集群管理员可以为每个命名空间创建一个或多个 ResourceQuota 对象。
-
当用户在命名空间下创建资源(如 Pod、Service 等)时,Kubernetes 的配额系统会跟踪集群的资源使用情况, 以确保使用的资源用量不超过 ResourceQuota 中定义的硬性资源限额。
-
如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN), 并在消息中给出有可能违反的约束。
-
如果命名空间下的计算资源 (如
cpu和memory)的配额被启用, 则用户必须为这些资源设定请求值(request)和约束值(limit),否则配额系统将拒绝 Pod 的创建。 提示: 可使用LimitRanger准入控制器来为没有设置计算资源需求的 Pod 设置默认值。若想避免这类问题,请参考 演练示例。
说明:
- 对于
cpu和memory资源:ResourceQuota 强制该命名空间中的每个(新)Pod 为该资源设置限制。 如果你在命名空间中为cpu和memory实施资源配额, 你或其他客户端必须为你提交的每个新 Pod 指定该资源的requests或limits。 否则,控制平面可能会拒绝接纳该 Pod。 - 对于其他资源:ResourceQuota 可以工作,并且会忽略命名空间中的 Pod,而无需为该资源设置限制或请求。 这意味着,如果资源配额限制了此命名空间的临时存储,则可以创建没有限制/请求临时存储的新 Pod。 你可以使用限制范围自动设置对这些资源的默认请求。
ResourceQuota 对象的名称必须是合法的 DNS 子域名。
下面是使用命名空间和配额构建策略的示例:
- 在具有 32 GiB 内存和 16 核 CPU 资源的集群中,允许 A 团队使用 20 GiB 内存 和 10 核的 CPU 资源, 允许 B 团队使用 10 GiB 内存和 4 核的 CPU 资源,并且预留 2 GiB 内存和 2 核的 CPU 资源供将来分配。
- 限制 "testing" 命名空间使用 1 核 CPU 资源和 1GiB 内存。允许 "production" 命名空间使用任意数量。
在集群容量小于各命名空间配额总和的情况下,可能存在资源竞争。资源竞争时,Kubernetes 系统会遵循先到先得的原则。
不管是资源竞争还是配额的修改,都不会影响已经创建的资源使用对象。
启用资源配额
资源配额的支持在很多 Kubernetes 版本中是默认启用的。
当 API 服务器
的命令行标志 --enable-admission-plugins= 中包含 ResourceQuota 时,
资源配额会被启用。
当命名空间中存在一个 ResourceQuota 对象时,对于该命名空间而言,资源配额就是开启的。
计算资源配额
用户可以对给定命名空间下的可被请求的 计算资源 总量进行限制。
配额机制所支持的资源类型:
| 资源名称 | 描述 |
|---|---|
limits.cpu |
所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。 |
limits.memory |
所有非终止状态的 Pod,其内存限额总量不能超过该值。 |
requests.cpu |
所有非终止状态的 Pod,其 CPU 需求总量不能超过该值。 |
requests.memory |
所有非终止状态的 Pod,其内存需求总量不能超过该值。 |
hugepages-<size> |
对于所有非终止状态的 Pod,针对指定尺寸的巨页请求总数不能超过此值。 |
cpu |
与 requests.cpu 相同。 |
memory |
与 requests.memory 相同。 |
扩展资源的资源配额
除上述资源外,在 Kubernetes 1.10 版本中,还添加了对 扩展资源 的支持。
由于扩展资源不可超量分配,因此没有必要在配额中为同一扩展资源同时指定 requests 和 limits。
对于扩展资源而言,目前仅允许使用前缀为 requests. 的配额项。
以 GPU 拓展资源为例,如果资源名称为 nvidia.com/gpu,并且要将命名空间中请求的 GPU
资源总数限制为 4,则可以如下定义配额:
requests.nvidia.com/gpu: 4
有关更多详细信息,请参阅查看和设置配额。
存储资源配额
用户可以对给定命名空间下的存储资源 总量进行限制。
此外,还可以根据相关的存储类(Storage Class)来限制存储资源的消耗。
| 资源名称 | 描述 |
|---|---|
requests.storage |
所有 PVC,存储资源的需求总量不能超过该值。 |
persistentvolumeclaims |
在该命名空间中所允许的 PVC 总量。 |
<storage-class-name>.storageclass.storage.k8s.io/requests.storage |
在所有与 <storage-class-name> 相关的持久卷申领中,存储请求的总和不能超过该值。 |
<storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims |
在与 storage-class-name 相关的所有持久卷申领中,命名空间中可以存在的持久卷申领总数。 |
例如,如果一个操作人员针对 gold 存储类型与 bronze 存储类型设置配额,
操作人员可以定义如下配额:
gold.storageclass.storage.k8s.io/requests.storage: 500Gibronze.storageclass.storage.k8s.io/requests.storage: 100Gi
在 Kubernetes 1.8 版本中,本地临时存储的配额支持已经是 Alpha 功能:
| 资源名称 | 描述 |
|---|---|
requests.ephemeral-storage |
在命名空间的所有 Pod 中,本地临时存储请求的总和不能超过此值。 |
limits.ephemeral-storage |
在命名空间的所有 Pod 中,本地临时存储限制值的总和不能超过此值。 |
ephemeral-storage |
与 requests.ephemeral-storage 相同。 |
说明:
如果所使用的是 CRI 容器运行时,容器日志会被计入临时存储配额。 这可能会导致存储配额耗尽的 Pods 被意外地驱逐出节点。 参考日志架构 了解详细信息。
对象数量配额
你可以使用以下语法对所有标准的、命名空间域的资源类型进行配额设置:
count/<resource>.<group>:用于非核心(core)组的资源count/<resource>:用于核心组的资源
这是用户可能希望利用对象计数配额来管理的一组资源示例。
count/persistentvolumeclaimscount/servicescount/secretscount/configmapscount/replicationcontrollerscount/deployments.appscount/replicasets.appscount/statefulsets.appscount/jobs.batchcount/cronjobs.batch
相同语法也可用于自定义资源。
例如,要对 example.com API 组中的自定义资源 widgets 设置配额,请使用
count/widgets.example.com。
当使用 count/* 资源配额时,如果对象存在于服务器存储中,则会根据配额管理资源。
这些类型的配额有助于防止存储资源耗尽。例如,用户可能想根据服务器的存储能力来对服务器中
Secret 的数量进行配额限制。
集群中存在过多的 Secret 实际上会导致服务器和控制器无法启动。
用户可以选择对 Job 进行配额管理,以防止配置不当的 CronJob 在某命名空间中创建太多
Job 而导致集群拒绝服务。
对有限的一组资源上实施一般性的对象数量配额也是可能的。
支持以下类型:
| 资源名称 | 描述 |
|---|---|
configmaps |
在该命名空间中允许存在的 ConfigMap 总数上限。 |
persistentvolumeclaims |
在该命名空间中允许存在的 PVC 的总数上限。 |
pods |
在该命名空间中允许存在的非终止状态的 Pod 总数上限。Pod 终止状态等价于 Pod 的 .status.phase in (Failed, Succeeded) 为真。 |
replicationcontrollers |
在该命名空间中允许存在的 ReplicationController 总数上限。 |
resourcequotas |
在该命名空间中允许存在的 ResourceQuota 总数上限。 |
services |
在该命名空间中允许存在的 Service 总数上限。 |
services.loadbalancers |
在该命名空间中允许存在的 LoadBalancer 类型的 Service 总数上限。 |
services.nodeports |
在该命名空间中允许存在的 NodePort 类型的 Service 总数上限。 |
secrets |
在该命名空间中允许存在的 Secret 总数上限。 |
例如,pods 配额统计某个命名空间中所创建的、非终止状态的 Pod 个数并确保其不超过某上限值。
用户可能希望在某命名空间中设置 pods 配额,以避免有用户创建很多小的 Pod,
从而耗尽集群所能提供的 Pod IP 地址。
配额作用域
每个配额都有一组相关的 scope(作用域),配额只会对作用域内的资源生效。
配额机制仅统计所列举的作用域的交集中的资源用量。
当一个作用域被添加到配额中后,它会对作用域相关的资源数量作限制。 如配额中指定了允许(作用域)集合之外的资源,会导致验证错误。
| 作用域 | 描述 |
|---|---|
Terminating |
匹配所有 spec.activeDeadlineSeconds 不小于 0 的 Pod。 |
NotTerminating |
匹配所有 spec.activeDeadlineSeconds 是 nil 的 Pod。 |
BestEffort |
匹配所有 Qos 是 BestEffort 的 Pod。 |
NotBestEffort |
匹配所有 Qos 不是 BestEffort 的 Pod。 |
PriorityClass |
匹配所有引用了所指定的优先级类的 Pods。 |
CrossNamespacePodAffinity |
匹配那些设置了跨名字空间 (反)亲和性条件的 Pod。 |
BestEffort 作用域限制配额跟踪以下资源:
pods
Terminating、NotTerminating、NotBestEffort 和 PriorityClass 这些作用域限制配额跟踪以下资源:
podscpumemoryrequests.cpurequests.memorylimits.cpulimits.memory
需要注意的是,你不可以在同一个配额对象中同时设置 Terminating 和 NotTerminating
作用域,你也不可以在同一个配额中同时设置 BestEffort 和 NotBestEffort
作用域。
scopeSelector 支持在 operator 字段中使用以下值:
InNotInExistsDoesNotExist
定义 scopeSelector 时,如果使用以下值之一作为 scopeName 的值,则对应的
operator 只能是 Exists。
TerminatingNotTerminatingBestEffortNotBestEffort
如果 operator 是 In 或 NotIn 之一,则 values 字段必须至少包含一个值。
例如:
scopeSelector:
matchExpressions:
- scopeName: PriorityClass
operator: In
values:
- middle
如果 operator 为 Exists 或 DoesNotExist,则不可以设置 values 字段。
基于优先级类(PriorityClass)来设置资源配额
特性状态:
Kubernetes v1.17 [stable]
Pod 可以创建为特定的优先级。
通过使用配额规约中的 scopeSelector 字段,用户可以根据 Pod 的优先级控制其系统资源消耗。
仅当配额规范中的 scopeSelector 字段选择到某 Pod 时,配额机制才会匹配和计量 Pod 的资源消耗。
如果配额对象通过 scopeSelector 字段设置其作用域为优先级类,
则配额对象只能跟踪以下资源:
podscpumemoryephemeral-storagelimits.cpulimits.memorylimits.ephemeral-storagerequests.cpurequests.memoryrequests.ephemeral-storage
本示例创建一个配额对象,并将其与具有特定优先级的 Pod 进行匹配。 该示例的工作方式如下:
- 集群中的 Pod 可取三个优先级类之一,即 "low"、"medium"、"high"。
- 为每个优先级创建一个配额对象。
将以下 YAML 保存到文件 quota.yml 中。
apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-high
spec:
hard:
cpu: "1000"
memory: 200Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["high"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-medium
spec:
hard:
cpu: "10"
memory: 20Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["medium"]
- apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-low
spec:
hard:
cpu: "5"
memory: 10Gi
pods: "10"
scopeSelector:
matchExpressions:
- operator: In
scopeName: PriorityClass
values: ["low"]
使用 kubectl create 命令运行以下操作。
kubectl create -f ./quota.yml
resourcequota/pods-high created
resourcequota/pods-medium created
resourcequota/pods-low created
使用 kubectl describe quota 操作验证配额的 Used 值为 0。
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 1k
memory 0 200Gi
pods 0 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
创建优先级为 "high" 的 Pod。
将以下 YAML 保存到文件 high-priority-pod.yml 中。
apiVersion: v1
kind: Pod
metadata:
name: high-priority
spec:
containers:
- name: high-priority
image: ubuntu
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
resources:
requests:
memory: "10Gi"
cpu: "500m"
limits:
memory: "10Gi"
cpu: "500m"
priorityClassName: high
使用 kubectl create 运行以下操作。
kubectl create -f ./high-priority-pod.yml
确认 "high" 优先级配额 pods-high 的 "Used" 统计信息已更改,并且其他两个配额未更改。
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 500m 1k
memory 10Gi 200Gi
pods 1 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
跨名字空间的 Pod 亲和性配额
特性状态:
Kubernetes v1.24 [stable]
集群运维人员可以使用 CrossNamespacePodAffinity
配额作用域来限制哪个名字空间中可以存在包含跨名字空间亲和性规则的 Pod。
更为具体一点,此作用域用来配置哪些 Pod 可以在其 Pod 亲和性规则中设置
namespaces 或 namespaceSelector 字段。
禁止用户使用跨名字空间的亲和性规则可能是一种被需要的能力, 因为带有反亲和性约束的 Pod 可能会阻止所有其他名字空间的 Pod 被调度到某失效域中。
使用此作用域操作符可以避免某些名字空间(例如下面例子中的 foo-ns)运行特别的 Pod,
这类 Pod 使用跨名字空间的 Pod 亲和性约束,在该名字空间中创建了作用域为
CrossNamespacePodAffinity 的、硬性约束为 0 的资源配额对象。
apiVersion: v1
kind: ResourceQuota
metadata:
name: disable-cross-namespace-affinity
namespace: foo-ns
spec:
hard:
pods: "0"
scopeSelector:
matchExpressions:
- scopeName: CrossNamespacePodAffinity
operator: Exists
如果集群运维人员希望默认禁止使用 namespaces 和 namespaceSelector,
而仅仅允许在特定名字空间中这样做,他们可以将 CrossNamespacePodAffinity
作为一个被约束的资源。方法是为 kube-apiserver 设置标志
--admission-control-config-file,使之指向如下的配置文件:
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: apiserver.config.k8s.io/v1
kind: ResourceQuotaConfiguration
limitedResources:
- resource: pods
matchScopes:
- scopeName: CrossNamespacePodAffinity
operator: Exists
基于上面的配置,只有名字空间中包含作用域为 CrossNamespacePodAffinity
且硬性约束大于或等于使用 namespaces 和 namespaceSelector 字段的 Pod
个数时,才可以在该名字空间中继续创建在其 Pod 亲和性规则中设置 namespaces
或 namespaceSelector 的新 Pod。
请求与限制的比较
分配计算资源时,每个容器可以为 CPU 或内存指定请求和约束。 配额可以针对二者之一进行设置。
如果配额中指定了 requests.cpu 或 requests.memory 的值,则它要求每个容器都显式给出对这些资源的请求。
同理,如果配额中指定了 limits.cpu 或 limits.memory 的值,那么它要求每个容器都显式设定对应资源的限制。
查看和设置配额
Kubectl 支持创建、更新和查看配额:
kubectl create namespace myspace
cat <<EOF > compute-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
requests.nvidia.com/gpu: 4
EOF
kubectl create -f ./compute-resources.yaml --namespace=myspace
cat <<EOF > object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
pods: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
EOF
kubectl create -f ./object-counts.yaml --namespace=myspace
kubectl get quota --namespace=myspace
NAME AGE
compute-resources 30s
object-counts 32s
kubectl describe quota compute-resources --namespace=myspace
Name: compute-resources
Namespace: myspace
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
requests.cpu 0 1
requests.memory 0 1Gi
requests.nvidia.com/gpu 0 4
kubectl describe quota object-counts --namespace=myspace
Name: object-counts
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 0 10
persistentvolumeclaims 0 4
pods 0 4
replicationcontrollers 0 20
secrets 1 10
services 0 10
services.loadbalancers 0 2
kubectl 还使用语法 count/<resource>.<group> 支持所有标准的、命名空间域的资源的对象计数配额:
kubectl create namespace myspace
kubectl create quota test --hard=count/deployments.apps=2,count/replicasets.apps=4,count/pods=3,count/secrets=4 --namespace=myspace
kubectl create deployment nginx --image=nginx --namespace=myspace --replicas=2
kubectl describe quota --namespace=myspace
Name: test
Namespace: myspace
Resource Used Hard
-------- ---- ----
count/deployments.apps 1 2
count/pods 2 3
count/replicasets.apps 1 4
count/secrets 1 4
配额和集群容量
ResourceQuota 与集群资源总量是完全独立的。它们通过绝对的单位来配置。 所以,为集群添加节点时,资源配额不会自动赋予每个命名空间消耗更多资源的能力。
有时可能需要资源配额支持更复杂的策略,比如:
- 在几个团队中按比例划分总的集群资源。
- 允许每个租户根据需要增加资源使用量,但要有足够的限制以防止资源意外耗尽。
- 探测某个命名空间的需求,添加物理节点并扩大资源配额值。
这些策略可以通过将资源配额作为一个组成模块、手动编写一个控制器来监控资源使用情况, 并结合其他信号调整命名空间上的硬性资源配额来实现。
注意:资源配额对集群资源总体进行划分,但它对节点没有限制:来自不同命名空间的 Pod 可能在同一节点上运行。
默认情况下限制特定优先级的资源消耗
有时候可能希望当且仅当某名字空间中存在匹配的配额对象时,才可以创建特定优先级 (例如 "cluster-services")的 Pod。
通过这种机制,操作人员能够限制某些高优先级类仅出现在有限数量的命名空间中, 而并非每个命名空间默认情况下都能够使用这些优先级类。
要实现此目的,应设置 kube-apiserver 的标志 --admission-control-config-file
指向如下配置文件:
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: "ResourceQuota"
configuration:
apiVersion: apiserver.config.k8s.io/v1
kind: ResourceQuotaConfiguration
limitedResources:
- resource: pods
matchScopes:
- scopeName: PriorityClass
operator: In
values: ["cluster-services"]
现在在 kube-system 名字空间中创建一个资源配额对象:
apiVersion: v1
kind: ResourceQuota
metadata:
name: pods-cluster-services
spec:
scopeSelector:
matchExpressions:
- operator : In
scopeName: PriorityClass
values: ["cluster-services"]kubectl apply -f https://k8s.io/examples/policy/priority-class-resourcequota.yaml -n kube-system
resourcequota/pods-cluster-services created
在这里,当以下条件满足时可以创建 Pod:
- Pod 未设置
priorityClassName - Pod 的
priorityClassName设置值不是cluster-services - Pod 的
priorityClassName设置值为cluster-services,它将被创建于kube-system名字空间中,并且它已经通过了资源配额检查。
如果 Pod 的 priorityClassName 设置为 cluster-services,但要被创建到
kube-system 之外的别的名字空间,则 Pod 创建请求也被拒绝。
接下来
- 参阅资源配额设计文档。
- 参阅如何使用资源配额的详细示例。
- 参阅优先级类配额支持的设计文档了解更多信息。
- 参阅 LimitedResources。
9.3 - 进程 ID 约束与预留
特性状态:
Kubernetes v1.20 [stable]
Kubernetes 允许你限制一个 Pod 中可以使用的进程 ID(PID)数目。 你也可以为每个节点预留一定数量的可分配的 PID, 供操作系统和守护进程(而非 Pod)使用。
进程 ID(PID)是节点上的一种基础资源。很容易就会在尚未超出其它资源约束的时候就已经触及任务个数上限, 进而导致宿主机器不稳定。
集群管理员需要一定的机制来确保集群中运行的 Pod 不会导致 PID 资源枯竭, 甚而造成宿主机上的守护进程(例如 kubelet 或者 kube-proxy 乃至包括容器运行时本身)无法正常运行。 此外,确保 Pod 中 PID 的个数受限对于保证其不会影响到同一节点上其它负载也很重要。
说明:
在某些 Linux 安装环境中,操作系统会将 PID 约束设置为一个较低的默认值,例如
32768。这时可以考虑提升 /proc/sys/kernel/pid_max 的设置值。
你可以配置 kubelet 限制给定 Pod 能够使用的 PID 个数。
例如,如果你的节点上的宿主操作系统被设置为最多可使用 262144 个 PID,
同时预期节点上会运行的 Pod 个数不会超过 250,那么你可以为每个 Pod 设置 1000 个 PID
的预算,避免耗尽该节点上可用 PID 的总量。
如果管理员系统像 CPU 或内存那样允许对 PID 进行过量分配(Overcommit),他们也可以这样做,
只是会有一些额外的风险。不管怎样,任何一个 Pod 都不可以将整个机器的运行状态破坏。
这类资源限制有助于避免简单的派生炸弹(Fork Bomb)影响到整个集群的运行。
在 Pod 级别设置 PID 限制使得管理员能够保护 Pod 之间不会互相伤害, 不过无法确保所有调度到该宿主机器上的所有 Pod 都不会影响到节点整体。 Pod 级别的限制也无法保护节点代理任务自身不会受到 PID 耗尽的影响。
你也可以预留一定量的 PID,作为节点的额外开销,与分配给 Pod 的 PID 集合独立。 这有点类似于在给操作系统和其它设施预留 CPU、内存或其它资源时所做的操作, 这些任务都在 Pod 及其所包含的容器之外运行。
PID 限制是与计算资源
请求和限制相辅相成的一种机制。不过,你需要用一种不同的方式来设置这一限制:
你需要将其设置到 kubelet 上而不是在 Pod 的 .spec 中为 Pod 设置资源限制。
目前还不支持在 Pod 级别设置 PID 限制。
注意:
这意味着,施加在 Pod 之上的限制值可能因为 Pod 运行所在的节点不同而有差别。 为了简化系统,最简单的方法是为所有节点设置相同的 PID 资源限制和预留值。
节点级别 PID 限制
Kubernetes 允许你为系统预留一定量的进程 ID。为了配置预留数量,你可以使用
kubelet 的 --system-reserved 和 --kube-reserved 命令行选项中的参数
pid=<number>。你所设置的参数值分别用来声明为整个系统和 Kubernetes
系统守护进程所保留的进程 ID 数目。
Pod 级别 PID 限制
Kubernetes 允许你限制 Pod 中运行的进程个数。你可以在节点级别设置这一限制,
而不是为特定的 Pod 来将其设置为资源限制。每个节点都可以有不同的 PID 限制设置。
要设置限制值,你可以设置 kubelet 的命令行参数 --pod-max-pids,或者在 kubelet
的配置文件中设置
PodPidsLimit。
基于 PID 的驱逐
你可以配置 kubelet 使之在 Pod 行为不正常或者消耗不正常数量资源的时候将其终止。这一特性称作驱逐。
你可以针对不同的驱逐信号配置资源不足的处理。
使用 pid.available 驱逐信号来配置 Pod 使用的 PID 个数的阈值。
你可以设置硬性的和软性的驱逐策略。不过,即使使用硬性的驱逐策略,
如果 PID 个数增长过快,节点仍然可能因为触及节点 PID 限制而进入一种不稳定状态。
驱逐信号的取值是周期性计算的,而不是一直能够强制实施约束。
Pod 级别和节点级别的 PID 限制会设置硬性限制。 一旦触及限制值,工作负载会在尝试获得新的 PID 时开始遇到问题。 这可能会也可能不会导致 Pod 被重新调度,取决于工作负载如何应对这类失败以及 Pod 的存活性和就绪态探测是如何配置的。 可是,如果限制值被正确设置,你可以确保其它 Pod 负载和系统进程不会因为某个 Pod 行为不正常而没有 PID 可用。
接下来
- 参阅 PID 约束改进文档 以了解更多信息。
- 关于历史背景,请阅读 Kubernetes 1.14 中限制进程 ID 以提升稳定性 的博文。
- 请阅读为容器管理资源。
- 学习如何配置资源不足情况的处理。
9.4 - 节点资源管理器
Kubernetes 提供了一组资源管理器,用于支持延迟敏感的、高吞吐量的工作负载。 资源管理器的目标是协调和优化节点资源,以支持对 CPU、设备和内存(巨页)等资源有特殊需求的 Pod。
主管理器,也叫拓扑管理器(Topology Manager),是一个 Kubelet 组件, 它通过策略, 协调全局的资源管理过程。
各个管理器的配置方式会在专项文档中详细阐述:
10 - 调度、抢占和驱逐
在 Kubernetes 中,调度(scheduling)指的是确保 Pod 匹配到合适的节点, 以便 kubelet 能够运行它们。抢占(Preemption)指的是终止低优先级的 Pod 以便高优先级的 Pod 可以调度运行的过程。驱逐(Eviction)是在资源匮乏的节点上,主动让一个或多个 Pod 失效的过程。
在 Kubernetes 中,调度(scheduling)指的是确保 Pod 匹配到合适的节点, 以便 kubelet 能够运行它们。 抢占(Preemption)指的是终止低优先级的 Pod 以便高优先级的 Pod 可以调度运行的过程。 驱逐(Eviction)是在资源匮乏的节点上,主动让一个或多个 Pod 失效的过程。
调度
- Kubernetes 调度器
- 将 Pod 指派到节点
- Pod 开销
- Pod 拓扑分布约束
- 污点和容忍度
- 动态资源分配
- 调度框架
- 调度器性能调试
- 扩展资源的资源装箱
- Pod 调度就绪
- Descheduler
Pod 干扰
Pod 干扰 是指节点上的 Pod 被自愿或非自愿终止的过程。
自愿干扰是由应用程序所有者或集群管理员有意启动的。非自愿干扰是无意的, 可能由不可避免的问题触发,如节点耗尽资源或意外删除。
10.1 - Kubernetes 调度器
在 Kubernetes 中,调度是指将 Pod 放置到合适的节点上,以便对应节点上的 Kubelet 能够运行这些 Pod。
调度概览
调度器通过 Kubernetes 的监测(Watch)机制来发现集群中新创建且尚未被调度到节点上的 Pod。 调度器会将所发现的每一个未调度的 Pod 调度到一个合适的节点上来运行。 调度器会依据下文的调度原则来做出调度选择。
如果你想要理解 Pod 为什么会被调度到特定的节点上, 或者你想要尝试实现一个自定义的调度器,这篇文章将帮助你了解调度。
kube-scheduler
kube-scheduler 是 Kubernetes 集群的默认调度器,并且是集群 控制面 的一部分。 如果你真得希望或者有这方面的需求,kube-scheduler 在设计上允许你自己编写一个调度组件并替换原有的 kube-scheduler。
Kube-scheduler 选择一个最佳节点来运行新创建的或尚未调度(unscheduled)的 Pod。 由于 Pod 中的容器和 Pod 本身可能有不同的要求,调度程序会过滤掉任何不满足 Pod 特定调度需求的节点。 或者,API 允许你在创建 Pod 时为它指定一个节点,但这并不常见,并且仅在特殊情况下才会这样做。
在一个集群中,满足一个 Pod 调度请求的所有节点称之为可调度节点。 如果没有任何一个节点能满足 Pod 的资源请求, 那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。
调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分, 选出其中得分最高的节点来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做绑定。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、 亲和以及反亲和要求、数据局部性、负载间的干扰等等。
kube-scheduler 中的节点选择
kube-scheduler 给一个 Pod 做调度选择时包含两个步骤:
- 过滤
- 打分
过滤阶段会将所有满足 Pod 调度需求的节点选出来。 例如,PodFitsResources 过滤函数会检查候选节点的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下, 这个节点列表包含不止一个节点。如果这个列表是空的,代表这个 Pod 不可调度。
在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的节点。 根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的节点上。 如果存在多个得分最高的节点,kube-scheduler 会从中随机选取一个。
支持以下两种方式配置调度器的过滤和打分行为:
- 调度策略 允许你配置过滤所用的 断言(Predicates) 和打分所用的 优先级(Priorities)。
- 调度配置 允许你配置实现不同调度阶段的插件,
包括:
QueueSort、Filter、Score、Bind、Reserve、Permit等等。 你也可以配置 kube-scheduler 运行不同的配置文件。
接下来
- 阅读关于调度器性能调优
- 阅读关于 Pod 拓扑分布约束
- 阅读关于 kube-scheduler 的参考文档
- 阅读 kube-scheduler 配置参考(v1)
- 了解关于配置多个调度器 的方式
- 了解关于拓扑结构管理策略
- 了解关于 Pod 开销
- 了解关于如何在以下情形使用卷来调度 Pod:
10.2 - 将 Pod 指派给节点
你可以约束一个 Pod 以便限制其只能在特定的节点上运行, 或优先在特定的节点上运行。有几种方法可以实现这点,推荐的方法都是用 标签选择算符来进行选择。 通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 Pod 分散到节点上, 而不是将 Pod 放置在可用资源不足的节点上等等)。但在某些情况下,你可能需要进一步控制 Pod 被部署到哪个节点。例如,确保 Pod 最终落在连接了 SSD 的机器上, 或者将来自两个不同的服务且有大量通信的 Pod 被放置在同一个可用区。
你可以使用下列方法中的任何一种来选择 Kubernetes 对特定 Pod 的调度:
- 与节点标签匹配的 nodeSelector
- 亲和性与反亲和性
- nodeName 字段
- Pod 拓扑分布约束
节点标签
与很多其他 Kubernetes 对象类似,节点也有标签。 你可以手动地添加标签。 Kubernetes 也会为集群中所有节点添加一些标准的标签。
说明:
这些标签的取值是取决于云提供商的,并且是无法在可靠性上给出承诺的。
例如,kubernetes.io/hostname 的取值在某些环境中可能与节点名称相同,
而在其他环境中会取不同的值。
节点隔离/限制
通过为节点添加标签,你可以准备让 Pod 调度到特定节点或节点组上。 你可以使用这个功能来确保特定的 Pod 只能运行在具有一定隔离性、安全性或监管属性的节点上。
如果使用标签来实现节点隔离,建议选择节点上的 kubelet 无法修改的标签键。 这可以防止受感染的节点在自身上设置这些标签,进而影响调度器将工作负载调度到受感染的节点。
NodeRestriction 准入插件防止
kubelet 使用 node-restriction.kubernetes.io/ 前缀设置或修改标签。
要使用该标签前缀进行节点隔离:
- 确保你在使用节点鉴权机制并且已经启用了 NodeRestriction 准入插件。
- 将带有
node-restriction.kubernetes.io/前缀的标签添加到 Node 对象, 然后在节点选择算符中使用这些标签。 例如,example.com.node-restriction.kubernetes.io/fips=true或example.com.node-restriction.kubernetes.io/pci-dss=true。
nodeSelector
nodeSelector 是节点选择约束的最简单推荐形式。你可以将 nodeSelector 字段添加到
Pod 的规约中设置你希望目标节点所具有的节点标签。
Kubernetes 只会将 Pod 调度到拥有你所指定的每个标签的节点上。
进一步的信息可参见将 Pod 指派给节点。
亲和性与反亲和性
nodeSelector 提供了一种最简单的方法来将 Pod 约束到具有特定标签的节点上。
亲和性和反亲和性扩展了你可以定义的约束类型。使用亲和性与反亲和性的一些好处有:
- 亲和性、反亲和性语言的表达能力更强。
nodeSelector只能选择拥有所有指定标签的节点。 亲和性、反亲和性为你提供对选择逻辑的更强控制能力。 - 你可以标明某规则是“软需求”或者“偏好”,这样调度器在无法找到匹配节点时仍然调度该 Pod。
- 你可以使用节点上(或其他拓扑域中)运行的其他 Pod 的标签来实施调度约束, 而不是只能使用节点本身的标签。这个能力让你能够定义规则允许哪些 Pod 可以被放置在一起。
亲和性功能由两种类型的亲和性组成:
- 节点亲和性功能类似于
nodeSelector字段,但它的表达能力更强,并且允许你指定软规则。 - Pod 间亲和性/反亲和性允许你根据其他 Pod 的标签来约束 Pod。
节点亲和性
节点亲和性概念上类似于 nodeSelector,
它使你可以根据节点上的标签来约束 Pod 可以调度到哪些节点上。
节点亲和性有两种:
requiredDuringSchedulingIgnoredDuringExecution: 调度器只有在规则被满足的时候才能执行调度。此功能类似于nodeSelector, 但其语法表达能力更强。preferredDuringSchedulingIgnoredDuringExecution: 调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
说明:
在上述类型中,IgnoredDuringExecution 意味着如果节点标签在 Kubernetes
调度 Pod 后发生了变更,Pod 仍将继续运行。
你可以使用 Pod 规约中的 .spec.affinity.nodeAffinity 字段来设置节点亲和性。
例如,考虑下面的 Pod 规约:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0在这一示例中,所应用的规则如下:
- 节点必须包含一个键名为
topology.kubernetes.io/zone的标签, 并且该标签的取值必须为antarctica-east1或antarctica-west1。 - 节点最好具有一个键名为
another-node-label-key且取值为another-node-label-value的标签。
你可以使用 operator 字段来为 Kubernetes 设置在解释规则时要使用的逻辑操作符。
你可以使用 In、NotIn、Exists、DoesNotExist、Gt 和 Lt 之一作为操作符。
阅读操作符了解有关这些操作的更多信息。
NotIn 和 DoesNotExist 可用来实现节点反亲和性行为。
你也可以使用节点污点
将 Pod 从特定节点上驱逐。
说明:
如果你同时指定了 nodeSelector 和 nodeAffinity,两者必须都要满足,
才能将 Pod 调度到候选节点上。
如果你在与 nodeAffinity 类型关联的 nodeSelectorTerms 中指定多个条件,
只要其中一个 nodeSelectorTerms 满足(各个条件按逻辑或操作组合)的话,Pod 就可以被调度到节点上。
如果你在与 nodeSelectorTerms 中的条件相关联的单个 matchExpressions 字段中指定多个表达式,
则只有当所有表达式都满足(各表达式按逻辑与操作组合)时,Pod 才能被调度到节点上。
参阅使用节点亲和性来为 Pod 指派节点, 以了解进一步的信息。
节点亲和性权重
你可以为 preferredDuringSchedulingIgnoredDuringExecution 亲和性类型的每个实例设置
weight 字段,其取值范围是 1 到 100。
当调度器找到能够满足 Pod 的其他调度请求的节点时,调度器会遍历节点满足的所有的偏好性规则,
并将对应表达式的 weight 值加和。
最终的加和值会添加到该节点的其他优先级函数的评分之上。 在调度器为 Pod 作出调度决定时,总分最高的节点的优先级也最高。
例如,考虑下面的 Pod 规约:
apiVersion: v1
kind: Pod
metadata:
name: with-affinity-anti-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: label-1
operator: In
values:
- key-1
- weight: 50
preference:
matchExpressions:
- key: label-2
operator: In
values:
- key-2
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0如果存在两个候选节点,都满足 preferredDuringSchedulingIgnoredDuringExecution 规则,
其中一个节点具有标签 label-1:key-1,另一个节点具有标签 label-2:key-2,
调度器会考察各个节点的 weight 取值,并将该权重值添加到节点的其他得分值之上,
说明:
如果你希望 Kubernetes 能够成功地调度此例中的 Pod,你必须拥有打了
kubernetes.io/os=linux 标签的节点。
逐个调度方案中设置节点亲和性
特性状态:
Kubernetes v1.20 [beta]
在配置多个调度方案时,
你可以将某个方案与节点亲和性关联起来,如果某个调度方案仅适用于某组特殊的节点时,
这样做是很有用的。
要实现这点,可以在调度器配置中为
NodeAffinity 插件的
args 字段添加 addedAffinity。例如:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: foo-scheduler
pluginConfig:
- name: NodeAffinity
args:
addedAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduler-profile
operator: In
values:
- foo
这里的 addedAffinity 除遵从 Pod 规约中设置的节点亲和性之外,
还适用于将 .spec.schedulerName 设置为 foo-scheduler。
换言之,为了匹配 Pod,节点需要满足 addedAffinity 和 Pod 的 .spec.NodeAffinity。
由于 addedAffinity 对最终用户不可见,其行为可能对用户而言是出乎意料的。
应该使用与调度方案名称有明确关联的节点标签。
说明:
DaemonSet 控制器为 DaemonSet 创建 Pod,
但该控制器不理会调度方案。
DaemonSet 控制器创建 Pod 时,默认的 Kubernetes 调度器负责放置 Pod,
并遵从 DaemonSet 控制器中设置的 nodeAffinity 规则。
Pod 间亲和性与反亲和性
Pod 间亲和性与反亲和性使你可以基于已经在节点上运行的 Pod 的标签来约束 Pod 可以调度到的节点,而不是基于节点上的标签。
Pod 间亲和性与反亲和性的规则格式为“如果 X 上已经运行了一个或多个满足规则 Y 的 Pod, 则这个 Pod 应该(或者在反亲和性的情况下不应该)运行在 X 上”。 这里的 X 可以是节点、机架、云提供商可用区或地理区域或类似的拓扑域, Y 则是 Kubernetes 尝试满足的规则。
你通过标签选择算符 的形式来表达规则(Y),并可根据需要指定选关联的名字空间列表。 Pod 在 Kubernetes 中是名字空间作用域的对象,因此 Pod 的标签也隐式地具有名字空间属性。 针对 Pod 标签的所有标签选择算符都要指定名字空间,Kubernetes 会在指定的名字空间内寻找标签。
你会通过 topologyKey 来表达拓扑域(X)的概念,其取值是系统用来标示域的节点标签键。
相关示例可参见常用标签、注解和污点。
说明:
Pod 间亲和性和反亲和性都需要相当的计算量,因此会在大规模集群中显著降低调度速度。 我们不建议在包含数百个节点的集群中使用这类设置。
说明:
Pod 反亲和性需要节点上存在一致性的标签。换言之,
集群中每个节点都必须拥有与 topologyKey 匹配的标签。
如果某些或者所有节点上不存在所指定的 topologyKey 标签,调度行为可能与预期的不同。
Pod 间亲和性与反亲和性的类型
与节点亲和性类似,Pod 的亲和性与反亲和性也有两种类型:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
例如,你可以使用 requiredDuringSchedulingIgnoredDuringExecution 亲和性来告诉调度器,
将两个服务的 Pod 放到同一个云提供商可用区内,因为它们彼此之间通信非常频繁。
类似地,你可以使用 preferredDuringSchedulingIgnoredDuringExecution
反亲和性来将同一服务的多个 Pod 分布到多个云提供商可用区中。
要使用 Pod 间亲和性,可以使用 Pod 规约中的 .affinity.podAffinity 字段。
对于 Pod 间反亲和性,可以使用 Pod 规约中的 .affinity.podAntiAffinity 字段。
调度一组具有 Pod 间亲和性的 Pod
如果当前正被调度的 Pod 在具有自我亲和性的 Pod 序列中排在第一个, 那么只要它满足其他所有的亲和性规则,它就可以被成功调度。 这是通过以下方式确定的:确保集群中没有其他 Pod 与此 Pod 的名字空间和标签选择算符匹配; 该 Pod 满足其自身定义的条件,并且选定的节点满足所指定的所有拓扑要求。 这确保即使所有的 Pod 都配置了 Pod 间亲和性,也不会出现调度死锁的情况。
Pod 亲和性示例
考虑下面的 Pod 规约:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:2.0
本示例定义了一条 Pod 亲和性规则和一条 Pod 反亲和性规则。Pod 亲和性规则配置为
requiredDuringSchedulingIgnoredDuringExecution,而 Pod 反亲和性配置为
preferredDuringSchedulingIgnoredDuringExecution。
亲和性规则规定,只有节点属于特定的区域
且该区域中的其他 Pod 已打上 security=S1 标签时,调度器才可以将示例 Pod 调度到此节点上。
例如,如果我们有一个具有指定区域(称之为 "Zone V")的集群,此区域由带有 topology.kubernetes.io/zone=V
标签的节点组成,那么只要 Zone V 内已经至少有一个 Pod 打了 security=S1 标签,
调度器就可以将此 Pod 调度到 Zone V 内的任何节点。相反,如果 Zone V 中没有带有 security=S1 标签的 Pod,
则调度器不会将示例 Pod 调度给该区域中的任何节点。
反亲和性规则规定,如果节点属于特定的区域
且该区域中的其他 Pod 已打上 security=S2 标签,则调度器应尝试避免将 Pod 调度到此节点上。
例如,如果我们有一个具有指定区域(我们称之为 "Zone R")的集群,此区域由带有 topology.kubernetes.io/zone=R
标签的节点组成,只要 Zone R 内已经至少有一个 Pod 打了 security=S2 标签,
调度器应避免将 Pod 分配给 Zone R 内的任何节点。相反,如果 Zone R 中没有带有 security=S2 标签的 Pod,
则反亲和性规则不会影响将 Pod 调度到 Zone R。
查阅设计文档 以进一步熟悉 Pod 亲和性与反亲和性的示例。
你可以针对 Pod 间亲和性与反亲和性为其 operator 字段使用 In、NotIn、Exists、
DoesNotExist 等值。
阅读操作符了解有关这些操作的更多信息。
原则上,topologyKey 可以是任何合法的标签键。出于性能和安全原因,topologyKey
有一些限制:
- 对于 Pod 亲和性而言,在
requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution中,topologyKey不允许为空。 - 对于
requiredDuringSchedulingIgnoredDuringExecution要求的 Pod 反亲和性, 准入控制器LimitPodHardAntiAffinityTopology要求topologyKey只能是kubernetes.io/hostname。如果你希望使用其他定制拓扑逻辑, 你可以更改准入控制器或者禁用之。
除了 labelSelector 和 topologyKey,你也可以指定 labelSelector
要匹配的名字空间列表,方法是在 labelSelector 和 topologyKey
所在层同一层次上设置 namespaces。
如果 namespaces 被忽略或者为空,则默认为 Pod 亲和性/反亲和性的定义所在的名字空间。
名字空间选择算符
特性状态:
Kubernetes v1.24 [stable]
用户也可以使用 namespaceSelector 选择匹配的名字空间,namespaceSelector
是对名字空间集合进行标签查询的机制。
亲和性条件会应用到 namespaceSelector 所选择的名字空间和 namespaces 字段中所列举的名字空间之上。
注意,空的 namespaceSelector({})会匹配所有名字空间,而 null 或者空的
namespaces 列表以及 null 值 namespaceSelector 意味着“当前 Pod 的名字空间”。
matchLabelKeys
特性状态:
Kubernetes v1.29 [alpha]
说明:
matchLabelKeys 字段是一个 Alpha 级别的字段,在 Kubernetes 1.29 中默认被禁用。
当你想要使用此字段时,你必须通过 MatchLabelKeysInPodAffinity
特性门控启用它。
Kubernetes 在 Pod 亲和性或反亲和性中包含一个可选的 matchLabelKeys 字段。
此字段指定了应与传入 Pod 的标签匹配的标签键,以满足 Pod 的(反)亲和性。
这些键用于从 Pod 的标签中查找值;这些键值标签与使用 labelSelector 字段定义的匹配限制组合(使用 AND 操作)。
这种组合的过滤机制选择将用于 Pod(反)亲和性计算的现有 Pod 集合。
一个常见的用例是在 matchLabelKeys 中使用 pod-template-hash
(设置在作为 Deployment 的一部分进行管理的 Pod 上,其中每个版本的值是唯一的)。
在 matchLabelKeys 中使用 pod-template-hash 允许你定位与传入 Pod 相同版本的 Pod,
确保滚动升级不会破坏亲和性。
apiVersion: apps/v1
kind: Deployment
metadata:
name: application-server
...
spec:
template:
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- database
topologyKey: topology.kubernetes.io/zone
# 只有在计算 Pod 亲和性时,才考虑指定上线的 Pod。
# 如果你更新 Deployment,替代的 Pod 将遵循它们自己的亲和性规则
# (如果在新的 Pod 模板中定义了任何规则)。
matchLabelKeys:
- pod-template-hash
mismatchLabelKeys
特性状态:
Kubernetes v1.29 [alpha]
说明:
mismatchLabelKeys 字段是一个 Alpha 级别的字段,在 Kubernetes 1.29 中默认被禁用。
当你想要使用此字段时,你必须通过 MatchLabelKeysInPodAffinity
特性门控启用它。
Kubernetes 为 Pod 亲和性或反亲和性提供了一个可选的 mismatchLabelKeys 字段。
此字段指定了在满足 Pod(反)亲和性时,不应与传入 Pod 的标签匹配的键。
一个示例用例是确保 Pod 进入指定的拓扑域(节点、区域等),在此拓扑域中只调度来自同一租户或团队的 Pod。 换句话说,你想要避免在同一拓扑域中同时运行来自两个不同租户的 Pod。
apiVersion: v1
kind: Pod
metadata:
labels:
# 假设所有相关的 Pod 都设置了 “tenant” 标签
tenant: tenant-a
...
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# 确保与此租户关联的 Pod 落在正确的节点池上
- matchLabelKeys:
- tenant
topologyKey: node-pool
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
# 确保与此租户关联的 Pod 不能调度到用于其他租户的节点上
- mismatchLabelKeys:
- tenant # 无论此 Pod 的 “tenant” 标签的值是什么,
# 如果节点池中有来自别的租户的任何 Pod 在运行,
# 都会阻碍此 Pod 被调度到这些节点池中的节点上
labelSelector:
# 我们必须有一个 labelSelector,只选择具有 “tenant” 标签的 Pod,
# 否则此 Pod 也会与来自 DaemonSet 的 Pod 发生冲突,
# 而这些 Pod 不应该具有 “tenant” 标签
matchExpressions:
- key: tenant
operator: Exists
topologyKey: node-pool
更实际的用例
Pod 间亲和性与反亲和性在与更高级别的集合(例如 ReplicaSet、StatefulSet、 Deployment 等)一起使用时,它们可能更加有用。 这些规则使得你可以配置一组工作负载,使其位于所定义的同一拓扑中; 例如优先将两个相关的 Pod 置于相同的节点上。
以一个三节点的集群为例。你使用该集群运行一个带有内存缓存(例如 Redis)的 Web 应用程序。 在此例中,还假设 Web 应用程序和内存缓存之间的延迟应尽可能低。 你可以使用 Pod 间的亲和性和反亲和性来尽可能地将该 Web 服务器与缓存并置。
在下面的 Redis 缓存 Deployment 示例中,副本上设置了标签 app=store。
podAntiAffinity 规则告诉调度器避免将多个带有 app=store 标签的副本部署到同一节点上。
因此,每个独立节点上会创建一个缓存实例。
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
下例的 Deployment 为 Web 服务器创建带有标签 app=web-store 的副本。
Pod 亲和性规则告诉调度器将每个副本放到存在标签为 app=store 的 Pod 的节点上。
Pod 反亲和性规则告诉调度器决不要在单个节点上放置多个 app=web-store 服务器。
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
创建前面两个 Deployment 会产生如下的集群布局,每个 Web 服务器与一个缓存实例并置, 并分别运行在三个独立的节点上。
| node-1 | node-2 | node-3 |
|---|---|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
总体效果是每个缓存实例都非常可能被在同一个节点上运行的某个客户端访问, 这种方法旨在最大限度地减少偏差(负载不平衡)和延迟。
你可能还有使用 Pod 反亲和性的一些其他原因。 参阅 ZooKeeper 教程 了解一个 StatefulSet 的示例,该 StatefulSet 配置了反亲和性以实现高可用, 所使用的是与此例相同的技术。
nodeName
nodeName 是比亲和性或者 nodeSelector 更为直接的形式。nodeName 是 Pod
规约中的一个字段。如果 nodeName 字段不为空,调度器会忽略该 Pod,
而指定节点上的 kubelet 会尝试将 Pod 放到该节点上。
使用 nodeName 规则的优先级会高于使用 nodeSelector 或亲和性与非亲和性的规则。
使用 nodeName 来选择节点的方式有一些局限性:
- 如果所指代的节点不存在,则 Pod 无法运行,而且在某些情况下可能会被自动删除。
- 如果所指代的节点无法提供用来运行 Pod 所需的资源,Pod 会失败, 而其失败原因中会给出是否因为内存或 CPU 不足而造成无法运行。
- 在云环境中的节点名称并不总是可预测的,也不总是稳定的。
说明:
nodeName 旨在供自定义调度器或需要绕过任何已配置调度器的高级场景使用。
如果已分配的 Node 负载过重,绕过调度器可能会导致 Pod 失败。
你可以使用节点亲和性或 nodeselector 字段将
Pod 分配给特定 Node,而无需绕过调度器。
下面是一个使用 nodeName 字段的 Pod 规约示例:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
上面的 Pod 只能运行在节点 kube-01 之上。
Pod 拓扑分布约束
你可以使用 拓扑分布约束(Topology Spread Constraints) 来控制 Pod 在集群内故障域之间的分布, 故障域的示例有区域(Region)、可用区(Zone)、节点和其他用户自定义的拓扑域。 这样做有助于提升性能、实现高可用或提升资源利用率。
阅读 Pod 拓扑分布约束 以进一步了解这些约束的工作方式。
操作符
下面是你可以在上述 nodeAffinity 和 podAffinity 的 operator
字段中可以使用的所有逻辑运算符。
| 操作符 | 行为 |
|---|---|
In |
标签值存在于提供的字符串集中 |
NotIn |
标签值不包含在提供的字符串集中 |
Exists |
对象上存在具有此键的标签 |
DoesNotExist |
对象上不存在具有此键的标签 |
以下操作符只能与 nodeAffinity 一起使用。
| 操作符 | 行为 |
|---|---|
Gt |
提供的值将被解析为整数,并且该整数小于通过解析此选择算符命名的标签的值所得到的整数 |
Lt |
提供的值将被解析为整数,并且该整数大于通过解析此选择算符命名的标签的值所得到的整数 |
说明:
Gt 和 Lt 操作符不能与非整数值一起使用。
如果给定的值未解析为整数,则该 Pod 将无法被调度。
另外,Gt 和 Lt 不适用于 podAffinity。
接下来
- 进一步阅读污点与容忍度文档。
- 阅读节点亲和性 和 Pod 间亲和性与反亲和性 的设计文档。
- 了解拓扑管理器如何参与节点层面资源分配决定。
- 了解如何使用 nodeSelector。
- 了解如何使用亲和性和反亲和性。
10.3 - Pod 开销
特性状态:
Kubernetes v1.24 [stable]
在节点上运行 Pod 时,Pod 本身占用大量系统资源。这些是运行 Pod 内容器所需资源之外的资源。 在 Kubernetes 中,POD 开销 是一种方法,用于计算 Pod 基础设施在容器请求和限制之上消耗的资源。
在 Kubernetes 中,Pod 的开销是根据与 Pod 的 RuntimeClass 相关联的开销在准入时设置的。
在调度 Pod 时,除了考虑容器资源请求的总和外,还要考虑 Pod 开销。 类似地,kubelet 将在确定 Pod cgroups 的大小和执行 Pod 驱逐排序时也会考虑 Pod 开销。
配置 Pod 开销
你需要确保使用一个定义了 overhead 字段的 RuntimeClass。
使用示例
要使用 Pod 开销,你需要一个定义了 overhead 字段的 RuntimeClass。
作为例子,下面的 RuntimeClass 定义中包含一个虚拟化所用的容器运行时,
RuntimeClass 如下,其中每个 Pod 大约使用 120MiB 用来运行虚拟机和寄宿操作系统:
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: kata-fc
handler: kata-fc
overhead:
podFixed:
memory: "120Mi"
cpu: "250m"
通过指定 kata-fc RuntimeClass 处理程序创建的工作负载会将内存和 CPU
开销计入资源配额计算、节点调度以及 Pod cgroup 尺寸确定。
假设我们运行下面给出的工作负载示例 test-pod:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
runtimeClassName: kata-fc
containers:
- name: busybox-ctr
image: busybox:1.28
stdin: true
tty: true
resources:
limits:
cpu: 500m
memory: 100Mi
- name: nginx-ctr
image: nginx
resources:
limits:
cpu: 1500m
memory: 100Mi
在准入阶段 RuntimeClass 准入控制器
更新工作负载的 PodSpec 以包含
RuntimeClass 中定义的 overhead。如果 PodSpec 中已定义该字段,该 Pod 将会被拒绝。
在这个例子中,由于只指定了 RuntimeClass 名称,所以准入控制器更新了 Pod,使之包含 overhead。
在 RuntimeClass 准入控制器进行修改后,你可以查看更新后的 Pod 开销值:
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
输出:
map[cpu:250m memory:120Mi]
如果定义了 ResourceQuota,
则容器请求的总量以及 overhead 字段都将计算在内。
当 kube-scheduler 决定在哪一个节点调度运行新的 Pod 时,调度器会兼顾该 Pod 的
overhead 以及该 Pod 的容器请求总量。在这个示例中,调度器将资源请求和开销相加,
然后寻找具备 2.25 CPU 和 320 MiB 内存可用的节点。
一旦 Pod 被调度到了某个节点, 该节点上的 kubelet 将为该 Pod 新建一个 cgroup。 底层容器运行时将在这个 Pod 中创建容器。
如果该资源对每一个容器都定义了一个限制(定义了限制值的 Guaranteed QoS 或者
Burstable QoS),kubelet 会为与该资源(CPU 的 cpu.cfs_quota_us 以及内存的
memory.limit_in_bytes)
相关的 Pod cgroup 设定一个上限。该上限基于 PodSpec 中定义的容器限制总量与 overhead 之和。
对于 CPU,如果 Pod 的 QoS 是 Guaranteed 或者 Burstable,kubelet 会基于容器请求总量与
PodSpec 中定义的 overhead 之和设置 cpu.shares。
请看这个例子,验证工作负载的容器请求:
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
容器请求总计 2000m CPU 和 200MiB 内存:
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
对照从节点观察到的情况来检查一下:
kubectl describe node | grep test-pod -B2
该输出显示请求了 2250m CPU 以及 320MiB 内存。请求包含了 Pod 开销在内:
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
验证 Pod cgroup 限制
在工作负载所运行的节点上检查 Pod 的内存 cgroups。在接下来的例子中,
将在该节点上使用具备 CRI 兼容的容器运行时命令行工具
crictl。
这是一个显示 Pod 开销行为的高级示例, 预计用户不需要直接在节点上检查 cgroups。
首先在特定的节点上确定该 Pod 的标识符:
# 在该 Pod 被调度到的节点上执行如下命令:
POD_ID="$(sudo crictl pods --name test-pod -q)"
可以依此判断该 Pod 的 cgroup 路径:
# 在该 Pod 被调度到的节点上执行如下命令:
sudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
执行结果的 cgroup 路径中包含了该 Pod 的 pause 容器。Pod 级别的 cgroup 在即上一层目录。
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
在这个例子中,该 Pod 的 cgroup 路径是 kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2。
验证内存的 Pod 级别 cgroup 设置:
# 在该 Pod 被调度到的节点上执行这个命令。
# 另外,修改 cgroup 的名称以匹配为该 Pod 分配的 cgroup。
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
和预期的一样,这一数值为 320 MiB。
335544320
可观察性
在 kube-state-metrics 中可以通过
kube_pod_overhead_* 指标来协助确定何时使用 Pod 开销,
以及协助观察以一个既定开销运行的工作负载的稳定性。
该特性在 kube-state-metrics 的 1.9 发行版本中不可用,不过预计将在后续版本中发布。
在此之前,用户需要从源代码构建 kube-state-metrics。
接下来
- 学习更多关于 RuntimeClass 的信息
- 阅读 PodOverhead 设计增强建议以获取更多上下文
10.4 - Pod 调度就绪态
特性状态:
Kubernetes v1.27 [beta]
Pod 一旦创建就被认为准备好进行调度。 Kubernetes 调度程序尽职尽责地寻找节点来放置所有待处理的 Pod。 然而,在实际环境中,会有一些 Pod 可能会长时间处于"缺少必要资源"状态。 这些 Pod 实际上以一种不必要的方式扰乱了调度器(以及 Cluster AutoScaler 这类下游的集成方)。
通过指定或删除 Pod 的 .spec.schedulingGates,可以控制 Pod 何时准备好被纳入考量进行调度。
配置 Pod schedulingGates
schedulingGates 字段包含一个字符串列表,每个字符串文字都被视为 Pod 在被认为可调度之前应该满足的标准。
该字段只能在创建 Pod 时初始化(由客户端创建,或在准入期间更改)。
创建后,每个 schedulingGate 可以按任意顺序删除,但不允许添加新的调度门控。

图:Pod SchedulingGates
用法示例
要将 Pod 标记为未准备好进行调度,你可以在创建 Pod 时附带一个或多个调度门控,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
schedulingGates:
- name: foo
- name: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.6
Pod 创建后,你可以使用以下方法检查其状态:
kubectl get pod test-pod
输出显示它处于 SchedulingGated 状态:
NAME READY STATUS RESTARTS AGE
test-pod 0/1 SchedulingGated 0 7s
你还可以通过运行以下命令检查其 schedulingGates 字段:
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
输出是:
[{"name":"example.com/foo"},{"name":"example.com/bar"}]
要通知调度程序此 Pod 已准备好进行调度,你可以通过重新应用修改后的清单来完全删除其 schedulingGates:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: pause
image: registry.k8s.io/pause:3.6
你可以通过运行以下命令检查 schedulingGates 是否已被清空:
kubectl get pod test-pod -o jsonpath='{.spec.schedulingGates}'
预计输出为空,你可以通过运行下面的命令来检查它的最新状态:
kubectl get pod test-pod -o wide
鉴于 test-pod 不请求任何 CPU/内存资源,预计此 Pod 的状态会从之前的
SchedulingGated 转变为 Running:
NAME READY STATUS RESTARTS AGE IP NODE
test-pod 1/1 Running 0 15s 10.0.0.4 node-2
可观测性
指标 scheduler_pending_pods 带有一个新标签 "gated",
以区分 Pod 是否已尝试调度但被宣称不可调度,或明确标记为未准备好调度。
你可以使用 scheduler_pending_pods{queue="gated"} 来检查指标结果。
可变 Pod 调度指令
特性状态:
Kubernetes v1.27 [beta]
当 Pod 具有调度门控时,你可以在某些约束条件下改变 Pod 的调度指令。 在高层次上,你只能收紧 Pod 的调度指令。换句话说,更新后的指令将导致 Pod 只能被调度到它之前匹配的节点子集上。 更具体地说,更新 Pod 的调度指令的规则如下:
-
对于
.spec.nodeSelector,只允许增加。如果原来未设置,则允许设置此字段。 -
对于
spec.affinity.nodeAffinity,如果当前值为 nil,则允许设置为任意值。
- 如果
NodeSelectorTerms之前为空,则允许设置该字段。 如果之前不为空,则仅允许增加NodeSelectorRequirements到matchExpressions或fieldExpressions,且不允许更改当前的matchExpressions和fieldExpressions。 这是因为.requiredDuringSchedulingIgnoredDuringExecution.NodeSelectorTerms中的条目被执行逻辑或运算,而nodeSelectorTerms[].matchExpressions和nodeSelectorTerms[].fieldExpressions中的表达式被执行逻辑与运算。
- 对于
.preferredDuringSchedulingIgnoredDuringExecution,所有更新都被允许。 这是因为首选条目不具有权威性,因此策略控制器不会验证这些条目。
接下来
- 阅读 PodSchedulingReadiness KEP 了解更多详情
10.5 - Pod 拓扑分布约束
你可以使用 拓扑分布约束(Topology Spread Constraints) 来控制 Pod 在集群内故障域之间的分布, 例如区域(Region)、可用区(Zone)、节点和其他用户自定义拓扑域。 这样做有助于实现高可用并提升资源利用率。
你可以将集群级约束设为默认值,或为个别工作负载配置拓扑分布约束。
动机
假设你有一个最多包含二十个节点的集群,你想要运行一个自动扩缩的 工作负载,请问要使用多少个副本? 答案可能是最少 2 个 Pod,最多 15 个 Pod。 当只有 2 个 Pod 时,你倾向于这 2 个 Pod 不要同时在同一个节点上运行: 你所遭遇的风险是如果放在同一个节点上且单节点出现故障,可能会让你的工作负载下线。
除了这个基本的用法之外,还有一些高级的使用案例,能够让你的工作负载受益于高可用性并提高集群利用率。
随着你的工作负载扩容,运行的 Pod 变多,将需要考虑另一个重要问题。 假设你有 3 个节点,每个节点运行 5 个 Pod。这些节点有足够的容量能够运行许多副本; 但与这个工作负载互动的客户端分散在三个不同的数据中心(或基础设施可用区)。 现在你可能不太关注单节点故障问题,但你会注意到延迟高于自己的预期, 在不同的可用区之间发送网络流量会产生一些网络成本。
你决定在正常运营时倾向于将类似数量的副本调度 到每个基础设施可用区,且你想要该集群在遇到问题时能够自愈。
Pod 拓扑分布约束使你能够以声明的方式进行配置。
topologySpreadConstraints 字段
Pod API 包括一个 spec.topologySpreadConstraints 字段。这个字段的用法如下所示:
---
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# 配置一个拓扑分布约束
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # 可选;自从 v1.25 开始成为 Beta
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # 可选;自从 v1.27 开始成为 Beta
nodeAffinityPolicy: [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
nodeTaintsPolicy: [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
### 其他 Pod 字段置于此处
你可以运行 kubectl explain Pod.spec.topologySpreadConstraints 或参阅 Pod API
参考的调度一节,
了解有关此字段的更多信息。
分布约束定义
你可以定义一个或多个 topologySpreadConstraints 条目以指导 kube-scheduler
如何将每个新来的 Pod 与跨集群的现有 Pod 相关联。这些字段包括:
-
maxSkew 描述这些 Pod 可能被不均匀分布的程度。你必须指定此字段且该数值必须大于零。 其语义将随着
whenUnsatisfiable的值发生变化:- 如果你选择
whenUnsatisfiable: DoNotSchedule,则maxSkew定义目标拓扑中匹配 Pod 的数量与全局最小值(符合条件的域中匹配的最小 Pod 数量,如果符合条件的域数量小于 MinDomains 则为零) 之间的最大允许差值。例如,如果你有 3 个可用区,分别有 2、2 和 1 个匹配的 Pod,则MaxSkew设为 1, 且全局最小值为 1。 - 如果你选择
whenUnsatisfiable: ScheduleAnyway,则该调度器会更为偏向能够降低偏差值的拓扑域。
- 如果你选择
-
minDomains 表示符合条件的域的最小数量。此字段是可选的。域是拓扑的一个特定实例。 符合条件的域是其节点与节点选择器匹配的域。
说明:MinDomainsInPodTopologySpread特性门控为 Pod 拓扑分布启用minDomains。自 v1.28 起,MinDomainsInPodTopologySpread特性门控默认被启用。 在早期的 Kubernetes 集群中,此特性门控可能被显式禁用或此字段可能不可用。- 指定的
minDomains值必须大于 0。你可以结合whenUnsatisfiable: DoNotSchedule仅指定minDomains。 - 当符合条件的、拓扑键匹配的域的数量小于
minDomains时,拓扑分布将“全局最小值”(global minimum)设为 0, 然后进行skew计算。“全局最小值”是一个符合条件的域中匹配 Pod 的最小数量, 如果符合条件的域的数量小于minDomains,则全局最小值为零。 - 当符合条件的拓扑键匹配域的个数等于或大于
minDomains时,该值对调度没有影响。 - 如果你未指定
minDomains,则约束行为类似于minDomains等于 1。
- 指定的
-
topologyKey 是节点标签的键。如果节点使用此键标记并且具有相同的标签值, 则将这些节点视为处于同一拓扑域中。我们将拓扑域中(即键值对)的每个实例称为一个域。 调度器将尝试在每个拓扑域中放置数量均衡的 Pod。 另外,我们将符合条件的域定义为其节点满足 nodeAffinityPolicy 和 nodeTaintsPolicy 要求的域。
-
whenUnsatisfiable 指示如果 Pod 不满足分布约束时如何处理:
DoNotSchedule(默认)告诉调度器不要调度。ScheduleAnyway告诉调度器仍然继续调度,只是根据如何能将偏差最小化来对节点进行排序。
-
labelSelector 用于查找匹配的 Pod。匹配此标签的 Pod 将被统计,以确定相应拓扑域中 Pod 的数量。 有关详细信息,请参考标签选择算符。
-
matchLabelKeys 是一个 Pod 标签键的列表,用于选择需要计算分布方式的 Pod 集合。 这些键用于从 Pod 标签中查找值,这些键值标签与
labelSelector进行逻辑与运算,以选择一组已有的 Pod, 通过这些 Pod 计算新来 Pod 的分布方式。matchLabelKeys和labelSelector中禁止存在相同的键。 未设置labelSelector时无法设置matchLabelKeys。Pod 标签中不存在的键将被忽略。 null 或空列表意味着仅与labelSelector匹配。借助
matchLabelKeys,你无需在变更 Pod 修订版本时更新pod.spec。 控制器或 Operator 只需要将不同修订版的标签键设为不同的值。 调度器将根据matchLabelKeys自动确定取值。例如,如果你正在配置一个 Deployment, 则你可以使用由 Deployment 控制器自动添加的、以 pod-template-hash 为键的标签来区分同一个 Deployment 的不同修订版。topologySpreadConstraints: - maxSkew: 1 topologyKey: kubernetes.io/hostname whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app: foo matchLabelKeys: - pod-template-hash说明:matchLabelKeys字段是 1.27 中默认启用的一个 Beta 级别字段。 你可以通过禁用MatchLabelKeysInPodTopologySpread特性门控来禁用此字段。
-
nodeAffinityPolicy 表示我们在计算 Pod 拓扑分布偏差时将如何处理 Pod 的 nodeAffinity/nodeSelector。 选项为:
- Honor:只有与 nodeAffinity/nodeSelector 匹配的节点才会包括到计算中。
- Ignore:nodeAffinity/nodeSelector 被忽略。所有节点均包括到计算中。
如果此值为 nil,此行为等同于 Honor 策略。
说明:nodeAffinityPolicy是 1.26 中默认启用的一个 Beta 级别字段。 你可以通过禁用NodeInclusionPolicyInPodTopologySpread特性门控来禁用此字段。
-
nodeTaintsPolicy 表示我们在计算 Pod 拓扑分布偏差时将如何处理节点污点。选项为:
- Honor:包括不带污点的节点以及污点被新 Pod 所容忍的节点。
- Ignore:节点污点被忽略。包括所有节点。
如果此值为 null,此行为等同于 Ignore 策略。
说明:nodeTaintsPolicy是一个 Beta 级别字段,在 1.26 版本默认启用。 你可以通过禁用NodeInclusionPolicyInPodTopologySpread特性门控来禁用此字段。
当 Pod 定义了不止一个 topologySpreadConstraint,这些约束之间是逻辑与的关系。
kube-scheduler 会为新的 Pod 寻找一个能够满足所有约束的节点。
节点标签
拓扑分布约束依赖于节点标签来标识每个节点所在的拓扑域。 例如,某节点可能具有标签:
region: us-east-1
zone: us-east-1a
说明:
为了简便,此示例未使用众所周知的标签键
topology.kubernetes.io/zone 和 topology.kubernetes.io/region。
但是,建议使用那些已注册的标签键,而不是此处使用的私有(不合格)标签键 region 和 zone。
你无法对不同上下文之间的私有标签键的含义做出可靠的假设。
假设你有一个 4 节点的集群且带有以下标签:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB
那么,从逻辑上看集群如下:
graph TB
subgraph "zoneB"
n3(Node3)
n4(Node4)
end
subgraph "zoneA"
n1(Node1)
n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4 k8s;
class zoneA,zoneB cluster;
一致性
你应该为一个组中的所有 Pod 设置相同的 Pod 拓扑分布约束。
通常,如果你正使用一个工作负载控制器,例如 Deployment,则 Pod 模板会帮你解决这个问题。 如果你混合不同的分布约束,则 Kubernetes 会遵循该字段的 API 定义; 但是,该行为可能更令人困惑,并且故障排除也没那么简单。
你需要一种机制来确保拓扑域(例如云提供商区域)中的所有节点具有一致的标签。
为了避免你需要手动为节点打标签,大多数集群会自动填充知名的标签,
例如 kubernetes.io/hostname。检查你的集群是否支持此功能。
拓扑分布约束示例
示例:一个拓扑分布约束
假设你拥有一个 4 节点集群,其中标记为 foo: bar 的 3 个 Pod 分别位于 node1、node2 和 node3 中:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class zoneA,zoneB cluster;
如果你希望新来的 Pod 均匀分布在现有的可用区域,则可以按如下设置其清单:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1从此清单看,topologyKey: zone 意味着均匀分布将只应用于存在标签键值对为 zone: <any value> 的节点
(没有 zone 标签的节点将被跳过)。如果调度器找不到一种方式来满足此约束,
则 whenUnsatisfiable: DoNotSchedule 字段告诉该调度器将新来的 Pod 保持在 pending 状态。
如果该调度器将这个新来的 Pod 放到可用区 A,则 Pod 的分布将成为 [3, 1]。
这意味着实际偏差是 2(计算公式为 3 - 1),这违反了 maxSkew: 1 的约定。
为了满足这个示例的约束和上下文,新来的 Pod 只能放到可用区 B 中的一个节点上:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
或者
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
p4(mypod) --> n3
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
你可以调整 Pod 规约以满足各种要求:
- 将
maxSkew更改为更大的值,例如2,这样新来的 Pod 也可以放在可用区A中。 - 将
topologyKey更改为node,以便将 Pod 均匀分布在节点上而不是可用区中。 在上面的例子中,如果maxSkew保持为1,则新来的 Pod 只能放到node4节点上。 - 将
whenUnsatisfiable: DoNotSchedule更改为whenUnsatisfiable: ScheduleAnyway, 以确保新来的 Pod 始终可以被调度(假设满足其他的调度 API)。但是,最好将其放置在匹配 Pod 数量较少的拓扑域中。 请注意,这一优先判定会与其他内部调度优先级(如资源使用率等)排序准则一起进行标准化。
示例:多个拓扑分布约束
下面的例子建立在前面例子的基础上。假设你拥有一个 4 节点集群,
其中 3 个标记为 foo: bar 的 Pod 分别位于 node1、node2 和 node3 上:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
可以组合使用 2 个拓扑分布约束来控制 Pod 在节点和可用区两个维度上的分布:
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1在这种情况下,为了匹配第一个约束,新的 Pod 只能放置在可用区 B 中;
而在第二个约束中,新来的 Pod 只能调度到节点 node4 上。
该调度器仅考虑满足所有已定义约束的选项,因此唯一可行的选择是放置在节点 node4 上。
示例:有冲突的拓扑分布约束
多个约束可能导致冲突。假设有一个跨 2 个可用区的 3 节点集群:
graph BT
subgraph "zoneB"
p4(Pod) --> n3(Node3)
p5(Pod) --> n3
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n1
p3(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3,p4,p5 k8s;
class zoneA,zoneB cluster;
如果你将 two-constraints.yaml
(来自上一个示例的清单)应用到这个集群,你将看到 Pod mypod 保持在 Pending 状态。
出现这种情况的原因为:为了满足第一个约束,Pod mypod 只能放置在可用区 B 中;
而在第二个约束中,Pod mypod 只能调度到节点 node2 上。
两个约束的交集将返回一个空集,且调度器无法放置该 Pod。
为了应对这种情形,你可以提高 maxSkew 的值或修改其中一个约束才能使用 whenUnsatisfiable: ScheduleAnyway。
根据实际情形,例如若你在故障排查时发现某个漏洞修复工作毫无进展,你还可能决定手动删除一个现有的 Pod。
与节点亲和性和节点选择算符的相互作用
如果 Pod 定义了 spec.nodeSelector 或 spec.affinity.nodeAffinity,
调度器将在偏差计算中跳过不匹配的节点。
示例:带节点亲和性的拓扑分布约束
假设你有一个跨可用区 A 到 C 的 5 节点集群:
graph BT
subgraph "zoneB"
p3(Pod) --> n3(Node3)
n4(Node4)
end
subgraph "zoneA"
p1(Pod) --> n1(Node1)
p2(Pod) --> n2(Node2)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n1,n2,n3,n4,p1,p2,p3 k8s;
class p4 plain;
class zoneA,zoneB cluster;
graph BT
subgraph "zoneC"
n5(Node5)
end
classDef plain fill:#ddd,stroke:#fff,stroke-width:4px,color:#000;
classDef k8s fill:#326ce5,stroke:#fff,stroke-width:4px,color:#fff;
classDef cluster fill:#fff,stroke:#bbb,stroke-width:2px,color:#326ce5;
class n5 k8s;
class zoneC cluster;
而且你知道可用区 C 必须被排除在外。在这种情况下,可以按如下方式编写清单,
以便将 Pod mypod 放置在可用区 B 上,而不是可用区 C 上。
同样,Kubernetes 也会一样处理 spec.nodeSelector。
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: NotIn
values:
- zoneC
containers:
- name: pause
image: registry.k8s.io/pause:3.1隐式约定
这里有一些值得注意的隐式约定:
-
只有与新来的 Pod 具有相同命名空间的 Pod 才能作为匹配候选者。
-
调度器会忽略没有任何
topologySpreadConstraints[*].topologyKey的节点。这意味着:- 位于这些节点上的 Pod 不影响
maxSkew计算,在上面的例子中, 假设节点node1没有标签 "zone",则 2 个 Pod 将被忽略,因此新来的 Pod 将被调度到可用区A中。 - 新的 Pod 没有机会被调度到这类节点上。在上面的例子中,
假设节点
node5带有拼写错误的标签zone-typo: zoneC(且没有设置zone标签)。 节点node5接入集群之后,该节点将被忽略且针对该工作负载的 Pod 不会被调度到那里。
- 位于这些节点上的 Pod 不影响
- 注意,如果新 Pod 的
topologySpreadConstraints[*].labelSelector与自身的标签不匹配,将会发生什么。 在上面的例子中,如果移除新 Pod 的标签,则 Pod 仍然可以放置到可用区B中的节点上,因为这些约束仍然满足。 然而,在放置之后,集群的不平衡程度保持不变。可用区A仍然有 2 个 Pod 带有标签foo: bar, 而可用区B有 1 个 Pod 带有标签foo: bar。如果这不是你所期望的, 更新工作负载的topologySpreadConstraints[*].labelSelector以匹配 Pod 模板中的标签。
集群级别的默认约束
为集群设置默认的拓扑分布约束也是可能的。默认拓扑分布约束在且仅在以下条件满足时才会被应用到 Pod 上:
- Pod 没有在其
.spec.topologySpreadConstraints中定义任何约束。 - Pod 隶属于某个 Service、ReplicaSet、StatefulSet 或 ReplicationController。
默认约束可以设置为调度方案中
PodTopologySpread 插件参数的一部分。约束的设置采用如前所述的 API,
只是 labelSelector 必须为空。
选择算符是根据 Pod 所属的 Service、ReplicaSet、StatefulSet 或 ReplicationController 来设置的。
配置的示例可能看起来像下面这个样子:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
内置默认约束
特性状态:
Kubernetes v1.24 [stable]
如果你没有为 Pod 拓扑分布配置任何集群级别的默认约束, kube-scheduler 的行为就像你指定了以下默认拓扑约束一样:
defaultConstraints:
- maxSkew: 3
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: ScheduleAnyway
- maxSkew: 5
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: ScheduleAnyway
此外,原来用于提供等同行为的 SelectorSpread 插件默认被禁用。
说明:
对于分布约束中所指定的拓扑键而言,PodTopologySpread 插件不会为不包含这些拓扑键的节点评分。
这可能导致在使用默认拓扑约束时,其行为与原来的 SelectorSpread 插件的默认行为不同。
如果你的节点不会同时设置 kubernetes.io/hostname 和 topology.kubernetes.io/zone 标签,
你应该定义自己的约束而不是使用 Kubernetes 的默认约束。
如果你不想为集群使用默认的 Pod 分布约束,你可以通过设置 defaultingType 参数为 List,
并将 PodTopologySpread 插件配置中的 defaultConstraints 参数置空来禁用默认 Pod 分布约束:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints: []
defaultingType: List
比较 podAffinity 和 podAntiAffinity
在 Kubernetes 中, Pod 间亲和性和反亲和性控制 Pod 彼此的调度方式(更密集或更分散)。
podAffinity- 吸引 Pod;你可以尝试将任意数量的 Pod 集中到符合条件的拓扑域中。
podAntiAffinity- 驱逐 Pod。如果将此设为
requiredDuringSchedulingIgnoredDuringExecution模式, 则只有单个 Pod 可以调度到单个拓扑域;如果你选择preferredDuringSchedulingIgnoredDuringExecution, 则你将丢失强制执行此约束的能力。
要实现更细粒度的控制,你可以设置拓扑分布约束来将 Pod 分布到不同的拓扑域下,从而实现高可用性或节省成本。 这也有助于工作负载的滚动更新和平稳地扩展副本规模。
有关详细信息,请参阅有关 Pod 拓扑分布约束的增强倡议的 动机一节。
已知局限性
-
当 Pod 被移除时,无法保证约束仍被满足。例如,缩减某 Deployment 的规模时,Pod 的分布可能不再均衡。
你可以使用 Descheduler 来重新实现 Pod 分布的均衡。
-
具有污点的节点上匹配的 Pod 也会被统计。 参考 Issue 80921。
-
该调度器不会预先知道集群拥有的所有可用区和其他拓扑域。 拓扑域由集群中存在的节点确定。在自动扩缩的集群中,如果一个节点池(或节点组)的节点数量缩减为零, 而用户正期望其扩容时,可能会导致调度出现问题。 因为在这种情况下,调度器不会考虑这些拓扑域,直至这些拓扑域中至少包含有一个节点。
你可以通过使用感知 Pod 拓扑分布约束并感知整个拓扑域集的集群自动扩缩工具来解决此问题。
接下来
- 博客:PodTopologySpread 介绍详细解释了
maxSkew, 并给出了一些进阶的使用示例。 - 阅读针对 Pod 的 API 参考的调度一节。
10.6 - 污点和容忍度
节点亲和性 是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点 (这可能出于一种偏好,也可能是硬性要求)。 污点(Taint) 则相反——它使节点能够排斥一类特定的 Pod。
容忍度(Toleration) 是应用于 Pod 上的。容忍度允许调度器调度带有对应污点的 Pod。 容忍度允许调度但并不保证调度:作为其功能的一部分, 调度器也会评估其他参数。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod, 是不会被该节点接受的。
概念
你可以使用命令 kubectl taint 给节点增加一个污点。比如:
kubectl taint nodes node1 key1=value1:NoSchedule
给节点 node1 增加一个污点,它的键名是 key1,键值是 value1,效果是 NoSchedule。
这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到 node1 这个节点。
若要移除上述命令所添加的污点,你可以执行:
kubectl taint nodes node1 key1=value1:NoSchedule-
你可以在 Pod 规约中为 Pod 设置容忍度。
下面两个容忍度均与上面例子中使用 kubectl taint 命令创建的污点相匹配,
因此如果一个 Pod 拥有其中的任何一个容忍度,都能够被调度到 node1:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
这里是一个使用了容忍度的 Pod:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
operator 的默认值是 Equal。
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
- 如果
operator是Exists(此时容忍度不能指定value),或者 - 如果
operator是Equal,则它们的值应该相等。
说明:
存在两种特殊情况:
如果一个容忍度的 key 为空且 operator 为 Exists,
表示这个容忍度与任意的 key、value 和 effect 都匹配,即这个容忍度能容忍任何污点。
如果 effect 为空,则可以与所有键名 key1 的效果相匹配。
上述例子中 effect 使用的值为 NoSchedule,你也可以使用另外一个值 PreferNoSchedule。
effect 字段的允许值包括:
NoExecute- 这会影响已在节点上运行的 Pod,具体影响如下:
- 如果 Pod 不能容忍这类污点,会马上被驱逐。
- 如果 Pod 能够容忍这类污点,但是在容忍度定义中没有指定
tolerationSeconds, 则 Pod 还会一直在这个节点上运行。 - 如果 Pod 能够容忍这类污点,而且指定了
tolerationSeconds, 则 Pod 还能在这个节点上继续运行这个指定的时间长度。 这段时间过去后,节点生命周期控制器从节点驱除这些 Pod。
NoSchedule- 除非具有匹配的容忍度规约,否则新的 Pod 不会被调度到带有污点的节点上。 当前正在节点上运行的 Pod 不会被驱逐。
PreferNoSchedulePreferNoSchedule是“偏好”或“软性”的NoSchedule。 控制平面将尝试避免将不能容忍污点的 Pod 调度到的节点上,但不能保证完全避免。
你可以给一个节点添加多个污点,也可以给一个 Pod 添加多个容忍度设置。 Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历, 过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了 Pod 是否会被分配到该节点。需要注意以下情况:
- 如果未被忽略的污点中存在至少一个 effect 值为
NoSchedule的污点, 则 Kubernetes 不会将 Pod 调度到该节点。 - 如果未被忽略的污点中不存在 effect 值为
NoSchedule的污点, 但是存在至少一个 effect 值为PreferNoSchedule的污点, 则 Kubernetes 会尝试不将 Pod 调度到该节点。 - 如果未被忽略的污点中存在至少一个 effect 值为
NoExecute的污点, 则 Kubernetes 不会将 Pod 调度到该节点(如果 Pod 还未在节点上运行), 并且会将 Pod 从该节点驱逐(如果 Pod 已经在节点上运行)。
例如,假设你给一个节点添加了如下污点:
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
假定某个 Pod 有两个容忍度:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
在这种情况下,上述 Pod 不会被调度到上述节点,因为其没有容忍度和第三个污点相匹配。 但是如果在给节点添加上述污点之前,该 Pod 已经在上述节点运行, 那么它还可以继续运行在该节点上,因为第三个污点是三个污点中唯一不能被这个 Pod 容忍的。
通常情况下,如果给一个节点添加了一个 effect 值为 NoExecute 的污点,
则任何不能容忍这个污点的 Pod 都会马上被驱逐,任何可以容忍这个污点的 Pod 都不会被驱逐。
但是,如果 Pod 存在一个 effect 值为 NoExecute 的容忍度指定了可选属性
tolerationSeconds 的值,则表示在给节点添加了上述污点之后,
Pod 还能继续在节点上运行的时间。例如,
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
这表示如果这个 Pod 正在运行,同时一个匹配的污点被添加到其所在的节点, 那么 Pod 还将继续在节点上运行 3600 秒,然后被驱逐。 如果在此之前上述污点被删除了,则 Pod 不会被驱逐。
使用例子
通过污点和容忍度,可以灵活地让 Pod 避开某些节点或者将 Pod 从某些节点驱逐。 下面是几个使用例子:
- 专用节点:如果想将某些节点专门分配给特定的一组用户使用,你可以给这些节点添加一个污点(即,
kubectl taint nodes nodename dedicated=groupName:NoSchedule), 然后给这组用户的 Pod 添加一个相对应的容忍度 (通过编写一个自定义的准入控制器, 很容易就能做到)。 拥有上述容忍度的 Pod 就能够被调度到上述专用节点,同时也能够被调度到集群中的其它节点。 如果你希望这些 Pod 只能被调度到上述专用节点, 那么你还需要给这些专用节点另外添加一个和上述污点类似的 label(例如:dedicated=groupName), 同时还要在上述准入控制器中给 Pod 增加节点亲和性要求,要求上述 Pod 只能被调度到添加了dedicated=groupName标签的节点上。
- 配备了特殊硬件的节点:在部分节点配备了特殊硬件(比如 GPU)的集群中,
我们希望不需要这类硬件的 Pod 不要被调度到这些特殊节点,以便为后继需要这类硬件的 Pod 保留资源。
要达到这个目的,可以先给配备了特殊硬件的节点添加污点
(例如
kubectl taint nodes nodename special=true:NoSchedule或kubectl taint nodes nodename special=true:PreferNoSchedule), 然后给使用了这类特殊硬件的 Pod 添加一个相匹配的容忍度。 和专用节点的例子类似,添加这个容忍度的最简单的方法是使用自定义 准入控制器。 比如,我们推荐使用扩展资源 来表示特殊硬件,给配置了特殊硬件的节点添加污点时包含扩展资源名称, 然后运行一个 ExtendedResourceToleration 准入控制器。此时,因为节点已经被设置污点了,没有对应容忍度的 Pod 不会被调度到这些节点。 但当你创建一个使用了扩展资源的 Pod 时,ExtendedResourceToleration准入控制器会自动给 Pod 加上正确的容忍度,这样 Pod 就会被自动调度到这些配置了特殊硬件的节点上。 这种方式能够确保配置了特殊硬件的节点专门用于运行需要这些硬件的 Pod, 并且你无需手动给这些 Pod 添加容忍度。
- 基于污点的驱逐:这是在每个 Pod 中配置的在节点出现问题时的驱逐行为, 接下来的章节会描述这个特性。
基于污点的驱逐
特性状态:
Kubernetes v1.18 [stable]
当某种条件为真时,节点控制器会自动给节点添加一个污点。当前内置的污点包括:
node.kubernetes.io/not-ready:节点未准备好。这相当于节点状况Ready的值为 "False"。node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状况Ready的值为 "Unknown"。node.kubernetes.io/memory-pressure:节点存在内存压力。node.kubernetes.io/disk-pressure:节点存在磁盘压力。node.kubernetes.io/pid-pressure:节点的 PID 压力。node.kubernetes.io/network-unavailable:节点网络不可用。node.kubernetes.io/unschedulable:节点不可调度。node.cloudprovider.kubernetes.io/uninitialized:如果 kubelet 启动时指定了一个“外部”云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager 的一个控制器初始化这个节点后,kubelet 将删除这个污点。
在节点被排空时,节点控制器或者 kubelet 会添加带有 NoExecute 效果的相关污点。
此效果被默认添加到 node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 污点中。
如果异常状态恢复正常,kubelet 或节点控制器能够移除相关的污点。
在某些情况下,当节点不可达时,API 服务器无法与节点上的 kubelet 进行通信。 在与 API 服务器的通信被重新建立之前,删除 Pod 的决定无法传递到 kubelet。 同时,被调度进行删除的那些 Pod 可能会继续运行在分区后的节点上。
说明:
控制面会限制向节点添加新污点的速率。这一速率限制可以管理多个节点同时不可达时 (例如出现网络中断的情况),可能触发的驱逐的数量。
你可以为 Pod 设置 tolerationSeconds,以指定当节点失效或者不响应时,
Pod 维系与该节点间绑定关系的时长。
比如,你可能希望在出现网络分裂事件时,对于一个与节点本地状态有着深度绑定的应用而言, 仍然停留在当前节点上运行一段较长的时间,以等待网络恢复以避免被驱逐。 你为这种 Pod 所设置的容忍度看起来可能是这样:
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
说明:
Kubernetes 会自动给 Pod 添加针对 node.kubernetes.io/not-ready 和
node.kubernetes.io/unreachable 的容忍度,且配置 tolerationSeconds=300,
除非用户自身或者某控制器显式设置此容忍度。
这些自动添加的容忍度意味着 Pod 可以在检测到对应的问题之一时,在 5 分钟内保持绑定在该节点上。
DaemonSet 中的 Pod 被创建时,
针对以下污点自动添加的 NoExecute 的容忍度将不会指定 tolerationSeconds:
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
这保证了出现上述问题时 DaemonSet 中的 Pod 永远不会被驱逐。
基于节点状态添加污点
控制平面使用节点控制器自动创建
与节点状况
对应的、效果为 NoSchedule 的污点。
调度器在进行调度时检查污点,而不是检查节点状况。这确保节点状况不会直接影响调度。
例如,如果 DiskPressure 节点状况处于活跃状态,则控制平面添加
node.kubernetes.io/disk-pressure 污点并且不会调度新的 Pod 到受影响的节点。
如果 MemoryPressure 节点状况处于活跃状态,则控制平面添加
node.kubernetes.io/memory-pressure 污点。
对于新创建的 Pod,可以通过添加相应的 Pod 容忍度来忽略节点状况。
控制平面还在具有除 BestEffort 之外的
QoS 类的 Pod 上添加
node.kubernetes.io/memory-pressure 容忍度。
这是因为 Kubernetes 将 Guaranteed 或 Burstable QoS 类中的 Pod(甚至没有设置内存请求的 Pod)
视为能够应对内存压力,而新创建的 BestEffort Pod 不会被调度到受影响的节点上。
DaemonSet 控制器自动为所有守护进程添加如下 NoSchedule 容忍度,以防 DaemonSet 崩溃:
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/pid-pressure(1.14 或更高版本)node.kubernetes.io/unschedulable(1.10 或更高版本)node.kubernetes.io/network-unavailable(只适合主机网络配置)
添加上述容忍度确保了向后兼容,你也可以选择自由向 DaemonSet 添加容忍度。
接下来
10.7 - 调度框架
特性状态:
Kubernetes v1.19 [stable]
调度框架是面向 Kubernetes 调度器的一种插件架构, 它由一组直接编译到调度程序中的“插件” API 组成。 这些 API 允许大多数调度功能以插件的形式实现,同时使调度“核心”保持简单且可维护。 请参考调度框架的设计提案 获取框架设计的更多技术信息。
框架工作流程
调度框架定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。 这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。
每次调度一个 Pod 的尝试都分为两个阶段,即调度周期和绑定周期。
调度周期和绑定周期
调度周期为 Pod 选择一个节点,绑定周期将该决策应用于集群。 调度周期和绑定周期一起被称为“调度上下文”。
调度周期是串行运行的,而绑定周期可能是同时运行的。
如果确定 Pod 不可调度或者存在内部错误,则可以终止调度周期或绑定周期。 Pod 将返回队列并重试。
接口
下图显示了一个 Pod 的调度上下文以及调度框架公开的接口。
一个插件可能实现多个接口,以执行更为复杂或有状态的任务。
某些接口与可以通过调度器配置来设置的调度器扩展点匹配。
调度框架扩展点
PreEnqueue
这些插件在将 Pod 被添加到内部活动队列之前被调用,在此队列中 Pod 被标记为准备好进行调度。
只有当所有 PreEnqueue 插件返回 Success 时,Pod 才允许进入活动队列。
否则,它将被放置在内部无法调度的 Pod 列表中,并且不会获得 Unschedulable 状态。
要了解有关内部调度器队列如何工作的更多详细信息,请阅读 kube-scheduler 调度队列。
EnqueueExtension
EnqueueExtension 作为一个接口,插件可以在此接口之上根据集群中的变化来控制是否重新尝试调度被此插件拒绝的 Pod。实现 PreEnqueue、PreFilter、Filter、Reserve 或 Permit 的插件应实现此接口。
QueueingHint
特性状态:
Kubernetes v1.28 [beta]
QueueingHint 作为一个回调函数,用于决定是否将 Pod 重新排队到活跃队列或回退队列。 每当集群中发生某种事件或变化时,此函数就会被执行。 当 QueueingHint 发现事件可能使 Pod 可调度时,Pod 将被放入活跃队列或回退队列, 以便调度器可以重新尝试调度 Pod。
说明:
在调度过程中对 QueueingHint 求值是一个 Beta 级别的特性。
v1.28 的系列小版本最初都开启了这个特性的门控;但是发现了内存占用过多的问题,
于是 Kubernetes 项目将该特性门控设置为默认禁用。
在 Kubernetes 的 1.29 版本中,这个特性门控被禁用,你需要手动开启它。
你可以通过 SchedulerQueueingHints
特性门控来启用它。
队列排序
这些插件用于对调度队列中的 Pod 进行排序。
队列排序插件本质上提供 Less(Pod1, Pod2) 函数。
一次只能启动一个队列插件。
PreFilter
这些插件用于预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。 如果 PreFilter 插件返回错误,则调度周期将终止。
Filter
这些插件用于过滤出不能运行该 Pod 的节点。对于每个节点, 调度器将按照其配置顺序调用这些过滤插件。如果任何过滤插件将节点标记为不可行, 则不会为该节点调用剩下的过滤插件。节点可以被同时进行评估。
PostFilter
这些插件在 Filter 阶段后调用,但仅在该 Pod 没有可行的节点时调用。 插件按其配置的顺序调用。如果任何 PostFilter 插件标记节点为 "Schedulable", 则其余的插件不会调用。典型的 PostFilter 实现是抢占,试图通过抢占其他 Pod 的资源使该 Pod 可以调度。
PreScore
这些插件用于执行“前置评分(pre-scoring)”工作,即生成一个可共享状态供 Score 插件使用。 如果 PreScore 插件返回错误,则调度周期将终止。
Score
这些插件用于对通过过滤阶段的节点进行排序。调度器将为每个节点调用每个评分插件。 将有一个定义明确的整数范围,代表最小和最大分数。 在标准化评分阶段之后, 调度器将根据配置的插件权重合并所有插件的节点分数。
NormalizeScore
这些插件用于在调度器计算 Node 排名之前修改分数。 在此扩展点注册的插件被调用时会使用同一插件的 Score 结果。每个插件在每个调度周期调用一次。
例如,假设一个 BlinkingLightScorer 插件基于具有的闪烁指示灯数量来对节点进行排名。
func ScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
return getBlinkingLightCount(n)
}
然而,最大的闪烁灯个数值可能比 NodeScoreMax 小。要解决这个问题,
BlinkingLightScorer 插件还应该注册该扩展点。
func NormalizeScores(scores map[string]int) {
highest := 0
for _, score := range scores {
highest = max(highest, score)
}
for node, score := range scores {
scores[node] = score*NodeScoreMax/highest
}
}
如果任何 NormalizeScore 插件返回错误,则调度阶段将终止。
说明:
希望执行“预保留”工作的插件应该使用 NormalizeScore 扩展点。
Reserve
实现了 Reserve 接口的插件,拥有两个方法,即 Reserve 和 Unreserve,
他们分别支持两个名为 Reserve 和 Unreserve 的信息传递性质的调度阶段。
维护运行时状态的插件(又称"有状态插件")应该使用这两个阶段,
以便在节点上的资源被保留和解除保留给特定的 Pod 时,得到调度器的通知。
Reserve 阶段发生在调度器实际将一个 Pod 绑定到其指定节点之前。
它的存在是为了防止在调度器等待绑定成功时发生竞争情况。
每个 Reserve 插件的 Reserve 方法可能成功,也可能失败;
如果一个 Reserve 方法调用失败,后面的插件就不会被执行,Reserve 阶段被认为失败。
如果所有插件的 Reserve 方法都成功了,Reserve 阶段就被认为是成功的,
剩下的调度周期和绑定周期就会被执行。
如果 Reserve 阶段或后续阶段失败了,则触发 Unreserve 阶段。
发生这种情况时,所有 Reserve 插件的 Unreserve 方法将按照
Reserve 方法调用的相反顺序执行。
这个阶段的存在是为了清理与保留的 Pod 相关的状态。
注意:
Reserve 插件中 Unreserve 方法的实现必须是幂等的,并且不能失败。
这个是调度周期的最后一步。 一旦 Pod 处于保留状态,它将在绑定周期结束时触发 Unreserve 插件(失败时)或 PostBind 插件(成功时)。
Permit
Permit 插件在每个 Pod 调度周期的最后调用,用于防止或延迟 Pod 的绑定。 一个允许插件可以做以下三件事之一:
- 批准
一旦所有 Permit 插件批准 Pod 后,该 Pod 将被发送以进行绑定。
- 拒绝
如果任何 Permit 插件拒绝 Pod,则该 Pod 将被返回到调度队列。 这将触发 Reserve 插件中的 Unreserve 阶段。
- 等待(带有超时)
如果一个 Permit 插件返回“等待”结果,则 Pod 将保持在一个内部的“等待中” 的 Pod 列表,同时该 Pod 的绑定周期启动时即直接阻塞直到得到批准。 如果超时发生,等待变成拒绝,并且 Pod 将返回调度队列,从而触发 Reserve 插件中的 Unreserve 阶段。
说明:
尽管任何插件可以访问“等待中”状态的 Pod 列表并批准它们
(查看 FrameworkHandle)。
我们期望只有允许插件可以批准处于“等待中”状态的预留 Pod 的绑定。
一旦 Pod 被批准了,它将发送到 PreBind 阶段。
PreBind
这些插件用于执行 Pod 绑定前所需的所有工作。 例如,一个 PreBind 插件可能需要制备网络卷并且在允许 Pod 运行在该节点之前将其挂载到目标节点上。
如果任何 PreBind 插件返回错误,则 Pod 将被拒绝并且退回到调度队列中。
Bind
Bind 插件用于将 Pod 绑定到节点上。直到所有的 PreBind 插件都完成,Bind 插件才会被调用。 各 Bind 插件按照配置顺序被调用。Bind 插件可以选择是否处理指定的 Pod。 如果某 Bind 插件选择处理某 Pod,剩余的 Bind 插件将被跳过。
PostBind
这是个信息传递性质的接口。 PostBind 插件在 Pod 成功绑定后被调用。这是绑定周期的结尾,可用于清理相关的资源。
插件 API
插件 API 分为两个步骤。首先,插件必须完成注册并配置,然后才能使用扩展点接口。 扩展点接口具有以下形式。
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
// ...
插件配置
你可以在调度器配置中启用或禁用插件。 如果你在使用 Kubernetes v1.18 或更高版本, 大部分调度插件都在使用中且默认启用。
除了默认的插件,你还可以实现自己的调度插件并且将它们与默认插件一起配置。 你可以访问 scheduler-plugins 了解更多信息。
如果你正在使用 Kubernetes v1.18 或更高版本,你可以将一组插件设置为一个调度器配置文件, 然后定义不同的配置文件来满足各类工作负载。 了解更多关于多配置文件。
10.8 - 动态资源分配
特性状态:
Kubernetes v1.27 [alpha]
动态资源分配是一个用于在 Pod 之间和 Pod 内部容器之间请求和共享资源的 API。 它是对为通用资源所提供的持久卷 API 的泛化。第三方资源驱动程序负责跟踪和分配资源。 不同类型的资源支持用任意参数进行定义和初始化。
准备开始
Kubernetes v1.29 包含用于动态资源分配的集群级 API 支持, 但它需要被显式启用。 你还必须为此 API 要管理的特定资源安装资源驱动程序。 如果你未运行 Kubernetes v1.29, 请查看对应版本的 Kubernetes 文档。
API
resource.k8s.io/v1alpha2
API 组提供四种类型:
- ResourceClass
- 定义由哪个资源驱动程序处理某种资源,并为其提供通用参数。 集群管理员在安装资源驱动程序时创建 ResourceClass。
- ResourceClaim
- 定义工作负载所需的特定资源实例。 由用户创建(手动管理生命周期,可以在不同的 Pod 之间共享), 或者由控制平面基于 ResourceClaimTemplate 为特定 Pod 创建 (自动管理生命周期,通常仅由一个 Pod 使用)。
- ResourceClaimTemplate
- 定义用于创建 ResourceClaim 的 spec 和一些元数据。 部署工作负载时由用户创建。
- PodSchedulingContext
- 供控制平面和资源驱动程序内部使用, 在需要为 Pod 分配 ResourceClaim 时协调 Pod 调度。
ResourceClass 和 ResourceClaim 的参数存储在单独的对象中,通常使用安装资源驱动程序时创建的 CRD 所定义的类型。
core/v1 的 PodSpec 在 resourceClaims 字段中定义 Pod 所需的 ResourceClaim。
该列表中的条目引用 ResourceClaim 或 ResourceClaimTemplate。
当引用 ResourceClaim 时,使用此 PodSpec 的所有 Pod
(例如 Deployment 或 StatefulSet 中的 Pod)共享相同的 ResourceClaim 实例。
引用 ResourceClaimTemplate 时,每个 Pod 都有自己的实例。
容器资源的 resources.claims 列表定义容器可以访问的资源实例,
从而可以实现在一个或多个容器之间共享资源。
下面是一个虚构的资源驱动程序的示例。 该示例将为此 Pod 创建两个 ResourceClaim 对象,每个容器都可以访问其中一个。
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClass
name: resource.example.com
driverName: resource-driver.example.com
---
apiVersion: cats.resource.example.com/v1
kind: ClaimParameters
name: large-black-cat-claim-parameters
spec:
color: black
size: large
---
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaimTemplate
metadata:
name: large-black-cat-claim-template
spec:
spec:
resourceClassName: resource.example.com
parametersRef:
apiGroup: cats.resource.example.com
kind: ClaimParameters
name: large-black-cat-claim-parameters
–--
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
containers:
- name: container0
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-0
- name: container1
image: ubuntu:20.04
command: ["sleep", "9999"]
resources:
claims:
- name: cat-1
resourceClaims:
- name: cat-0
source:
resourceClaimTemplateName: large-black-cat-claim-template
- name: cat-1
source:
resourceClaimTemplateName: large-black-cat-claim-template
调度
与原生资源(CPU、RAM)和扩展资源(由设备插件管理,并由 kubelet 公布)不同, 调度器不知道集群中有哪些动态资源, 也不知道如何将它们拆分以满足特定 ResourceClaim 的要求。 资源驱动程序负责这些任务。 资源驱动程序在为 ResourceClaim 保留资源后将其标记为“已分配(Allocated)”。 然后告诉调度器集群中可用的 ResourceClaim 的位置。
ResourceClaim 可以在创建时就进行分配(“立即分配”),不用考虑哪些 Pod 将使用它。 默认情况下采用延迟分配,直到需要 ResourceClaim 的 Pod 被调度时 (即“等待第一个消费者”)再进行分配。
在这种模式下,调度器检查 Pod 所需的所有 ResourceClaim,并创建一个 PodScheduling 对象, 通知负责这些 ResourceClaim 的资源驱动程序,告知它们调度器认为适合该 Pod 的节点。 资源驱动程序通过排除没有足够剩余资源的节点来响应调度器。 一旦调度器有了这些信息,它就会选择一个节点,并将该选择存储在 PodScheduling 对象中。 然后,资源驱动程序为分配其 ResourceClaim,以便资源可用于该节点。 完成后,Pod 就会被调度。
作为此过程的一部分,ResourceClaim 会为 Pod 保留。 目前,ResourceClaim 可以由单个 Pod 独占使用或不限数量的多个 Pod 使用。
除非 Pod 的所有资源都已分配和保留,否则 Pod 不会被调度到节点,这是一个重要特性。 这避免了 Pod 被调度到一个节点但无法在那里运行的情况, 这种情况很糟糕,因为被挂起 Pod 也会阻塞为其保留的其他资源,如 RAM 或 CPU。
说明:
由于需要额外的通信,使用 ResourceClaim 的 Pod 的调度将会变慢。 请注意,这也可能会影响不使用 ResourceClaim 的 Pod,因为一次仅调度一个 Pod,在使用 ResourceClaim 处理 Pod 时会进行阻塞 API 调用, 从而推迟调度下一个 Pod。
监控资源
kubelet 提供了一个 gRPC 服务,以便发现正在运行的 Pod 的动态资源。 有关 gRPC 端点的更多信息,请参阅资源分配报告。
预调度的 Pod
当你(或别的 API 客户端)创建设置了 spec.nodeName 的 Pod 时,调度器将被绕过。
如果 Pod 所需的某个 ResourceClaim 尚不存在、未被分配或未为该 Pod 保留,那么 kubelet
将无法运行该 Pod,并会定期重新检查,因为这些要求可能在以后得到满足。
这种情况也可能发生在 Pod 被调度时调度器中未启用动态资源分配支持的时候(原因可能是版本偏差、配置、特性门控等)。 kube-controller-manager 能够检测到这一点,并尝试通过触发分配和/或预留所需的 ResourceClaim 来使 Pod 可运行。
然而,最好避免这种情况,因为分配给节点的 Pod 会锁住一些正常的资源(RAM、CPU), 而这些资源在 Pod 被卡住时无法用于其他 Pod。为了让一个 Pod 在特定节点上运行, 同时仍然通过正常的调度流程进行,请在创建 Pod 时使用与期望的节点精确匹配的节点选择算符:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-cats
spec:
nodeSelector:
kubernetes.io/hostname: name-of-the-intended-node
...
你还可以在准入时变更传入的 Pod,取消设置 .spec.nodeName 字段,并改为使用节点选择算符。
启用动态资源分配
动态资源分配是一个 Alpha 特性,只有在启用 DynamicResourceAllocation
特性门控
和 resource.k8s.io/v1alpha2
API 组 时才启用。
有关详细信息,参阅 --feature-gates 和 --runtime-config
kube-apiserver 参数。
kube-scheduler、kube-controller-manager 和 kubelet 也需要设置该特性门控。
快速检查 Kubernetes 集群是否支持该功能的方法是列出 ResourceClass 对象:
kubectl get resourceclasses
如果你的集群支持动态资源分配,则响应是 ResourceClass 对象列表或:
No resources found
如果不支持,则会输出如下错误:
error: the server doesn't have a resource type "resourceclasses"
kube-scheduler 的默认配置仅在启用特性门控且使用 v1 配置 API 时才启用 "DynamicResources" 插件。 自定义配置可能需要被修改才能启用它。
除了在集群中启用该功能外,还必须安装资源驱动程序。 欲了解详细信息,请参阅驱动程序的文档。
接下来
- 了解更多该设计的信息, 参阅动态资源分配 KEP。
10.9 - 调度器性能调优
特性状态:
Kubernetes v1.14 [beta]
作为 kubernetes 集群的默认调度器, kube-scheduler 主要负责将 Pod 调度到集群的 Node 上。
在一个集群中,满足一个 Pod 调度请求的所有 Node 称之为可调度 Node。 调度器先在集群中找到一个 Pod 的可调度 Node,然后根据一系列函数对这些可调度 Node 打分, 之后选出其中得分最高的 Node 来运行 Pod。 最后,调度器将这个调度决定告知 kube-apiserver,这个过程叫做绑定(Binding)。
这篇文章将会介绍一些在大规模 Kubernetes 集群下调度器性能优化的方式。
在大规模集群中,你可以调节调度器的表现来平衡调度的延迟(新 Pod 快速就位) 和精度(调度器很少做出糟糕的放置决策)。
你可以通过设置 kube-scheduler 的 percentageOfNodesToScore 来配置这个调优设置。
这个 KubeSchedulerConfiguration 设置决定了调度集群中节点的阈值。
设置阈值
percentageOfNodesToScore 选项接受从 0 到 100 之间的整数值。
0 值比较特殊,表示 kube-scheduler 应该使用其编译后的默认值。
如果你设置 percentageOfNodesToScore 的值超过了 100,
kube-scheduler 的表现等价于设置值为 100。
要修改这个值,先编辑
kube-scheduler 的配置文件然后重启调度器。
大多数情况下,这个配置文件是 /etc/kubernetes/config/kube-scheduler.yaml。
修改完成后,你可以执行
kubectl get pods -n kube-system | grep kube-scheduler
来检查该 kube-scheduler 组件是否健康。
节点打分阈值
要提升调度性能,kube-scheduler 可以在找到足够的可调度节点之后停止查找。 在大规模集群中,比起考虑每个节点的简单方法相比可以节省时间。
你可以使用整个集群节点总数的百分比作为阈值来指定需要多少节点就足够。 kube-scheduler 会将它转换为节点数的整数值。在调度期间,如果 kube-scheduler 已确认的可调度节点数足以超过了配置的百分比数量, kube-scheduler 将停止继续查找可调度节点并继续进行 打分阶段。
调度器如何遍历节点详细介绍了这个过程。
默认阈值
如果你不指定阈值,Kubernetes 使用线性公式计算出一个比例,在 100-节点集群 下取 50%,在 5000-节点的集群下取 10%。这个自动设置的参数的最低值是 5%。
这意味着,调度器至少会对集群中 5% 的节点进行打分,除非用户将该参数设置的低于 5。
如果你想让调度器对集群内所有节点进行打分,则将 percentageOfNodesToScore 设置为 100。
示例
下面就是一个将 percentageOfNodesToScore 参数设置为 50% 的例子。
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50
调节 percentageOfNodesToScore 参数
percentageOfNodesToScore 的值必须在 1 到 100 之间,而且其默认值是通过集群的规模计算得来的。
另外,还有一个 50 个 Node 的最小值是硬编码在程序中。
说明:
当集群中的可调度节点少于 50 个时,调度器仍然会去检查所有的 Node, 因为可调度节点太少,不足以停止调度器最初的过滤选择。
同理,在小规模集群中,如果你将 percentageOfNodesToScore
设置为一个较低的值,则没有或者只有很小的效果。
如果集群只有几百个节点或者更少,请保持这个配置的默认值。 改变基本不会对调度器的性能有明显的提升。
值得注意的是,该参数设置后可能会导致只有集群中少数节点被选为可调度节点, 很多节点都没有进入到打分阶段。这样就会造成一种后果, 一个本来可以在打分阶段得分很高的节点甚至都不能进入打分阶段。
由于这个原因,这个参数不应该被设置成一个很低的值。 通常的做法是不会将这个参数的值设置的低于 10。 很低的参数值一般在调度器的吞吐量很高且对节点的打分不重要的情况下才使用。 换句话说,只有当你更倾向于在可调度节点中任意选择一个节点来运行这个 Pod 时, 才使用很低的参数设置。
调度器做调度选择的时候如何覆盖所有的 Node
如果你想要理解这一个特性的内部细节,那么请仔细阅读这一章节。
在将 Pod 调度到节点上时,为了让集群中所有节点都有公平的机会去运行这些 Pod,
调度器将会以轮询的方式覆盖全部的 Node。
你可以将 Node 列表想象成一个数组。调度器从数组的头部开始筛选可调度节点,
依次向后直到可调度节点的数量达到 percentageOfNodesToScore 参数的要求。
在对下一个 Pod 进行调度的时候,前一个 Pod 调度筛选停止的 Node 列表的位置,
将会来作为这次调度筛选 Node 开始的位置。
如果集群中的 Node 在多个区域,那么调度器将从不同的区域中轮询 Node, 来确保不同区域的 Node 接受可调度性检查。如下例,考虑两个区域中的六个节点:
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
调度器将会按照如下的顺序去评估 Node 的可调度性:
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
在评估完所有 Node 后,将会返回到 Node 1,从头开始。
接下来
10.10 - 资源装箱
在 kube-scheduler 的调度插件
NodeResourcesFit 中存在两种支持资源装箱(bin packing)的策略:MostAllocated 和
RequestedToCapacityRatio。
使用 MostAllocated 策略启用资源装箱
MostAllocated 策略基于资源的利用率来为节点计分,优选分配比率较高的节点。
针对每种资源类型,你可以设置一个权重值以改变其对节点得分的影响。
要为插件 NodeResourcesFit 设置 MostAllocated 策略,
可以使用一个类似于下面这样的调度器配置:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
scoringStrategy:
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
- name: intel.com/foo
weight: 3
- name: intel.com/bar
weight: 3
type: MostAllocated
name: NodeResourcesFit
要进一步了解其它参数及其默认配置,请参阅
NodeResourcesFitArgs
的 API 文档。
使用 RequestedToCapacityRatio 策略来启用资源装箱
RequestedToCapacityRatio 策略允许用户基于请求值与容量的比率,针对参与节点计分的每类资源设置权重。
这一策略使得用户可以使用合适的参数来对扩展资源执行装箱操作,进而提升大规模集群中稀有资源的利用率。
此策略根据所分配资源的一个配置函数来评价节点。
NodeResourcesFit 计分函数中的 RequestedToCapacityRatio 可以通过
scoringStrategy
字段来控制。在 scoringStrategy 字段中,你可以配置两个参数:
requestedToCapacityRatio 和 resources。requestedToCapacityRatio 参数中的 shape
设置使得用户能够调整函数的算法,基于 utilization 和 score 值计算最少请求或最多请求。
resources 参数中包含计分过程中需要考虑的资源的 name,以及用来设置每种资源权重的 weight。
下面是一个配置示例,使用 requestedToCapacityRatio 字段为扩展资源 intel.com/foo
和 intel.com/bar 设置装箱行为:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- args:
scoringStrategy:
resources:
- name: intel.com/foo
weight: 3
- name: intel.com/bar
weight: 3
requestedToCapacityRatio:
shape:
- utilization: 0
score: 0
- utilization: 100
score: 10
type: RequestedToCapacityRatio
name: NodeResourcesFit
使用 kube-scheduler 标志 --config=/path/to/config/file
引用 KubeSchedulerConfiguration 文件,可以将配置传递给调度器。
要进一步了解其它参数及其默认配置,可以参阅
NodeResourcesFitArgs
的 API 文档。
调整计分函数
shape 用于指定 RequestedToCapacityRatio 函数的行为。
shape:
- utilization: 0
score: 0
- utilization: 100
score: 10
上面的参数在 utilization 为 0% 时给节点评分为 0,在 utilization 为
100% 时给节点评分为 10,因此启用了装箱行为。
要启用最少请求(least requested)模式,必须按如下方式反转得分值。
shape:
- utilization: 0
score: 10
- utilization: 100
score: 0
resources 是一个可选参数,默认值为:
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
它可以像下面这样用来添加扩展资源:
resources:
- name: intel.com/foo
weight: 5
- name: cpu
weight: 3
- name: memory
weight: 1
weight 参数是可选的,如果未指定,则设置为 1。
同时,weight 不能设置为负值。
节点容量分配的评分
本节适用于希望了解此功能的内部细节的人员。 以下是如何针对给定的一组值来计算节点得分的示例。
请求的资源:
intel.com/foo : 2
memory: 256MB
cpu: 2
资源权重:
intel.com/foo : 5
memory: 1
cpu: 3
FunctionShapePoint {{0, 0}, {100, 10}}
节点 1 配置:
可用:
intel.com/foo: 4
memory: 1 GB
cpu: 8
已用:
intel.com/foo: 1
memory: 256MB
cpu: 1
节点得分:
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4)
= (100 - 25)
= 75 # requested + used = 75% * available
= rawScoringFunction(75)
= 7 # floor(75/10)
memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50 # requested + used = 50% * available
= rawScoringFunction(50)
= 5 # floor(50/10)
cpu = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5 # requested + used = 37.5% * available
= rawScoringFunction(37.5)
= 3 # floor(37.5/10)
NodeScore = ((7 * 5) + (5 * 1) + (3 * 3)) / (5 + 1 + 3)
= 5
节点 2 配置:
可用:
intel.com/foo: 8
memory: 1GB
cpu: 8
已用:
intel.com/foo: 2
memory: 512MB
cpu: 6
节点得分:
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
cpu = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = ((5 * 5) + (7 * 1) + (10 * 3)) / (5 + 1 + 3)
= 7
接下来
10.11 - Pod 优先级和抢占
特性状态:
Kubernetes v1.14 [stable]
Pod 可以有优先级。 优先级表示一个 Pod 相对于其他 Pod 的重要性。 如果一个 Pod 无法被调度,调度程序会尝试抢占(驱逐)较低优先级的 Pod, 以使悬决 Pod 可以被调度。
警告:
在一个并非所有用户都是可信的集群中,恶意用户可能以最高优先级创建 Pod, 导致其他 Pod 被驱逐或者无法被调度。 管理员可以使用 ResourceQuota 来阻止用户创建高优先级的 Pod。 参见默认限制优先级消费。
如何使用优先级和抢占
要使用优先级和抢占:
-
新增一个或多个 PriorityClass。
-
创建 Pod,并将其
priorityClassName设置为新增的 PriorityClass。 当然你不需要直接创建 Pod;通常,你将会添加priorityClassName到集合对象(如 Deployment) 的 Pod 模板中。
继续阅读以获取有关这些步骤的更多信息。
说明:
Kubernetes 已经提供了 2 个 PriorityClass:
system-cluster-critical 和 system-node-critical。
这些是常见的类,用于确保始终优先调度关键组件。
PriorityClass
PriorityClass 是一个无命名空间对象,它定义了从优先级类名称到优先级整数值的映射。
名称在 PriorityClass 对象元数据的 name 字段中指定。
值在必填的 value 字段中指定。值越大,优先级越高。
PriorityClass 对象的名称必须是有效的
DNS 子域名,
并且它不能以 system- 为前缀。
PriorityClass 对象可以设置任何小于或等于 10 亿的 32 位整数值。 这意味着 PriorityClass 对象的值范围是从 -2,147,483,648 到 1,000,000,000(含)。 保留更大的数字,用于表示关键系统 Pod 的内置 PriorityClass。 集群管理员应该为这类映射分别创建独立的 PriorityClass 对象。
PriorityClass 还有两个可选字段:globalDefault 和 description。
globalDefault 字段表示这个 PriorityClass 的值应该用于没有 priorityClassName 的 Pod。
系统中只能存在一个 globalDefault 设置为 true 的 PriorityClass。
如果不存在设置了 globalDefault 的 PriorityClass,
则没有 priorityClassName 的 Pod 的优先级为零。
description 字段是一个任意字符串。
它用来告诉集群用户何时应该使用此 PriorityClass。
关于 PodPriority 和现有集群的注意事项
-
如果你升级一个已经存在的但尚未使用此特性的集群,该集群中已经存在的 Pod 的优先级等效于零。
-
添加一个将
globalDefault设置为true的 PriorityClass 不会改变现有 Pod 的优先级。 此类 PriorityClass 的值仅用于添加 PriorityClass 后创建的 Pod。 -
如果你删除了某个 PriorityClass 对象,则使用被删除的 PriorityClass 名称的现有 Pod 保持不变, 但是你不能再创建使用已删除的 PriorityClass 名称的 Pod。
PriorityClass 示例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "此优先级类应仅用于 XYZ 服务 Pod。"
非抢占式 PriorityClass
特性状态:
Kubernetes v1.24 [stable]
配置了 preemptionPolicy: Never 的 Pod 将被放置在调度队列中较低优先级 Pod 之前,
但它们不能抢占其他 Pod。等待调度的非抢占式 Pod 将留在调度队列中,直到有足够的可用资源,
它才可以被调度。非抢占式 Pod,像其他 Pod 一样,受调度程序回退的影响。
这意味着如果调度程序尝试这些 Pod 并且无法调度它们,它们将以更低的频率被重试,
从而允许其他优先级较低的 Pod 排在它们之前。
非抢占式 Pod 仍可能被其他高优先级 Pod 抢占。
preemptionPolicy 默认为 PreemptLowerPriority,
这将允许该 PriorityClass 的 Pod 抢占较低优先级的 Pod(现有默认行为也是如此)。
如果 preemptionPolicy 设置为 Never,则该 PriorityClass 中的 Pod 将是非抢占式的。
数据科学工作负载是一个示例用例。用户可以提交他们希望优先于其他工作负载的作业,
但不希望因为抢占运行中的 Pod 而导致现有工作被丢弃。
设置为 preemptionPolicy: Never 的高优先级作业将在其他排队的 Pod 之前被调度,
只要足够的集群资源“自然地”变得可用。
非抢占式 PriorityClass 示例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-nonpreempting
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "This priority class will not cause other pods to be preempted."
Pod 优先级
在你拥有一个或多个 PriorityClass 对象之后,
你可以创建在其规约中指定这些 PriorityClass 名称之一的 Pod。
优先级准入控制器使用 priorityClassName 字段并填充优先级的整数值。
如果未找到所指定的优先级类,则拒绝 Pod。
以下 YAML 是 Pod 配置的示例,它使用在前面的示例中创建的 PriorityClass。 优先级准入控制器检查 Pod 规约并将其优先级解析为 1000000。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
Pod 优先级对调度顺序的影响
当启用 Pod 优先级时,调度程序会按优先级对悬决 Pod 进行排序, 并且每个悬决的 Pod 会被放置在调度队列中其他优先级较低的悬决 Pod 之前。 因此,如果满足调度要求,较高优先级的 Pod 可能会比具有较低优先级的 Pod 更早调度。 如果无法调度此类 Pod,调度程序将继续并尝试调度其他较低优先级的 Pod。
抢占
Pod 被创建后会进入队列等待调度。 调度器从队列中挑选一个 Pod 并尝试将它调度到某个节点上。 如果没有找到满足 Pod 的所指定的所有要求的节点,则触发对悬决 Pod 的抢占逻辑。 让我们将悬决 Pod 称为 P。抢占逻辑试图找到一个节点, 在该节点中删除一个或多个优先级低于 P 的 Pod,则可以将 P 调度到该节点上。 如果找到这样的节点,一个或多个优先级较低的 Pod 会被从节点中驱逐。 被驱逐的 Pod 消失后,P 可以被调度到该节点上。
用户暴露的信息
当 Pod P 抢占节点 N 上的一个或多个 Pod 时,
Pod P 状态的 nominatedNodeName 字段被设置为节点 N 的名称。
该字段帮助调度程序跟踪为 Pod P 保留的资源,并为用户提供有关其集群中抢占的信息。
请注意,Pod P 不一定会调度到“被提名的节点(Nominated Node)”。
调度程序总是在迭代任何其他节点之前尝试“指定节点”。
在 Pod 因抢占而牺牲时,它们将获得体面终止期。
如果调度程序正在等待牺牲者 Pod 终止时另一个节点变得可用,
则调度程序可以使用另一个节点来调度 Pod P。
因此,Pod 规约中的 nominatedNodeName 和 nodeName 并不总是相同。
此外,如果调度程序抢占节点 N 上的 Pod,但随后比 Pod P 更高优先级的 Pod 到达,
则调度程序可能会将节点 N 分配给新的更高优先级的 Pod。
在这种情况下,调度程序会清除 Pod P 的 nominatedNodeName。
通过这样做,调度程序使 Pod P 有资格抢占另一个节点上的 Pod。
抢占的限制
被抢占牺牲者的体面终止
当 Pod 被抢占时,牺牲者会得到他们的 体面终止期。 它们可以在体面终止期内完成工作并退出。如果它们不这样做就会被杀死。 这个体面终止期在调度程序抢占 Pod 的时间点和待处理的 Pod (P) 可以在节点 (N) 上调度的时间点之间划分出了一个时间跨度。 同时,调度器会继续调度其他待处理的 Pod。当牺牲者退出或被终止时, 调度程序会尝试在待处理队列中调度 Pod。 因此,调度器抢占牺牲者的时间点与 Pod P 被调度的时间点之间通常存在时间间隔。 为了最小化这个差距,可以将低优先级 Pod 的体面终止时间设置为零或一个小数字。
支持 PodDisruptionBudget,但不保证
PodDisruptionBudget (PDB) 允许多副本应用程序的所有者限制因自愿性质的干扰而同时终止的 Pod 数量。 Kubernetes 在抢占 Pod 时支持 PDB,但对 PDB 的支持是基于尽力而为原则的。 调度器会尝试寻找不会因被抢占而违反 PDB 的牺牲者,但如果没有找到这样的牺牲者, 抢占仍然会发生,并且即使违反了 PDB 约束也会删除优先级较低的 Pod。
与低优先级 Pod 之间的 Pod 间亲和性
只有当这个问题的答案是肯定的时,才考虑在一个节点上执行抢占操作: “如果从此节点上删除优先级低于悬决 Pod 的所有 Pod,悬决 Pod 是否可以在该节点上调度?”
说明:
抢占并不一定会删除所有较低优先级的 Pod。 如果悬决 Pod 可以通过删除少于所有较低优先级的 Pod 来调度, 那么只有一部分较低优先级的 Pod 会被删除。 即便如此,上述问题的答案必须是肯定的。 如果答案是否定的,则不考虑在该节点上执行抢占。
如果悬决 Pod 与节点上的一个或多个较低优先级 Pod 具有 Pod 间亲和性, 则在没有这些较低优先级 Pod 的情况下,无法满足 Pod 间亲和性规则。 在这种情况下,调度程序不会抢占节点上的任何 Pod。 相反,它寻找另一个节点。调度程序可能会找到合适的节点, 也可能不会。无法保证悬决 Pod 可以被调度。
我们针对此问题推荐的解决方案是仅针对同等或更高优先级的 Pod 设置 Pod 间亲和性。
跨节点抢占
假设正在考虑在一个节点 N 上执行抢占,以便可以在 N 上调度待处理的 Pod P。 只有当另一个节点上的 Pod 被抢占时,P 才可能在 N 上变得可行。 下面是一个例子:
- 调度器正在考虑将 Pod P 调度到节点 N 上。
- Pod Q 正在与节点 N 位于同一区域的另一个节点上运行。
- Pod P 与 Pod Q 具有 Zone 维度的反亲和(
topologyKey:topology.kubernetes.io/zone)设置。 - Pod P 与 Zone 中的其他 Pod 之间没有其他反亲和性设置。
- 为了在节点 N 上调度 Pod P,可以抢占 Pod Q,但调度器不会进行跨节点抢占。 因此,Pod P 将被视为在节点 N 上不可调度。
如果将 Pod Q 从所在节点中移除,则不会违反 Pod 间反亲和性约束, 并且 Pod P 可能会被调度到节点 N 上。
如果有足够的需求,并且如果我们找到性能合理的算法, 我们可能会考虑在未来版本中添加跨节点抢占。
故障排除
Pod 优先级和抢占可能会产生不必要的副作用。以下是一些潜在问题的示例以及处理这些问题的方法。
Pod 被不必要地抢占
抢占在资源压力较大时从集群中删除现有 Pod,为更高优先级的悬决 Pod 腾出空间。
如果你错误地为某些 Pod 设置了高优先级,这些无意的高优先级 Pod 可能会导致集群中出现抢占行为。
Pod 优先级是通过设置 Pod 规约中的 priorityClassName 字段来指定的。
优先级的整数值然后被解析并填充到 podSpec 的 priority 字段。
为了解决这个问题,你可以将这些 Pod 的 priorityClassName 更改为使用较低优先级的类,
或者将该字段留空。默认情况下,空的 priorityClassName 解析为零。
当 Pod 被抢占时,集群会为被抢占的 Pod 记录事件。只有当集群没有足够的资源用于 Pod 时, 才会发生抢占。在这种情况下,只有当悬决 Pod(抢占者)的优先级高于受害 Pod 时才会发生抢占。 当没有悬决 Pod,或者悬决 Pod 的优先级等于或低于牺牲者时,不得发生抢占。 如果在这种情况下发生抢占,请提出问题。
有 Pod 被抢占,但抢占者并没有被调度
当 Pod 被抢占时,它们会收到请求的体面终止期,默认为 30 秒。 如果受害 Pod 在此期限内没有终止,它们将被强制终止。 一旦所有牺牲者都离开,就可以调度抢占者 Pod。
在抢占者 Pod 等待牺牲者离开的同时,可能某个适合同一个节点的更高优先级的 Pod 被创建。 在这种情况下,调度器将调度优先级更高的 Pod 而不是抢占者。
这是预期的行为:具有较高优先级的 Pod 应该取代具有较低优先级的 Pod。
优先级较高的 Pod 在优先级较低的 Pod 之前被抢占
调度程序尝试查找可以运行悬决 Pod 的节点。如果没有找到这样的节点, 调度程序会尝试从任意节点中删除优先级较低的 Pod,以便为悬决 Pod 腾出空间。 如果具有低优先级 Pod 的节点无法运行悬决 Pod, 调度器可能会选择另一个具有更高优先级 Pod 的节点(与其他节点上的 Pod 相比)进行抢占。 牺牲者的优先级必须仍然低于抢占者 Pod。
当有多个节点可供执行抢占操作时,调度器会尝试选择具有一组优先级最低的 Pod 的节点。 但是,如果此类 Pod 具有 PodDisruptionBudget,当它们被抢占时, 则会违反 PodDisruptionBudget,那么调度程序可能会选择另一个具有更高优先级 Pod 的节点。
当存在多个节点抢占且上述场景均不适用时,调度器会选择优先级最低的节点。
Pod 优先级和服务质量之间的相互作用
Pod 优先级和 QoS 类 是两个正交特征,交互很少,并且对基于 QoS 类设置 Pod 的优先级没有默认限制。 调度器的抢占逻辑在选择抢占目标时不考虑 QoS。 抢占会考虑 Pod 优先级并尝试选择一组优先级最低的目标。 仅当移除优先级最低的 Pod 不足以让调度程序调度抢占式 Pod, 或者最低优先级的 Pod 受 PodDisruptionBudget 保护时,才会考虑优先级较高的 Pod。
kubelet 使用优先级来确定 节点压力驱逐 Pod 的顺序。 你可以使用 QoS 类来估计 Pod 最有可能被驱逐的顺序。kubelet 根据以下因素对 Pod 进行驱逐排名:
- 对紧俏资源的使用是否超过请求值
- Pod 优先级
- 相对于请求的资源使用量
有关更多详细信息,请参阅 kubelet 驱逐时 Pod 的选择。
当某 Pod 的资源用量未超过其请求时,kubelet 节点压力驱逐不会驱逐该 Pod。 如果优先级较低的 Pod 的资源使用量没有超过其请求,则不会被驱逐。 另一个优先级较高且资源使用量超过其请求的 Pod 可能会被驱逐。
接下来
10.12 - 节点压力驱逐
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。
kubelet 监控集群节点的内存、磁盘空间和文件系统的 inode 等资源。 当这些资源中的一个或者多个达到特定的消耗水平, kubelet 可以主动地使节点上一个或者多个 Pod 失效,以回收资源防止饥饿。
在节点压力驱逐期间,kubelet 将所选 Pod 的阶段
设置为 Failed 并终止 Pod。
节点压力驱逐不同于 API 发起的驱逐。
kubelet 并不理会你配置的 PodDisruptionBudget
或者是 Pod 的 terminationGracePeriodSeconds。
如果你使用了软驱逐条件,kubelet 会考虑你所配置的
eviction-max-pod-grace-period。
如果你使用了硬驱逐条件,kubelet 使用 0s
宽限期(立即关闭)来终止 Pod。
自我修复行为
kubelet 在终止最终用户 Pod 之前会尝试回收节点级资源。 例如,它会在磁盘资源不足时删除未使用的容器镜像。
如果 Pod 是由替换失败 Pod 的工作负载资源
(例如 StatefulSet
或者 Deployment)管理,
则控制平面或 kube-controller-manager 会创建新的 Pod 来代替被驱逐的 Pod。
静态 Pod 的自我修复
如果你在面临资源压力的节点上运行静态 Pod,则 kubelet 可能会驱逐该静态 Pod。 由于静态 Pod 始终表示在该节点上运行 Pod 的意图,kubelet 会尝试创建替代 Pod。
创建替代 Pod 时,kubelet 会考虑静态 Pod 的优先级。如果静态 Pod 清单指定了低优先级, 并且集群的控制平面内定义了优先级更高的 Pod,并且节点面临资源压力,则 kubelet 可能无法为该静态 Pod 腾出空间。 即使节点上存在资源压力,kubelet 也会继续尝试运行所有静态 pod。
驱逐信号和阈值
kubelet 使用各种参数来做出驱逐决定,如下所示:
- 驱逐信号
- 驱逐条件
- 监控间隔
驱逐信号
驱逐信号是特定资源在特定时间点的当前状态。 kubelet 使用驱逐信号,通过将信号与驱逐条件进行比较来做出驱逐决定, 驱逐条件是节点上应该可用资源的最小量。
Linux 系统中,kubelet 使用以下驱逐信号:
| 驱逐信号 | 描述 |
|---|---|
memory.available |
memory.available := node.status.capacity[memory] - node.stats.memory.workingSet |
nodefs.available |
nodefs.available := node.stats.fs.available |
nodefs.inodesFree |
nodefs.inodesFree := node.stats.fs.inodesFree |
imagefs.available |
imagefs.available := node.stats.runtime.imagefs.available |
imagefs.inodesFree |
imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
pid.available |
pid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc |
在上表中,描述列显示了 kubelet 如何获取信号的值。每个信号支持百分比值或者是字面值。 kubelet 计算相对于与信号有关的总量的百分比值。
memory.available 的值来自 cgroupfs,而不是像 free -m 这样的工具。
这很重要,因为 free -m 在容器中不起作用,如果用户使用
节点可分配资源
这一功能特性,资源不足的判定是基于 cgroup 层次结构中的用户 Pod 所处的局部及 cgroup 根节点作出的。
这个脚本或者
cgroupv2 脚本
重现了 kubelet 为计算 memory.available 而执行的相同步骤。
kubelet 在其计算中排除了 inactive_file(非活动 LRU 列表上基于文件来虚拟的内存的字节数),
因为它假定在压力下内存是可回收的。
kubelet 可识别以下两个特定的文件系统标识符:
nodefs:节点的主要文件系统,用于本地磁盘卷、不受内存支持的 emptyDir 卷、日志存储等。 例如,nodefs包含/var/lib/kubelet/。imagefs:可选文件系统,供容器运行时存储容器镜像和容器可写层。
kubelet 会自动发现这些文件系统并忽略节点本地的其它文件系统。kubelet 不支持其他配置。
一些 kubelet 垃圾收集功能已被弃用,以鼓励使用驱逐机制。
| 现有标志 | 原因 |
|---|---|
--maximum-dead-containers |
一旦旧的日志存储在容器的上下文之外就会被弃用 |
--maximum-dead-containers-per-container |
一旦旧的日志存储在容器的上下文之外就会被弃用 |
--minimum-container-ttl-duration |
一旦旧的日志存储在容器的上下文之外就会被弃用 |
驱逐条件
你可以为 kubelet 指定自定义驱逐条件,以便在作出驱逐决定时使用。 你可以设置软性的和硬性的驱逐阈值。
驱逐条件的形式为 [eviction-signal][operator][quantity],其中:
eviction-signal是要使用的驱逐信号。operator是你想要的关系运算符, 比如<(小于)。quantity是驱逐条件数量,例如1Gi。quantity的值必须与 Kubernetes 使用的数量表示相匹配。 你可以使用文字值或百分比(%)。
例如,如果一个节点的总内存为 10GiB 并且你希望在可用内存低于 1GiB 时触发驱逐,
则可以将驱逐条件定义为 memory.available<10% 或
memory.available< 1G(你不能同时使用二者)。
你可以配置软和硬驱逐条件。
软驱逐条件
软驱逐条件将驱逐条件与管理员所必须指定的宽限期配对。 在超过宽限期之前,kubelet 不会驱逐 Pod。 如果没有指定的宽限期,kubelet 会在启动时返回错误。
你可以既指定软驱逐条件宽限期,又指定 Pod 终止宽限期的上限,给 kubelet 在驱逐期间使用。 如果你指定了宽限期的上限并且 Pod 满足软驱逐阈条件,则 kubelet 将使用两个宽限期中的较小者。 如果你没有指定宽限期上限,kubelet 会立即杀死被驱逐的 Pod,不允许其体面终止。
你可以使用以下标志来配置软驱逐条件:
eviction-soft:一组驱逐条件,如memory.available<1.5Gi, 如果驱逐条件持续时长超过指定的宽限期,可以触发 Pod 驱逐。eviction-soft-grace-period:一组驱逐宽限期, 如memory.available=1m30s,定义软驱逐条件在触发 Pod 驱逐之前必须保持多长时间。eviction-max-pod-grace-period:在满足软驱逐条件而终止 Pod 时使用的最大允许宽限期(以秒为单位)。
硬驱逐条件
硬驱逐条件没有宽限期。当达到硬驱逐条件时, kubelet 会立即杀死 pod,而不会正常终止以回收紧缺的资源。
你可以使用 eviction-hard 标志来配置一组硬驱逐条件,
例如 memory.available<1Gi。
kubelet 具有以下默认硬驱逐条件:
memory.available<100Minodefs.available<10%imagefs.available<15%nodefs.inodesFree<5%(Linux 节点)
只有在没有更改任何参数的情况下,硬驱逐阈值才会被设置成这些默认值。 如果你更改了任何参数的值,则其他参数的取值不会继承其默认值设置,而将被设置为零。 为了提供自定义值,你应该分别设置所有阈值。
驱逐监测间隔
kubelet 根据其配置的 housekeeping-interval(默认为 10s)评估驱逐条件。
节点状况
kubelet 报告节点状况以反映节点处于压力之下, 原因是满足硬性的或软性的驱逐条件,与配置的宽限期无关。
kubelet 根据下表将驱逐信号映射为节点状况:
| 节点条件 | 驱逐信号 | 描述 |
|---|---|---|
MemoryPressure |
memory.available |
节点上的可用内存已满足驱逐条件 |
DiskPressure |
nodefs.available、nodefs.inodesFree、imagefs.available 或 imagefs.inodesFree |
节点的根文件系统或镜像文件系统上的可用磁盘空间和 inode 已满足驱逐条件 |
PIDPressure |
pid.available |
(Linux) 节点上的可用进程标识符已低于驱逐条件 |
控制平面还将这些节点状况映射为其污点。
kubelet 根据配置的 --node-status-update-frequency 更新节点条件,默认为 10s。
节点状况波动
在某些情况下,节点在软驱逐条件上下振荡,而没有保持定义的宽限期。
这会导致报告的节点条件在 true 和 false 之间不断切换,从而导致错误的驱逐决策。
为了防止振荡,你可以使用 eviction-pressure-transition-period 标志,
该标志控制 kubelet 在将节点条件转换为不同状态之前必须等待的时间。
过渡期的默认值为 5m。
回收节点级资源
kubelet 在驱逐最终用户 Pod 之前会先尝试回收节点级资源。
当报告 DiskPressure 节点状况时,kubelet 会根据节点上的文件系统回收节点级资源。
有 imagefs
如果节点有一个专用的 imagefs 文件系统供容器运行时使用,kubelet 会执行以下操作:
- 如果
nodefs文件系统满足驱逐条件,kubelet 垃圾收集死亡 Pod 和容器。 - 如果
imagefs文件系统满足驱逐条件,kubelet 将删除所有未使用的镜像。
没有 imagefs
如果节点只有一个满足驱逐条件的 nodefs 文件系统,
kubelet 按以下顺序释放磁盘空间:
- 对死亡的 Pod 和容器进行垃圾收集
- 删除未使用的镜像
kubelet 驱逐时 Pod 的选择
如果 kubelet 回收节点级资源的尝试没有使驱逐信号低于条件, 则 kubelet 开始驱逐最终用户 Pod。
kubelet 使用以下参数来确定 Pod 驱逐顺序:
- Pod 的资源使用是否超过其请求
- Pod 优先级
- Pod 相对于请求的资源使用情况
因此,kubelet 按以下顺序排列和驱逐 Pod:
- 首先考虑资源使用量超过其请求的
BestEffort或BurstablePod。 这些 Pod 会根据它们的优先级以及它们的资源使用级别超过其请求的程度被逐出。 - 资源使用量少于请求量的
GuaranteedPod 和BurstablePod 根据其优先级被最后驱逐。
说明:
kubelet 不使用 Pod 的 QoS 类来确定驱逐顺序。
在回收内存等资源时,你可以使用 QoS 类来估计最可能的 Pod 驱逐顺序。
QoS 分类不适用于临时存储(EphemeralStorage)请求,
因此如果节点在 DiskPressure 下,则上述场景将不适用。
仅当 Guaranteed Pod 中所有容器都被指定了请求和限制并且二者相等时,才保证 Pod 不被驱逐。
这些 Pod 永远不会因为另一个 Pod 的资源消耗而被驱逐。
如果系统守护进程(例如 kubelet 和 journald)
消耗的资源比通过 system-reserved 或 kube-reserved 分配保留的资源多,
并且该节点只有 Guaranteed 或 Burstable Pod 使用的资源少于其上剩余的请求,
那么 kubelet 必须选择驱逐这些 Pod 中的一个以保持节点稳定性并减少资源匮乏对其他 Pod 的影响。
在这种情况下,它会选择首先驱逐最低优先级的 Pod。
如果你正在运行静态 Pod
并且希望避免其在资源压力下被驱逐,请直接为该 Pod 设置 priority 字段。
静态 Pod 不支持 priorityClassName 字段。
当 kubelet 因 inode 或 进程 ID 不足而驱逐 Pod 时, 它使用 Pod 的相对优先级来确定驱逐顺序,因为 inode 和 PID 没有对应的请求字段。
kubelet 根据节点是否具有专用的 imagefs 文件系统对 Pod 进行不同的排序:
有 imagefs
如果 nodefs 触发驱逐,
kubelet 会根据 nodefs 使用情况(本地卷 + 所有容器的日志)对 Pod 进行排序。
如果 imagefs 触发驱逐,kubelet 会根据所有容器的可写层使用情况对 Pod 进行排序。
没有 imagefs
如果 nodefs 触发驱逐,
kubelet 会根据磁盘总用量(本地卷 + 日志和所有容器的可写层)对 Pod 进行排序。
最小驱逐回收
在某些情况下,驱逐 Pod 只会回收少量的紧俏资源。 这可能导致 kubelet 反复达到配置的驱逐条件并触发多次驱逐。
你可以使用 --eviction-minimum-reclaim 标志或
kubelet 配置文件
为每个资源配置最小回收量。
当 kubelet 注意到某个资源耗尽时,它会继续回收该资源,直到回收到你所指定的数量为止。
例如,以下配置设置最小回收量:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
evictionHard:
memory.available: "500Mi"
nodefs.available: "1Gi"
imagefs.available: "100Gi"
evictionMinimumReclaim:
memory.available: "0Mi"
nodefs.available: "500Mi"
imagefs.available: "2Gi"
在这个例子中,如果 nodefs.available 信号满足驱逐条件,
kubelet 会回收资源,直到信号达到 1GiB 的条件,
然后继续回收至少 500MiB 直到信号达到 1.5GiB。
类似地,kubelet 尝试回收 imagefs 资源,直到 imagefs.available 值达到 102Gi,
即 102 GiB 的可用容器镜像存储。如果 kubelet 可以回收的存储量小于 2GiB,
则 kubelet 不会回收任何内容。
对于所有资源,默认的 eviction-minimum-reclaim 为 0。
节点内存不足行为
如果节点在 kubelet 能够回收内存之前遇到内存不足(OOM)事件, 则节点依赖 oom_killer 来响应。
kubelet 根据 Pod 的服务质量(QoS)为每个容器设置一个 oom_score_adj 值。
| 服务质量 | oom_score_adj |
|---|---|
Guaranteed |
-997 |
BestEffort |
1000 |
Burstable |
min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
说明:
kubelet 还将具有 system-node-critical
优先级
的任何 Pod 中的容器 oom_score_adj 值设为 -997。
如果 kubelet 在节点遇到 OOM 之前无法回收内存,
则 oom_killer 根据它在节点上使用的内存百分比计算 oom_score,
然后加上 oom_score_adj 得到每个容器有效的 oom_score。
然后它会杀死得分最高的容器。
这意味着低 QoS Pod 中相对于其调度请求消耗内存较多的容器,将首先被杀死。
与 Pod 驱逐不同,如果容器被 OOM 杀死,
kubelet 可以根据其 restartPolicy 重新启动它。
良好实践
以下各小节阐述驱逐配置的好的做法。
可调度的资源和驱逐策略
当你为 kubelet 配置驱逐策略时, 你应该确保调度程序不会在 Pod 触发驱逐时对其进行调度,因为这类 Pod 会立即引起内存压力。
考虑以下场景:
- 节点内存容量:10GiB
- 操作员希望为系统守护进程(内核、
kubelet等)保留 10% 的内存容量 - 操作员希望在节点内存利用率达到 95% 以上时驱逐 Pod,以减少系统 OOM 的概率。
为此,kubelet 启动设置如下:
--eviction-hard=memory.available<500Mi
--system-reserved=memory=1.5Gi
在此配置中,--system-reserved 标志为系统预留了 1GiB 的内存,
即 总内存的 10% + 驱逐条件量。
如果 Pod 使用的内存超过其请求值或者系统使用的内存超过 1Gi,
则节点可以达到驱逐条件,这使得 memory.available 信号低于 500MiB 并触发条件。
DaemonSets 和节点压力驱逐
Pod 优先级是做出驱逐决定的主要因素。
如果你不希望 kubelet 驱逐属于 DaemonSet 的 Pod,
请在 Pod 规约中通过指定合适的 priorityClassName 为这些 Pod
提供足够高的 priorityClass。
你还可以使用较低优先级或默认优先级,以便
仅在有足够资源时才运行 DaemonSet Pod。
已知问题
以下部分描述了与资源不足处理相关的已知问题。
kubelet 可能不会立即观察到内存压力
默认情况下,kubelet 轮询 cAdvisor 以定期收集内存使用情况统计信息。
如果该轮询时间窗口内内存使用量迅速增加,kubelet 可能无法足够快地观察到 MemoryPressure,
但是 OOM killer 仍将被调用。
你可以使用 --kernel-memcg-notification
标志在 kubelet 上启用 memcg 通知 API,以便在超过条件时立即收到通知。
如果你不是追求极端利用率,而是要采取合理的过量使用措施,
则解决此问题的可行方法是使用 --kube-reserved 和 --system-reserved 标志为系统分配内存。
active_file 内存未被视为可用内存
在 Linux 上,内核跟踪活动最近最少使用(LRU)列表上的基于文件所虚拟的内存字节数作为 active_file 统计信息。
kubelet 将 active_file 内存区域视为不可回收。
对于大量使用块设备形式的本地存储(包括临时本地存储)的工作负载,
文件和块数据的内核级缓存意味着许多最近访问的缓存页面可能被计为 active_file。
如果这些内核块缓冲区中在活动 LRU 列表上有足够多,
kubelet 很容易将其视为资源用量过量并为节点设置内存压力污点,从而触发 Pod 驱逐。
更多细节请参见 https://github.com/kubernetes/kubernetes/issues/43916。
你可以通过为可能执行 I/O 密集型活动的容器设置相同的内存限制和内存请求来应对该行为。 你将需要估计或测量该容器的最佳内存限制值。
接下来
- 了解 API 发起的驱逐
- 了解 Pod 优先级和抢占
- 了解 PodDisruptionBudgets
- 了解服务质量(QoS)
- 查看驱逐 API
10.13 - API 发起的驱逐
API 发起的驱逐是一个先调用
Eviction API
创建 Eviction 对象,再由该对象体面地中止 Pod 的过程。
你可以通过直接调用 Eviction API 发起驱逐,也可以通过编程的方式使用
API 服务器的客户端来发起驱逐,
比如 kubectl drain 命令。
此操作创建一个 Eviction 对象,该对象再驱动 API 服务器终止选定的 Pod。
API 发起的驱逐将遵从你的
PodDisruptionBudgets
和 terminationGracePeriodSeconds
配置。
使用 API 创建 Eviction 对象,就像对 Pod 执行策略控制的
DELETE 操作
调用 Eviction API
你可以使用 Kubernetes 语言客户端
来访问 Kubernetes API 并创建 Eviction 对象。
要执行此操作,你应该用 POST 发出要尝试的请求,类似于下面的示例:
说明:
policy/v1 版本的 Eviction 在 v1.22 以及更高的版本中可用,之前的发行版本使用 policy/v1beta1 版本。
{
"apiVersion": "policy/v1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
说明:
在 v1.22 版本废弃以支持 policy/v1。
{
"apiVersion": "policy/v1beta1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
或者,你可以通过使用 curl 或者 wget 来访问 API 以尝试驱逐操作,类似于以下示例:
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
API 发起驱逐的工作原理
当你使用 API 来请求驱逐时,API 服务器将执行准入检查,并通过以下方式之一做出响应:
200 OK:允许驱逐,子资源Eviction被创建,并且 Pod 被删除, 类似于发送一个DELETE请求到 Pod 地址。429 Too Many Requests:当前不允许驱逐,因为配置了 PodDisruptionBudget。 你可以稍后再尝试驱逐。你也可能因为 API 速率限制而看到这种响应。500 Internal Server Error:不允许驱逐,因为存在配置错误, 例如存在多个 PodDisruptionBudgets 引用同一个 Pod。
如果你想驱逐的 Pod 不属于有 PodDisruptionBudget 的工作负载,
API 服务器总是返回 200 OK 并且允许驱逐。
如果 API 服务器允许驱逐,Pod 按照如下方式删除:
- API 服务器中的
Pod资源会更新上删除时间戳,之后 API 服务器会认为此Pod资源将被终止。 此Pod资源还会标记上配置的宽限期。 - 本地运行状态的 Pod 所处的节点上的 kubelet
注意到
Pod资源被标记为终止,并开始优雅停止本地 Pod。 - 当 kubelet 停止 Pod 时,控制面从 Endpoint 和 EndpointSlice 对象中移除该 Pod。因此,控制器不再将此 Pod 视为有用对象。
- Pod 的宽限期到期后,kubelet 强制终止本地 Pod。
- kubelet 告诉 API 服务器删除
Pod资源。 - API 服务器删除
Pod资源。
解决驱逐被卡住的问题
在某些情况下,你的应用可能进入中断状态,
在你干预之前,驱逐 API 总是返回 429 或 500。
例如,如果 ReplicaSet 为你的应用程序创建了 Pod,
但新的 Pod 没有进入 Ready 状态,就会发生这种情况。
在最后一个被驱逐的 Pod 有很长的终止宽限期的情况下,你可能也会注意到这种行为。
如果你注意到驱逐被卡住,请尝试以下解决方案之一:
- 终止或暂停导致问题的自动化操作,重新启动操作之前,请检查被卡住的应用程序。
- 等待一段时间后,直接从集群控制平面删除 Pod,而不是使用 Eviction API。
接下来
- 了解如何使用 Pod 干扰预算保护你的应用。
- 了解节点压力引发的驱逐。
- 了解 Pod 优先级和抢占。
11 - 集群管理
关于创建和管理 Kubernetes 集群的底层细节。
集群管理概述面向任何创建和管理 Kubernetes 集群的读者人群。 我们假设你大概了解一些核心的 Kubernetes 概念。
规划集群
查阅安装中的指导,获取如何规划、建立以及配置 Kubernetes 集群的示例。本文所列的文章称为发行版。
说明:
并非所有发行版都是被积极维护的。 请选择使用最近 Kubernetes 版本测试过的发行版。
在选择一个指南前,有一些因素需要考虑:
- 你是打算在你的计算机上尝试 Kubernetes,还是要构建一个高可用的多节点集群? 请选择最适合你需求的发行版。
- 你正在使用类似 Google Kubernetes Engine 这样的被托管的 Kubernetes 集群, 还是管理你自己的集群?
- 你的集群是在本地还是云(IaaS) 上?Kubernetes 不能直接支持混合集群。 作为代替,你可以建立多个集群。
- 如果你在本地配置 Kubernetes, 需要考虑哪种网络模型最适合。
- 你的 Kubernetes 在裸机上还是虚拟机(VM) 上运行?
- 你是想运行一个集群,还是打算参与开发 Kubernetes 项目代码? 如果是后者,请选择一个处于开发状态的发行版。 某些发行版只提供二进制发布版,但提供更多的选择。
- 让你自己熟悉运行一个集群所需的组件。
管理集群
保护集群
- 生成证书描述了使用不同的工具链生成证书的步骤。
- Kubernetes 容器环境描述了 Kubernetes 节点上由 Kubelet 管理的容器的环境。
- 控制对 Kubernetes API 的访问描述了 Kubernetes 如何为自己的 API 实现访问控制。
- 身份认证阐述了 Kubernetes 中的身份认证功能,包括许多认证选项。
- 鉴权与身份认证不同,用于控制如何处理 HTTP 请求。
- 使用准入控制器阐述了在认证和授权之后拦截到 Kubernetes API 服务的请求的插件。
- 在 Kubernetes 集群中使用 sysctl
描述了管理员如何使用
sysctl命令行工具来设置内核参数。 - 审计描述了如何与 Kubernetes 的审计日志交互。
保护 kubelet
可选集群服务
11.1 - 证书
要了解如何为集群生成证书,参阅证书。
11.2 - 管理资源
你已经部署了应用并通过服务暴露它。然后呢? Kubernetes 提供了一些工具来帮助管理你的应用部署,包括扩缩容和更新。
组织资源配置
许多应用需要创建多个资源,例如 Deployment 和 Service。
可以通过将多个资源组合在同一个文件中(在 YAML 中以 --- 分隔)
来简化对它们的管理。例如:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
可以用创建单个资源相同的方式来创建多个资源:
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
资源将按照它们在文件中的顺序创建。 因此,最好先指定服务,这样在控制器(例如 Deployment)创建 Pod 时能够 确保调度器可以将与服务关联的多个 Pod 分散到不同节点。
kubectl apply 也接受多个 -f 参数:
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml \
-f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
建议的做法是,将同一个微服务或同一应用层相关的资源放到同一个文件中, 将同一个应用相关的所有文件按组存放到同一个目录中。 如果应用的各层使用 DNS 相互绑定,你可以将堆栈的所有组件一起部署。
还可以使用 URL 作为配置源,便于直接使用已经提交到 GitHub 上的配置文件进行部署:
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
kubectl 中的批量操作
资源创建并不是 kubectl 可以批量执行的唯一操作。
kubectl 还可以从配置文件中提取资源名,以便执行其他操作,
特别是删除你之前创建的资源:
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
在仅有两种资源的情况下,你可以使用"资源类型/资源名"的语法在命令行中 同时指定这两个资源:
kubectl delete deployments/my-nginx services/my-nginx-svc
对于资源数目较大的情况,你会发现使用 -l 或 --selector
指定筛选器(标签查询)能很容易根据标签筛选资源:
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
由于 kubectl 用来输出资源名称的语法与其所接受的资源名称语法相同,
你可以使用 $() 或 xargs 进行链式操作:
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service | xargs -i kubectl get {}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
上面的命令中,我们首先使用 examples/application/nginx/ 下的配置文件创建资源,
并使用 -o name 的输出格式(以"资源/名称"的形式打印每个资源)打印所创建的资源。
然后,我们通过 grep 来过滤 "service",最后再打印 kubectl get 的内容。
如果你碰巧在某个路径下的多个子路径中组织资源,那么也可以递归地在所有子路径上
执行操作,方法是在 --filename,-f 后面指定 --recursive 或者 -R。
例如,假设有一个目录路径为 project/k8s/development,它保存开发环境所需的
所有清单,并按资源类型组织:
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
默认情况下,对 project/k8s/development 执行的批量操作将停止在目录的第一级,
而不是处理所有子目录。
如果我们试图使用以下命令在此目录中创建资源,则会遇到一个错误:
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
正确的做法是,在 --filename,-f 后面标明 --recursive 或者 -R 之后:
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
--recursive 可以用于接受 --filename,-f 参数的任何操作,例如:
kubectl {create,get,delete,describe,rollout} 等。
有多个 -f 参数出现的时候,--recursive 参数也能正常工作:
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
如果你有兴趣进一步学习关于 kubectl 的内容,请阅读命令行工具(kubectl)。
金丝雀部署(Canary Deployments)
另一个需要多标签的场景是用来区分同一组件的不同版本或者不同配置的多个部署。 常见的做法是部署一个使用金丝雀发布来部署新应用版本 (在 Pod 模板中通过镜像标签指定),保持新旧版本应用同时运行。 这样,新版本在完全发布之前也可以接收实时的生产流量。
例如,你可以使用 track 标签来区分不同的版本。
主要稳定的发行版将有一个 track 标签,其值为 stable:
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
然后,你可以创建 guestbook 前端的新版本,让这些版本的 track 标签带有不同的值
(即 canary),以便两组 Pod 不会重叠:
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
前端服务通过选择标签的公共子集(即忽略 track 标签)来覆盖两组副本,
以便流量可以转发到两个应用:
selector:
app: guestbook
tier: frontend
你可以调整 stable 和 canary 版本的副本数量,以确定每个版本将接收
实时生产流量的比例(在本例中为 3:1)。
一旦有信心,你就可以将新版本应用的 track 标签的值从
canary 替换为 stable,并且将老版本应用删除。
想要了解更具体的示例,请查看 Ghost 部署教程。
更新注解
有时,你可能希望将注解附加到资源中。注解是 API 客户端(如工具、库等)
用于检索的任意非标识元数据。这可以通过 kubectl annotate 来完成。例如:
kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
想要了解更多信息,请参考注解和
kubectl annotate
命令文档。
扩缩你的应用
当应用上的负载增长或收缩时,使用 kubectl 能够实现应用规模的扩缩。
例如,要将 nginx 副本的数量从 3 减少到 1,请执行以下操作:
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
现在,你的 Deployment 管理的 Pod 只有一个了。
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
想要让系统自动选择需要 nginx 副本的数量,范围从 1 到 3,请执行以下操作:
kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
现在,你的 nginx 副本将根据需要自动地增加或者减少。
想要了解更多信息,请参考 kubectl scale命令文档、 kubectl autoscale 命令文档和水平 Pod 自动伸缩文档。
就地更新资源
有时,有必要对你所创建的资源进行小范围、无干扰地更新。
kubectl apply
建议在源代码管理中维护一组配置文件
(参见配置即代码),
这样,它们就可以和应用代码一样进行维护和版本管理。
然后,你可以用 kubectl apply
将配置变更应用到集群中。
这个命令将会把推送的版本与以前的版本进行比较,并应用你所做的更改, 但是不会自动覆盖任何你没有指定更改的属性。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
注意,kubectl apply 将为资源增加一个额外的注解,以确定自上次调用以来对配置的更改。
执行时,kubectl apply 会在以前的配置、提供的输入和资源的当前配置之间
找出三方差异,以确定如何修改资源。
目前,新创建的资源是没有这个注解的,所以,第一次调用 kubectl apply 时
将使用提供的输入和资源的当前配置双方之间差异进行比较。
在第一次调用期间,它无法检测资源创建时属性集的删除情况。
因此,kubectl 不会删除它们。
所有后续的 kubectl apply 操作以及其他修改配置的命令,如 kubectl replace
和 kubectl edit,都将更新注解,并允许随后调用的 kubectl apply
使用三方差异进行检查和执行删除。
kubectl edit
或者,你也可以使用 kubectl edit 更新资源:
kubectl edit deployment/my-nginx
这相当于首先 get 资源,在文本编辑器中编辑它,然后用更新的版本 apply 资源:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# 做一些编辑,然后保存文件
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
这使你可以更加容易地进行更重大的更改。
请注意,可以使用 EDITOR 或 KUBE_EDITOR 环境变量来指定编辑器。
想要了解更多信息,请参考 kubectl edit 文档。
kubectl patch
你可以使用 kubectl patch 来更新 API 对象。此命令支持 JSON patch、
JSON merge patch、以及 strategic merge patch。
请参考使用 kubectl patch 更新 API 对象和
kubectl patch。
破坏性的更新
在某些情况下,你可能需要更新某些初始化后无法更新的资源字段,或者你可能只想立即进行递归更改,
例如修复 Deployment 创建的不正常的 Pod。若要更改这些字段,请使用 replace --force,
它将删除并重新创建资源。在这种情况下,你可以修改原始配置文件:
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
在不中断服务的情况下更新应用
在某些时候,你最终需要更新已部署的应用,通常都是通过指定新的镜像或镜像标签,
如上面的金丝雀发布的场景中所示。kubectl 支持几种更新操作,
每种更新操作都适用于不同的场景。
我们将指导你通过 Deployment 如何创建和更新应用。
假设你正运行的是 1.14.2 版本的 nginx:
kubectl create deployment my-nginx --image=nginx:1.14.2
deployment.apps/my-nginx created
运行 3 个副本(这样新旧版本可以同时存在)
kubectl scale deployment my-nginx --current-replicas=1 --replicas=3
deployment.apps/my-nginx scaled
要更新到 1.16.1 版本,只需使用我们前面学到的 kubectl 命令将
.spec.template.spec.containers[0].image 从 nginx:1.14.2 修改为 nginx:1.16.1。
kubectl edit deployment/my-nginx
没错,就是这样!Deployment 将在后台逐步更新已经部署的 nginx 应用。 它确保在更新过程中,只有一定数量的旧副本被开闭,并且只有一定基于所需 Pod 数量的新副本被创建。 想要了解更多细节,请参考 Deployment。
接下来
11.3 - 集群网络系统
集群网络系统是 Kubernetes 的核心部分,但是想要准确了解它的工作原理可是个不小的挑战。 下面列出的是网络系统的的四个主要问题:
- 高度耦合的容器间通信:这个已经被 Pod
和
localhost通信解决了。 - Pod 间通信:这是本文档讲述的重点。
- Pod 与 Service 间通信:涵盖在 Service 中。
- 外部与 Service 间通信:也涵盖在 Service 中。
Kubernetes 的宗旨就是在应用之间共享机器。 通常来说,共享机器需要两个应用之间不能使用相同的端口,但是在多个应用开发者之间 去大规模地协调端口是件很困难的事情,尤其是还要让用户暴露在他们控制范围之外的集群级别的问题上。
动态分配端口也会给系统带来很多复杂度 - 每个应用都需要设置一个端口的参数, 而 API 服务器还需要知道如何将动态端口数值插入到配置模块中,服务也需要知道如何找到对方等等。 与其去解决这些问题,Kubernetes 选择了其他不同的方法。
要了解 Kubernetes 网络模型,请参阅此处。
Kubernetes IP 地址范围
Kubernetes 集群需要从以下组件中配置的可用地址范围中为 Pod、Service 和 Node 分配不重叠的 IP 地址:
- 网络插件配置为向 Pod 分配 IP 地址。
- kube-apiserver 配置为向 Service 分配 IP 地址。
- kubelet 或 cloud-controller-manager 配置为向 Node 分配 IP 地址。

集群网络类型
根据配置的 IP 协议族,Kubernetes 集群可以分为以下几类:
- 仅 IPv4:网络插件、kube-apiserver 和 kubelet/cloud-controller-manager 配置为仅分配 IPv4 地址。
- 仅 IPv6:网络插件、kube-apiserver 和 kubelet/cloud-controller-manager 配置为仅分配 IPv6 地址。
- IPv4/IPv6 或 IPv6/IPv4 双协议栈:
- 网络插件配置为分配 IPv4 和 IPv6 地址。
- kube-apiserver 配置为分配 IPv4 和 IPv6 地址。
- kubelet 或 cloud-controller-manager 配置为分配 IPv4 和 IPv6 地址。
- 所有组件必须就配置的主要 IP 协议族达成一致。
Kubernetes 集群只考虑 Pod、Service 和 Node 对象中存在的 IP 协议族,而不考虑所表示对象的现有 IP。
例如,服务器或 Pod 的接口上可以有多个 IP 地址,但只有 node.status.addresses 或 pod.status.ips
中的 IP 地址被认为是实现 Kubernetes 网络模型和定义集群类型的。
如何实现 Kubernetes 的网络模型
网络模型由各节点上的容器运行时来实现。最常见的容器运行时使用 Container Network Interface (CNI) 插件来管理其网络和安全能力。 来自不同供应商 CNI 插件有很多。其中一些仅提供添加和删除网络接口的基本功能, 而另一些则提供更复杂的解决方案,例如与其他容器编排系统集成、运行多个 CNI 插件、高级 IPAM 功能等。
请参阅此页面了解 Kubernetes 支持的网络插件的非详尽列表。
接下来
网络模型的早期设计、运行原理都在联网设计文档里有详细描述。 关于未来的计划,以及旨在改进 Kubernetes 联网能力的一些正在进行的工作,可以参考 SIG Network 的 KEPs。
11.4 - 日志架构
应用日志可以让你了解应用内部的运行状况。日志对调试问题和监控集群活动非常有用。 大部分现代化应用都有某种日志记录机制。同样地,容器引擎也被设计成支持日志记录。 针对容器化应用,最简单且最广泛采用的日志记录方式就是写入标准输出和标准错误流。
但是,由容器引擎或运行时提供的原生功能通常不足以构成完整的日志记录方案。
例如,如果发生容器崩溃、Pod 被逐出或节点宕机等情况,你可能想访问应用日志。
在集群中,日志应该具有独立的存储,并且其生命周期与节点、Pod 或容器的生命周期相独立。 这个概念叫集群级的日志。
集群级日志架构需要一个独立的后端用来存储、分析和查询日志。 Kubernetes 并不为日志数据提供原生的存储解决方案。 相反,有很多现成的日志方案可以集成到 Kubernetes 中。 下面各节描述如何在节点上处理和存储日志。
Pod 和容器日志
Kubernetes 从正在运行的 Pod 中捕捉每个容器的日志。
此示例使用带有一个容器的 Pod 的清单,该容器每秒将文本写入标准输出一次。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
要运行此 Pod,请执行以下命令:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
输出为:
pod/counter created
要获取这些日志,请执行以下 kubectl logs 命令:
kubectl logs counter
输出类似于:
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
你可以使用 kubectl logs --previous 从容器的先前实例中检索日志。
如果你的 Pod 有多个容器,请如下通过将容器名称追加到该命令并使用 -c
标志来指定要访问哪个容器的日志:
kubectl logs counter -c count
详见 kubectl logs 文档。
节点的容器日志处理方式
容器运行时对写入到容器化应用程序的 stdout 和 stderr 流的所有输出进行处理和转发。
不同的容器运行时以不同的方式实现这一点;不过它们与 kubelet 的集成都被标准化为 CRI 日志格式。
默认情况下,如果容器重新启动,kubelet 会保留一个终止的容器及其日志。 如果一个 Pod 被逐出节点,所对应的所有容器及其日志也会被逐出。
kubelet 通过 Kubernetes API 的特殊功能将日志提供给客户端访问。
访问这个日志的常用方法是运行 kubectl logs。
日志轮转
特性状态:
Kubernetes v1.21 [stable]
你可以配置 kubelet 令其自动轮转日志。
如果配置轮转,kubelet 负责轮转容器日志并管理日志目录结构。 kubelet(使用 CRI)将此信息发送到容器运行时,而运行时则将容器日志写到给定位置。
你可以使用 kubelet 配置文件配置两个
kubelet 配置选项、
containerLogMaxSize 和 containerLogMaxFiles。
这些设置分别允许你分别配置每个日志文件大小的最大值和每个容器允许的最大文件数。
当类似于基本日志示例一样运行 kubectl logs 时,
节点上的 kubelet 会处理请求并直接从日志文件读取。kubelet 将返回该日志文件的内容。
说明:
只有最新的日志文件的内容可以通过 kubectl logs 获得。
例如,如果 Pod 写入 40 MiB 的日志,并且 kubelet 在 10 MiB 之后轮转日志,
则运行 kubectl logs 将最多返回 10 MiB 的数据。
系统组件日志
系统组件有两种类型:通常在容器中运行的组件和直接参与容器运行的组件。例如:
- kubelet 和容器运行时不在容器中运行。kubelet 运行你的容器 (一起按 Pod 分组)
- Kubernetes 调度器、控制器管理器和 API 服务器在 Pod 中运行
(通常是静态 Pod。
etcd 组件在控制平面中运行,最常见的也是作为静态 Pod。
如果你的集群使用 kube-proxy,则通常将其作为
DaemonSet运行。
日志位置
kubelet 和容器运行时写入日志的方式取决于节点使用的操作系统:
在使用 systemd 的 Linux 节点上,kubelet 和容器运行时默认写入 journald。
你要使用 journalctl 来阅读 systemd 日志;例如:journalctl -u kubelet。
如果 systemd 不存在,kubelet 和容器运行时将写入到 /var/log 目录中的 .log 文件。
如果你想将日志写入其他地方,你可以通过辅助工具 kube-log-runner 间接运行 kubelet,
并使用该工具将 kubelet 日志重定向到你所选择的目录。
kubelet 始终指示你的容器运行时将日志写入 /var/log/pods 中的目录。
有关 kube-log-runner 的更多信息,请阅读系统日志。
默认情况下,kubelet 将日志写入目录 C:\var\logs 中的文件(注意这不是 C:\var\log)。
尽管 C:\var\log 是这些日志的 Kubernetes 默认位置,
但一些集群部署工具会将 Windows 节点设置为将日志放到 C:\var\log\kubelet。
如果你想将日志写入其他地方,你可以通过辅助工具 kube-log-runner 间接运行 kubelet,
并使用该工具将 kubelet 日志重定向到你所选择的目录。
但是,kubelet 总是指示你的容器运行时在目录 C:\var\log\pods 中写入日志。
有关 kube-log-runner 的更多信息,请阅读系统日志。
对于在 Pod 中运行的 Kubernetes 集群组件,其日志会写入 /var/log 目录中的文件,
相当于绕过默认的日志机制(组件不会写入 systemd 日志)。
你可以使用 Kubernetes 的存储机制将持久存储映射到运行该组件的容器中。
有关 etcd 及其日志的详细信息,请查阅 etcd 文档。 同样,你可以使用 Kubernetes 的存储机制将持久存储映射到运行该组件的容器中。
说明:
如果你部署 Kubernetes 集群组件(例如调度器)以将日志记录到从父节点共享的卷中, 则需要考虑并确保这些日志被轮转。 Kubernetes 不管理这种日志轮转。
你的操作系统可能会自动实现一些日志轮转。例如,如果你将目录 /var/log 共享到一个组件的静态 Pod 中,
则节点级日志轮转会将该目录中的文件视同为 Kubernetes 之外的组件所写入的文件。
一些部署工具会考虑日志轮转并将其自动化;而其他一些工具会将此留给你来处理。
集群级日志架构
虽然 Kubernetes 没有为集群级日志记录提供原生的解决方案,但你可以考虑几种常见的方法。 以下是一些选项:
- 使用在每个节点上运行的节点级日志记录代理。
- 在应用程序的 Pod 中,包含专门记录日志的边车(Sidecar)容器。
- 将日志直接从应用程序中推送到日志记录后端。
使用节点级日志代理
你可以通过在每个节点上使用节点级的日志记录代理来实现集群级日志记录。 日志记录代理是一种用于暴露日志或将日志推送到后端的专用工具。 通常,日志记录代理程序是一个容器,它可以访问包含该节点上所有应用程序容器的日志文件的目录。
由于日志记录代理必须在每个节点上运行,推荐以 DaemonSet 的形式运行该代理。
节点级日志在每个节点上仅创建一个代理,不需要对节点上的应用做修改。
容器向标准输出和标准错误输出写出数据,但在格式上并不统一。 节点级代理收集这些日志并将其进行转发以完成汇总。
使用边车容器运行日志代理
你可以通过以下方式之一使用边车(Sidecar)容器:
- 边车容器将应用程序日志传送到自己的标准输出。
- 边车容器运行一个日志代理,配置该日志代理以便从应用容器收集日志。
传输数据流的边车容器
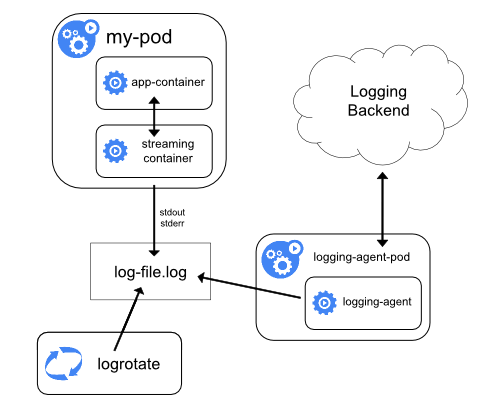
利用边车容器,写入到自己的 stdout 和 stderr 传输流,
你就可以利用每个节点上的 kubelet 和日志代理来处理日志。
边车容器从文件、套接字或 journald 读取日志。
每个边车容器向自己的 stdout 和 stderr 流中输出日志。
这种方法允许你将日志流从应用程序的不同部分分离开,其中一些可能缺乏对写入
stdout 或 stderr 的支持。重定向日志背后的逻辑是最小的,因此它的开销不大。
另外,因为 stdout 和 stderr 由 kubelet 处理,所以你可以使用内置的工具 kubectl logs。
例如,某 Pod 中运行一个容器,且该容器使用两个不同的格式写入到两个不同的日志文件。 下面是这个 Pod 的清单:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
不建议在同一个日志流中写入不同格式的日志条目,即使你成功地将其重定向到容器的 stdout 流。
相反,你可以创建两个边车容器。每个边车容器可以从共享卷跟踪特定的日志文件,
并将文件内容重定向到各自的 stdout 流。
下面是运行两个边车容器的 Pod 的清单:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
现在当你运行这个 Pod 时,你可以运行如下命令分别访问每个日志流:
kubectl logs counter count-log-1
输出类似于:
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
输出类似于:
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
如果你在集群中安装了节点级代理,由代理自动获取上述日志流,而无需任何进一步的配置。 如果你愿意,你可以将代理配置为根据源容器解析日志行。
即使对于 CPU 和内存使用率较低的 Pod(CPU 为几毫核,内存为几兆字节),将日志写入一个文件,
将这些日志流写到 stdout 也有可能使节点所需的存储量翻倍。
如果你有一个写入特定文件的应用程序,则建议将 /dev/stdout 设置为目标文件,而不是采用流式边车容器方法。
边车容器还可用于轮转应用程序本身无法轮转的日志文件。
这种方法的一个例子是定期运行 logrotate 的小容器。
但是,直接使用 stdout 和 stderr 更直接,而将轮转和保留策略留给 kubelet。
集群中安装的节点级代理会自动获取这些日志流,而无需进一步配置。 如果你愿意,你也可以配置代理程序来解析源容器的日志行。
注意,尽管 CPU 和内存使用率都很低(以多个 CPU 毫核指标排序或者按内存的兆字节排序),
向文件写日志然后输出到 stdout 流仍然会成倍地增加磁盘使用率。
如果你的应用向单一文件写日志,通常最好设置 /dev/stdout 作为目标路径,
而不是使用流式的边车容器方式。
如果应用程序本身不能轮转日志文件,则可以通过边车容器实现。
这种方式的一个例子是运行一个小的、定期轮转日志的容器。
然而,还是推荐直接使用 stdout 和 stderr,将日志的轮转和保留策略交给 kubelet。
具有日志代理功能的边车容器
如果节点级日志记录代理程序对于你的场景来说不够灵活, 你可以创建一个带有单独日志记录代理的边车容器,将代理程序专门配置为与你的应用程序一起运行。
说明:
在边车容器中使用日志代理会带来严重的资源损耗。
此外,你不能使用 kubectl logs 访问日志,因为日志并没有被 kubelet 管理。
下面是两个配置文件,可以用来实现一个带日志代理的边车容器。 第一个文件包含用来配置 fluentd 的 ConfigMap。
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
说明:
你可以将此示例配置中的 fluentd 替换为其他日志代理,从应用容器内的其他来源读取数据。
第二个清单描述了一个运行 fluentd 边车容器的 Pod。 该 Pod 挂载一个卷,flutend 可以从这个卷上拣选其配置数据。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
从应用中直接暴露日志目录
从各个应用中直接暴露和推送日志数据的集群日志机制已超出 Kubernetes 的范围。
接下来
- 阅读有关 Kubernetes 系统日志的信息
- 进一步了解追踪 Kubernetes 系统组件
- 了解当 Pod 失效时如何定制 Kubernetes 记录的终止消息
11.5 - Kubernetes 系统组件指标
通过系统组件指标可以更好地了解系统组个内部发生的情况。系统组件指标对于构建仪表板和告警特别有用。
Kubernetes 组件以 Prometheus 格式生成度量值。 这种格式是结构化的纯文本,旨在使人和机器都可以阅读。
Kubernetes 中组件的指标
在大多数情况下,可以通过 HTTP 访问组件的 /metrics 端点来获取组件的度量值。
对于那些默认情况下不暴露端点的组件,可以使用 --bind-address 标志启用。
这些组件的示例:
在生产环境中,你可能需要配置 Prometheus 服务器或 某些其他指标搜集器以定期收集这些指标,并使它们在某种时间序列数据库中可用。
请注意,kubelet 还会在 /metrics/cadvisor,
/metrics/resource 和 /metrics/probes 端点中公开度量值。这些度量值的生命周期各不相同。
如果你的集群使用了 RBAC,
则读取指标需要通过基于用户、组或 ServiceAccount 的鉴权,要求具有允许访问
/metrics 的 ClusterRole。
例如:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- nonResourceURLs:
- "/metrics"
verbs:
- get
指标生命周期
Alpha 指标 → 稳定的指标 → 弃用的指标 → 隐藏的指标 → 删除的指标
Alpha 指标没有稳定性保证。这些指标可以随时被修改或者删除。
稳定的指标可以保证不会改变。这意味着:
- 稳定的、不包含已弃用(deprecated)签名的指标不会被删除(或重命名)
- 稳定的指标的类型不会被更改
已弃用的指标最终将被删除,不过仍然可用。 这类指标包含注解,标明其被废弃的版本。
例如:
-
被弃用之前:
# HELP some_counter this counts things # TYPE some_counter counter some_counter 0
-
被弃用之后:
# HELP some_counter (Deprecated since 1.15.0) this counts things # TYPE some_counter counter some_counter 0
隐藏的指标不会再被发布以供抓取,但仍然可用。 要使用隐藏指标,请参阅显式隐藏指标节。
删除的指标不再被发布,亦无法使用。
显示隐藏指标
如上所述,管理员可以通过设置可执行文件的命令行参数来启用隐藏指标, 如果管理员错过了上一版本中已经弃用的指标的迁移,则可以把这个用作管理员的逃生门。
show-hidden-metrics-for-version 标志接受版本号作为取值,版本号给出
你希望显示该发行版本中已弃用的指标。
版本表示为 x.y,其中 x 是主要版本,y 是次要版本。补丁程序版本不是必须的,
即使指标可能会在补丁程序发行版中弃用,原因是指标弃用策略规定仅针对次要版本。
该参数只能使用前一个次要版本。如果管理员将先前版本设置为 show-hidden-metrics-for-version,
则先前版本中隐藏的度量值会再度生成。不允许使用过旧的版本,因为那样会违反指标弃用策略。
以指标 A 为例,此处假设 A 在 1.n 中已弃用。根据指标弃用策略,我们可以得出以下结论:
- 在版本
1.n中,这个指标已经弃用,且默认情况下可以生成。 - 在版本
1.n+1中,这个指标默认隐藏,可以通过命令行参数show-hidden-metrics-for-version=1.n来再度生成。 - 在版本
1.n+2中,这个指标就将被从代码中移除,不会再有任何逃生窗口。
如果你要从版本 1.12 升级到 1.13,但仍依赖于 1.12 中弃用的指标 A,则应通过命令行设置隐藏指标:
--show-hidden-metrics=1.12,并记住在升级到 1.14 版本之前删除此指标依赖项。
组件指标
kube-controller-manager 指标
控制器管理器指标可提供有关控制器管理器性能和运行状况的重要洞察。 这些指标包括通用的 Go 语言运行时指标(例如 go_routine 数量)和控制器特定的度量指标, 例如可用于评估集群运行状况的 etcd 请求延迟或云提供商(AWS、GCE、OpenStack)的 API 延迟等。
从 Kubernetes 1.7 版本开始,详细的云提供商指标可用于 GCE、AWS、Vsphere 和 OpenStack 的存储操作。 这些指标可用于监控持久卷操作的运行状况。
比如,对于 GCE,这些指标称为:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
kube-scheduler 指标
特性状态:
Kubernetes v1.21 [beta]
调度器会暴露一些可选的指标,报告所有运行中 Pod 所请求的资源和期望的约束值。 这些指标可用来构造容量规划监控面板、访问调度约束的当前或历史数据、 快速发现因为缺少资源而无法被调度的负载,或者将 Pod 的实际资源用量与其请求值进行比较。
kube-scheduler 组件能够辩识各个 Pod 所配置的资源 请求和约束。 在 Pod 的资源请求值或者约束值非零时,kube-scheduler 会以度量值时间序列的形式 生成报告。该时间序列值包含以下标签:
- 名字空间
- Pod 名称
- Pod 调度所处节点,或者当 Pod 未被调度时用空字符串表示
- 优先级
- 为 Pod 所指派的调度器
- 资源的名称(例如,
cpu) - 资源的单位,如果知道的话(例如,
cores)
一旦 Pod 进入完成状态(其 restartPolicy 为 Never 或 OnFailure,且
其处于 Succeeded 或 Failed Pod 阶段,或者已经被删除且所有容器都具有
终止状态),该时间序列停止报告,因为调度器现在可以调度其它 Pod 来执行。
这两个指标称作 kube_pod_resource_request 和 kube_pod_resource_limit。
指标暴露在 HTTP 端点 /metrics/resources,与调度器上的 /metrics 端点
一样要求相同的访问授权。你必须使用
--show-hidden-metrics-for-version=1.20 标志才能暴露那些稳定性为 Alpha
的指标。
禁用指标
你可以通过命令行标志 --disabled-metrics 来关闭某指标。
在例如某指标会带来性能问题的情况下,这一操作可能是有用的。
标志的参数值是一组被禁止的指标(例如:--disabled-metrics=metric1,metric2)。
指标顺序性保证
在 Alpha 阶段,标志只能接受一组映射值作为可以使用的指标标签。
每个映射值的格式为<指标名称>,<标签名称>=<可用标签列表>,其中
<可用标签列表> 是一个用逗号分隔的、可接受的标签名的列表。
最终的格式看起来会是这样:
--allow-label-value <指标名称>,<标签名称>='<可用值1>,<可用值2>...', <指标名称2>,<标签名称>='<可用值1>, <可用值2>...', ...
下面是一个例子:
--allow-label-value number_count_metric,odd_number='1,3,5', number_count_metric,even_number='2,4,6', date_gauge_metric,weekend='Saturday,Sunday'
除了从 CLI 中指定之外,还可以在配置文件中完成此操作。
你可以使用组件的 --allow-metric-labels-manifest 命令行参数指定该配置文件的路径。
以下是该配置文件的内容示例:
allow-list:
- "metric1,label2": "v1,v2,v3"
- "metric2,label1": "v1,v2,v3"
此外,cardinality_enforcement_unexpected_categorizations_total
元指标记录基数执行期间意外分类的计数,即每当遇到允许列表约束不允许的标签值时。
接下来
- 阅读有关指标的 Prometheus 文本格式
- 阅读有关 Kubernetes 弃用策略
11.6 - 系统日志
系统组件的日志记录集群中发生的事件,这对于调试非常有用。 你可以配置日志的精细度,以展示更多或更少的细节。 日志可以是粗粒度的,如只显示组件内的错误, 也可以是细粒度的,如显示事件的每一个跟踪步骤(比如 HTTP 访问日志、pod 状态更新、控制器动作或调度器决策)。
警告:
与此处描述的命令行标志不同,日志输出本身不属于 Kubernetes API 的稳定性保证范围: 单个日志条目及其格式可能会在不同版本之间发生变化!
Klog
klog 是 Kubernetes 的日志库。 klog 为 Kubernetes 系统组件生成日志消息。
Kubernetes 正在进行简化其组件日志的努力。下面的 klog 命令行参数从 Kubernetes v1.23 开始已被废弃, 在 Kubernetes v1.26 中被移除:
--add-dir-header--alsologtostderr--log-backtrace-at--log-dir--log-file--log-file-max-size--logtostderr--one-output--skip-headers--skip-log-headers--stderrthreshold
输出总会被写到标准错误输出(stderr)之上,无论输出格式如何。 对输出的重定向将由调用 Kubernetes 组件的软件来处理。 这一软件可以是 POSIX Shell 或者类似 systemd 这样的工具。
在某些场合下,例如对于无发行主体的(distroless)容器或者 Windows 系统服务,
这些替代方案都是不存在的。那么你可以使用
kube-log-runner
可执行文件来作为 Kubernetes 的封装层,完成对输出的重定向。
在很多 Kubernetes 基础镜像中,都包含一个预先构建的可执行程序。
这个程序原来称作 /go-runner,而在服务器和节点的发行版本库中,称作 kube-log-runner。
下表展示的是 kube-log-runner 调用与 Shell 重定向之间的对应关系:
| 用法 | POSIX Shell(例如 Bash) | kube-log-runner <options> <cmd> |
|---|---|---|
| 合并 stderr 与 stdout,写出到 stdout | 2>&1 |
kube-log-runner(默认行为 ) |
| 将 stderr 与 stdout 重定向到日志文件 | 1>>/tmp/log 2>&1 |
kube-log-runner -log-file=/tmp/log |
| 输出到 stdout 并复制到日志文件中 | 2>&1 | tee -a /tmp/log |
kube-log-runner -log-file=/tmp/log -also-stdout |
| 仅将 stdout 重定向到日志 | >/tmp/log |
kube-log-runner -log-file=/tmp/log -redirect-stderr=false |
klog 输出
传统的 klog 原生格式示例:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
消息字符串可能包含换行符:
I1025 00:15:15.525108 1 example.go:79] This is a message
which has a line break.
结构化日志
特性状态:
Kubernetes v1.23 [beta]
警告:
迁移到结构化日志消息是一个正在进行的过程。在此版本中,并非所有日志消息都是结构化的。 解析日志文件时,你也必须要处理非结构化日志消息。
日志格式和值的序列化可能会发生变化。
结构化日志记录旨在日志消息中引入统一结构,以便以编程方式提取信息。 你可以方便地用更小的开销来处理结构化日志。 生成日志消息的代码决定其使用传统的非结构化的 klog 还是结构化的日志。
默认的结构化日志消息是以文本形式呈现的,其格式与传统的 klog 保持向后兼容:
<klog header> "<message>" <key1>="<value1>" <key2>="<value2>" ...
示例:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
字符串在输出时会被添加引号。其他数值类型都使用 %+v
来格式化,因此可能导致日志消息会延续到下一行,
具体取决于数据本身。
I1025 00:15:15.525108 1 example.go:116] "Example" data="This is text with a line break\nand \"quotation marks\"." someInt=1 someFloat=0.1 someStruct={StringField: First line,
second line.}
上下文日志
特性状态:
Kubernetes v1.24 [alpha]
上下文日志建立在结构化日志之上。 它主要是关于开发人员如何使用日志记录调用:基于该概念的代码将更加灵活, 并且支持在结构化日志 KEP 中描述的额外用例。
如果开发人员在他们的组件中使用额外的函数,比如 WithValues 或 WithName,
那么日志条目将会包含额外的信息,这些信息会被调用者传递给函数。
目前这一特性是由 StructuredLogging 特性门控所控制的,默认关闭。
这个基础设施是在 1.24 中被添加的,并不需要修改组件。
该 component-base/logs/example
命令演示了如何使用新的日志记录调用以及组件如何支持上下文日志记录。
$ cd $GOPATH/src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool A set of key=value pairs that describe feature gates for alpha/experimental features. Options are:
AllAlpha=true|false (ALPHA - default=false)
AllBeta=true|false (BETA - default=false)
ContextualLogging=true|false (ALPHA - default=false)
$ go run . --feature-gates ContextualLogging=true
...
I0404 18:00:02.916429 451895 logger.go:94] "example/myname: runtime" foo="bar" duration="1m0s"
I0404 18:00:02.916447 451895 logger.go:95] "example: another runtime" foo="bar" duration="1m0s"
example 前缀和 foo="bar" 会被函数的调用者添加上,
不需修改该函数,它就会记录 runtime 消息和 duration="1m0s" 值。
禁用上下文日志后,WithValues 和 WithName 什么都不会做,
并且会通过调用全局的 klog 日志记录器记录日志。
因此,这些附加信息不再出现在日志输出中:
$ go run . --feature-gates ContextualLogging=false
...
I0404 18:03:31.171945 452150 logger.go:94] "runtime" duration="1m0s"
I0404 18:03:31.171962 452150 logger.go:95] "another runtime" duration="1m0s"
JSON 日志格式
特性状态:
Kubernetes v1.19 [alpha]
警告:
JSON 输出并不支持太多标准 klog 参数。对于不受支持的 klog 参数的列表, 请参见命令行工具参考。
并不是所有日志都保证写成 JSON 格式(例如,在进程启动期间)。 如果你打算解析日志,请确保可以处理非 JSON 格式的日志行。
字段名和 JSON 序列化可能会发生变化。
--logging-format=json 参数将日志格式从 klog 原生格式改为 JSON 格式。
JSON 日志格式示例(美化输出):
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
具有特殊意义的 key:
ts- Unix 时间风格的时间戳(必选项,浮点值)v- 精细度(仅用于 info 级别,不能用于错误信息,整数)err- 错误字符串(可选项,字符串)msg- 消息(必选项,字符串)
当前支持 JSON 格式的组件列表:
日志精细度级别
参数 -v 控制日志的精细度。增大该值会增大日志事件的数量。
减小该值可以减小日志事件的数量。增大精细度会记录更多的不太严重的事件。
精细度设置为 0 时只记录关键(critical)事件。
日志位置
有两种类型的系统组件:运行在容器中的组件和不运行在容器中的组件。例如:
- Kubernetes 调度器和 kube-proxy 在容器中运行。
- kubelet 和容器运行时不在容器中运行。
在使用 systemd 的系统中,kubelet 和容器运行时写入 journald。
在别的系统中,日志写入 /var/log 目录下的 .log 文件中。
容器中的系统组件总是绕过默认的日志记录机制,写入 /var/log 目录下的 .log 文件。
与容器日志类似,你应该轮转 /var/log 目录下系统组件日志。
在 kube-up.sh 脚本创建的 Kubernetes 集群中,日志轮转由 logrotate 工具配置。
logrotate 工具,每天或者当日志大于 100MB 时,轮转日志。
日志查询
特性状态:
Kubernetes v1.27 [alpha]
为了帮助在节点上调试问题,Kubernetes v1.27 引入了一个特性来查看节点上当前运行服务的日志。
要使用此特性,请确保已为节点启用了 NodeLogQuery
特性门控,
且 kubelet 配置选项 enableSystemLogHandler 和 enableSystemLogQuery 均被设置为 true。
在 Linux 上,我们假设可以通过 journald 查看服务日志。
在 Windows 上,我们假设可以在应用日志提供程序中查看服务日志。
在两种操作系统上,都可以通过读取 /var/log/ 内的文件查看日志。
假如你被授权与节点对象交互,你可以在所有节点或只是某个子集上试用此 Alpha 特性。 这里有一个从节点中检索 kubelet 服务日志的例子:
# 从名为 node-1.example 的节点中获取 kubelet 日志
kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet"
你也可以获取文件,前提是日志文件位于 kubelet 允许进行日志获取的目录中。
例如你可以从 Linux 节点上的 /var/log 中获取日志。
kubectl get --raw "/api/v1/nodes/<insert-node-name-here>/proxy/logs/?query=/<insert-log-file-name-here>"
kubelet 使用启发方式来检索日志。
如果你还未意识到给定的系统服务正将日志写入到操作系统的原生日志记录程序(例如 journald)
或 /var/log/ 中的日志文件,这会很有帮助。这种启发方式先检查原生的日志记录程序,
如果不可用,则尝试从 /var/log/<servicename>、/var/log/<servicename>.log
或 /var/log/<servicename>/<servicename>.log 中检索第一批日志。
可用选项的完整列表如下:
| 选项 | 描述 |
|---|---|
boot |
boot 显示来自特定系统引导的消息 |
pattern |
pattern 通过提供的兼容 PERL 的正则表达式来过滤日志条目 |
query |
query 是必需的,指定返回日志的服务或文件 |
sinceTime |
显示日志的 RFC3339 起始时间戳(包含) |
untilTime |
显示日志的 RFC3339 结束时间戳(包含) |
tailLines |
指定要从日志的末尾检索的行数;默认为获取全部日志 |
更复杂的查询示例:
# 从名为 node-1.example 且带有单词 "error" 的节点中获取 kubelet 日志
kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet&pattern=error"
接下来
- 阅读 Kubernetes 日志架构
- 阅读结构化日志提案(英文)
- 阅读上下文日志提案(英文)
- 阅读 klog 参数的废弃(英文)
- 阅读日志严重级别约定(英文)
11.7 - 追踪 Kubernetes 系统组件
特性状态:
Kubernetes v1.27 [beta]
系统组件追踪功能记录各个集群操作的时延信息和这些操作之间的关系。
Kubernetes 组件基于 gRPC 导出器的 OpenTelemetry 协议 发送追踪信息,并用 OpenTelemetry Collector 收集追踪信息,再将其转交给追踪系统的后台。
追踪信息的收集
关于收集追踪信息、以及使用收集器的完整指南,可参见 Getting Started with the OpenTelemetry Collector。 不过,还有一些特定于 Kubernetes 组件的事项值得注意。
默认情况下,Kubernetes 组件使用 gRPC 的 OTLP 导出器来导出追踪信息,将信息写到 IANA OpenTelemetry 端口。 举例来说,如果收集器以 Kubernetes 组件的边车模式运行, 以下接收器配置会收集 span 信息,并将它们写入到标准输出。
receivers:
otlp:
protocols:
grpc:
exporters:
# 用适合你后端环境的导出器替换此处的导出器
logging:
logLevel: debug
service:
pipelines:
traces:
receivers: [otlp]
exporters: [logging]
组件追踪
kube-apiserver 追踪
kube-apiserver 为传入的 HTTP 请求、传出到 webhook 和 etcd 的请求以及重入的请求生成 span。 由于 kube-apiserver 通常是一个公开的端点,所以它通过出站的请求传播 W3C 追踪上下文, 但不使用入站请求的追踪上下文。
在 kube-apiserver 中启用追踪
要启用追踪特性,需要使用 --tracing-config-file=<<配置文件路径> 为
kube-apiserver 提供追踪配置文件。下面是一个示例配置,它为万分之一的请求记录
span,并使用了默认的 OpenTelemetry 端点。
apiVersion: apiserver.config.k8s.io/v1beta1
kind: TracingConfiguration
# 默认值
#endpoint: localhost:4317
samplingRatePerMillion: 100
有关 TracingConfiguration 结构体的更多信息,请参阅 API 服务器配置 API (v1beta1)。
kubelet 追踪
特性状态:
Kubernetes v1.27 [beta]
kubelet CRI 接口和实施身份验证的 HTTP 服务器被插桩以生成追踪 span。 与 API 服务器一样,端点和采样率是可配置的。 追踪上下文传播也是可以配置的。始终优先采用父 span 的采样决策。 用户所提供的追踪配置采样率将被应用到不带父级的 span。 如果在没有配置端点的情况下启用,将使用默认的 OpenTelemetry Collector 接收器地址 “localhost:4317”。
在 kubelet 中启用追踪
要启用追踪,需应用追踪配置。 以下是 kubelet 配置的示例代码片段,每 10000 个请求中记录一个请求的 span,并使用默认的 OpenTelemetry 端点:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletTracing: true
tracing:
# 默认值
#endpoint: localhost:4317
samplingRatePerMillion: 100
如果 samplingRatePerMillion 被设置为一百万 (1000000),则所有 span 都将被发送到导出器。
Kubernetes v1.29 中的 kubelet 收集与垃圾回收、Pod 同步例程以及每个 gRPC 方法相关的 Span。 kubelet 借助 gRPC 来传播跟踪上下文,以便 CRI-O 和 containerd 这类带有跟踪插桩的容器运行时可以在其导出的 Span 与 kubelet 所提供的跟踪上下文之间建立关联。所得到的跟踪数据会包含 kubelet 与容器运行时 Span 之间的父子链接关系,从而为调试节点问题提供有用的上下文信息。
请注意导出 span 始终会对网络和 CPU 产生少量性能开销,具体取决于系统的总体配置。
如果在启用追踪的集群中出现类似性能问题,可以通过降低 samplingRatePerMillion
或通过移除此配置来彻底禁用追踪来缓解问题。
稳定性
追踪工具仍在积极开发中,未来它会以多种方式发生变化。 这些变化包括:span 名称、附加属性、检测端点等等。 此类特性在达到稳定版本之前,不能保证追踪工具的向后兼容性。
接下来
11.8 - Kubernetes 中的代理
本文讲述了 Kubernetes 中所使用的代理。
代理
用户在使用 Kubernetes 的过程中可能遇到几种不同的代理(proxy):
-
- 运行在用户的桌面或 pod 中
- 从本机地址到 Kubernetes apiserver 的代理
- 客户端到代理使用 HTTP 协议
- 代理到 apiserver 使用 HTTPS 协议
- 指向 apiserver
- 添加认证头信息
-
- 是一个建立在 apiserver 内部的“堡垒”
- 将集群外部的用户与集群 IP 相连接,这些 IP 是无法通过其他方式访问的
- 运行在 apiserver 进程内
- 客户端到代理使用 HTTPS 协议 (如果配置 apiserver 使用 HTTP 协议,则使用 HTTP 协议)
- 通过可用信息进行选择,代理到目的地可能使用 HTTP 或 HTTPS 协议
- 可以用来访问 Node、 Pod 或 Service
- 当用来访问 Service 时,会进行负载均衡
-
- 在每个节点上运行
- 代理 UDP、TCP 和 SCTP
- 不支持 HTTP
- 提供负载均衡能力
- 只用来访问 Service
-
apiserver 之前的代理/负载均衡器:
- 在不同集群中的存在形式和实现不同 (如 nginx)
- 位于所有客户端和一个或多个 API 服务器之间
- 存在多个 API 服务器时,扮演负载均衡器的角色
-
外部服务的云负载均衡器:
- 由一些云供应商提供 (如 AWS ELB、Google Cloud Load Balancer)
- Kubernetes 服务类型为
LoadBalancer时自动创建 - 通常仅支持 UDP/TCP 协议
- SCTP 支持取决于云供应商的负载均衡器实现
- 不同云供应商的云负载均衡器实现不同
Kubernetes 用户通常只需要关心前两种类型的代理,集群管理员通常需要确保后面几种类型的代理设置正确。
请求重定向
代理已经取代重定向功能,重定向功能已被弃用。
11.9 - API 优先级和公平性
特性状态:
Kubernetes v1.29 [stable]
对于集群管理员来说,控制 Kubernetes API 服务器在过载情况下的行为是一项关键任务。
kube-apiserver
有一些控件(例如:命令行标志 --max-requests-inflight 和 --max-mutating-requests-inflight),
可以限制将要接受的未处理的请求,从而防止过量请求入站,潜在导致 API 服务器崩溃。
但是这些标志不足以保证在高流量期间,最重要的请求仍能被服务器接受。
API 优先级和公平性(APF)是一种替代方案,可提升上述最大并发限制。 APF 以更细粒度的方式对请求进行分类和隔离。 它还引入了空间有限的排队机制,因此在非常短暂的突发情况下,API 服务器不会拒绝任何请求。 通过使用公平排队技术从队列中分发请求,这样, 一个行为不佳的控制器就不会饿死其他控制器 (即使优先级相同)。
本功能特性在设计上期望其能与标准控制器一起工作得很好; 这类控制器使用通知组件(Informers)获得信息并对 API 请求的失效作出反应, 在处理失效时能够执行指数型回退。其他客户端也以类似方式工作。
注意:
属于 “长时间运行” 类型的某些请求(例如远程命令执行或日志拖尾)不受 API 优先级和公平性过滤器的约束。
如果未启用 APF 特性,即便设置 --max-requests-inflight 标志,该类请求也不受约束。
APF 适用于 watch 请求。当 APF 被禁用时,watch 请求不受 --max-requests-inflight 限制。
启用/禁用 API 优先级和公平性
API 优先级与公平性(APF)特性由命令行标志控制,默认情况下启用。
有关可用 kube-apiserver 命令行参数以及如何启用和禁用的说明,
请参见参数。
APF 的命令行参数是 "--enable-priority-and-fairness"。
此特性也与某个 API 组相关:
(a) 稳定的 v1 版本,在 1.29 中引入,默认启用;
(b) v1beta3 版本,默认被启用,在 1.29 中被弃用。
你可以通过添加以下内容来禁用 Beta 版的 v1beta3 API 组:
kube-apiserver \
--runtime-config=flowcontrol.apiserver.k8s.io/v1beta3=false \
# ...其他配置不变
命令行标志 --enable-priority-fairness=false 将彻底禁用 APF 特性。
概念
APF 特性包含几个不同的功能。 传入的请求通过 FlowSchema 按照其属性分类,并分配优先级。 每个优先级维护自定义的并发限制,加强了隔离度,这样不同优先级的请求,就不会相互饿死。 在同一个优先级内,公平排队算法可以防止来自不同 流(Flow) 的请求相互饿死。 该算法将请求排队,通过排队机制,防止在平均负载较低时,通信量突增而导致请求失败。
优先级
如果未启用 APF,API 服务器中的整体并发量将受到 kube-apiserver 的参数
--max-requests-inflight 和 --max-mutating-requests-inflight 的限制。
启用 APF 后,将对这些参数定义的并发限制进行求和,然后将总和分配到一组可配置的 优先级 中。
每个传入的请求都会分配一个优先级;每个优先级都有各自的限制,设定特定限制允许分发的并发请求数。
例如,默认配置包括针对领导者选举请求、内置控制器请求和 Pod 请求都单独设置优先级。 这表示即使异常的 Pod 向 API 服务器发送大量请求,也无法阻止领导者选举或内置控制器的操作执行成功。
优先级的并发限制会被定期调整,允许利用率较低的优先级将并发度临时借给利用率很高的优先级。 这些限制基于一个优先级可以借出多少个并发度以及可以借用多少个并发度的额定限制和界限, 所有这些均源自下述配置对象。
请求占用的席位
上述并发管理的描述是基线情况。各个请求具有不同的持续时间, 但在与一个优先级的并发限制进行比较时,这些请求在任何给定时刻都以同等方式进行计数。 在这个基线场景中,每个请求占用一个并发单位。 我们用 “席位(Seat)” 一词来表示一个并发单位,其灵感来自火车或飞机上每位乘客占用一个固定座位的供应方式。
但有些请求所占用的席位不止一个。有些请求是服务器预估将返回大量对象的 list 请求。 我们发现这类请求会给服务器带来异常沉重的负担。 出于这个原因,服务器估算将返回的对象数量,并认为请求所占用的席位数与估算得到的数量成正比。
watch 请求的执行时间调整
APF 管理 watch 请求,但这需要考量基线行为之外的一些情况。 第一个关注点是如何判定 watch 请求的席位占用时长。 取决于请求参数不同,对 watch 请求的响应可能以针对所有预先存在的对象 create 通知开头,也可能不这样。 一旦最初的突发通知(如果有)结束,APF 将认为 watch 请求已经用完其席位。
每当向服务器通知创建/更新/删除一个对象时,正常通知都会以并发突发的方式发送到所有相关的 watch 响应流。 为此,APF 认为每个写入请求都会在实际写入完成后花费一些额外的时间来占用席位。 服务器估算要发送的通知数量,并调整写入请求的席位数以及包含这些额外工作后的席位占用时间。
排队
即使在同一优先级内,也可能存在大量不同的流量源。 在过载情况下,防止一个请求流饿死其他流是非常有价值的 (尤其是在一个较为常见的场景中,一个有故障的客户端会疯狂地向 kube-apiserver 发送请求, 理想情况下,这个有故障的客户端不应对其他客户端产生太大的影响)。 公平排队算法在处理具有相同优先级的请求时,实现了上述场景。 每个请求都被分配到某个 流(Flow) 中,该 流 由对应的 FlowSchema 的名字加上一个 流区分项(Flow Distinguisher) 来标识。 这里的流区分项可以是发出请求的用户、目标资源的名字空间或什么都不是。 系统尝试为不同流中具有相同优先级的请求赋予近似相等的权重。 要启用对不同实例的不同处理方式,多实例的控制器要分别用不同的用户名来执行身份认证。
将请求划分到流中之后,APF 功能将请求分配到队列中。 分配时使用一种称为混洗分片(Shuffle-Sharding)的技术。 该技术可以相对有效地利用队列隔离低强度流与高强度流。
排队算法的细节可针对每个优先等级进行调整,并允许管理员在内存占用、 公平性(当总流量超标时,各个独立的流将都会取得进展)、 突发流量的容忍度以及排队引发的额外延迟之间进行权衡。
豁免请求
某些特别重要的请求不受制于此特性施加的任何限制。 这些豁免可防止不当的流控配置完全禁用 API 服务器。
资源
流控 API 涉及两种资源。 PriorityLevelConfiguration 定义可用的优先级和可处理的并发预算量,还可以微调排队行为。 FlowSchema 用于对每个入站请求进行分类,并与一个 PriorityLevelConfiguration 相匹配。
PriorityLevelConfiguration
一个 PriorityLevelConfiguration 表示单个优先级。每个 PriorityLevelConfiguration 对未完成的请求数有各自的限制,对排队中的请求数也有限制。
PriorityLevelConfiguration 的额定并发限制不是指定请求绝对数量,而是以“额定并发份额”的形式指定。
API 服务器的总并发量限制通过这些份额按例分配到现有 PriorityLevelConfiguration 中,
为每个级别按照数量赋予其额定限制。
集群管理员可以更改 --max-requests-inflight (或 --max-mutating-requests-inflight)的值,
再重新启动 kube-apiserver 来增加或减小服务器的总流量,
然后所有的 PriorityLevelConfiguration 将看到其最大并发增加(或减少)了相同的比例。
注意:
在 v1beta3 之前的版本中,相关的 PriorityLevelConfiguration
字段被命名为“保证并发份额”而不是“额定并发份额”。此外在 Kubernetes v1.25
及更早的版本中,不存在定期的调整:所实施的始终是额定/保证的限制,不存在调整。
一个优先级可以借出的并发数界限以及可以借用的并发数界限在 PriorityLevelConfiguration 表现该优先级的额定限制。 这些界限值乘以额定限制/100.0 并取整,被解析为绝对席位数量。 某优先级的动态调整并发限制范围被约束在 (a) 其额定限制的下限值减去其可借出的席位和 (b) 其额定限制的上限值加上它可以借用的席位之间。 在每次调整时,通过每个优先级推导得出动态限制,具体过程为回收最近出现需求的所有借出的席位, 然后在刚刚描述的界限内共同公平地响应有关这些优先级最近的席位需求。
注意:
启用 APF 特性时,服务器的总并发限制被设置为 --max-requests-inflight 及
--max-mutating-requests-inflight 之和。变更性和非变更性请求之间不再有任何不同;
如果你想针对某给定资源分别进行处理,请制作单独的 FlowSchema,分别匹配变更性和非变更性的动作。
当入站请求的数量大于分配的 PriorityLevelConfiguration 中允许的并发级别时,
type 字段将确定对额外请求的处理方式。
Reject 类型,表示多余的流量将立即被 HTTP 429(请求过多)错误所拒绝。
Queue 类型,表示对超过阈值的请求进行排队,将使用阈值分片和公平排队技术来平衡请求流之间的进度。
公平排队算法支持通过排队配置对优先级微调。 可以在增强建议中阅读算法的详细信息, 但总之:
queues递增能减少不同流之间的冲突概率,但代价是增加了内存使用量。 值为 1 时,会禁用公平排队逻辑,但仍允许请求排队。
queueLengthLimit递增可以在不丢弃任何请求的情况下支撑更大的突发流量, 但代价是增加了等待时间和内存使用量。
-
修改
handSize允许你调整过载情况下不同流之间的冲突概率以及单个流可用的整体并发性。说明:较大的
handSize使两个单独的流程发生碰撞的可能性较小(因此,一个流可以饿死另一个流), 但是更有可能的是少数流可以控制 apiserver。 较大的handSize还可能增加单个高并发流的延迟量。 单个流中可能排队的请求的最大数量为handSize * queueLengthLimit。
下表显示了有趣的随机分片配置集合,每行显示给定的老鼠(低强度流) 被不同数量的大象挤压(高强度流)的概率。 表来源请参阅: https://play.golang.org/p/Gi0PLgVHiUg
| 随机分片 | 队列数 | 1 个大象 | 4 个大象 | 16 个大象 |
|---|---|---|---|---|
| 12 | 32 | 4.428838398950118e-09 | 0.11431348830099144 | 0.9935089607656024 |
| 10 | 32 | 1.550093439632541e-08 | 0.0626479840223545 | 0.9753101519027554 |
| 10 | 64 | 6.601827268370426e-12 | 0.00045571320990370776 | 0.49999929150089345 |
| 9 | 64 | 3.6310049976037345e-11 | 0.00045501212304112273 | 0.4282314876454858 |
| 8 | 64 | 2.25929199850899e-10 | 0.0004886697053040446 | 0.35935114681123076 |
| 8 | 128 | 6.994461389026097e-13 | 3.4055790161620863e-06 | 0.02746173137155063 |
| 7 | 128 | 1.0579122850901972e-11 | 6.960839379258192e-06 | 0.02406157386340147 |
| 7 | 256 | 7.597695465552631e-14 | 6.728547142019406e-08 | 0.0006709661542533682 |
| 6 | 256 | 2.7134626662687968e-12 | 2.9516464018476436e-07 | 0.0008895654642000348 |
| 6 | 512 | 4.116062922897309e-14 | 4.982983350480894e-09 | 2.26025764343413e-05 |
| 6 | 1024 | 6.337324016514285e-16 | 8.09060164312957e-11 | 4.517408062903668e-07 |
FlowSchema
FlowSchema 匹配一些入站请求,并将它们分配给优先级。
每个入站请求都会对 FlowSchema 测试是否匹配,
首先从 matchingPrecedence 数值最低的匹配开始,
然后依次进行,直到首个匹配出现。
注意:
对一个请求来说,只有首个匹配的 FlowSchema 才有意义。
如果一个入站请求与多个 FlowSchema 匹配,则将基于逻辑上最高优先级 matchingPrecedence 的请求进行筛选。
如果一个请求匹配多个 FlowSchema 且 matchingPrecedence 的值相同,则按 name 的字典序选择最小,
但是最好不要依赖它,而是确保不存在两个 FlowSchema 具有相同的 matchingPrecedence 值。
当给定的请求与某个 FlowSchema 的 rules 的其中一条匹配,那么就认为该请求与该 FlowSchema 匹配。
判断规则与该请求是否匹配,不仅要求该条规则的 subjects 字段至少存在一个与该请求相匹配,
而且要求该条规则的 resourceRules 或 nonResourceRules
(取决于传入请求是针对资源 URL 还是非资源 URL)字段至少存在一个与该请求相匹配。
对于 subjects 中的 name 字段和资源和非资源规则的
verbs、apiGroups、resources、namespaces 和 nonResourceURLs 字段,
可以指定通配符 * 来匹配任意值,从而有效地忽略该字段。
FlowSchema 的 distinguisherMethod.type 字段决定了如何把与该模式匹配的请求分散到各个流中。
可能是 ByUser,在这种情况下,一个请求用户将无法饿死其他容量的用户;
或者是 ByNamespace,在这种情况下,一个名字空间中的资源请求将无法饿死其它名字空间的资源请求;
或者为空(或者可以完全省略 distinguisherMethod),
在这种情况下,与此 FlowSchema 匹配的请求将被视为单个流的一部分。
资源和你的特定环境决定了如何选择正确一个 FlowSchema。
默认值
每个 kube-apiserver 会维护两种类型的 APF 配置对象:强制的(Mandatory)和建议的(Suggested)。
强制的配置对象
有四种强制的配置对象对应内置的守护行为。这里的行为是服务器在还未创建对象之前就具备的行为, 而当这些对象存在时,其规约反映了这类行为。四种强制的对象如下:
- 强制的
exempt优先级用于完全不受流控限制的请求:它们总是立刻被分发。 强制的exemptFlowSchema 把system:masters组的所有请求都归入该优先级。 如果合适,你可以定义新的 FlowSchema,将其他请求定向到该优先级。
- 强制的
catch-all优先级与强制的catch-allFlowSchema 结合使用, 以确保每个请求都分类。一般而言,你不应该依赖于catch-all的配置, 而应适当地创建自己的catch-allFlowSchema 和 PriorityLevelConfiguration (或使用默认安装的global-default配置)。 因为这一优先级不是正常场景下要使用的,catch-all优先级的并发度份额很小, 并且不会对请求进行排队。
建议的配置对象
建议的 FlowSchema 和 PriorityLevelConfiguration 包含合理的默认配置。 你可以修改这些对象或者根据需要创建新的配置对象。如果你的集群可能承受较重负载, 那么你就要考虑哪种配置最合适。
建议的配置把请求分为六个优先级:
node-high优先级用于来自节点的健康状态更新。
system优先级用于system:nodes组(即 kubelet)的与健康状态更新无关的请求; kubelet 必须能连上 API 服务器,以便工作负载能够调度到其上。
leader-election优先级用于内置控制器的领导选举的请求 (特别是来自kube-system名字空间中system:kube-controller-manager和system:kube-scheduler用户和服务账号,针对endpoints、configmaps或leases的请求)。 将这些请求与其他流量相隔离非常重要,因为领导者选举失败会导致控制器发生故障并重新启动, 这反过来会导致新启动的控制器在同步信息时,流量开销更大。
workload-high优先级用于内置控制器的其他请求。workload-low优先级用于来自所有其他服务帐户的请求,通常包括来自 Pod 中运行的控制器的所有请求。global-default优先级可处理所有其他流量,例如:非特权用户运行的交互式kubectl命令。
建议的 FlowSchema 用来将请求导向上述的优先级内,这里不再一一列举。
强制的与建议的配置对象的维护
每个 kube-apiserver 都独立地维护其强制的与建议的配置对象,
这一维护操作既是服务器的初始行为,也是其周期性操作的一部分。
因此,当存在不同版本的服务器时,如果各个服务器对于配置对象中的合适内容有不同意见,
就可能出现抖动。
每个 kube-apiserver 都会对强制的与建议的配置对象执行初始的维护操作,
之后(每分钟)对这些对象执行周期性的维护。
对于强制的配置对象,维护操作包括确保对象存在并且包含合适的规约(如果存在的话)。 服务器会拒绝创建或更新与其守护行为不一致的规约。
对建议的配置对象的维护操作被设计为允许其规约被重载。删除操作是不允许的,
维护操作期间会重建这类配置对象。如果你不需要某个建议的配置对象,
你需要将它放在一边,并让其规约所产生的影响最小化。
对建议的配置对象而言,其维护方面的设计也支持在上线新的 kube-apiserver
时完成自动的迁移动作,即便可能因为当前的服务器集合存在不同的版本而可能造成抖动仍是如此。
对建议的配置对象的维护操作包括基于服务器建议的规约创建对象
(如果对象不存在的话)。反之,如果对象已经存在,维护操作的行为取决于是否
kube-apiserver 或者用户在控制对象。如果 kube-apiserver 在控制对象,
则服务器确保对象的规约与服务器所给的建议匹配,如果用户在控制对象,
对象的规约保持不变。
关于谁在控制对象这个问题,首先要看对象上的 apf.kubernetes.io/autoupdate-spec
注解。如果对象上存在这个注解,并且其取值为true,则 kube-apiserver
在控制该对象。如果存在这个注解,并且其取值为false,则用户在控制对象。
如果这两个条件都不满足,则需要进一步查看对象的 metadata.generation。
如果该值为 1,则 kube-apiserver 控制对象,否则用户控制对象。
这些规则是在 1.22 发行版中引入的,而对 metadata.generation
的考量是为了便于从之前较简单的行为迁移过来。希望控制建议的配置对象的用户应该将对象的
apf.kubernetes.io/autoupdate-spec 注解设置为 false。
对强制的或建议的配置对象的维护操作也包括确保对象上存在 apf.kubernetes.io/autoupdate-spec
这一注解,并且其取值准确地反映了是否 kube-apiserver 在控制着对象。
维护操作还包括删除那些既非强制又非建议的配置,同时注解配置为
apf.kubernetes.io/autoupdate-spec=true 的对象。
健康检查并发豁免
推荐配置没有为本地 kubelet 对 kube-apiserver 执行健康检查的请求进行任何特殊处理
——它们倾向于使用安全端口,但不提供凭据。
在推荐配置中,这些请求将分配 global-default FlowSchema 和 global-default 优先级,
这样其他流量可以排除健康检查。
如果添加以下 FlowSchema,健康检查请求不受速率限制。
注意:
进行此更改后,任何敌对方都可以发送与此 FlowSchema 匹配的任意数量的健康检查请求。 如果你有 Web 流量过滤器或类似的外部安全机制保护集群的 API 服务器免受常规网络流量的侵扰, 则可以配置规则,阻止所有来自集群外部的健康检查请求。
apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: FlowSchema
metadata:
name: health-for-strangers
spec:
matchingPrecedence: 1000
priorityLevelConfiguration:
name: exempt
rules:
- nonResourceRules:
- nonResourceURLs:
- "/healthz"
- "/livez"
- "/readyz"
verbs:
- "*"
subjects:
- kind: Group
group:
name: "system:unauthenticated"
可观察性
指标
说明:
在 Kubernetes v1.20 之前的版本中,标签 flow_schema 和 priority_level
的名称有时被写作 flowSchema 和 priorityLevel,即存在不一致的情况。
如果你在运行 Kubernetes v1.19 或者更早版本,你需要参考你所使用的集群版本对应的文档。
当你开启了 APF 后,kube-apiserver 会暴露额外指标。 监视这些指标有助于判断你的配置是否不当地限制了重要流量, 或者发现可能会损害系统健康的,行为不良的工作负载。
成熟度水平 BETA
-
apiserver_flowcontrol_rejected_requests_total是一个计数器向量, 记录被拒绝的请求数量(自服务器启动以来累计值), 可按标签flow_chema(表示与请求匹配的 FlowSchema)、priority_level(表示分配给请该求的优先级)和reason分解。reason标签将是以下值之一:queue-full,表明已经有太多请求排队concurrency-limit,表示将 PriorityLevelConfiguration 配置为Reject而不是Queue,或者time-out,表示在其排队时间超期的请求仍在队列中。cancelled,表示该请求未被清除锁定,已从队列中移除。
apiserver_flowcontrol_dispatched_requests_total是一个计数器向量, 记录开始执行的请求数量(自服务器启动以来的累积值), 可按flow_schema和priority_level分解。
-
apiserver_flowcontrol_current_inqueue_requests是一个测量向量, 记录排队中的(未执行)请求的瞬时数量,可按priority_level和flow_schema分解。 -
apiserver_flowcontrol_current_executing_requests是一个测量向量, 记录执行中(不在队列中等待)请求的瞬时数量,可按priority_level和flow_schema分解。
-
apiserver_flowcontrol_current_executing_seats是一个测量向量, 记录了按priority_level和flow_schema细分的瞬时占用席位数量。 -
apiserver_flowcontrol_request_wait_duration_seconds是一个直方图向量, 记录了按flow_schema、priority_level和execute标签细分的请求在队列中等待的时长。execute标签表示请求是否已开始执行。说明:由于每个 FlowSchema 总会给请求分配 PriorityLevelConfiguration, 因此你可以将一个优先级的所有 FlowSchema 的直方图相加,以得到分配给该优先级的请求的有效直方图。
成熟度水平 ALPHA
apiserver_current_inqueue_requests是一个测量向量, 记录最近排队请求数量的高水位线, 由标签request_kind分组,标签的值为mutating或readOnly。 这些高水位线表示在最近一秒钟内看到的最大数字。 它们补充说明了老的测量向量apiserver_current_inflight_requests(该量保存了最后一个窗口中,正在处理的请求数量的高水位线)。
apiserver_current_inqueue_seats是一个测量向量, 记录了排队请求中每个请求将占用的最大席位数的总和, 按flow_schema和priority_level两个标签进行分组。
apiserver_flowcontrol_read_vs_write_current_requests是一个直方图向量, 在每个纳秒结束时记录请求数量的观察值,可按标签phase(取值为waiting及executing) 和request_kind(取值为mutating及readOnly)分解。 每个观察到的值是一个介于 0 和 1 之间的比值,计算方式为请求数除以该请求数的对应限制 (等待的队列长度限制和执行所用的并发限制)。
apiserver_flowcontrol_request_concurrency_in_use是一个规范向量, 包含占用席位的瞬时数量,可按priority_level和flow_schema分解。
apiserver_flowcontrol_priority_level_request_utilization是一个直方图向量, 在每个纳秒结束时记录请求数量的观察值, 可按标签phase(取值为waiting及executing)和priority_level分解。 每个观察到的值是一个介于 0 和 1 之间的比值,计算方式为请求数除以该请求数的对应限制 (等待的队列长度限制和执行所用的并发限制)。
apiserver_flowcontrol_priority_level_seat_utilization是一个直方图向量, 在每个纳秒结束时记录某个优先级并发度限制利用率的观察值,可按标签priority_level分解。 此利用率是一个分数:(占用的席位数)/(并发限制)。 此指标考虑了除 WATCH 之外的所有请求的所有执行阶段(包括写入结束时的正常延迟和额外延迟, 以覆盖相应的通知操作);对于 WATCH 请求,只考虑传递预先存在对象通知的初始阶段。 该向量中的每个直方图也带有phase: executing(等待阶段没有席位限制)的标签。
-
apiserver_flowcontrol_request_queue_length_after_enqueue是一个直方图向量, 记录请求队列的长度,可按priority_level和flow_schema分解。 每个排队中的请求都会为其直方图贡献一个样本,并在添加请求后立即上报队列的长度。 请注意,这样产生的统计数据与无偏调查不同。说明:直方图中的离群值在这里表示单个流(即,一个用户或一个名字空间的请求, 具体取决于配置)正在疯狂地向 API 服务器发请求,并受到限制。 相反,如果一个优先级的直方图显示该优先级的所有队列都比其他优先级的队列长, 则增加 PriorityLevelConfiguration 的并发份额是比较合适的。
apiserver_flowcontrol_request_concurrency_limit与apiserver_flowcontrol_nominal_limit_seats相同。在优先级之间引入并发度借用之前, 此字段始终等于apiserver_flowcontrol_current_limit_seats(它过去不作为一个独立的指标存在)。
apiserver_flowcontrol_lower_limit_seats是一个测量向量,包含每个优先级的动态并发度限制的下限。
apiserver_flowcontrol_upper_limit_seats是一个测量向量,包含每个优先级的动态并发度限制的上限。
apiserver_flowcontrol_demand_seats是一个直方图向量, 统计每纳秒结束时每个优先级的(席位需求)/(额定并发限制)比率的观察值。 某优先级的席位需求是针对排队的请求和初始执行阶段的请求,在请求的初始和最终执行阶段占用的最大席位数之和。
apiserver_flowcontrol_demand_seats_high_watermark是一个测量向量, 为每个优先级包含了上一个并发度借用调整期间所观察到的最大席位需求。
apiserver_flowcontrol_demand_seats_average是一个测量向量, 为每个优先级包含了上一个并发度借用调整期间所观察到的时间加权平均席位需求。
apiserver_flowcontrol_demand_seats_stdev是一个测量向量, 为每个优先级包含了上一个并发度借用调整期间所观察到的席位需求的时间加权总标准偏差。
apiserver_flowcontrol_demand_seats_smoothed是一个测量向量, 为每个优先级包含了上一个并发度调整期间确定的平滑包络席位需求。
apiserver_flowcontrol_target_seats是一个测量向量, 包含每个优先级触发借用分配问题的并发度目标值。
apiserver_flowcontrol_seat_fair_frac是一个测量向量, 包含了上一个借用调整期间确定的公平分配比例。
apiserver_flowcontrol_current_limit_seats是一个测量向量, 包含每个优先级的上一次调整期间得出的动态并发限制。
apiserver_flowcontrol_request_execution_seconds是一个直方图向量, 记录请求实际执行需要花费的时间, 可按标签flow_schema和priority_level分解。
apiserver_flowcontrol_watch_count_samples是一个直方图向量, 记录给定写的相关活动 WATCH 请求数量, 可按标签flow_schema和priority_level分解。
apiserver_flowcontrol_work_estimated_seats是一个直方图向量, 记录与估计席位(最初阶段和最后阶段的最多人数)相关联的请求数量, 可按标签flow_schema和priority_level分解。
apiserver_flowcontrol_request_dispatch_no_accommodation_total是一个事件数量的计数器,这些事件在原则上可能导致请求被分派, 但由于并发度不足而没有被分派, 可按标签flow_schema和priority_level分解。
apiserver_flowcontrol_epoch_advance_total是一个计数器向量, 记录了将优先级进度计向后跳跃以避免数值溢出的尝试次数, 按priority_level和success两个标签进行分组。
使用 API 优先级和公平性的最佳实践
当某个给定的优先级级别超过其所被允许的并发数时,请求可能会遇到延迟增加, 或以错误 HTTP 429 (Too Many Requests) 的形式被拒绝。 为了避免这些 APF 的副作用,你可以修改你的工作负载或调整你的 APF 设置,确保有足够的席位来处理请求。
要检测请求是否由于 APF 而被拒绝,可以检查以下指标:
- apiserver_flowcontrol_rejected_requests_total: 每个 FlowSchema 和 PriorityLevelConfiguration 拒绝的请求总数。
- apiserver_flowcontrol_current_inqueue_requests: 每个 FlowSchema 和 PriorityLevelConfiguration 中排队的当前请求数。
- apiserver_flowcontrol_request_wait_duration_seconds:请求在队列中等待的延迟时间。
- apiserver_flowcontrol_priority_level_seat_utilization: 每个 PriorityLevelConfiguration 的席位利用率。
工作负载修改
为了避免由于 APF 导致请求排队、延迟增加或被拒绝,你可以通过以下方式优化请求:
- 减少请求执行的速率。在固定时间段内减少请求数量将导致在某一给定时间点需要的席位数更少。
- 避免同时发出大量消耗较多席位的请求。请求可以被优化为使用更少的席位或降低延迟, 使这些请求占用席位的时间变短。列表请求根据请求期间获取的对象数量可能会占用多个席位。 例如通过使用分页等方式限制列表请求中取回的对象数量,可以在更短时间内使用更少的总席位数。 此外,将列表请求替换为监视请求将需要更低的总并发份额,因为监视请求仅在初始的通知突发阶段占用 1 个席位。 如果在 1.27 及更高版本中使用流式列表,因为集合的整个状态必须以流式传输, 所以监视请求在其初始的通知突发阶段将占用与列表请求相同数量的席位。 请注意,在这两种情况下,监视请求在此初始阶段之后将不再保留任何席位。
请注意,由于请求数量增加或现有请求的延迟增加,APF 可能会导致请求排队或被拒绝。 例如,如果通常需要 1 秒执行的请求开始需要 60 秒,由于延迟增加, 请求所占用的席位时间可能超过了正常情况下的时长,APF 将开始拒绝请求。 如果在没有工作负载显著变化的情况下,APF 开始在多个优先级级别上拒绝请求, 则可能存在控制平面性能的潜在问题,而不是工作负载或 APF 设置的问题。
优先级和公平性设置
你还可以修改默认的 FlowSchema 和 PriorityLevelConfiguration 对象, 或创建新的对象来更好地容纳你的工作负载。
APF 设置可以被修改以实现下述目标:
- 给予高优先级请求更多的席位。
- 隔离那些非必要或开销大的请求,因为如果与其他流共享,这些请求可能会耗尽所有并发级别。
给予高优先级请求更多的席位
- 如果有可能,你可以通过提高
max-requests-inflight和max-mutating-requests-inflight参数的值为特定kube-apiserver提高所有优先级级别均可用的席位数量。另外, 如果在请求的负载均衡足够好的情况下,水平扩缩kube-apiserver实例的数量将提高集群中每个优先级级别的总并发数。
- 你可以创建一个新的 FlowSchema,在其中引用并发级别更高的 PriorityLevelConfiguration。
这个新的 PriorityLevelConfiguration 可以是现有的级别,也可以是具有自己一组额定并发份额的新级别。
例如,你可以引入一个新的 FlowSchema 来将请求的 PriorityLevelConfiguration
从全局默认值更改为工作负载较低的级别,以增加用户可用的席位数。
创建一个新的 PriorityLevelConfiguration 将减少为现有级别指定的席位数。
请注意,编辑默认的 FlowSchema 或 PriorityLevelConfiguration 需要将
apf.kubernetes.io/autoupdate-spec注解设置为 false。
- 你还可以为服务于高优先级请求的 PriorityLevelConfiguration 提高 NominalConcurrencyShares。 此外在 1.26 及更高版本中,你可以为有竞争的优先级级别提高 LendablePercent,以便给定优先级级别可以借用更多的席位。
隔离非关键请求以免饿死其他流
为了进行请求隔离,你可以创建一个 FlowSchema,使其主体与发起这些请求的用户匹配, 或者创建一个与请求内容匹配(对应 resourceRules)的 FlowSchema。 接下来,你可以将该 FlowSchema 映射到一个具有较低席位份额的 PriorityLevelConfiguration。
例如,假设来自 default 名字空间中运行的 Pod 的每个事件列表请求使用 10 个席位,并且执行时间为 1 分钟。 为了防止这些开销大的请求影响使用现有服务账号 FlowSchema 的其他 Pod 的请求,你可以应用以下 FlowSchema 将这些列表调用与其他请求隔离开来。
用于隔离列表事件请求的 FlowSchema 对象示例:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: FlowSchema
metadata:
name: list-events-default-service-account
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default- 这个 FlowSchema 用于抓取 default 名字空间中默认服务账号所发起的所有事件列表调用。 匹配优先级为 8000,低于现有服务账号 FlowSchema 所用的 9000,因此这些列表事件调用将匹配到 list-events-default-service-account 而不是服务账号。
- 通用 PriorityLevelConfiguration 用于隔离这些请求。通用优先级级别具有非常小的并发份额,并且不对请求进行排队。
接下来
- 你可以查阅流控参考文档了解有关故障排查的更多信息。
- 有关 API 优先级和公平性的设计细节的背景信息, 请参阅增强提案。
- 你可以通过 SIG API Machinery 或特性的 Slack 频道提出建议和特性请求。
11.10 - 安装扩展(Addon)
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
Add-on 扩展了 Kubernetes 的功能。
本文列举了一些可用的 add-on 以及到它们各自安装说明的链接。该列表并不试图详尽无遗。
联网和网络策略
- ACI 通过 Cisco ACI 提供集成的容器网络和安全网络。
- Antrea 在第 3/4 层执行操作,为 Kubernetes 提供网络连接和安全服务。Antrea 利用 Open vSwitch 作为网络的数据面。 Antrea 是一个沙箱级的 CNCF 项目。
- Calico 是一个联网和网络策略供应商。 Calico 支持一套灵活的网络选项,因此你可以根据自己的情况选择最有效的选项,包括非覆盖和覆盖网络,带或不带 BGP。 Calico 使用相同的引擎为主机、Pod 和(如果使用 Istio 和 Envoy)应用程序在服务网格层执行网络策略。
- Canal 结合 Flannel 和 Calico,提供联网和网络策略。
- Cilium 是一种网络、可观察性和安全解决方案,具有基于 eBPF 的数据平面。 Cilium 提供了简单的 3 层扁平网络, 能够以原生路由(routing)和覆盖/封装(overlay/encapsulation)模式跨越多个集群, 并且可以使用与网络寻址分离的基于身份的安全模型在 L3 至 L7 上实施网络策略。 Cilium 可以作为 kube-proxy 的替代品;它还提供额外的、可选的可观察性和安全功能。 Cilium 是一个毕业级别的 CNCF 项目。
- CNI-Genie 使 Kubernetes 无缝连接到 Calico、Canal、Flannel 或 Weave 等其中一种 CNI 插件。 CNI-Genie 是一个沙箱级的 CNCF 项目。
- Contiv 为各种用例和丰富的策略框架提供可配置的网络 (带 BGP 的原生 L3、带 vxlan 的覆盖、标准 L2 和 Cisco-SDN/ACI)。 Contiv 项目完全开源。 其安装程序 提供了基于 kubeadm 和非 kubeadm 的安装选项。
- Contrail 基于 Tungsten Fabric,是一个开源的多云网络虚拟化和策略管理平台。 Contrail 和 Tungsten Fabric 与业务流程系统(例如 Kubernetes、OpenShift、OpenStack 和 Mesos)集成在一起, 为虚拟机、容器或 Pod 以及裸机工作负载提供了隔离模式。
- Flannel 是一个可以用于 Kubernetes 的 overlay 网络提供者。
- Gateway API 是一个由 SIG Network 社区管理的开源项目, 为服务网络建模提供一种富有表达力、可扩展和面向角色的 API。
- Knitter 是在一个 Kubernetes Pod 中支持多个网络接口的插件。
- Multus 是一个多插件, 可在 Kubernetes 中提供多种网络支持,以支持所有 CNI 插件(例如 Calico、Cilium、Contiv、Flannel), 而且包含了在 Kubernetes 中基于 SRIOV、DPDK、OVS-DPDK 和 VPP 的工作负载。
- OVN-Kubernetes 是一个 Kubernetes 网络驱动, 基于 OVN(Open Virtual Network)实现,是从 Open vSwitch (OVS) 项目衍生出来的虚拟网络实现。OVN-Kubernetes 为 Kubernetes 提供基于覆盖网络的网络实现, 包括一个基于 OVS 实现的负载均衡器和网络策略。
- Nodus 是一个基于 OVN 的 CNI 控制器插件, 提供基于云原生的服务功能链 (SFC)。
- NSX-T 容器插件(NCP) 提供了 VMware NSX-T 与容器协调器(例如 Kubernetes)之间的集成,以及 NSX-T 与基于容器的 CaaS / PaaS 平台(例如关键容器服务(PKS)和 OpenShift)之间的集成。
- Nuage 是一个 SDN 平台,可在 Kubernetes Pods 和非 Kubernetes 环境之间提供基于策略的联网,并具有可视化和安全监控。
- Romana 是一个 Pod 网络的第三层解决方案,并支持 NetworkPolicy API。
- Spiderpool 为 Kubernetes 提供了下层网络和 RDMA 高速网络解决方案,兼容裸金属、虚拟机和公有云等运行环境。
- Weave Net 提供在网络分组两端参与工作的联网和网络策略,并且不需要额外的数据库。
服务发现
可视化管理
- Dashboard 是一个 Kubernetes 的 Web 控制台界面。
- Weave Scope 是一个可视化工具,用于查看你的容器、Pod、服务等。
基础设施
遗留 Add-on
还有一些其它 add-on 归档在已废弃的 cluster/addons 路径中。
维护完善的 add-on 应该被链接到这里。欢迎提出 PR!
12 - Kubernetes 中的 Windows
Kubernetes 支持运行 Microsoft Windows 节点。
Kubernetes 支持运行 Linux 或 Microsoft Windows 的工作节点。
🛇 本条目指向第三方项目或产品,而该项目(产品)不是 Kubernetes 的一部分。更多信息
CNCF 及其母公司 Linux 基金会采用供应商中立的方法来实现兼容性。可以将你的 Windows 服务器作为工作节点加入 Kubernetes 集群。
无论你的集群使用什么操作系统, 都可以在 Windows 上安装和设置 kubectl。
如果你使用的是 Windows 节点,你可以阅读:
- Windows 上的网络
- Kubernetes 中的 Windows 存储
- Windows 节点的资源管理
- 为 Windows Pod 和容器配置 RunAsUserName
- 创建 Windows HostProcess Pod
- 为 Windows Pod 和容器配置组托管服务帐户
- Windows 节点的安全性
- Windows 调试技巧
- 在 Kubernetes 中调度 Windows 容器指南
或者,要了解概览,请阅读:
12.1 - Kubernetes 中的 Windows 容器
在许多组织中,所运行的很大一部分服务和应用是 Windows 应用。 Windows 容器提供了一种封装进程和包依赖项的方式, 从而简化了 DevOps 实践,令 Windows 应用同样遵从云原生模式。
对于同时投入基于 Windows 应用和 Linux 应用的组织而言,他们不必寻找不同的编排系统来管理其工作负载, 使其跨部署的运营效率得以大幅提升,而不必关心所用的操作系统。
Kubernetes 中的 Windows 节点
若要在 Kubernetes 中启用对 Windows 容器的编排,可以在现有的 Linux 集群中包含 Windows 节点。 在 Kubernetes 上调度 Pod 中的 Windows 容器与调度基于 Linux 的容器类似。
为了运行 Windows 容器,你的 Kubernetes 集群必须包含多个操作系统。 尽管你只能在 Linux 上运行控制平面, 你可以部署运行 Windows 或 Linux 的工作节点。
支持 Windows 节点的前提是操作系统为 Windows Server 2019 或 Windows Server 2022。
本文使用术语 Windows 容器表示具有进程隔离能力的 Windows 容器。 Kubernetes 不支持使用 Hyper-V 隔离能力来运行 Windows 容器。
兼容性与局限性
某些节点层面的功能特性仅在使用特定容器运行时时才可用; 另外一些特性则在 Windows 节点上不可用,包括:
- 巨页(HugePages):Windows 容器当前不支持。
- 特权容器:Windows 容器当前不支持。 HostProcess 容器提供类似功能。
- TerminationGracePeriod:需要 containerD。
Windows 节点并不支持共享命名空间的所有功能特性。 有关更多详细信息,请参考 API 兼容性。
有关 Kubernetes 测试时所使用的 Windows 版本的详细信息,请参考 Windows 操作系统版本兼容性。
从 API 和 kubectl 的角度来看,Windows 容器的行为与基于 Linux 的容器非常相似。 然而,在本节所概述的一些关键功能上,二者存在一些显著差异。
与 Linux 比较
Kubernetes 关键组件在 Windows 上的工作方式与在 Linux 上相同。 本节介绍几个关键的工作负载抽象及其如何映射到 Windows。
-
Pod 是 Kubernetes 的基本构建块,是可以创建或部署的最小和最简单的单元。 你不可以在同一个 Pod 中部署 Windows 和 Linux 容器。 Pod 中的所有容器都调度到同一 Node 上,每个 Node 代表一个特定的平台和体系结构。 Windows 容器支持以下 Pod 能力、属性和事件:
- 每个 Pod 有一个或多个容器,具有进程隔离和卷共享能力
- Pod
status字段 - 就绪、存活和启动探针
- postStart 和 preStop 容器生命周期回调
- ConfigMap 和 Secret:作为环境变量或卷
emptyDir卷- 命名管道形式的主机挂载
- 资源限制
- 操作系统字段:
.spec.os.name字段应设置为windows以表明当前 Pod 使用 Windows 容器。如果你将 `.spec.os.name` 字段设置为 `windows`,则你必须不能在对应 Pod 的
.spec中设置以下字段:spec.hostPIDspec.hostIPCspec.securityContext.seLinuxOptionsspec.securityContext.seccompProfilespec.securityContext.fsGroupspec.securityContext.fsGroupChangePolicyspec.securityContext.sysctlsspec.shareProcessNamespacespec.securityContext.runAsUserspec.securityContext.runAsGroupspec.securityContext.supplementalGroupsspec.containers[*].securityContext.seLinuxOptionsspec.containers[*].securityContext.seccompProfilespec.containers[*].securityContext.capabilitiesspec.containers[*].securityContext.readOnlyRootFilesystemspec.containers[*].securityContext.privilegedspec.containers[*].securityContext.allowPrivilegeEscalationspec.containers[*].securityContext.procMountspec.containers[*].securityContext.runAsUserspec.containers[*].securityContext.runAsGroup
在上述列表中,通配符(`*`)表示列表中的所有项。例如,
spec.containers[*].securityContext指代所有容器的 SecurityContext 对象。 如果指定了这些字段中的任意一个,则 API 服务器不会接受此 Pod。
-
工作负载资源包括:
- ReplicaSet
- Deployment
- StatefulSet
- DaemonSet
- Job
- CronJob
- ReplicationController
-
Services
有关更多详细信息,请参考负载均衡和 Service。
Pod、工作负载资源和 Service 是在 Kubernetes 上管理 Windows 工作负载的关键元素。 然而,它们本身还不足以在动态的云原生环境中对 Windows 工作负载进行恰当的生命周期管理。
kubectl exec- Pod 和容器度量指标
- Pod 水平自动扩缩容
- 资源配额
- 调度器抢占
kubelet 的命令行选项
某些 kubelet 命令行选项在 Windows 上的行为不同,如下所述:
--windows-priorityclass允许你设置 kubelet 进程的调度优先级 (参考 CPU 资源管理)。--kube-reserved、--system-reserved和--eviction-hard标志更新 NodeAllocatable。- 未实现使用
--enforce-node-allocable驱逐。 - 未实现使用
--eviction-hard和--eviction-soft驱逐。 - 在 Windows 节点上运行时,kubelet 没有内存或 CPU 限制。
--kube-reserved和--system-reserved仅从NodeAllocatable中减去,并且不保证为工作负载提供的资源。 有关更多信息,请参考 Windows 节点的资源管理。 - 未实现
MemoryPressure条件。 - kubelet 不会执行 OOM 驱逐操作。
API 兼容性
由于操作系统和容器运行时的缘故,Kubernetes API 在 Windows 上的工作方式存在细微差异。 某些工作负载属性是为 Linux 设计的,无法在 Windows 上运行。
从较高的层面来看,以下操作系统概念是不同的:
- 身份 - Linux 使用 userID(UID)和 groupID(GID),表示为整数类型。
用户名和组名是不规范的,它们只是
/etc/groups或/etc/passwd中的别名, 作为 UID+GID 的后备标识。 Windows 使用更大的二进制安全标识符(SID), 存放在 Windows 安全访问管理器(Security Access Manager,SAM)数据库中。 此数据库在主机和容器之间或容器之间不共享。 - 文件权限 - Windows 使用基于 SID 的访问控制列表, 而像 Linux 使用基于对象权限和 UID+GID 的位掩码(POSIX 系统)以及可选的访问控制列表。
- 文件路径 - Windows 上的约定是使用
\而不是/。 Go IO 库通常接受两者,能让其正常工作,但当你设置要在容器内解读的路径或命令行时, 可能需要用\。
- 信号 - Windows 交互式应用处理终止的方式不同,可以实现以下一种或多种:
- UI 线程处理包括
WM_CLOSE在内准确定义的消息。 - 控制台应用使用控制处理程序(Control Handler)处理 Ctrl-C 或 Ctrl-Break。
- 服务会注册可接受
SERVICE_CONTROL_STOP控制码的服务控制处理程序(Service Control Handler)函数。
- UI 线程处理包括
容器退出码遵循相同的约定,其中 0 表示成功,非零表示失败。 具体的错误码在 Windows 和 Linux 中可能不同。 但是,从 Kubernetes 组件(kubelet、kube-proxy)传递的退出码保持不变。
容器规约的字段兼容性
以下列表记录了 Pod 容器规约在 Windows 和 Linux 之间的工作方式差异:
- 巨页(Huge page)在 Windows 容器运行时中未实现,且不可用。 巨页需要不可为容器配置的用户特权生效。
requests.cpu和requests.memory- 从节点可用资源中减去请求,因此请求可用于避免一个节点过量供应。 但是,请求不能用于保证已过量供应的节点中的资源。 如果运营商想要完全避免过量供应,则应将设置请求作为最佳实践应用到所有容器。
securityContext.allowPrivilegeEscalation- 不能在 Windows 上使用;所有权能字都无法生效。securityContext.capabilities- POSIX 权能未在 Windows 上实现。securityContext.privileged- Windows 不支持特权容器, 可使用 HostProcess 容器代替。securityContext.procMount- Windows 没有/proc文件系统。securityContext.readOnlyRootFilesystem- 不能在 Windows 上使用;对于容器内运行的注册表和系统进程,写入权限是必需的。securityContext.runAsGroup- 不能在 Windows 上使用,因为不支持 GID。
securityContext.runAsNonRoot- 此设置将阻止以ContainerAdministrator身份运行容器,这是 Windows 上与 root 用户最接近的身份。securityContext.runAsUser- 改用runAsUserName。securityContext.seLinuxOptions- 不能在 Windows 上使用,因为 SELinux 特定于 Linux。terminationMessagePath- 这个字段有一些限制,因为 Windows 不支持映射单个文件。 默认值为/dev/termination-log,因为默认情况下它在 Windows 上不存在,所以能生效。
Pod 规约的字段兼容性
以下列表记录了 Pod 规约在 Windows 和 Linux 之间的工作方式差异:
hostIPC和hostpid- 不能在 Windows 上共享主机命名空间。hostNetwork- 参见下文dnsPolicy- Windows 不支持将 PoddnsPolicy设为ClusterFirstWithHostNet, 因为未提供主机网络。Pod 始终用容器网络运行。podSecurityContext参见下文shareProcessNamespace- 这是一个 Beta 版功能特性,依赖于 Windows 上未实现的 Linux 命名空间。 Windows 无法共享进程命名空间或容器的根文件系统(root filesystem)。 只能共享网络。
terminationGracePeriodSeconds- 这在 Windows 上的 Docker 中没有完全实现, 请参考 GitHub issue。 目前的行为是通过 CTRL_SHUTDOWN_EVENT 发送 ENTRYPOINT 进程,然后 Windows 默认等待 5 秒, 最后使用正常的 Windows 关机行为终止所有进程。 5 秒默认值实际上位于容器内的 Windows 注册表中,因此在构建容器时可以覆盖这个值。volumeDevices- 这是一个 Beta 版功能特性,未在 Windows 上实现。 Windows 无法将原始块设备挂接到 Pod。volumes- 如果你定义一个
emptyDir卷,则你无法将卷源设为memory。
- 如果你定义一个
- 你无法为卷挂载启用
mountPropagation,因为这在 Windows 上不支持。
hostNetwork 的字段兼容性
特性状态:
Kubernetes v1.26 [alpha]
现在,kubelet 可以请求在 Windows 节点上运行的 Pod 使用主机的网络命名空间,而不是创建新的 Pod 网络命名空间。
要启用此功能,请将 --feature-gates=WindowsHostNetwork=true 传递给 kubelet。
说明:
此功能需要支持该功能的容器运行时。
Pod 安全上下文的字段兼容性
Pod 的 securityContext
中只有 securityContext.runAsNonRoot 和 securityContext.windowsOptions 字段在 Windows 上生效。
节点问题检测器
节点问题检测器(参考节点健康监测)初步支持 Windows。 有关更多信息,请访问该项目的 GitHub 页面。
Pause 容器
在 Kubernetes Pod 中,首先创建一个基础容器或 “pause” 容器来承载容器。 在 Linux 中,构成 Pod 的 cgroup 和命名空间维持持续存在需要一个进程; 而 pause 进程就提供了这个功能。 属于同一 Pod 的容器(包括基础容器和工作容器)共享一个公共网络端点 (相同的 IPv4 和/或 IPv6 地址,相同的网络端口空间)。 Kubernetes 使用 pause 容器以允许工作容器崩溃或重启,而不会丢失任何网络配置。
Kubernetes 维护一个多体系结构的镜像,包括对 Windows 的支持。
对于 Kubernetes v1.29.2,推荐的 pause 镜像为 registry.k8s.io/pause:3.6。
可在 GitHub 上获得源代码。
Microsoft 维护一个不同的多体系结构镜像,支持 Linux 和 Windows amd64,
你可以找到的镜像类似 mcr.microsoft.com/oss/kubernetes/pause:3.6。
此镜像的构建与 Kubernetes 维护的镜像同源,但所有 Windows 可执行文件均由
Microsoft 进行了验证码签名。
如果你正部署到一个需要签名可执行文件的生产或类生产环境,
Kubernetes 项目建议使用 Microsoft 维护的镜像。
容器运行时
你需要将容器运行时安装到集群中的每个节点, 这样 Pod 才能在这些节点上运行。
以下容器运行时适用于 Windows:
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
ContainerD
特性状态:
Kubernetes v1.20 [stable]
对于运行 Windows 的 Kubernetes 节点,你可以使用 ContainerD 1.4.0+ 作为容器运行时。
说明:
将 GMSA 和 containerd 一起用于访问 Windows 网络共享时存在已知限制, 这需要一个内核补丁。
Mirantis 容器运行时
Mirantis 容器运行时(MCR) 可作为所有 Windows Server 2019 和更高版本的容器运行时。
有关更多信息,请参考在 Windows Server 上安装 MCR。
Windows 操作系统版本兼容性
在 Windows 节点上,如果主机操作系统版本必须与容器基础镜像操作系统版本匹配, 则会应用严格的兼容性规则。 仅 Windows Server 2019 作为容器操作系统时,才能完全支持 Windows 容器。
对于 Kubernetes v1.29,Windows 节点(和 Pod)的操作系统兼容性如下:
- Windows Server LTSC release
- Windows Server 2019
- Windows Server 2022
- Windows Server SAC release
- Windows Server version 20H2
也适用 Kubernetes 版本偏差策略。
硬件建议和注意事项
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
说明:
这里列出的硬件规格应被视为合理的默认值。 它们并不代表生产环境的最低要求或具体推荐。 根据你的工作负载要求,这些值可能需要进行调整。
- 64 位处理器,4 核或更多的 CPU,能够支持虚拟化
- 8GB 或更多的 RAM
- 50GB 或更多的可用磁盘空间
有关最新的最低硬件要求信息, 请参考微软文档:Windows Server 的硬件要求。 有关决定生产工作节点资源的指导信息, 请参考 Kubernetes 文档:生产用工作节点。
为了优化系统资源,如果图形用户界面不是必需的,最好选择一个不包含 Windows 桌面体验安装选项的 Windows Server 操作系统安装包,因为这种配置通常会释放更多的系统资源。
在估算 Windows 工作节点的磁盘空间时,需要注意 Windows 容器镜像通常比 Linux 容器镜像更大,
单个镜像的容器大小范围从 300MB 到超过 10GB。
此外,需要注意 Windows 容器中的 C: 驱动器默认呈现的虚拟剩余空间为 20GB,
这不是实际的占用空间,而是使用主机上的本地存储时单个容器可以最多占用的磁盘大小。
有关更多详细信息,
请参见在 Windows 上运行容器 - 容器存储文档。
获取帮助和故障排查
对 Kubernetes 集群进行故障排查的主要帮助来源应始于故障排查页面。
本节包括了一些其他特定于 Windows 的故障排查帮助。 日志是解决 Kubernetes 中问题的重要元素。 确保在任何时候向其他贡献者寻求故障排查协助时随附了日志信息。 遵照 SIG Windows 日志收集贡献指南中的指示说明。
报告问题和功能请求
如果你发现疑似 bug,或者你想提出功能请求,请按照 SIG Windows 贡献指南 新建一个 Issue。你应该先搜索 Issue 列表,以防之前报告过这个问题,凭你对该问题的经验添加评论, 并随附日志信息。Kubernetes Slack 上的 SIG Windows 频道也是一个很好的途径, 可以在创建工单之前获得一些初始支持和故障排查思路。
接下来
部署工具
kubeadm 工具帮助你部署 Kubernetes 集群,提供管理集群的控制平面以及运行工作负载的节点。
Kubernetes 集群 API 项目也提供了自动部署 Windows 节点的方式。
Windows 分发渠道
有关 Windows 分发渠道的详细阐述,请参考 Microsoft 文档。
有关支持模型在内的不同 Windows Server 服务渠道的信息,请参考 Windows Server 服务渠道。
12.2 - Kubernetes 中的 Windows 容器调度指南
在许多组织中运行的服务和应用程序中,Windows 应用程序构成了很大一部分。 本指南将引导你完成在 Kubernetes 中配置和部署 Windows 容器的步骤。
目标
- 配置 Deployment 样例以在 Windows 节点上运行 Windows 容器
- 在 Kubernetes 中突出 Windows 特定的功能
在你开始之前
- 创建一个 Kubernetes 集群,其中包含一个控制平面和一个运行 Windows Server 的工作节点。
- 务必请注意,在 Kubernetes 上创建和部署服务和工作负载的行为方式与 Linux 和 Windows 容器的行为方式大致相同。 与集群交互的 kubectl 命令是一致的。 下一小节的示例旨在帮助你快速开始使用 Windows 容器。
快速开始:部署 Windows 容器
以下示例 YAML 文件部署了一个在 Windows 容器内运行的简单 Web 服务器的应用程序。
创建一个名为 win-webserver.yaml 的 Service 规约,其内容如下:
apiVersion: v1
kind: Service
metadata:
name: win-webserver
labels:
app: win-webserver
spec:
ports:
# 此 Service 服务的端口
- port: 80
targetPort: 80
selector:
app: win-webserver
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: win-webserver
name: win-webserver
spec:
replicas: 2
selector:
matchLabels:
app: win-webserver
template:
metadata:
labels:
app: win-webserver
name: win-webserver
spec:
containers:
- name: windowswebserver
image: mcr.microsoft.com/windows/servercore:ltsc2019
command:
- powershell.exe
- -command
- "<#code used from https://gist.github.com/19WAS85/5424431#> ; $$listener = New-Object System.Net.HttpListener ; $$listener.Prefixes.Add('http://*:80/') ; $$listener.Start() ; $$callerCounts = @{} ; Write-Host('Listening at http://*:80/') ; while ($$listener.IsListening) { ;$$context = $$listener.GetContext() ;$$requestUrl = $$context.Request.Url ;$$clientIP = $$context.Request.RemoteEndPoint.Address ;$$response = $$context.Response ;Write-Host '' ;Write-Host('> {0}' -f $$requestUrl) ; ;$$count = 1 ;$$k=$$callerCounts.Get_Item($$clientIP) ;if ($$k -ne $$null) { $$count += $$k } ;$$callerCounts.Set_Item($$clientIP, $$count) ;$$ip=(Get-NetAdapter | Get-NetIpAddress); $$header='<html><body><H1>Windows Container Web Server</H1>' ;$$callerCountsString='' ;$$callerCounts.Keys | % { $$callerCountsString+='<p>IP {0} callerCount {1} ' -f $$ip[1].IPAddress,$$callerCounts.Item($$_) } ;$$footer='</body></html>' ;$$content='{0}{1}{2}' -f $$header,$$callerCountsString,$$footer ;Write-Output $$content ;$$buffer = [System.Text.Encoding]::UTF8.GetBytes($$content) ;$$response.ContentLength64 = $$buffer.Length ;$$response.OutputStream.Write($$buffer, 0, $$buffer.Length) ;$$response.Close() ;$$responseStatus = $$response.StatusCode ;Write-Host('< {0}' -f $$responseStatus) } ; "
nodeSelector:
kubernetes.io/os: windows
说明:
端口映射也是支持的,但为简单起见,此示例将容器的端口 80 直接暴露给服务。
-
检查所有节点是否健康
kubectl get nodes
-
部署 Service 并监视 Pod 更新:
kubectl apply -f win-webserver.yaml kubectl get pods -o wide -w当 Service 被正确部署时,两个 Pod 都被标记为就绪(Ready)。要退出 watch 命令,请按 Ctrl+C。
-
检查部署是否成功。请验证:
- 当执行
kubectl get pods命令时,能够从 Linux 控制平面所在的节点上列出两个 Pod。 - 跨网络的节点到 Pod 通信,从 Linux 控制平面所在的节点上执行
curl命令来访问 Pod IP 的 80 端口以检查 Web 服务器响应。 - Pod 间通信,使用
docker exec或kubectl exec命令进入容器,并在 Pod 之间(以及跨主机,如果你有多个 Windows 节点)相互进行 ping 操作。 - Service 到 Pod 的通信,在 Linux 控制平面所在的节点以及独立的 Pod 中执行
curl命令来访问虚拟的服务 IP(在kubectl get services命令下查看)。 - 服务发现,执行
curl命令来访问带有 Kubernetes 默认 DNS 后缀的服务名称。 - 入站连接,在 Linux 控制平面所在的节点上或集群外的机器上执行
curl命令来访问 NodePort 服务。 - 出站连接,使用
kubectl exec,从 Pod 内部执行curl访问外部 IP。
- 当执行
说明:
由于当前 Windows 平台的网络堆栈限制,Windows 容器主机无法访问调度到其上的 Service 的 IP。 只有 Windows Pod 能够访问 Service IP。
可观察性
捕捉来自工作负载的日志
日志是可观察性的重要元素;它们使用户能够深入了解工作负载的运行情况,并且是解决问题的关键因素。
由于 Windows 容器和 Windows 容器中的工作负载与 Linux 容器的行为不同,因此用户很难收集日志,从而限制了操作可见性。
例如,Windows 工作负载通常配置为记录到 ETW(Windows 事件跟踪)或向应用程序事件日志推送条目。
LogMonitor
是一个微软开源的工具,是监视 Windows 容器内所配置的日志源的推荐方法。
LogMonitor 支持监视事件日志、ETW 提供程序和自定义应用程序日志,将它们传送到 STDOUT 以供 kubectl logs <pod> 使用。
按照 LogMonitor GitHub 页面中的说明,将其二进制文件和配置文件复制到所有容器, 并为 LogMonitor 添加必要的入口点以将日志推送到标准输出(STDOUT)。
配置容器用户
使用可配置的容器用户名
Windows 容器可以配置为使用不同于镜像默认值的用户名来运行其入口点和进程。 在这里了解更多信息。
使用组托管服务帐户(GMSA)管理工作负载身份
Windows 容器工作负载可以配置为使用组托管服务帐户(Group Managed Service Accounts,GMSA)。 组托管服务帐户是一种特定类型的活动目录(Active Directory)帐户,可提供自动密码管理、 简化的服务主体名称(Service Principal Name,SPN)管理,以及将管理委派给多个服务器上的其他管理员的能力。 配置了 GMSA 的容器可以携带使用 GMSA 配置的身份访问外部活动目录域资源。 在此处了解有关为 Windows 容器配置和使用 GMSA 的更多信息。
污点和容忍度
用户需要使用某种污点(Taint)和节点选择器的组合,以便将 Linux 和 Windows 工作负载各自调度到特定操作系统的节点。 下面概述了推荐的方法,其主要目标之一是该方法不应破坏现有 Linux 工作负载的兼容性。
从 1.25 开始,你可以(并且应该)将每个 Pod 的 .spec.os.name 设置为 Pod 中的容器设计所用于的操作系统。
对于运行 Linux 容器的 Pod,将 .spec.os.name 设置为 linux。
对于运行 Windows 容器的 Pod,将 .spec.os.name 设置为 windows。
调度器在将 Pod 分配到节点时并不使用 .spec.os.name 的值。
你应该使用正常的 Kubernetes 机制将 Pod 分配给节点,
以确保集群的控制平面将 Pod 放置到运行适当操作系统的节点上。
.spec.os.name 值对 Windows Pod 的调度没有影响,
因此仍然需要污点和容忍以及节点选择器来确保 Windows Pod 落在适当的 Windows 节点。
确保特定于操作系统的工作负载落到合适的容器主机上
用户可以使用污点(Taint)和容忍度(Toleration)确保将 Windows 容器调度至合适的主机上。 现在,所有的 Kubernetes 节点都有以下默认标签:
- kubernetes.io/os = [windows|linux]
- kubernetes.io/arch = [amd64|arm64|...]
如果 Pod 规约没有指定像 "kubernetes.io/os": windows 这样的 nodeSelector,
则 Pod 可以被调度到任何主机上,Windows 或 Linux。
这可能会有问题,因为 Windows 容器只能在 Windows 上运行,而 Linux 容器只能在 Linux 上运行。
最佳实践是使用 nodeSelector。
但是,我们了解到,在许多情况下,用户已经预先存在大量 Linux 容器部署, 以及现成配置的生态系统,例如社区中的 Helm Chart 包和程序化的 Pod 生成案例,例如 Operator。 在这些情况下,你可能不愿更改配置来添加节点选择器。 另一种方法是使用污点。因为 kubelet 可以在注册过程中设置污点, 所以可以很容易地修改为,当只能在 Windows 上运行时,自动添加污点。
例如:--register-with-taints='os=windows:NoSchedule'
通过向所有 Windows 节点添加污点,任何负载都不会被调度到这些节点上(包括现有的 Linux Pod)。 为了在 Windows 节点上调度 Windows Pod,它需要 nodeSelector 和匹配合适的容忍度来选择 Windows。
nodeSelector:
kubernetes.io/os: windows
node.kubernetes.io/windows-build: '10.0.17763'
tolerations:
- key: "os"
operator: "Equal"
value: "windows"
effect: "NoSchedule"
处理同一集群中的多个 Windows 版本
每个 Pod 使用的 Windows Server 版本必须与节点的版本匹配。 如果要在同一个集群中使用多个 Windows Server 版本,则应设置额外的节点标签和节点选择器。
Kubernetes 1.17 自动添加了一个新标签 node.kubernetes.io/windows-build 来简化这一点。
如果你运行的是旧版本,则建议手动将此标签添加到 Windows 节点。
此标签反映了需要匹配以实现兼容性的 Windows 主要、次要和内部版本号。 以下是目前用于每个 Windows Server 版本的值。
| 产品名称 | 构建号 |
|---|---|
| Windows Server 2019 | 10.0.17763 |
| Windows Server, Version 20H2 | 10.0.19042 |
| Windows Server 2022 | 10.0.20348 |
使用 RuntimeClass 进行简化
RuntimeClass 可用于简化使用污点和容忍度的流程。
集群管理员可以创建一个用于封装这些污点和容忍度的 RuntimeClass 对象。
-
将此文件保存到
runtimeClasses.yml。它包括针对 Windows 操作系统、架构和版本的nodeSelector。--- apiVersion: node.k8s.io/v1 kind: RuntimeClass metadata: name: windows-2019 handler: example-container-runtime-handler scheduling: nodeSelector: kubernetes.io/os: 'windows' kubernetes.io/arch: 'amd64' node.kubernetes.io/windows-build: '10.0.17763' tolerations: - effect: NoSchedule key: os operator: Equal value: "windows"
-
以集群管理员身份运行
kubectl create -f runtimeClasses.yml -
根据情况,向 Pod 规约中添加
runtimeClassName: windows-2019例如:
--- apiVersion: apps/v1 kind: Deployment metadata: name: iis-2019 labels: app: iis-2019 spec: replicas: 1 template: metadata: name: iis-2019 labels: app: iis-2019 spec: runtimeClassName: windows-2019 containers: - name: iis image: mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019 resources: limits: cpu: 1 memory: 800Mi requests: cpu: .1 memory: 300Mi ports: - containerPort: 80 selector: matchLabels: app: iis-2019 --- apiVersion: v1 kind: Service metadata: name: iis spec: type: LoadBalancer ports: - protocol: TCP port: 80 selector: app: iis-2019
13 - 扩展 Kubernetes
改变你的 Kubernetes 集群的行为的若干方法。
Kubernetes 是高度可配置且可扩展的。因此,大多数情况下, 你不需要派生自己的 Kubernetes 副本或者向项目代码提交补丁。
本指南描述定制 Kubernetes 的可选方式。主要针对的读者是希望了解如何针对自身工作环境需要来调整 Kubernetes 的集群管理者。 对于那些充当平台开发人员的开发人员或 Kubernetes 项目的贡献者而言, 他们也会在本指南中找到有用的介绍信息,了解系统中存在哪些扩展点和扩展模式, 以及它们所附带的各种权衡和约束等等。
定制化的方法主要可分为配置和扩展两种。 前者主要涉及更改命令行参数、本地配置文件或者 API 资源; 后者则需要额外运行一些程序、网络服务或两者。 本文主要关注扩展。
配置
配置文件和命令参数的说明位于在线文档的参考一节, 每个可执行文件一个页面:
在托管的 Kubernetes 服务中或者受控安装的发行版本中,命令参数和配置文件不总是可以修改的。 即使它们是可修改的,通常其修改权限也仅限于集群操作员。 此外,这些内容在将来的 Kubernetes 版本中很可能发生变化,设置新参数或配置文件可能需要重启进程。 有鉴于此,应该在没有其他替代方案时才会使用这些命令参数和配置文件。
诸如 ResourceQuota、 NetworkPolicy 和基于角色的访问控制(RBAC) 等内置策略 API 都是以声明方式配置策略选项的内置 Kubernetes API。 即使在托管的 Kubernetes 服务和受控的 Kubernetes 安装环境中,API 通常也是可用的。 内置策略 API 遵循与 Pod 这类其他 Kubernetes 资源相同的约定。 当你使用稳定版本的策略 API, 它们与其他 Kubernetes API 一样,采纳的是一种预定义的支持策略。 出于以上原因,在条件允许的情况下,基于策略 API 的方案应该优先于配置文件和命令参数。
扩展
扩展(Extensions)是一些扩充 Kubernetes 能力并与之深度集成的软件组件。 它们调整 Kubernetes 的工作方式使之支持新的类型和新的硬件种类。
大多数集群管理员会使用一种托管的 Kubernetes 服务或者其某种发行版本。 这类集群通常都预先安装了扩展。因此,大多数 Kubernetes 用户不需要安装扩展, 至于需要自己编写新的扩展的情况就更少了。
扩展模式
Kubernetes 从设计上即支持通过编写客户端程序来将其操作自动化。 任何能够对 Kubernetes API 发出读写指令的程序都可以提供有用的自动化能力。 自动化组件可以运行在集群上,也可以运行在集群之外。 通过遵从本文中的指南,你可以编写高度可用的、运行稳定的自动化组件。 自动化组件通常可以用于所有 Kubernetes 集群,包括托管的集群和受控的安装环境。
编写客户端程序有一种特殊的控制器(Controller)模式,
能够与 Kubernetes 很好地协同工作。控制器通常会读取某个对象的 .spec,或许还会执行一些操作,
之后更新对象的 .status。
控制器是 Kubernetes API 的客户端。当 Kubernetes 充当客户端且调用某远程服务时, Kubernetes 将此称作 Webhook。该远程服务称作 Webhook 后端。 与定制的控制器相似,Webhook 也会引入失效点(Point of Failure)。
说明:
在 Kubernetes 之外,“Webhook” 这个词通常是指一种异步通知机制, 其中 Webhook 调用将用作对另一个系统或组件的单向通知。 在 Kubernetes 生态系统中,甚至同步的 HTTP 调用也经常被描述为 “Webhook”。
在 Webhook 模型中,Kubernetes 向远程服务发起网络请求。 在另一种称作可执行文件插件(Binary Plugin) 模型中,Kubernetes 执行某个可执行文件(程序)。 这些可执行文件插件由 kubelet(例如,CSI 存储插件和 CNI 网络插件) 和 kubectl 使用。
扩展点
下图展示了 Kubernetes 集群中的这些扩展点及其访问集群的客户端。
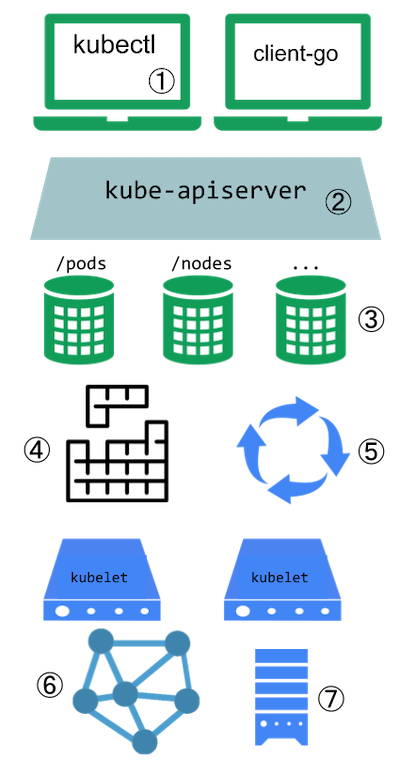
Kubernetes 扩展点
图示要点
-
用户通常使用
kubectl与 Kubernetes API 交互。 插件定制客户端的行为。 有一些通用的扩展可以应用到不同的客户端,还有一些特定的方式可以扩展kubectl。 -
API 服务器处理所有请求。API 服务器中的几种扩展点能够使用户对请求执行身份认证、 基于其内容阻止请求、编辑请求内容、处理删除操作等等。 这些扩展点在 API 访问扩展节详述。
-
API 服务器能提供各种类型的资源(Resources) 服务。 诸如
pods的内置资源类型是由 Kubernetes 项目所定义的,无法改变。 请查阅 API 扩展了解如何扩展 Kubernetes API。
-
Kubernetes 调度器负责决定 Pod 要放置到哪些节点上执行。有几种方式来扩展调度行为,这些方法将在调度器扩展节中展开说明。
-
Kubernetes 中的很多行为都是通过称为控制器(Controller)的程序来实现的, 这些程序也都是 API 服务器的客户端。控制器常常与定制资源结合使用。 进一步了解请查阅结合使用新的 API 与自动化组件和更改内置资源。
-
Kubelet 运行在各个服务器(节点)上,帮助 Pod 展现为虚拟的服务器并在集群网络中拥有自己的 IP。 网络插件使得 Kubernetes 能够采用不同实现技术来连接 Pod 网络。
-
你可以使用设备插件集成定制硬件或其他专用的节点本地设施, 使得这些设施可用于集群中运行的 Pod。Kubelet 包括了对使用设备插件的支持。
扩展点选择流程图
如果你无法确定从何处入手,下面的流程图可能对你有些帮助。 注意,某些方案可能需要同时采用几种类型的扩展。

选择一个扩展方式的流程图指导
客户端扩展
kubectl 所用的插件是单独的二进制文件,用于添加或替换特定子命令的行为。
kubectl 工具还可以与凭据插件集成。
这些扩展只影响单个用户的本地环境,因此不能强制执行站点范围的策略。
如果你要扩展 kubectl 工具,请阅读用插件扩展 kubectl。
API 扩展
定制资源对象
如果你想要定义新的控制器、应用配置对象或者其他声明式 API,并且使用 Kubernetes
工具(如 kubectl)来管理它们,可以考虑向 Kubernetes 添加定制资源。
关于定制资源的更多信息,可参见定制资源概念指南。
API 聚合层
你可以使用 Kubernetes 的 API 聚合层将 Kubernetes API 与其他服务集成,例如指标。
结合使用新 API 与自动化组件
定制资源 API 与控制回路的组合称作控制器模式。 如果你的控制器代替人工操作员根据所需状态部署基础设施,那么控制器也可以遵循 Operator 模式。 Operator 模式用于管理特定的应用;通常,这些应用需要维护状态并需要仔细考虑状态的管理方式。
你还可以创建自己的定制 API 和控制回路来管理其他资源(例如存储)或定义策略(例如访问控制限制)。
更改内置资源
当你通过添加定制资源来扩展 Kubernetes 时,所添加的资源总是会被放在一个新的 API 组中。 你不可以替换或更改现有的 API 组。添加新的 API 不会直接让你影响现有 API(如 Pod)的行为,不过 API 访问扩展能够实现这点。
API 访问扩展
当请求到达 Kubernetes API 服务器时,首先要经过身份认证,之后是鉴权操作, 再之后要经过若干类型的准入控制(某些请求实际上未通过身份认证,需要特殊处理)。 参见控制 Kubernetes API 访问以了解此流程的细节。
Kubernetes 身份认证/授权流程中的每个步骤都提供了扩展点。
身份认证
身份认证负责将所有请求中的头部或证书映射到发出该请求的客户端的用户名。
Kubernetes 提供若干内置的身份认证方法。它也可以运行在某种身份认证代理的后面,
并且可以将来自 Authorization: 头部的令牌发送到某个远程服务
(认证 Webhook
来执行验证操作,以备内置方法无法满足你的要求。
鉴权
鉴权操作负责确定特定的用户是否可以读、写 API 资源或对其执行其他操作。此操作仅在整个资源集合的层面进行。 换言之,它不会基于对象的特定字段作出不同的判决。
如果内置的鉴权选项无法满足你的需要, 你可以使用鉴权 Webhook 来调用用户提供的代码,执行定制的鉴权决定。
动态准入控制
请求的鉴权操作结束之后,如果请求的是写操作, 还会经过准入控制处理步骤。 除了内置的处理步骤,还存在一些扩展点:
- 镜像策略 Webhook 能够限制容器中可以运行哪些镜像。
- 为了执行任意的准入控制决定, 可以使用一种通用的准入 Webhook 机制。这类准入 Webhook 可以拒绝创建或更新请求。 一些准入 Webhook 会先修改传入的请求数据,才会由 Kubernetes 进一步处理这些传入请求数据。
基础设施扩展
设备插件
设备插件允许一个节点通过设备插件发现新的 Node 资源(除了内置的类似 CPU 和内存这类资源之外)。
存储插件
容器存储接口 (CSI) 插件提供了一种扩展 Kubernetes 的方式使其支持新类别的卷。 这些卷可以由持久的外部存储提供支持,可以提供临时存储,还可以使用文件系统范型为信息提供只读接口。
Kubernetes 还包括对 FlexVolume 插件的支持,该插件自 Kubernetes v1.23 起被弃用(被 CSI 替代)。
FlexVolume 插件允许用户挂载 Kubernetes 本身不支持的卷类型。 当你运行依赖于 FlexVolume 存储的 Pod 时,kubelet 会调用一个二进制插件来挂载该卷。 归档的 FlexVolume 设计提案对此方法有更多详细说明。
Kubernetes 存储供应商的卷插件 FAQ 包含了有关存储插件的通用信息。
网络插件
你的 Kubernetes 集群需要一个网络插件才能拥有一个正常工作的 Pod 网络, 才能支持 Kubernetes 网络模型的其他方面。
网络插件可以让 Kubernetes 使用不同的网络拓扑和技术。
Kubelet 镜像凭据提供程序插件
特性状态:
Kubelet 镜像凭据提供程序是 Kubelet 动态检索镜像仓库凭据的插件。
当你从与配置匹配的容器镜像仓库中拉取镜像时,这些凭据将被使用。
Kubernetes v1.26 [stable]
这些插件可以与外部服务通信或使用本地文件来获取凭据。这样,kubelet 就不需要为每个仓库都设置静态凭据,并且可以支持各种身份验证方法和协议。
有关插件配置的详细信息,请参阅 配置 kubelet 镜像凭据提供程序。
调度扩展
调度器是一种特殊的控制器,负责监视 Pod 变化并将 Pod 分派给节点。 默认的调度器可以被整体替换掉,同时继续使用其他 Kubernetes 组件。 或者也可以在同一时刻使用多个调度器。
这是一项非同小可的任务,几乎绝大多数 Kubernetes 用户都会发现其实他们不需要修改调度器。
你可以控制哪些调度插件处于激活状态, 或将插件集关联到名字不同的调度器配置文件上。 你还可以编写自己的插件,与一个或多个 kube-scheduler 的扩展点集成。
最后,内置的 kube-scheduler 组件支持
Webhook,
从而允许远程 HTTP 后端(调度器扩展)来为 kube-scheduler 选择的 Pod 所在节点执行过滤和优先排序操作。
说明:
你只能使用调度器扩展程序 Webhook 来影响节点过滤和节点优先排序; 其他扩展点无法通过集成 Webhook 获得。
接下来
- 进一步了解基础设施扩展
- 进一步了解 kubectl 插件
- 进一步了解定制资源
- 进一步了解扩展 API 服务器
- 进一步了解动态准入控制
- 进一步了解 Operator 模式
13.1 - Operator 模式
Operator 是 Kubernetes 的扩展软件, 它利用定制资源管理应用及其组件。 Operator 遵循 Kubernetes 的理念,特别是在控制器方面。
初衷
Operator 模式 旨在记述(正在管理一个或一组服务的)运维人员的关键目标。 这些运维人员负责一些特定的应用和 Service,他们需要清楚地知道系统应该如何运行、如何部署以及出现问题时如何处理。
在 Kubernetes 上运行工作负载的人们都喜欢通过自动化来处理重复的任务。 Operator 模式会封装你编写的(Kubernetes 本身提供功能以外的)任务自动化代码。
Kubernetes 上的 Operator
Kubernetes 为自动化而生。无需任何修改,你即可以从 Kubernetes 核心中获得许多内置的自动化功能。 你可以使用 Kubernetes 自动化部署和运行工作负载,甚至 可以自动化 Kubernetes 自身。
Kubernetes 的 Operator 模式概念允许你在不修改 Kubernetes 自身代码的情况下, 通过为一个或多个自定义资源关联控制器来扩展集群的能力。 Operator 是 Kubernetes API 的客户端, 充当自定义资源的控制器。
Operator 示例
使用 Operator 可以自动化的事情包括:
- 按需部署应用
- 获取/还原应用状态的备份
- 处理应用代码的升级以及相关改动。例如数据库 Schema 或额外的配置设置
- 发布一个 Service,要求不支持 Kubernetes API 的应用也能发现它
- 模拟整个或部分集群中的故障以测试其稳定性
- 在没有内部成员选举程序的情况下,为分布式应用选择首领角色
想要更详细的了解 Operator?下面是一个示例:
- 有一个名为 SampleDB 的自定义资源,你可以将其配置到集群中。
- 一个包含 Operator 控制器部分的 Deployment,用来确保 Pod 处于运行状态。
- Operator 代码的容器镜像。
- 控制器代码,负责查询控制平面以找出已配置的 SampleDB 资源。
- Operator 的核心是告诉 API 服务器,如何使现实与代码里配置的资源匹配。
- 如果添加新的 SampleDB,Operator 将设置 PersistentVolumeClaims 以提供持久化的数据库存储, 设置 StatefulSet 以运行 SampleDB,并设置 Job 来处理初始配置。
- 如果你删除它,Operator 将建立快照,然后确保 StatefulSet 和 Volume 已被删除。
- Operator 也可以管理常规数据库的备份。对于每个 SampleDB 资源,Operator 会确定何时创建(可以连接到数据库并进行备份的)Pod。这些 Pod 将依赖于 ConfigMap 和/或具有数据库连接详细信息和凭据的 Secret。
- 由于 Operator 旨在为其管理的资源提供强大的自动化功能,因此它还需要一些额外的支持性代码。 在这个示例中,代码将检查数据库是否正运行在旧版本上, 如果是,则创建 Job 对象为你升级数据库。
部署 Operator
部署 Operator 最常见的方法是将自定义资源及其关联的控制器添加到你的集群中。 跟运行容器化应用一样,控制器通常会运行在控制平面之外。 例如,你可以在集群中将控制器作为 Deployment 运行。
使用 Operator
部署 Operator 后,你可以对 Operator 所使用的资源执行添加、修改或删除操作。 按照上面的示例,你将为 Operator 本身建立一个 Deployment,然后:
kubectl get SampleDB # 查找所配置的数据库
kubectl edit SampleDB/example-database # 手动修改某些配置
可以了!Operator 会负责应用所作的更改并保持现有服务处于良好的状态。
编写你自己的 Operator
如果生态系统中没有可以实现你目标的 Operator,你可以自己编写代码。
你还可以使用任何支持 Kubernetes API 客户端的语言或运行时来实现 Operator(即控制器)。
以下是一些库和工具,你可用于编写自己的云原生 Operator。
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
- Charmed Operator Framework
- Java Operator SDK
- Kopf (Kubernetes Operator Pythonic Framework)
- kube-rs (Rust)
- kubebuilder
- KubeOps (.NET operator SDK)
- KUDO(Kubernetes 通用声明式 Operator)
- Mast
- Metacontroller,可与 Webhook 结合使用,以实现自己的功能。
- Operator Framework
- shell-operator
接下来
- 阅读 CNCF Operator 白皮书。
- 详细了解定制资源
- 在 OperatorHub.io 上找到现成的、适合你的 Operator
- 发布你的 Operator,让别人也可以使用
- 阅读 CoreOS 原始文章,它介绍了 Operator 模式(这是一个存档版本的原始文章)。
- 阅读这篇来自谷歌云的关于构建 Operator 最佳实践的文章
13.2 - 计算、存储和网络扩展
本节介绍不属于 Kubernetes 本身组成部分的一些集群扩展。 你可以使用这些扩展来增强集群中的节点,或者提供将 Pod 关联在一起的网络结构。
-
CSI 和 FlexVolume 存储插件
容器存储接口 (CSI) 插件提供了一种扩展 Kubernetes 的方式使其支持新类别的卷。 这些卷可以由持久的外部存储提供支持,可以提供临时存储,还可以使用文件系统范型为信息提供只读接口。
Kubernetes 还包括对 FlexVolume 插件的扩展支持,该插件自 Kubernetes v1.23 起被弃用(被 CSI 替代)。
FlexVolume 插件允许用户挂载 Kubernetes 本身不支持的卷类型。 当你运行依赖于 FlexVolume 存储的 Pod 时,kubelet 会调用一个二进制插件来挂载该卷。 归档的 FlexVolume 设计提案对此方法有更多详细说明。
Kubernetes 存储供应商的卷插件 FAQ 包含了有关存储插件的通用信息。
-
设备插件允许一个节点发现新的 Node 设施(除了
cpu和memory等内置的节点资源之外), 并向请求资源的 Pod 提供了这些自定义的节点本地设施。
13.2.1 - 网络插件
Kubernetes 1.29 支持用于集群联网的容器网络接口 (CNI) 插件。 你必须使用和你的集群相兼容并且满足你的需求的 CNI 插件。 在更广泛的 Kubernetes 生态系统中你可以使用不同的插件(开源和闭源)。
要实现 Kubernetes 网络模型,你需要一个 CNI 插件。
你必须使用与 v0.4.0 或更高版本的 CNI 规范相符合的 CNI 插件。 Kubernetes 推荐使用一个兼容 v1.0.0 CNI 规范的插件(插件可以兼容多个规范版本)。
安装
在网络语境中,容器运行时(Container Runtime)是在节点上的守护进程, 被配置用来为 kubelet 提供 CRI 服务。具体而言,容器运行时必须配置为加载所需的 CNI 插件,从而实现 Kubernetes 网络模型。
说明:
在 Kubernetes 1.24 之前,CNI 插件也可以由 kubelet 使用命令行参数 cni-bin-dir
和 network-plugin 管理。Kubernetes 1.24 移除了这些命令行参数,
CNI 的管理不再是 kubelet 的工作。
如果你在移除 dockershim 之后遇到问题, 请参阅排查 CNI 插件相关的错误。
要了解容器运行时如何管理 CNI 插件的具体信息,可参见对应容器运行时的文档,例如:
要了解如何安装和管理 CNI 插件的具体信息,可参阅对应的插件或 网络驱动(Networking Provider) 的文档。
网络插件要求
对于插件开发人员以及时常会构建并部署 Kubernetes 的用户而言,
插件可能也需要特定的配置来支持 kube-proxy。
iptables 代理依赖于 iptables,插件可能需要确保 iptables 能够监控容器的网络通信。
例如,如果插件将容器连接到 Linux 网桥,插件必须将 net/bridge/bridge-nf-call-iptables
sysctl 参数设置为 1,以确保 iptables 代理正常工作。
如果插件不使用 Linux 网桥,而是使用类似于 Open vSwitch 或者其它一些机制,
它应该确保为代理对容器通信执行正确的路由。
默认情况下,如果未指定 kubelet 网络插件,则使用 noop 插件,
该插件设置 net/bridge/bridge-nf-call-iptables=1,以确保简单的配置
(如带网桥的 Docker)与 iptables 代理正常工作。
本地回路 CNI
除了安装到节点上用于实现 Kubernetes 网络模型的 CNI 插件外,Kubernetes
还需要容器运行时提供一个本地回路接口 lo,用于各个沙箱(Pod 沙箱、虚机沙箱……)。
实现本地回路接口的工作可以通过复用
CNI 本地回路插件来实现,
也可以通过开发自己的代码来实现
(参阅 CRI-O 中的示例)。
支持 hostPort
CNI 网络插件支持 hostPort。你可以使用官方
portmap
插件,它由 CNI 插件团队提供,或者使用你自己的带有 portMapping 功能的插件。
如果你想要启动 hostPort 支持,则必须在 cni-conf-dir 指定 portMappings capability。
例如:
{
"name": "k8s-pod-network",
"cniVersion": "0.4.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"capabilities": {"portMappings": true},
"externalSetMarkChain": "KUBE-MARK-MASQ"
}
]
}
支持流量整形
实验功能
CNI 网络插件还支持 Pod 入站和出站流量整形。 你可以使用 CNI 插件团队提供的 bandwidth 插件,也可以使用你自己的具有带宽控制功能的插件。
如果你想要启用流量整形支持,你必须将 bandwidth 插件添加到 CNI 配置文件
(默认是 /etc/cni/net.d)并保证该可执行文件包含在你的 CNI 的 bin
文件夹内 (默认为 /opt/cni/bin)。
{
"name": "k8s-pod-network",
"cniVersion": "0.4.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
}
]
}
现在,你可以将 kubernetes.io/ingress-bandwidth 和 kubernetes.io/egress-bandwidth
注解添加到 Pod 中。例如:
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/ingress-bandwidth: 1M
kubernetes.io/egress-bandwidth: 1M
...
接下来
- 进一步了解关于集群网络的信息
- 进一步了解关于网络策略的信息
- 进一步了解关于排查 CNI 插件相关错误的信息
13.2.2 - 设备插件
设备插件可以让你配置集群以支持需要特定于供应商设置的设备或资源,例如 GPU、NIC、FPGA 或非易失性主存储器。
特性状态:
Kubernetes v1.26 [stable]
Kubernetes 提供了一个设备插件框架,你可以用它来将系统硬件资源发布到 Kubelet。
供应商可以实现设备插件,由你手动部署或作为 DaemonSet 来部署,而不必定制 Kubernetes 本身的代码。目标设备包括 GPU、高性能 NIC、FPGA、 InfiniBand 适配器以及其他类似的、可能需要特定于供应商的初始化和设置的计算资源。
注册设备插件
kubelet 提供了一个 Registration 的 gRPC 服务:
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
设备插件可以通过此 gRPC 服务在 kubelet 进行注册。在注册期间,设备插件需要发送下面几样内容:
- 设备插件的 Unix 套接字。
- 设备插件的 API 版本。
ResourceName是需要公布的。这里ResourceName需要遵循扩展资源命名方案, 类似于vendor-domain/resourcetype。(比如 NVIDIA GPU 就被公布为nvidia.com/gpu。)
成功注册后,设备插件就向 kubelet 发送它所管理的设备列表,然后 kubelet 负责将这些资源发布到 API 服务器,作为 kubelet 节点状态更新的一部分。
比如,设备插件在 kubelet 中注册了 hardware-vendor.example/foo
并报告了节点上的两个运行状况良好的设备后,节点状态将更新以通告该节点已安装 2 个
"Foo" 设备并且是可用的。
然后,用户可以请求设备作为 Pod 规范的一部分, 参见 Container。 请求扩展资源类似于管理请求和限制的方式, 其他资源,有以下区别:
- 扩展资源仅可作为整数资源使用,并且不能被过量使用
- 设备不能在容器之间共享
示例
假设 Kubernetes 集群正在运行一个设备插件,该插件在一些节点上公布的资源为 hardware-vendor.example/foo。
下面就是一个 Pod 示例,请求此资源以运行一个工作负载的示例:
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
containers:
- name: demo-container-1
image: registry.k8s.io/pause:2.0
resources:
limits:
hardware-vendor.example/foo: 2
#
# 这个 pod 需要两个 hardware-vendor.example/foo 设备
# 而且只能够调度到满足需求的节点上
#
# 如果该节点中有 2 个以上的设备可用,其余的可供其他 Pod 使用
设备插件的实现
设备插件的常规工作流程包括以下几个步骤:
-
初始化。在这个阶段,设备插件将执行特定于供应商的初始化和设置,以确保设备处于就绪状态。
-
插件使用主机路径
/var/lib/kubelet/device-plugins/下的 UNIX 套接字启动一个 gRPC 服务,该服务实现以下接口:service DevicePlugin { // GetDevicePluginOptions 返回与设备管理器沟通的选项。 rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {} // ListAndWatch 返回 Device 列表构成的数据流。 // 当 Device 状态发生变化或者 Device 消失时,ListAndWatch // 会返回新的列表。 rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {} // Allocate 在容器创建期间调用,这样设备插件可以运行一些特定于设备的操作, // 并告诉 kubelet 如何令 Device 可在容器中访问的所需执行的具体步骤 rpc Allocate(AllocateRequest) returns (AllocateResponse) {} // GetPreferredAllocation 从一组可用的设备中返回一些优选的设备用来分配, // 所返回的优选分配结果不一定会是设备管理器的最终分配方案。 // 此接口的设计仅是为了让设备管理器能够在可能的情况下做出更有意义的决定。 rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {} // PreStartContainer 在设备插件注册阶段根据需要被调用,调用发生在容器启动之前。 // 在将设备提供给容器使用之前,设备插件可以运行一些诸如重置设备之类的特定于 // 具体设备的操作, rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {} }说明:插件并非必须为
GetPreferredAllocation()或PreStartContainer()提供有用的实现逻辑, 调用GetDevicePluginOptions()时所返回的DevicePluginOptions消息中应该设置一些标志,表明这些调用(如果有)是否可用。kubelet在直接调用这些函数之前,总会调用GetDevicePluginOptions()来查看哪些可选的函数可用。
-
插件通过位于主机路径
/var/lib/kubelet/device-plugins/kubelet.sock下的 UNIX 套接字向 kubelet 注册自身。说明:工作流程的顺序很重要。插件必须在向 kubelet 注册自己之前开始提供 gRPC 服务,才能保证注册成功。
-
成功注册自身后,设备插件将以提供服务的模式运行,在此期间,它将持续监控设备运行状况, 并在设备状态发生任何变化时向 kubelet 报告。它还负责响应
AllocategRPC 请求。 在Allocate期间,设备插件可能还会做一些特定于设备的准备;例如 GPU 清理或 QRNG 初始化。 如果操作成功,则设备插件将返回AllocateResponse,其中包含用于访问被分配的设备容器运行时的配置。 kubelet 将此信息传递到容器运行时。AllocateResponse包含零个或多个ContainerAllocateResponse对象。 设备插件在这些对象中给出为了访问设备而必须对容器定义所进行的修改。 这些修改包括:- 注解
- 设备节点
- 环境变量
- 挂载点
- 完全限定的 CDI 设备名称
说明:设备管理器处理完全限定的 CDI 设备名称时, 需要为 kubelet 和 kube-apiserver 启用
DevicePluginCDIDevices特性门控。 在 Kubernetes v1.28 版本中作为 Alpha 特性被加入,并在 v1.29 版本中升级为 Beta 特性。
处理 kubelet 重启
设备插件应能监测到 kubelet 重启,并且向新的 kubelet 实例来重新注册自己。
新的 kubelet 实例启动时会删除 /var/lib/kubelet/device-plugins 下所有已经存在的 Unix 套接字。
设备插件需要能够监控到它的 Unix 套接字被删除,并且当发生此类事件时重新注册自己。
设备插件部署
你可以将你的设备插件作为节点操作系统的软件包来部署、作为 DaemonSet 来部署或者手动部署。
规范目录 /var/lib/kubelet/device-plugins 是需要特权访问的,
所以设备插件必须要在被授权的安全的上下文中运行。
如果你将设备插件部署为 DaemonSet,/var/lib/kubelet/device-plugins 目录必须要在插件的
PodSpec
中声明作为 卷(Volume) 被挂载到插件中。
如果你选择 DaemonSet 方法,你可以通过 Kubernetes 进行以下操作: 将设备插件的 Pod 放置在节点上,在出现故障后重新启动守护进程 Pod,来进行自动升级。
API 兼容性
之前版本控制方案要求设备插件的 API 版本与 Kubelet 的版本完全匹配。 自从此特性在 v1.12 中进阶为 Beta 后,这不再是硬性要求。 API 是版本化的,并且自此特性进阶 Beta 后一直表现稳定。 因此,kubelet 升级应该是无缝的,但在稳定之前 API 仍然可能会有变更,还不能保证升级不会中断。
说明:
尽管 Kubernetes 的设备管理器(Device Manager)组件是正式发布的特性, 但设备插件 API 还不稳定。有关设备插件 API 和版本兼容性的信息, 请参阅设备插件 API 版本。
作为一个项目,Kubernetes 建议设备插件开发者:
- 注意未来版本中设备插件 API 的变更。
- 支持多个版本的设备插件 API,以实现向后/向前兼容性。
若在需要升级到具有较新设备插件 API 版本的某个 Kubernetes 版本的节点上运行这些设备插件, 请在升级这些节点之前先升级设备插件以支持这两个版本。 采用该方法将确保升级期间设备分配的连续运行。
监控设备插件资源
特性状态:
Kubernetes v1.28 [stable]
为了监控设备插件提供的资源,监控代理程序需要能够发现节点上正在使用的设备,
并获取元数据来描述哪个指标与容器相关联。
设备监控代理暴露给 Prometheus 的指标应该遵循
Kubernetes Instrumentation Guidelines,
使用 pod、namespace 和 container 标签来标识容器。
kubelet 提供了 gRPC 服务来使得正在使用中的设备被发现,并且还为这些设备提供了元数据:
// PodResourcesLister 是一个由 kubelet 提供的服务,用来提供供节点上
// Pod 和容器使用的节点资源的信息
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
rpc Get(GetPodResourcesRequest) returns (GetPodResourcesResponse) {}
}
List gRPC 端点
这一 List 端点提供运行中 Pod 的资源信息,包括类似独占式分配的
CPU ID、设备插件所报告的设备 ID 以及这些设备分配所处的 NUMA 节点 ID。
此外,对于基于 NUMA 的机器,它还会包含为容器保留的内存和大页的信息。
从 Kubernetes v1.27 开始,List 端点可以通过 DynamicResourceAllocation API 提供在
ResourceClaims 中分配的当前运行 Pod 的资源信息。
要启用此特性,必须使用以下标志启动 kubelet:
--feature-gates=DynamicResourceAllocation=true,KubeletPodResourcesDynamicResources=true
// ListPodResourcesResponse 是 List 函数的响应
message ListPodResourcesResponse {
repeated PodResources pod_resources = 1;
}
// PodResources 包含关于分配给 Pod 的节点资源的信息
message PodResources {
string name = 1;
string namespace = 2;
repeated ContainerResources containers = 3;
}
// ContainerResources 包含分配给容器的资源的信息
message ContainerResources {
string name = 1;
repeated ContainerDevices devices = 2;
repeated int64 cpu_ids = 3;
repeated ContainerMemory memory = 4;
repeated DynamicResource dynamic_resources = 5;
}
// ContainerMemory 包含分配给容器的内存和大页信息
message ContainerMemory {
string memory_type = 1;
uint64 size = 2;
TopologyInfo topology = 3;
}
// Topology 描述资源的硬件拓扑结构
message TopologyInfo {
repeated NUMANode nodes = 1;
}
// NUMA 代表的是 NUMA 节点
message NUMANode {
int64 ID = 1;
}
// ContainerDevices 包含分配给容器的设备信息
message ContainerDevices {
string resource_name = 1;
repeated string device_ids = 2;
TopologyInfo topology = 3;
}
// DynamicResource 包含通过 Dynamic Resource Allocation 分配到容器的设备信息
message DynamicResource {
string class_name = 1;
string claim_name = 2;
string claim_namespace = 3;
repeated ClaimResource claim_resources = 4;
}
// ClaimResource 包含每个插件的资源信息
message ClaimResource {
repeated CDIDevice cdi_devices = 1 [(gogoproto.customname) = "CDIDevices"];
}
// CDIDevice 指定 CDI 设备信息
message CDIDevice {
// 完全合格的 CDI 设备名称
// 例如:vendor.com/gpu=gpudevice1
// 参阅 CDI 规范中的更多细节:
// https://github.com/container-orchestrated-devices/container-device-interface/blob/main/SPEC.md
string name = 1;
}
说明:
List 端点中的 ContainerResources 中的 cpu_ids 对应于分配给某个容器的专属 CPU。
如果要统计共享池中的 CPU,List 端点需要与 GetAllocatableResources 端点一起使用,如下所述:
- 调用
GetAllocatableResources获取所有可用的 CPU。 - 在系统中所有的
ContainerResources上调用GetCpuIds。 - 用
GetAllocatableResources获取的 CPU 数减去GetCpuIds获取的 CPU 数。
GetAllocatableResources gRPC 端点
特性状态:
Kubernetes v1.28 [stable]
端点 GetAllocatableResources 提供工作节点上原始可用的资源信息。
此端点所提供的信息比导出给 API 服务器的信息更丰富。
说明:
GetAllocatableResources 应该仅被用于评估一个节点上的可分配的资源。
如果目标是评估空闲/未分配的资源,此调用应该与 List() 端点一起使用。
除非暴露给 kubelet 的底层资源发生变化,否则 GetAllocatableResources 得到的结果将保持不变。
这种情况很少发生,但当发生时(例如:热插拔,设备健康状况改变),客户端应该调用 GetAlloctableResources 端点。
然而,调用 GetAllocatableResources 端点在 cpu、内存被更新的情况下是不够的,
Kubelet 需要重新启动以获取正确的资源容量和可分配的资源。
// AllocatableResourcesResponses 包含 kubelet 所了解到的所有设备的信息
message AllocatableResourcesResponse {
repeated ContainerDevices devices = 1;
repeated int64 cpu_ids = 2;
repeated ContainerMemory memory = 3;
}
ContainerDevices 会向外提供各个设备所隶属的 NUMA 单元这类拓扑信息。
NUMA 单元通过一个整数 ID 来标识,其取值与设备插件所报告的一致。
设备插件注册到 kubelet 时
会报告这类信息。
gRPC 服务通过 /var/lib/kubelet/pod-resources/kubelet.sock 的 UNIX 套接字来提供服务。
设备插件资源的监控代理程序可以部署为守护进程或者 DaemonSet。
规范的路径 /var/lib/kubelet/pod-resources 需要特权来进入,
所以监控代理程序必须要在获得授权的安全的上下文中运行。
如果设备监控代理以 DaemonSet 形式运行,必须要在插件的
PodSpec
中声明将 /var/lib/kubelet/pod-resources
目录以卷的形式被挂载到设备监控代理中。
说明:
在从 DaemonSet 或以容器形式部署在主机上的任何其他应用中访问
/var/lib/kubelet/pod-resources/kubelet.sock 时,
如果将套接字作为卷挂载,最好的做法是挂载目录 /var/lib/kubelet/pod-resources/
而不是 /var/lib/kubelet/pod-resources/kubelet.sock。
这样可以确保在 kubelet 重新启动后,容器将能够重新连接到此套接字。
容器挂载是通过引用套接字或目录的 inode 进行管理的,具体取决于挂载的内容。 当 kubelet 重新启动时,套接字会被删除并创建一个新的套接字,而目录则保持不变。 因此,针对原始套接字的 inode 将变得无法使用,而到目录的 inode 将继续正常工作。
Get gRPC 端点
特性状态:
Kubernetes v1.27 [alpha]
Get 端点提供了当前运行 Pod 的资源信息。它会暴露与 List 端点中所述类似的信息。
Get 端点需要当前运行 Pod 的 PodName 和 PodNamespace。
// GetPodResourcesRequest 包含 Pod 相关信息
message GetPodResourcesRequest {
string pod_name = 1;
string pod_namespace = 2;
}
要启用此特性,你必须使用以下标志启动 kubelet 服务:
--feature-gates=KubeletPodResourcesGet=true
Get 端点可以提供与动态资源分配 API 所分配的动态资源相关的 Pod 信息。
要启用此特性,你必须确保使用以下标志启动 kubelet 服务:
--feature-gates=KubeletPodResourcesGet=true,DynamicResourceAllocation=true,KubeletPodResourcesDynamicResources=true
设备插件与拓扑管理器的集成
特性状态:
Kubernetes v1.27 [stable]
拓扑管理器是 Kubelet 的一个组件,它允许以拓扑对齐方式来调度资源。
为了做到这一点,设备插件 API 进行了扩展来包括一个 TopologyInfo 结构体。
message TopologyInfo {
repeated NUMANode nodes = 1;
}
message NUMANode {
int64 ID = 1;
}
设备插件希望拓扑管理器可以将填充的 TopologyInfo 结构体作为设备注册的一部分以及设备 ID 和设备的运行状况发送回去。然后设备管理器将使用此信息来咨询拓扑管理器并做出资源分配决策。
TopologyInfo 支持将 nodes 字段设置为 nil 或一个 NUMA 节点的列表。
这样就可以使设备插件通告跨越多个 NUMA 节点的设备。
将 TopologyInfo 设置为 nil 或为给定设备提供一个空的
NUMA 节点列表表示设备插件没有该设备的 NUMA 亲和偏好。
下面是一个由设备插件为设备填充 TopologyInfo 结构体的示例:
pluginapi.Device{ID: "25102017", Health: pluginapi.Healthy, Topology:&pluginapi.TopologyInfo{Nodes: []*pluginapi.NUMANode{&pluginapi.NUMANode{ID: 0,},}}}
设备插件示例
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循CNCF 网站指南,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读内容指南。
下面是一些设备插件实现的示例:
- AMD GPU 设备插件
- 适用于通用 Linux 设备和 USB 设备的通用设备插件
- Intel 设备插件支持 Intel GPU、FPGA、QAT、VPU、SGX、DSA、DLB 和 IAA 设备
- KubeVirt 设备插件 用于硬件辅助的虚拟化
- 为 Container-Optimized OS 所提供的 NVIDIA GPU 设备插件
- RDMA 设备插件
- SocketCAN 设备插件
- Solarflare 设备插件
- SR-IOV 网络设备插件
- Xilinx FPGA 设备插件
接下来
- 查看调度 GPU 资源来学习使用设备插件
- 查看在节点上如何公布扩展资源
- 学习拓扑管理器
- 阅读如何在 Kubernetes 中使用 TLS Ingress 的硬件加速
13.3 - 扩展 Kubernetes API
13.3.1 - 定制资源
定制资源(Custom Resource) 是对 Kubernetes API 的扩展。 本页讨论何时向 Kubernetes 集群添加定制资源,何时使用独立的服务。 本页描述添加定制资源的两种方法以及怎样在二者之间做出抉择。
定制资源
资源(Resource) 是 Kubernetes API 中的一个端点, 其中存储的是某个类别的 API 对象的一个集合。 例如内置的 Pod 资源包含一组 Pod 对象。
定制资源(Custom Resource) 是对 Kubernetes API 的扩展,不一定在默认的 Kubernetes 安装中就可用。定制资源所代表的是对特定 Kubernetes 安装的一种定制。 不过,很多 Kubernetes 核心功能现在都用定制资源来实现,这使得 Kubernetes 更加模块化。
定制资源可以通过动态注册的方式在运行中的集群内或出现或消失,集群管理员可以独立于集群更新定制资源。 一旦某定制资源被安装,用户可以使用 kubectl 来创建和访问其中的对象,就像他们为 Pod 这种内置资源所做的一样。
定制控制器
就定制资源本身而言,它只能用来存取结构化的数据。 当你将定制资源与定制控制器(Custom Controller) 结合时, 定制资源就能够提供真正的声明式 API(Declarative API)。
Kubernetes 声明式 API 强制对职权做了一次分离操作。 你声明所用资源的期望状态,而 Kubernetes 控制器使 Kubernetes 对象的当前状态与你所声明的期望状态保持同步。 声明式 API 的这种机制与命令式 API(你指示服务器要做什么,服务器就去做什么)形成鲜明对比。
你可以在一个运行中的集群上部署和更新定制控制器,这类操作与集群的生命周期无关。 定制控制器可以用于任何类别的资源,不过它们与定制资源结合起来时最为有效。 Operator 模式就是将定制资源与定制控制器相结合的。 你可以使用定制控制器来将特定于某应用的领域知识组织起来,以编码的形式构造对 Kubernetes API 的扩展。
我是否应该向我的 Kubernetes 集群添加定制资源?
在创建新的 API 时, 请考虑是将你的 API 与 Kubernetes 集群 API 聚合起来, 还是让你的 API 独立运行。
| 考虑 API 聚合的情况 | 优选独立 API 的情况 |
|---|---|
| 你的 API 是声明式的。 | 你的 API 不符合声明式模型。 |
你希望可以是使用 kubectl 来读写你的新资源类别。 |
不要求 kubectl 支持。 |
| 你希望在 Kubernetes UI (如仪表板)中和其他内置类别一起查看你的新资源类别。 | 不需要 Kubernetes UI 支持。 |
| 你在开发新的 API。 | 你已经有一个提供 API 服务的程序并且工作良好。 |
| 你有意愿取接受 Kubernetes 对 REST 资源路径所作的格式限制,例如 API 组和名字空间。(参阅 API 概述) | 你需要使用一些特殊的 REST 路径以便与已经定义的 REST API 保持兼容。 |
| 你的资源可以自然地界定为集群作用域或集群中某个名字空间作用域。 | 集群作用域或名字空间作用域这种二分法很不合适;你需要对资源路径的细节进行控制。 |
| 你希望复用 Kubernetes API 支持特性。 | 你不需要这类特性。 |
声明式 API
典型地,在声明式 API 中:
- 你的 API 包含相对而言为数不多的、尺寸较小的对象(资源)。
- 对象定义了应用或者基础设施的配置信息。
- 对象更新操作频率较低。
- 通常需要人来读取或写入对象。
- 对象的主要操作是 CRUD 风格的(创建、读取、更新和删除)。
- 不需要跨对象的事务支持:API 对象代表的是期望状态而非确切实际状态。
命令式 API(Imperative API)与声明式有所不同。 以下迹象表明你的 API 可能不是声明式的:
- 客户端发出“做这个操作”的指令,之后在该操作结束时获得同步响应。
- 客户端发出“做这个操作”的指令,并获得一个操作 ID,之后需要检查一个 Operation(操作) 对象来判断请求是否成功完成。
- 你会将你的 API 类比为远程过程调用(Remote Procedure Call,RPC)。
- 直接存储大量数据;例如每个对象几 kB,或者存储上千个对象。
- 需要较高的访问带宽(长期保持每秒数十个请求)。
- 存储有应用来处理的最终用户数据(如图片、个人标识信息(PII)等)或者其他大规模数据。
- 在对象上执行的常规操作并非 CRUD 风格。
- API 不太容易用对象来建模。
- 你决定使用操作 ID 或者操作对象来表现悬决的操作。
我应该使用一个 ConfigMap 还是一个定制资源?
如果满足以下条件之一,应该使用 ConfigMap:
- 存在一个已有的、文档完备的配置文件格式约定,例如
mysql.cnf或pom.xml。 - 你希望将整个配置文件放到某 configMap 中的一个主键下面。
- 配置文件的主要用途是针对运行在集群中 Pod 内的程序,供后者依据文件数据配置自身行为。
- 文件的使用者期望以 Pod 内文件或者 Pod 内环境变量的形式来使用文件数据, 而不是通过 Kubernetes API。
- 你希望当文件被更新时通过类似 Deployment 之类的资源完成滚动更新操作。
说明:
请使用 Secret 来保存敏感数据。 Secret 类似于 configMap,但更为安全。
如果以下条件中大多数都被满足,你应该使用定制资源(CRD 或者 聚合 API):
- 你希望使用 Kubernetes 客户端库和 CLI 来创建和更改新的资源。
- 你希望
kubectl能够直接支持你的资源;例如,kubectl get my-object object-name。 - 你希望构造新的自动化机制,监测新对象上的更新事件,并对其他对象执行 CRUD 操作,或者监测后者更新前者。
- 你希望编写自动化组件来处理对对象的更新。
- 你希望使用 Kubernetes API 对诸如
.spec、.status和.metadata等字段的约定。 - 你希望对象是对一组受控资源的抽象,或者对其他资源的归纳提炼。
添加定制资源
Kubernetes 提供了两种方式供你向集群中添加定制资源:
- CRD 相对简单,创建 CRD 可以不必编程。
- API 聚合需要编程, 但支持对 API 行为进行更多的控制,例如数据如何存储以及在不同 API 版本间如何转换等。
Kubernetes 提供这两种选项以满足不同用户的需求,这样就既不会牺牲易用性也不会牺牲灵活性。
聚合 API 指的是一些下位的 API 服务器,运行在主 API 服务器后面;主 API 服务器以代理的方式工作。这种组织形式称作 API 聚合(API Aggregation,AA) 。 对用户而言,看起来仅仅是 Kubernetes API 被扩展了。
CRD 允许用户创建新的资源类别同时又不必添加新的 API 服务器。 使用 CRD 时,你并不需要理解 API 聚合。
无论以哪种方式安装定制资源,新的资源都会被当做定制资源,以便与内置的 Kubernetes 资源(如 Pods)相区分。
说明:
避免将定制资源用于存储应用、最终用户或监控数据: 将应用数据存储在 Kubernetes API 内的架构设计通常代表一种过于紧密耦合的设计。
在架构上,云原生应用架构倾向于各组件之间的松散耦合。 如果部分工作负载需要支持服务来维持其日常运转,则这种支持服务应作为一个组件运行或作为一个外部服务来使用。 这样,工作负载的正常运转就不会依赖 Kubernetes API 了。
CustomResourceDefinitions
CustomResourceDefinition API 资源允许你定义定制资源。 定义 CRD 对象的操作会使用你所设定的名字和模式定义(Schema)创建一个新的定制资源, Kubernetes API 负责为你的定制资源提供存储和访问服务。 CRD 对象的名称必须是合法的 DNS 子域名。
CRD 使得你不必编写自己的 API 服务器来处理定制资源,不过其背后实现的通用性也意味着你所获得的灵活性要比 API 服务器聚合少很多。
关于如何注册新的定制资源、使用新资源类别的实例以及如何使用控制器来处理事件, 相关的例子可参见定制控制器示例。
API 服务器聚合
通常,Kubernetes API 中的每个资源都需要处理 REST 请求和管理对象持久性存储的代码。 Kubernetes API 主服务器能够处理诸如 Pod 和 Service 这些内置资源, 也可以按通用的方式通过 CRD 来处理定制资源。
聚合层(Aggregation Layer) 使得你可以通过编写和部署你自己的 API 服务器来为定制资源提供特殊的实现。 主 API 服务器将针对你要处理的定制资源的请求全部委托给你自己的 API 服务器来处理, 同时将这些资源提供给其所有客户端。
选择添加定制资源的方法
CRD 更为易用;聚合 API 则更为灵活。请选择最符合你的需要的方法。
通常,如果存在以下情况,CRD 可能更合适:
- 定制资源的字段不多;
- 你在组织内部使用该资源或者在一个小规模的开源项目中使用该资源,而不是在商业产品中使用。
比较易用性
CRD 比聚合 API 更容易创建。
| CRD | 聚合 API |
|---|---|
| 无需编程。用户可选择任何语言来实现 CRD 控制器。 | 需要编程,并构建可执行文件和镜像。 |
| 无需额外运行服务;CRD 由 API 服务器处理。 | 需要额外创建服务,且该服务可能失效。 |
| 一旦 CRD 被创建,不需要持续提供支持。Kubernetes 主控节点升级过程中自动会带入缺陷修复。 | 可能需要周期性地从上游提取缺陷修复并更新聚合 API 服务器。 |
| 无需处理 API 的多个版本;例如,当你控制资源的客户端时,你可以更新它使之与 API 同步。 | 你需要处理 API 的多个版本;例如,在开发打算与很多人共享的扩展时。 |
高级特性与灵活性
聚合 API 可提供更多的高级 API 特性,也可对其他特性实行定制;例如,对存储层进行定制。
| 特性 | 描述 | CRD | 聚合 API |
|---|---|---|---|
| 合法性检查 | 帮助用户避免错误,允许你独立于客户端版本演化 API。这些特性对于由很多无法同时更新的客户端的场合。 | 可以。大多数验证可以使用 OpenAPI v3.0 合法性检查 来设定。CRDValidationRatcheting 特性门控允许在资源的失败部分未发生变化的情况下,忽略 OpenAPI 指定的失败验证。其他合法性检查操作可以通过添加合法性检查 Webhook来实现。 | 可以,可执行任何合法性检查。 |
| 默认值设置 | 同上 | 可以。可通过 OpenAPI v3.0 合法性检查的 default 关键词(自 1.17 正式发布)或更改性(Mutating)Webhook来实现(不过从 etcd 中读取老的对象时不会执行这些 Webhook)。 |
可以。 |
| 多版本支持 | 允许通过两个 API 版本同时提供同一对象。可帮助简化类似字段更名这类 API 操作。如果你能控制客户端版本,这一特性将不再重要。 | 可以。 | 可以。 |
| 定制存储 | 支持使用具有不同性能模式的存储(例如,要使用时间序列数据库而不是键值存储),或者因安全性原因对存储进行隔离(例如对敏感信息执行加密)。 | 不可以。 | 可以。 |
| 定制业务逻辑 | 在创建、读取、更新或删除对象时,执行任意的检查或操作。 | 可以。要使用 Webhook。 | 可以。 |
| 支持 scale 子资源 | 允许 HorizontalPodAutoscaler 和 PodDisruptionBudget 这类子系统与你的新资源交互。 | 可以。 | 可以。 |
| 支持 status 子资源 | 允许在用户写入 spec 部分而控制器写入 status 部分时执行细粒度的访问控制。允许在对定制资源的数据进行更改时增加对象的代际(Generation);这需要资源对 spec 和 status 部分有明确划分。 | 可以。 | 可以。 |
| 其他子资源 | 添加 CRUD 之外的操作,例如 "logs" 或 "exec"。 | 不可以。 | 可以。 |
| strategic-merge-patch | 新的端点要支持标记了 Content-Type: application/strategic-merge-patch+json 的 PATCH 操作。对于更新既可在本地更改也可在服务器端更改的对象而言是有用的。要了解更多信息,可参见使用 kubectl patch 来更新 API 对象。 |
不可以。 | 可以。 |
| 支持协议缓冲区 | 新的资源要支持想要使用协议缓冲区(Protocol Buffer)的客户端。 | 不可以。 | 可以。 |
| OpenAPI Schema | 是否存在新资源类别的 OpenAPI(Swagger)Schema 可供动态从服务器上读取?是否存在机制确保只能设置被允许的字段以避免用户犯字段拼写错误?是否实施了字段类型检查(换言之,不允许在 string 字段设置 int 值)? |
可以,依据 OpenAPI v3.0 合法性检查 模式(1.16 中进入正式发布状态)。 | 可以。 |
公共特性
与在 Kubernetes 平台之外实现定制资源相比, 无论是通过 CRD 还是通过聚合 API 来创建定制资源,你都会获得很多 API 特性:
| 功能特性 | 具体含义 |
|---|---|
| CRUD | 新的端点支持通过 HTTP 和 kubectl 发起的 CRUD 基本操作 |
| 监测(Watch) | 新的端点支持通过 HTTP 发起的 Kubernetes Watch 操作 |
| 发现(Discovery) | 类似 kubectl 和仪表盘(Dashboard)这类客户端能够自动提供列举、显示、在字段级编辑你的资源的操作 |
| json-patch | 新的端点支持带 Content-Type: application/json-patch+json 的 PATCH 操作 |
| merge-patch | 新的端点支持带 Content-Type: application/merge-patch+json 的 PATCH 操作 |
| HTTPS | 新的端点使用 HTTPS |
| 内置身份认证 | 对扩展的访问会使用核心 API 服务器(聚合层)来执行身份认证操作 |
| 内置鉴权授权 | 对扩展的访问可以复用核心 API 服务器所使用的鉴权授权机制;例如,RBAC |
| Finalizers | 在外部清除工作结束之前阻止扩展资源被删除 |
| 准入 Webhooks | 在创建、更新和删除操作中对扩展资源设置默认值和执行合法性检查 |
| UI/CLI 展示 | kubectl 和仪表盘(Dashboard)可以显示扩展资源 |
| 区分未设置值和空值 | 客户端能够区分哪些字段是未设置的,哪些字段的值是被显式设置为零值的 |
| 生成客户端库 | Kubernetes 提供通用的客户端库,以及用来生成特定类别客户端库的工具 |
| 标签和注解 | 提供涵盖所有对象的公共元数据结构,且工具知晓如何编辑核心资源和定制资源的这些元数据 |
准备安装定制资源
在向你的集群添加定制资源之前,有些事情需要搞清楚。
第三方代码和新的失效点的问题
尽管添加新的 CRD 不会自动带来新的失效点(Point of Failure),例如导致第三方代码被在 API 服务器上运行, 类似 Helm Charts 这种软件包或者其他安装包通常在提供 CRD 的同时还包含带有第三方代码的 Deployment,负责实现新的定制资源的业务逻辑。
安装聚合 API 服务器时,也总会牵涉到运行一个新的 Deployment。
存储
定制资源和 ConfigMap 一样也会消耗存储空间。创建过多的定制资源可能会导致 API 服务器上的存储空间超载。
聚合 API 服务器可以使用主 API 服务器相同的存储。如果是这样,你也要注意此警告。
身份认证、鉴权授权以及审计
CRD 通常与 API 服务器上的内置资源一样使用相同的身份认证、鉴权授权和审计日志机制。
如果你使用 RBAC 来执行鉴权授权,大多数 RBAC 角色都不会授权对新资源的访问 (除了 cluster-admin 角色以及使用通配符规则创建的其他角色)。 你要显式地为新资源的访问授权。CRD 和聚合 API 通常在交付时会包含针对所添加的类别的新的角色定义。
聚合 API 服务器可能会使用主 API 服务器相同的身份认证、鉴权授权和审计机制,也可能不会。
访问定制资源
Kubernetes 客户端库可用来访问定制资源。 并非所有客户端库都支持定制资源。Go 和 Python 客户端库是支持的。
当你添加了新的定制资源后,可以用如下方式之一访问它们:
kubectl- Kubernetes 动态客户端
- 你所编写的 REST 客户端
- 使用 Kubernetes 客户端生成工具所生成的客户端。 生成客户端的工作有些难度,不过某些项目可能会随着 CRD 或聚合 API 一起提供一个客户端。
接下来
13.3.2 - Kubernetes API 聚合层
使用聚合层(Aggregation Layer),用户可以通过附加的 API 扩展 Kubernetes, 而不局限于 Kubernetes 核心 API 提供的功能。 这里的附加 API 可以是现成的解决方案,比如 metrics server, 或者你自己开发的 API。
聚合层不同于 定制资源(Custom Resources)。 后者的目的是让 kube-apiserver 能够识别新的对象类别(Kind)。
聚合层
聚合层在 kube-apiserver 进程内运行。在扩展资源注册之前,聚合层不做任何事情。
要注册 API,你可以添加一个 APIService 对象,用它来 “申领” Kubernetes API 中的 URL 路径。
自此以后,聚合层将把发给该 API 路径的所有内容(例如 /apis/myextension.mycompany.io/v1/…)
转发到已注册的 APIService。
APIService 的最常见实现方式是在集群中某 Pod 内运行扩展 API 服务器(Extension API Server)。 如果你在使用扩展 API 服务器来管理集群中的资源,该扩展 API 服务器(也被写成 "extension-apiserver") 一般需要和一个或多个控制器一起使用。 apiserver-builder 库同时提供构造扩展 API 服务器和控制器框架代码。
响应延迟
扩展 API 服务器(Extension API Server)与 kube-apiserver 之间需要存在低延迟的网络连接。 发现请求需要在五秒钟或更短的时间内完成到 kube-apiserver 的往返。
如果你的扩展 API 服务器无法满足这一延迟要求,应考虑如何更改配置以满足需要。
接下来
- 阅读配置聚合层文档, 了解如何在自己的环境中启用聚合器。
- 接下来,了解安装扩展 API 服务器, 开始使用聚合层。
- 从 API 参考资料中研究关于 APIService 的内容。